一、引言
分治法是算法设计领域的核心策略之一,其核心思想是将复杂问题分解为规模更小的同类子问题,通过求解子问题并合并结果得到原问题的解,是归并排序、快速排序、二分查找等众多高效算法的理论基础。在软考软件设计师考试中,分治法属于数据结构与算法模块的高频考点,选择题中每年固定考查 1-2 题 ,案例分析中常结合排序、查找等场景考查算法设计与复杂度分析,分值占比约 3%-5%。
本文将系统讲解递归的核心要素、分治法的核心思想与实现步骤、典型算法实例,以及考试中的常见考点与答题技巧,帮助考生全面掌握分治法的理论与应用。
二、递归:分治法的实现基石
分治法 的实现高度依赖递归机制 ,递归是指函数在执行过程中直接或间接调用自身的程序设计方法,是将大问题分解为同类小问题的核心实现手段。
2.1 递归的两大核心要素
递归算法的设计必须满足两个必要条件,缺一不可:
递归出口(边界条件)
定义递归调用的终止场景,当问题规模缩小到满足边界条件时,直接返回确定结果,避免无限递归导致的栈溢出错误。边界条件的定义必须明确且可到达,例如阶乘计算中 n=0 时返回 1,斐波那契数列计算中 n=0 返回 0、n=1 返回 1,均属于典型的递归出口。
递归体(递推关系式)
描述原问题与子问题的关联关系,将原问题转化为一个或多个规模更小的同类子问题,通过调用自身求解子问题后,组合得到原问题的解。递归体的设计必须保证问题规模逐次缩小,且子问题与原问题的求解逻辑完全一致,例如阶乘的递推关系式为 n! = n × (n-1)!,每次调用时参数 n 减 1,确保最终会到达 n=0 的边界条件。
2.2 递归的执行机制与复杂度分析
