1. 背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力;
- 一个工程中的源文件不计其数,按其类型,功能,模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作;
- makefile带来的好处就是---"自动化编译",一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率;
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GUN的make。可见,makefie都成为了一种在工程方面的编译方法;
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2. 基本使用
首先使用命令创建一个makefile/Makefile文件:
touch makefile/Makefilemakefile文件中写的内容是有固定格式和固定内容的:
bash
目标文件:依赖文件/依赖文件列表
[tab]依赖方法演示:
首先创建一个myproc.c文件,然后创建文件makefile,使用vim打开文件makefile,并在里面写入以下内容并保存退出:
bash
1 myproc:myproc.c
2 gcc -o myproc myproc.c 随后直接使用make就可以直接对myproc.c文件进行编译了:
bash
[cyq@VM-0-5-centos ~]$ vim myproc.c
[cyq@VM-0-5-centos ~]$ ll
total 24
-rw-rw-r-- 1 cyq cyq 0 May 17 15:13 myproc.c
[cyq@VM-0-5-centos ~]$ touch makefile
[cyq@VM-0-5-centos ~]$ vim makefile
[cyq@VM-0-5-centos ~]$ cat makefile
myproc:myproc.c
gcc -o myproc myproc.c
[cyq@VM-0-5-centos ~]$ make
gcc -o myproc myproc.c
[cyq@VM-0-5-centos ~]$ ll
total 44
-rw-rw-r-- 1 cyq cyq 40 May 17 15:14 makefile
-rwxrwxr-x 1 cyq cyq 8360 May 17 15:19 myproc
-rw-rw-r-- 1 cyq cyq 66 May 17 15:19 myproc.c项目清理
如果想要对编译生成的可执行程序文件进行清理,可以继续在makefile文件中添加内容:
bash
1 myproc:myproc.c
2 gcc -o myproc myproc.c
3 .PHONY:clean
4 clean:
5 rm -f myproc然后保存退出,随后在命令行中便可以直接使用make clean命令对myproc文件进行清理:
bash
[cyq@VM-0-5-centos ~]$ ll
total 44
-rw-rw-r-- 1 cyq cyq 74 May 17 15:30 makefile
-rwxrwxr-x 1 cyq cyq 8360 May 17 15:19 myproc
-rw-rw-r-- 1 cyq cyq 66 May 17 15:19 myproc.c
[cyq@VM-0-5-centos ~]$ make clean
rm -f myproc
[cyq@VM-0-5-centos ~]$ ll
total 32
-rw-rw-r-- 1 cyq cyq 74 May 17 15:30 makefile
-rw-rw-r-- 1 cyq cyq 66 May 17 15:19 myproc.c什么叫做总是被执行?
从上面的演示中我们可以发现,当使用make命令时,默认执行的是makefile文件中所写的第一个依赖方法,使用make clean命令时,才执行makefile文件中所写的第二个依赖方法,简而言之:make命令扫描makefile文件的时候,从上向下扫描,默认形成第一个目标文件。一般写makefile文件时,都习惯将生成可执行程序的依赖方法写在第一个。
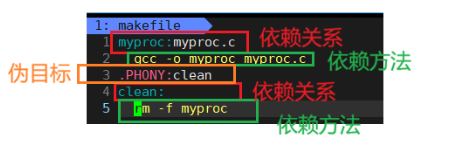
在上面所写的makefile文件内容中,每行的结构如上图所示,可以发现:第三行的内容为:.PHONY:clean,这行指代的是伪目标,他起到的作用是能够让对应的依赖方法总是被执行,对于第一个依赖方法而言,前面并没有加上伪目标,所以在命令行重复执行make命令来实施第一个依赖方法时,会出现如下展示的输出结果:
bash
[cyq@VM-0-5-centos ~]$ make
make: `myproc' is up to date.
[cyq@VM-0-5-centos ~]$ make
make: `myproc' is up to date.
