5| 模型评估与模型选择
1| 损失函数
对于模型 一次预测 结果的好坏 ,需要有一个度量标准。
对于监督学习而言,给定一个输入_X_,选取的模型就相当于一个"决策函数"f ,它可以输出一个预测结果_f(X),而真实的结果(标签)记为_Y 。f(X) 和_Y_之间可能会有偏差,我们就用一个损失函数 (loss function)来度量预测偏差的程度,记作 L(Y,f(X))。
- 损失函数用来衡量模型预测误差的大小(损失函数值越小,模型就越好)
- 损失函数是_f(X)_和_Y_的非负实值函数;
1)0-1损失函数
L(Y,f(X))={1,Y≠f(X)0,Y=f(X) L(Y, f(X)) = \begin{cases} 1, & Y \neq f(X) \\ 0, & Y = f(X) \end{cases} L(Y,f(X))={1,0,Y=f(X)Y=f(X)
2)平方损失函数
L(Y,f(X))=(Y−f(X))2 L(Y, f(X)) = (Y - f(X))^2 L(Y,f(X))=(Y−f(X))2
3)绝对损失函数
L(Y,f(X))=∣Y−f(X)∣ L(Y, f(X)) = |Y - f(X)| L(Y,f(X))=∣Y−f(X)∣
4)对数似然损失函数
L(Y,P(Y∣X))=−logP(Y∣X) L(Y, P(Y|X)) = -\log P(Y|X) L(Y,P(Y∣X))=−logP(Y∣X)
机器学习和深度学习中,log常指ln通常指自然对
2| 经验误差
给定一个训练数据集,数据个数为 n:
T={(x1,y1),(x2,y2),...,(xn,yn)} T = \{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\} T={(x1,y1),(x2,y2),...,(xn,yn)}
根据选取的损失函数,就可以计算模型 f(X)在训练集上的平均误差,称为训练误差 ,也被称作 经验误差 (empirical error)或 经验风险(empirical risk)。
Remp(f)=1n∑i=1nL(yi,f(xi)) R_{\text{emp}}(f) = \frac{1}{n} \sum_{i=1}^{n} L(y_i, f(x_i)) Remp(f)=n1i=1∑nL(yi,f(xi))
类似地,在测试数据集上平均误差,被称为测试误差 或者泛化误差(generalization error)。
一般情况下对模型评估的策略,就是考察经验误差:当经验误差(训练误差)最小时,就认为取到了最优的模型。这种策略被称为 经验风险最小化(empirical risk minimization,ERM)。
3| 拟合与欠拟合
拟合 (Fitting)是指机器学习模型在训练数据上调整参数以逼近目标函数的过程。理想情况下,模型不仅能在训练数据上表现良好,更能从中学习到数据背后的真实规律,从而在未见过的测试数据上也具有良好的预测能力,即具备良好的泛化能力 。
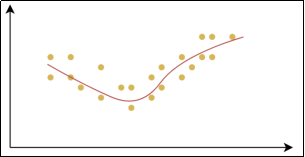
欠拟合 (Underfitting):是指模型在训练数据上表现不佳,无法很好地捕捉数据中的规律。这样的模型不仅在训练集上表现不好,在测试集上也同样表现差。
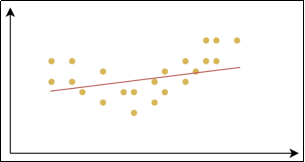
过拟合 (Overfitting):是指模型在训练数据上表现得很好,但在测试数据或新数据 上表现较差的情况。过拟合的模型对训练数据中的噪声或细节过度敏感,把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,从而失去了泛化能力。
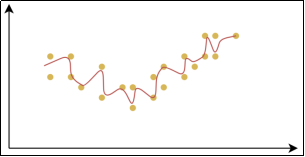
产生欠拟合和过拟合的根本原因,是模型 的复杂度过低或过高,从而导致测试误差(泛化误差)偏大。
- 欠拟合:模型在训练集和测试集上误差都比较大。模型过于简单,高偏差。
- 过拟合:模型在训练集上误差较小,但在测试集上误差较大。模型过于复杂,高方差。
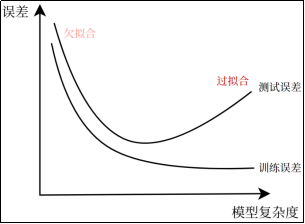
3.1| 欠、过拟合产生原因与解决办法
产生原因:
- 模型复杂度不足:模型过于简单,无法捕捉数据中的复杂关系。
- 特征不足:输入特征不充分,或者特征选择不恰当,导致模型无法充分学习数据的模式。
- 训练不充分:训练过程中迭代次数太少,模型没 有足够的时间学习数据的规律。
- 过强的正则化:正则化项设置过大,强制模型过于简单,导致模型无法充分拟合数据。
解决办法:
- 增加模型复杂度:选择更复杂的模型。
- 增加特征或改进特征工程:添加更多的特征或通过特征工程来创造更有信息量的特征。
- 增加训练时间:增加 训练的迭代次数,让模型有更多机会去学习。
- 减少正则化强度( λ):如果使用了正则化,尝试减小正则化的权重,以让模型更灵活。
3.1.2| 过拟合
产生原因:
- 模型复杂度过高:模型过于复杂,参数太多
- 训练数据不足:数据集太小,模型能记住 训练数据的细节,但无法泛化到新数据。
- 特征过多:特征太多,模型可能会"记住 "数据中的噪声,而不是学到真正的规律。
- 训练过长:训练时间过长,导致模型学习到 训练数据中的噪声,而非数据的真正规律。
解决办法:
-
减少模型复杂度:降低模型的参数数量、使用简化的模型或降维来减小模型复杂度
-
增加训练数据:收集更多数据,或通过数据增强来增加训练数据的多样性
-
使用正则化:引入L1、L2正则化,避免过度拟合训练数据
-
交叉验证:使用交叉验证技术评估模型在不同数据集上的表现,以减少过拟合的风险(交叉验证不能防止过拟合,但它能识别出过拟合的真相;)
发现问题:如果交叉验证的误差远高于训练误差 → 警告:可能过拟合!
