本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(14)-Azure OpenAI(5)-OpenAI 智能文本处理小工具
前言
本文是上一篇"多格式文本处理工具"的进阶升级,聚焦职场「场景化交互+实用功能落地」,基于Azure OpenAI打造一款交互式工作助手。工具仍保持纯单Python文件运行,在保留多格式文本处理核心能力的基础上,新增三大实用升级:上下文记忆功能(支持多轮追问)、自定义提示词模板(适配个性化职场场景)、处理结果导出(直接保存为文档复用),逐步从"批量工具"向"个人AI助手"过渡。
工具核心价值:
- 交互更友好:命令行交互式升级,支持多轮对话追问,贴合日常沟通习惯;
- 个性化适配:可自定义提示词模板(如需求分析、面试反馈、周报生成),适配不同岗位需求;
- 复用性更强:处理结果可导出为TXT/Word/Excel,直接应用到工作文档中;
- 衔接性强:复用前序Azure OpenAI配置、提示工程、多格式处理逻辑,无新增学习成本。
适用人群:已掌握第一篇工具实操,希望提升工具交互体验、增加实用功能,逐步搭建个人AI工作助手的职场人士。
一、环境准备(前置条件)
完全复用上一篇的环境,无需额外配置,仅补充1个可选依赖(用于结果导出优化):
-
基础环境:已安装Python 3.8+,且已完成第一篇的环境配置;
-
依赖检查:确保已安装以下库(若已安装,无需重复执行):
pip install openai python-docx openpyxl PyPDF2 --upgrade
- 配置准备:已获取Azure OpenAI的
azure_endpoint、api_key、DEPLOYMENT_NAME。
二、实操
python
# Azure OpenAI 交互式工作助手(进阶版)
# 核心升级:多轮记忆+自定义模板+结果导出,支持TXT/Word/Excel/PDF多格式处理
from openai import AzureOpenAI
import os
from docx import Document
import openpyxl
import PyPDF2
from datetime import datetime
# ===================== 基础配置(替换为你的信息,复用第一篇) =====================
client = AzureOpenAI(
azure_endpoint="https://你的资源名.openai.azure.com/",
api_key="你的Key",
api_version="2024-08-01-preview"
)
DEPLOYMENT_NAME = "你的部署名"
# ===================== 新增:自定义提示词模板(可按需修改,适配职场场景) =====================
# 模板格式:{模板名: 提示词内容},可新增自己岗位常用的模板
PROMPT_TEMPLATES = {
"会议纪要总结": "你是专业的职场会议纪要总结助手,总结需包含「会议主题、核心结论、行动项、责任人、截止时间」,语言简洁正式,控制在200字内,无冗余内容。",
"需求信息提取": "你是职场需求分析专家,从文本中提取「需求名称、核心诉求、优先级、责任人、风险点、截止时间」,无则标注「无」,分点清晰,适配Excel导入格式。",
"面试反馈整理": "你是HR面试辅助助手,整理面试反馈需包含「候选人姓名、岗位、核心优势、不足、面试结论、下一步安排」,语言客观,格式标准化,可直接复制到面试记录表。",
"周报生成": "你是职场周报助手,根据日常工作文本,生成「本周工作内容、完成情况、遇到的问题、下周计划」四大模块,语言简洁,贴合职场周报规范。",
"自定义模板": "你是职场文本处理助手,按用户自定义的要求处理文本,确保输出贴合需求、格式规范。"
}
# ===================== 核心功能函数(升级:新增记忆、模板、导出) =====================
def get_prompt_by_template(template_name, custom_prompt=""):
"""根据模板名称获取提示词,支持自定义模板"""
if template_name == "自定义模板" and custom_prompt:
return custom_prompt
return PROMPT_TEMPLATES.get(template_name, PROMPT_TEMPLATES["会议纪要总结"])
def process_text(text, prompt_template="会议纪要总结", custom_prompt="", temperature=0.2):
"""
核心文本处理:支持模板选择+自定义提示词,输出结果+费用
:param text: 待处理文本
:param prompt_template: 提示词模板名称
:param custom_prompt: 自定义提示词(仅模板为"自定义模板"时生效)
:param temperature: 输出随机性(0-1,越小越稳定)
:return: 处理结果 + 单次费用
"""
system_prompt = get_prompt_by_template(prompt_template, custom_prompt)
try:
response = client.chat.completions.create(
model=DEPLOYMENT_NAME,
messages=[{"role": "system", "content": system_prompt},
