背景
电力工业是国民经济发展中的重要基础性能源产业,是保证国民经济和社会持续、稳定、健康的发展的关键。电力工业的发展建设对国家各行业起到至关重要的作用。随着改革开放后中国经济的高速发展,各领域的用电需求在不断激增,推动着电力系统向数字化、智能化转型发展。
随着全球对可再生能源的日益重视以及电力系统结构的转型,传统的负荷预测和电力平衡技术面临着新的挑战和机遇。全球范围内,人们对电力系统的可靠性、经济性和环境友好性的要求日益增加,而这些要求往往受到可再生能源波动性和不确定性的影响。因此,急需解决的关键问题之一是如何准确预测负荷需求,实现电力供需的平衡,并有效整合可再生能源,满足日益增长的电力需求,同时降低碳排放并确保电网稳定运行。
需求分析
业务需求:根据电网中的历史负荷数据,预测下一小时的电力负荷
功能需求:基于历史的电力负荷数据,尽可能充分的挖掘特征,对未来下一个时间步(1小时)的电力负荷进行预测
数据源:包含时间、电力负荷两个字段的历史电力负荷数据
技术栈:pandas、matplotlib、sklearn、xgboost
实现方法:将时序数据特征以及时间特征整合成特征数据,要预测的指标作为目标数据,处理成二维的结构化数据集,训练机器学习模型进行预测。
时间序列预测是一种根据历史时间序列数据来预测未来值的方法。
该案例是基于时间与用电量负荷值 的线性关系完成 未来某段时间内的 用电量负荷的预测!!!
实现方案:
多变量单步:根据多个时间序列变量的历史数据来预测目标变量未来一个时间步的值
项目架构
该项目基于历史的电力负荷数据,训练XGBoost模型,实现多变量单步的电力负荷预测 data: 数据 log: 日志 model: 保存的模型文件 src: 项目主要的业务逻辑,包括机器学习建模相关的代码 utils: 项目中自定义的工具包
train.csv数据格式
test.csv数据格式
log封装
python
# -*- coding: utf-8 -*-
import logging
import os
from datetime import datetime
import pandas as pd
class Logger(object):
# 日志级别关系映射
level_relations = {
'debug': logging.DEBUG,
'info': logging.INFO,
'warning': logging.WARNING,
'error': logging.ERROR,
'crit': logging.CRITICAL
}
def __init__(self, root_path, log_name, level='info', fmt='%(asctime)s - %(levelname)s: %(message)s'):
# 指定日志保存的路径
self.root_path = root_path
# 初始logger名称和格式
self.log_name = log_name
# 初始格式
self.fmt = fmt
# 先声明一个 Logger 对象
self.logger = logging.getLogger(log_name)
# 设置日志级别
self.logger.setLevel(self.level_relations.get(level))
def get_logger(self):
# 指定对应的 Handler 为 FileHandler 对象, 这个可适用于多线程情况
path = os.path.join(self.root_path, 'log') # 日志保存路径
os.makedirs(path, exist_ok=True) # 创建目录, exist_ok=True 如果目录已存在,不会报错
file_name = os.path.join(path, self.log_name + '.log')
# print('file_name', file_name)
rotate_handler = logging.FileHandler(file_name, encoding="utf-8", mode="a")
# Handler 对象 rotate_handler 的输出格式
formatter = logging.Formatter(self.fmt)
rotate_handler.setFormatter(formatter)
# 将rotate_handler添加到Logger
self.logger.addHandler(rotate_handler)
return self.logger
# 测试日志功能.
if __name__ == '__main__':
# 1. 创建日志对象.
# new_name = 'train_' + pd.to_datetime(datetime.now()).strftime('%Y%m%d%H%M%S') + '.log'
new_name = 'train_' + 'load_predict_project'
logger = Logger('../', new_name).get_logger()
logger.info('我是一个info日志...')
logger.error('我是一个error日志...')
logger.debug('我一个debug日志...')
logger.warning('我一个warning日志...')
