
💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》
🌸Yupureki🌸的简介:

目录
[1. 定长内存池的介绍](#1. 定长内存池的介绍)
[2. 定长内存池的构建](#2. 定长内存池的构建)
[2.1 内存申请的系统调用](#2.1 内存申请的系统调用)
[2.2 ObjectPool的总体框架构建](#2.2 ObjectPool的总体框架构建)
[2.3 New函数实现](#2.3 New函数实现)
[2.4 Delete函数的实现](#2.4 Delete函数的实现)
[2.5 测试性能](#2.5 测试性能)
1. 定长内存池的介绍
作为程序员(C/C++)我们知道申请内存使用的是malloc,malloc其实就是一个通用的大众货,什么场景下都可以用,但是什么场景下都可以用就意味着什么场景下都不会有很高的性能,下面我们就先来设计一个定长内存池做个开胃菜,当然这个定长内存池在我们后面的高并发内存池中也是有价值的,所以学习他目的有两层,先熟悉一下简单内存池是如何控制的,第二他会作为我们后面内存池的一个基础组件。
定长内存池通常被用作对象池,即ObjectPool。整个内存池只用来给一种数据结构用。
对象池适用于以下场景:
-
高成本初始化 :如 StringBuilder 或大型缓冲区。
-
有限资源:如数据库连接或线程。
-
频繁使用:如在高并发环境中重复使用的对象
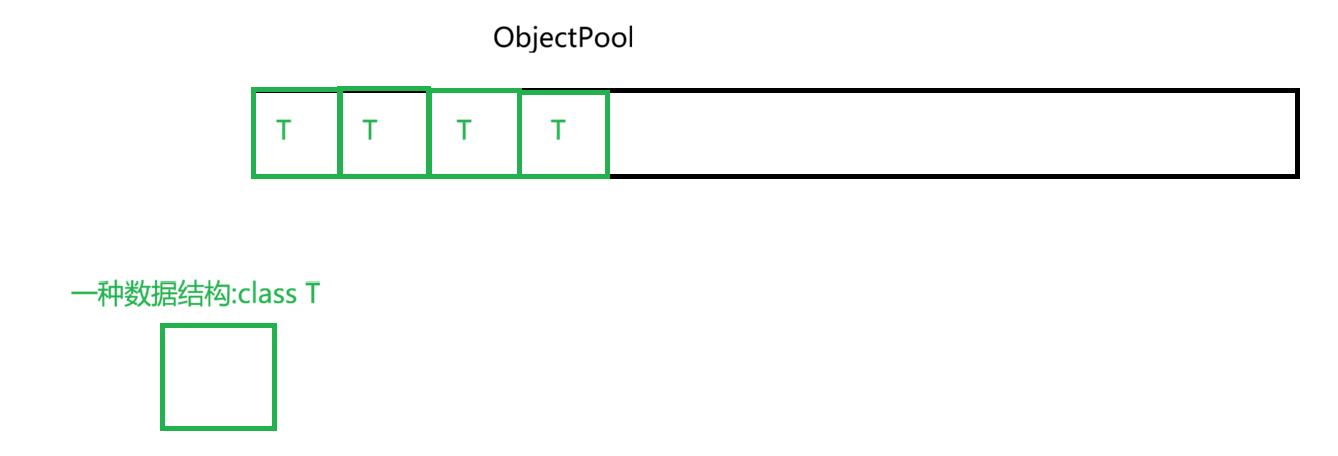
2. 定长内存池的构建
2.1 内存申请的系统调用
由于malloc的局限性,我们在内存申请方面使用系统调用,提高效率
并且在操作系统中,系统通常以页为单位进行数据的访问和保存,通常一页是4kb/8kb(我们选择8kb),所以我们向系统申请内存时,最好是以页为单位申请
关于内存申请的系统调用:
Windows:VirtualAlloc_百度百科
Linux:Linux进程分配内存的两种方式--brk() 和mmap() - VinoZhu - 博客园
