5.1 逻辑回归简介
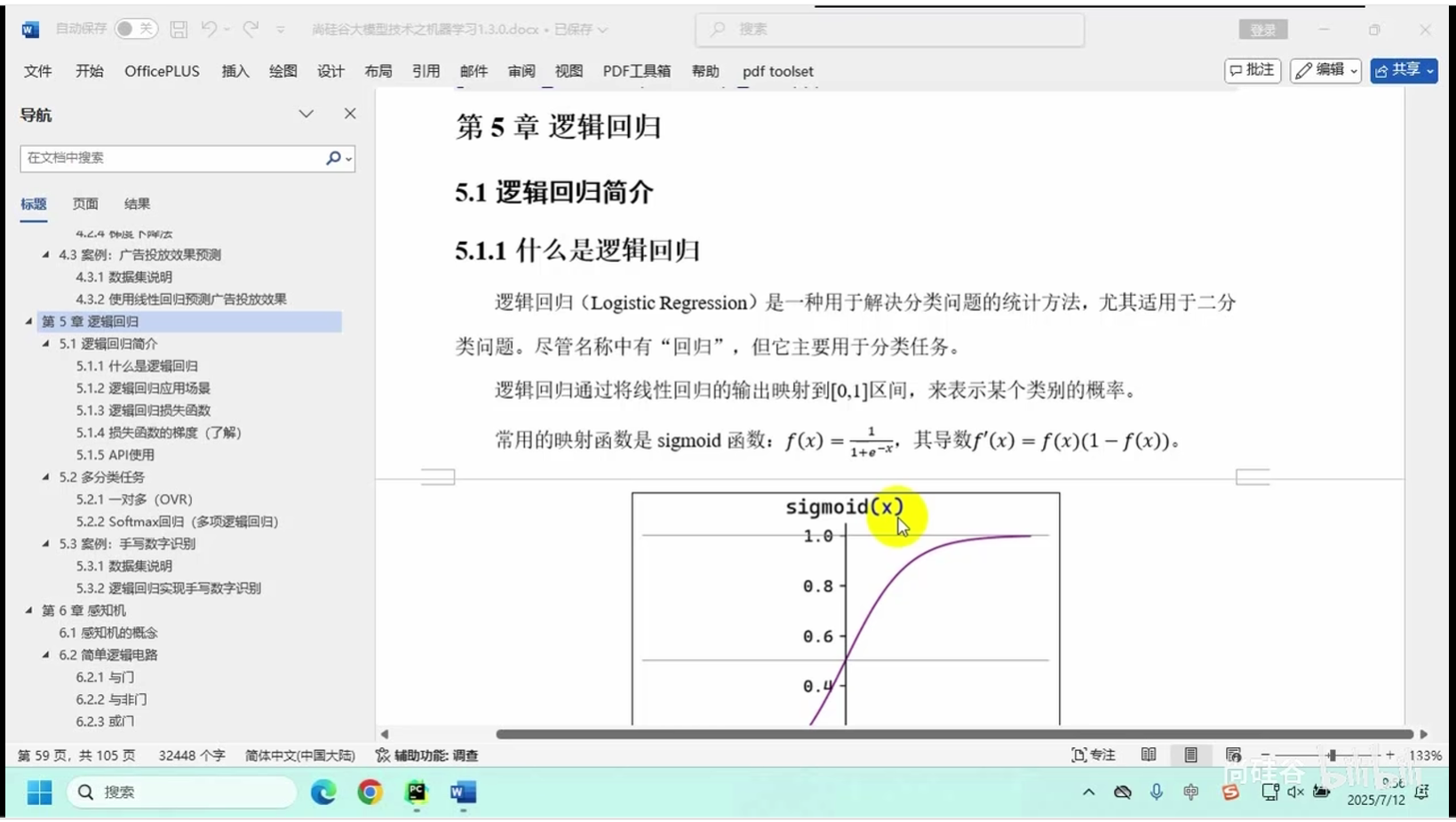
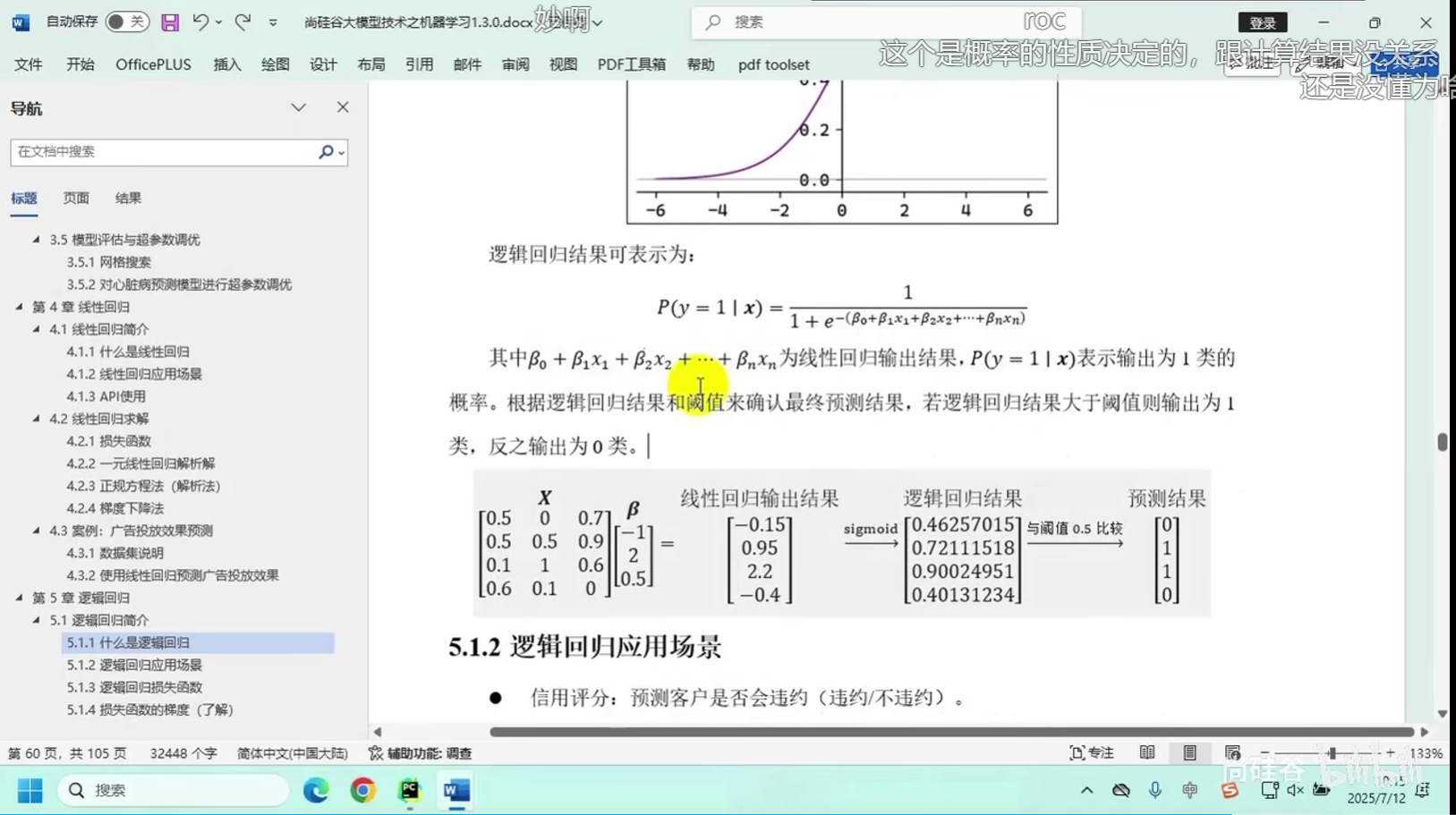
逻辑回归(Logistic Regression)是一种广义线性模型,主要用于处理分类问题。它通过对特征进行线性组合,然后通过Sigmoid函数将结果映射到(0,1)区间,以此来预测样本属于某个类别的概率。