文章目录
-
- [一、Redis Set 核心特性](#一、Redis Set 核心特性)
- [二、Set 核心命令(交、并、差集)](#二、Set 核心命令(交、并、差集))
- 三、典型应用场景与实战模拟
-
- [场景1:交集模拟: 共同好友/共同关注](#场景1:交集模拟: 共同好友/共同关注)
- 场景2:并集模拟:活动参与用户去重统计
- 场景3:差集:个性化推荐(好友/内容)
- 四、核心优势与适用场景小结

一、Redis Set 核心特性
Redis Set 是无序、唯一的字符串集合,底层基于哈希表实现,支持高效的交、并、差集运算,天然适配"去重、关系计算"类分布式场景,是实现"共同好友、活动去重、推荐系统"的最优解。
二、Set 核心命令(交、并、差集)
| 操作类型 | 命令格式 | 作用 |
|---|---|---|
| 交集 | SINTER key1 key2 [key3...] |
返回多个 Set 的共同元素(都包含的元素) |
| 并集 | SUNION key1 key2 [key3...] |
返回多个 Set 的全部元素(自动去重) |
| 差集 | SDIFF key1 key2 [key3...] |
返回 key1 有、但其他 key 没有的元素(顺序敏感) |
| 新增元素 | SADD key member1 [member2...] |
向 Set 中添加元素(Set 自动去重) |
| 查看所有元素 | SMEMBERS key |
返回 Set 中的所有元素 |
三、典型应用场景与实战模拟
场景1:交集模拟: 共同好友/共同关注
核心命令 : SINTER
业务思路
将每个用户的"好友/关注列表"存储为独立的 Set,通过交集运算快速获取两个用户的共同好友/关注,无需遍历全量数据。
模拟(命令行)
redis
# 1. 初始化数据:用户A和用户B的关注列表
SADD user:follow:A B C D E # 用户A关注:B、C、D、E
SADD user:follow:B A C D F # 用户B关注:A、C、D、F
# 2. 计算共同关注(交集)
SINTER user:follow:A user:follow:B # 返回结果:C、D
# 3. 查看验证
SMEMBERS user:follow:A # 确认用户A的关注列表
SMEMBERS user:follow:B # 确认用户B的关注列表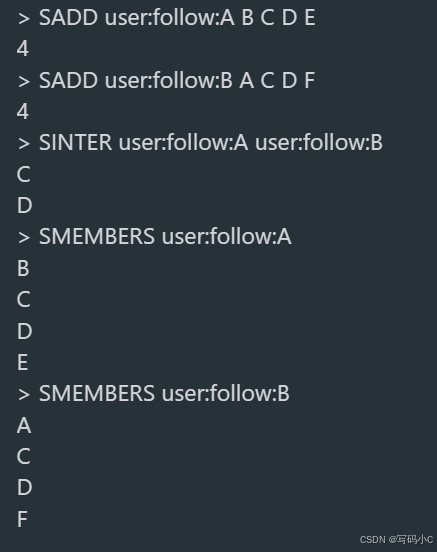
场景2:并集模拟:活动参与用户去重统计
核心命令:SUNION
业务思路
将每个活动的参与用户存储为独立的 Set,通过并集运算汇总所有参与过活动的用户(自动去重),避免重复统计。
模拟(命令行)
redis
# 1. 初始化数据:活动1和活动2的参与用户
SADD activity:participant:1 A B C # 活动1参与用户:A、B、C
SADD activity:participant:2 B C D # 活动2参与用户:B、C、D
# 2. 统计所有参与过活动的用户(并集)
SUNION activity:participant:1 activity:participant:2 # 返回结果:A、B、C、D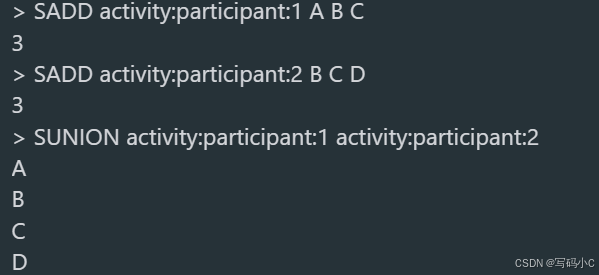
场景3:差集:个性化推荐(好友/内容)
核心命令:SDIFF
业务思路
以"用户已拥有的内容"为基准 Set,减去"候选池内容"的 Set,剩余元素即为"用户未接触过、可推荐的内容",适配好友推荐、音乐/商品推荐等场景。
实战模拟(命令行)
redis
# 1. 初始化数据:我的好友 + 好友A的好友
SADD my:friends A B C # 我的好友:A、B、C
SADD friend:A:friends B C D E # 好友A的好友:B、C、D、E
# 2. 计算"好友A有但我没有的好友"(差集)
SDIFF friend:A:friends my:friends # 返回结果:D、E(可推荐给我的好友)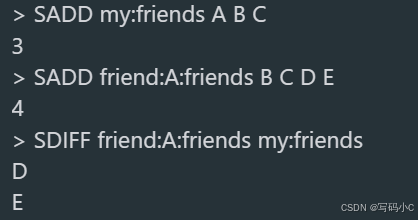
redis
# 扩展场景:音乐推荐
SADD my:music 歌1 歌2 歌3 # 我听过的歌
SADD hot:music 歌2 歌3 歌4 歌5 # 热门歌单
SDIFF hot:music my:music # 返回结果:歌4、歌5(可推荐的新歌)
四、核心优势与适用场景小结
| 运算类型 | 核心优势 | 典型业务场景 |
|---|---|---|
| 交集 | 快速计算"共同特征",无需全量遍历 | 共同好友、共同关注、共同喜好、权限交集校验 |
| 并集 | 全局去重汇总,避免重复数据 | 活动参与用户统计、全量标签汇总、多渠道数据去重 |
| 差集 | 精准筛选"差异化内容",适配推荐逻辑 | 好友推荐、内容推荐、未读消息筛选、权限缺失校验 |
关键注意事项
-
Redis Set 交并差集运算为内存操作,性能极高,适合百万级以下数据量;
-
差集运算顺序敏感 :
SDIFF A B≠SDIFF B A,需根据业务逻辑确认 Set 顺序; -
分布式场景下,可通过多实例分片存储超大 Set,结合
SUNIONSTORE/SINTERSTORE将运算结果存入新 Set,便于后续复用。- 比如我们要计算两个集合交集后的容量:
redis# 先存结果到临时 key SUNIONSTORE temp activity:participant:1 activity:participant:2 SCARD temp DEL temp