logger.critical('我一个critical日志...')
try:
logger.info('开始计算')
print(10 / 0)
except Exception as e:
logger.error(f'计算出错了, 错误信息是: {e}')
else:
logger.info('计算成功')
finally:
logger.info('计算结束')common封装
python
"""
对数据进行预处理
"""
import pandas as pd
def data_preprocessing(path):
"""
1.加载数据
2.时间格式转换
3.按时间升序排序
4.去重
:param path:
:return:
"""
# 1.加载数据
data = pd.read_csv(path)
# data.info()
# 时间格式转换
data['time'] = pd.to_datetime(data['time']).dt.strftime('%Y-%m-%d %H:%M:%S')
# 按时间升序排序
data.sort_values('time', ascending=True, inplace=True)
# 去重
data.drop_duplicates(inplace=True)
# print(data.head())
return data
if __name__ == '__main__':
data_preprocessing('../data/train.csv')train 模型训练
python
# -*- coding: utf-8 -*-
import os
import pandas as pd
import matplotlib.pyplot as plt
import datetime
from utils.log import Logger
from utils.common import data_preprocessing
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error, mean_absolute_error
import joblib
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['font.size'] = 15
def ana_data(data):
"""
1.查看数据整体情况
2.负荷整体的分布情况
3.各个小时的平均负荷趋势,看一下负荷在一天中的变化情况
4.各个月份的平均负荷趋势,看一下负荷在一年中的变化情况
5.工作日与周末的平均负荷情况,看一下工作日的负荷与周末的负荷是否有区别
:param data: 数据源
:return:
"""
data = data.copy(deep=True)
# 1.数据整体情况
print(data.info())
print(data.head())
fig = plt.figure(figsize=(20, 32))
# 2.负荷整体的分布情况
ax1 = fig.add_subplot(411)
ax1.hist(data['power_load'], bins=100)
ax1.set_title('负荷分布直方图')
# 3.各个小时的平均负荷趋势,看一下负荷在一天中的变化情况
ax2 = fig.add_subplot(412)
data['hour'] = data['time'].str[11:13]
data_hour_avg = data.groupby(by='hour', as_index=False)['power_load'].mean()
ax2.plot(data_hour_avg['hour'], data_hour_avg['power_load'], color='b', linewidth=2)
ax2.set_title('各小时的平均负荷趋势图')
ax2.set_xlabel('小时')
ax2.set_ylabel('负荷')
# 4.各个月份的平均负荷趋势,看一下负荷在一年中的变化情况
ax3 = fig.add_subplot(413)
data['month'] = data['time'].str[5:7]
data_month_avg = data.groupby('month', as_index=False)['power_load'].mean()
ax3.plot(data_month_avg['month'], data_month_avg['power_load'], color='r', linewidth=2)
ax3.set_title('各月份平均负荷')
ax3.set_xlabel('月份')
ax3.set_ylabel('平均负荷')
# 5.工作日与周末的平均负荷情况,看一下工作日的负荷与周末的负荷是否有区别
ax4 = fig.add_subplot(414)