{"role": "user", "content": f"请按要求处理以下文本:\n{text}"}],
temperature=temperature
)
# 费用计算(复用第一篇逻辑,精准监控)
prompt_tokens = response.usage.prompt_tokens
completion_tokens = response.usage.completion_tokens
cost = (prompt_tokens / 1000 * 0.00015) + (completion_tokens / 1000 * 0.0006)
return response.choices[0].message.content.strip(), round(cost, 6)
except Exception as e:
return f"处理失败:{str(e)}", 0
def export_result(result, export_format="txt", file_name="处理结果"):
"""
新增:结果导出功能,支持TXT/Word/Excel三种格式
:param result: 待导出的处理结果
:param export_format: 导出格式(txt/word/excel)
:param file_name: 导出文件名(无需加后缀)
:return: 导出结果提示(成功/失败)
"""
# 生成带时间戳的文件名,避免覆盖
time_str = datetime.now().strftime("%Y%m%d%H%M%S")
file_path = f"{file_name}_{time_str}.{export_format}"
try:
if export_format == "txt":
with open(file_path, "w", encoding="utf-8") as f:
f.write(result)
elif export_format == "word":
doc = Document()
doc.add_heading("OpenAI 处理结果", level=1)
doc.add_paragraph(result)
doc.save(file_path)
elif export_format == "excel":
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "处理结果"
# 按行拆分结果,写入Excel(适配批量处理结果)
lines = result.split("\n")
for row_idx, line in enumerate(lines, start=1):
ws.cell(row=row_idx, column=1, value=line)
wb.save(file_path)
else:
return f"不支持的导出格式:{export_format}"
return f"结果已成功导出,路径:{os.path.abspath(file_path)}"
except Exception as e:
return f"导出失败:{str(e)}"
# ===================== 多格式处理函数(复用第一篇,优化异常处理) =====================
def process_txt(file_path, prompt_template="会议纪要总结", custom_prompt=""):
if not os.path.exists(file_path):
return "文件不存在,请检查路径", 0
total_cost = 0
results = []
with open(file_path, "r", encoding="utf-8") as f:
lines = [line.strip() for line in f.readlines() if line.strip()]
for idx, line in enumerate(lines):
print(f"\n正在处理TXT第{idx+1}条文本...")
result, cost = process_text(line, prompt_template, custom_prompt)
total_cost += cost
results.append(f"【TXT第{idx+1}条】\n处理结果:{result}\n单次费用:${cost}\n")
summary = f"\n===== TXT处理完成 =====\n共处理{len(results)}条有效文本,总费用:${total_cost:.6f}\n"
return "\n".join(results + [summary]), total_cost
def process_word(file_path, prompt_template="会议纪要总结", custom_prompt=""):
if not os.path.exists(file_path) or not file_path.endswith(".docx"):
return "文件不存在或非.docx格式", 0
try:
doc = Document(file_path)
full_text = "\n".join([para.text.strip() for para in doc.paragraphs if para.text.strip()])
if not full_text:
return "Word文档无有效文本内容", 0
print("\n正在处理Word文档...")
result, cost = process_text(full_text, prompt_template, custom_prompt)
summary = f"\n===== Word处理完成 =====\n文档路径:{file_path}\n处理结果:\n{result}\n总费用:${cost:.6f}\n"
return summary, cost
except Exception as e:
return f"Word处理失败:{str(e)}", 0
def process_excel(file_path, sheet_name="Sheet1", col_index=0, prompt_template="会议纪要总结", custom_prompt=""):
if not os.path.exists(file_path) or not file_path.endswith(".xlsx"):
return "文件不存在或非.xlsx格式", 0
try:
wb = openpyxl.load_workbook(file_path)
ws = wb[sheet_name] if sheet_name in wb.sheetnames else wb.active
total_cost = 0
results = []
for row_idx, row in enumerate(ws.iter_rows(min_row=2, min_col=col_index+1, max_col=col_index+1, values_only=True)):
cell_text = row[0]
if not cell_text or not isinstance(cell_text, str):
continue
print(f"\n正在处理Excel第{row_idx+2}行文本...")
result, cost = process_text(str(cell_text), prompt_template, custom_prompt)
total_cost += cost
results.append(f"【Excel第{row_idx+2}行】\n处理结果:{result}\n单次费用:${cost}\n")
wb.close()
summary = f"\n===== Excel处理完成 =====\n共处理{len(results)}行有效文本,总费用:${total_cost:.6f}\n"
return "\n".join(results + [summary]), total_cost
except Exception as e:
return f"Excel处理失败:{str(e)}", 0
def process_pdf(file_path, prompt_template="会议纪要总结", custom_prompt=""):
if not os.path.exists(file_path) or not file_path.endswith(".pdf"):
return "文件不存在或非.pdf格式", 0
try:
with open(file_path, "rb") as f:
pdf_reader = PyPDF2.PdfReader(f)
full_text = ""
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
page_text = page.extract_text()
if page_text:
full_text += page_text.strip() + "\n"
if not full_text:
return "PDF文档无可提取的文本(可能是图片型PDF)", 0
print("\n正在处理PDF文档...")
result, cost = process_text(full_text, prompt_template, custom_prompt)
summary = f"\n===== PDF处理完成 =====\n文档路径:{file_path}\n处理结果:\n{result}\n总费用:${cost:.6f}\n"
return summary, cost
except Exception as e:
return f"PDF处理失败:{str(e)}", 0
# ===================== 新增:多轮记忆交互函数 =====================
def memory_interaction():
"""多轮对话交互,支持上下文记忆,贴合日常沟通场景"""
