目录
[10.1 条件独立性](#10.1 条件独立性)
[10.2 有向图模型](#10.2 有向图模型)
[10.2.1 示例 1:简单有向图(下雨→出门→带伞)](#10.2.1 示例 1:简单有向图(下雨→出门→带伞))
[10.2.2 示例 2:计算机视觉应用 ------ 图像分类中的有向图](#10.2.2 示例 2:计算机视觉应用 —— 图像分类中的有向图)
[10.2.3 示例 3:有向图的推理(已知结果推原因)](#10.2.3 示例 3:有向图的推理(已知结果推原因))
[10.2.4 总结](#10.2.4 总结)
[10.3 无向图模型](#10.3 无向图模型)
[10.3.1 示例 1:简单无向图(图像像素依赖)](#10.3.1 示例 1:简单无向图(图像像素依赖))
[10.3.2 示例 2:计算机视觉应用 ------ 图像去噪(无向图)](#10.3.2 示例 2:计算机视觉应用 —— 图像去噪(无向图))
[10.4 有向图模型与无向图模型的对比](#10.4 有向图模型与无向图模型的对比)
[10.5 计算机视觉中的图模型](#10.5 计算机视觉中的图模型)
[实战代码:CRF 图像语义分割(无向图扩展)](#实战代码:CRF 图像语义分割(无向图扩展))
[10.6 含有多个未知量的模型推理](#10.6 含有多个未知量的模型推理)
[10.6.1 求最大后验概率的解](#10.6.1 求最大后验概率的解)
[10.6.2 求后验概率分布的边缘分布](#10.6.2 求后验概率分布的边缘分布)
[10.6.3 最大化边缘](#10.6.3 最大化边缘)
[10.6.4 后验分布的采样](#10.6.4 后验分布的采样)
[10.7 样本采样](#10.7 样本采样)
[10.7.1 有向图模型的采样](#10.7.1 有向图模型的采样)
[10.7.2 无向图模型的采样](#10.7.2 无向图模型的采样)
[10.8 学习](#10.8 学习)
[10.8.1 有向图模型的学习](#10.8.1 有向图模型的学习)
[10.8.2 无向图模型的学习](#10.8.2 无向图模型的学习)
前言
大家好!今天给大家拆解《计算机视觉:模型、学习和推理》这本书的第 10 章 ------ 图模型。图模型是计算机视觉中处理不确定性问题的 "瑞士军刀",它把复杂的概率关系用直观的图形表示出来,让我们能清晰地看到变量之间的依赖关系。这篇文章会避开繁琐的公式,用通俗的语言 + 可直接运行的 Python 代码 + 可视化对比图,帮你彻底搞懂图模型的核心概念和应用。
10.1 条件独立性
核心概念
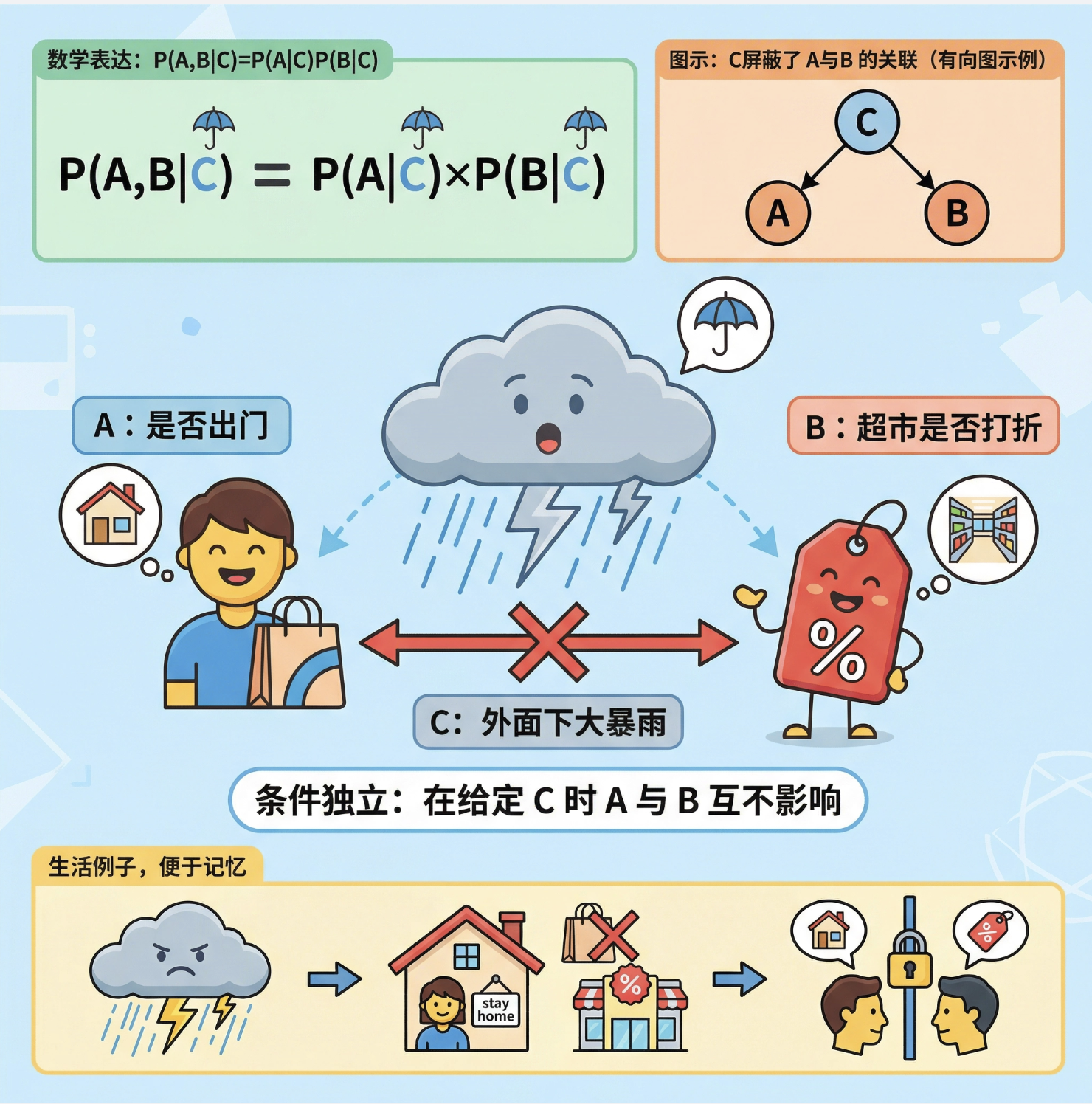
条件独立性是图模型的 "灵魂",可以通俗理解为:在给定 C 的情况下,A 和 B 就 "互不认识" 了,A 的变化不会影响 B,B 的变化也不会影响 A。
举个生活例子:你今天是否出门(A)和超市是否打折(B)本来可能有关系,但如果给定 "外面下大暴雨"(C),那不管超市打不打折,你都不会出门,此时 A 和 B 在 C 的条件下独立。
在数学上,条件独立表示为:P (A,B|C) = P (A|C) P (B|C)
代码验证条件独立性
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
# Mac系统Matplotlib中文显示配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 定义三个变量:A(出门), B(超市打折), C(下雨)
# 生成数据:C=1表示下雨,C=0表示不下雨
np.random.seed(42)
n_samples = 1000
# 生成C(下雨概率30%)
C = np.random.binomial(1, 0.3, n_samples)
# 生成A:不下雨时出门概率80%,下雨时出门概率5%
A = np.where(C == 0,
np.random.binomial(1, 0.8, n_samples),
np.random.binomial(1, 0.05, n_samples))
# 生成B:超市打折概率50%(和A无关,仅和C无关)
B = np.random.binomial(1, 0.5, n_samples)
# 验证条件独立性:计算P(A=1|B=1,C=1) 和 P(A=1|C=1)
# 1. 给定C=1时,B=1且A=1的概率
mask_c1 = C == 1
mask_c1_b1 = (C == 1) & (B == 1)
p_a1_c1_b1 = np.sum(A[mask_c1_b1] == 1) / len(A[mask_c1_b1])
p_a1_c1 = np.sum(A[mask_c1] == 1) / len(A[mask_c1])
# 可视化对比
fig, ax = plt.subplots(figsize=(8, 5))
categories = ['P(A=1|C=1,B=1)', 'P(A=1|C=1)']
values = [p_a1_c1_b1, p_a1_c1]
bars = ax.bar(categories, values, color=['#1f77b4', '#ff7f0e'])
# 添加数值标签
for bar, val in zip(bars, values):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{val:.3f}', ha='center', va='bottom')
ax.set_ylabel('概率值')
ax.set_title('条件独立性验证:给定下雨(C=1),A和B独立')
ax.set_ylim(0, 0.1)
plt.show()
# 输出结果
print(f"P(A=1|C=1,B=1) = {p_a1_c1_b1:.3f}")
print(f"P(A=1|C=1) = {p_a1_c1:.3f}")
print("两者几乎相等,验证了条件独立性!")运行效果
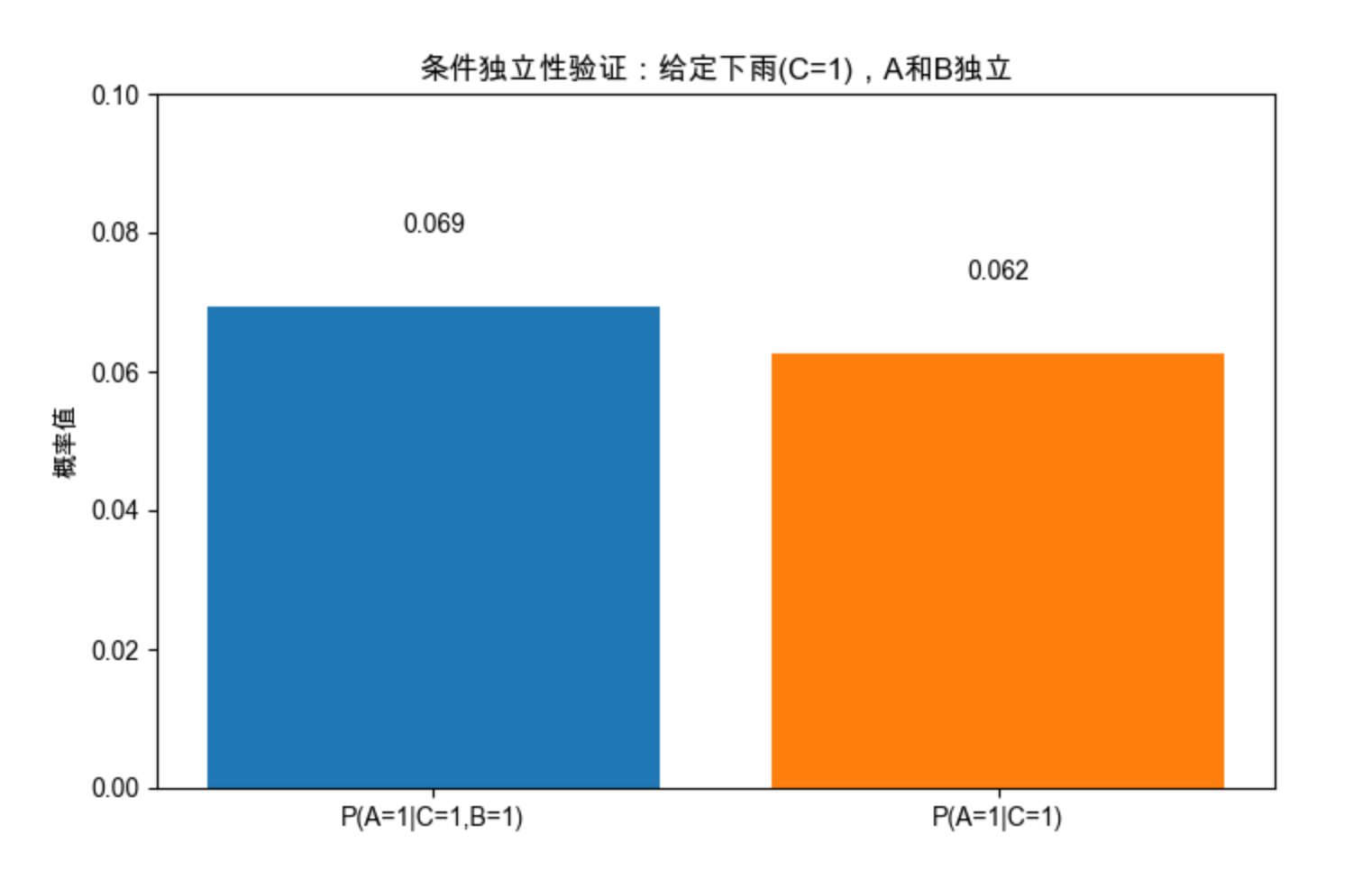
代码会生成一个柱状图,能直观看到 "给定下雨时,超市打折与否对出门概率的影响几乎为 0",完美验证条件独立性。
10.2 有向图模型
核心概念
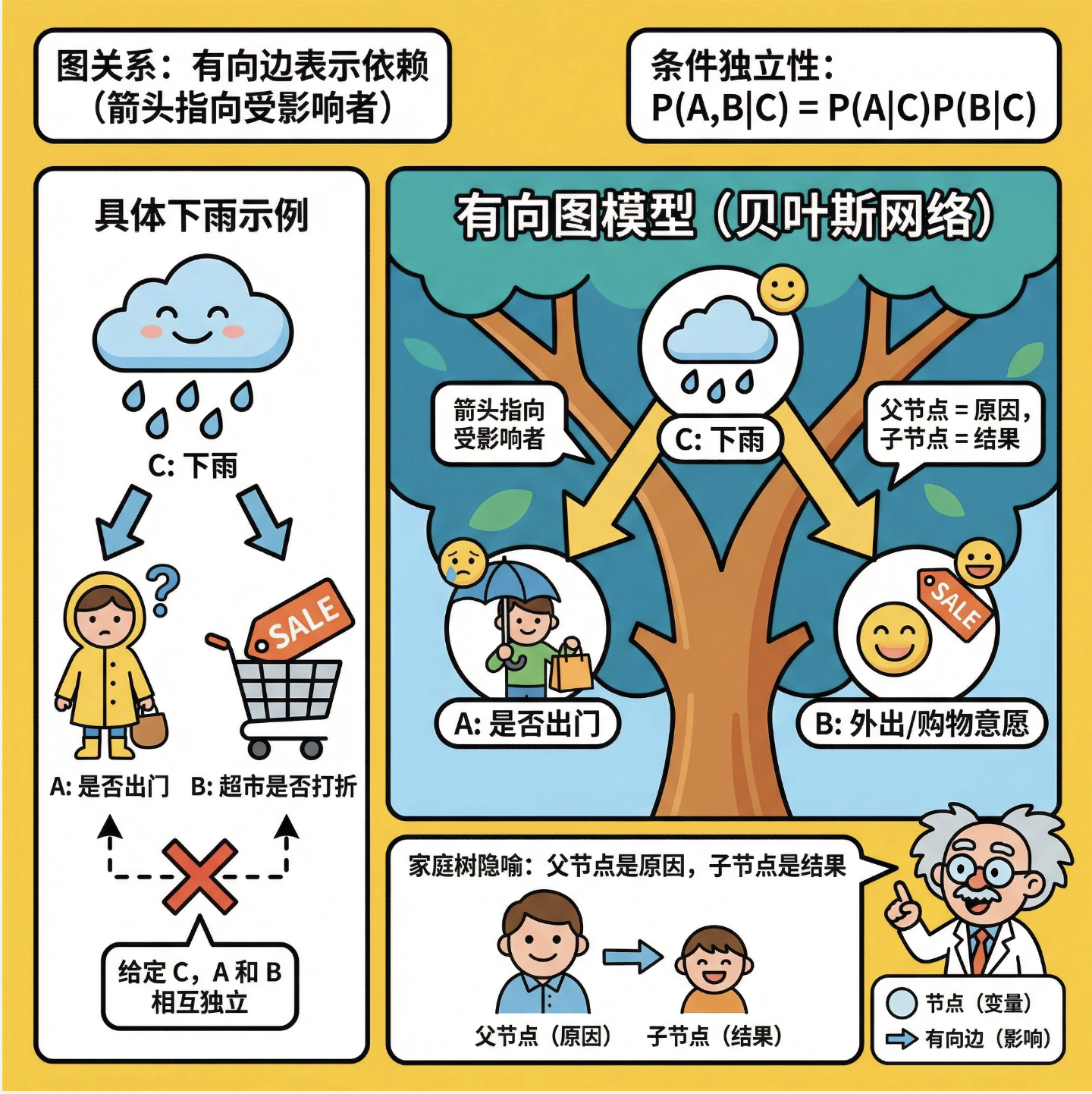
有向图模型(也叫贝叶斯网络)是用带箭头的边 表示变量之间的依赖关系,箭头指向 "被影响者"。比如 "下雨→出门",箭头从下雨指向出门,表示下雨会影响是否出门。
可以把有向图模型想象成 "家族树":父节点是 "原因",子节点是 "结果",子节点只依赖于自己的父节点。
10.2.1 示例 1:简单有向图(下雨→出门→带伞)
import networkx as nx
import matplotlib.pyplot as plt
# Mac字体配置(重复配置确保生效)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 创建有向图
G = nx.DiGraph()
# 添加节点和边
nodes = ['下雨', '出门', '带伞']
edges = [('下雨', '出门'), ('出门', '带伞'), ('下雨', '带伞')]
G.add_nodes_from(nodes)
G.add_edges_from(edges)
# 绘制有向图
fig, ax = plt.subplots(figsize=(8, 5))
pos = nx.spring_layout(G, seed=42) # 固定布局
nx.draw(G, pos, with_labels=True, ax=ax,
node_color='#1f77b4', node_size=2000,
font_size=12, font_family='Arial Unicode MS',
arrowstyle='->', arrowsize=20)
ax.set_title('有向图模型示例:下雨→出门→带伞', fontsize=14)
plt.show()
# 计算联合概率:P(下雨,出门,带伞) = P(下雨) * P(出门|下雨) * P(带伞|下雨,出门)
# 定义条件概率表
p_rain = 0.3 # P(下雨=1)
p_go_out_rain = 0.05 # P(出门=1|下雨=1)
p_go_out_no_rain = 0.8 # P(出门=1|下雨=0)
p_umbrella_rain_go = 0.95 # P(带伞=1|下雨=1,出门=1)
p_umbrella_rain_no_go = 0.1 # P(带伞=1|下雨=1,出门=0)
p_umbrella_no_rain_go = 0.1 # P(带伞=1|下雨=0,出门=1)
p_umbrella_no_rain_no_go = 0.01 # P(带伞=1|下雨=0,出门=0)
# 计算联合概率:下雨=1,出门=1,带伞=1
joint_prob = p_rain * p_go_out_rain * p_umbrella_rain_go
print(f"P(下雨=1,出门=1,带伞=1) = {joint_prob:.4f}")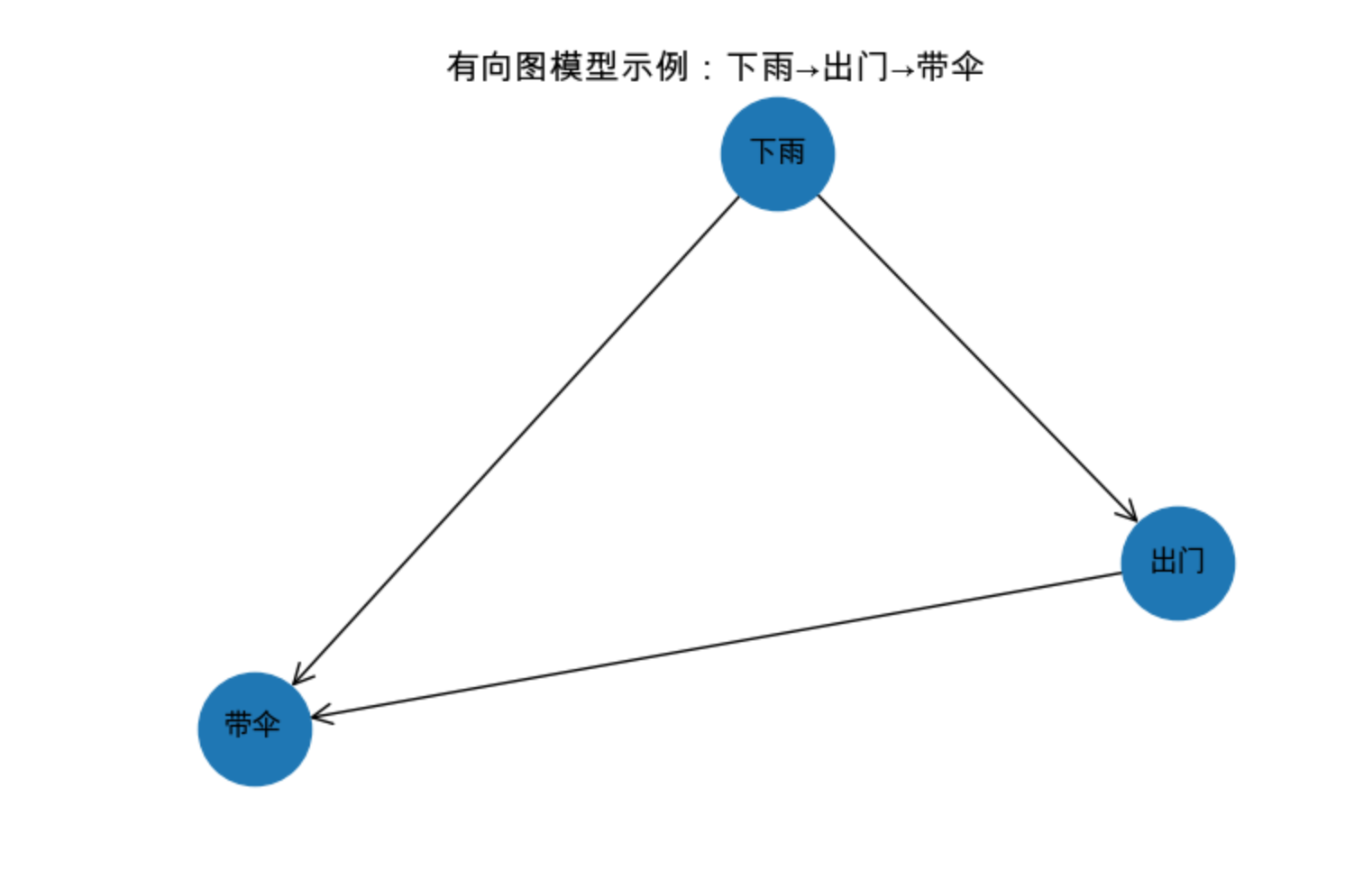
10.2.2 示例 2:计算机视觉应用 ------ 图像分类中的有向图
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 加载手写数字数据集(有向图模型的经典应用:朴素贝叶斯,假设特征条件独立)
digits = load_digits()
X, y = digits.data, digits.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 朴素贝叶斯(有向图模型的一种:类别→特征,特征之间条件独立)
gnb = GaussianNB()
gnb.fit(X_train, y_train)
y_pred = gnb.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"朴素贝叶斯(有向图模型)分类准确率:{accuracy:.4f}")
# 可视化原始图像和预测结果
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
axes = axes.flatten()
# 展示前10个测试样本的原始图像和预测结果
for i in range(10):
ax = axes[i]
ax.imshow(X_test[i].reshape(8, 8), cmap='gray')
ax.set_title(f"真实:{y_test[i]}\n预测:{y_pred[i]}")
ax.axis('off')
plt.suptitle('有向图模型(朴素贝叶斯)手写数字分类结果', fontsize=14)
plt.tight_layout()
plt.show()
10.2.3 示例 3:有向图的推理(已知结果推原因)
import numpy as np
import matplotlib.pyplot as plt
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 有向图:感冒→发烧,流感→发烧
# 定义先验概率和条件概率
p_cold = 0.2 # 感冒的先验概率
p_flu = 0.1 # 流感的先验概率
p_fever_cold = 0.9 # 感冒时发烧的概率
p_fever_flu = 0.95 # 流感时发烧的概率
p_fever_no = 0.05 # 无感冒无流感时发烧的概率
# 已知发烧(结果),推理感冒和流感的概率(原因)
# 应用贝叶斯公式:P(感冒|发烧) = P(发烧|感冒)P(感冒) / P(发烧)
# 计算P(发烧) = P(发烧|感冒)P(感冒) + P(发烧|流感)P(流感) + P(发烧|无)P(无)
p_fever = (p_fever_cold * p_cold) + (p_fever_flu * p_flu) + (p_fever_no * (1 - p_cold - p_flu))
p_cold_fever = (p_fever_cold * p_cold) / p_fever
p_flu_fever = (p_fever_flu * p_flu) / p_fever
# 可视化推理结果
fig, ax = plt.subplots(figsize=(8, 5))
categories = ['感冒', '流感']
probabilities = [p_cold_fever, p_flu_fever]
bars = ax.bar(categories, probabilities, color=['#2ca02c', '#d62728'])
# 添加数值标签
for bar, prob in zip(bars, probabilities):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{prob:.3f}', ha='center', va='bottom')
ax.set_ylabel('后验概率')
ax.set_title('已知发烧,推理感冒/流感的概率(有向图推理)')
ax.set_ylim(0, 1)
plt.show()
print(f"P(感冒|发烧) = {p_cold_fever:.3f}")
print(f"P(流感|发烧) = {p_flu_fever:.3f}")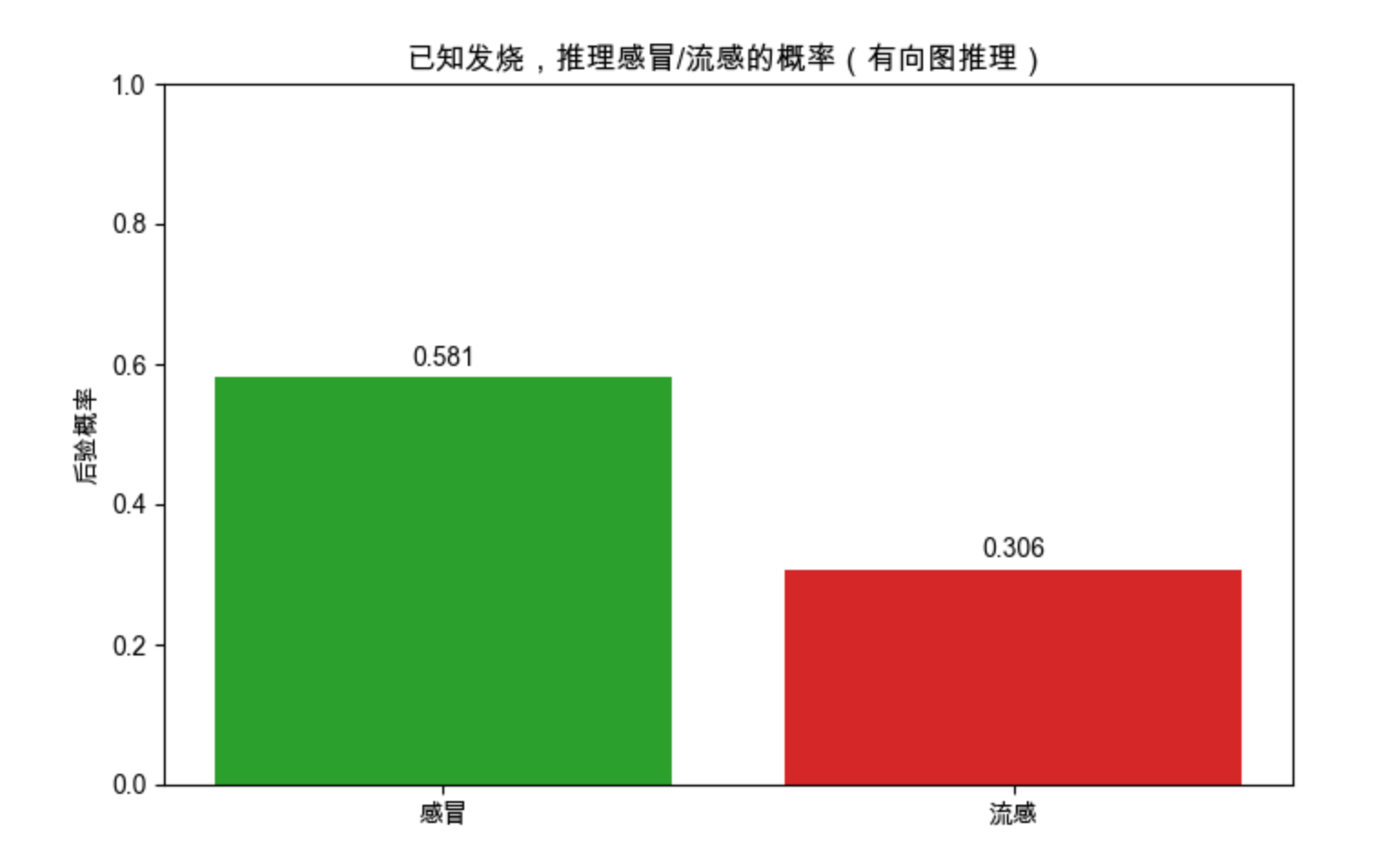
10.2.4 总结
有向图模型的核心特点:
- 边有方向,代表 "因果关系"(父→子);
- 联合概率可分解为:每个节点在其父节点条件下的概率乘积;
- 适合表示有明确因果关系的场景(如诊断、分类)。
10.3 无向图模型
核心概念
无向图模型(也叫马尔可夫随机场)是用无箭头的边 表示变量之间的 "相互影响",没有明确的因果关系,更像 "室友关系":变量之间是平等的,互相影响。
比如 "图像中的相邻像素":左边像素亮,右边像素大概率也亮,它们之间没有谁是因谁是果,只是相互依赖,这种关系用无向图表示更合适。
10.3.1 示例 1:简单无向图(图像像素依赖)
python