递归算法的执行过程分为 "递推" 和 "回溯" 两个阶段:递推阶段从原问题出发,按照递归体逐次调用自身,直到触发递归出口;回溯阶段从边界条件的返回值开始,逐层向上计算并返回上层调用的结果,最终得到原问题的解。
递归算法的时间复杂度通过递推关系式求解,常见的求解方法包括代入法、递归树法和主定理法;空间复杂度主要由递归调用栈的深度决定,等于递归的最大层数。需要注意的是,递归实现通常会带来额外的栈空间开销,对于大规模问题可能需要转换为迭代实现以避免栈溢出。
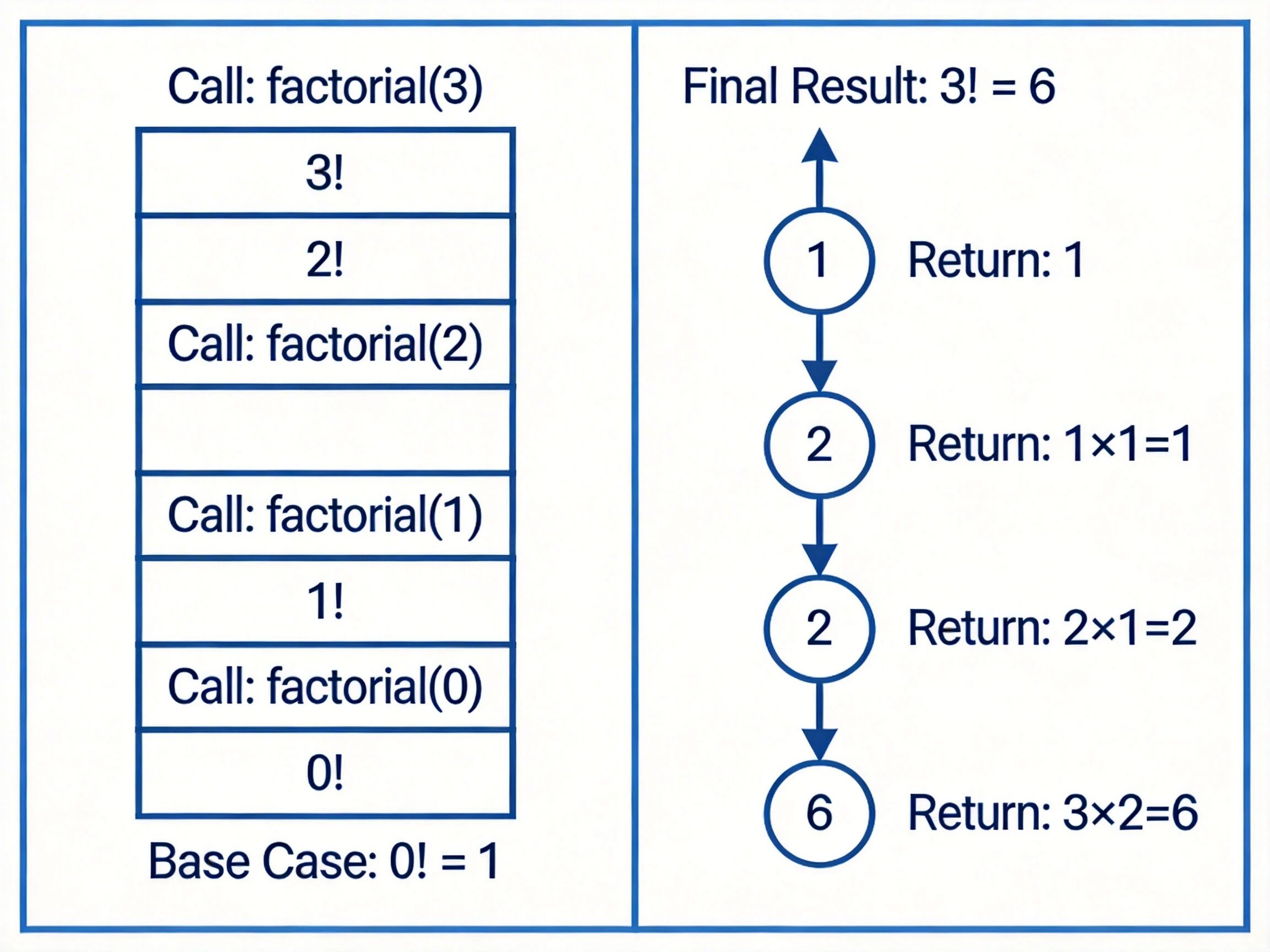
递归执行过程示意图,以阶乘计算为例,左侧展示递推阶段调用栈的变化,右侧展示回溯阶段结果计算过程
三、分治法的核心思想与设计步骤
分治法的核心逻辑是 "化整为零,逐个击破",通过将复杂大问题分解为多个可独立求解的小问题,降低问题求解的难度,同时通过子问题的并行求解提升算法效率。
3.1 分治法的适用条件
应用分治法求解的问题必须满足以下四个条件:
问题可分解性:原问题可以分解为若干个规模较小、与原问题形式相同的子问题,即子问题与原问题的求解逻辑一致,仅输入规模存在差异。
子问题独立性:分解得到的子问题之间相互独立,不存在公共子问题,子问题的求解不会互相影响。这是分治法与动态规划的核心区别,动态规划适用于子问题存在重叠的场景,而分治法要求子问题完全独立。
边界可解性:当子问题的规模缩小到一定程度时,可以直接求解,不需要继续分解,对应递归算法的出口条件。
解可合并性:子问题的解可以通过明确的规则合并为原问题的解,合并步骤的复杂度是决定分治法整体效率的关键因素。
