目录
1.摘要
针对多AUV在大规模复杂海底环境中执行多目标任务时面临的路径规划难题,本文突破传统单目标静态建模方式,将问题建模为动态多目标优化问题,并提出一种协同进化计算算法。该方法采用双层编码结构表示投放位置与任务访问顺序,结合多目标多种群框架、基于重组的采样策略以及环境变化下的增量响应机制,以提升解的多样性与收敛性能。基于新西兰海底地形数据构建的大规模复杂场景实验表明,该方法在解的多样性和最优性方面优于现有先进算法。
2.问题背景
问题阐述
本文研究多自主水下航行器(Multi-AUV)在大尺度复杂海洋环境中执行多目标任务的路径规划优化,设任务集为 M = { m 1 , ... , m N } M = \{m_1, \dots, m_N\} M={m1,...,mN},多个AUV通过水面移动平台投放并可进行多次往返航行。要求每个目标任务仅被一次航次访问,且每个航次的总载荷不超过AUV最大载荷 L max L_{\max} Lmax,同时航次能量消耗不超过最大可用能量 E max E_{\max} Emax。由于海洋环境与任务可能随时间变化,问题被建模为动态多目标优化模型:
min F ( X , t ) = ( f 1 ( X , t ) , f 2 ( X , t ) ) , \min F(X, t) = (f_1(X, t), f_2(X, t)), minF(X,t)=(f1(X,t),f2(X,t)),
其中, f 1 f_1 f1 表示所有航次的总运行成本
f 1 ( X , t ) = ∑ j = 1 n v g j + w e ⋅ n v f_1(X, t) = \sum_{j=1}^{n_v} g_j + w_e \cdot n_v f1(X,t)=j=1∑nvgj+we⋅nv
综合考虑航行能耗与AUV发射回收的固定成本, f 2 f_2 f2 表示所有航次中的最大完成时间
f 2 ( X , t ) = max 1 ≤ j ≤ n v h j f_2(X, t) = \max_{1 \leq j \leq n_v} h_j f2(X,t)=1≤j≤nvmaxhj
其用于衡量任务负荷均衡性。约束条件包括任务唯一分配约束
∑ j = 1 n v x i j = 1 \sum_{j=1}^{n_v} x_{ij} = 1 j=1∑nvxij=1
载荷约束
∑ i = 1 N l i x i j ≤ L max \sum_{i=1}^{N} l_i x_{ij} \leq L_{\max} i=1∑Nlixij≤Lmax
能量约束
g j ≤ E max g_j \leq E_{\max} gj≤Emax
其中,单个航次的能量消耗定义为
g j = w 1 l e n ( p j ) + w 2 h t ( p j ) + w 3 t u r n ( p j ) + w 4 r i s k ( p j ) , g_j = w_1 \mathrm{len}(p_j) + w_2 \mathrm{ht}(p_j) + w_3 \mathrm{turn}(p_j) + w_4 \mathrm{risk}(p_j), gj=w1len(pj)+w2ht(pj)+w3turn(pj)+w4risk(pj),
分别对应路径长度代价、地形高度变化代价、转向代价和风险代价。路径长度代价
len ( p j ) = ∑ ∥ w j i , k − w j i , k + 1 ∥ \operatorname{len}(p_j) = \sum \|w_j^{i,k} - w_j^{i,k+1}\| len(pj)=∑∥wji,k−wji,k+1∥
高度代价
ht ( p j ) = ∑ height ( w j i , k , w j i , k + 1 ) \operatorname{ht}(p_j) = \sum \operatorname{height}(w_j^{i,k}, w_j^{i,k+1}) ht(pj)=∑height(wji,k,wji,k+1)
转向代价
turn ( w j i , k ) = 1 − cos ( θ j i , k ) \operatorname{turn}(w_j^{i,k}) = 1 - \cos(\theta_j^{i,k}) turn(wji,k)=1−cos(θji,k)
风险代价与风险区域的空间分布相关:
risk ( p j ) = ∑ r t ( w j i , k ) , r t ( w ) = ∑ r = 1 n r R I ⋅ max ( 0 , R r − ∥ w − r c r ∥ ) / R r . \operatorname{risk}(p_j) = \sum rt(w_j^{i,k}), \quad rt(w) = \sum_{r=1}^{n_r} RI \cdot \max(0, R_r - \|w - r_c^r\|)/R_r. risk(pj)=∑rt(wji,k),rt(w)=r=1∑nrRI⋅max(0,Rr−∥w−rcr∥)/Rr.