data['week_day'] = data['time'].apply(lambda x: pd.to_datetime(x).weekday())
data['is_workday'] = data['week_day'].apply(lambda x: 1 if x <= 4 else 0)
power_load_workday_avg = data[data['is_workday'] == 1]['power_load'].mean()
power_load_holiday_avg = data[data['is_workday'] == 0]['power_load'].mean()
ax4.bar(x=['工作日平均负荷', '周末平均负荷'], height=[power_load_workday_avg, power_load_holiday_avg])
ax4.set_ylabel('平均负荷')
ax4.set_title('工作日与周末的平均负荷对比')
# plt.savefig('../data/fig/负荷分析图.png')
def feature_engineering(data, logger):
"""
对给定的数据源,进行特征工程处理,提取出关键的特征
1.提取出时间特征:月份、小时
2.提取出相近时间窗口中的负荷特征:step大小窗口的负荷
3.提取昨日同时刻负荷特征
4.剔除出现空值的样本
5.整理时间特征,并返回
:param data: 数据源
:param logger: 日志
:return:
"""
logger.info("===============开始进行特征工程处理===============")
result = data.copy(deep=True)
logger.info("===============开始提取时间特征===================")
# 1、提取出时间特征
# 1.1提取出对应的小时,用以表示短期的时间特征
result['hour'] = result['time'].str[11:13]
# 1.2提取出对应的月份,用以表示长期的时间特征
result['month'] = result['time'].str[5:7]
# 1.3 对时间特征进行one-hot编码
# 1.3.1对小时数进行one-hot编码
hour_encoding = pd.get_dummies(result['hour'])
hour_encoding.columns = ['hour_' + str(i) for i in hour_encoding.columns]
# 1.3.2对月份进行one-hot编码
month_encoding = pd.get_dummies(result['month'])
month_encoding.columns = ['month_' + str(i) for i in month_encoding.columns]
# 1.3.3 对one-hot编码后的结果进行拼接
result = pd.concat([result, hour_encoding, month_encoding], axis=1)
logger.info("==============开始提取相近时间窗口中的负荷特征====================")
# 2指定window_size下的相近时间窗口负荷
window_size = 3
shift_list = [result['power_load'].shift(i) for i in range(1, window_size + 1)]
shift_data = pd.concat(shift_list, axis=1)
shift_data.columns = ['前' + str(i) + '小时' for i in range(1, window_size + 1)]
result = pd.concat([result, shift_data], axis=1)
logger.info("============开始提取昨日同时刻负荷特征===========================")
# 3提取昨日同时刻负荷特征
# 3.1时间与负荷转为字典
time_load_dict = result.set_index('time')['power_load'].to_dict()
# 3.2计算昨日相同的时刻
result['yesterday_time'] = result['time'].apply(
lambda x: (pd.to_datetime(x) - pd.to_timedelta('1d')).strftime('%Y-%m-%d %H:%M:%S'))
# 3.3昨日相同的时刻的负荷
result['yesterday_load'] = result['yesterday_time'].apply(lambda x: time_load_dict.get(x))