3.2 分治法的三大核心步骤
分治法的实现严格遵循 "分解 - 求解 - 合并" 的三步流程:
分解:将原问题按照统一规则分解为若干个规模大致相等的子问题,分解的粒度需要平衡子问题求解成本与合并成本,通常分解为 2 个规模相等的子问题(如二分查找、归并排序),少数场景下分解为更多子问题(如斯特拉森矩阵乘法分解为 7 个子问题)。
求解:判断子问题规模是否足够小,若满足边界条件则直接求解;否则递归地对每个子问题应用分治策略,继续分解求解。
合并:将所有子问题的解按照问题的逻辑规则进行合并,得到原问题的最终解。合并步骤的设计是分治法的核心难点,合并的时间复杂度直接影响算法的整体效率。
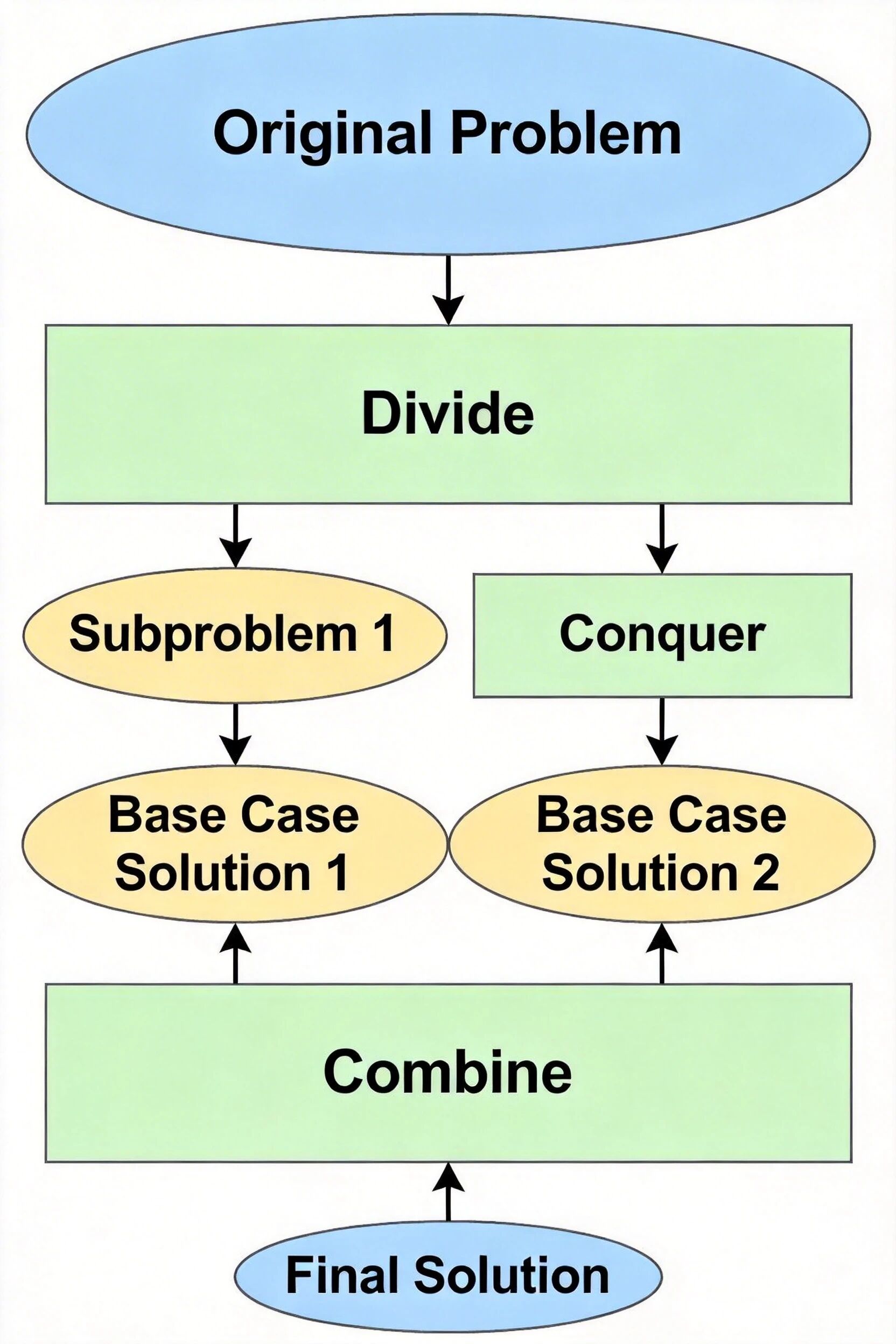
分治法执行流程图,展示原问题分解为多层子问题、子问题求解、结果逐层合并的完整过程
3.3 分治法的复杂度分析
分治法的时间复杂度通常通过主定理(Master Theorem)求解,对于递推关系式 T (n) = aT (n/b) + f (n),其中 a≥1、b>1 为常数,f (n) 为分解与合并步骤的时间复杂度:
若 f (n) = O (n^log_b a - ε)(ε>0),则 T (n) = Θ(n^log_b a)
若 f (n) = Θ(n^log_b a),则 T (n) = Θ(n^log_b a × log n)
若 f (n) = Ω(n^log_b a + ε)(ε>0),且对足够大的 n 满足 a×f (n/b) ≤ c×f (n)(c<1),则 T (n) = Θ(f (n))
例如归并排序的递推关系式为 T (n) = 2T (n/2) + O (n),其中 a=2、b=2、log_b a=1,f (n)=O (n) 符合第二种情况,因此时间复杂度为 Θ(n log n)。
四、分治法典型实例剖析
分治法在排序、查找、数值计算等领域有广泛应用,以下两个实例是软考考试的高频考点。
4.1 归并排序
归并排序是分治法在排序领域的典型应用,适用于大规模数据的排序场景,是稳定的排序算法。
分治实现逻辑
分解:将待排序序列从中间位置拆分为两个长度大致相等的子序列,当子序列长度为 1 时停止分解(长度为 1 的序列天然有序,为递归出口)。
求解:递归地对左右两个子序列执行归并排序。
合并:采用双指针法将两个有序子序列合并为一个有序序列,合并时依次比较两个子序列的当前头部元素,将较小的元素放入结果序列,直到所有元素合并完成。
算法特性
时间复杂度为 O (n log₂n),最好、最坏、平均情况复杂度一致,不受输入数据分布影响;空间复杂度为 O (n),需要额外的辅助空间存储合并过程的临时序列;排序过程稳定,相等元素的相对顺序在排序后保持不变。
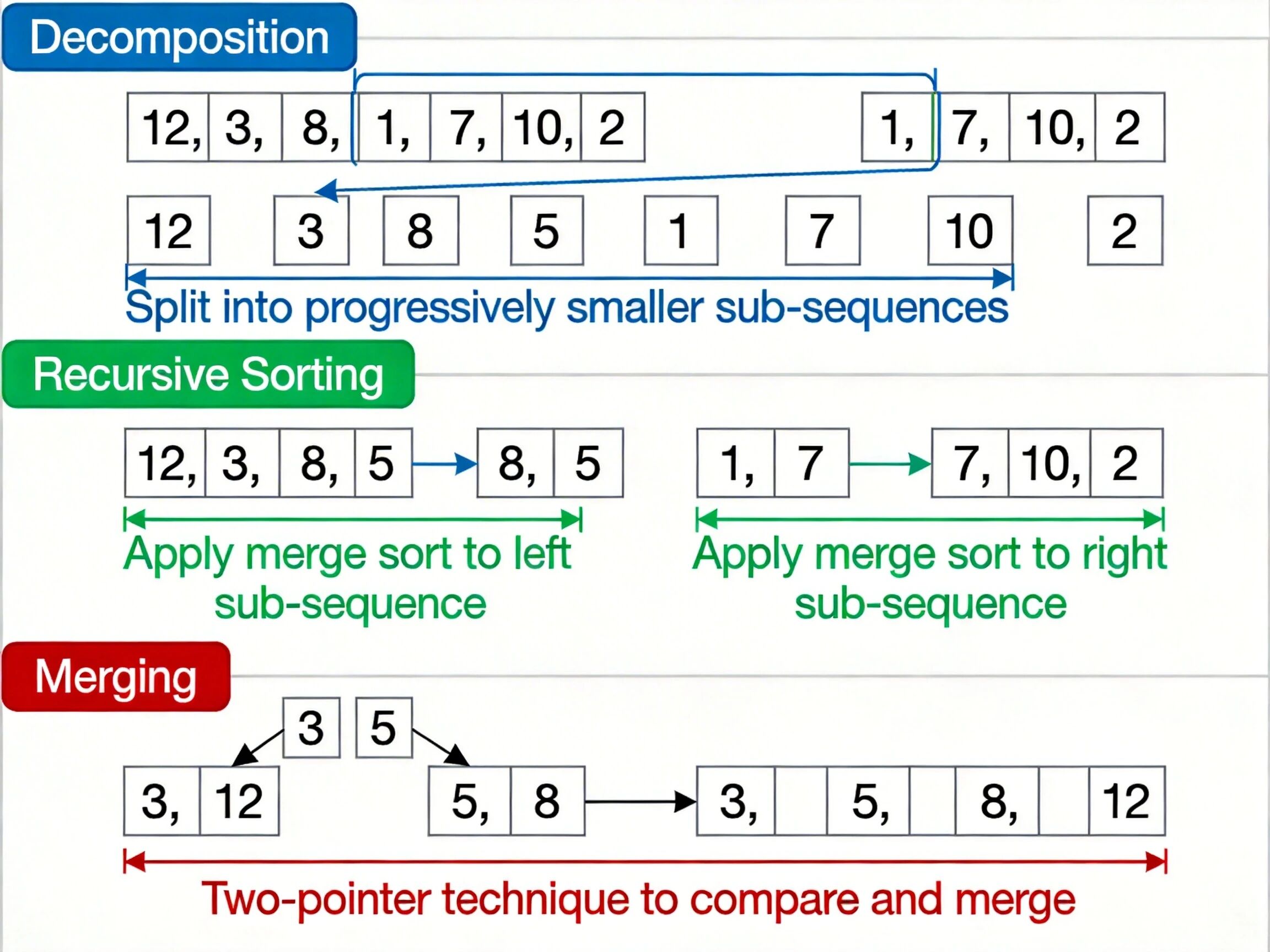
归并排序执行过程示意图,展示序列分解、子序列排序、合并为完整有序序列的完整步骤
4.2 最大子段和问题
最大子段和问题要求给定包含负数的整数序列,求解其连续子序列的最大和,是分治法在最优解求解领域的典型应用。
分治实现逻辑
分解:将序列从中间位置拆分为左右两个子序列,最大子段和的存在位置有三种可能:完全位于左子序列、完全位于右子序列、跨越中间位置同时包含左右子序列的部分元素。