[cyq@VM-0-5-centos ~]$ make
make: `myproc' is up to date.而加上了伪目标修饰的make clean命令进行多次重复执行时,则不会出现这样的输出:
bash
[cyq@VM-0-5-centos ~]$ make clean
rm -f myproc
[cyq@VM-0-5-centos ~]$ make clean
rm -f myproc
[cyq@VM-0-5-centos ~]$ make clean
rm -f myproc在 Makefile 中,编译生成最终可执行文件的目标通常不声明为伪目标(.PHONY),主要是因为它本身对应着具体的产物文件。伪目标用于声明那些不代表真实文件的动作(如 clean、install等),这些目标每次都应无条件执行。而可执行文件目标(如 main)代表一个实际存在的输出文件,Make 工具会根据其依赖的时间戳决定是否需要重新编译,从而提高编译效率,避免不必要的重复构建。如果将其声明为伪目标,则每次都会强制执行,即便依赖没有更新,这会破坏增量编译机制,降低构建性能。
那么问题又来了,make命令怎么知道bin文件(二进制文件,对应上面示例中的myproc文件)和.c文件(对应myproc.c文件)的新旧问题呢?
Make 工具判断文件新旧的核心依据是文件的修改时间(modify time)。在执行 Makefile 时,make 会比较目标文件(如可执行文件 myproc)与其依赖文件(如源文件 myproc.c)的最后修改时间戳。如果目标文件不存在,或者任意一个依赖文件的时间戳比目标文件更新,make 就认为目标已"过时",需要重新执行对应的命令来生成或更新目标文件。反之,如果目标文件存在且其时间戳晚于所有依赖文件,make 就判定目标为最新,跳过重新构建的步骤,从而实现了高效的增量编译,节省编译时间。

结论: .PHONY:让make忽略源⽂件和可执行目标文件的M时间对比。
查看文件的修改时间的指令如下:
bash
stat [文件名称]示例:
bash
[cyq@VM-0-5-centos ~]$ stat myproc
File: 'myproc'
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 797874 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1001/ cyq) Gid: ( 1001/ cyq)
Access: 2026-05-17 16:25:43.670337824 +0800
Modify: 2026-05-17 16:25:43.005336920 +0800
Change: 2026-05-17 16:25:43.005336920 +0800
Birth: -对于一个已经存在的文件,直接对其使用touch命令可以改变这个文件的所有时间(Access time,Modify time,Change time):
bash
[cyq@VM-0-5-centos ~]$ stat myproc.c
File: 'myproc.c'
Size: 66 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 797877 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ cyq) Gid: ( 1001/ cyq)
Access: 2026-05-17 15:19:28.300974137 +0800
Modify: 2026-05-17 15:19:28.298974134 +0800
Change: 2026-05-17 15:19:28.298974134 +0800
Birth: -
[cyq@VM-0-5-centos ~]$ touch myproc.c
[cyq@VM-0-5-centos ~]$ stat myproc.c
File: 'myproc.c'
Size: 66 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 797877 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ cyq) Gid: ( 1001/ cyq)