逻辑回归模型不仅能够预测分类结果,还能给出属于某一类别的概率估计。
损失函数
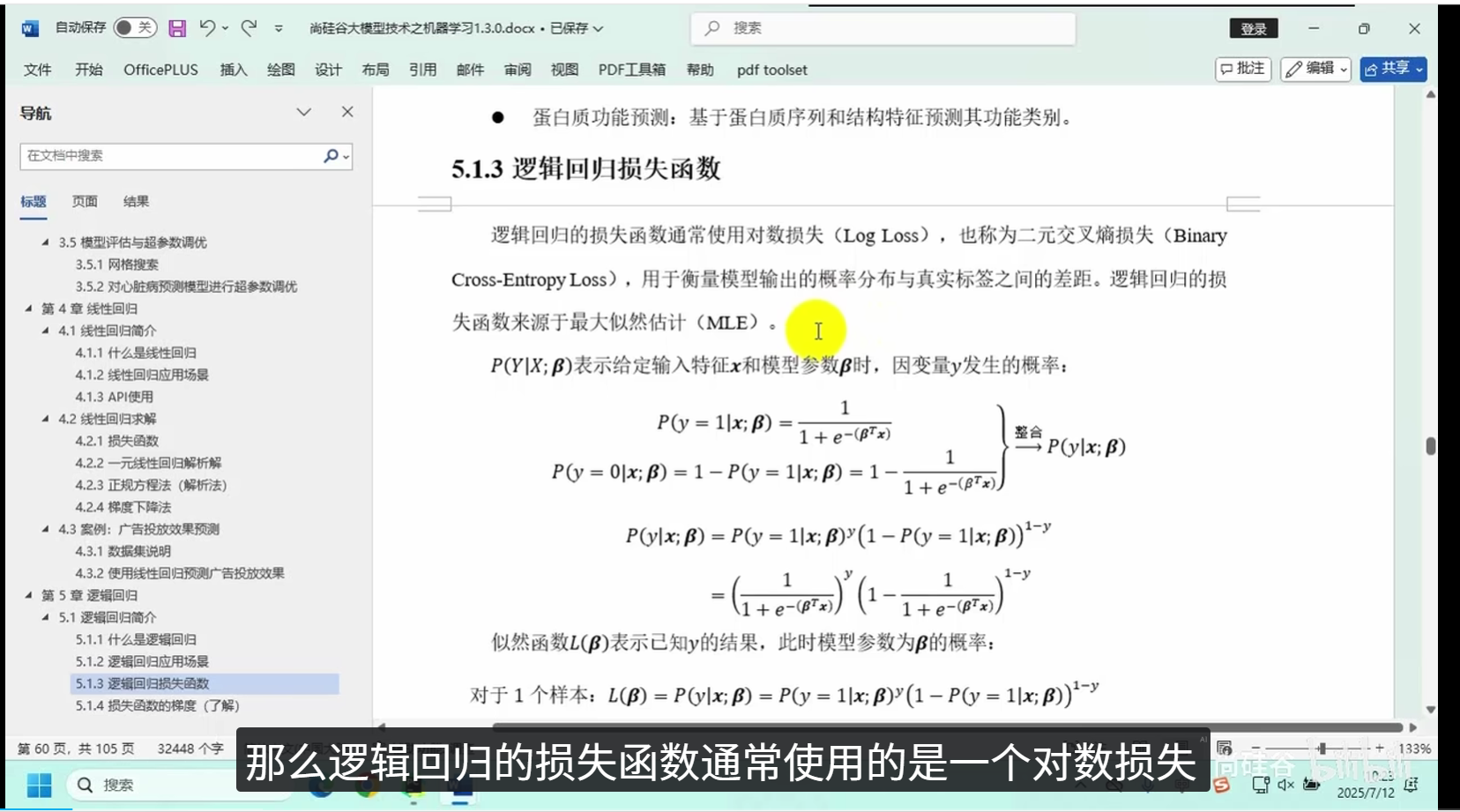
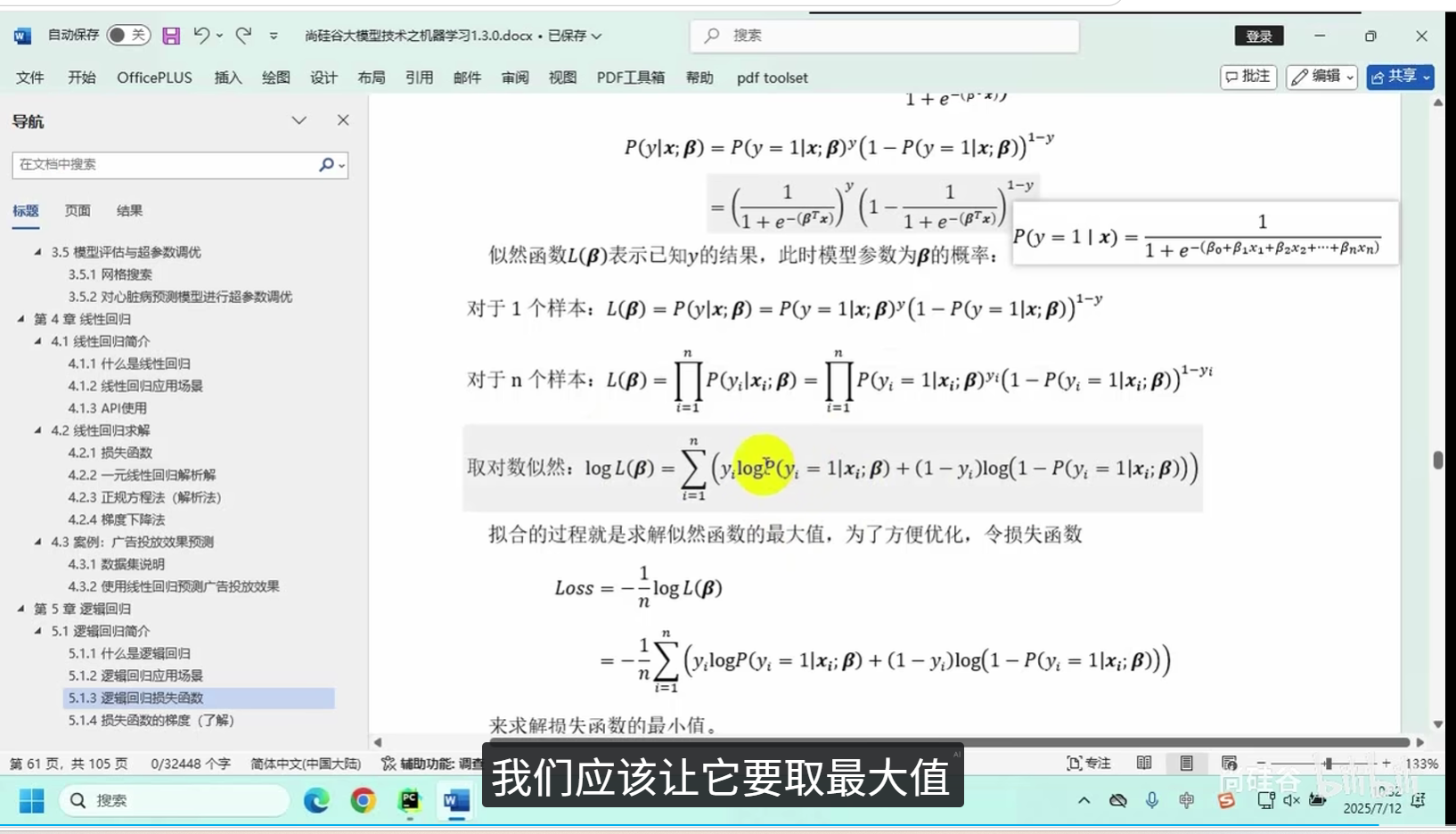
逻辑回归通常使用交叉熵(Cross Entropy)作为损失函数,它能够衡量模型预测概率分布与真实概率分布之间的差异。