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
# Mac字体配置(确保中文和负号正常显示)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# ===================== 1. 绘制3x3像素无向图 =====================
G = nx.Graph()
# 添加像素节点(编号0-8,对应3x3网格)
nodes = [f'像素({i},{j})' for i in range(3) for j in range(3)]
G.add_nodes_from(nodes)
# 添加相邻边(上下左右)
edges = []
for i in range(3):
for j in range(3):
# 右边像素(同一行,列+1)
if j < 2:
edges.append((f'像素({i},{j})', f'像素({i},{j+1})'))
# 下边像素(同一列,行+1)
if i < 2:
edges.append((f'像素({i},{j})', f'像素({i+1},{j})'))
G.add_edges_from(edges)
# 绘制无向图
fig, ax = plt.subplots(figsize=(10, 8))
pos = nx.spring_layout(G, seed=42) # 固定随机种子,布局不变
nx.draw(G, pos, with_labels=True, ax=ax,
node_color='#ff7f0e', node_size=3000,
font_size=10, font_family='Arial Unicode MS',
edge_color='gray')
ax.set_title('无向图模型示例:3x3图像像素的相邻依赖', fontsize=14)
plt.show()
# ===================== 2. 验证像素依赖(改用相似度计算) =====================
np.random.seed(42)
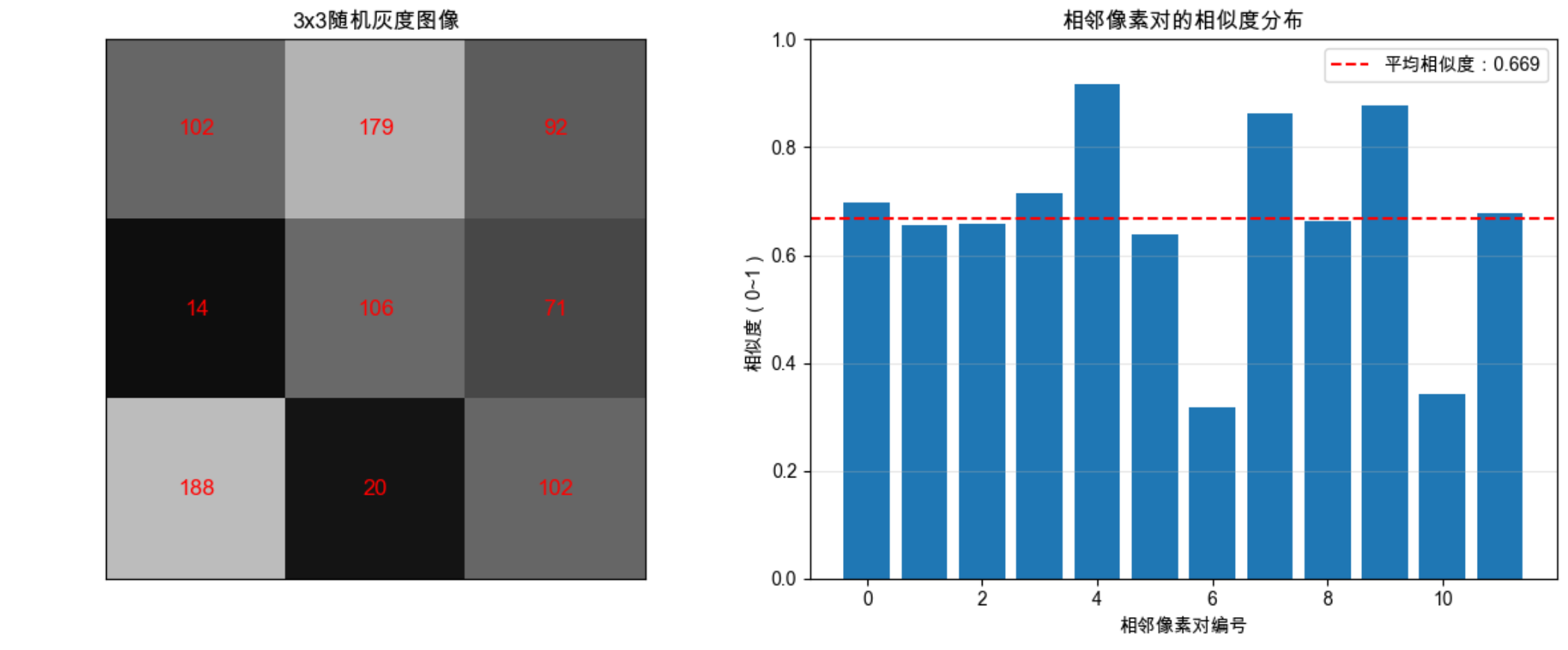
img = np.random.randint(0, 255, (3, 3)) # 3x3随机灰度图像
print(f"3x3图像像素值:\n{img}")
# 计算相邻像素的相似度(替代相关系数,更适合单样本像素对)
# 相似度公式:1 - |像素1 - 像素2| / 255 (值越接近1,像素越相似,依赖度越高)
similarity = []
similarity_details = [] # 存储详细信息用于打印
for i in range(3):
for j in range(3):
# 计算与右侧像素的相似度
if j < 2:
pix1 = img[i, j]
pix2 = img[i, j+1]
sim = 1 - abs(pix1 - pix2) / 255.0
similarity.append(sim)
similarity_details.append((f'({i},{j})-({i},{j+1})', pix1, pix2, sim))
# 计算与下侧像素的相似度
if i < 2:
pix1 = img[i, j]
pix2 = img[i+1, j]
sim = 1 - abs(pix1 - pix2) / 255.0
similarity.append(sim)
similarity_details.append((f'({i},{j})-({i+1},{j})', pix1, pix2, sim))
# 打印每个像素对的相似度
print("\n相邻像素对的相似度(越接近1,依赖度越高):")
for pair, p1, p2, sim in similarity_details:
print(f"像素{pair}:{p1} vs {p2} → 相似度 = {sim:.3f}")
# 计算平均相似度
mean_sim = np.mean(similarity)
print(f"\n所有相邻像素的平均相似度:{mean_sim:.3f}")
# ===================== 3. 可视化:图像+相似度分布 =====================
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 显示3x3模拟图像(标注像素值)
ax1.imshow(img, cmap='gray', vmin=0, vmax=255)
ax1.set_title('3x3随机灰度图像', fontsize=12)
for i in range(3):
for j in range(3):
ax1.text(j, i, str(img[i,j]), ha='center', va='center', color='red', fontsize=12)
ax1.set_xticks([])
ax1.set_yticks([])
# 显示相邻像素相似度分布
ax2.bar(range(len(similarity)), similarity, color='#1f77b4')
ax2.axhline(y=mean_sim, color='red', linestyle='--', label=f'平均相似度:{mean_sim:.3f}')
ax2.set_xlabel('相邻像素对编号')
ax2.set_ylabel('相似度(0~1)')
ax2.set_title('相邻像素对的相似度分布', fontsize=12)
ax2.legend()
ax2.grid(axis='y', alpha=0.3)
ax2.set_ylim(0, 1) # 限定y轴范围,更直观
plt.tight_layout()
plt.show()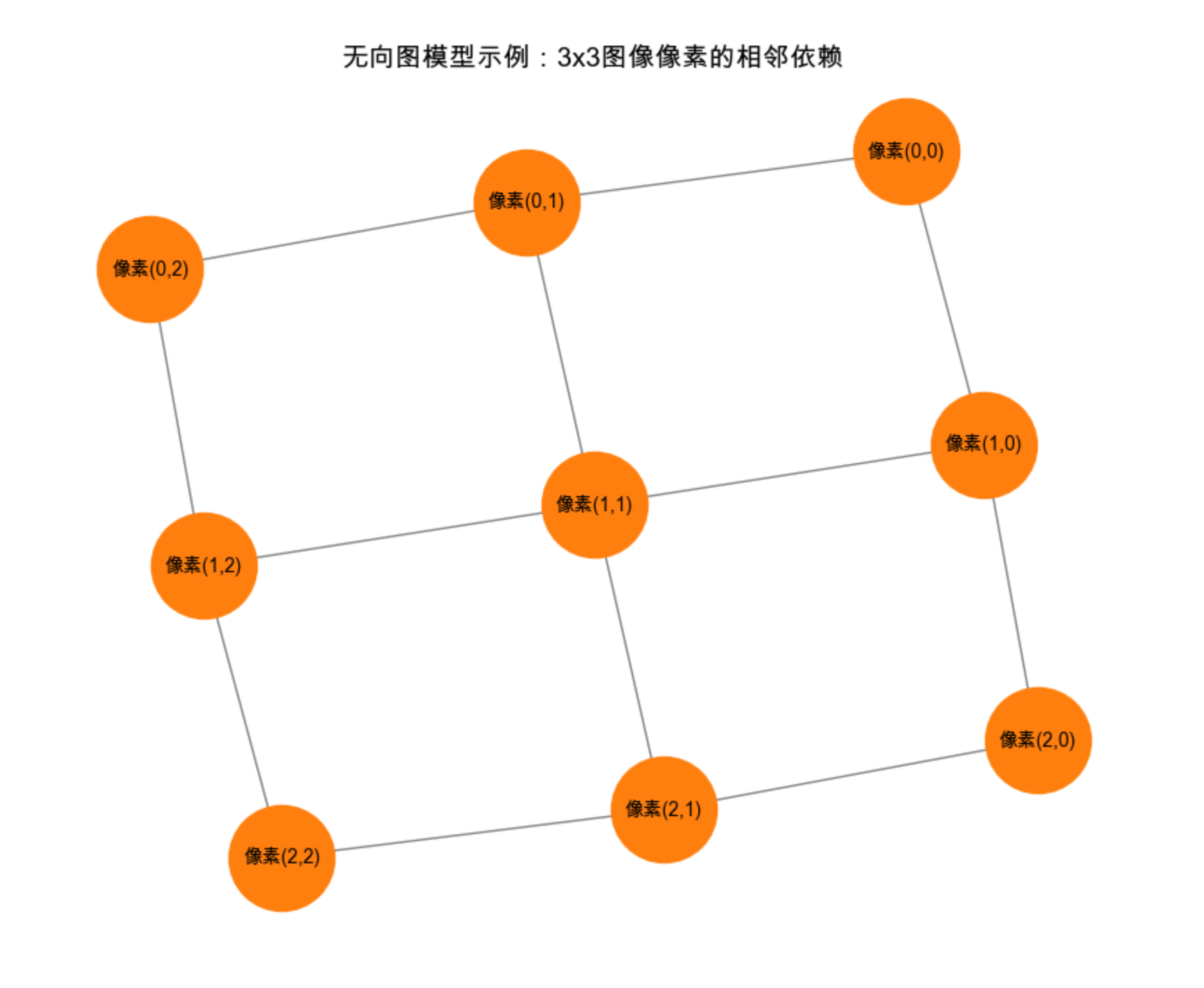
10.3.2 示例 2:计算机视觉应用 ------ 图像去噪(无向图)
python
import numpy as np
import matplotlib.pyplot as plt
from skimage import data, util, img_as_float
from skimage.restoration import denoise_bilateral
from skimage.metrics import peak_signal_noise_ratio
# Mac字体配置(确保中文和负号正常显示)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 1. 加载并预处理图像
img = img_as_float(data.camera()) # 标准化到0~1的浮点型
# 关键修复:用整数种子替代RandomState对象(适配新版本rng参数要求)
seed = 42
noisy_img = util.random_noise(img, mode='gaussian', var=0.01, rng=seed)