指导调参
:比如调整正则化强度 λ:
- λ 太小 → 交叉验证误差高(过拟合,惩罚小,噪声也学了)
- λ 太大 → 交叉验证误差也高(欠拟合,惩罚大,特征都没了)
- 选交叉验证误差最低的 λ → 找到最佳平衡点
公平比较模型:避免因为某次"幸运划分"选了一个实际上会过拟合的模型
场景 作用 超参数调优(如正则化强度 λ、树的深度) 用交叉验证选择在验证集上表现最好的超参数,避免选到过拟合的配置 模型比较(如 SVM vs 随机森林) 基于交叉验证得分选泛化能力强的模型 防止数据划分偶然性 避免因某次"幸运"的训练/测试划分而误判模型性能
- 早停:训练时,当模型的验证损失不再下降 时,提前停止训练,避免过度拟合训练集
4| 正则化
正则化(Regularization)是一种在训练机器学习模型时,在损失函数中添加额外项 ,来惩罚过大的参数,进而限制模型复杂度、避免过拟合,提高模型泛化能力的技术。
如在平方损失函数中加入正则化项。(总损失=数据损失+正则化 )
Loss=1n(∑i=1n(f(xi)−yi)2+λ∑i=1kωi2) Loss = \frac{1}{n} (\sum_{i=1}^{n} (f(\mathbf{x}i) - y_i)^2 + \lambda \sum{i=1}^{k} \omega_i^2) Loss=n1(i=1∑n(f(xi)−yi)2+λi=1∑kωi2)
原损失函数 的目的:更好的拟合数据集
∑i=1n(f(xi)−yi)2 \sum_{i=1}^{n} (f(\mathbf{x}_i) - y_i)^2 i=1∑n(f(xi)−yi)2
正则化项 的目的:减小参数的大小,从而降低模型的复杂度。
λ∑i=1kωi2 \lambda \sum_{i=1}^{k} \omega_i^2 λi=1∑kωi2
这里的λ 是 正则化系数 (一定>0),用来表示惩罚项的权重,正则化系数不属于模型的参数,无法通过训练学习得到,需要在模型训练开始之前手动设置,这种参数被称为"超参数";正则化项中的求和(1 到 k):是对k 个模型参数(权重)的大小进行惩罚。
常见的正则化技术有 L1 正则化和 L2 正则化。
4.1.1|L1 正则化(Lasso 回归)
L1 正则化在损失函数中加入参数的绝对值之和:
LossL1=原Loss+λ∑i=1k∣ωi∣ Loss_{L1} = \text{原}Loss + \lambda \sum_{i=1}^{k} |\omega_i| LossL1=原Loss+λi=1∑k∣ωi∣
L1 正则化通过惩罚模型参数的绝对值,使得部分权重趋近于 0 甚至变为 0 。这会导致特征选择,即模型会自动"丢弃"一些不重要的特征。L1 正则化有助于创建稀疏模型(即许多参数为 0)。在解决回归问题时,使用 L1 正则化也被称为"Lasso 回归"。
λ 超参数控制着正则化的强度。较大的 λ 值意味着强烈的正则化,会使模型更简单,可能导致欠拟合;而较小的 λ 值则会使模型更复杂,可能导致过拟合。
4.1.2|L2 正则化(Ridge 回归,岭回归)
L2 正则化在损失函数中加入参数的平方之和:
LossL2=原Loss+λ∑i=1kωi2 Loss_{L2} = \text{原}Loss + \lambda \sum_{i=1}^{k} \omega_i^2 LossL2=原Loss+λi=1∑kωi2
L2 正则化通过惩罚模型参数的平方,使得所有参数都变得更小,但不会将参数强行压缩为 0。它会使得模型尽量平滑,从而防止过拟合。
在解决回归问题时,使用 L2 正则化也被称为"岭回归"。
4.1.3|ElasticNet 正则化(弹性网络回归)
ElasticNet 正则化结合了 L1 和 L2 正则化,通过调整两个正则化项的比例来取得平衡,从而同时具备稀疏性和稳定性的优点。
LossElasticNet=原Loss+λ(α∑i=1n∣ωi∣+1−α2∑i=1nωi2) Loss_{ElasticNet} = \text{原}Loss + \lambda \left( \alpha \sum_{i=1}^{n} |\omega_i| + \frac{1 - \alpha}{2} \sum_{i=1}^{n} \omega_i^2 \right) LossElasticNet=原Loss+λ(αi=1∑n∣ωi∣+21−αi=1∑nωi2)