求解:对于完全位于左、右子序列的情况,递归调用最大子段和算法求解;对于跨越中间位置的情况,从中间元素分别向左、向右遍历,计算左半部分以中间元素为右端点的最大子段和、右半部分以中间元素相邻位置为左端点的最大子段和,两者相加即为跨越中点的最大子段和。
合并:比较左子序列最大和、右子序列最大和、跨越中点的最大和三者的最大值,即为原序列的最大子段和。
算法特性
时间复杂度为 O (n log₂n),优于暴力求解的 O (n²),略低于动态规划实现的 O (n),适用于需要并行计算的场景;空间复杂度为 O (log n),由递归调用栈的深度决定。
4.3 二分查找
二分查找是分治法在查找领域的典型应用,适用于有序序列的元素查找场景。
分治实现逻辑
分解:将有序序列的查找区间与中间元素比较,若中间元素等于目标值则直接返回;若目标值小于中间元素,则将查找区间缩小为左半部分;若目标值大于中间元素,则将查找区间缩小为右半部分。
求解:递归地在缩小后的子区间中执行查找,当查找区间左边界大于右边界时返回查找失败(递归出口)。
合并:二分查找的结果直接由子问题返回,不需要额外的合并步骤,是分治法中合并复杂度为 O (1) 的特殊场景。
算法特性
时间复杂度为 O (log₂n),查找效率远高于顺序查找的 O (n);仅适用于有序序列,且要求序列支持随机访问;平均成功查找长度为判定树的平均路径长度,n 个元素的有序序列平均查找长度约为 log₂(n+1)-1。
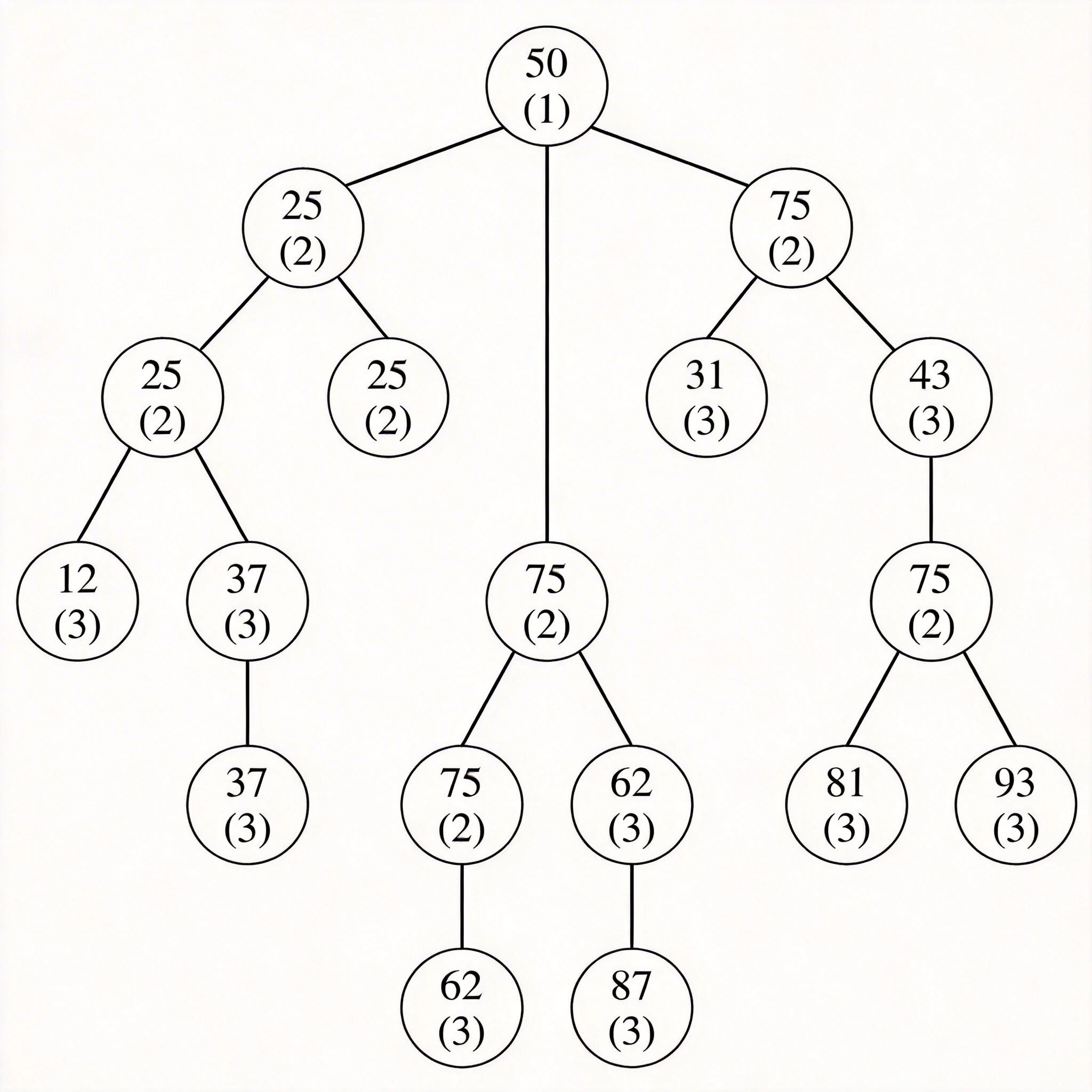
