这篇文章是接着上一篇来的,上一篇使用了积分法来计算π值,这一篇,采用古老的割圆法来计算。
毕竟,在15个世纪前,南北朝时期的大数学家祖冲之,就使用割圆术将圆周率精确到小数点后第七位了。
公式推导
割圆法,这里是以正六边形为基础,开始进行下一步的分割,推导下一次分割的边长,与上一次的边长的关系。
这里的推导还是比较简单的,只需要有初中的几何知识就够了。
见下图:
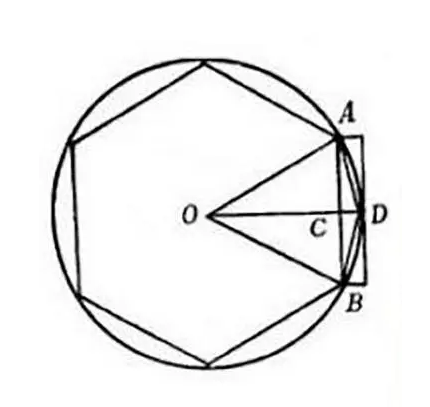
设圆的半径为R,上一次的边长为L(AB),计算下一次的边长L2(AD):
这里我们要计算AD的长度,就是要用R与L表示出来:
L2^2=AD^2=AC^2+CD^2
AC=L/2
CD=OD-OC=R-OC
OC^2=OA^2-AC^2=R^2-(L/2)^2结合以上4个式子,就可以将L2表示出来了:
L2=sqrt((L/2)^2+(R-sqrt(R-(L/2)^2))^2)这其实就是一个递推公式了。
基于6边形计算一次,得到L2为12边形的边长。
再分割一次,其边长的计算,就是以12边形的边长值代入公式的L中来计算,这样可以得到24边形的边长。
如此递推,可以进行无限分割下去。
为了计算简单,设定圆的半径R=1。
L的初始长度,按正六边形的边长算,也是1。
有多少条边呢?
以正六边形为基础,第一次算出来的L2,是正12边形的边长,就是有12条边。
再下一次推导,就是24边形。
所以,边长数目可以表示为:6*2^n
第一次实现
下面是实现的代码:
from decimal import Decimal, getcontext
import sys
import time
printed = False
getcontext().prec = 20 # 设置精度
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), " prec=", getcontext().prec)
def read_file(file_name) :
file = open(file_name, 'r')
str = file.read()
file.close()
return str
# 读取文件 pi-10000.txt ,并将其内容存放到一个字符串中
pi_str = read_file("pi-10000.txt")
# 比较两个字符串,前n个字符相等
def strCompare(str1, str2):
n = 0
min_length = min(len(str1), len(str2))
for i in range(min_length):
if str1[i] == str2[i]:
n += 1
else:
break
print("the same is: ", n-2)
return n
def CircleDevision(num):
global printed
if not printed: #控制函数名只打印一次
print(sys._getframe().f_code.co_name)
printed = True
sum=Decimal(0.0)
length1 = Decimal(1.0)
for i in range(num):
a = Decimal(length1/2)**2
b = Decimal(1-a)**Decimal(0.5)
c = Decimal(1-b)**2
length2 = Decimal(c+a)**Decimal(0.5)
length1 = length2
sum = (Decimal(2)**Decimal(num))*6 * length1
return sum/2
i=0
for j in [1, 10, 100, 1000, 10000, 100000]:
num=j
i += 1
start = time.time()
count_pi = Decimal(3.0)
count_pi = CircleDevision(num)
print("num=", num,', use time={:.2f}'.format(time.time() - start))
print("count_pi=",count_pi)
strCompare(pi_str, str(count_pi))运行结果如下:
2026-02-21 18:39:08 prec= 20
CircleDevision
num= 1 , use time=0.00
count_pi= 3.1058285412302491482
the same is: 1
num= 10 , use time=0.00
count_pi= 3.1415925166921574480
the same is: 6
num= 100 , use time=0.01
count_pi= 3.1415926535897932390
the same is: 17
num= 1000 , use time=0.10
count_pi= 3.1415926535897932383
the same is: 18
num= 10000 , use time=0.96
count_pi= 3.1415926535897932390
the same is: 17可以看出来,运行耗时很短,还不到一秒钟,计算的精度就达到18位了。
根据边长数目的计算方法:6*2^n
n=1,就是6*2^1=12,即12边形
n=10,就是6*2^10=12,即6144边形,此时精度达到小数点后6位。
历史记载,祖冲之的计算是精确到小数点后7位。
修改代码,试了计算结果精度相近的几个分割情况,运行结果如下:
num= 10 , use time=0.00
count_pi= 3.1415925166921574480
the same is: 6
num= 11 , use time=0.00
count_pi= 3.1415926193653839556
the same is: 7
num= 12 , use time=0.00
count_pi= 3.1415926450336908971
the same is: 7
num= 13 , use time=0.00
count_pi= 3.1415926514507676522
the same is: 8对应计算结果精度为7的情况,是num=11与12的情况,其对应边数情况:
n=11,边数是6*2^11,即12288边形
n=12,边数是6*2^12=12,即24576边形
据此推测,祖冲之可能是将圆周分割到这两种正多边形,计算得到的7位精度。
继续分析运行结果:
num= 10000 时,精度反而下降了,比num= 1000时还要低!
这说明可能是到达计算数据精度的上限了。这次运行时,设定的数据精度是20位,而计算过程中最尾部数据必然不够准确,计算过程中积累误差,导致精度达不到设定的20位。
接下来,就将设定的数据精度继续提升,相应的,计算结果的精度也能达到100位,1000位了。
下面,是将精度设置为1000位时的结果:
2026-02-21 18:43:13 prec= 1000
CircleDevision
num= 1 , use time=0.09
the same is: 1
num= 10 , use time=0.68
the same is: 6
num= 100 , use time=5.09
the same is: 61
num= 1000 , use time=82.68
the same is: 599
num= 10000 , use time=573.20
the same is: 996精度提升到1000位时,运行不到10分钟,就精确到996位,这其实是再次到达设定数据精度的极限了。
看前面几次精度的提升,基本上num值变为10倍,精度位数变化也接近10倍。从599再提升,下一次的10倍,就应该是5990左右。
当然,这个也可以进行验证,就是将精度位数改大到超过5990,再跑一遍程序即可,只是需要等待一段时间。
然而,提升设定的数据精度位数后,打印出来的耗时,让我大吃一惊:
2026-02-22 17:34:09 prec= 6500
CircleDevision
num= 1 , use time=11.31
the same is: 1
num= 10 , use time=96.87
the same is: 6
num= 100 , use time=833.85
the same is: 61循环100次,耗时就833秒,接近14分钟。
往后估算,那么循环1000次,就大约需要140分钟,2个多小时!
循环10000次,就大约需要1400分钟,需要23小时!
这个耗时太长了,试试看有没有优化耗时的方法。
第一次优化(公式化简)
尝试优化耗时:
将这个式子展开化简:
L2=sqrt((L/2)^2+(R-sqrt(R-(L/2)^2))^2)得到:
L2=sqrt(2-sqrt(4-L^2))对比两个公式,第二个公式明显减少了计算量。
实现代码如下:
#公式化简
def CircleDevision2(num):
sum=Decimal(0.0)
length1 = Decimal(1.0)
for i in range(num):
a = Decimal(Decimal(1) - Decimal(length1/2)**2)**Decimal(0.5)
length2 = Decimal(Decimal(2) - a*2)**Decimal(0.5)
length1 = length2
sum = (Decimal(2)**Decimal(num))*6 * length1
return sum/2运行发现,看不到明显的耗时减少。
再次对比公式看,发现加减法与平方的次数都有减少,但是开方的次数都一样,是2次,估计是计算过程中,开方是最耗时的。
第二次优化(公式优化)
查看公式,看能否进一步优化:
L2=sqrt(2-sqrt(4-L^2))推理下一次分割:
L3=sqrt(2-sqrt(4-L2^2))代入L2得:
L3=sqrt(2-sqrt(2+sqrt(4-L2^2)))继续推理第三次分割:
L4=sqrt(2-sqrt(4-L3^2))代入L3得:
L4=sqrt(2-sqrt(2+sqrt(2+sqrt(4-L2^2))))这样,可以看出来一个规律:
每多分割一次,就是增加一个: sqrt(2+
这次得到的新公式,是每增加一次分割,只需要增加一次开根号运算。相比与上一版的公式,可是将开方运算减少了一半了,这下应该是真的减少了计算量吧。再来验证下。
实现代码如下:
#公式改进
def CircleDevision3(num):
sum=Decimal(0.0)
length1 = Decimal(Decimal(4) - Decimal(1)**2)**Decimal(0.5)
for i in range(num):
length1 = Decimal(2 + length1)**Decimal(0.5)
length2 = Decimal(Decimal(2) - length1)**Decimal(0.5)
sum = (Decimal(2)**Decimal(num+1))*6 * length2
return sum/2运行结果:
2026-02-23 11:06:30 prec= 1000
CircleDevision3
num= 1 , use time=0.14
the same is: 1
num= 10 , use time=0.54
the same is: 7
num= 100 , use time=4.58
the same is: 61
num= 1000 , use time=45.10
the same is: 395
num= 10000 , use time=449.97
the same is: -2可以看出,耗时确实减少了,对比100次分割的情况,从82秒下降到45秒。
但是,在num= 1000时,精度却下降了,从599下降到395。
这真的是超乎意料。太奇怪了!
想不明白原因,还是来多做做测试吧。
修改代码,对比测试了不同的分割次数num,大约得到一个关系:
精度位数 = num - 600
这个600,就大约是循环1000次能达到的最高精度。
数值精度超过1200,就能达到循环1000次的最高精度了。
为什么是这样,还是不明白。继续增加打印信息跟踪,发现精度值是先上升后下降的!
是上升到了499之后,逐渐下降到395的!
499,几乎就是1000的一半。
而对于达到一半的精度,在这个计算中,有一个典型的情况,就是开方!
例如,0.000001开方,就是0.001,这两者的位数,分别是6位与3位,就是2倍的关系。
开方后数据的精度要达到3位,就要求开方前数据的精度达到6位!
也就是说,要实现600位的精度,数据精度的设置,就要超过1200位!这和之前测试的情况是匹配的。
但是,还有另外一个问题,就是使用最初没有做优化的计算方法时,怎么精度值就不会下降?并且能达到599!
再次对比这两个公式的差异:
L2=sqrt((L/2)^2+(R-sqrt(R-(L/2)^2))^2)
L2=sqrt(2-sqrt(4-L^2))是最初没有做优化的公式,有一个独立的 (L/2)^2 ,估计是这个部分,保留了之前计算的精度。
由上面遇到的问题来看,在涉及到高精度计算时,有些东西和我们平常做控制程序真不一样。
这样,虽然做了优化,但是由于公式发生了变化,反而要求设定更高的数据精度位数。
而翻了倍的数据精度,会大幅度增加运行耗时。
所以,还是最初那个公式的计算的效率最高。
结论
1,同样耗时情况下,割圆法计算的精度远远高于积分法,积分法运行17分钟,才达到15位精度,而割圆法运行10分钟,就达到1000位精度。
2,对割圆法求边长的公式做了化简,计算效率上没有明显提升,反而在对数据精度要求更高了,要求2倍的数据精度。才能达到计算结果的最高精度。
3,对割圆法求边长的公式做了优化,减少了计算量,但是对数据精度的要求还是2倍。
4,对高精度数据计算,其要求与普通编程不一样,有些精妙处需要继续探究。