print("\n===== 多轮记忆交互模式 =====")
print("提示:输入「退出」可结束交互,输入「清空记忆」可重置上下文,输入「导出」可保存当前所有结果\n")
# 上下文记忆列表,存储历史对话(system+user+assistant)
messages = [{"role": "system", "content": "你是专业的职场AI助手,能记住上下文对话内容,回答贴合职场场景,简洁实用。"}]
total_cost = 0
all_results = [] # 存储所有交互结果,用于导出
while True:
user_input = input("你:")
if user_input.strip() == "退出":
summary = f"\n===== 交互结束 =====\n共产生费用:${total_cost:.6f}\n"
all_results.append(summary)
print(summary)
break
elif user_input.strip() == "清空记忆":
messages = [{"role": "system", "content": "你是专业的职场AI助手,能记住上下文对话内容,回答贴合职场场景,简洁实用。"}]
all_results = []
print("助手:记忆已清空,可重新开始交互\n")
continue
elif user_input.strip() == "导出":
if not all_results:
print("助手:暂无可导出的结果\n")
continue
export_format = input("请选择导出格式(txt/word/excel):") or "txt"
file_name = input("请输入导出文件名(无需加后缀):") or "多轮交互结果"
export_msg = export_result("\n".join(all_results), export_format, file_name)
print(f"助手:{export_msg}\n")
continue
# 新增用户输入到上下文
messages.append({"role": "user", "content": user_input})
try:
response = client.chat.completions.create(
model=DEPLOYMENT_NAME,
messages=messages,
temperature=0.3
)
# 计算费用并累计
prompt_tokens = response.usage.prompt_tokens
completion_tokens = response.usage.completion_tokens
cost = (prompt_tokens / 1000 * 0.00015) + (completion_tokens / 1000 * 0.0006)
total_cost += cost
response_content = response.choices[0].message.content.strip()
# 新增助手回复到上下文和结果列表
messages.append({"role": "assistant", "content": response_content})
all_results.append(f"你:{user_input}\n助手:{response_content}\n费用:${cost}")
# 输出回复
print(f"助手:{response_content}\n(本次费用:${cost},累计费用:${total_cost:.6f})\n")
except Exception as e:
error_msg = f"处理失败:{str(e)}"
print(f"助手:{error_msg}\n")
all_results.append(f"你:{user_input}\n助手:{error_msg}\n费用:$0")
# ===================== 主程序(升级:多模式交互,新手友好) =====================
if __name__ == "__main__":
print("===== Azure OpenAI 交互式工作助手(进阶版)=====\n")
print("支持模式:1. 多格式文件处理 2. 多轮记忆交互 3. 自定义模板处理")
mode_choice = input("请选择使用模式(输入1/2/3):")
# 1. 多格式文件处理(复用第一篇,新增模板选择)
if mode_choice == "1":
print("\n===== 多格式文件处理 =====")
print("支持格式:1.TXT 2.Word(.docx) 3.Excel(.xlsx) 4.PDF")
format_choice = input("请选择待处理文件格式(输入1/2/3/4):")
# 选择提示词模板
print("\n支持模板:")
for idx, template in enumerate(PROMPT_TEMPLATES.keys(), start=1):
print(f"{idx}. {template}")
template_choice = input("请选择提示词模板(输入序号):") or "1"
template_name = list(PROMPT_TEMPLATES.keys())[int(template_choice)-1]
custom_prompt = ""
if template_name == "自定义模板":
custom_prompt = input("请输入自定义提示词:")
# 执行对应格式处理
if format_choice == "1":
file_path = input("请输入TXT文件完整路径:")
result, _ = process_txt(file_path, template_name, custom_prompt)
elif format_choice == "2":
file_path = input("请输入Word文件完整路径:")
result, _ = process_word(file_path, template_name, custom_prompt)
elif format_choice == "3":
file_path = input("请输入Excel文件完整路径:")
sheet_name = input("请输入工作表名称(默认Sheet1):") or "Sheet1"
col_index = input("请输入待处理列索引(从0开始,默认0):")
col_index = int(col_index) if col_index.isdigit() else 0
result, _ = process_excel(file_path, sheet_name, col_index, template_name, custom_prompt)
elif format_choice == "4":
file_path = input("请输入PDF文件完整路径:")
result, _ = process_pdf(file_path, template_name, custom_prompt)
else:
result = "输入错误,程序退出"
# 结果导出选项
export_choice = input("\n是否导出处理结果?(y/n):")
if export_choice.lower() == "y":
export_format = input("请选择导出格式(txt/word/excel):") or "txt"
file_name = input("请输入导出文件名(无需加后缀):") or "文件处理结果"
export_msg = export_result(result, export_format, file_name)
print(f"\n{export_msg}")
print("\n===================== 处理结果 =====================")
print(result)
# 2. 多轮记忆交互(新增功能)
elif mode_choice == "2":
memory_interaction()
# 3. 自定义模板处理(新增功能,适配个性化需求)
elif mode_choice == "3":
print("\n===== 自定义模板处理 =====")
print("请选择处理方式:1. 输入文本 2. 上传文件")
custom_choice = input("输入1/2:")
template_name = "自定义模板"
custom_prompt = input("请输入自定义提示词(明确处理要求):")
if custom_choice == "1":
text = input("请输入待处理文本:\n")
result, cost = process_text(text, template_name, custom_prompt)
result = f"处理结果:\n{result}\n费用:${cost}"
elif custom_choice == "2":