我们再把系统调用封装一层(函数内),利用条件编译,可以实现跨平台使用
cpp
#define PAGE_SHIFT 13//(kpage << PAGE_SHIFT)表示一页的字节大小 8kb = 8 * 1024,即2*13
#ifdef _WIN32
#include <Windows.h>
#elif __LINUX__
#include <unistd.h>
#endif
// 直接去堆上按页申请空间
// 封装系统调用
inline static void* SystemAlloc(size_t kpage)//kpage:页数
{
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << PAGE_SHIFT, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
void* ptr = mmap(NULL, kpage << PAGE_SHIFT, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED)
ptr = nullptr;
#endif
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}2.2 ObjectPool的总体框架构建
ObjectPool是只给一种数据结构用的内存池,因此我们可以用模板,来指定所用的数据结构
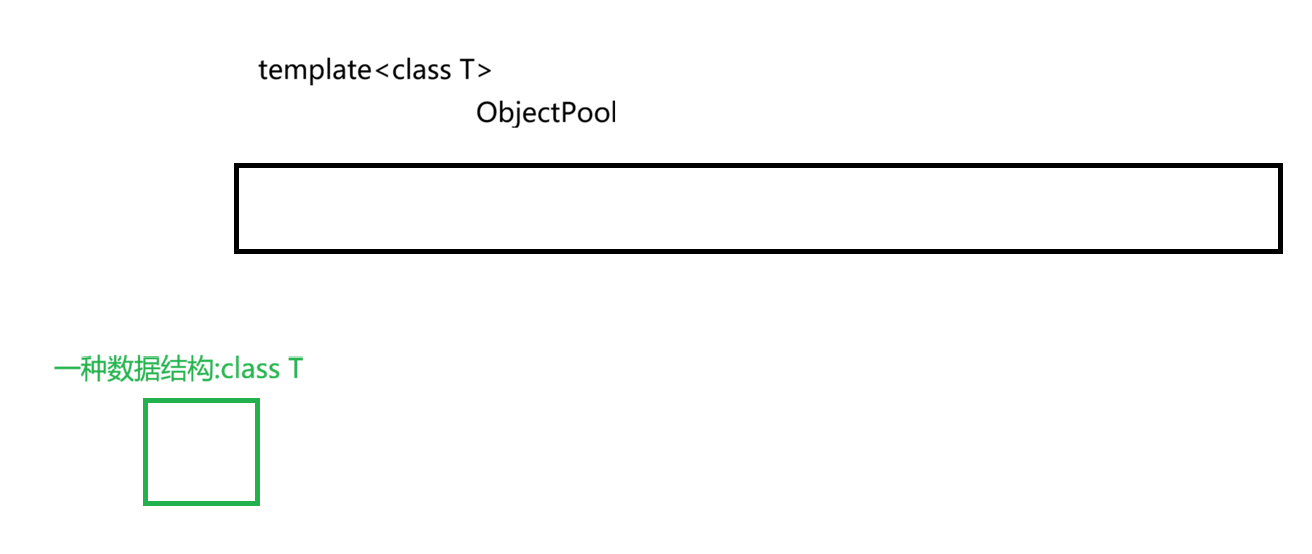
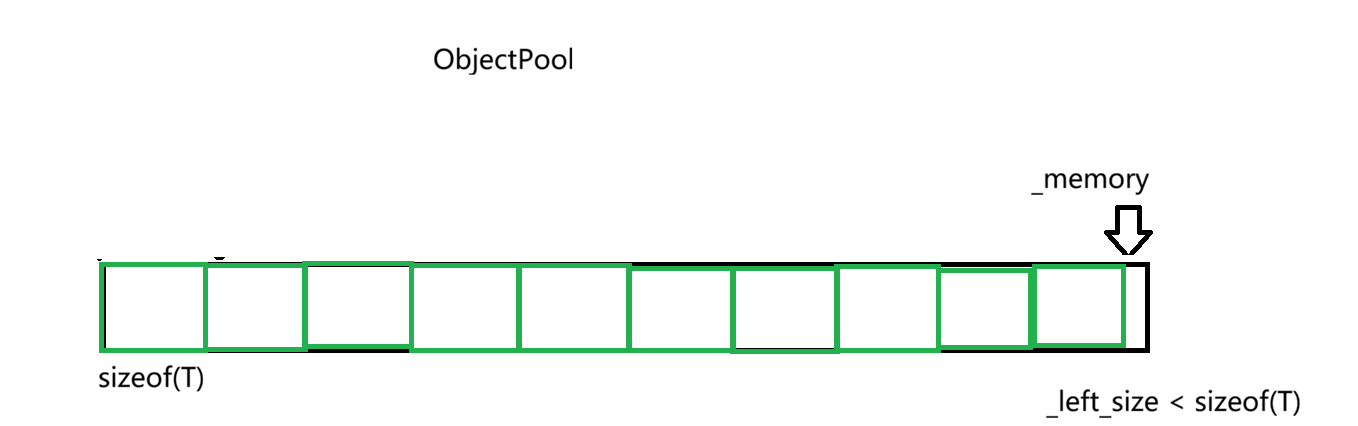
当我们向系统申请内存后,需要一个指针指向其内存的首地址,即_memory
其中进程始终先拿_memory所指向一块资源
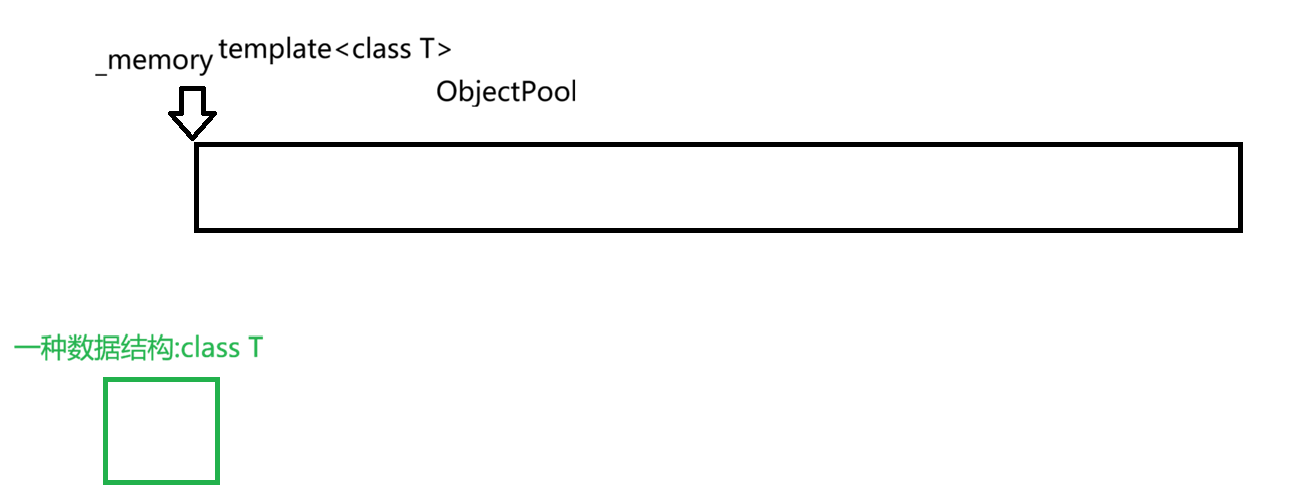
当向ObjectPool的头部拿走了一块资源后,需要把_memory += sizeof(T)
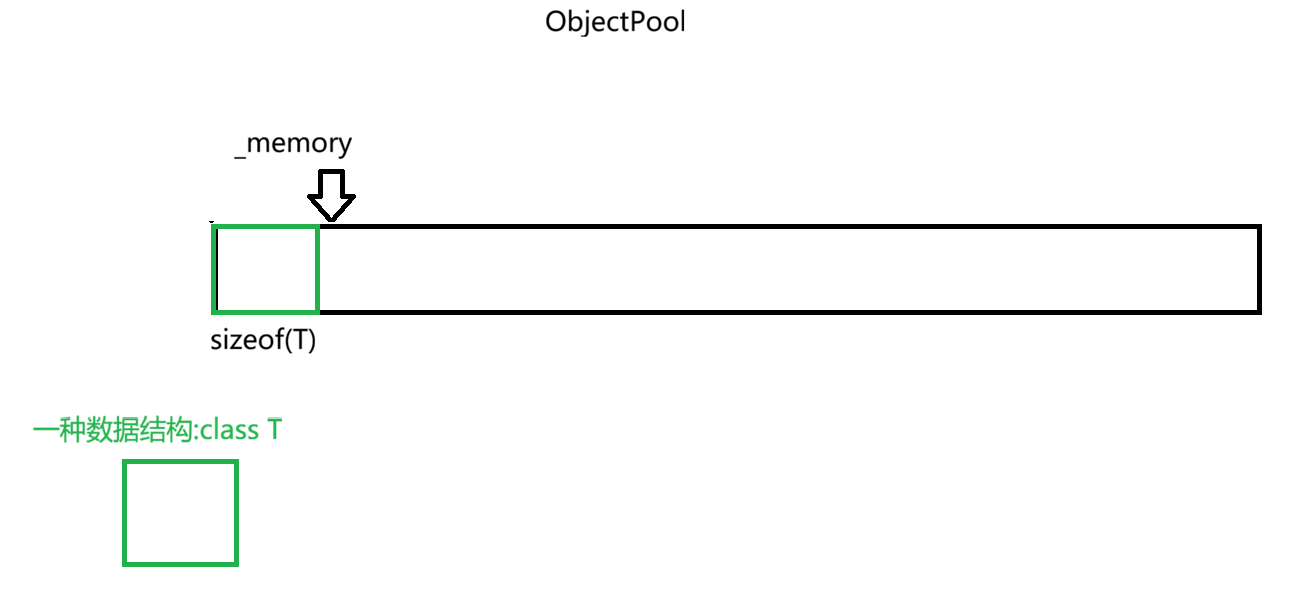
直到_memory到了内存池底部,有可能剩余的空间不够一个class T使用,而我们需要判断这个状况,因此我们再引入一个_left_size的变量,表示内存池剩余的空间
如果_left_size < sizeof(T),那么需要重新开辟空间,_memory指向新的内存池,_left_size也得更新
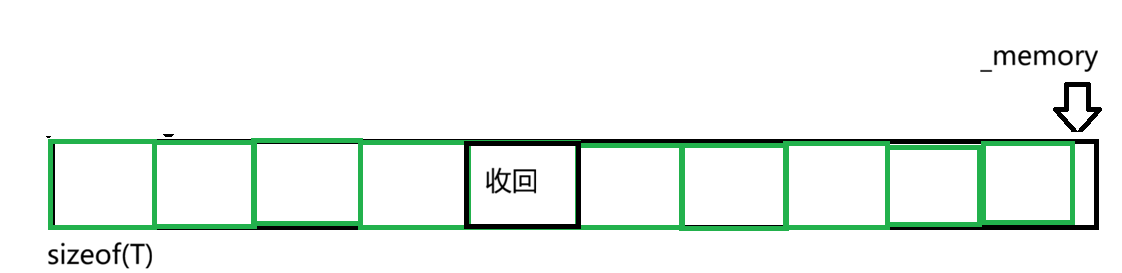
向内存池申请空间我们讲完了,那么如果释放资源如何处理?
难道我们再让_memory += sizeof(T)吗?但是我们不知道收回的那块资源在哪个位置,不可胡乱加
因此这里我们把收回的每一块资源用链表串起来(逻辑角度),用_free_list表示最前面的节点的地址
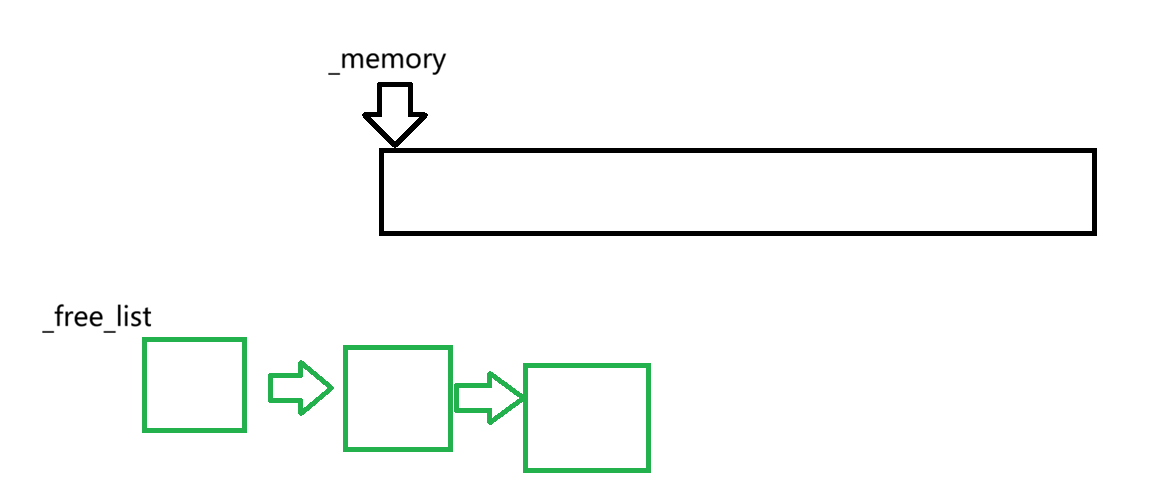
这样如果又有进程要来申请资源时,我们可以优先看_free_list中有没有空余的资源,如果有直接直接拿走即可
那么问题又来了,如何把这几块资源用链表串在一起?以前我们用的结构体内存在next指针,但一块空间可不存在next指针的变量
这里我们把每一块的前4/8个字节(一个指针的大小)放入下一个节点的地址 ,如果每一块不够一个指针的大小,则在申请资源的时候强制给一个指针的大小
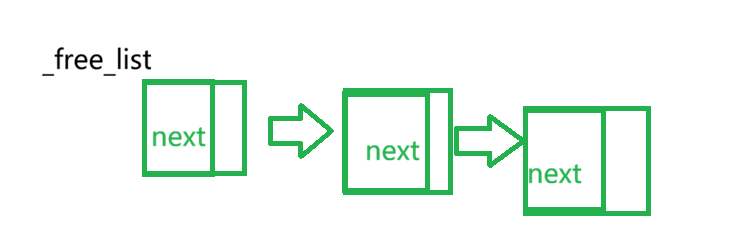 为了方便,我们专门引入一个函数,来查找链表中一个节点的下一个节点,即访问前4/8个字节
为了方便,我们专门引入一个函数,来查找链表中一个节点的下一个节点,即访问前4/8个字节
cpp
static void*& Next_Obj(void* obj)
{
return *((void**)obj);//自动访问一个指针大小的空间,32位下为4个字节,64位下为8个字节
}这样ObjectPool的大框架就出来了
cpp
template<class T>
class ObjectPool
{
public:
T* New()
{}
void Delete(T* obj)
{}
private:
char* _memory = nullptr;//剩余空间的首地址
size_t _left_size = 0;//剩余空间的大小
void* _free_list = nullptr;//回收链表的首节点地址
};2.3 New函数实现
回顾之前的申请资源的思路:
- 先看_free_list有没有空余资源,如果有,优先从这拿
- 如果_free_list为空(没有空余资源),则拿走有_memory指向的一块资源
其中从_memory拿又有两种情况:
- 剩余空间大于对象的大小,直接拿
- 剩余空间不够,需要重新开辟
代码实现:
cpp
T* New()
{
T* obj = nullptr;
if (_free_list)//先看_free_list为不为空
{
void* next = *((void**)_free_list);
obj = (T*)_free_list;
_free_list = next;
}
else
{
if (_left_size < sizeof(T))//剩余空间不够
{
_memory = (char*)SystemAlloc(DEFAULT_KPAGE_NUM);//重新开辟
_left_size = DEFUALT_KPAGE_SIZE;
if (_memory == nullptr)
{
throw std::bad_alloc();
}
}
obj = (T*)_memory;
size_t obj_size = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);//如果对象的大小不够一个指针的大小,则给的时候强制给一个指针的大小
_memory += obj_size;
_left_size -= obj_size;
}
new(obj)T;
return obj;
}2.4 Delete函数的实现
当回收资源时,串在_free_list的链表中
cpp
void Delete(T* obj)
{
obj->~T();
*((void**)obj) = _free_list;
_free_list = obj;
}2.5 测试性能
我们可以跟malloc对比一下,哪个更快
测试代码:
cpp
struct TreeNode
{
int _val;
TreeNode* _left;
TreeNode* _right;
TreeNode()
:_val(0)
, _left(nullptr)
, _right(nullptr)
{}
};
void TestObjectPool()
{
// 申请释放的轮次
const size_t Rounds = 5;
// 每轮申请释放多少次
const size_t N = 100000;
std::vector<TreeNode*> v1;
v1.reserve(N);
size_t begin1 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v1.push_back(new TreeNode);
}
for (int i = 0; i < N; ++i)
{
delete v1[i];
}
v1.clear();
}
size_t end1 = clock();
std::vector<TreeNode*> v2;
v2.reserve(N);
ObjectPool<TreeNode> TNPool;
size_t begin2 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v2.push_back(TNPool.New());
}
for (int i = 0; i < N; ++i)
{
TNPool.Delete(v2[i]);
}
v2.clear();
}
size_t end2 = clock();
cout << "new cost time:" << end1 - begin1 << endl;
cout << "object pool cost time:" << end2 - begin2 << endl;
}
显然我们的objectpool更快