Access: 2026-05-17 16:30:30.680729237 +0800
Modify: 2026-05-17 16:30:29.450727555 +0800
Change: 2026-05-17 16:30:29.450727555 +0800
Birth: -3. 推导过程
为了能够更好的理解编译的整个流程,重新编辑makefile文件中的内容如下:
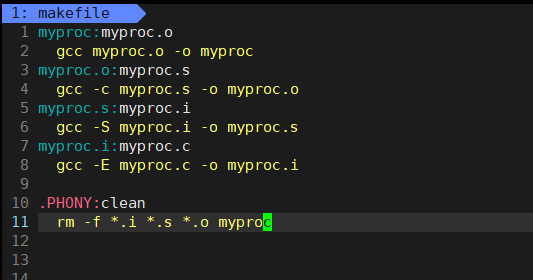
当我们保存 Makefile 并退出,然后在命令行执行 make命令时,整个构建过程就正式启动了。make 工具会按照 Makefile 的内容,从上至下逐行读取依赖关系。
首先,它会读到第一行的依赖关系,并发现目标文件 myproc.o目前并不存在。于是,它将与 myproc.o对应的依赖方法暂时入栈,等待后续处理。接着,make 继续读到第二个依赖关系,发现依赖文件 myproc.s也不存在,于是同样将第二个依赖方法入栈。依此类推,当遇到一个依赖目标也不存在时,其对应的依赖方法也会被依次入栈,直到最后一条依赖关系。
此时,make 发现当前目录中已经存在源文件 myproc.c,于是便执行对应的依赖方法,生成第一个实际的目标文件。之后,之前入栈的各个依赖方法会依次出栈并执行,每个步骤会生成上一级规则所需的中间文件。如此逐步向上回溯,直至最初的目标文件 myproc被成功创建,整个构建过程就顺利完成了。
4. 符合实际项目的Makefile写法
当然,在实际操作中,我们通常不会像之前那样直接编写编译命令,而是采用下面这种更为优雅和可维护的写法:
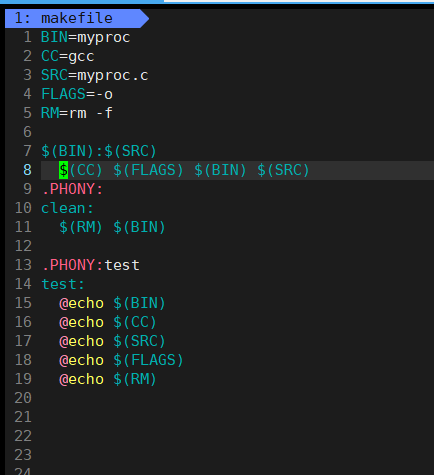
这种写法通过将依赖关系(如源文件、编译器)和执行命令(如编译选项、清理操作)抽象为变量进行管理。这样做的好处非常明显:当需要调整编译参数、更换编译器,或者增删源文件时,只需修改变量定义处即可,无需在复杂的命令块中来回查找替换,极大地提升了 Makefile 的可读性、可维护性以及项目的灵活性。
在上述基础上,我们还可以对 Makefile 进行进一步的优化。具体来说,在规则的命令部分,$@是一个自动化变量,它永远代表当前规则中冒号左侧的目标文件(即 $(BIN));而 $^则代表该目标所依赖的所有文件列表(即所有的源文件)。

这种写法的优势在于,当一个目标依赖多个源文件时,我们无需手动将它们一一列出,直接使用 $^即可指代全部依赖项。这不仅简化了命令的书写,也避免了因源文件增减而频繁修改命令的麻烦,使 Makefile 更加简洁且易于维护。
还有一点值得补充的是,如果在编写依赖方法(命令)时,在行首加上 @符号,执行 make命令时就会启用静默模式。在这种模式下,执行的命令本身不会在终端中被打印出来,只会显示最终的构建结果;如果没有加 @,系统则会默认回显正在执行的命令,这在调试时很有帮助,但在展示最终效果时可能会显得冗余。
正如演示所示,在静默式执行 make clean时,终端只显示了命令提示符,没有显示具体的 rm -f myproc操作;而在非静默式执行时,系统明确打印出了正在执行的删除命令。同样的,执行 make编译时,静默模式隐藏了具体的 gcc编译指令,只保留了干净的构建过程。
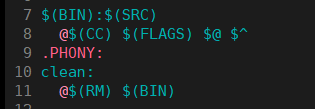
静默式执行:
bash
[cyq@VM-0-5-centos ~]$ make clean
[cyq@VM-0-5-centos ~]$ make非静默式执行:
bash
[cyq@VM-0-5-centos ~]$ make clean
rm -f myproc
[cyq@VM-0-5-centos ~]$ make
gcc -o myproc myproc.c当然,针对每一个目标(依赖关系),我们并非只能定义一个对应的执行方法。实际上,完全可以添加多个方法,正如你在示例中看到的那样------在每个依赖关系下方追加了一条回显指令,这样做的目的是向用户直观地反馈每一步操作的执行状态:告知对应的指令已经运行完毕。
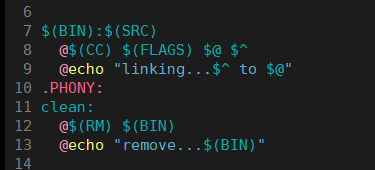
演示结果如下:
bash
[cyq@VM-0-5-centos ~]$ make clean