其中α∈0,1,决定 L1 和 L2 的权重。
4.1.4| 关于L1和L2的解读
L1 会让权重变成 0,而 L2 不会。
导数为0的点称为驻点 ,是不是最小值,要看 整体函数形状。
L2的倒数(处处可导)
∂∂wj(λwj2)=2λwj \frac{\partial}{\partial w_j} \left( \lambda w_j^2 \right) = 2\lambda w_j ∂wj∂(λwj2)=2λwj📌 特点:
当 wj=0,梯度(导数) = 0
越接近 0,惩罚越小(当 w→0 ,导数2λw→0 ),正则项几乎失效
L1 的导数在w=0处,左右导数不一样,所以不可导 。当w→0 ,惩罚的大小=常数λ,正则项从不"变弱",拉力恒定。
梯度始终 指向 0
一旦 w 被更新到负数:
- L1 拉力立刻反向
- 又把 w 推回 0
0 变成一个"陷阱点" ,最终w变成0 ;
当数据力量比较大的时候,训练到一定步骤,梯步不再下降,这个w就保存了下来。
∂∂wj∣wj∣={+1wj>0−1wj<0不可导(次梯度 −1,1)wj=0 \frac{\partial}{\partial w_j} |w_j| = \begin{cases} +1 & w_j > 0 \\ -1 & w_j < 0 \\ \text{不可导(次梯度 } -1, 1 \text{)} & w_j = 0 \end{cases} ∂wj∂∣wj∣=⎩ ⎨ ⎧+1−1不可导(次梯度 −1,1)wj>0wj<0wj=0
5| 交叉验证
交叉验证(Cross-Validation)是一种评估模型泛化能力的方法,通过将数据集划分为多个子集,反复进行训练和验证,以减少因单次数据划分带来的随机性误差。通过交叉验证能更可靠地估计模型在未知数据上的表现。亦能避免因单次数据划分不合理导致的模型过拟合或欠拟合。
5.1| 简单交叉验证(Hold-Out Validation)
将数据划分为训练集和验证集(如70%训练,30%验证)。结果受单次划分影响较大,可能高估或低估模型性能。
5.2| k折交叉验证(k-Fold Cross-Validation)
将数据均匀分为k个子集(称为"折"),每次用k−1折训练,剩余1折验证,重复k次后取平均性能。充分利用数据,结果更稳定。
- 用交叉验证选择最好的模型结构/超参数(比如 λ=0.1 比 λ=1.0 效果好)
- 固定超参数后 ,用全部数据重新训练一个最终模型
- 这个最终模型用于实际预测
5.2.1| 举例:
第一步:定义候选超参数集合
candidates = [0.01, 0.1, 1.0, 10.0]第二步:对每个候选λ,做 K 折交叉验证
以 λ=0.1为例(K=5,数据共100条):
- 将数据分成5折(每折20条)
- 循环5次:
- 用4折(80条)训练一个模型(使用 λ=0.1λ=0.1 )
- 在剩下1折(20条)上计算验证误差(如 MSE)
- 得到5个验证误差 → 取平均,记为 CV_score(λ=0.1)。
对每个λ都重复上述过程,得到:
- CV_score(0.01)=0.85CV_score(0.01)=0.85
- CV_score(0.1)=0.72CV_score(0.1)=0.72 ← 最低!
第三步:选择 CV 分数最好超参集,然后用全部数据用于训练
5.3| 留一交叉验证(Leave-One-Out,LOO)
每次仅留一个样本作为验证集,其余全部用于训练,重复直到所有样本都被验证一次。适用于小数据集,计算成本极高。
5.4| 验证对比
| 方法 | 训练/验证划分 | 重复次数 | 适用场景 |
|---|---|---|---|
| 简单划分 | 80% 训练 ,20% 验证 | 1 次 | 数据多、快速测试 |
| K折交叉验证(如5折) | 每次 80% 训练 ,20% 验证 | 5 次 | 通用、平衡效率与稳定性 |
| 留一交叉验证(LOO) | (n−1) 训练 , 1 验证 | n 次 | 极小数据集(n < 50) |