多模态大模型学习笔记(十六)------Transformer 学习之 Decoder Only
0. 前言
Decoder Only(仅解码器)是当前 GPT、LLaMA、Qwen 等生成式大模型 的主流底层架构,也是 GPT-4V、Qwen-VL 等多模态大模型的核心底座。
相较于传统的 Encoder-Decoder 架构(如 T5),Decoder Only 去掉了 Encoder 模块和 Cross-Attention 层,仅保留带掩码的自注意力层(Masked Self-Attention),通过自回归生成机制 完成文本生成、多模态内容生成等任务,是大模型落地最广泛的架构形态。

1. Decoder Only 核心定位
Transformer 三大主流架构对比:
| 架构类型 | 代表模型 | 核心特点 | 适用场景 |
|---|---|---|---|
| Encoder Only | BERT、RoBERTa | 无掩码自注意力,擅长理解 | 文本分类、命名实体识别 |
| Encoder-Decoder | T5、BART | 编码器+解码器+交叉注意力 | 机器翻译、文本摘要 |
| Decoder Only | GPT、LLaMA | 掩码自注意力+自回归生成 | 对话、创作、多模态生成 |
Decoder Only 成为生成式大模型主流的核心原因:
- 架构极简:无 Encoder、无 Cross-Attention,工程实现和部署成本低;
- 能力统一:同一架构同时支持"理解"和"生成",无需拆分模块;
- 拓展灵活:多模态适配仅需统一 Embedding 维度,无需修改核心逻辑。
2. Decoder Only 整体架构
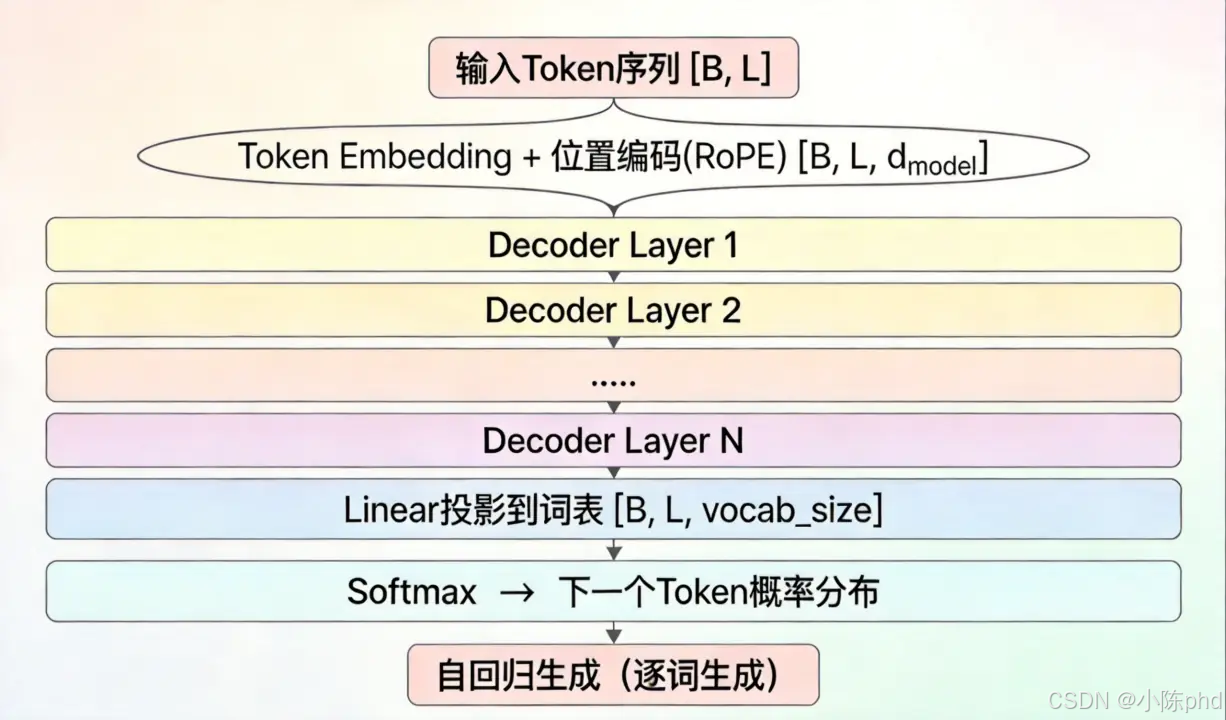
2.1 架构流程解析
- 输入层 :将离散的 Token 索引序列(维度
[B, L],B=批次大小、L=序列长度)转换为连续的 Token Embedding,并注入位置编码(主流用 RoPE 旋转位置编码),输出维度[B, L, d_model]; - 解码器堆叠层:将 N 层 Decoder Layer 堆叠(LLaMA-7B 为 32 层,GPT-3 为 96 层),逐层捕捉上下文语义依赖;
- 输出层 :通过 Linear 层将模型隐向量映射到词表空间(维度
[B, L, vocab_size]),经 Softmax 生成下一个 Token 的概率分布; - 生成层 :基于概率分布自回归逐词生成,直到输出结束符
<eos>或达到最大长度。
2.2 核心特点
- 仅保留 Decoder 模块,无 Encoder 模块;
- 仅使用 Masked Self-Attention,无 Cross-Attention;
- 天然支持自回归生成,符合人类语言生成习惯。
3. 单层 Decoder 结构(Pre-LN 范式)
现代大模型统一采用 Pre-LN(LayerNorm 前置) 设计(相较于原始 Transformer 的 Post-LN,Pre-LN 训练更稳定、收敛更快),结构如下:

3.1 结构流程
输入 x_{l-1} → LayerNorm 1 → Masked Multi-Head Attention → 残差连接 → LayerNorm 2 → FFN 前馈网络 → 残差连接 → LayerNorm 3 → 输出 x_l
3.2 关键组件作用
| 组件 | 核心作用 |
|---|---|
| LayerNorm | 归一化隐向量分布,稳定训练过程,Pre-LN 设计大幅降低训练难度 |
| Masked Self-Attention | 仅允许当前 Token 关注前文 Token,保证自回归生成的逻辑合理性 |
| 残差连接 | 缓解深层模型的梯度消失问题,保证信息在多层传递中不丢失 |
| FFN 前馈网络 | 对每个 Token 做非线性变换,捕捉复杂语义特征(主流用 GELU 激活函数) |
4. Masked Self-Attention:Decoder Only 的核心
Decoder Only 的核心是下三角掩码 ,其作用是:生成第 i 个 Token 时,仅能关注前 i-1 个 Token,绝对看不到后续 Token,保证自回归生成的逻辑闭环。
4.1 下三角掩码矩阵(L=5)

图例说明:
- 行:当前生成的 Token 位置
i; - 列:可关注的 Token 位置
j; ✓:可关注(掩码值为 0),-:不可关注(掩码值为-∞,Softmax 后权重趋近于 0)。
4.2 数学公式与参数解释
注意力计算核心公式
Attention(Q,K,V)=Softmax(QKTdk+M)V \text{Attention}(Q,K,V) = \text{Softmax}\left( \frac{QK^T}{\sqrt{d_k}} + M \right) V Attention(Q,K,V)=Softmax(dk QKT+M)V
掩码矩阵定义
Mi,j={0,j≤i(可关注)−∞,j>i(不可关注) M_{i,j} = \begin{cases} 0, & j \le i \quad \text{(可关注)} \\ -\infty, & j > i \quad \text{(不可关注)} \end{cases} Mi,j={0,−∞,j≤i(可关注)j>i(不可关注)
参数解释
Q/K/V:查询/键/值矩阵,维度均为[B, n_heads, L, d_k];d_k:单个注意力头的维度(d_k = d_model / n_heads);√d_k:缩放因子,避免高维向量点积结果过大;M:下三角掩码矩阵,维度[L, L]。
5. 自回归生成流程
Decoder Only 的生成逻辑是"逐词生成、循环拼接",是所有大模型对话、写作、代码生成的核心范式:
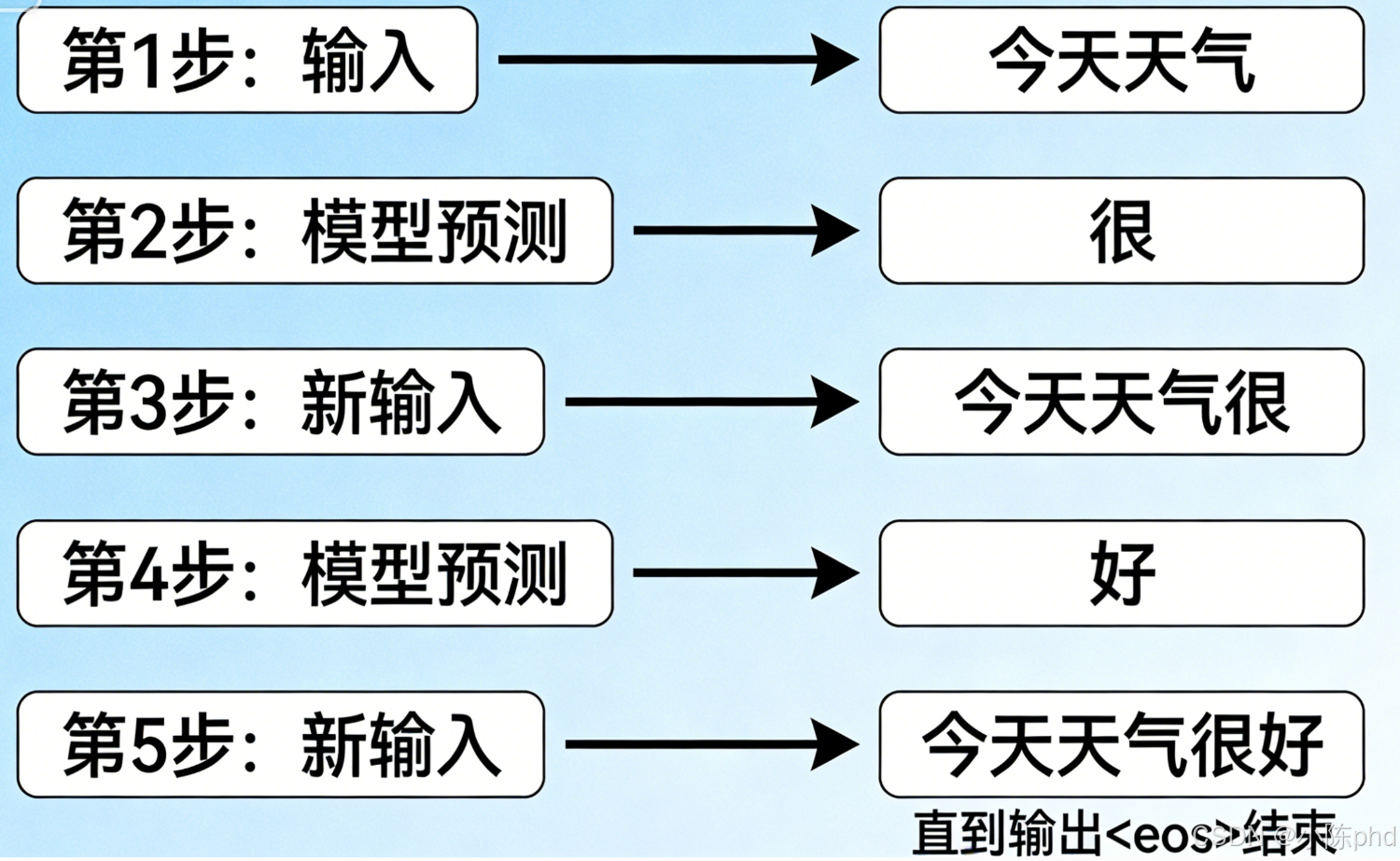
5.1 核心规则
- 每轮仅预测当前输入序列的最后一个 Token;
- 新生成的 Token 拼接到输入序列末尾,作为下一轮输入;
- 终止条件:输出
<eos>结束符,或达到预设的最大序列长度。
5.2 流程示例
输入:今天天气 → 预测:很 → 新输入:今天天气很 → 预测:好 → 新输入:今天天气很好 → ... → 输出 <eos> 终止。
6. 工业级优化:KV Cache 推理加速
原生自回归生成的时间复杂度为 O(L2)O(L^2)O(L2)(L 为序列长度),长序列生成效率极低。KV Cache(Key-Value 缓存)是 Decoder Only 推理加速的核心优化,可将生成效率提升 10~100 倍。
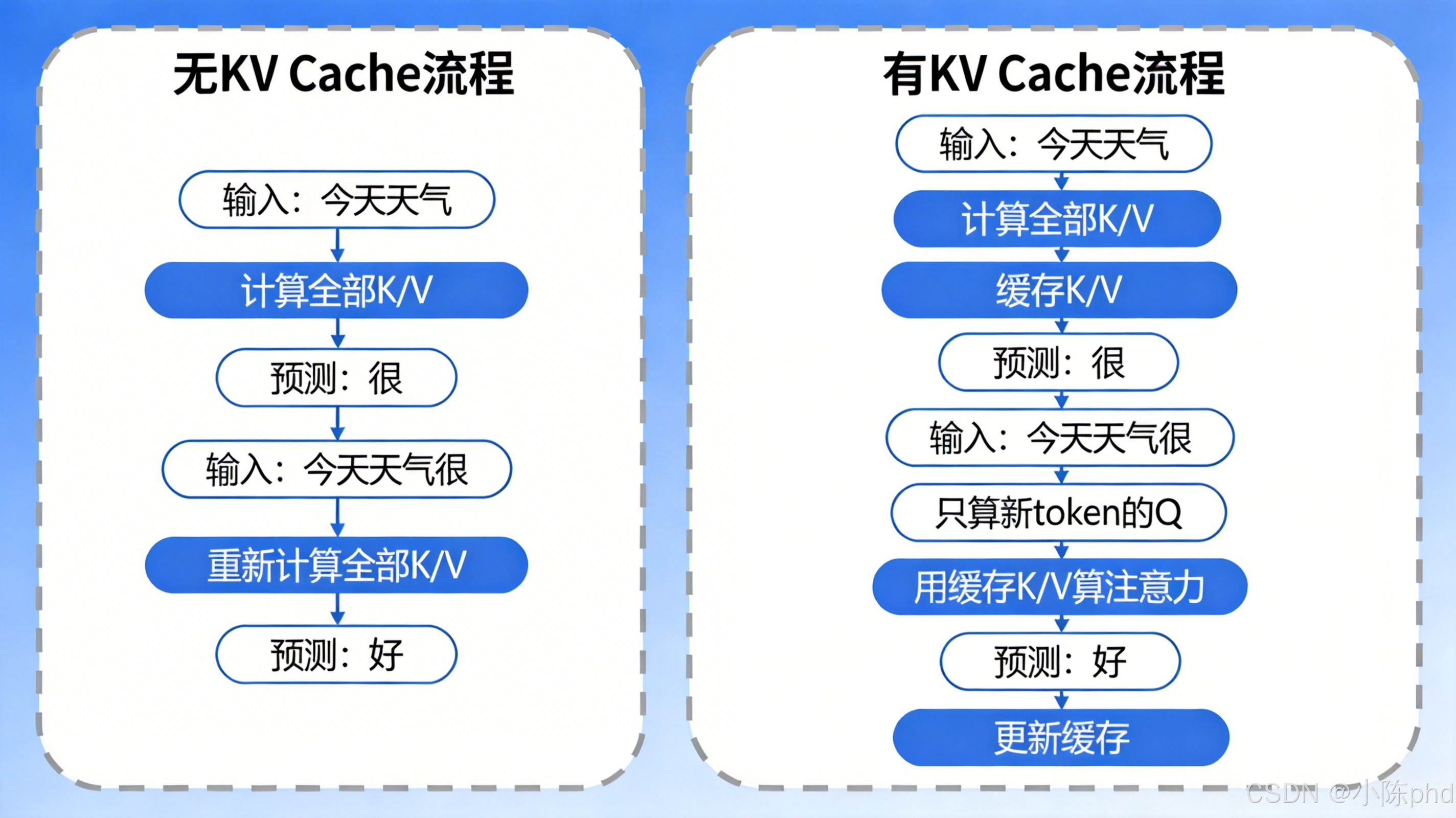
6.1 核心优化逻辑
| 无 KV Cache(低效) | 有 KV Cache(高效) |
|---|---|
| 每轮重新计算所有 Token 的 K/V 矩阵 | 仅计算新 Token 的 Q 矩阵,复用缓存的历史 K/V 矩阵 |
| 时间复杂度 O(L2)O(L^2)O(L2) | 时间复杂度降至 O(L)O(L)O(L) |
6.2 一句话总结
KV Cache 缓存已生成 Token 的 K/V 矩阵,每轮仅计算新 Token 的 Q 矩阵,与缓存的 K/V 计算注意力,不再重复计算前文的 K/V,大幅降低计算量。
7. 多模态拓展:Decoder Only 的无缝适配
GPT-4V、Qwen-VL 等多模态大模型的核心逻辑是:将图像/音频等模态的 Embedding 与文本 Embedding 统一维度后,拼接为输入序列,直接送入 Decoder Only 模型。
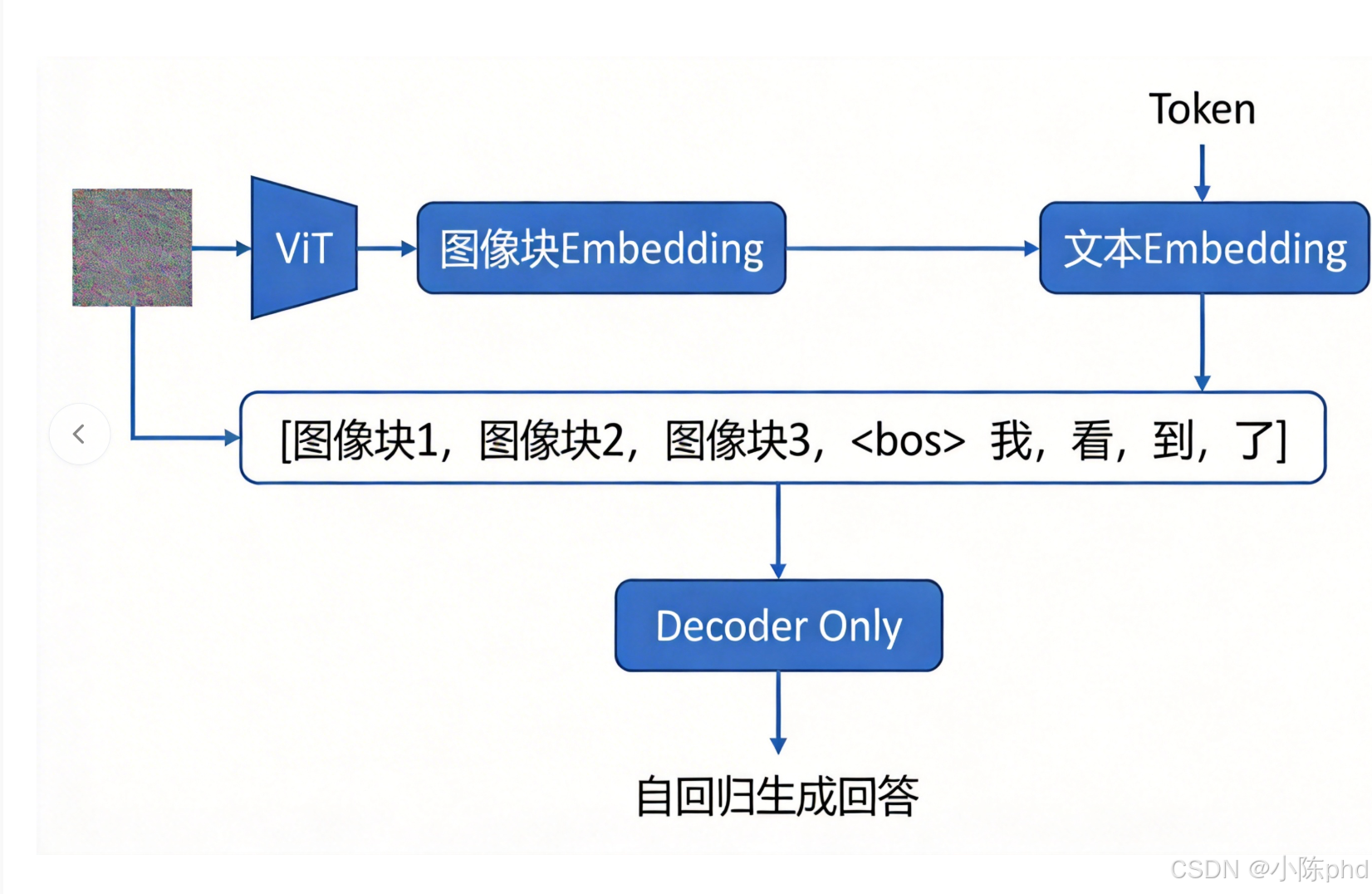
7.1 核心适配逻辑
- 图像模态:通过 ViT(视觉Transformer)将图像转换为图像块 Embedding(维度与文本 Embedding 一致,如
d_model=4096); - 文本模态:通过 Tokenizer 转换为文本 Embedding;
- 序列拼接:
[图像块1, 图像块2, ..., <bos>, 文本Token1, 文本Token2, ...]; - 生成:送入 Decoder Only 模型,自回归生成多模态相关文本。
7.2 核心前提
所有模态的 Embedding 维度必须与 Decoder Only 模型的 d_model 一致,保证输入序列的维度统一。
8. 完整 PyTorch 实现(带关键注释)
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class MaskedMultiHeadAttention(nn.Module):
"""掩码多头注意力层(Decoder Only 核心组件)"""
def __init__(self, d_model, n_heads):
super().__init__()
self.n_heads = n_heads # 注意力头数
self.d_head = d_model // n_heads # 单个注意力头的维度
self.qkv = nn.Linear(d_model, d_model*3) # 合并QKV投影,提升效率
self.out = nn.Linear(d_model, d_model) # 注意力输出投影
def forward(self, x):
B, L, D = x.shape # B=批次大小, L=序列长度, D=d_model
# 1. QKV投影与维度变换:[B,L,3D] → [3,B,n_heads,L,d_head]
qkv = self.qkv(x).reshape(B, L, 3, self.n_heads, self.d_head).permute(2,0,3,1,4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 2. 生成下三角掩码:遮挡未来Token
mask = torch.triu(torch.ones(L, L), diagonal=1).bool().to(x.device)
# 3. 缩放点积注意力计算 + 掩码
attn_scores = (q @ k.transpose(-2,-1)) / (self.d_head ** 0.5) # 缩放避免数值过大
attn_scores = attn_scores.masked_fill(mask, -1e9) # 掩码未来Token
attn_weights = F.softmax(attn_scores, dim=-1) # 注意力权重归一化
# 4. 注意力加权求和 + 输出投影
attn_out = (attn_weights @ v).transpose(1,2).reshape(B,L,D) # 合并注意力头
return self.out(attn_out)
class DecoderLayer(nn.Module):
"""单层Decoder(Pre-LN 范式)"""
def __init__(self, d_model, n_heads, d_ff):
super().__init__()
self.norm1 = nn.LayerNorm(d_model) # 注意力层前置归一化
self.masked_attn = MaskedMultiHeadAttention(d_model, n_heads)
self.norm2 = nn.LayerNorm(d_model) # FFN层前置归一化
# FFN前馈网络(GELU为大模型主流激活函数)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Linear(d_ff, d_model)
)
self.norm3 = nn.LayerNorm(d_model) # 最终归一化
def forward(self, x):
# 注意力分支:LayerNorm → MaskedAttn → 残差连接
x = x + self.masked_attn(self.norm1(x))
# FFN分支:LayerNorm → FFN → 残差连接
x = x + self.ffn(self.norm2(x))
return self.norm3(x)
class DecoderOnly(nn.Module):
"""完整的Decoder Only模型"""
def __init__(self, vocab_size, d_model=512, n_heads=8, n_layers=6, d_ff=2048):
super().__init__()
self.emb = nn.Embedding(vocab_size, d_model) # Token嵌入层
# 堆叠多层Decoder
self.layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff) for _ in range(n_layers)])
self.out = nn.Linear(d_model, vocab_size) # 输出映射到词表
def forward(self, x):
x = self.emb(x) # Token序列 → Embedding
for layer in self.layers:
x = layer(x) # 逐层计算
return self.out(x) # 输出词表概率分布
# 测试代码
if __name__ == "__main__":
# 初始化模型(小型演示配置)
model = DecoderOnly(vocab_size=10000)
# 模拟输入:批次大小=2,序列长度=10
x = torch.randint(0, 10000, (2, 10))
# 前向计算
logits = model(x)
print("输出形状:", logits.shape) # 输出:[2, 10, 10000](B, L, vocab_size)9. 总结与落地建议
9.1 核心总结
- Decoder Only 是生成式大模型的主流架构,核心为"掩码自注意力 + 自回归生成";
- 下三角掩码是自回归生成的核心保障,保证仅能关注前文 Token;
- KV Cache 是工业级推理的必备优化,大幅提升长序列生成效率;
- 多模态适配仅需统一 Embedding 维度,无需修改 Decoder Only 核心逻辑。