关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
提到多数据源,你可以首先想到Mybatis-Plus的多数据源。今天介绍的多数据源绝对颠覆你的认知。(至少把我震惊了)
有没有想过通过SQL的方式查询内存对象,CSV,甚至关联查询。以前想都不敢想,本能反应根本实现不了。现在可以了,通过Apache Calcite就可以实现。
02 简介
Apache Calcite是一个高性能数据库的基础框架,特别擅长通过标准SQL接口统一访问和优化来自多种数据源的数据。
Calcite 通过 Adapters(适配器)来连接第三方数据源。每个适配器都让一种外部数据(如 CSV 文件、MySQL 数据库、Java内存对象、Redis 等)在 Calcite 看来像是一张可以通过 SQL查询的表。
Calcite 是一个"查询优化框架",它位于各种数据源之上,提供统一的SQL查询接口。它不持有数据,只负责将查询计划优化并下推到底层数据源执行。它不是数据库,本身不存储数据,因此 不支持标准的INSERT、UPDATE、DELETE 等数据操作语言(DML)。
官网地址:calcite.apache.org/
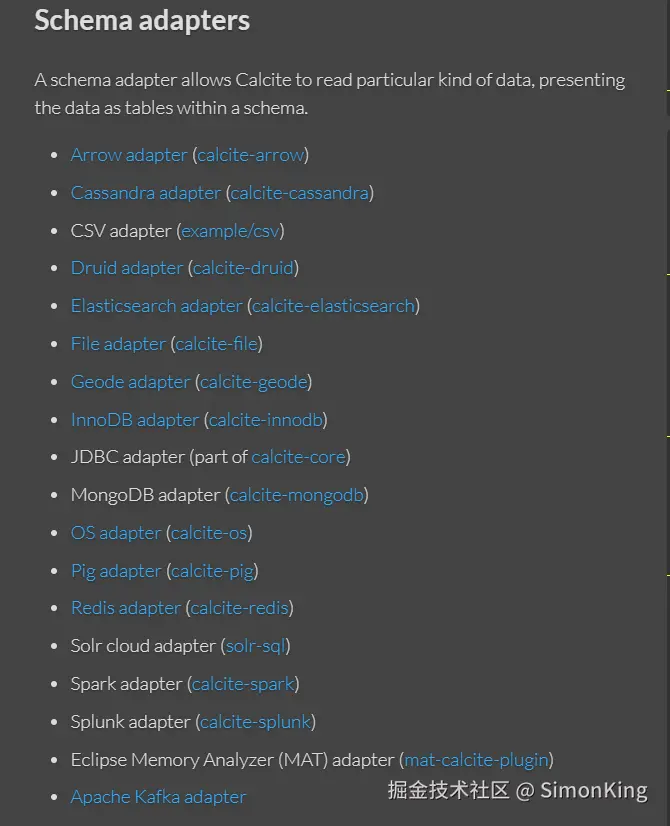
支持的适配器:
03 主要参数说明
我们分别从Java内存对象、CSV文件、Mysql数据库来了解,最后看看混合查询的效果。
3.1 主要依赖
xml
<!-- Apache Calcite -->
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.38.0</version>
</dependency>
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-csv</artifactId>
<version>1.38.0</version>
</dependency>3.2 参数说明
多数据管理的核心文件是一个JSON文件,包含的主要参数:
json
{
"version": "1.0",
"defaultSchema": "your schema name",
"schemas": [
{
"name": "your schema name",
"type": "custom",
"factory": "",
"operand": {
}
}
]
}最外层参数
version:定义的版本defaultSchema:默认使用的Schemaschemas:具体的Schema,是一个数组
具体Schema参数
name:Schema的名称type:Schema类型。包括:custom、map、jdbccustom:自定义/扩展模式,需要配置factorymap:内置的、基于内存映射的简单模式,无需配置factoryjdbc:传统的JDBC连接模式
factory:适配工厂operand:数据源的相关信息,不同的数据源参数不同
04 内存对象SQL查询
内存对象的SQL查询来自calcite-core的支持,关键的Schema类:
java
org.apache.calcite.adapter.java.ReflectiveSchema$Factory注意这里的$,表示内部类。
模型数据
json
{
"version": "1.0",
"defaultSchema": "MEM",
"schemas": [
{
"name": "MEM",
"type": "custom",
"factory": "org.apache.calcite.adapter.java.ReflectiveSchema$Factory",
"operand": {
"class": "com.simonking.boot.calcite.schema.UserSchema"
}
}
]
}内存对象使用的是反射,这里需要配置class。对应的class就是数据源。
4.1 数据源定义
java
public class UserSchema {
public final User[] users;
public UserSchema() {
// 模拟数据
this.users = new User[]{
new User(1, "zhangsan", 18),
new User(2, "admin", 20),
new User(3, "lisi", 22)
};
}
/**
* @Description: 字段类型
**/
@AllArgsConstructor
public class User {
/** 用户id */
public final Integer id;
/** 用户名 */
public final String name;
/** 年龄 */
public final Integer age;
}
}因为所数据源无法修改数据,数据库可以设计为final类型。
库表为public类型的字段,字段的类型必须是数组类型,否则无法获取数据。表的字段必须为内部类,内部类的字段必须是public类型。
4.2 客户端查询
客户端的和标准的jdbc非常类似。
java
@Test
void test01() throws Exception {
CalciteConnection calciteConn = getCalciteConnection();