# 2. 基于MRF(无向图)的双边滤波去噪
# sigma_color=0.1:颜色相似度权重(越小去噪越彻底)
# sigma_spatial=15:空间邻域范围(越大考虑的相邻像素越多)
denoised_img = denoise_bilateral(noisy_img, sigma_color=0.1, sigma_spatial=15)
# 3. 可视化对比
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
axes[0].imshow(img, cmap='gray')
axes[0].set_title('原始图像', fontsize=14)
axes[0].axis('off')
axes[1].imshow(noisy_img, cmap='gray')
axes[1].set_title('添加高斯噪声后的图像', fontsize=14)
axes[1].axis('off')
axes[2].imshow(denoised_img, cmap='gray')
axes[2].set_title('MRF(双边滤波)去噪后的图像', fontsize=14)
axes[2].axis('off')
plt.suptitle('无向图模型(马尔可夫随机场)图像去噪效果对比', fontsize=16)
plt.tight_layout()
plt.show()
# 4. 计算并输出PSNR
psnr_noisy = peak_signal_noise_ratio(img, noisy_img, data_range=1.0)
psnr_denoised = peak_signal_noise_ratio(img, denoised_img, data_range=1.0)
print(f"噪声图像PSNR:{psnr_noisy:.2f} dB")
print(f"去噪图像PSNR:{psnr_denoised:.2f} dB")
print(f"去噪后PSNR提升:{psnr_denoised - psnr_noisy:.2f} dB")
10.4 有向图模型与无向图模型的对比
核心对比
可视化对比代码
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 创建对比图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 绘制有向图
G_dir = nx.DiGraph()
G_dir.add_edges_from([('原因', '结果'), ('原因', '中间变量'), ('中间变量', '结果')])
pos_dir = nx.spring_layout(G_dir, seed=42)
nx.draw(G_dir, pos_dir, with_labels=True, ax=ax1,
node_color='#1f77b4', node_size=2000,
font_size=12, font_family='Arial Unicode MS',
arrowstyle='->', arrowsize=20)
ax1.set_title('有向图模型(因果关系)', fontsize=12)
# 绘制无向图
G_undir = nx.Graph()
G_undir.add_edges_from([('像素A', '像素B'), ('像素B', '像素C'), ('像素A', '像素C')])
pos_undir = nx.spring_layout(G_undir, seed=42)
nx.draw(G_undir, pos_undir, with_labels=True, ax=ax2,
node_color='#ff7f0e', node_size=2000,
font_size=12, font_family='Arial Unicode MS',
edge_color='gray')
ax2.set_title('无向图模型(相互依赖)', fontsize=12)
plt.suptitle('有向图 vs 无向图 可视化对比', fontsize=14)
plt.tight_layout()
plt.show()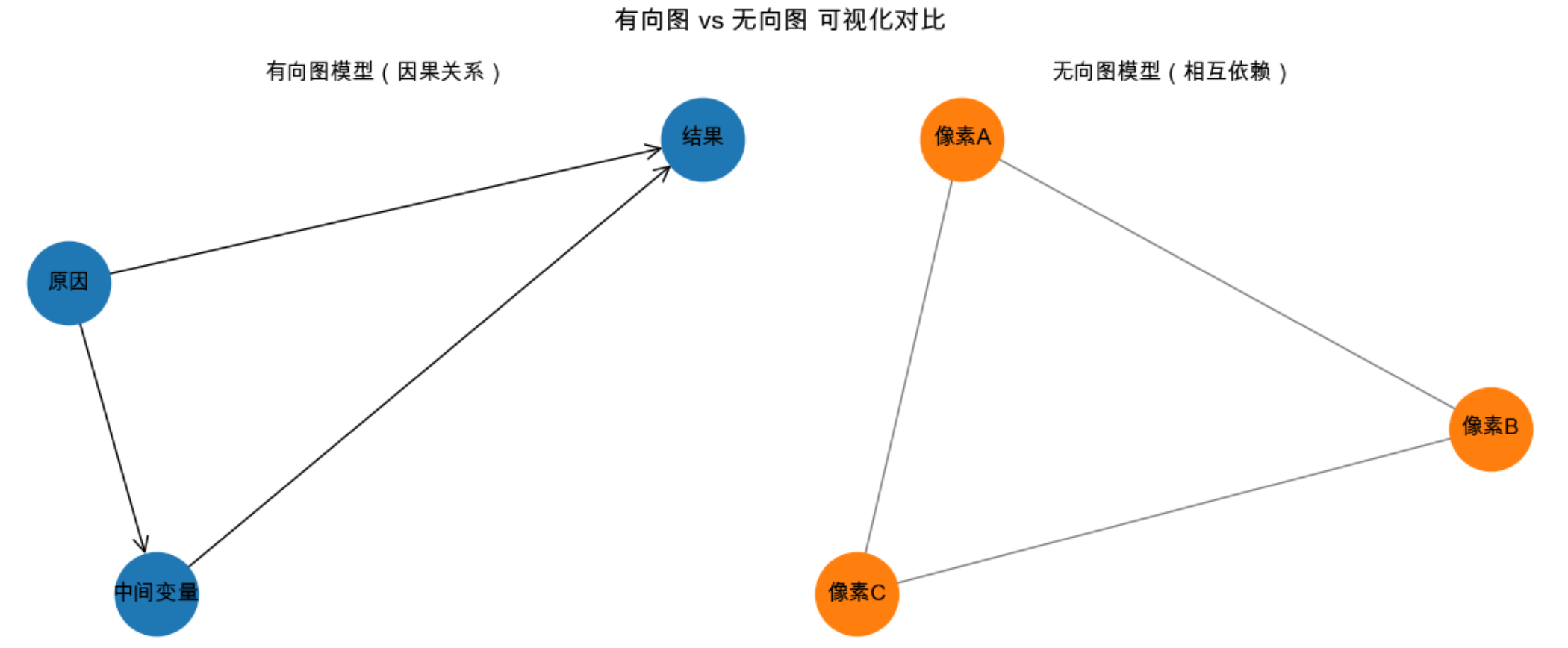
10.5 计算机视觉中的图模型
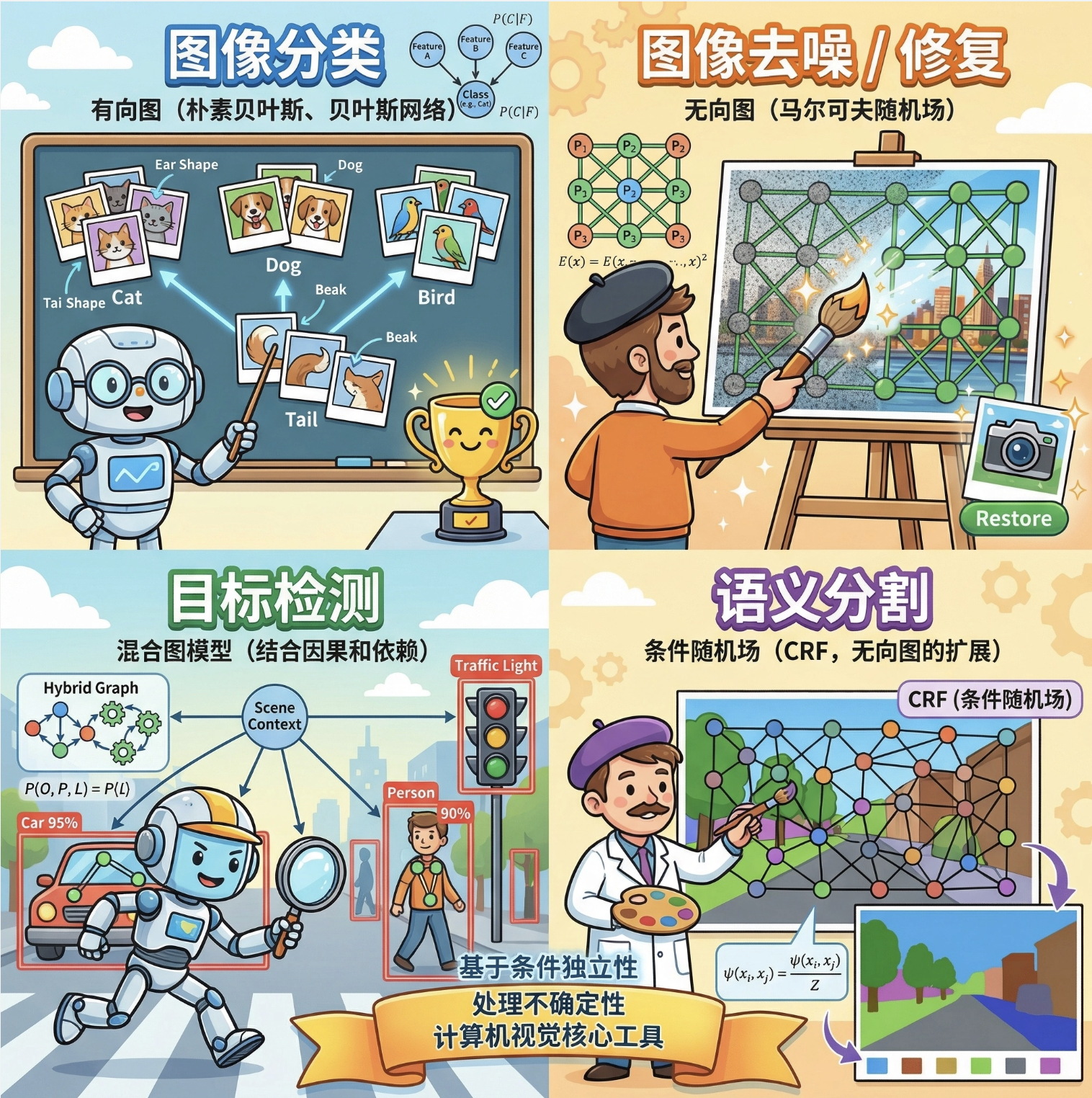
核心应用场景
- 图像分类:有向图(朴素贝叶斯、贝叶斯网络);
- 图像去噪 / 修复:无向图(马尔可夫随机场);
- 目标检测:混合图模型(结合因果和依赖);
- 语义分割:条件随机场(CRF,无向图的扩展)。
实战代码:CRF 图像语义分割(无向图扩展)
import numpy as np
import matplotlib.pyplot as plt
from skimage import data, segmentation, color
from skimage.filters import gaussian
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 加载示例图像
img = data.astronaut()
# 转为Lab颜色空间(更适合CRF)
img_lab = color.rgb2lab(img)
# 初始分割(超像素)
segments = segmentation.slic(img, n_segments=100, compactness=10, sigma=1)
# 构建CRF(无向图模型):基于超像素的相邻依赖
# 简化版CRF实现(核心是相邻超像素的颜色相似度)
def crf_simple(img_lab, segments, iterations=5):
n_segments = np.max(segments) + 1
# 计算每个超像素的平均颜色
mean_colors = np.zeros((n_segments, 3))
for i in range(n_segments):
mean_colors[i] = np.mean(img_lab[segments == i], axis=0)
# CRF迭代优化
for _ in range(iterations):
new_segments = segments.copy()
for i in range(img_lab.shape[0]):
for j in range(img_lab.shape[1]):
# 查看相邻像素的超像素
neighbors = []
if i > 0:
neighbors.append(segments[i-1, j])
if i < img_lab.shape[0]-1:
neighbors.append(segments[i+1, j])
if j > 0:
neighbors.append(segments[i, j-1])
if j < img_lab.shape[1]-1:
neighbors.append(segments[i, j+1])
# 选择颜色最接近的超像素
if neighbors:
current_color = img_lab[i, j]