交叉熵损失函数的形式如下:
其中,m是样本数量,y_i是样本的真实标签,h_theta(x_i)是模型对第i个样本的预测概率。
参数优化
逻辑回归模型的参数通过最大似然估计(MLE)进行优化,通常使用梯度下降法来最小化损失函数,从而求解模型参数。
逻辑回归的优缺点
优点:
模型简单:逻辑回归模型形式简单,易于理解和实现。
输出概率:能够给出样本属于某一类别的概率估计。
凸函数优化:损失函数是凸函数,易于求解全局最优解。
泛化能力:逻辑回归对小噪声的鲁棒性较好,不易过拟合。
缺点:
表达能力有限:逻辑回归是线性模型,对于非线性问题需要进行特征工程。
特征处理:需要对连续特征进行离散化,以增强模型的表达能力。
高维稀疏数据:在高维稀疏数据下,逻辑回归的性能可能不佳。
应用场景
逻辑回归广泛应用于各种二分类问题,如垃圾邮件检测、疾病诊断、金融欺诈预测等。它也可以通过一对多(One-vs-Rest)或多项逻辑回归(Multinomial Logistic Regression)的方式来处理多分类问题。
5.1.1 什么是逻辑回归
5.1.2 逻辑回归应用场景
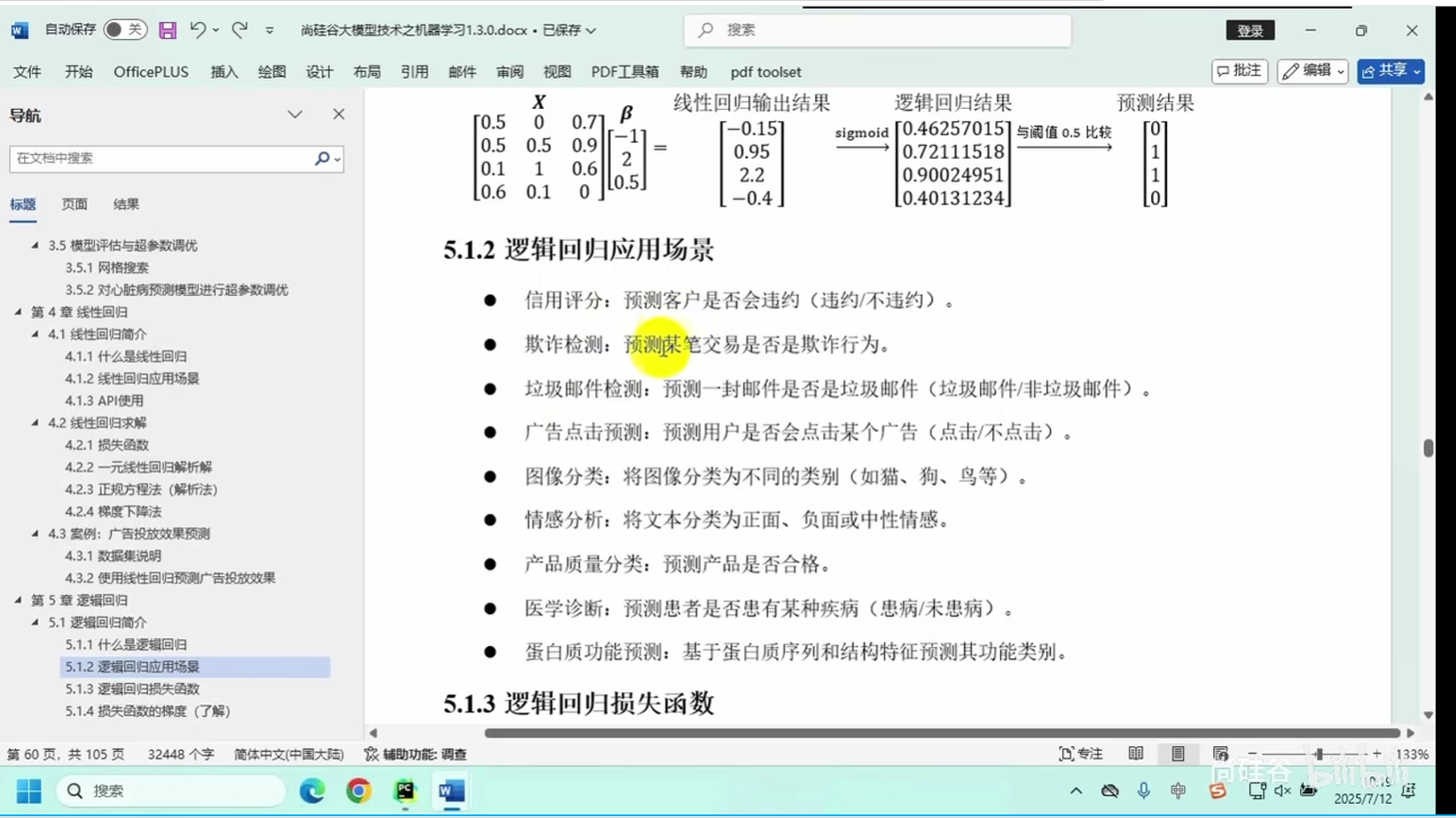
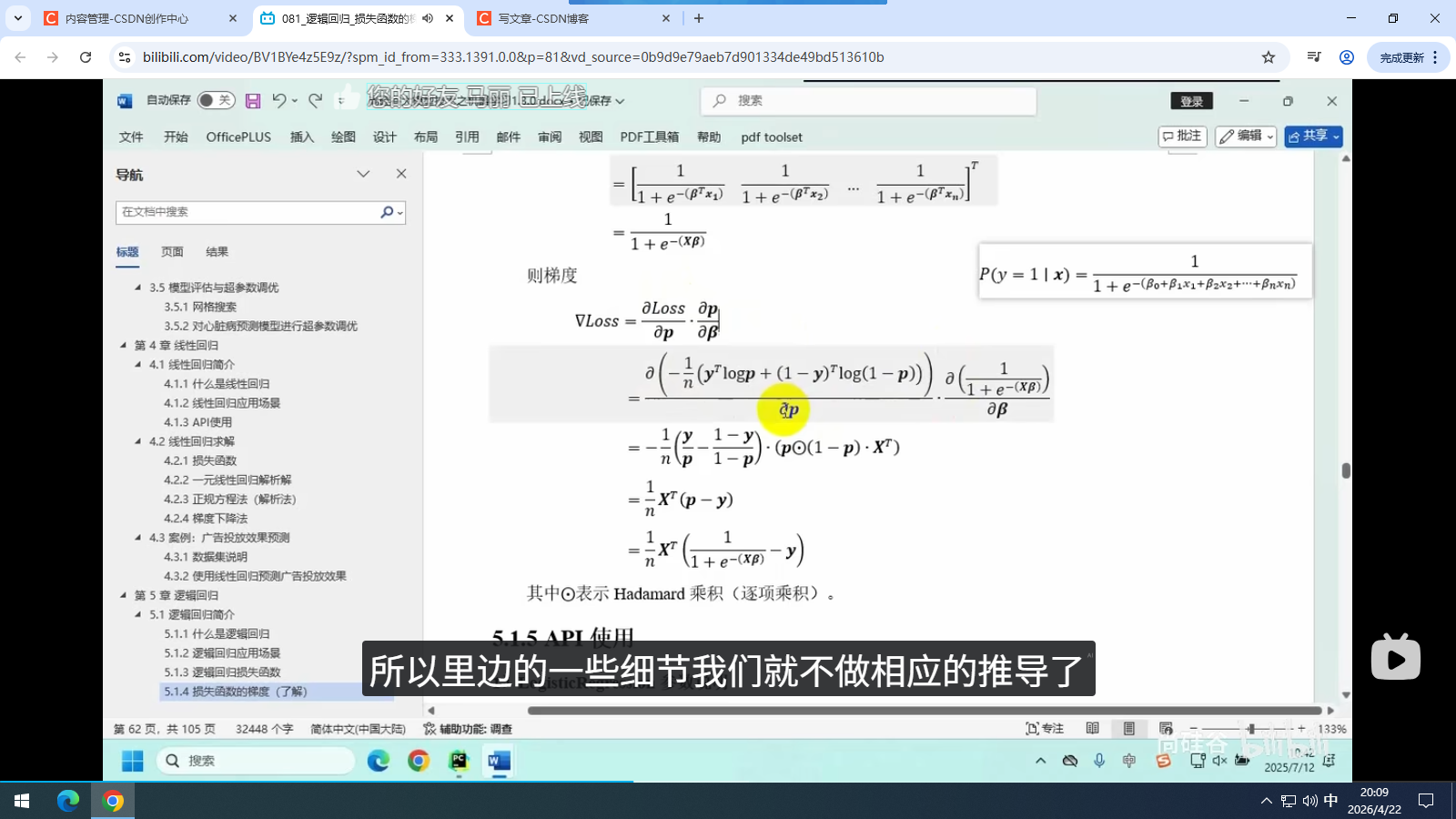
5.1.3 逻辑回归损失函数
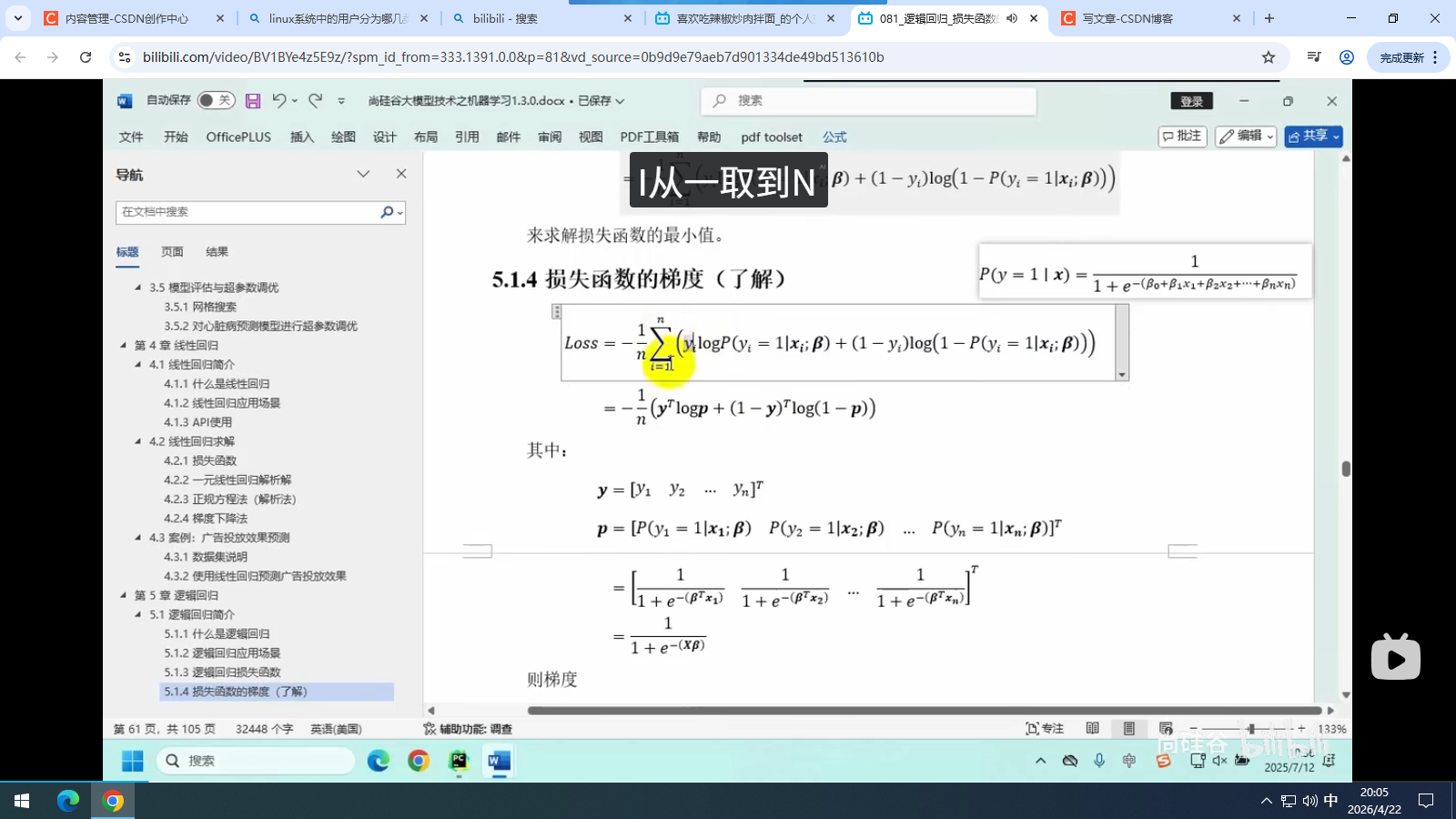
5.1.4 损失函数的梯度
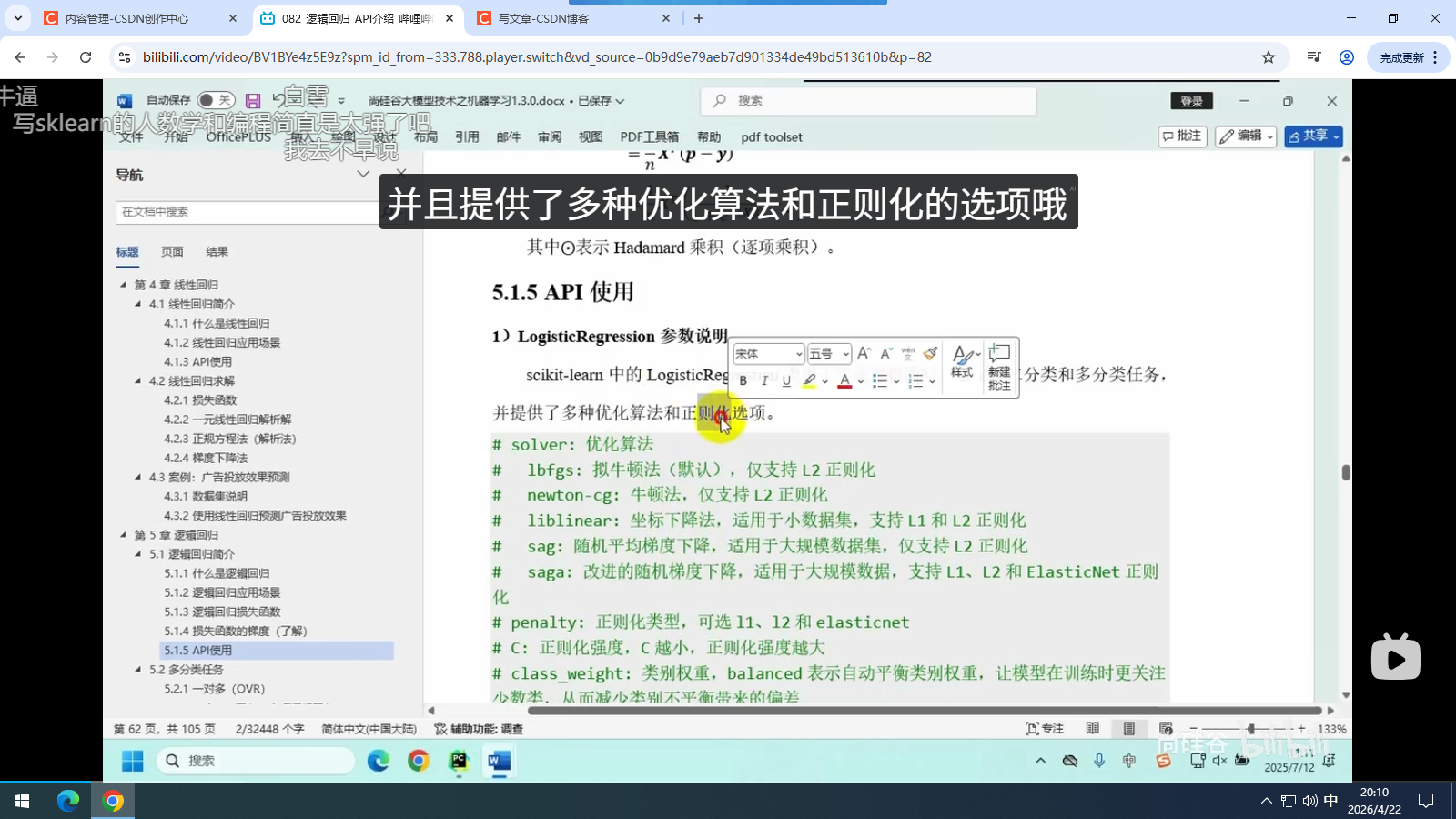
5.1.5 API的使用
5.2 多任务分类
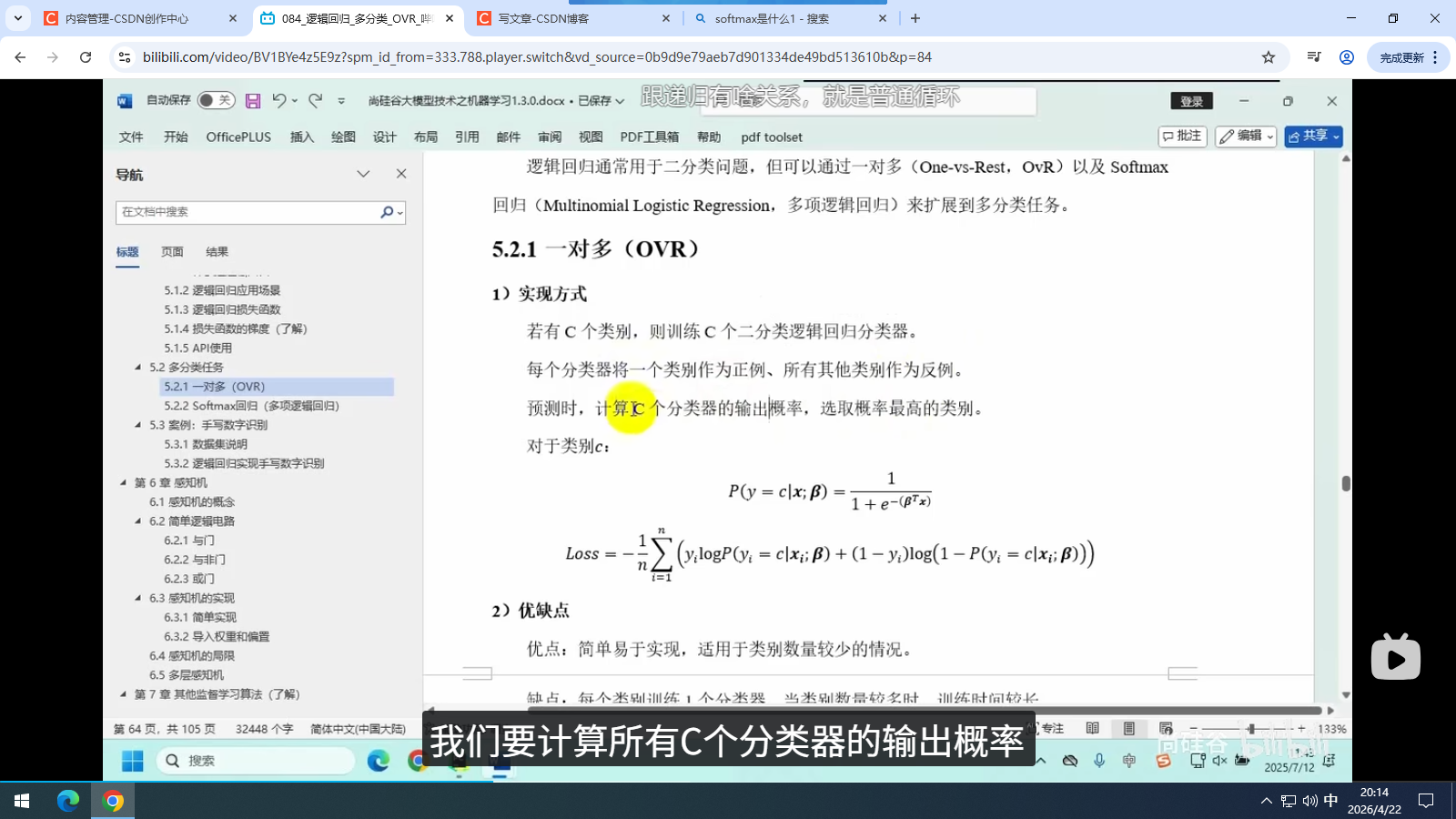
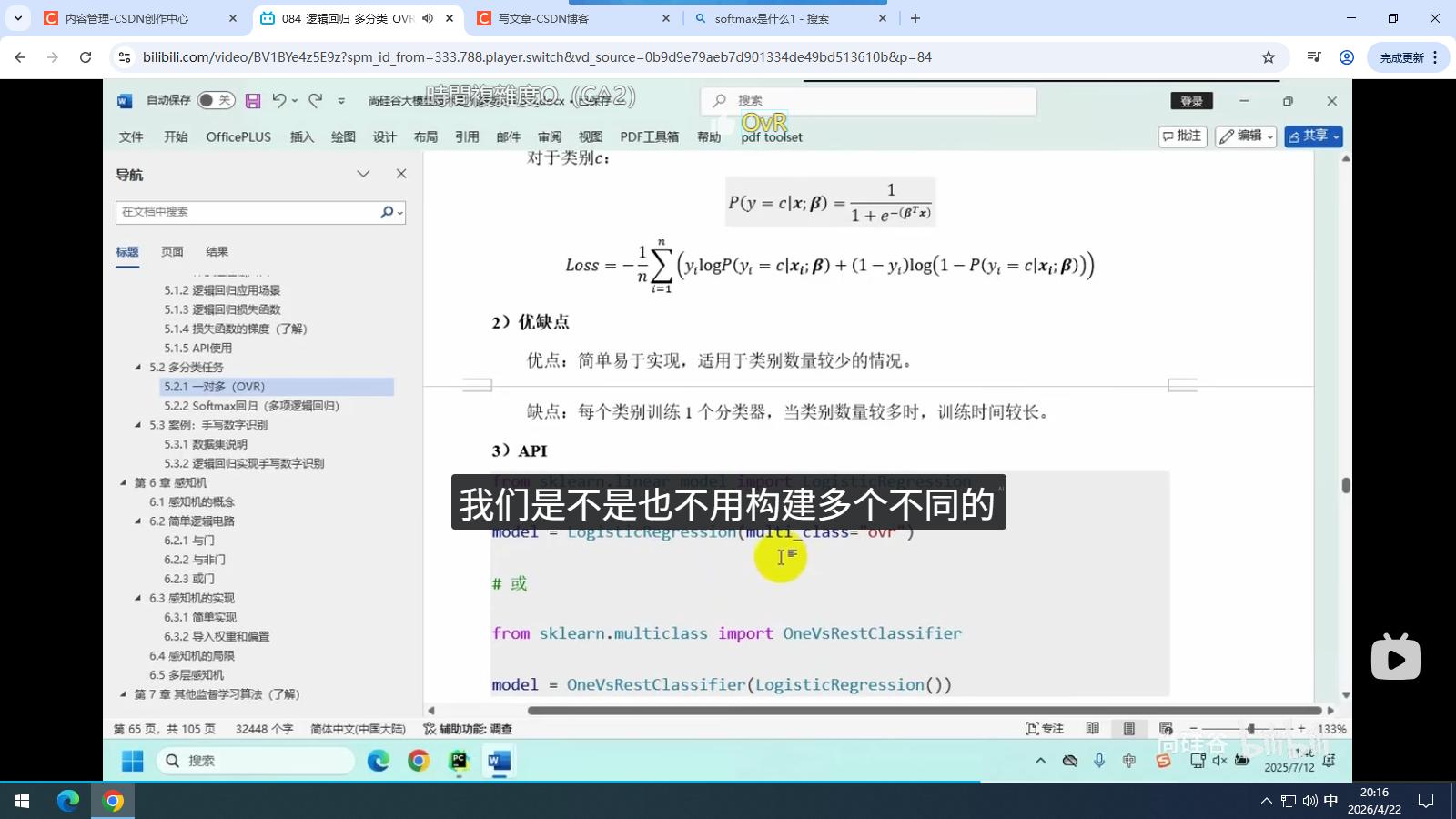
5.2.1 一对多(OVR)
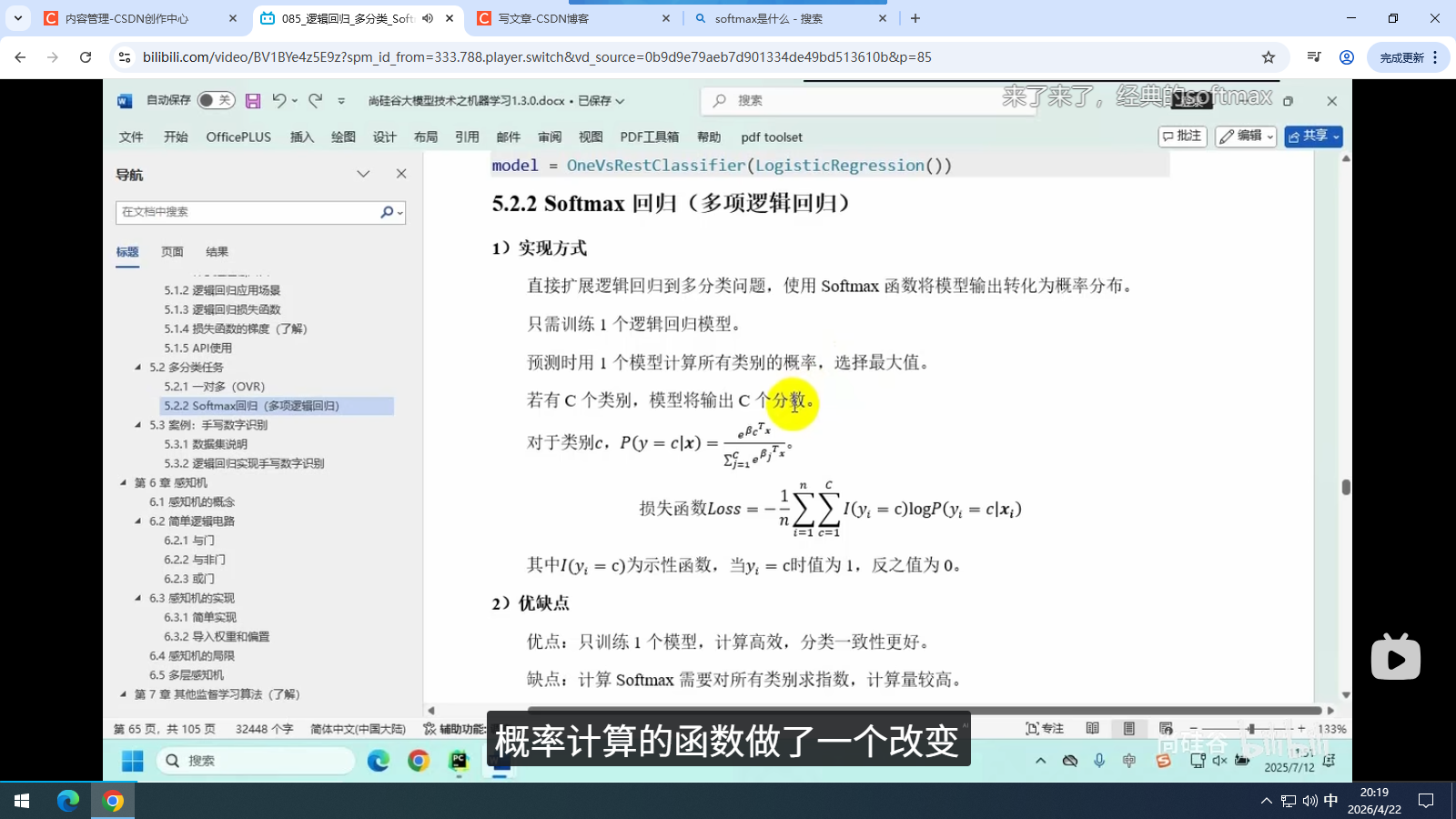
5.2.2 Softmax 回归 (多项逻辑回归)
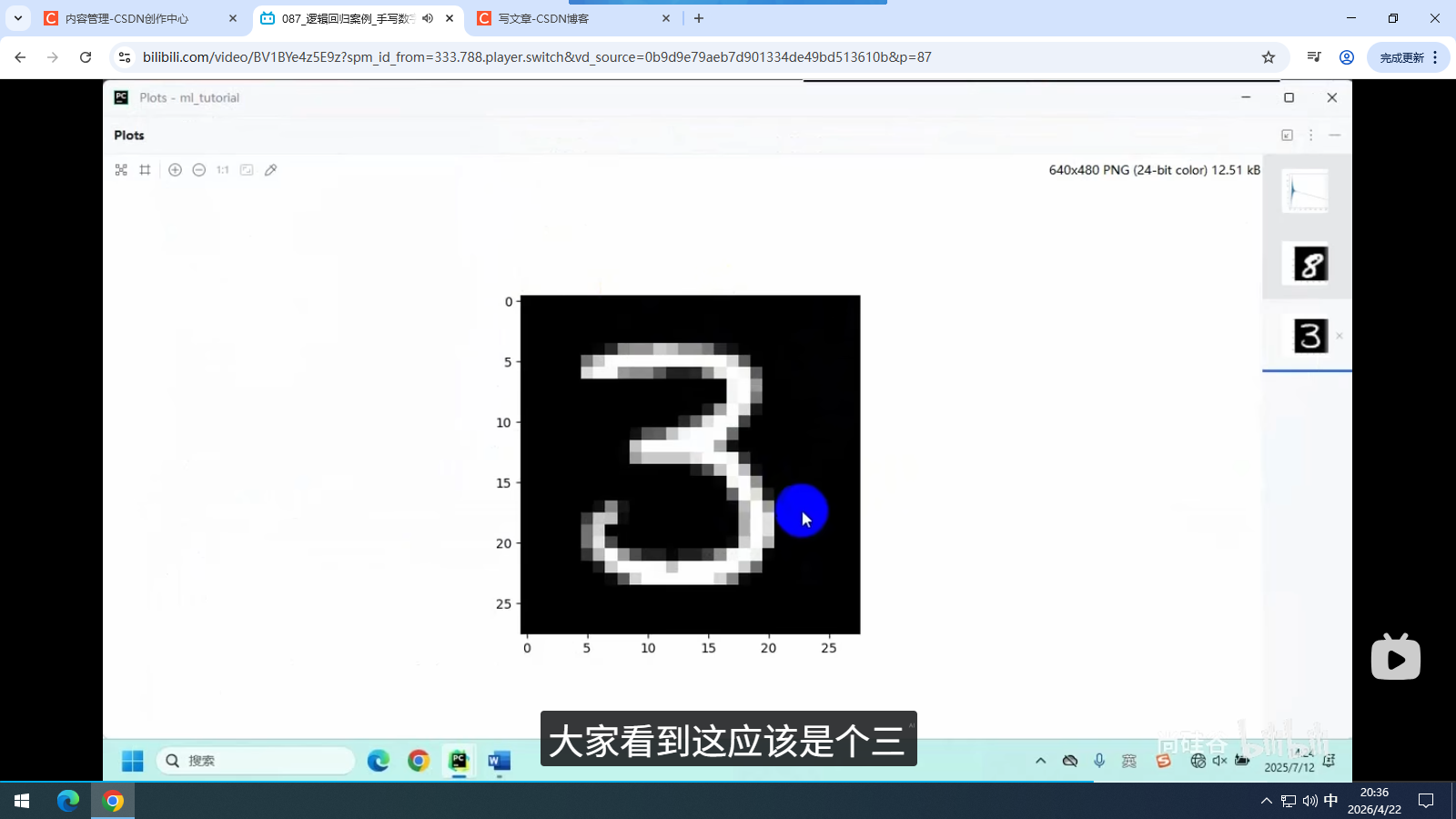
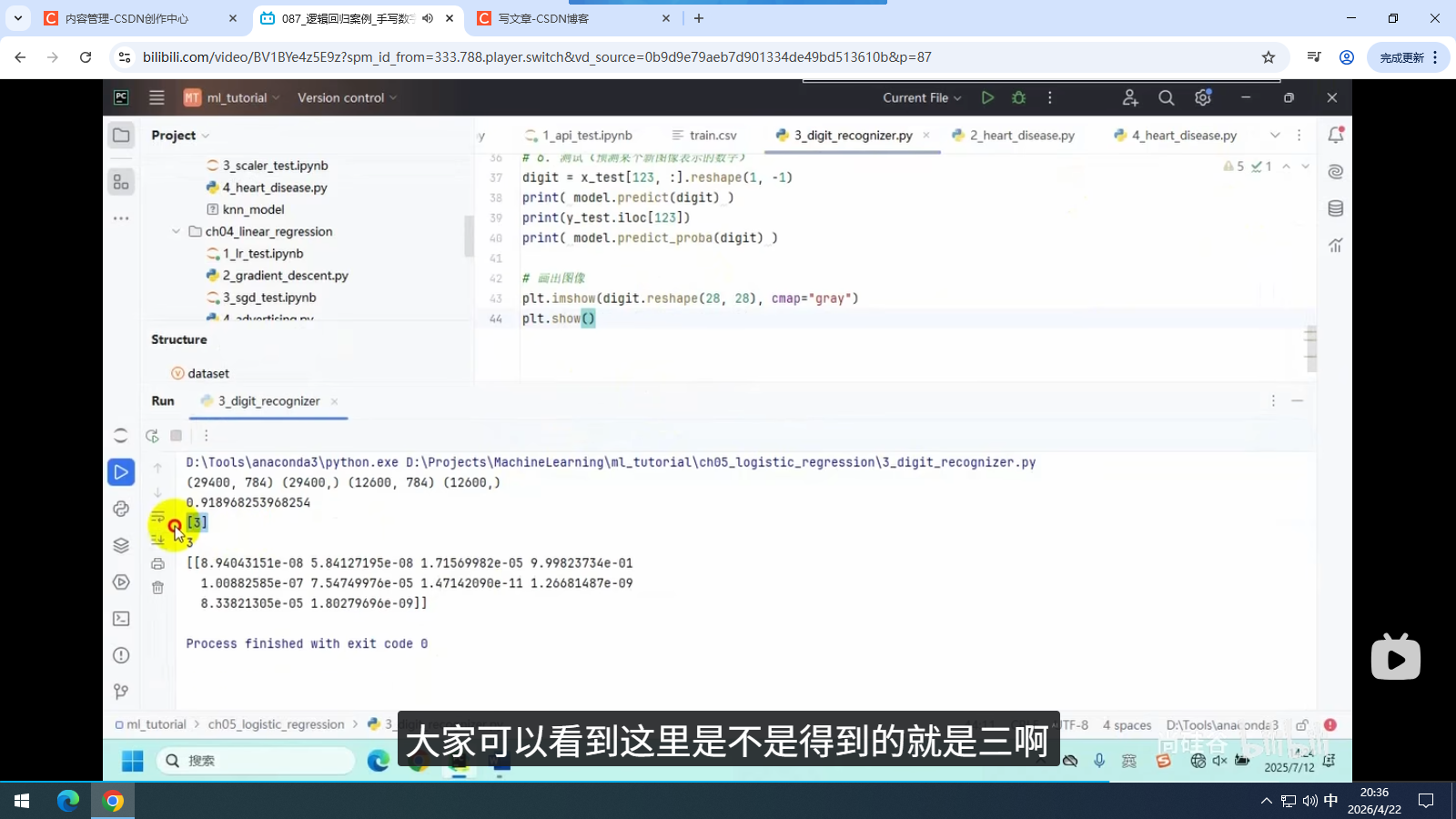
5.3 手写数字识别
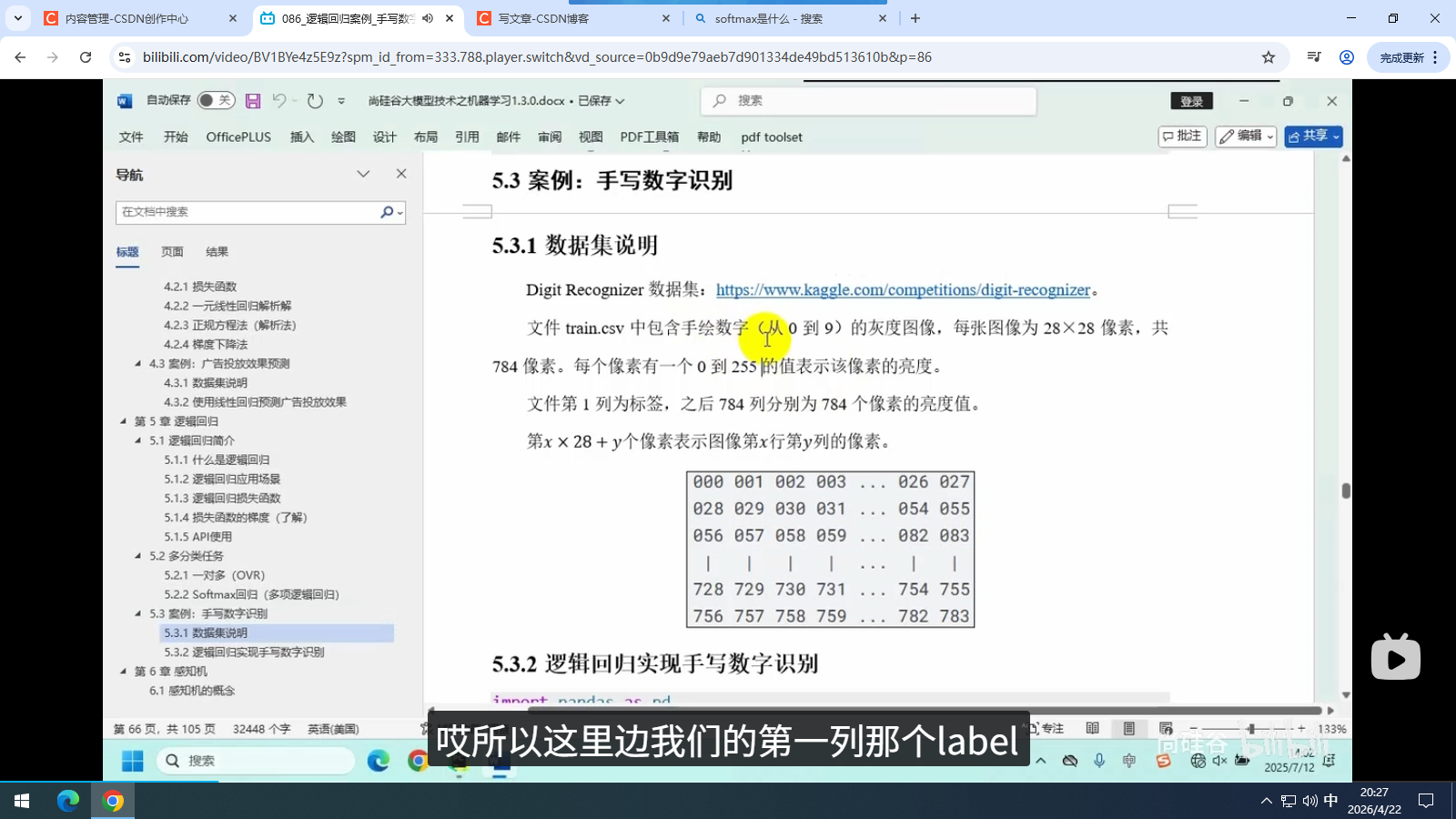
5.3.1 数据集说明
5.3.2 逻辑回归实现手写数字识别