remove...myproc
[cyq@VM-0-5-centos ~]$ make
linking...myproc.c to myproc5. Makefile写法的进一步优化
在实际工程中,Makefile 的构建通常采用一种更精细的编译策略:我们不直接将 .c 源文件一步编译为最终的可执行文件,而是先将每个 .c 文件编译成对应的 .o 目标文件,最后再将它们链接为最终的可执行程序。为了实现这个自动化过程,我们可以在 Makefile 中使用通配符 % 定义一条模式规则,如 %.o: %.c,它表示"每一个 .o 文件都依赖同名 .c 文件",然后在对应的命令中使用 (CC) (FLAGS) \< 进行编译。这条命令通过自动变量 < 获取了依赖列表中的第一个文件(即 .c 文件),从而实现了对每个 .c 文件的单独编译。
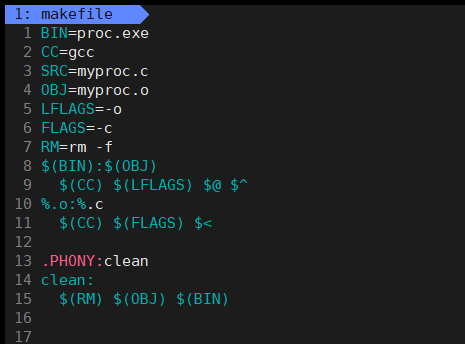
使用 %.o: %.c 是定义了一条模式规则,它告诉 Make:"所有 .o 文件的生成方式都相同,即从同名的 .c 文件编译而来"。这意味着无论有多少个源文件(如 a.c、b.c、c.c),只要它们符合这个模式,都会自动匹配这条规则,从而无需为每个文件单独写一条规则。
而如果写成 (OBJ): (SRC),就表示所有 .o 文件依赖于所有 .c 文件。这会导致任何 .c 文件被修改,都会触发所有 .o 文件重新编译,破坏了增量编译的优势,也无法明确每个 .o 文件与具体 .c 文件的一一对应关系。
命令行测试结果:
bash
[cyq@VM-0-5-centos ~]$ make clean
rm -f myproc.o proc.exe
[cyq@VM-0-5-centos ~]$ make
gcc -c myproc.c
gcc -o proc.exe myproc.o在完成上述操作后,我们可以进一步对命令进行静默处理,并添加提示信息以优化输出结果:
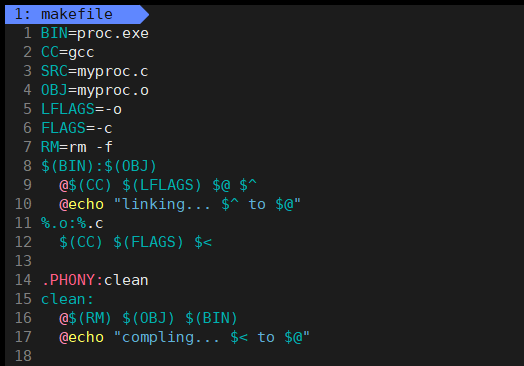
命令行测试结果:
bash
[cyq@VM-0-5-centos ~]$ make clean
compling... to clean
[cyq@VM-0-5-centos ~]$ make
gcc -c myproc.c
linking... myproc.o to proc.exe\<与^的区别
在 Makefile 的规则中,$<和 $^都是自动变量,但用途有根本区别:
$<代表依赖列表中的第一个 依赖文件,例如在规则 main.o: main.c a.h中,$<就是 main.c,通常用于编译场景,指明单个要编译的源文件。
$^则代表依赖列表中的所有 依赖文件,在同一个规则中,$^会同时包含 main.c和 a.h,通常用于链接场景,将多个目标文件一次性传给链接器以生成最终可执行文件。
简单来说,$<是"拿第一个依赖来编译",$^是"把所有依赖拿来链接"。
6. Makefile写法的终极优化
相较于手动逐个罗列源文件与目标文件的写法,这种方式在面对复杂项目时显然效率低下。为了优化这一流程,我们可以引入自动化依赖扫描机制,让 Makefile 自行检索所需的源代码,从而大幅提升编写的便捷性。
正如演示所示,SRC变量用于存放后缀为 .c的源文件列表。要实现自动获取目录下的所有 C 源文件,通常有两种等效的方法:
bash
SRC=$(shell ls *.c)
Src=$(wildcard *.c)这两种写法的作用完全一致,都能将当前目录下所有的 .c文件自动收录。接下来,为了生成与 C 文件一一对应的同名 .o目标文件,我们需要对 OBJ变量进行转换,只需使用 Makefile 特有的替换语法即可:
bash
OBJ=$(SRC:.c=.o)整体Makefile内容:
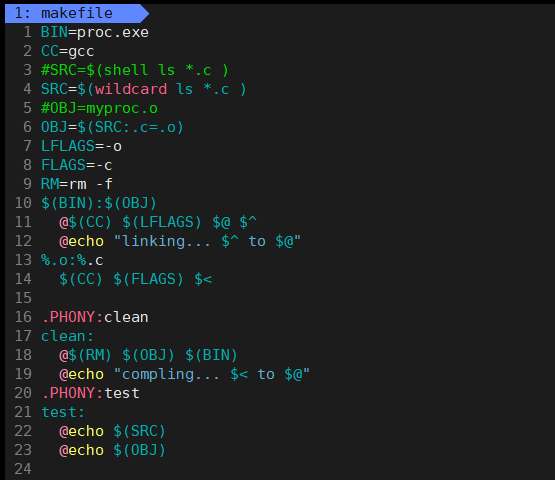
命令行演示如下:
bash
[cyq@VM-0-5-centos ~]$ make test
test.c myproc.c
test.o myproc.o
[cyq@VM-0-5-centos ~]$ make clean
compling... to clean
[cyq@VM-0-5-centos ~]$ make
