目录
[1. 路由层 (routers/)](#1. 路由层 (routers/))
[2. 数据校验层 (schemas/)](#2. 数据校验层 (schemas/))
[3. 业务逻辑层 (crud/)](#3. 业务逻辑层 (crud/))
[4. 数据模型层 (models/)](#4. 数据模型层 (models/))
[5. 工具与配置层](#5. 工具与配置层)
[6. 入口文件 (main.py)](#6. 入口文件 (main.py))
一个典型的 FastAPI 项目的分层架构,通过清晰的目录划分实现了代码的模块化和解耦。下面是结构化解析:
一、项目整体架构
|-----------|-----------------|-----------------------------------|----------------------|
| 层级 | 目录 | 核心职责 | 技术栈 |
| 1. 路由层 | routers/ | 定义 API 接口,处理 HTTP 请求和响应 | FastAPI APIRouter |
| 2. 数据校验层 | schemas/ | 定义 Pydantic 模型,用于请求 / 响应数据的校验和序列化 | Pydantic |
| 3. 业务逻辑层 | crud/ | 封装数据库的增删改查(CRUD)操作,实现业务逻辑 | SQLAlchemy Async ORM |
| 4. 数据模型层 | models/ | 定义 SQLAlchemy ORM 模型,映射数据库表结构 | SQLAlchemy |
| 5. 工具与配置层 | utils/, config/ | 提供通用工具函数和项目配置 | Python 标准库 / 第三方库 |
| 6. 入口文件 | main.py | 项目启动入口,初始化 FastAPI 应用,注册路由 | FastAPI |
二、各模块详细解析
1. 路由层 ( routers/ )
作用 :按业务模块(如 news.py、users.py)拆分 API 路由,避免 main.py 代码臃肿。
核心操作:
定义 APIRouter 实例。
编写 @router.get()、@router.post() 等装饰器,声明接口路径、HTTP 方法和参数。
通过 Depends 注入数据库会话和其他依赖。
在 main.py 中通过 app.include_router() 注册到主应用。
2. 数据校验层 ( schemas/ )
作用:定义 Pydantic 模型,确保请求数据合法,并规范响应数据的结构。
核心操作:
定义请求模型(如 NewsCreate),用于接收和校验前端发送的数据。
定义响应模型(如 NewsResponse),用于过滤和格式化返回给前端的数据。
使用 Field 等装饰器配置字段验证规则(如长度、正则、必填项)。
3. 业务逻辑层 ( crud/ )
作用:封装所有数据库操作,是连接路由层和数据模型层的桥梁。
核心操作:
接收从路由层传递的参数和数据库会话。
调用 SQLAlchemy API(如 select()、add()、delete())执行 CRUD 操作。
处理复杂的业务逻辑(如数据聚合、权限判断),并返回处理后的数据给路由层。
4. 数据模型层 ( models/ )
作用:定义 SQLAlchemy ORM 类,精确映射数据库中的表和字段。
核心操作:
定义继承自 Base 的模型类,通过 tablename 指定表名。
使用 Mapped 和 mapped_column 定义字段类型、主键、外键、约束和注释。
所有模型在应用启动时,通过 Base.metadata.create_all() 自动创建数据库表。
5. 工具与配置层
utils/:存放通用的工具函数,如日期处理、字符串转换、自定义异常等,供全项目复用。
config/(如 db_conf.py):存放项目配置,如数据库连接 URL、连接池参数、密钥等,便于集中管理和环境切换。