String sql = "SELECT * FROM MEM.users";
Statement stmt = calciteConn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
doResult(rs);
}这里的SQL需要注意:必须携带Schema,否则无法识别。
获取连接的方法
java
private static CalciteConnection getCalciteConnection() throws Exception {
Class.forName("org.apache.calcite.jdbc.Driver");
Properties prop = new Properties();
prop.put("lex", "MYSQL");
prop.put("model", "src/main/resources/calcite-model.json");
Connection connection = DriverManager.getConnection("jdbc:calcite:", prop);
CalciteConnection calciteConn = connection.unwrap(CalciteConnection.class);
return calciteConn;
}这里需要配置Properties参数:
lex:词汇侧率,类似标准SQL的方言,默认是ORACLE。这里改成MYSQL后,表名不区分大小写。

model:指定配置数据源的JSON文件路径
输入结果
java
private void doResult(ResultSet rs) throws SQLException {
ResultSetMetaData meta = rs.getMetaData();
StringBuffer sb = new StringBuffer("[");
while (rs.next()) {
sb.append("{");
for (int i = 1; i <= meta.getColumnCount(); i++) {
sb.append(meta.getColumnName(i))
.append(":")
.append(rs.getObject(i))
.append(",");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("},");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("]");
System.out.println(sb);
}这里没啥好说的,就是将查询的结果拼接成json,方便查看。