print("支持格式:TXT/Word/Excel/PDF")
file_path = input("请输入文件完整路径:")
if file_path.endswith(".txt"):
result, _ = process_txt(file_path, template_name, custom_prompt)
elif file_path.endswith(".docx"):
result, _ = process_word(file_path, template_name, custom_prompt)
elif file_path.endswith(".xlsx"):
sheet_name = input("请输入工作表名称(默认Sheet1):") or "Sheet1"
col_index = input("请输入待处理列索引(从0开始,默认0):")
col_index = int(col_index) if col_index.isdigit() else 0
result, _ = process_excel(file_path, sheet_name, col_index, template_name, custom_prompt)
elif file_path.endswith(".pdf"):
result, _ = process_pdf(file_path, template_name, custom_prompt)
else:
result = "不支持的文件格式"
else:
result = "输入错误"
export_choice = input("\n是否导出处理结果?(y/n):")
if export_choice.lower() == "y":
export_format = input("请选择导出格式(txt/word/excel):") or "txt"
file_name = input("请输入导出文件名(无需加后缀):") or "自定义处理结果"
export_msg = export_result(result, export_format, file_name)
print(f"\n{export_msg}")
print("\n===================== 处理结果 =====================")
print(result)
else:
print("输入错误,程序退出")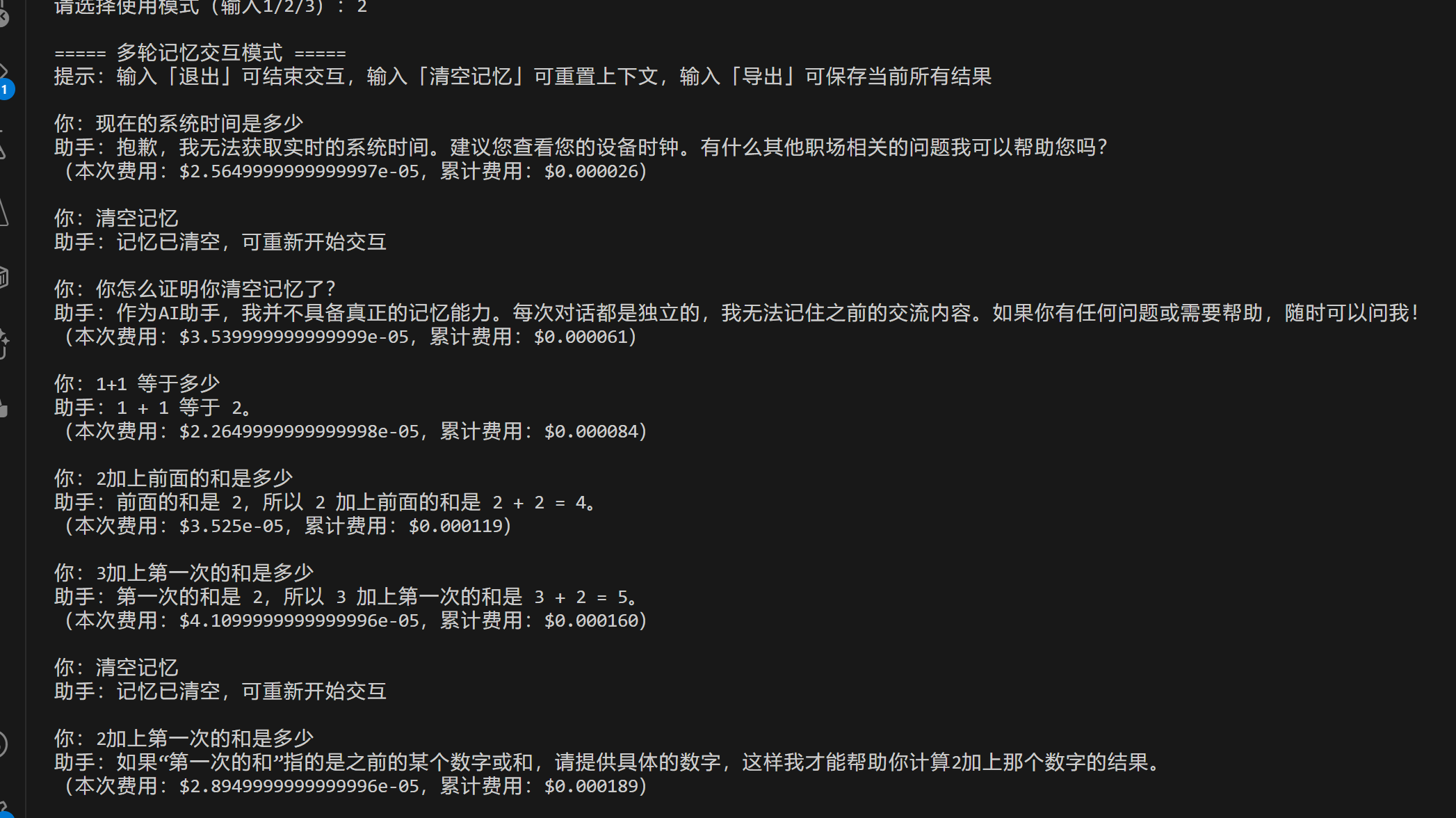
三、核心点详解
本篇工具在第一篇基础上,做了3大升级:
- 升级1:自定义提示词模板(适配个性化职场场景)
核心解决"第一篇提示词固定,无法适配不同岗位需求"的问题,新增5个常用职场模板(会议纪要总结、需求信息提取等),可直接修改、新增模板。
-
模板位置:代码中
PROMPT_TEMPLATES字典,格式为「模板名: 提示词内容」; -
使用方法:运行工具时,选择"模板序号"即可调用对应提示词,无需手动输入复杂提示;
-
个性化适配:新增"自定义模板"选项,可输入自己的提示词(如"产品需求分析""技术文档翻译"),适配自身岗位。
- 升级2:多轮记忆交互(贴合日常沟通习惯)
核心解决"第一篇仅支持单次处理,无法多轮追问"的问题,新增"多轮记忆模式",支持上下文连贯对话,类似ChatGPT的交互体验。
-
核心功能:记住历史对话内容,比如"先让助手总结会议纪要→再追问行动项细节→再让助手整理成表格",助手会衔接上下文;
-
操作指令:输入「退出」结束交互,「清空记忆」重置对话,「导出」保存所有交互结果;
-
职场价值:可用于日常工作答疑、多步骤文本处理,无需重复输入背景信息,提升沟通效率。
- 升级3:处理结果导出(直接落地工作文档)
核心解决"第一篇处理结果仅能在命令行查看,无法复用"的问题,新增结果导出功能,支持TXT/Word/Excel三种格式,直接保存为工作文档。
-
导出逻辑:处理完成后,输入"y"即可选择导出格式,自动生成带时间戳的文件(避免覆盖);
-
适配场景:批量处理的Excel结果可导出为Excel,直接粘贴到工作表格;会议纪要总结可导出为Word,直接分发;
-
优势:无需手动复制粘贴,减少重复工作,实现"处理→导出→复用"一站式完成。
对应代码层面,核心逻辑可简单解释为:
- 通过定义
PROMPT_TEMPLATES字典实现模板功能。 - 借助
memory_interaction函数存储历史对话实现记忆能力。 - 通过
export_result函数适配不同格式完成结果导出,同时复用了上一篇的多格式处理函数(process_txt/word/excel/pdf)和Azure OpenAI调用逻辑
四、分步实操演示
本次演示聚焦"新增功能",多格式文件处理的基础操作可复用第一篇,重点演示模板使用、多轮记忆、结果导出三大核心升级功能。
演示1:自定义模板使用(以"面试反馈整理"为例)
适用场景:HR批量整理面试反馈,使用模板快速生成标准化反馈内容。
-
准备文件:在桌面新建TXT文件
面试反馈.txt,每行填写1条面试记录(示例):候选人:张三,岗位:AI工程师,面试表现:熟悉Azure OpenAI调用,提示工程基础较好,沟通能力强,不足:项目经验较少,结论:可安排二面。
候选人:李四,岗位:产品经理,面试表现:需求分析能力强,了解AI工具应用,不足:对技术实现细节不熟悉,结论:录用。
-
运行工具:
-
打开CMD,切换到桌面:
cd C:\Users\huang\Desktop; -
运行代码:
python ai_work_assistant.py; -
选择模式:输入
1(多格式文件处理); -
选择格式:输入
1(TXT); -
选择模板:输入
3(面试反馈整理); -
输入文件路径:
"C:\Users\huang\Desktop\面试反馈.txt";
- 导出结果:处理完成后,输入
y(导出),选择格式excel,文件名输入面试反馈整理,回车即可导出Excel文件,直接用于面试记录归档。
演示2:多轮记忆交互(以"会议纪要多轮追问"为例)
适用场景:处理会议纪要时,多轮追问细节,让助手逐步完善内容。
-
运行工具:执行
python ai_work_assistant.py,选择模式2(多轮记忆交互); -
多轮交互示例:
你:帮我总结这段会议纪要:2026.03.10项目会议,参会人:张三、李四、王五,核心内容:确定A模块开发优先级最高,责任人张三,截止3月20日;B模块延后开发,责任人李四,截止4月5日;讨论了项目风险,主要是技术人员不足。
助手:【会议纪要总结】会议主题:2026.03.10项目会议;参会人:张三、李四、王五;核心结论:A模块优先开发(责任人张三,截止3月20日),B模块延后开发(责任人李四,截止4月5日);风险点:技术人员不足。(本次费用:0.00012,累计费用:0.00012)
你:把风险点展开说明,给出应对建议
助手:【风险点展开+应对建议】风险点:技术人员不足,可能导致A/B模块开发进度滞后,影响项目交付。应对建议:1. 协调公司内部技术人员支援;2. 短期招聘兼职技术人员;3. 优化开发流程,合理分配任务,避免人力浪费。(本次费用:0.00015,累计费用:0.00027)
你:把所有内容整理成表格格式
助手:| 项目 | 责任人 | 截止时间 | 备注 |
|------|--------|----------|------|
| A模块开发 | 张三 | 3月20日 | 优先级最高 |
| B模块开发 | 李四 | 4月5日 | 延后开发 |
| 项目风险 | - | - | 技术人员不足;应对:内部支援+兼职招聘+流程优化 |(本次费用:0.00018,累计费用:0.00045)
你:导出
助手:请选择导出格式(txt/word/excel):excel
请输入导出文件名(无需加后缀):会议纪要整理
结果已成功导出,路径:C:\Users\huang\Desktop\会议纪要整理_20260310153020.xlsx
- 核心优势:助手记住了所有历史对话,无需重复输入会议纪要原文,逐步完善内容,最终导出可直接复用的表格。
演示3:自定义模板+结果导出(以"产品需求分析"为例)
适用场景:产品经理处理用户反馈,自定义提示词,让助手生成标准化需求分析报告。
-
运行工具:执行
python ai_work_assistant.py,选择模式3(自定义模板处理); -
操作步骤:
-
选择处理方式:输入
1(输入文本); -
输入自定义提示词:"你是产品需求分析助手,从用户反馈中提取需求名称、核心诉求、目标用户、实现难度,分点输出,格式标准化,适配产品需求文档。";
-
输入待处理文本:"用户反馈:希望系统新增批量导入数据功能,每次手动输入数据太繁琐,主要用于日常数据统计,希望操作简单,无需复杂配置。";
-
导出结果:处理完成后,输入
y,选择格式word,文件名用户需求分析,导出后可直接粘贴到产品需求文档中。
总结
本篇工具在第一篇多格式处理的基础上,聚焦"交互升级+实用落地",新增的模板、记忆、导出三大功能,均贴合职场高频需求,保持单Python文件运行,无新增学习成本。为下一篇"轻量GUI界面AI应用"做好铺垫。
后续可根据自身工作场景,进一步优化功能(如新增模板、优化导出格式),让工具更贴合个人需求。下一篇将重点升级"GUI界面",摆脱命令行操作,打造更直观、更易用的桌面版AI工作助手。