gcc -c test.c
gcc -c myproc.c
linking... test.o myproc.o to proc.exe7. 书写进度条的预备知识
7.1 回车换行
在计算机的文本表示中,回车和换行是两个不同的概念,代表两个独立的动作。
-
回车 是指将光标(或打印头)从当前位置移动到本行的行首。
-
换行 是指将光标(或打印头)从当前行垂直移动到下一行,但列位置不变。
这两个概念源于早期打字机的机械操作:当写完一行内容时,需先执行回车动作(\r)将打印头退回左侧起点,再执行换行动作(\n)将纸张上移一行。在计算机领域,这种连续的操作通常被称为"回车换行"。
在编程语言和文本编辑中,这两个动作有对应的控制字符:
-
换行符 通常用
\n表示。 -
回车符 通常用
\r表示。
在 Microsoft Windows 等系统中,换行标记常用 \r\n表示,即先回车、后换行。而在 Linux、macOS 等系统中,通常只使用 \n来表示换行。
7.2 缓冲区问题
在现阶段的学习中,我们无需对缓冲区做深入探究,只需建立一个核心认知:缓冲区本质上就是内存中的一块临时存储区域。
下面通过一个简单的示例来直观感受缓冲区的存在及其作用。请先用 vim 编辑器创建以下代码:
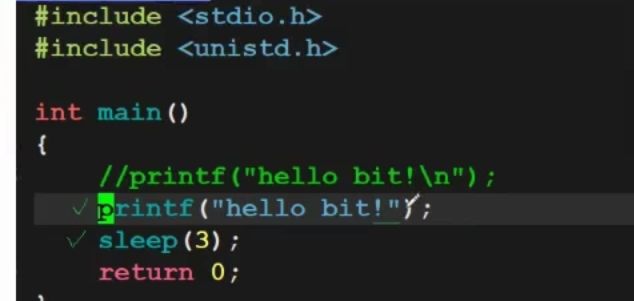
可以观察到,图中两处 printf函数的区别仅在于是否包含换行符 \n 。当我们使用带 \n的第一个 printf时,程序会立即输出"hello bit",随后等待 3 秒才结束;而使用不带 \n的第二个 printf时,系统会先休眠 3 秒,之后才在控制台显示"hello bit"。
造成这种输出顺序差异的关键原因正是 \n触发的"行缓冲刷新"机制 。当 printf内容中包含 \n时,会立即执行一次缓冲区刷新,将其中暂存的内容输出到终端;反之,未包含 \n的输出内容会暂时保留在缓冲区中,直到程序正常退出时,系统自动执行最后的缓冲区刷新操作,才将其打印出来。
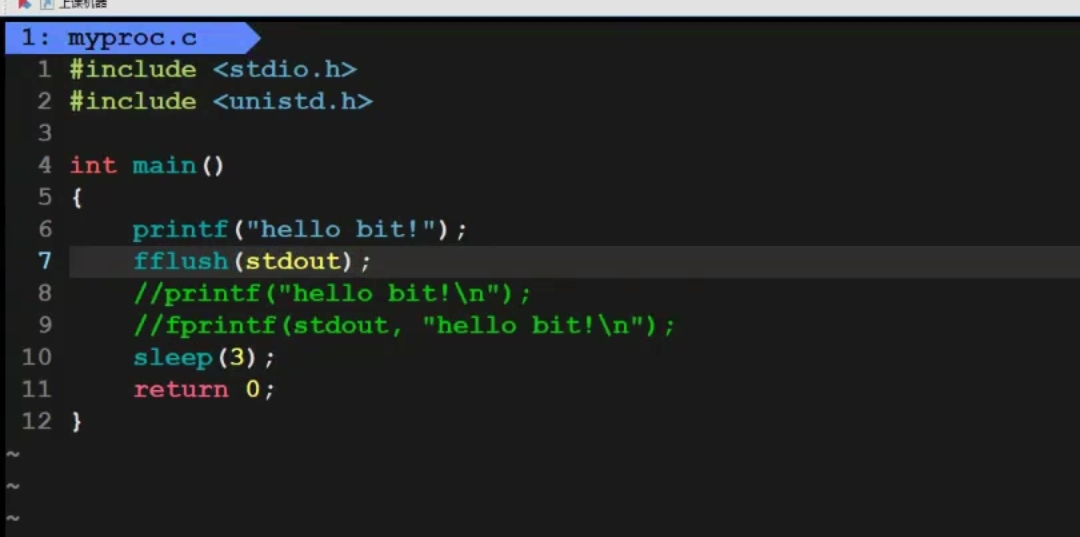
如果想要没有\n的printf函数立马刷新输出内容,可以使用fflush函数:
7.3 倒计时程序
当我们在vin编辑器中编辑一段如下图所示的代码时:
bash
1 #include<stdio.h>
2 int main()
3 {
4 int i = 9;
5 while(i>=0)
6 {
7 printf("%d\n",i);
8
9 i--;
10 sleep(1);
11 }
12
13 return 0;
14 }
运行发现输出结果如下图所示:
bash
[cyq@VM-0-5-centos ~]$ make
gcc -c myproc.c
linking... test.o myproc.o to proc.exe
[cyq@VM-0-5-centos ~]$ ./proc.exe
9
8
7
6
5
4
3
2
1
0观察到数字显示在每一行,这是因为我们在printf函数中使用了\n,如果想要每个数字显示在同一行,那么就不能使用\n,而是使用\r,同时要搭配上fflush函数来刷新缓冲区使内容输出:
bash
1 #include<stdio.h>
2 int main()
3 {
4 int i = 9;
5 while(i>=0)
6 {
7 printf("%d\r",i);
8 fflush(stdout);
9 i--;
10 sleep(1);
11 }
12 printf("\n");
13 return 0;
14 }命令行输出结果为:
bash
[cyq@VM-0-5-centos ~]$ make
gcc -c myproc.c
linking... test.o myproc.o to proc.exe
[cyq@VM-0-5-centos ~]$ ./proc.exe
0但如果将代码中i的初始值改为i=10,然后在命令行运行时输出结果如下:
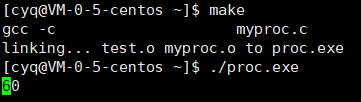
这是因为显示器显示数字12345时,其实显示的是'1','2','3','4','5',五个字符,因为显示器只认字符,它属于字符设备。
所以要使得输出结果能够正常,就需要在书写代码过程中设置位宽:
bash