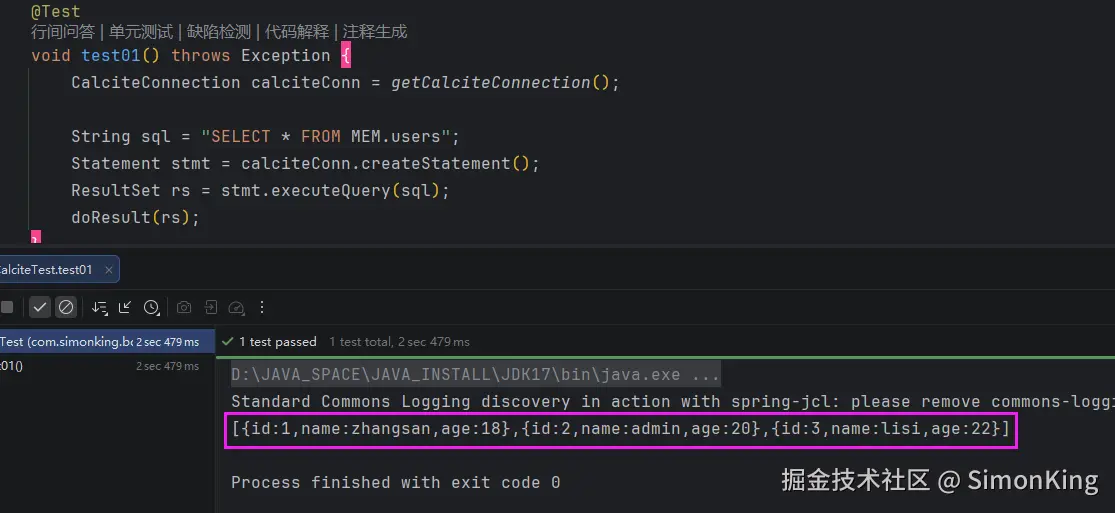
4.3 查询结果
05 CSV查询
CSV的查询需要引入扩展包calcite-csv,关键的Schema类:
java
org.apache.calcite.adapter.csv.CsvSchemaFactory模型数据
只需要追加Schema即可。
json
{
"version": "1.0",
"defaultSchema": "MEM",
"schemas": [
{
"name": "MEM",
"type": "custom",
"factory": "org.apache.calcite.adapter.java.ReflectiveSchema$Factory",
"operand": {
"class": "com.simonking.boot.calcite.schema.UserSchema"
}
},
{
"name": "CSV",
"type": "custom",
"factory": "org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand": {
"directory": "csv",
"flavor": "scannable"
}
}
]
}这里的的数据源参数:directory表示csv的位置,默认在classpath下。flavor表示查询的类型。

可以不配置,默认scannable
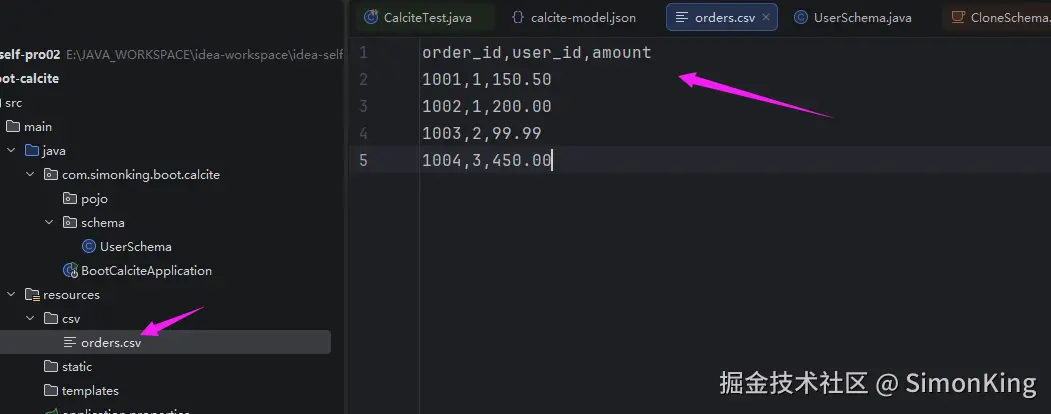
4.1 数据源定义
直接定义csv文件即可,文件名为表名
4.2 客户端查询
java
@Test
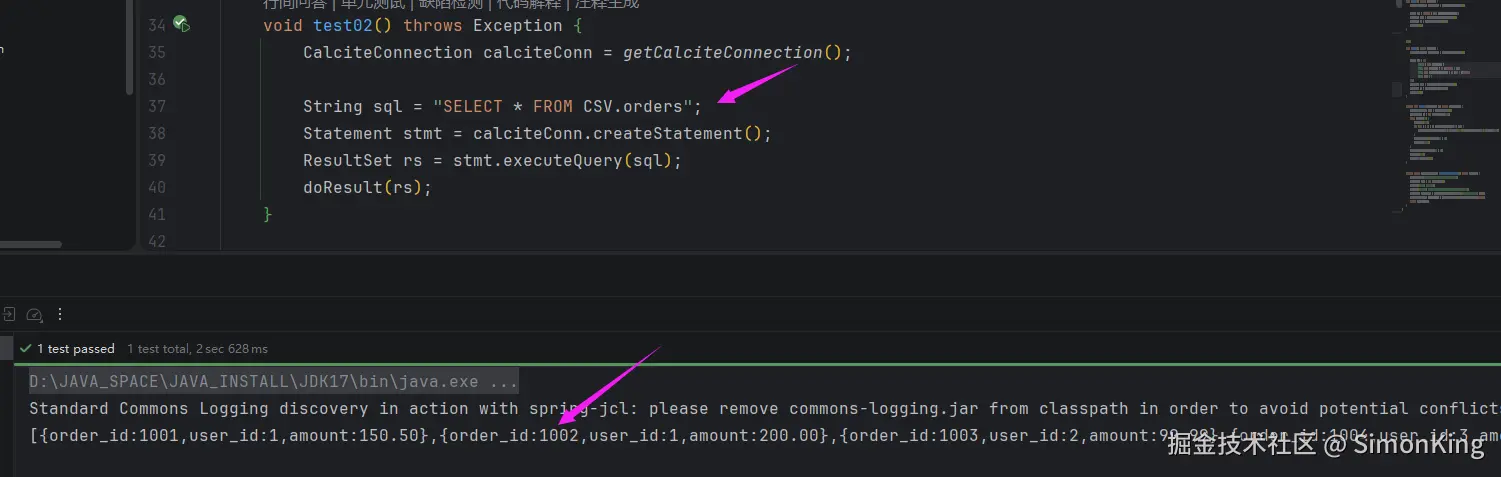
void test02() throws Exception {
CalciteConnection calciteConn = getCalciteConnection();
String sql = "SELECT * FROM CSV.orders";
Statement stmt = calciteConn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
doResult(rs);
}4.3 查询结果
06 Mysql查询
Mysql查询来自calcite-core的支持,关键的Schema类:
java
org.apache.calcite.adapter.jdbc.JdbcSchema$Factory模型数据
只需要追加Schema即可。
json
{
"version": "1.0",