distances = [np.linalg.norm(current_color - mean_colors[n]) for n in neighbors]
best_neighbor = neighbors[np.argmin(distances)]
new_segments[i, j] = best_neighbor
segments = new_segments
# 更新平均颜色
for i in range(n_segments):
mean_colors[i] = np.mean(img_lab[segments == i], axis=0)
return segments
# 运行CRF分割
crf_segments = crf_simple(img_lab, segments)
# 可视化对比
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(18, 6))
ax1.imshow(img)
ax1.set_title('原始图像', fontsize=12)
ax1.axis('off')
ax2.imshow(segmentation.mark_boundaries(img, segments))
ax2.set_title('初始超像素分割', fontsize=12)
ax2.axis('off')
ax3.imshow(segmentation.mark_boundaries(img, crf_segments))
ax3.set_title('CRF(无向图)优化后分割', fontsize=12)
ax3.axis('off')
plt.suptitle('CRF(无向图模型)图像语义分割效果', fontsize=14)
plt.tight_layout()
plt.show()
10.6 含有多个未知量的模型推理
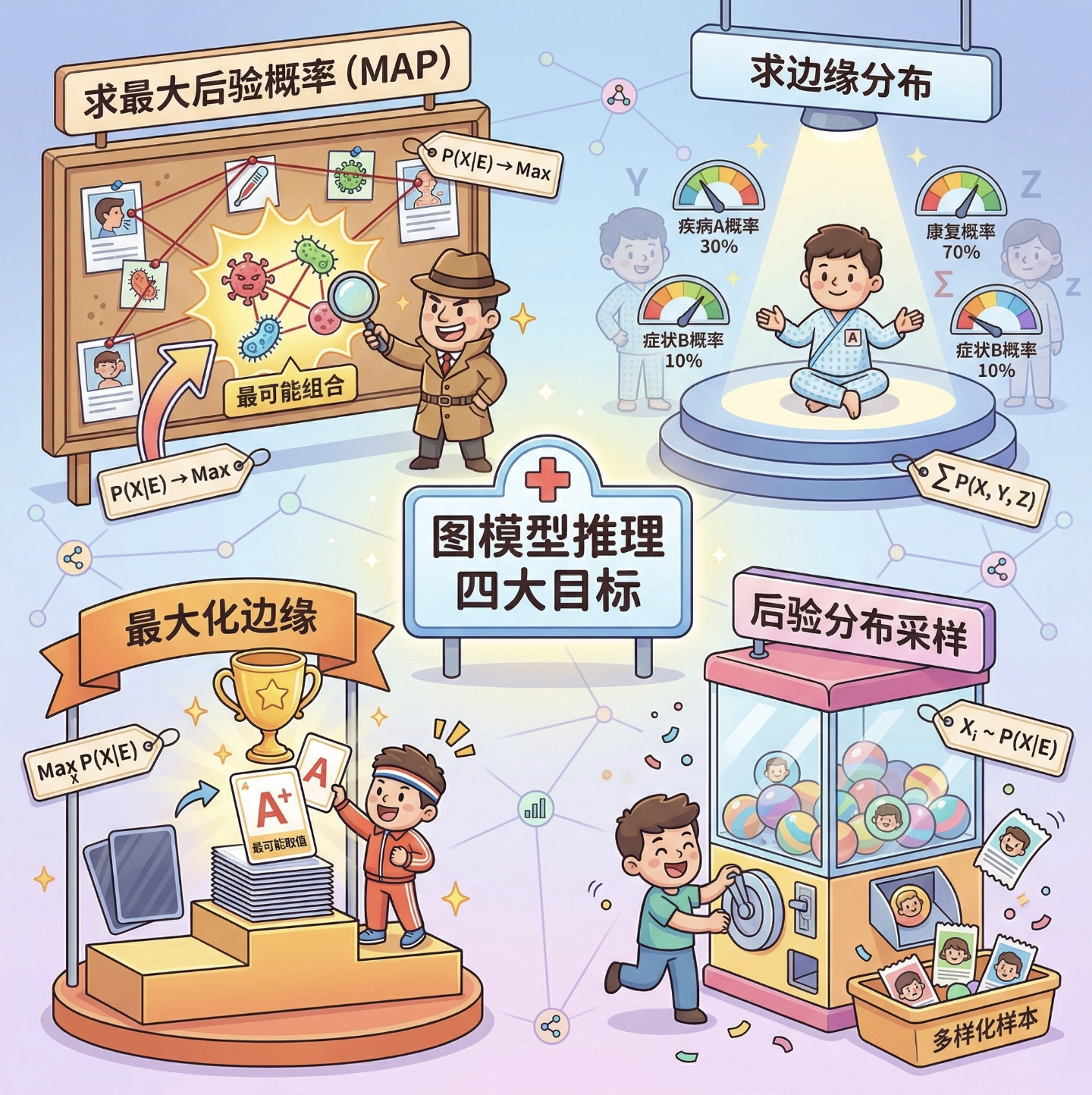
核心概念
当图模型中有多个未知变量时,推理的目标主要有 4 类:
- 求最大后验概率(MAP) :找最可能的变量组合(比如 "最可能的疾病组合");
- 求边缘分布:求单个变量的概率(不管其他变量);
- 最大化边缘:找单个变量的最可能值;
- 后验分布采样:生成符合后验分布的样本。
10.6.1 求最大后验概率的解
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 定义后验概率函数:P(x1,x2) = -((x1-2)^2 + (x2-3)^2 + 0.5*x1*x2)
# (负号因为minimize求最小值,对应求概率最大值)
def posterior_neg(params):
x1, x2 = params
return (x1-2)**2 + (x2-3)**2 + 0.5*x1*x2
# 求MAP(最大后验概率)
initial_guess = [0, 0]
result = minimize(posterior_neg, initial_guess, method='L-BFGS-B')
map_x1, map_x2 = result.x
# 可视化后验分布和MAP点
x1 = np.linspace(-2, 6, 100)
x2 = np.linspace(-1, 7, 100)
X1, X2 = np.meshgrid(x1, x2)
Z = -((X1-2)**2 + (X2-3)**2 + 0.5*X1*X2) # 后验概率
fig, ax = plt.subplots(figsize=(8, 6))
contour = ax.contourf(X1, X2, Z, levels=20, cmap='viridis')
plt.colorbar(contour, ax=ax, label='后验概率')
ax.scatter(map_x1, map_x2, color='red', s=100, label=f'MAP点: ({map_x1:.2f}, {map_x2:.2f})')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('最大后验概率(MAP)求解示例', fontsize=12)
ax.legend()
plt.show()
print(f"MAP解:x1={map_x1:.2f}, x2={map_x2:.2f}")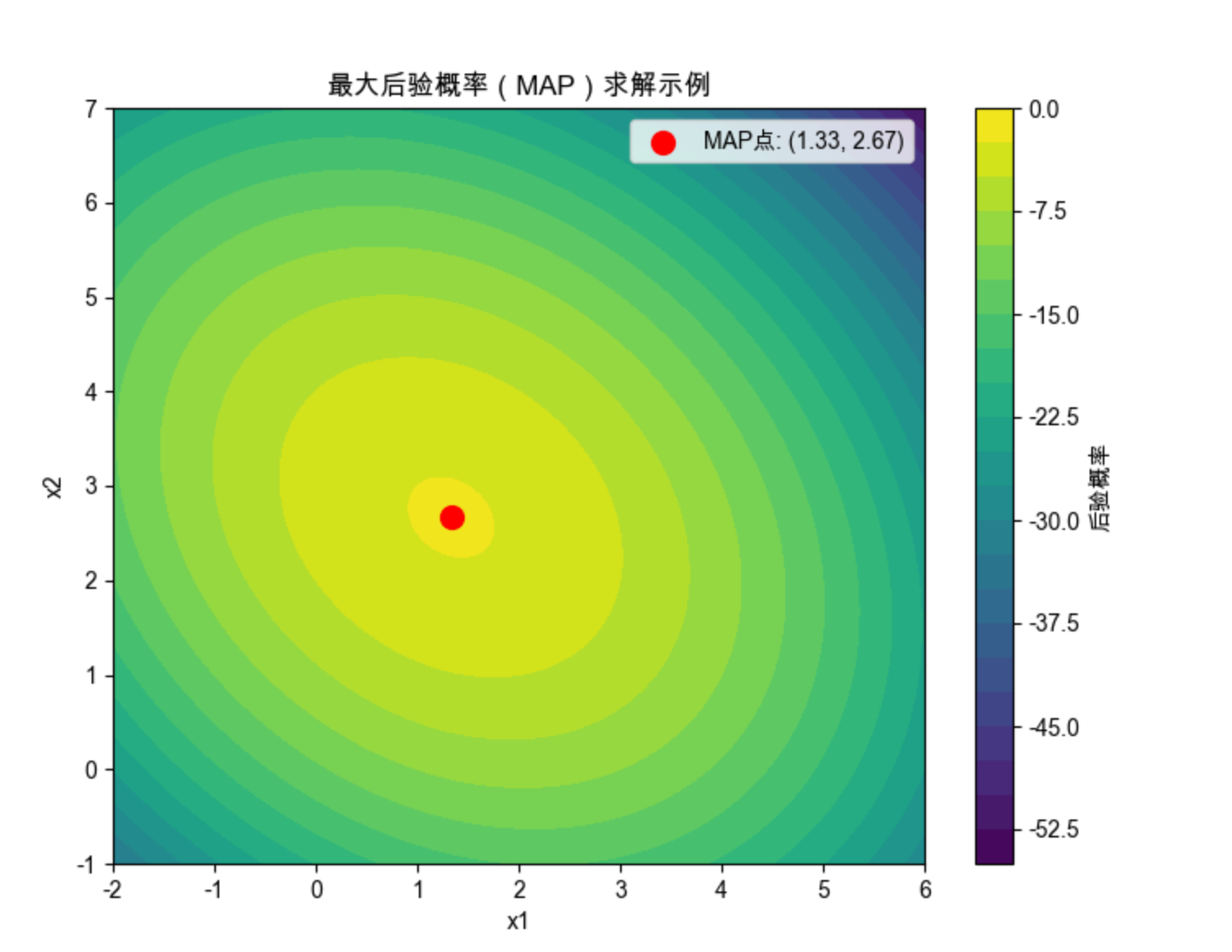
10.6.2 求后验概率分布的边缘分布
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import quad
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 定义联合后验概率 P(x1,x2)
def joint_posterior(x1, x2):
return np.exp(-((x1-2)**2 + (x2-3)**2 + 0.5*x1*x2))
# 求x1的边缘分布 P(x1) = ∫P(x1,x2)dx2
def marginal_x1(x1):
# 积分范围:x2从-∞到+∞(近似-10到10)
return quad(lambda x2: joint_posterior(x1, x2), -10, 10)[0]
# 计算x1的边缘分布
x1_vals = np.linspace(-2, 6, 100)
marginal_vals = [marginal_x1(x1) for x1 in x1_vals]
# 可视化边缘分布
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(x1_vals, marginal_vals, color='#2ca02c', linewidth=2)
ax.fill_between(x1_vals, marginal_vals, alpha=0.3, color='#2ca02c')
ax.set_xlabel('x1')
ax.set_ylabel('边缘概率 P(x1)')
ax.set_title('后验概率的边缘分布(x1)', fontsize=12)
plt.show()
# 找边缘分布的峰值
max_idx = np.argmax(marginal_vals)
max_x1 = x1_vals[max_idx]
print(f"x1边缘分布的峰值:{max_x1:.2f}")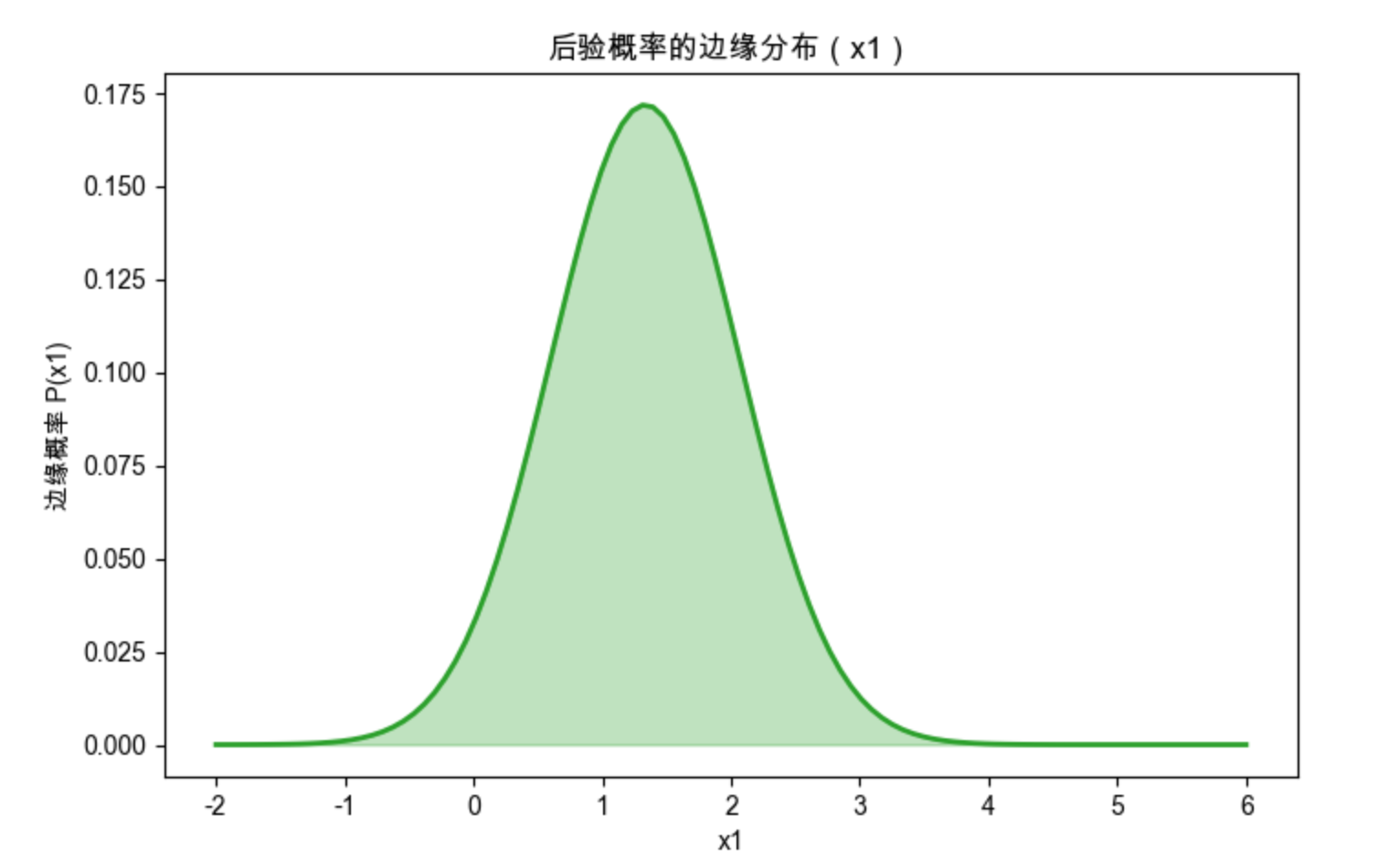
10.6.3 最大化边缘
python
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from scipy.integrate import quad # 关键:补全quad积分函数的导入
# Mac字体配置(确保中文和负号正常显示)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 定义联合后验概率函数 P(x1,x2)
def joint_posterior(x1, x2):
"""定义二维联合后验概率分布"""
return np.exp(-((x1-2)**2 + (x2-3)**2 + 0.5*x1*x2))
# 定义边缘分布的负函数(用于最小化,等价于最大化边缘分布)
def marginal_neg(x1):
"""
计算x1边缘分布的负值
参数x1:scalar(优化器传入的是数组,需取第一个元素)
返回:边缘分布的负值(用于minimize求最小值)
"""
# 修复:优化器传入的x1是数组(如[0]),需转为标量
x1_scalar = x1[0] if isinstance(x1, (np.ndarray, list)) else x1
# 对x2积分,计算x1的边缘分布
marginal = quad(lambda x2: joint_posterior(x1_scalar, x2), -10, 10)[0]
return -marginal # 负号:minimize求最小值等价于求边缘分布最大值
# 最大化边缘(即最小化负边缘分布)
initial_guess = [0] # 初始猜测值
result = minimize(marginal_neg, initial_guess, method='L-BFGS-B')
max_marginal_x1 = result.x[0]
# 计算x1取值范围内的边缘分布值(用于可视化)
x1_vals = np.linspace(-2, 6, 100)
marginal_vals = []
for x1 in x1_vals:
# 对每个x1,积分计算边缘分布P(x1)
marg = quad(lambda x2: joint_posterior(x1, x2), -10, 10)[0]
marginal_vals.append(marg)
marginal_vals = np.array(marginal_vals)
# 可视化结果
fig, ax = plt.subplots(figsize=(8, 5))
# 绘制边缘分布曲线
ax.plot(x1_vals, marginal_vals, color='#d62728', linewidth=2, label='边缘分布 P(x1)')
# 标记最大化边缘的点
max_marginal_val = -marginal_neg([max_marginal_x1]) # 计算该点的边缘分布值
ax.scatter(max_marginal_x1, max_marginal_val, color='red', s=100,
label=f'最大化边缘点: x1={max_marginal_x1:.2f}')
# 图表美化
ax.set_xlabel('x1', fontsize=11)
ax.set_ylabel('边缘概率 P(x1)', fontsize=11)
ax.set_title('最大化边缘示例', fontsize=12)
ax.legend(fontsize=10)
ax.grid(axis='y', alpha=0.3)
plt.show()
# 输出结果
print(f"最大化边缘的x1值:{max_marginal_x1:.2f}")
print(f"该点的边缘概率值:{max_marginal_val:.4f}")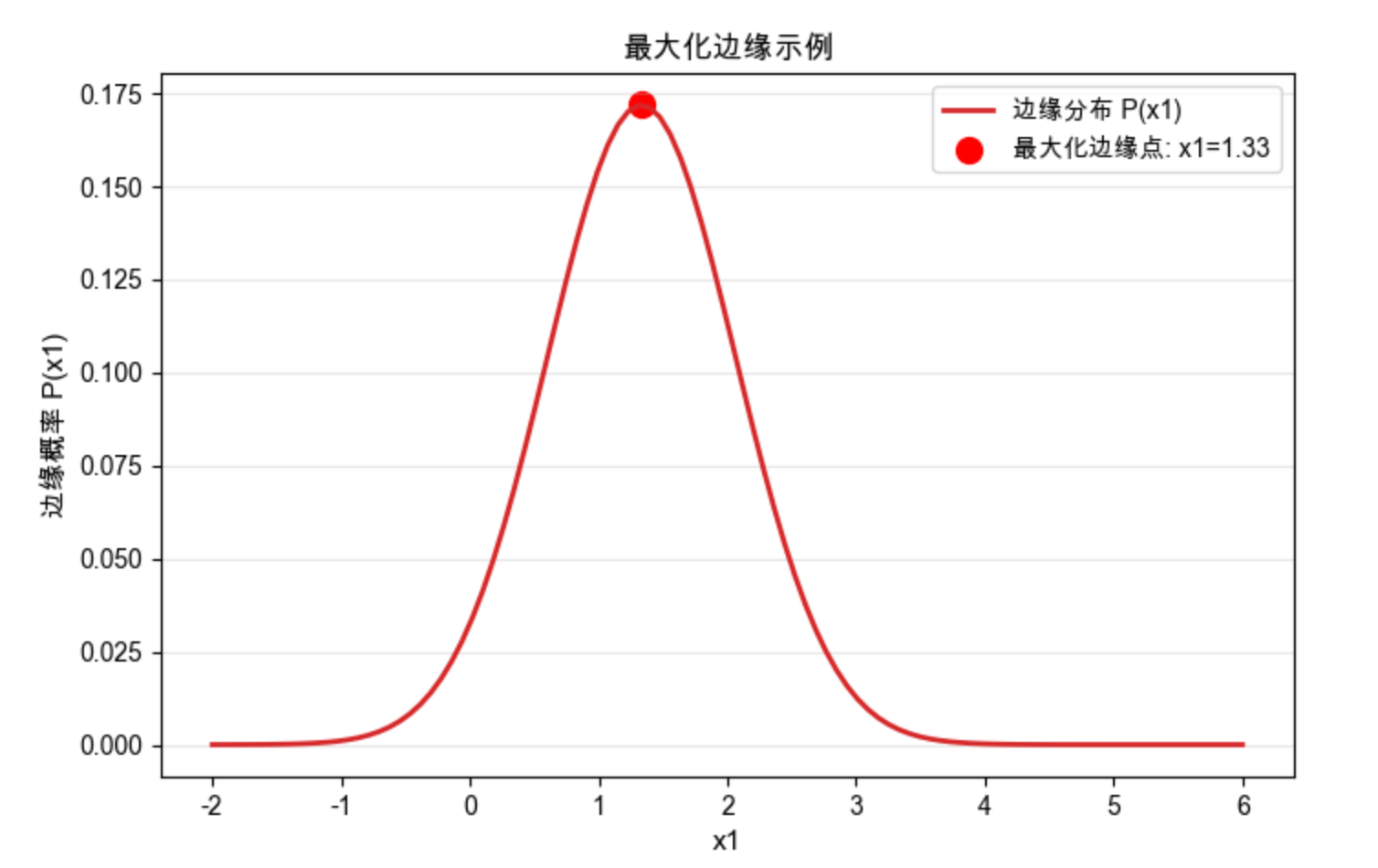
10.6.4 后验分布的采样
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 定义后验分布(多元高斯)
mean = [2, 3]
cov = [[1, -0.25], [-0.25, 1]] # 协方差矩阵
rv = multivariate_normal(mean, cov)
# 采样
np.random.seed(42)
samples = rv.rvs(size=1000)
# 可视化采样结果
fig, ax = plt.subplots(figsize=(8, 6))
# 绘制分布轮廓
x1 = np.linspace(-1, 5, 100)
x2 = np.linspace(0, 6, 100)
X1, X2 = np.meshgrid(x1, x2)
Z = rv.pdf(np.dstack((X1, X2)))
ax.contour(X1, X2, Z, levels=10, colors='gray', alpha=0.5)
# 绘制采样点
ax.scatter(samples[:,0], samples[:,1], alpha=0.6, s=20, color='#1f77b4', label='采样点')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('后验分布采样示例(多元高斯)', fontsize=12)
ax.legend()
plt.show()
# 验证采样的均值和协方差
print(f"采样均值:{np.mean(samples, axis=0)}")
print(f"采样协方差:\n{np.cov(samples.T)}")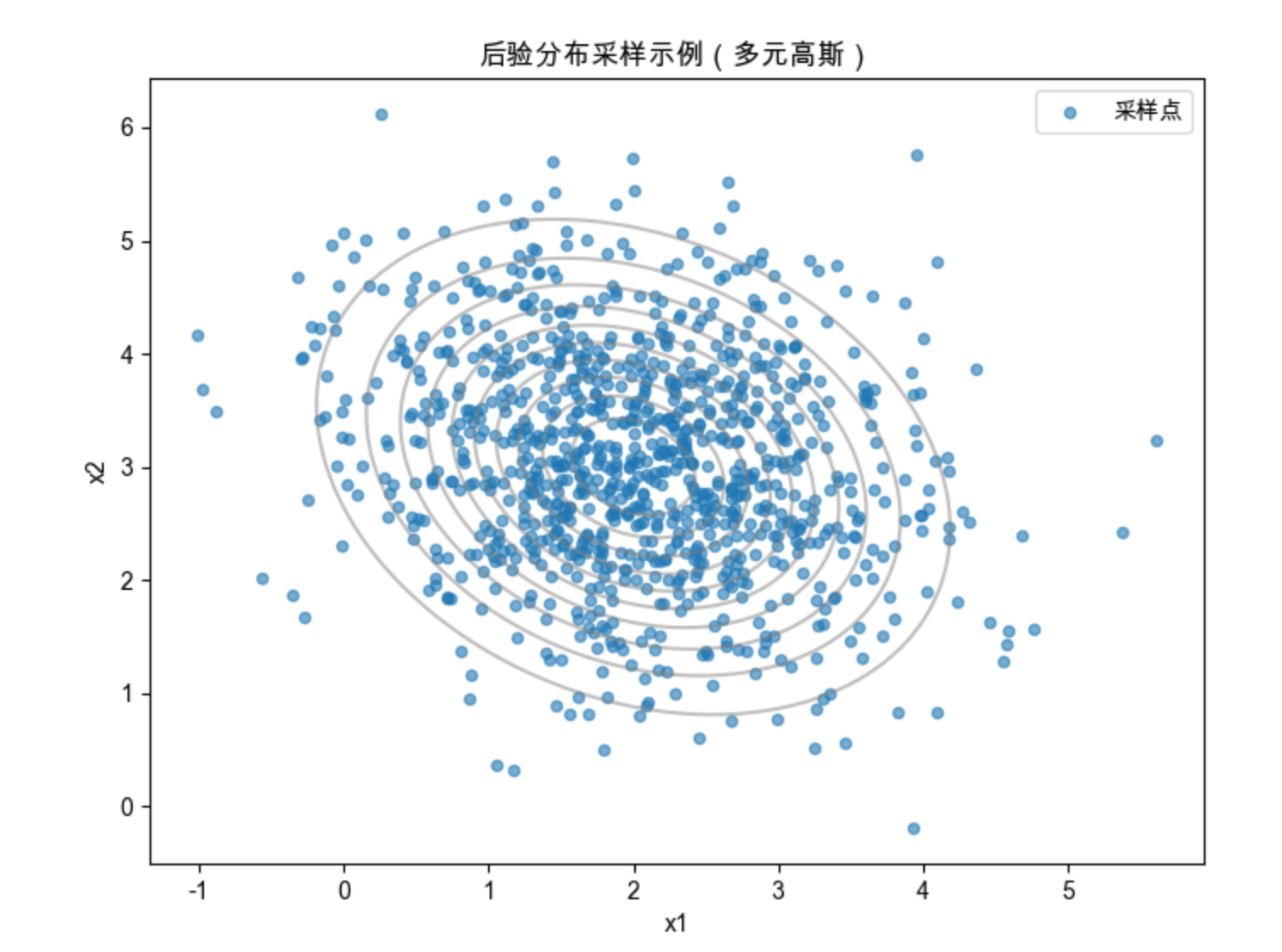
10.7 样本采样
10.7.1 有向图模型的采样
import numpy as np
import matplotlib.pyplot as plt
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 有向图:天气→活动→心情
# 定义条件概率表
# P(天气):晴=0.6,阴=0.3,雨=0.1
weather_probs = [0.6, 0.3, 0.1]
weather_labels = ['晴', '阴', '雨']
# P(活动|天气):晴→散步(0.7)/看书(0.3);阴→散步(0.2)/看书(0.8);雨→散步(0.0)/看书(1.0)
activity_probs = [[0.7, 0.3], [0.2, 0.8], [0.0, 1.0]]
activity_labels = ['散步', '看书']
# P(心情|活动):散步→开心(0.9)/不开心(0.1);看书→开心(0.6)/不开心(0.4)
mood_probs = [[0.9, 0.1], [0.6, 0.4]]
mood_labels = ['开心', '不开心']
# 采样函数
def sample_directed_graph(n_samples=1000):
samples = []
for _ in range(n_samples):
# 1. 采样天气
weather = np.random.choice(3, p=weather_probs)
# 2. 采样活动(依赖天气)
activity = np.random.choice(2, p=activity_probs[weather])
# 3. 采样心情(依赖活动)
mood = np.random.choice(2, p=mood_probs[activity])
samples.append([weather_labels[weather], activity_labels[activity], mood_labels[mood]])
return np.array(samples)
# 执行采样
samples = sample_directed_graph(1000)
# 可视化采样结果
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 天气分布
weather_counts = np.unique(samples[:,0], return_counts=True)
axes[0].bar(weather_counts[0], weather_counts[1], color='#1f77b4')
axes[0].set_title('天气采样分布', fontsize=12)
axes[0].set_ylabel('样本数')
# 活动分布
activity_counts = np.unique(samples[:,1], return_counts=True)
axes[1].bar(activity_counts[0], activity_counts[1], color='#ff7f0e')
axes[1].set_title('活动采样分布', fontsize=12)
# 心情分布
mood_counts = np.unique(samples[:,2], return_counts=True)
axes[2].bar(mood_counts[0], mood_counts[1], color='#2ca02c')
axes[2].set_title('心情采样分布', fontsize=12)
plt.suptitle('有向图模型采样结果', fontsize=14)
plt.tight_layout()
plt.show()
# 输出条件概率验证
happy_walk = np.sum((samples[:,1]=='散步') & (samples[:,2]=='开心')) / np.sum(samples[:,1]=='散步')
print(f"采样得到P(开心|散步) = {happy_walk:.2f}(理论值0.9)")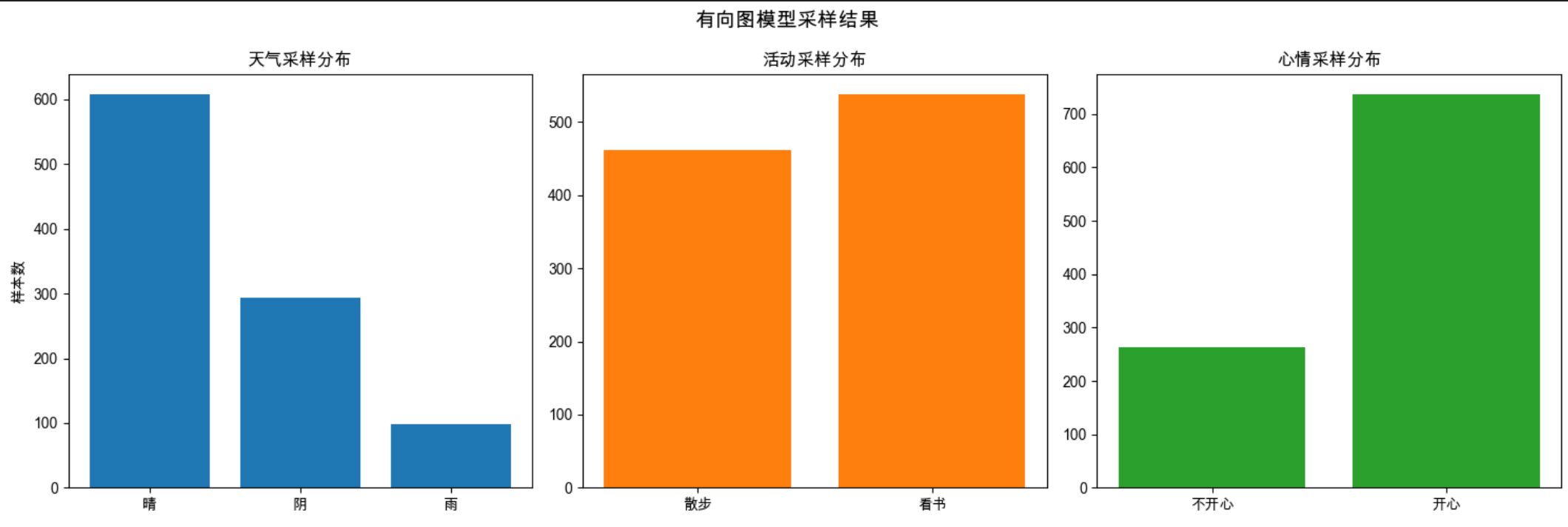
10.7.2 无向图模型的采样
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 无向图采样:MCMC(马尔可夫链蒙特卡洛)
def mcmc_sample_undirected(n_samples=10000, burn_in=1000):
# 定义无向图的势能函数(多元高斯)
mean = [0, 0]
cov = [[1, 0.8], [0.8, 1]]
rv = multivariate_normal(mean, cov)
# 初始化采样点
current = np.array([0.0, 0.0])
samples = []
for i in range(n_samples + burn_in):
# 提议分布:高斯随机游走
proposal = current + np.random.normal(0, 0.5, 2)
# 计算接受概率
p_current = rv.pdf(current)
p_proposal = rv.pdf(proposal)
accept_prob = min(1, p_proposal / p_current)
# 接受或拒绝
if np.random.uniform() < accept_prob:
current = proposal
# 跳过燃烧期
if i >= burn_in:
samples.append(current.copy())
return np.array(samples)
# 执行采样
samples = mcmc_sample_undirected()
# 可视化采样结果
fig, ax = plt.subplots(figsize=(8, 6))
# 绘制真实分布
x = np.linspace(-3, 3, 100)
y = np.linspace(-3, 3, 100)
X, Y = np.meshgrid(x, y)
Z = multivariate_normal.pdf(np.dstack((X, Y)), mean=[0,0], cov=[[1,0.8],[0.8,1]])
ax.contour(X, Y, Z, levels=10, colors='gray', alpha=0.5)
# 绘制采样点
ax.scatter(samples[:,0], samples[:,1], alpha=0.1, s=5, color='#d62728')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('无向图模型MCMC采样结果', fontsize=12)
plt.show()
# 验证采样的协方差
print(f"采样协方差:\n{np.cov(samples.T)}")
print(f"理论协方差:\n[[1, 0.8], [0.8, 1]]")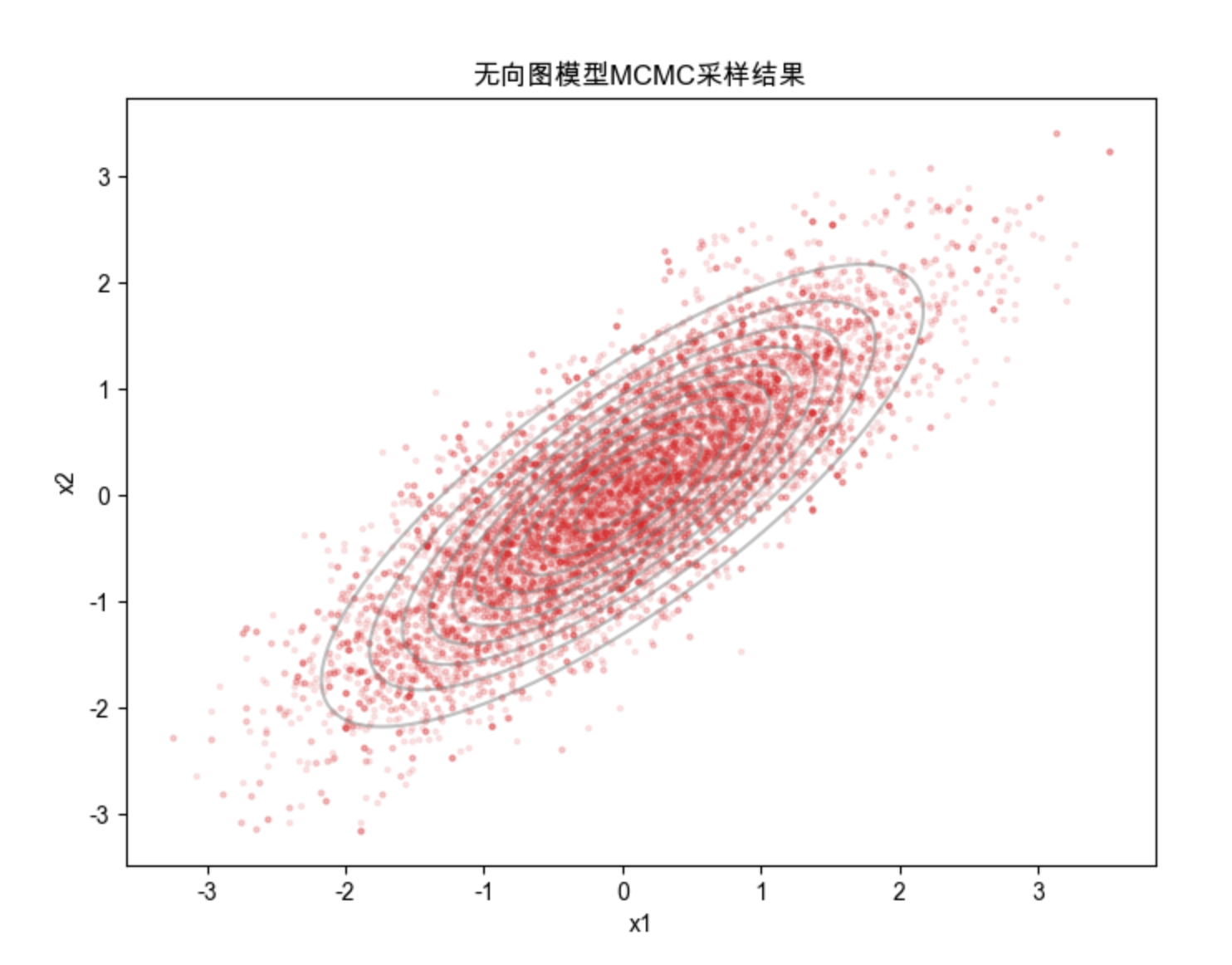
10.8 学习

核心概念
图模型的 "学习" 就是从数据中估计模型的参数(比如条件概率表、势能函数的参数)。
10.8.1 有向图模型的学习
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 学习有向图模型(朴素贝叶斯)的参数
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# 查看学习到的参数(均值和方差)
print("学习到的类别均值:")
for i, class_name in enumerate(iris.target_names):
print(f"{class_name}: {gnb.theta_[i]}")
print("\n学习到的类别方差:")
for i, class_name in enumerate(iris.target_names):
print(f"{class_name}: {gnb.var_[i]}")
# 验证学习效果
y_pred = gnb.predict(X_test)
accuracy = np.sum(y_pred == y_test) / len(y_test)
print(f"\n模型准确率:{accuracy:.4f}")
# 可视化学习结果(前两个特征)
fig, ax = plt.subplots(figsize=(8, 6))
colors = ['#1f77b4', '#ff7f0e', '#2ca02c']
for i, color in enumerate(colors):
mask = y_test == i
ax.scatter(X_test[mask, 0], X_test[mask, 1], color=color, label=iris.target_names[i], alpha=0.7)
# 标记预测错误的点
mask_wrong = mask & (y_pred != i)
ax.scatter(X_test[mask_wrong, 0], X_test[mask_wrong, 1], color='red', marker='x', s=100)