# 4.剔除出现空值的样本
result.dropna(axis=0, inplace=True)
# 5.整理特征列,并返回
time_feature_names = list(hour_encoding.columns) + list(month_encoding.columns) + list(shift_data.columns) + [
'yesterday_load']
logger.info(f"特征列名是:{time_feature_names}")
return result, time_feature_names
def model_train(data, features, logger):
"""
1.数据集切分
2.网格化搜索与交叉验证
3.模型实例化
4.模型训练
5.模型评价
6.模型保存
:param data: 特征工程处理后的输入数据
:param features: 特征名称
:param logger: 日志对象
:return:
"""
logger.info("=========开始模型训练===================")
# 1.数据集切分
x_data = data[features]
y_data = data['power_load']
# x_train:训练集特征数据
# y_train:训练集目标数据
# x_test:测试集特征数据
# y_test:测试集目标数据
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3, random_state=22)
# # 2.网格化搜索与交叉验证
# # 2.1备选的超参数
# print("开始网格化搜索")
# print(datetime.datetime.now()) # 2024-11-26 15:38:26.898828
# param_dict = {
# 'n_estimators': [50, 100, 150, 200],
# 'max_depth': [3, 6, 9],
# 'learning_rate': [0.1, 0.01]
# }
# # 2.2实例化网格化搜索,配置交叉验证
# grid_cv = GridSearchCV(estimator=XGBRegressor(),
# param_grid=param_dict, cv=5)
# # 2.3网格化搜索与交叉验证训练
# grid_cv.fit(x_train, y_train)
# # 2.4输出最优的超参数组合
# print(grid_cv.best_params_) # {'learning_rate': 0.1, 'max_depth': 6, 'n_estimators': 150}
# print("结束网格化搜索")
# print(datetime.datetime.now()) # 2024-11-26 15:39:07.216048
# logger.info("网格化搜索后找到的最优的超参数组合是:learning_rate: 0.1, max_depth: 6, n_estimators: 150")
# 3.模型训练
xgb = XGBRegressor(n_estimators=150, max_depth=6, learning_rate=0.1)
xgb.fit(x_train, y_train)
# 4.模型评价
# 4.1模型在训练集上的预测结果
y_pred_train = xgb.predict(x_train)
# 4.2模型在测试集上的预测结果
y_pred_test = xgb.predict(x_test)
# 4.3模型在训练集上的MSE、MAPE
mse_train = mean_squared_error(y_true=y_train, y_pred=y_pred_train)
mae_train = mean_absolute_error(y_true=y_train, y_pred=y_pred_train)
print(f"模型在训练集上的均方误差:{mse_train}")
print(f"模型在训练集上的平均绝对误差:{mae_train}")
# 4.4模型在测试集上的MSE、MAPE
mse_test = mean_squared_error(y_true=y_test, y_pred=y_pred_test)
mae_test = mean_absolute_error(y_true=y_test, y_pred=y_pred_test)
print(f"模型在测试集上的均方误差:{mse_test}")
print(f"模型在测试集上的平均绝对误差:{mae_test}")
logger.info("=========================模型训练完成=============================")
logger.info(f"模型在训练集上的均方误差:{mse_train}")
logger.info(f"模型在训练集上的平均绝对误差:{mae_train}")