"defaultSchema": "MEM",
"schemas": [
{
"name": "MEM",
"type": "custom",
"factory": "org.apache.calcite.adapter.java.ReflectiveSchema$Factory",
"operand": {
"class": "com.simonking.boot.calcite.schema.UserSchema"
}
},
{
"name": "CSV",
"type": "custom",
"factory": "org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand": {
"directory": "csv",
"flavor": "scannable"
}
},
{
"name": "MYSQL_DB",
"type": "custom",
"factory": "org.apache.calcite.adapter.jdbc.JdbcSchema$Factory",
"operand": {
"jdbcUrl": "jdbc:mysql://localhost:3306/test",
"jdbcUser": "root",
"jdbcPassword": "root"
}
}
]
}6.1 客户端查询
按照正常的SQL编写即可。
java
@Test
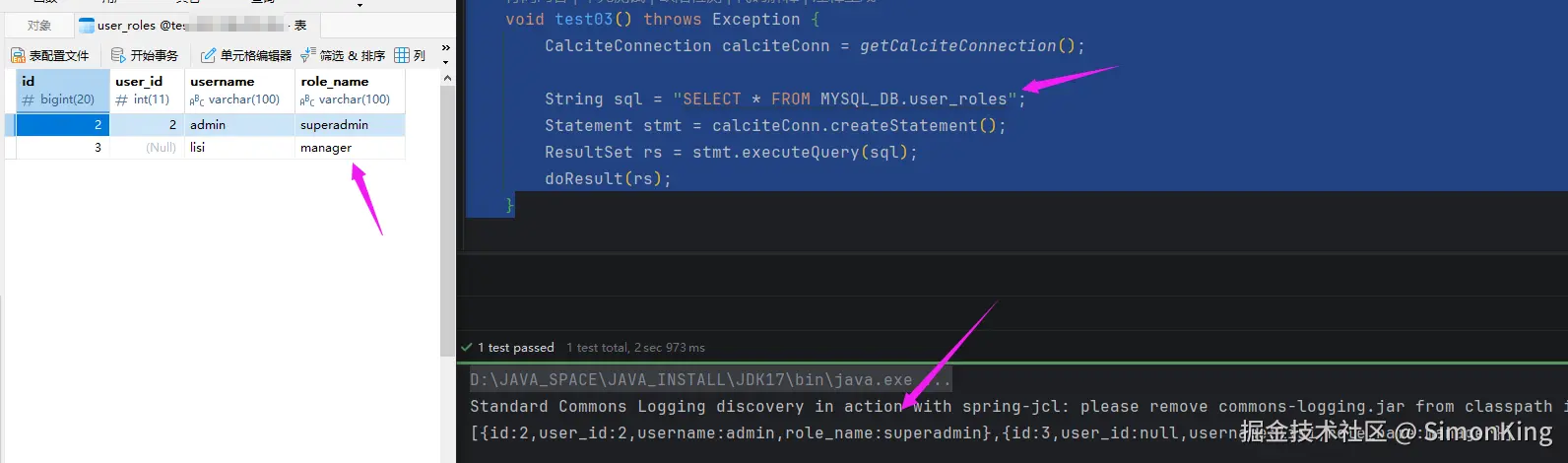
void test03() throws Exception {
CalciteConnection calciteConn = getCalciteConnection();
String sql = "SELECT * FROM MYSQL_DB.user_roles";
Statement stmt = calciteConn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
doResult(rs);
}6.2 查询结果
07 关联查询
沿用之前的模型配置,直接编写关联SQL即可。
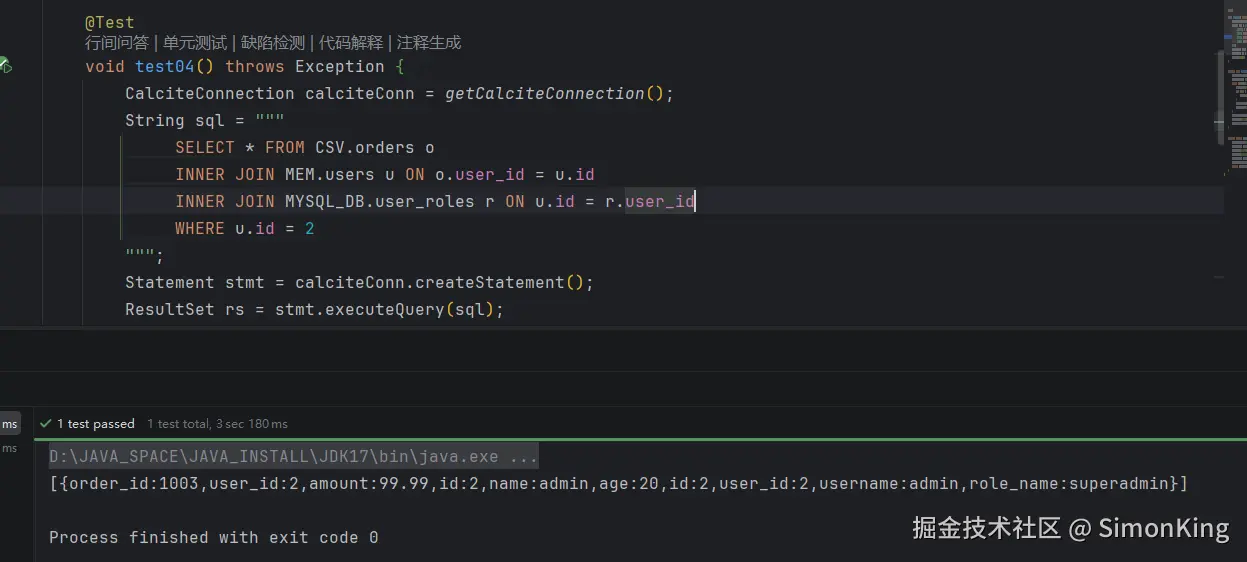
08 小结
很多企业会分库,但是为了解决跨库查询的问题,经常会同步一个全量的库来解决跨库查询的问题。而Apache Calcite可以直接解决此问题。
在测试过程中,发现版本升级到1.39.0及以上,如果出现关联CSV查询的时候出现查询结果为空的问题,主要原因是关联的CSV内容为空。但是单独查询又是可以的。不知道这个是BUG还是官方的一个优化。有知道的老铁么?