6. 入口文件 ( main.py )
作用:项目的启动和核心配置文件。
核心操作:
创建 FastAPI 应用实例。
注册所有子路由。
定义启动 / 关闭事件(如应用启动时自动创建数据库表)。
配置中间件、异常处理器等。
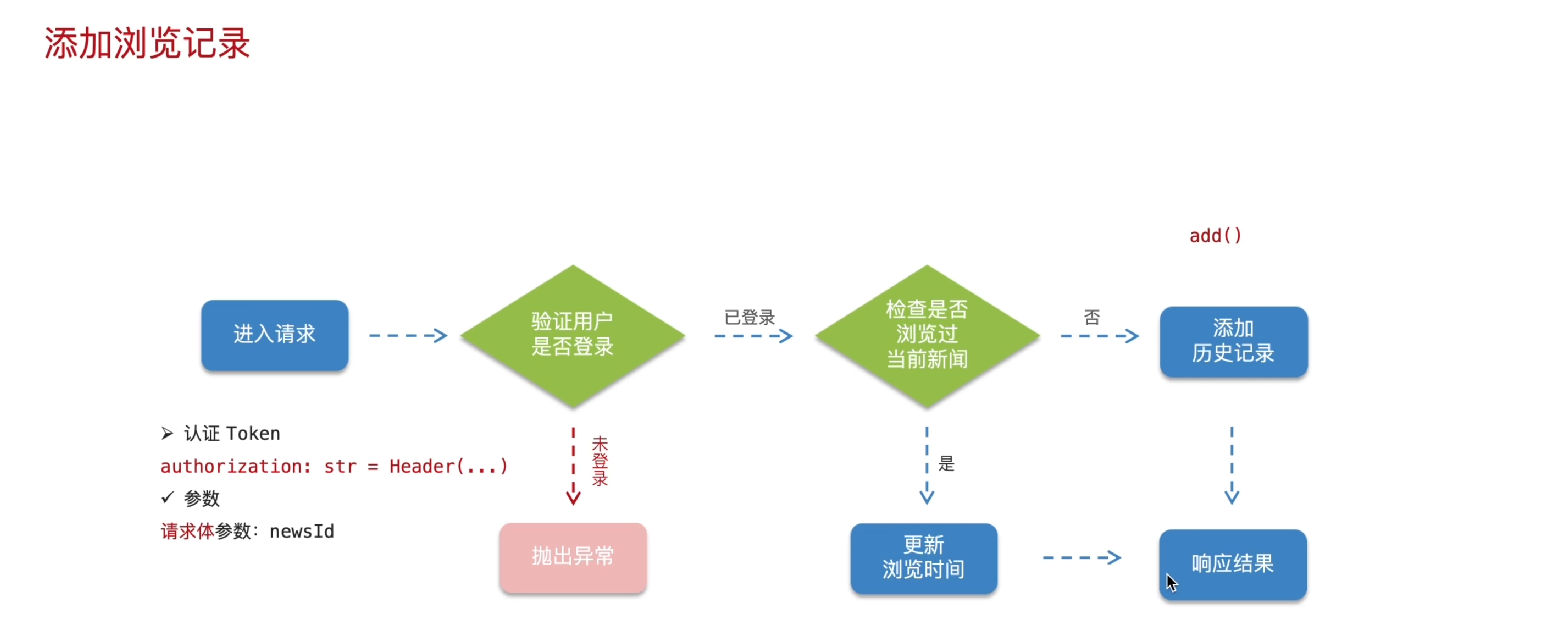
第一部分:添加浏览记录
一个基于 FastAPI 框架实现的 "添加浏览记录" 接口的完整设计与实现,主要分为接口文档说明 和代码实现两部分:
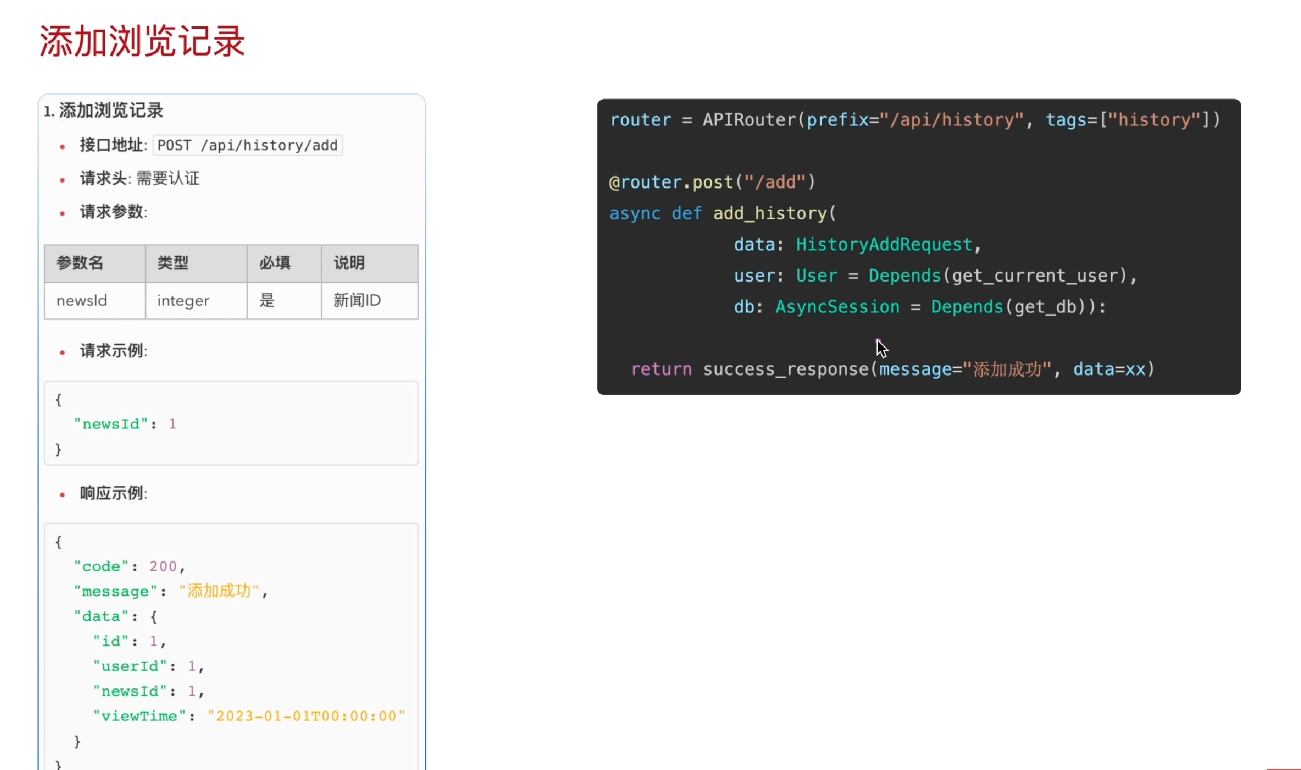 接口函数及详细说明如下:
接口函数及详细说明如下:
python
@router.post("/add")
async def add_history(
data: HistoryAddRequest,
user: User = Depends(get_current_user),
db: AsyncSession = Depends(get_db)
):
return success_response(message="添加成功", data=xx)
代码说明:
@router.post("/add"): 将函数绑定到 POST /api/history/add 路由。
函数参数:
data: HistoryAddRequest: 接收请求体,类型为 HistoryAddRequest(对应请求参数 newsId)。
user: User = Depends(get_current_user): 通过依赖注入获取当前已认证的用户信息。
db: AsyncSession = Depends(get_db): 通过依赖注入获取异步数据库会话。
返回值:调用 success_response 函数,返回标准化的成功响应,包含提示信息和数据(data=xx 为占位符,实际应为创建的浏览记录对象)。添加浏览记录开发流程总结
第二部分:获得浏览历史记录
一个基于 FastAPI 框架实现的 "获取浏览记录" 接口的完整设计与实现,主要分为接口文档说明 和代码实现两部分:
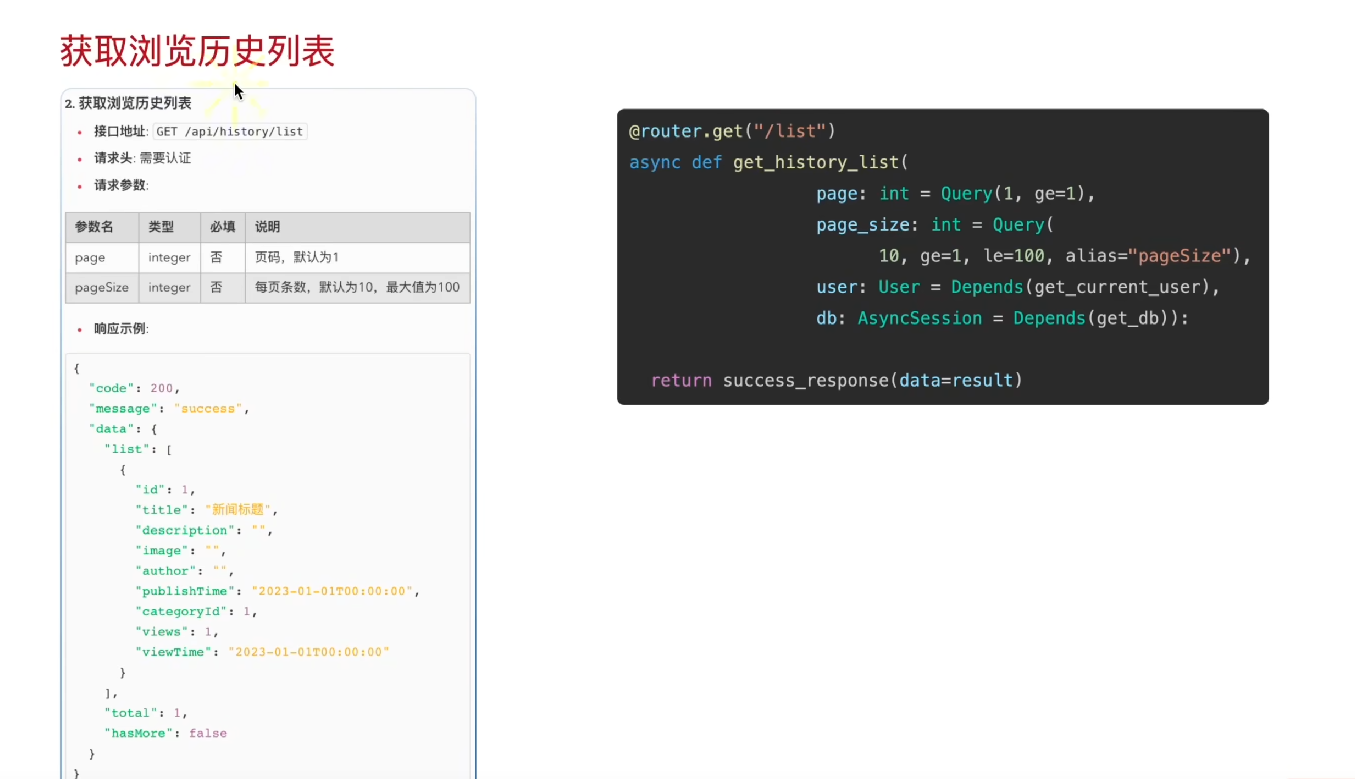
接口函数实现:
python
@router.get("/list")
async def get_history_list(
page: int = Query(1, ge=1),
page_size: int = Query(10, ge=1, le=100, alias="pageSize"),
user: User = Depends(get_current_user),
db: AsyncSession = Depends(get_db)
):
# 1. 从数据库查询当前用户的浏览历史,按 viewTime 倒序
# 2. 应用分页:offset = (page-1)*page_size, limit = page_size
# 3. 统计总条数 total,计算是否还有下一页 hasMore
# 4. 构造返回数据结构
return success_response(data=result)
依赖注入:
get_current_user:获取当前登录用户,用于筛选其个人浏览历史。
get_db:获取异步数据库会话,用于执行查询。
参数校验:使用 Query 对页码和页大小进行合法性校验,确保输入有效。
身份验证:确保只有登录用户才能访问自己的浏览历史。
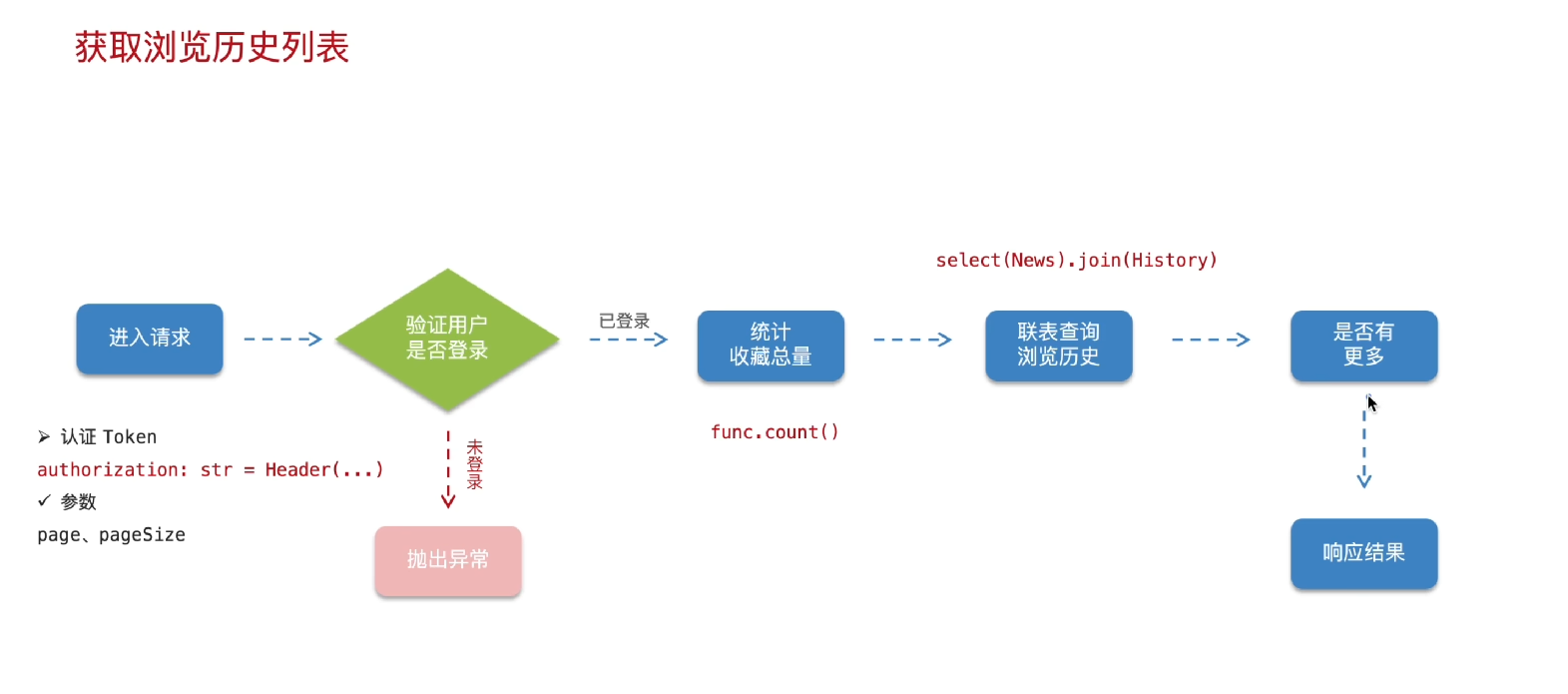
数据查询:根据用户 ID 从数据库中筛选浏览历史记录,并按浏览时间倒序排列。
分页处理:根据 page 和 page_size 计算偏移量,实现分页查询。
结果封装:将查询结果、总条数和是否有更多数据的标志,统一封装成前端友好的格式返回。添加浏览记录开发流程总结
第三部分:删除浏览历史记录
一个基于 FastAPI 框架实现的 "删除浏览记录" 接口的完整设计与实现,主要分为接口文档说明 和代码实现两部分:
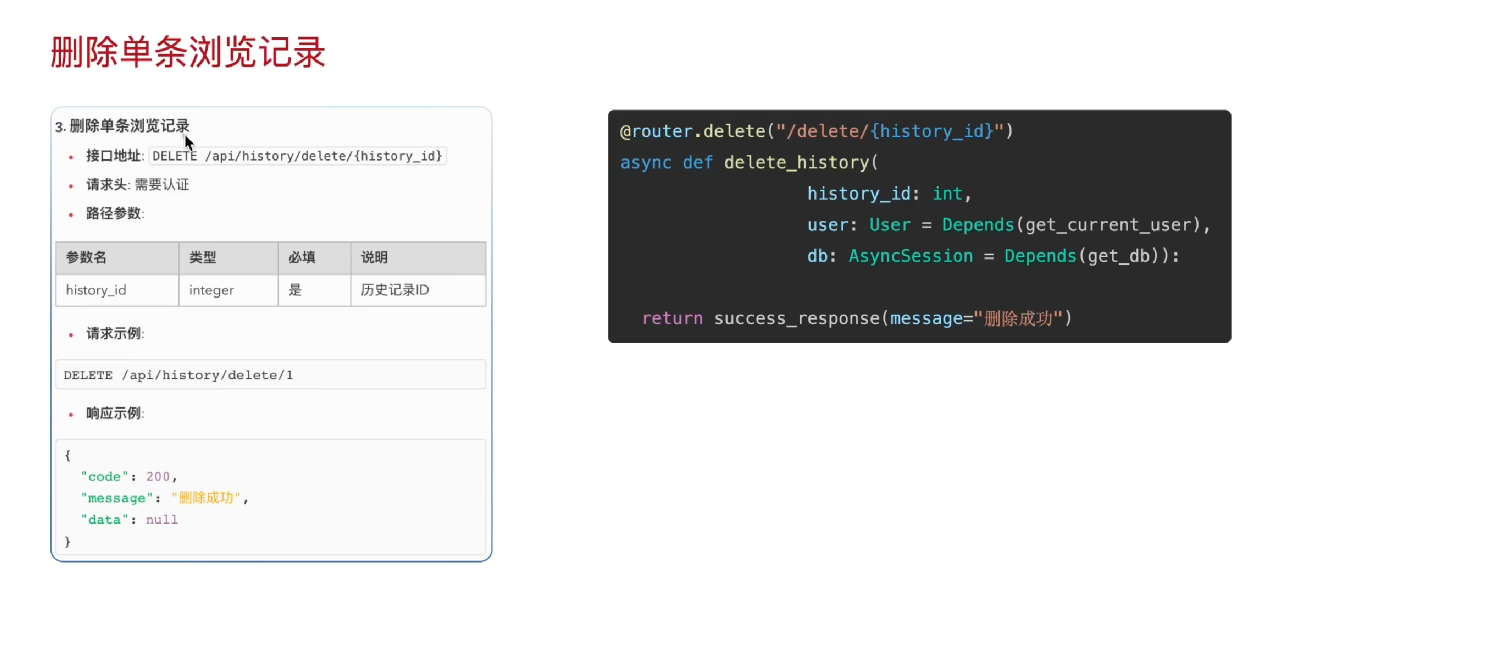 接口函数实现:
接口函数实现:
python
@router.delete("/delete/{history_id}")
async def delete_history(
history_id: int,
user: User = Depends(get_current_user),
db: AsyncSession = Depends(get_db)
):
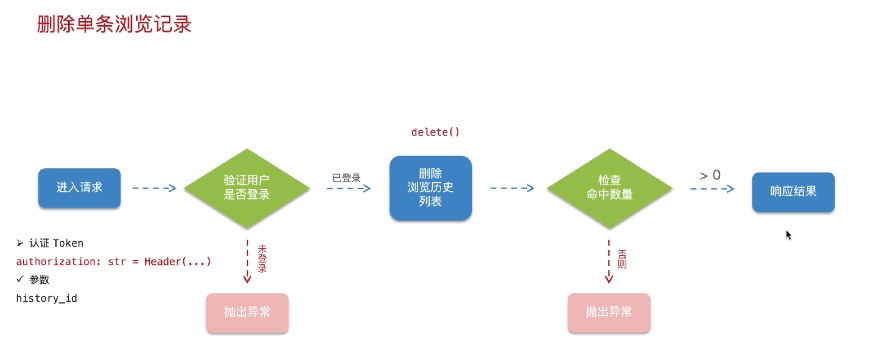
# 1. 从数据库查询该 history_id 对应的记录
# 2. 校验该记录是否属于当前登录用户(防止越权删除)
# 3. 如果存在且属于该用户,则执行删除操作
# 4. 返回成功响应
return success_response(message="删除成功")删除浏览记录开发流程总结
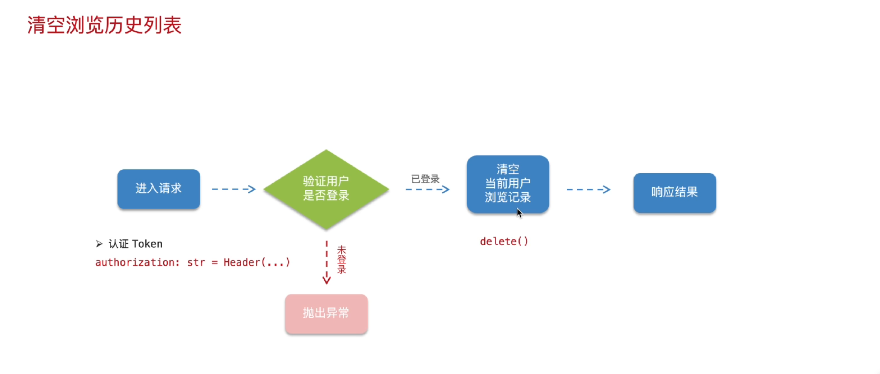
第四部分:清空历史列表
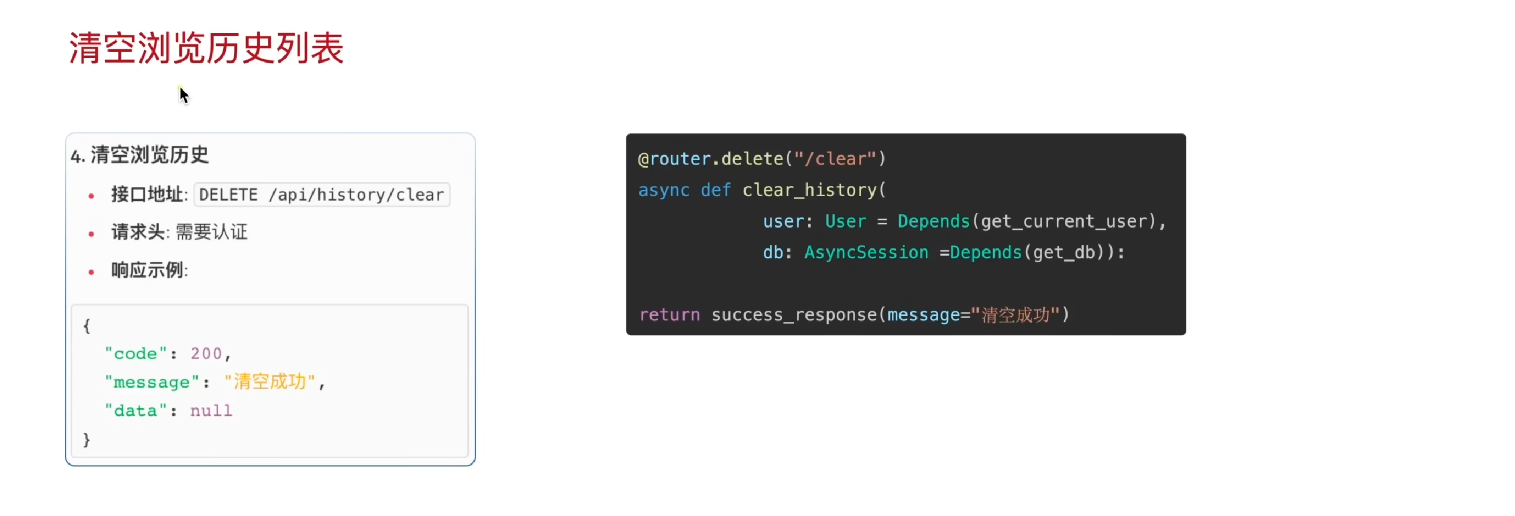
清空浏览历史开发流程总结