logger.info(f"模型在测试集上的均方误差:{mse_test}")
logger.info(f"模型在测试集上的平均绝对误差:{mae_test}")
# 5.模型保存
joblib.dump(xgb, '../model/xgb.pkl')
class PowerLoadModel(object):
def __init__(self, filename):
# 配置日志记录
logfile_name = "train_" + datetime.datetime.now().strftime('%Y%m%d%H%M%S')
self.logfile = Logger('../', logfile_name).get_logger()
# 获取数据源
self.data_source = data_preprocessing(filename)
if __name__ == '__main__':
# 1.加载数据集
input_file = os.path.join('../data', 'train.csv')
model = PowerLoadModel(input_file)
# 2.分析数据
ana_data(model.data_source)
# 3.特征工程
processed_data, feature_cols = feature_engineering(model.data_source, model.logfile)
# 4.模型训练、模型评价与模型保存
model_train(processed_data, feature_cols, model.logfile)predict模型预测
python
# -*- coding: utf-8 -*-
import os
import pandas as pd
import numpy as np
import datetime
from utils.log import Logger
from utils.common import data_preprocessing
from sklearn.metrics import mean_absolute_error
import matplotlib.ticker as mick
import joblib
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['font.size'] = 15
def pred_feature_extract(data_dict, time, logger):
"""
预测数据解析特征,保持与模型训练时的特征列名一致
1.解析时间特征
2.解析时间窗口特征
3.解析昨日同时刻特征
:param data_dict:历史数据,字典格式,key:时间,value:负荷
:param time:预测时间,字符串类型,格式为2024-12-20 09:00:00
:param logger:日志对象
:return:
"""
logger.info(f'=========解析预测时间为:{time}所对应的特征==============')
# 特征列清单
feature_names = ['hour_00', 'hour_01', 'hour_02', 'hour_03', 'hour_04', 'hour_05',
'hour_06', 'hour_07', 'hour_08', 'hour_09', 'hour_10', 'hour_11',
'hour_12', 'hour_13', 'hour_14', 'hour_15', 'hour_16', 'hour_17',
'hour_18', 'hour_19', 'hour_20', 'hour_21', 'hour_22', 'hour_23',
'month_01', 'month_02', 'month_03', 'month_04', 'month_05', 'month_06',
'month_07', 'month_08', 'month_09', 'month_10', 'month_11', 'month_12',
'前1小时', '前2小时', '前3小时', 'yesterday_load']
# 小时特征数据,使用列表保存起来
hour_part = []
pred_hour = time[11:13]
for i in range(24):
if pred_hour == feature_names[i][5:7]:
# if int(pred_hour) == i: # 这里我是这莫处理的
hour_part.append(1)
else:
hour_part.append(0)
# 月份特征数据,使用列表保存起来
month_part = []
pred_month = time[5:7]
for i in range(24, 36):
if pred_month == feature_names[i][6:8]:
# if int(pred_month) == i+1: # 这里我是这莫处理的
month_part.append(1)
else:
month_part.append(0)
# 历史负荷数据,使用列表保存起来
his_part = []
# 前1小时负荷
last_1h_time = (pd.to_datetime(time) - pd.to_timedelta('1h')).strftime('%Y-%m-%d %H:%M:%S')
last_1h_load = data_dict.get(last_1h_time, 600)
# 前2小时负荷
last_2h_time = (pd.to_datetime(time) - pd.to_timedelta('2h')).strftime('%Y-%m-%d %H:%M:%S')
last_2h_load = data_dict.get(last_2h_time, 600)
# 前3小时负荷
last_3h_time = (pd.to_datetime(time) - pd.to_timedelta('3h')).strftime('%Y-%m-%d %H:%M:%S')
last_3h_load = data_dict.get(last_3h_time, 600)
# 昨日同时刻负荷
last_day_time = (pd.to_datetime(time) - pd.to_timedelta('1d')).strftime('%Y-%m-%d %H:%M:%S')
last_day_load = data_dict.get(last_day_time, 600)
his_part = [last_1h_load, last_2h_load, last_3h_load, last_day_load]
# 特征数据,包含小时特征数据,月份特征数据,历史负荷数据
feature_list = [hour_part + month_part + his_part]
# feature_list需要转成dataframe并返回,所以这里用append变成一个二维列表
feature_df = pd.DataFrame(feature_list, columns=feature_names)
return feature_df, feature_names
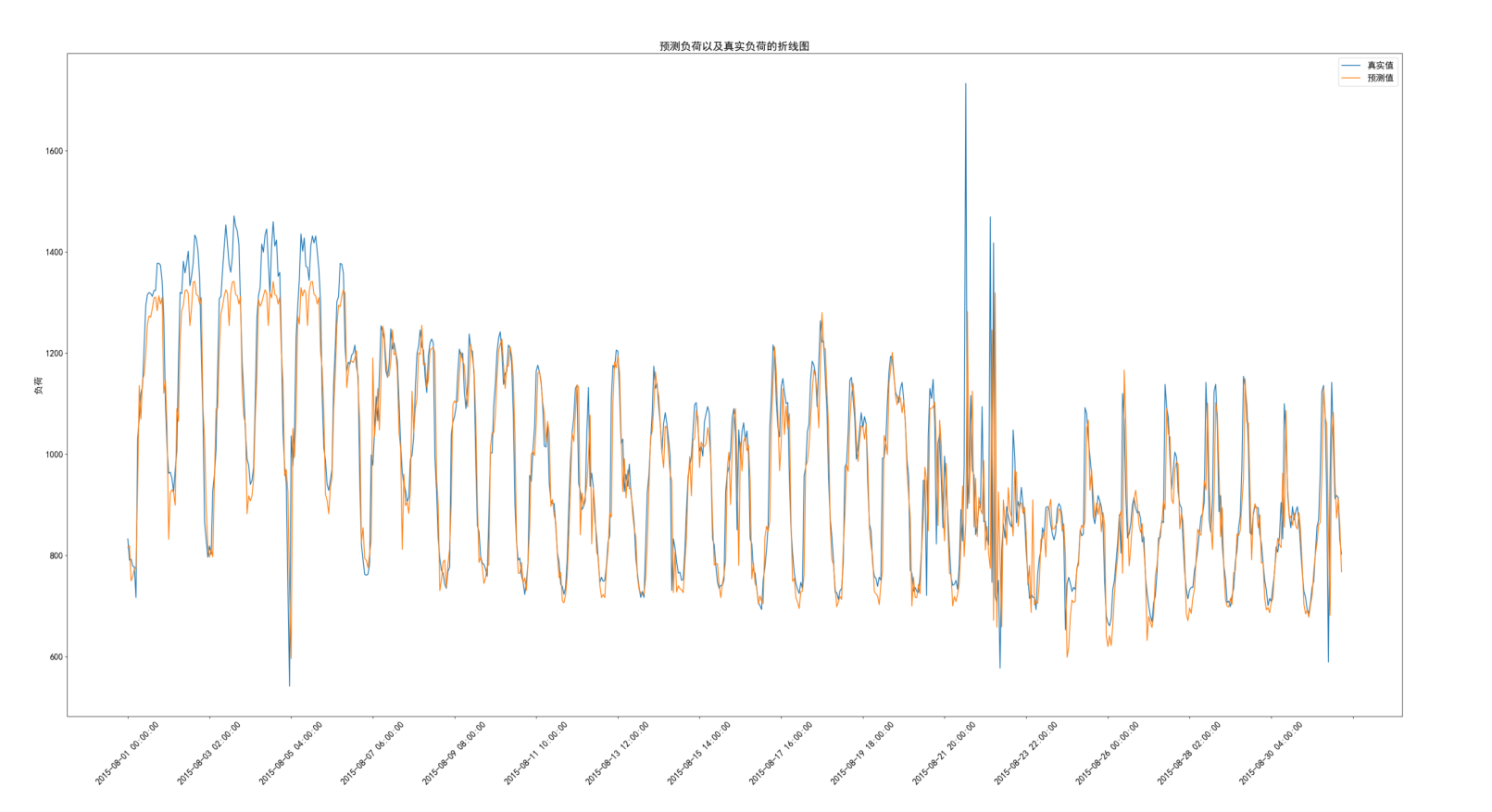
def prediction_plot(data):
"""
绘制时间与预测负荷折线图,时间与真实负荷折线图,展示预测效果
:param data: 数据一共有三列:时间、真实值、预测值
:return:
"""
# 绘制在新数据下
fig = plt.figure(figsize=(40, 20))
ax = fig.add_subplot()
# 绘制时间与真实负荷的折线图
ax.plot(data['时间'], data['真实值'], label='真实值')
# 绘制时间与预测负荷的折线图
ax.plot(data['时间'], data['预测值'], label='预测值')
ax.set_ylabel('负荷')
ax.set_title('预测负荷以及真实负荷的折线图')
# 横坐标时间若不处理太过密集,这里调大时间展示的间隔
ax.xaxis.set_major_locator(mick.MultipleLocator(50))
# 时间展示时旋转45度
plt.xticks(rotation=45)
plt.legend()
plt.savefig('../data/fig/预测效果.png')
class PowerLoadPredict(object):
def __init__(self, filename):
# 配置日志记录
logfile_name = "predict_" + datetime.datetime.now().strftime('%Y%m%d%H%M%S')
self.logfile = Logger('../', logfile_name).get_logger()
# 获取数据源
self.data_source = data_preprocessing(filename)
# 历史数据转为字典,key:时间,value:负荷,目的是为了避免频繁操作dataframe,提高效率。实际开发场景中可以使用redis进行缓存
self.data_dict = self.data_source.set_index('time')['power_load'].to_dict()
if __name__ == '__main__':
"""
模型预测
1.导包、配置绘图字体
2.定义电力负荷预测类,配置日志,获取数据源、历史数据转为字典(避免频繁操作dataframe,提高效率)
3.加载模型
4.模型预测
4.1 确定要预测的时间段(2015-08-01 00:00:00及以后的时间)