二分查找判定树示意图,展示 10 个元素的有序序列对应的判定树结构,标注每个节点的查找长度
五、分治法最佳实践与考试考点分析
5.1 分治法设计最佳实践
分解策略选择:优先选择将问题分解为规模相等的子问题,保证子问题的求解复杂度均衡,避免出现子问题规模差异过大导致的效率下降。例如二分查找每次将区间减半,归并排序每次将序列拆分为两个等长子序列,均属于最优分解策略。
合并步骤优化:合并步骤的复杂度是分治法效率的瓶颈,应尽可能降低合并的时间复杂度。例如归并排序的合并步骤采用双指针法实现 O (n) 复杂度,若采用其他合并方式可能导致复杂度升高至 O (n²),失去分治法的效率优势。
递归深度控制:对于规模极大的问题,递归实现可能导致栈溢出,可将递归转换为迭代实现,或设置合理的递归深度阈值,超过阈值时切换为其他求解策略。
5.2 常见问题与解决方案
子问题不独立:若分解后的子问题存在重叠,继续使用分治法会导致大量重复计算,此时应切换为动态规划策略,通过存储子问题的解避免重复计算。例如斐波那契数列求解若采用分治法会产生大量重复计算,而动态规划的迭代实现复杂度仅为 O (n)。
合并复杂度太高:若合并步骤的时间复杂度超过 O (n log n),分治法的整体效率可能低于直接求解,此时需要重新设计合并逻辑,或选择其他算法策略。
5.3 软考考试重点提示
选择题高频考点:分治法的适用条件、与动态规划 / 贪心 / 回溯等算法策略的区别、典型算法的归类(如归并排序、快速排序、二分查找均属于分治法)、二分查找的平均比较次数计算、分治算法的时间复杂度分析。
案例分析考点:结合排序场景设计分治算法的实现步骤、分析算法的时间与空间复杂度、针对特定场景(如最大子段和、矩阵乘法)设计分治求解逻辑。
六、总结与建议
6.1 核心要点总结
递归是分治法的实现基础,必须包含递归出口和递归体两大要素,执行过程分为递推和回溯两个阶段。
分治法的核心步骤为分解、求解、合并,要求问题满足可分解性、子问题独立性、边界可解性、解可合并性四大条件。
分治法与动态规划的核心区别为子问题是否独立,分治法适用于子问题无重叠的场景,动态规划适用于子问题存在重叠的场景。
归并排序、快速排序、二分查找、最大子段和分治实现是分治法的典型应用,对应的时间复杂度分别为 O (n log n)、O (n log n)(平均)、O (log n)、O (n log n)。
6.2 学习与备考建议
基础阶段:掌握递归的设计方法,能够独立实现阶乘、斐波那契数列等基础递归算法,理解递归调用栈的工作机制。
进阶阶段:手动实现归并排序、二分查找、最大子段和的分治版本,分析每个算法的分解、求解、合并步骤,熟练应用主定理计算时间复杂度。
应试阶段:重点记忆典型算法的策略归属,掌握二分查找判定树的绘制与平均查找长度计算,能够区分分治法与其他算法策略的适用场景,熟悉选择题中常见的概念混淆点(如将二分查找归为贪心策略等错误选项)。
6.3 技术发展趋势
分治法作为基础算法策略,在大数据处理、分布式计算领域有广泛应用,例如 MapReduce 框架的核心思想就是分治法,通过将大规模数据分解为多个子任务在分布式节点并行处理,最终合并结果得到最终输出。随着并行计算、分布式系统的发展,分治法的应用场景将进一步拓展,掌握其核心思想对理解大规模系统的设计逻辑具有重要意义。