NIN(Network in Network)是陈天奇(Min Lin)等人在2014年提出的经典网络结构。
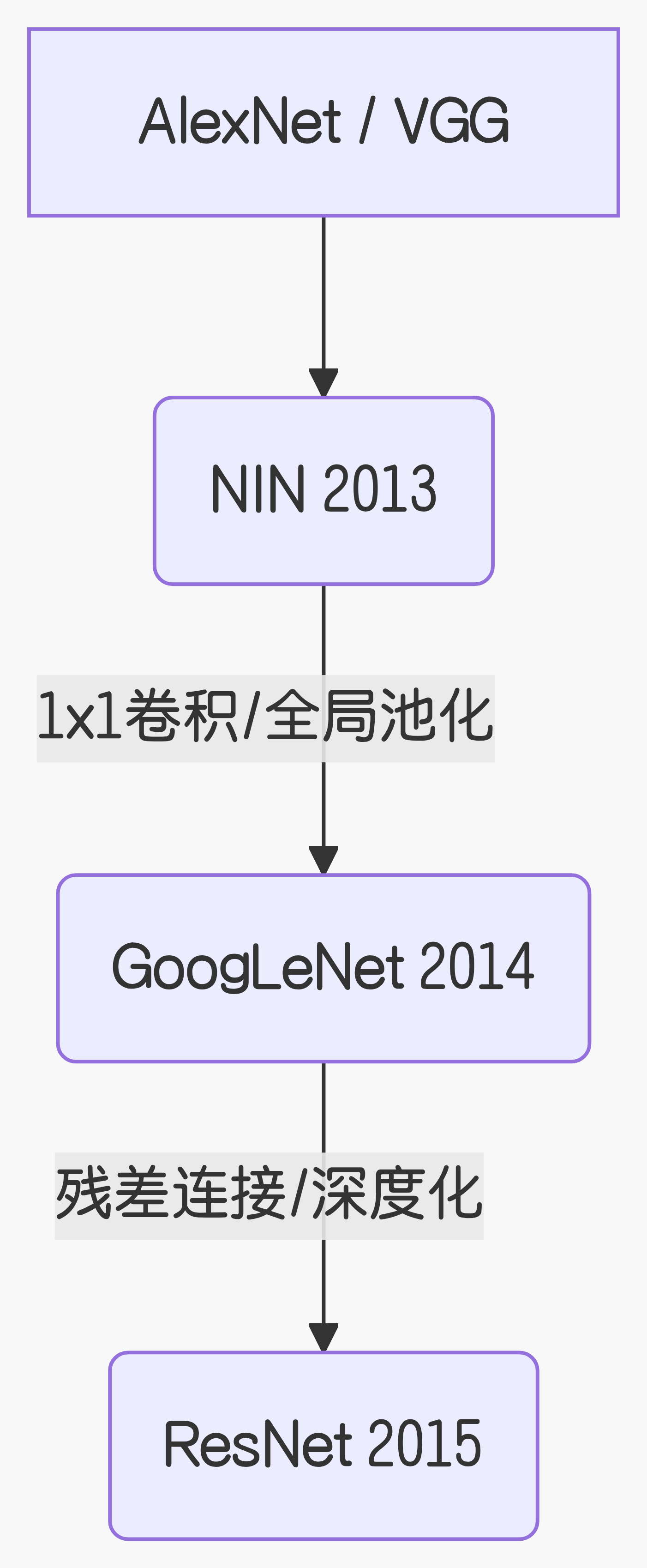
NIN直接参与了2014年的ImageNet大赛,虽然最终冠军是GoogLeNet,但它通过一系列"实验科学"般的探索,为深度学习贡献了两项核心经验------1x1卷积和全局平均池化思想被GoogLeNet和后续的ResNet等网络吸收采纳,成为了现代深度学习的基石技术。
1 它探索出了什么?(实验科学的经验)
NIN的核心贡献在于验证了"网络结构可以更复杂"和"分类器可以更简单"这两个在当时反直觉的结论。
经验一 :局部特征需要更强的非线性变换。
探索过程:传统卷积层(Conv)只是线性滤波+激活函数,NIN认为这不够复杂。它尝试在卷积层内部嵌套一个微型多层感知机(MLP),即"Network in Network"。
结论:这种"微网络"结构(后来演变为1x1卷积)能极大增强模型的非线性表达能力,让网络在局部区域就能学习到更抽象的特征。
经验二 :全连接层不是必须的。
探索过程:当时的主流网络(如AlexNet)依赖巨大的全连接层(FC)进行分类,容易过拟合且参数多。NIN大胆尝试去掉FC层,直接用全局平均池化(GAP)将特征图取平均作为分类依据。
结论:GAP不仅减少了参数、防止过拟合,还让网络对输入图像的平移更鲁棒。这一设计后来被ResNet等几乎所有现代网络沿用。
2 网络结构
如下文章非常好
【深入浅出之NIN网络 】https://blog.csdn.net/a8039974/article/details/143110885
深度学习网络从入门到入土 网络中的网络NiN
https://blog.csdn.net/qq_54636039/article/details/158070225
3 pytorch代码实现
以下代码构建了一个标准的NiN模型,适用于CIFAR-10或Fashion-MNIST等数据集。
c
import torch
import torch.nn as nn
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
"""定义NiN块:卷积 + 1x1卷积 + 1x1卷积"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), # 1x1卷积模拟全连接
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), # 1x1卷积模拟全连接
nn.ReLU()
)
class NiN(nn.Module):
def __init__(self, num_classes=10):
super(NiN, self).__init__()
self.net = nn.Sequential(
# 第一层:输入3通道,输出96通道,卷积核11x11,步长4(用于大图,如224x224)
nin_block(3, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2), # 池化降维
# 第二层:输入96通道,输出256通道,卷积核5x5
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
# 第三层:输入256通道,输出384通道,卷积核3x3
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5), # 防止过拟合
# 第四层:输出通道数直接设为类别数,准备做全局平均池化
nin_block(384, num_classes, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)), # 全局平均池化,输出1x1
nn.Flatten() # 展平为向量
)
def forward(self, x):
return self.net(x)
# 使用示例
model = NiN(num_classes=10)
print(model)⚙️ 参数说明
输入尺寸:上述代码默认适配ImageNet(224x224)的尺寸。如果用于CIFAR-10(32x32),需要调整第一层的卷积核和步长(如改为 kernel_size=5, strides=1, padding=2 )。
1x1卷积:这是NiN的灵魂,它让网络在早期就能进行跨通道的信息交互,比传统CNN更早地"理解"特征。
3 影响
NIN(Network in Network)虽然参数量大、计算成本高,但它提出的两个核心思想,直接启发了后续几乎所有主流深度学习架构的设计,堪称现代深度学习的"思想启蒙"。
3.1 1x1 卷积:跨通道的信息交互
这是 NIN 最伟大的贡献。它首次将 1x1 卷积作为网络的基本构建块,这直接导致了两个革命性变化:
降维与升维:1x1 卷积可以灵活地增加或减少通道数,极大地提升了网络的灵活性。
跨通道特征融合:它允许网络在早期就进行通道间的信息交互,而不仅仅是空间上的特征提取。
后续影响:
Inception 系列:直接借鉴了 NIN 的 1x1 卷积思想,在 Inception 模块中大量使用 1x1 卷积来降低计算量(Bottleneck 结构)和融合特征。GoogleNet 是 Inception 系列的开山之作,也是该系列中最具代表性的模型之一。
ResNet:在残差块中广泛使用 1x1 卷积来调整通道维度,实现恒等映射。
SENet:使用 1x1 卷积进行通道注意力权重的计算。
3.2 全局平均池化:替代全连接层
NIN 首次提出用 Global Average Pooling (GAP) 替代传统的全连接层(FC Layer)。
优势:GAP 将每个特征图直接映射为一个数值,极大地减少了参数量,有效防止了过拟合,并且对输入图像尺寸不敏感。
后续影响:
ResNet:ResNet 直接采纳了 GAP 作为网络的最后一层,成为现代 CNN 的标准配置。
轻量化网络:在 MobileNet、ShuffleNet 等轻量级网络中,GAP 是减少参数、提升效率的关键手段。
3.3 小结
NIN 虽然"生不逢时"(当时硬件算力不足),但它播下的种子在后续架构中开花结果。可以说,没有 NIN 的 1x1 卷积和全局池化,就没有现代深度学习的轻量化和高效化。
4 实验科学论
其实神经网络结构的探索也是基于一定的零散的不成体系的理论基础进行探索,是个实验科学。找到一个数学理论或者其他领域的理论,感觉可以尝试下,进行实验,看效果,效果好,就赶紧进行深层的理论挖掘。优秀的被后来者继承,成为后续网络的基础组件。
这些都是实验验证。
5 与Googlenet和resnet等网络关系
NIN 的"微网络"思想启发了 GoogLeNet 的 Inception 结构,而 ResNet 则解决了它们"太深难训"的问题。