4.2 为了模拟实际场景的预测,把要预测的时间以及以后的负荷都掩盖掉,因此新建一个数据字典,只保存预测时间以前的数据字典
4.3 预测负荷
4.3.1 解析特征(定义解析特征方法)
4.3.2 利用加载的模型预测
4.4 保存预测时间对应的真实负荷
4.5 结果保存到evaluate_list,三个元素分别是预测时间、真实负荷、预测负荷,方便后续进行预测结果评价
4.6 循环结束后,evaluate_list转为DataFrame
5.预测结果评价
5.1 计算预测结果与真实结果的MAE
5.2 绘制折线图(预测时间-真实负荷折线图,预测时间-预测负荷折线图),查看预测效果
"""
# 2.定义电力负荷预测类(PowerLoadPredict),配置日志,获取数据源、历史数据转为字典(避免频繁操作dataframe,提高效率)
input_file = os.path.join('../data', 'test.csv')
pred_obj = PowerLoadPredict(input_file)
# 3.加载模型
model = joblib.load('../model/xgb.pkl')
# 4.模型预测
evaluate_list = []
# 4.1确定要预测的时间段:2015-08-01 00:00:00及以后的时间
pred_times = pred_obj.data_source[pred_obj.data_source['time'] >= '2015-08-01 00:00:00']['time']
for pred_time in pred_times:
print(f"开始预测时间为:{pred_time}的负荷")
pred_obj.logfile.info(f"开始预测时间为:{pred_time}的负荷")
# 4.2为了模拟实际场景的预测,把要预测的时间以及以后的负荷都掩盖掉,因此新建一个数据字典,只保存预测时间以前的数据字典
data_his_dict = {k: v for k, v in pred_obj.data_dict.items() if k < pred_time}
# 4.3预测负荷
# 4.3.1解析特征
processed_data, feature_cols = pred_feature_extract(data_his_dict, pred_time, pred_obj.logfile)
# 4.3.2 模型预测
pred_value = model.predict(processed_data[feature_cols])
# 4.4真实负荷
true_value = pred_obj.data_dict.get(pred_time)
pred_obj.logfile.info(f"真实负荷为:{true_value}, 预测负荷为:{pred_value}")
# 4.5结果保存到evaluate_list,三个元素分别是预测时间、真实负荷、预测负荷
evaluate_list.append([pred_time, true_value, pred_value[0]])
# 4.6evaluate_list转为DataFrame
evaluate_df = pd.DataFrame(evaluate_list, columns=['时间', '真实值', '预测值'])
# 5.预测结果评价
# 5.1计算预测结果与真实结果的MAE
mae_score = mean_absolute_error(evaluate_df['真实值'], evaluate_df['预测值'])
print(f"模型对新数据进行预测的平均绝对误差:{mae_score}")
pred_obj.logfile.info(f"模型对新数据进行预测的平均绝对误差:{mae_score}")
# 5.2绘制折线图,查看预测效果
prediction_plot(evaluate_df)最终预测效果图
模型预测改进方向
特征工程角度
优化时间窗口 提取更有效的历史负荷特征
扩展外部特征,比如温度、湿度、风速、历史工业用电量、历史居民用电量等
算法角度
样本分群然后分别建模,比如分地区或者借助聚类算法先进行分群,然后针对不同分区分别训练模型,提升模型的适用性
寻找更优的算法,比如LightGBM、RNN类、iTransformer等算法 寻找更优的算法组合,比如bagging方式或stacking方式进行模型组合
预测(推理)速度角度
预测时也需要特征工程处理,历史负荷可以缓存到redis,使用时直接查询 扩展性角度 扩展通用的工具包,适用于各种数据源的输入输出,如mysql、pgsql、oracle、ES、redis、Hive等数据库的支持 项目打包成容器,适配各种服务器环境 预测模块与项目解耦,预测模块封装出接口,接收web传过来的参数,根据参数获取数据并进行预测
tips:
个人觉得这个项目具有不一样的意义,充分体现了数据挖掘 的价值和多样性\复杂性
同时也给与了我们数据提取的方向和思路,愿在数据挖掘的路上我们都不孤独!!!
顺便给大家安利一个不错的数据网站:
