目录规划
为了将这所有博客里的知识点逻辑顺畅地串联起来,特此设计了以下目录结构。这个顺序遵循了"概念引入 -> 基础回归 -> 分类进阶 -> 无监督学习"的学习路径:
- 第一章:启蒙篇------人工智能与机器学习的宏观版图
- 来源博客:人工智能和机器学习
- 核心内容:AI、ML、DL的关系,机器学习的分类(监督/无监督/强化),基本工作流程。
- 第二章:基石篇------预测连续值的线性回归
- 来源博客:线性回归
- 核心内容:一元/多元线性回归,损失函数,梯度下降,代码实战。
- 第三章:进阶篇------解决分类问题的逻辑回归
- 来源博客:逻辑回归
- 核心内容:从回归到分类的跨越,Sigmoid函数,决策边界,代码实战。
- 第四章:直觉篇------基于距离的K-近邻 (KNN)
- 来源博客:KNN算法
- 核心内容:KNN原理,K值选择,距离计算,优缺点分析,代码实战。
- 第五章:探索篇------发现数据内在结构的聚类算法
- 来源博客:聚类算法
- 核心内容:K-Means原理,簇的概念,与分类的区别,应用场景。
- 第六章:总结与展望
- 综合对比五大算法,如何选择适合的模型。
文章目录
- 目录规划
- 第二章:基石篇------预测连续值的线性回归
-
- [2.1 什么是线性回归?](#2.1 什么是线性回归?)
- [2.2 核心问题:如何找到"最好"的直线?](#2.2 核心问题:如何找到“最好”的直线?)
-
- [1. 损失函数 (Loss Function)](#1. 损失函数 (Loss Function))
- [2. 求解方法:梯度下降 (Gradient Descent)](#2. 求解方法:梯度下降 (Gradient Descent))
- [2.3 代码实战:从零实现线性回归逻辑](#2.3 代码实战:从零实现线性回归逻辑)
- [2.4 评估模型的好坏](#2.4 评估模型的好坏)
- [2.5 线性回归的局限性与应对](#2.5 线性回归的局限性与应对)
- [2.6 本章小结](#2.6 本章小结)
第二章:基石篇------预测连续值的线性回归
导读 :在机器学习的浩瀚星空中,线性回归 (Linear Regression) 是最亮的那颗启明星。它不仅是统计学中的经典方法,更是理解机器学习"损失函数"和"梯度下降"等核心概念的基石。本章带你深入理解如何通过一条直线来预测未来。
2.1 什么是线性回归?
简单来说,线性回归就是试图找到 之间的线性关系。
之间的线性关系。
- 应用场景 :预测连续数值 。
- 根据房屋面积预测房价。
- 根据广告投入预测销售额。
- 根据气温预测冰淇淋销量。
核心公式
对于只有一个特征的情况(一元线性回归),模型的形式就是我们在初中数学学过的一次函数:

2.2 核心问题:如何找到"最好"的直线?
面对散落在坐标系中的数据点,世界上有无数条直线可以穿过它们。哪一条才是最好的?
标准答案 :让所有数据点到这条直线的误差之和最小的那条线。
1. 损失函数 (Loss Function)
为了量化"误差",我们引入损失函数 。在线性回归中,最常用的是均方误差 (MSE, Mean Squared Error)。

- 为什么要平方?
- 消除正负误差的抵消(防止正误差和负误差相加变成0,掩盖了真实误差)。
- 放大较大误差的影响:如果某个点偏离直线很远,平方后误差会变得非常大,迫使模型优先修正这些大偏差。
我们的目标就是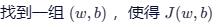 最小。
最小。
2. 求解方法:梯度下降 (Gradient Descent)
怎么找到让损失函数最小的 呢?这就好比你在云雾缭绕的山顶(高损失区),想要走到山谷最低点(最小损失区),但你看不到路。
呢?这就好比你在云雾缭绕的山顶(高损失区),想要走到山谷最低点(最小损失区),但你看不到路。
梯度下降的策略:
- 试探:感受脚下哪个方向坡度最陡(计算梯度的导数)。
- 迈步:沿着最陡的下坡方向走一步。
- 重复:不断重复上述过程,直到走到谷底(收敛)。
数学更新公式 :
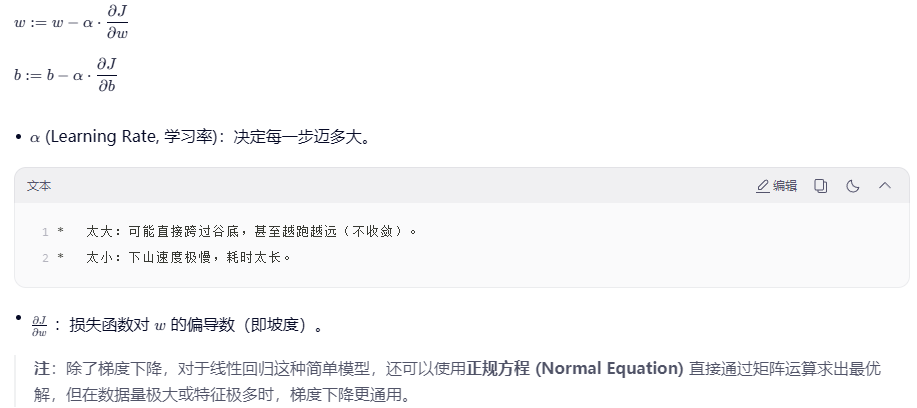
注 :除了梯度下降,对于线性回归这种简单模型,还可以使用正规方程 (Normal Equation) 直接通过矩阵运算求出最优解,但在数据量极大或特征极多时,梯度下降更通用。
2.3 代码实战:从零实现线性回归逻辑
为了让大家透彻理解,我们不仅调用库,还手动模拟一下"梯度下降"的核心逻辑,看看模型是如何一步步逼近真相的。
python
import numpy as np
import matplotlib.pyplot as plt
# 1. 准备数据
# 假设真实规律是 y = 3x + 2,加上一点噪音
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 2 + 3 * X + np.random.randn(100, 1)
# 2. 初始化参数
w = 0.0 # 初始斜率猜为0
b = 0.0 # 初始截距猜为0
learning_rate = 0.1 # 学习率
iterations = 100 # 迭代次数
# 3. 梯度下降过程
loss_history = []
for i in range(iterations):
# A. 预测
y_pred = w * X + b
# B. 计算误差 (残差)
error = y_pred - y
# C. 计算梯度 (导数)
# MSE对w的导数: (2/m) * sum(error * x)
# MSE对b的导数: (2/m) * sum(error)
dw = (2 / len(X)) * np.sum(error * X)
db = (2 / len(X)) * np.sum(error)
# D. 更新参数 (向反方向走)
w = w - learning_rate * dw
b = b - learning_rate * db
# 记录当前的损失值,用于观察收敛情况
loss = np.mean(error ** 2)
loss_history.append(loss)
print(f"训练结束!")
print(f"学到的权重 w: {w:.4f} (真实值应为 3.0)")
print(f"学到的偏置 b: {b:.4f} (真实值应为 2.0)")
# 4. 可视化结果
plt.figure(figsize=(12, 5))
# 图1:数据拟合效果
plt.subplot(1, 2, 1)
plt.scatter(X, y, alpha=0.5, label='原始数据')
plt.plot(X, w * X + b, 'r-', linewidth=2, label=f'拟合直线 (y={w:.2f}x+{b:.2f})')
plt.title('线性回归拟合效果')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
# 图2:损失函数下降曲线
plt.subplot(1, 2, 2)
plt.plot(loss_history)
plt.title('损失函数 (MSE) 下降过程')
plt.xlabel('迭代次数')
plt.ylabel('Loss')
plt.grid(True)
plt.tight_layout()
plt.show()代码解析:
- 我们并没有直接使用
sklearn,而是手动写了for循环来模拟学习过程。 - 在每次循环中,我们计算当前直线的误差,算出梯度,然后微调
 。
。 - 运行结果你会发现,经过100次迭代,
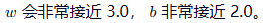 这就是机器"学习"的过程。
这就是机器"学习"的过程。
2.4 评估模型的好坏
训练好模型后,怎么知道它准不准?常用的指标有:
-
MSE (均方误差):即损失函数的值。越小越好,但对异常值敏感。
-
RMSE (均方根误差) :MSE 开根号。量纲与
 一致,更容易解释(例如:预测房价误差平均是 5 万元)。
一致,更容易解释(例如:预测房价误差平均是 5 万元)。 -

2.5 线性回归的局限性与应对
虽然线性回归很强大,但它也有明显的短板:

2.6 本章小结
- 线性回归 是解决回归问题(预测数值)的首选基准模型。
- 核心在于定义损失函数 (MSE) 并使用梯度下降来最小化它。
- 通过代码我们看到了参数
 是如何通过迭代一步步逼近真实值的。
是如何通过迭代一步步逼近真实值的。 - 它简单、可解释性强,但受限于线性假设,处理复杂非线性数据时需要特征工程辅助。
线性回归教会了我们"拟合"的概念。但是,现实世界中很多问题不是预测数值,而是做选择(是/否,猫/狗)。这时候,线性回归就不够用了,我们需要它的变体------逻辑回归。
下一章预告:《第三章:进阶篇------解决分类问题的逻辑回归》,我们将揭开如何用回归的思想来解决分类难题,并引入神奇的 Sigmoid 函数。