printf("%-2d\r",i);其中-2d中的2代表位宽,'-'代表让输出结果左对齐(默认是右对齐)。
完整代码:
bash
#include <stdio.h>
#include <unistd.h>
int main()
{
int i = 10;
while(i >= 0)
{
printf("%-2d\r", i); // \n
fflush(stdout);
i--;
sleep(1);
}
printf("\n");
return 0;
}8. 进度条代码
8.1 version1---原理版本
创建好需要的文件:
bash
[cyq@VM-0-5-centos ~]$ mkdir progress
[cyq@VM-0-5-centos ~]$ pwd
/home/cyq
[cyq@VM-0-5-centos ~]$ cd progress
[cyq@VM-0-5-centos progress]$ pwd
/home/cyq/progress
[cyq@VM-0-5-centos progress]$ ll
total 0
[cyq@VM-0-5-centos progress]$ touch process.h
[cyq@VM-0-5-centos progress]$ touch process.c
[cyq@VM-0-5-centos progress]$ touch main.c
[cyq@VM-0-5-centos progress]$ ll
total 0
-rw-rw-r-- 1 cyq cyq 0 May 18 11:19 main.c
-rw-rw-r-- 1 cyq cyq 0 May 18 11:19 process.c
-rw-rw-r-- 1 cyq cyq 0 May 18 11:19 process.h
[cyq@VM-0-5-centos progress]$ touch Makefile
[cyq@VM-0-5-centos progress]$ vim MakefileMakefile文件中写入以下内容:
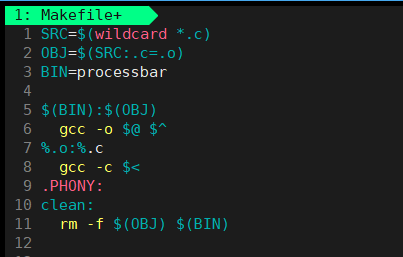
在process.h文件中写入以下内容:
bash
#pragma once
#include<stdio.h>
void process_v1():在process.c文件中写入以下内容:
bash
1 #include "process.h"
2 #include <string.h>
3 #include <unistd.h>
4
5 #define NUM 101
6 #define STYLE '-'
7
8 void process_v1()
9 {
10 char buffer[NUM];
11 memset(buffer, 0, sizeof(buffer);
12
13 const char *lable = "|/-\\";
14 int len = strlen(lable);
15
16 int cnt = 0;
17 while(cnt <= 100)
18 {
19 printf("[%-100s][%d%%][%c]\r", buffer, cnt, lable[cnt%len]);
20
21 fflush(stdout);
22 buffer[cnt] = STYLE;
23 cnt++;
24 usleep(50000); // 50ms, 控制速度
25 }
26 printf("\n");
27 } 随后在命令行运行mian函数得到输出结果:
bash
[cyq@VM-0-5-centos progress]$ make
gcc -c process.c
gcc -o processbar main.o process.o
[cyq@VM-0-5-centos progress]$ ./processbar
[----------------------------------------------------------------------------------------------------][100%][|]可以观察到,目前的进度条虽然在视觉上已经能够流畅地动态刷新,但它本质上仍是一个模拟演示版本 。该代码仅用于展示进度条在终端中的生成逻辑与渲染原理,并不具备真正的数据交互能力。换句话说,它无法实时获取文件下载的实际字节数或计算真实的传输速率,仅仅是通过固定的延时和计数器来"伪造"进度,属于教学级的原理验证,而非生产环境中可用的真实进度监控。