动态多目标优化
动态多目标优化需要持续跟踪变化的帕累托最优解,现有方法主要包括帕累托局部搜索、元启发式算法和学习驱动方法。帕累托局部搜索通过邻域搜索与存档优化提升效率,元启发式算法借助遗传算法、粒子群、蚁群等机制增强多样性与收敛性,学习方法则利用高斯过程、图神经网络或注意力模型构建或预测解。针对环境动态变化,常用策略包括解重用、预测、迁移学习和强化学习,但在稳定性、泛化能力与数据需求方面各有局限。
3.协同进化计算算法
水下环境建模
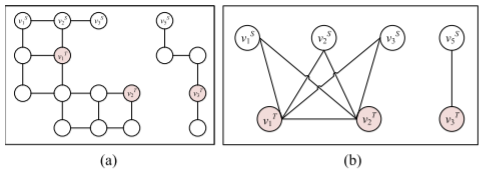
三维水下环境被离散为规则立方体网格并构建为搜索图 G = ( V , E ) G=(V,E) G=(V,E),立方体中心坐标为
x = ( i + 0.5 ) L C , y = ( j + 0.5 ) W C , z = ( k + 0.5 ) H C x=(i+0.5)L_C,\quad y=(j+0.5)W_C,\quad z=(k+0.5)H_C x=(i+0.5)LC,y=(j+0.5)WC,z=(k+0.5)HC
相邻立方体之间建立边连接,障碍或地形冲突的节点被删除,风险区域节点赋予风险值。与
水面相交的节点构成发射回收集合 V S V_S VS,包含任务的节点构成目标集合 V T V_T VT。
在加权图中,边权表示能量与时间成本,路径代价为边权之和,若能量与时间互不支配,则
优先选择能量更低的路径。最短路径通过SPFA算法计算。为降低规模,仅保留 V S ∪ V T V_S\cup V_T VS∪VT 构成子图
G ′ = ( V S ∪ V T , E ′ ) G'=(V_S\cup V_T,E') G′=(VS∪VT,E′)
其中,边权为原图中的最短路径代价,不设置 V S V_S VS 之间的连边。
协同进化计算算法
基于成本图 G ′ G' G′,协同进化算法(CEA)首先优化水面投放点与多AUV航次方案,再在原搜索图 G G G 上补全相邻节点间的具体轨迹。
双层编码表示
解采用双层结构:
X = ( S , P ) , S = ( s 1 , ... , s K ) , P = ( p 1 , ... , p K ) X = (S, P), \quad S = (s_1, \ldots, s_K), \quad P = (p_1, \ldots, p_K) X=(S,P),S=(s1,...,sK),P=(p1,...,pK)
其中, S S S 为 K K K 个水面投放点(2K维实向量编码), P P P 为对应航次序列,每个 p i p_i pi 为从 s i s_i si 出发、访问若干目标后返回的顶点序列。
多种群协同进化机制
设置两个种群分别优化 f 1 f_1 f1 与 f 2 f_2 f2,水面点位置采用差分进化(DE/best/1)更新:
S ′ = S b e s t + F ( S r 1 − S r 2 ) S' = S_{best} + F(S_{r1} - S_{r2}) S′=Sbest+F(Sr1−Sr2)
航次构建采用蚁群系统目标逐步选择,满足能量与载荷约束:
T = { v ∣ c 0 ( p ) + c 0 ( x t − 1 , v ) + c 0 ( v , s k ) ≤ E m a x , l ( p ) + l ( v ) ≤ L m a x } T = \{v \mid c_0(p) + c_0(x_{t-1}, v) + c_0(v, s_k) \leq E_{max},\, l(p) + l(v) \leq L_{max}\} T={v∣c0(p)+c0(xt−1,v)+c0(v,sk)≤Emax,l(p)+l(v)≤Lmax}
状态转移规则
x t = { arg max v ∈ T p r o ( v ) , r ≤ q 0 roulette , otherwise x_t = \begin{cases} \arg\max_{v \in T} pro(v), & r \leq q_0 \\ \text{roulette}, & \text{otherwise} \end{cases} xt={argmaxv∈Tpro(v),roulette,r≤q0otherwise
其中
p r o ( v ) = τ i ( x t − 1 , v ) η i ( x t − 1 , v ) β ∑ u ∈ T τ i ( x t − 1 , u ) η i ( x t − 1 , u ) β , η i = 1 c i pro(v) = \frac{\tau_i(x_{t-1}, v)\eta_i(x_{t-1}, v)^\beta}{\sum_{u \in T} \tau_i(x_{t-1}, u)\eta_i(x_{t-1}, u)^\beta}, \quad \eta_i = \frac{1}{c_i} pro(v)=∑u∈Tτi(xt−1,u)ηi(xt−1,u)βτi(xt−1,v)ηi(xt−1,v)β,ηi=ci1
通过局部与全局信息更新:
τ i ( x , v ) = ( 1 − ρ ) τ i ( u , v ) + ρ Δ τ \tau_i(x, v) = (1 - \rho)\tau_i(u, v) + \rho \Delta\tau τi(x,v)=(1−ρ)τi(u,v)+ρΔτ
τ i ( u , v ) = ( 1 − α ) τ i ( u , v ) + α Δ τ \tau_i(u, v) = (1 - \alpha)\tau_i(u, v) + \alpha \Delta\tau τi(u,v)=(1−α)τi(u,v)+αΔτ
由于两个种群分别偏向帕累托前沿两端,算法从存档中选取父代解进行交叉重组,当任务变化时,保留历史水面点,仅重构航次并重新评估,利用历史信息素与种群经验加速收敛。
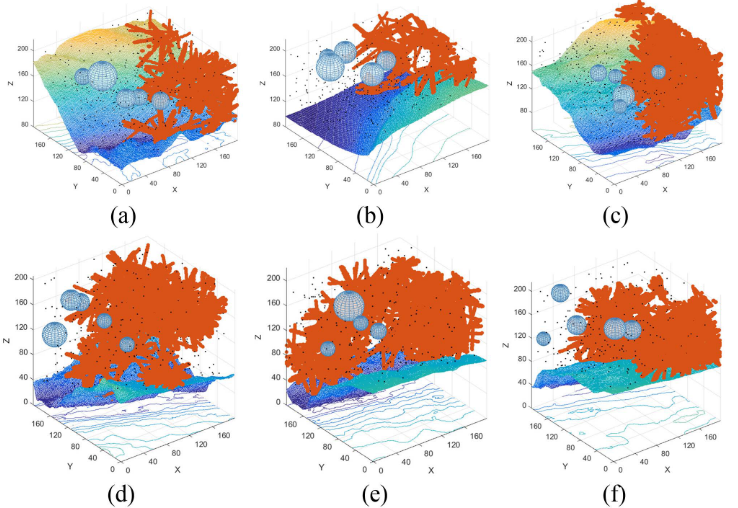
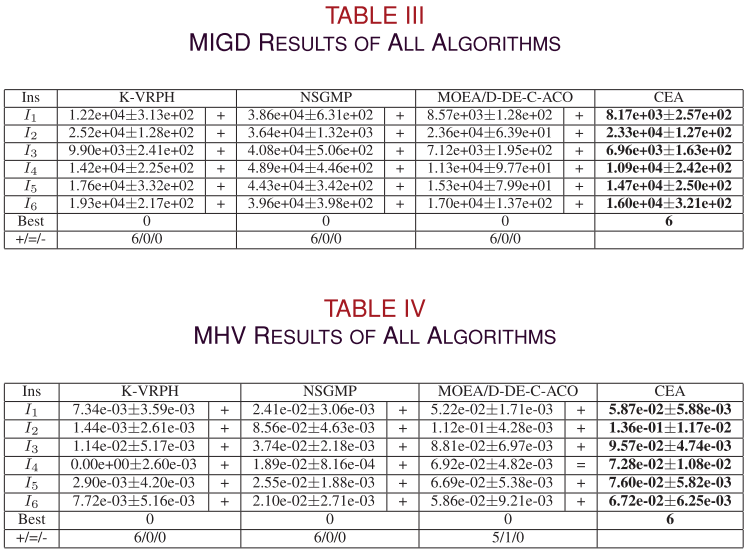
4.结果展示
5.参考文献
1 Liu X F, Fang Y, Zhan Z H, et al. A cooperative evolutionary computation algorithm for dynamic multiobjective multi-AUV path planningJ. IEEE Transactions on Industrial Informatics, 2023, 20(1): 669-680.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx