1. unordered_set和set的使用差异
-
set要求Key支持小于比较,而unordered_set要求Key支持转成整形且支持等于比较
-
set的iterator是双向迭代器,unordered_set是单向迭代器,其次set底层是红黑树
红黑树是二叉搜索树,走中序遍历是有序的,所以set迭代器遍历是有序+去重
而unordered_set底层是哈希表,迭代器遍历是无序+去重 -
大多数场景下,unordered_set的增删查改更快⼀些,因为红黑树增删查改效率是logn ,而哈希表增删查平均效率是O(1) ,具体可以参看下⾯代码的演示的对比差异。
map和unordered_map的差异也类似
2. 直接定址法
当关键字的范围比较集中时,直接定址法就是非常简单高效的方法
比如⼀组关键字值都在a,z的小写字母,那么我们开⼀个26个数的数组,每个关键字acsii码-a的ascii码就是存储位置的下标
字符串中的第一个唯一字符
c
class Solution {
public:
int firstUniqChar(string s) {
// 每个字⺟的ascii码-'a'的ascii码作为下标映射到count数组,数组中存储出现的次数
int count[26] = {0};
// 统计次数
for(auto ch : s)
{
count[ch-'a']++;
}
for(size_t i = 0; i < s.size(); ++i)
{
if(count[s[i]-'a'] == 1)
return i;
}
return -1;
}
};3. 哈希冲突
直接定址法的缺点也非常明显,当关键字的范围比较分散时,就很浪费内存甚至内存不够用。假设只要数据范围是0,9999的100(N)个值,此时大量浪费空间
所以一般我们采用哈希函数来解决,除模运算,用每个值%100(N),得到的就是这个数的下标,但50%100=50,250%100=50,此时两个不同的key映射到同一个位置,这种问题我们叫做哈希冲突,或者哈希碰撞,冲突是不可避免的,所以尽可能设计出优秀的哈希函数
4. 负载因子
哈希表中已经映射存储了N个值,哈希表的大小为M,负载因子=N/M,他的英文为load factor。负载因子越大,哈希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低
5. 哈希函数
⼀个好的哈希函数应该让N个关键字被等概率的均匀的散列分布到哈希表的M个空间中,但是实际中却很难做到,但是我们要尽量往这个方向去考量设计
5.1 除法散列法/除留余数法
除法散列法也叫做除留余数法,顾名思义,假设哈希表的大小为M,那么通过key除以M的余数作为映射位置的下标,也就是哈希函数为:h(key)=key%M
当使用除法散列法时,要尽量避免M为某些值,如2的幂,10的幂等。如果是2的x次幂 ,那么key%2的x次幂本质相当于保留key的后X位,那么后x位相同的值,计算出的哈希值都是⼀样的,就冲突了
{63,31}看起来没有关联的值,如果M是16,也就是2的4次幂 ,那么计算出的哈希值都是15,因为63的二进制后8位是00111111,31的二进制后8位是00011111,因为后四位相同,如果是10的x次幂 ,就更明显了,保留的都是10进值的后x位,如:{112,12312},如果M是100,也就是10的2次幂 ,那么计算出的哈希值都是12冲突
当使用除法散列法时,一般 M取不太接近2的整数次幂的⼀个质数(素数)
6. 处理哈希冲突
实践中哈希表⼀般还是选择除法散列法作为哈希函数,当然哈希表无论选择什么哈希函数也避免不了冲突,那么插入数据时,如何解决冲突呢?主要有两种两种方法,开放定址法和链地址法。
6.1 开放定址法
1. 线性探测
从发生冲突的位置开始,依次线性向后探测,直到寻找到下⼀个没有存储数据的位置为止,如果走到哈希表尾,则回绕到哈希表头的位置, 遍历到空查找结束
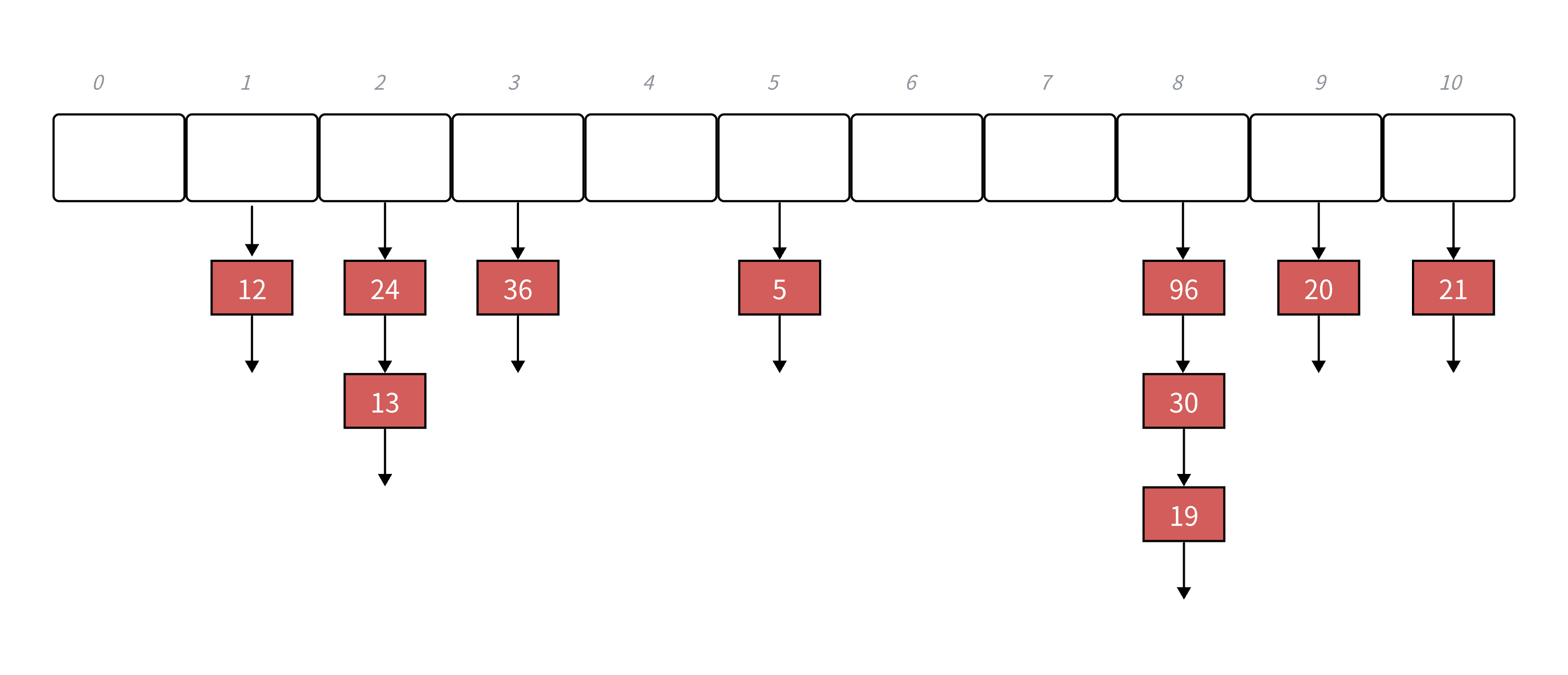
下面演示 {19,30,5,36,13,20,21,12} 等这⼀组值映射到M=11的表中。

h(19) = 8,h(30) = 8,h(5) = 5,h(36) = 3,h(13) = 2,h(20) = 9,h(21) = 10,h(12) = 1

这里首先是19%M=8,映射到8的位置,30%M=8也应该映射到8的位置,但是8的位置已经有值了,只能把30放到9的位置,20%11=9,但此时9的位置已经有值了,只能放到10的位置,21%11=10,10的位置有值了,放到0的位置,10+1%M=0
存在互相践踏的问题导致效率低下
2. 二次探测
二次探测是映射到的下标位置±i的平方,i从1开始取值,i的最大取值是表的一半,第一次一般是+,第二次是-,当计算的值小于0时+M
 h(19) = 8, h(30) = 8, h(52) = 8, h(63) = 8, h(11) = 0, h(22) = 0
h(19) = 8, h(30) = 8, h(52) = 8, h(63) = 8, h(11) = 0, h(22) = 0
6.2 链地址法
h(19) = 8,h(30) = 8,h(5) = 5,h(36) = 3,h(13) = 2,h(20) = 9,h(21) = 10,h(12) = 1,h(24) = 2,h(96) = 88
stl中unordered_xxx的最大负载因子基本控制在1,大于1就扩容