8.2 version2---真实版本
在这个版本中,我们需要对进度条进行核心升级,使其不再停留于模拟演示,而是能够真正用于实际场景。具体来说,要实现动态读取文件传输的实际字节数,并据此实时计算和刷新进度条的显示。
编辑mian.c文件内容:
bash
1 #include"process.h"
2 #include<stdio.h>
3 #include<unistd.h>
4
5 double total =1024.0;
6 double speed =1.0;
7
8 void DownLoad()
9 {
10 double current = 0;
11 while(current<=total)
12 {
13 FlushProcess(total,current);
14 usleep(1000);//充当下载数据
15 current += speed;
16 }
17 printf("download %.2lfMB Done\n",current);
18
19 }
20
21 int main()
22 {
23 DownLoad();
24 return 0;
25 } 编辑process.c文件内容:
bash
1 #include "process.h"
2 #include <string.h>
3 #include <unistd.h>
4
5 #define NUM 101
6 #define STYLE '-'
7
8
9 //version2
10 void FlushProcess(double total,double current)
11 {
12 char buffer[NUM];
13 memset(buffer,0,sizeof(buffer));
14 const char *lable="|/-\\";
15 int len = strlen(lable);
16 static int cnt = 0;
17 //不需要自己循环,填充#
18 int num = (int)(current*100/total);
19 for(int i = 0;i < num;i++)
20 {
21 buffer[i] = STYLE;
22 }
23 double rate = current/total;
24 cnt %= len;
25 printf("[%-100s][%.1f][%c]\r",buffer,rate*100,lable[cnt]);
26 cnt++;
27 fflush(stdout);
28 }命令行执行演示:
bash
[cyq@VM-0-5-centos progress]$ make
gcc -c main.c -std=c99
main.c: In function 'DownLoad':
main.c:14:5: warning: implicit declaration of function 'usleep' [-Wimplicit-function-declaration]
usleep(3000);//充当下载数据
^
gcc -c process.c -std=c99
process.c: In function 'process_v1':
process.c:46:9: warning: implicit declaration of function 'usleep' [-Wimplicit-function-declaration]
usleep(50000); // 50ms, 控制速度
^
gcc -o processbar main.o process.o
[cyq@VM-0-5-centos progress]$ ./processbar
[----------------------------------------------------------------------------------------------------][100.0][|]
download 1025.000000000000000000000MB Done可以看到:进度条正常运行!