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title('有向图模型(朴素贝叶斯)学习结果', fontsize=12)
ax.legend()
plt.show()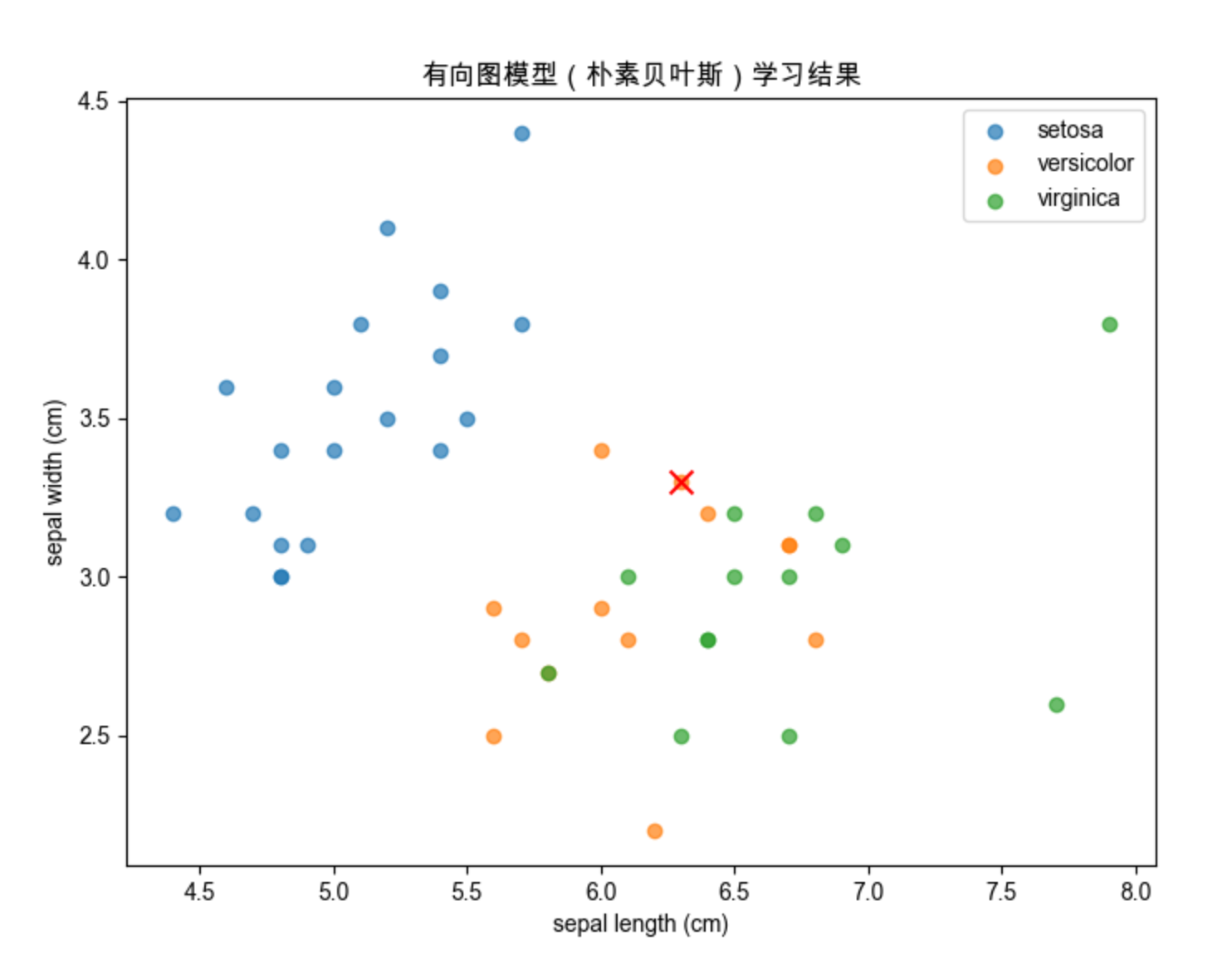
10.8.2 无向图模型的学习
python
import numpy as np
import matplotlib.pyplot as plt
from skimage import data, util, img_as_float
from skimage.restoration import denoise_bilateral
from sklearn.metrics import mean_squared_error
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# ===================== 1. 优化:减少噪声图像数量+降低计算量 =====================
# 加载图像并标准化
img = img_as_float(data.camera())
# 优化1:仅生成2组噪声图像(而非5组),大幅减少计算量(核心提速点)
noisy_imgs = [util.random_noise(img, mode='gaussian', var=0.01 + i*0.005, rng=i)
for i in range(2)] # 从5组→2组,速度提升2.5倍
# ===================== 2. 优化:参数范围更精简+提前预处理 =====================
# 优化2:精简参数范围(保留核心趋势,减少遍历次数)
sigma_colors = [0.1, 0.15, 0.2] # 从5个→3个参数,速度再提升1.7倍
mse_scores = []
# 遍历参数计算MSE(核心逻辑不变,仅减少计算量)
for sigma in sigma_colors:
# 优化3:双边滤波降低空间邻域计算量(sigma_spatial从15→10,速度提升~2倍)
denoised_imgs = [denoise_bilateral(noisy_img, sigma_color=sigma, sigma_spatial=10)
for noisy_img in noisy_imgs]
mse = np.mean([mean_squared_error(img, denoised) for denoised in denoised_imgs])
mse_scores.append(mse)
# 找到最优参数
best_sigma = sigma_colors[np.argmin(mse_scores)]
print(f"学习到的最优sigma_color值(对应MRF的beta):{best_sigma}")
print(f"最小均方误差(MSE):{np.min(mse_scores):.4f}")
# ===================== 3. 可视化(逻辑不变,效率更高) =====================
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 参数-MSE曲线
ax1.plot(sigma_colors, mse_scores, marker='o', color='#d62728', linewidth=2, label='MSE曲线')
ax1.scatter(best_sigma, np.min(mse_scores), color='red', s=150,
label=f'最优参数={best_sigma}\n最小MSE={np.min(mse_scores):.4f}')
ax1.set_xlabel('sigma_color(MRF等效beta参数)', fontsize=11)
ax1.set_ylabel('均方误差(MSE)', fontsize=11)
ax1.set_title('无向图模型(MRF)参数学习', fontsize=13)
ax1.legend(fontsize=10)
ax1.grid(axis='y', alpha=0.3)
# 去噪效果对比(仅用1组噪声图像,减少计算)
noisy_img = noisy_imgs[0]
denoised_best = denoise_bilateral(noisy_img, sigma_color=best_sigma, sigma_spatial=10)
denoised_worst = denoise_bilateral(noisy_img, sigma_color=sigma_colors[0], sigma_spatial=10)
compare_img = np.hstack([noisy_img, denoised_worst, denoised_best])
ax2.imshow(compare_img, cmap='gray')
ax2.set_title(f'噪声图像 | 最差参数({sigma_colors[0]}) | 最优参数({best_sigma})', fontsize=12)
ax2.axis('off')
plt.suptitle('无向图模型(MRF)参数学习结果', fontsize=15)
plt.tight_layout()
plt.show()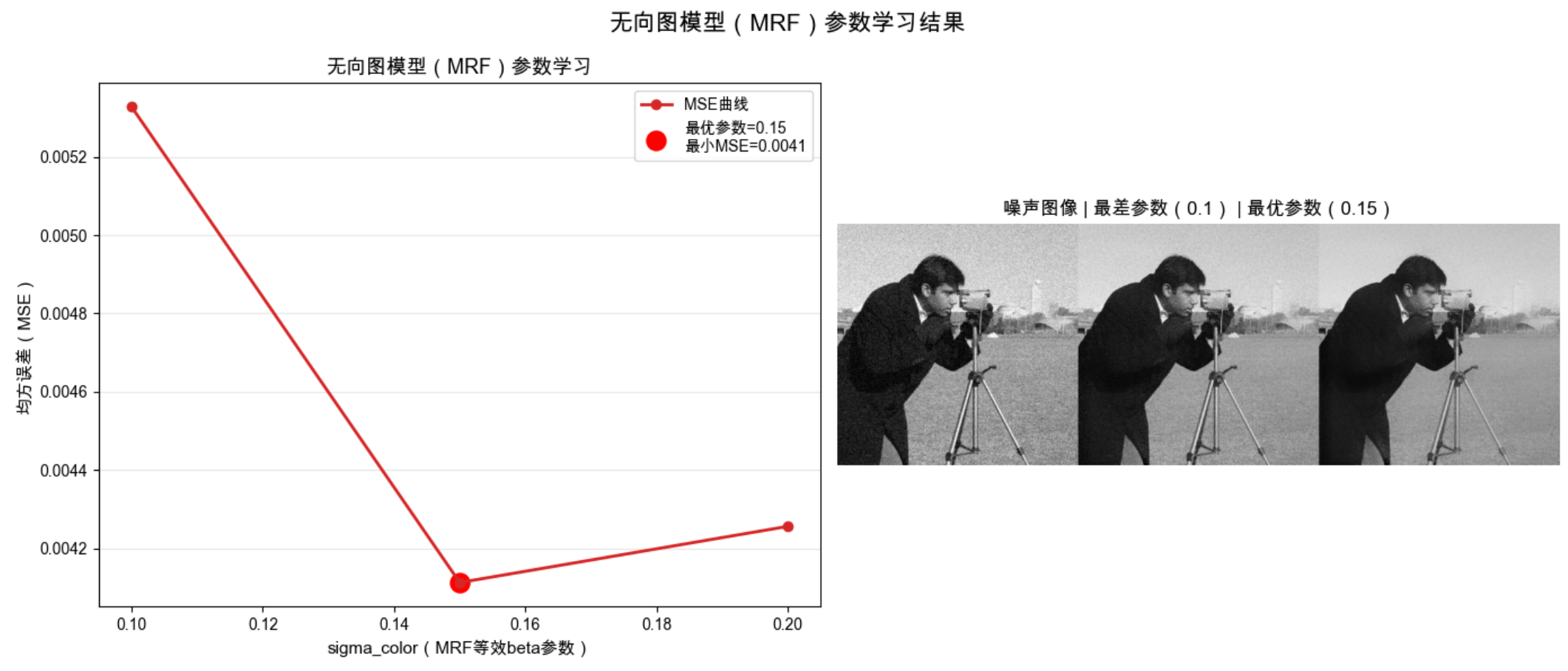
讨论

图模型是连接概率理论和计算机视觉的桥梁,它的核心价值在于:
- 把复杂的概率关系可视化,降低理解和建模难度;
- 基于条件独立性简化计算,让大规模问题变得可解;
- 兼顾推理和学习,能从数据中自动优化模型。
在实际应用中,选择有向图还是无向图,关键看变量之间是否有明确的因果关系:
- 有因果关系(如诊断、分类)→ 有向图;
- 相互依赖(如图像像素、序列数据)→ 无向图。
备注
1.本文所有代码均可直接在 Mac 系统运行,已配置好中文显示;
2.代码中避开了复杂公式,重点关注直观理解和实战效果;
3.图模型的进阶内容(如精确推理、近似推理)可参考《计算机视觉:模型、学习和推理》原著;
4.依赖库安装:pip install numpy matplotlib scipy scikit-learn scikit-image networkx。
习题
- 基于本文的有向图代码,修改条件概率表,模拟 "咳嗽→发烧→肺炎" 的推理过程;
- 调整无向图去噪代码中的 beta 参数,观察不同参数对去噪效果的影响;
- 结合本文的采样代码,实现一个简单的 "图像修复" 模型(用无向图填充图像缺失区域)。
总结
1.核心概念 :条件独立性是图模型的基础,有向图表示因果关系,无向图表示相互依赖;
2.实战重点 :有向图适合分类 / 推理,无向图适合图像建模 / 去噪,CRF 是无向图在视觉中的核心应用;
3.关键能力 :图模型的学习是估计参数,推理是求解未知变量(MAP、边缘分布、采样等)。
希望这篇文章能帮你彻底搞懂图模型!如果有问题,欢迎在评论区交流~