文章目录
- 1、seq2seq模型架构
- 2、数据集介绍
- 3、案例步骤
-
- 3.1、准备工作
- [3.2 数据预处理](#3.2 数据预处理)
-
- [1、数据读取并转换:\[英文1, 法文1, 英文2, 法文2, ...]](#1、数据读取并转换:[[英文1, 法文1], [英文2, 法文2], ...])
- [2、用 Tokenizer 构建词表(特殊token不能固定)](#2、用 Tokenizer 构建词表(特殊token不能固定))
- 3、合并字典
- 4、构建词表
- [5、get(str, default) 安全取值](#5、get(str, default) 安全取值)
- [6、避免在 `Dataset` 中使用 `.to(device)`](#6、避免在
Dataset中使用.to(device)) - [7、构建数据集 Dataset](#7、构建数据集 Dataset)
- [8、构建数据加载器 DataLoader](#8、构建数据加载器 DataLoader)
- [3.3 构建基于GRU的编码器和解码器](#3.3 构建基于GRU的编码器和解码器)
-
- [1、构建GRU 编码器 模型并测试](#1、构建GRU 编码器 模型并测试)
- [2、构建不带注意力的 GRU 解码器 模型并测试](#2、构建不带注意力的 GRU 解码器 模型并测试)
- [3、torch.nn.functional.relu 和 torch.relu](#3、torch.nn.functional.relu 和 torch.relu)
- [4、构建带注意力的 GRU 解码器](#4、构建带注意力的 GRU 解码器)
- [3.4 构建模型训练函数, 并进行训练](#3.4 构建模型训练函数, 并进行训练)
-
- [1、teacher_forcing 介绍](#1、teacher_forcing 介绍)
- 2、teacher_forcing的作用
- 3、Seq2Seq架构的优化器需要几个------1个即可
- 4、1个优化器装多个模型的参数
- 5、训练一个样本的函数
- 6、构建模型训练函数
- [3.5 构建模型评估函数并测试](#3.5 构建模型评估函数并测试)
- 3.6、整体代码:
1、seq2seq模型架构
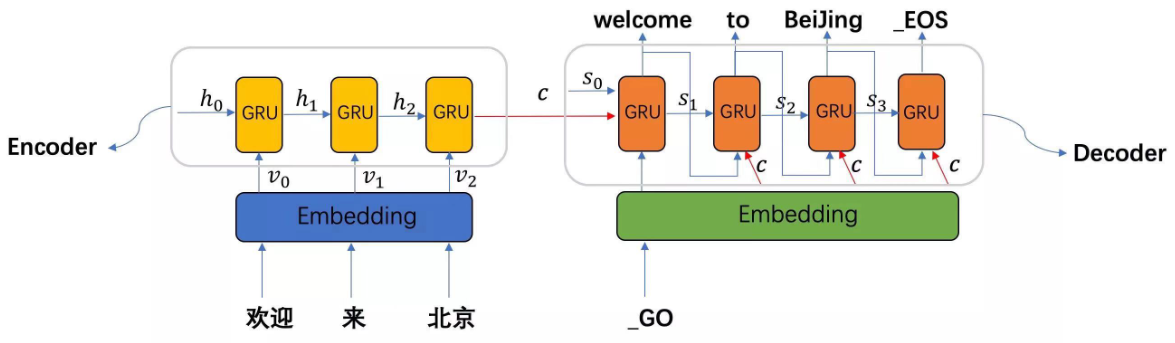
2、数据集介绍
python
完整的训练数据(一个.txt文件):
通过网盘分享的文件:eng-fra-v2.txt
链接: https://pan.baidu.com/s/1Lkfl9ZHGynO_PGczQiQ6_Q
训练数据示例:
i am from brazil . je viens du bresil .
i am from france . je viens de france .
i am from russia . je viens de russie .
i am frying fish . je fais frire du poisson .
i am not kidding . je ne blague pas .
i am on duty now . maintenant je suis en service .
i am on duty now . je suis actuellement en service .
i am only joking . je ne fais que blaguer .
i am out of time . je suis a court de temps .
i am out of work . je suis au chomage .
i am out of work . je suis sans travail .
i am paid weekly . je suis payee a la semaine .
i am pretty sure . je suis relativement sur .
i am truly sorry . je suis vraiment desole .
i am truly sorry . je suis vraiment desolee .3、案例步骤
基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步: 导入工具包和工具函数
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 第三步: 构建基于GRU的编码器和解码器
- 第四步: 构建模型训练函数, 并进行训练
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析
3.1、准备工作
1、导入工具包
可以后面用一个再导入一个,想起来哪个导哪个
python
import torch
import re
# from tensorflow.keras.preprocessing.text import Tokenizer
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import math
import torch.nn.functional as F
import torch.optim as optim
from itertools import chain
import time
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
from torchinfo import summary
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # ←←← 关键!放在最前面(解决报错)
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False # 设置正常显示符号2、数据查看
1.查看数据
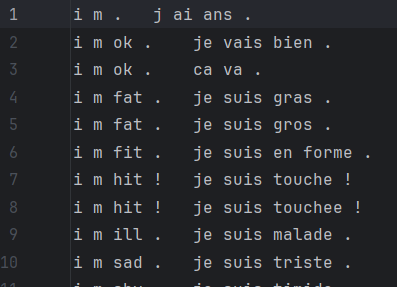
只看的话,不确定中间到底是由 "空格" or "制表符" or "其它符号" 隔开,所以:
直接复制一行,粘贴到一个列表里,直接打印,就能看到一行里都有哪些符号
python
li = ['i m . j ai ans .']
print(li)
# ['i m .\tj ai ans .'] # 可以看到中间是用 \t 隔开,别忘了每行最后还有个 \n2.统计句子长度
分别统计 输入句子 和 输出句子 的长度,取能覆盖绝大部分长度的值。经过统计,大多数句子的长度都不超过 10,故:
python
MAX_LENGTH = 103、把数据改成需要的(正则)
知道即可,可以直接让 AI 根据要求生成对应的正则表达式
python
# 文本清洗工具函数
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s4、代码
python
import torch
import re
# 能用 GPU 就用,否则用 CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
START_OF_SENTENCE = 0 # 解码器起始符号
END_OF_SENTENCE = 1 # 解码器结束符号
MAX_LENGTH = 10 # 每个句子的最大长度
# 文本清洗工具函数
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s3.2 数据预处理
对持久化文件中数据进行处理, 以满足模型训练要求
注意,是满足模型训练要求,所以就不会再对数据进行变更了,比如不会再把数据里面的大写变成小写
1、数据读取并转换:\[英文1, 法文1, 英文2, 法文2, ...]
读取数据,并通过正则把数据转换成需要的
python
# 2.读取数据集,构建平行语料的词典
def my_data():
# 每行数据的格式是【英文\t法文】,现在要把每行变成【[英文, 法文]】,即每行有一个列表分别把英文和法文装起立
# 最后把每行放到一个大列表中:[{[英文1, 法文1], [英文2, 法文2], [英文3, 法文3], ...]
with open(r'./data/eng-fra-v2.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
# 核心是这个列表推导式,结构是 [[英文1, 法文1], [英文2, 法文2], ...],所以里面又是个列表
mydata = [[normalizeString(sentence) for sentence in line.split('\t')] for line in lines]
print(mydata[: 2])
# [['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]2、用 Tokenizer 构建词表(特殊token不能固定)
尝试着使用 Tokenizer 构建词表,但特殊 token(解码器的 起始/终止 符) 不能固定,所以本案例中没有用这种方法
python
# 2.读取数据集,构建平行语料的词典
def my_data():
# 每行数据的格式是【英文\t法文】,现在要把每行变成【[英文, 法文]】,即每行有一个列表分别把英文和法文装起立
# 最后把每行放到一个大列表中:[{[英文1, 法文1], [英文2, 法文2], [英文3, 法文3], ...]
with open(r'./data/eng-fra-v2.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
mydata = [[normalizeString(sentence) for sentence in line.split('\t')] for line in lines]
# print(mydata[: 2])
# [['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
special_tokens = ['START_OF_SENTENCE', 'END_OF_SENTENCE'] # 编码器 起始符号、结束符号
english_tokenizer = Tokenizer(
num_words=None,
# 因为 起始/结束符号 有下划线,所以不需要用默认的过滤
# filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', # 要自动过滤的字符(注意:不含中文标点!)
filters='', # 不设置过滤,则为空串,不是None!
lower=False, # normalizeString 已转小写,此处无需重复;但起始/结束符号为大写,故不能统一转小写。
split=' ',
oov_token='<UNK>' # 未登录词的占位符,如 '<UNK>'(必须是字符串)
)
france_tokenizer = Tokenizer(
num_words=None,
# 因为 起始/结束符号 有下划线,所以不需要用默认的过滤
# filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', # 要自动过滤的字符(注意:不含中文标点!)
filters='', #
lower=False, # normalizeString 已转小写,此处无需重复;但起始/结束符号为大写,故不能统一转小写。
split=' ',
oov_token='<UNK>' # 未登录词的占位符,如 '<UNK>'(必须是字符串)
)
# `Tokenizer` 接收的是 list[str](英文) 或者 list[list[str]](中文)
# 比如:texts = ["I love deep learning", "Deep learning is powerful"]
# 1.构建英文的词表
eng_list = [line[0] for line in mydata] # line[0]是英文,line[1]是法文
eng_list.extend(special_tokens) # 加上编码器 起始符号、结束符号
english_tokenizer.fit_on_texts(eng_list)
print(english_tokenizer.word_index)
# {'<UNK>': 1, '.': 2, 'i': 3, 're': 4, 'you': 5, 'm': 6, ...}
print(english_tokenizer.index_word)
# {1: '<UNK>', 2: '.', 3: 'i', 4: 're', 5: 'you', 6: 'm', ...}
print(english_tokenizer.word_index['START_OF_SENTENCE'], # 2803
english_tokenizer.word_index['END_OF_SENTENCE']) # 2804
# 2. 构建法文的词表
fran_list = [line[1] for line in mydata]
fran_list.extend(special_tokens) # 加上编码器 起始符号、结束符号
france_tokenizer.fit_on_texts(fran_list)
print(france_tokenizer.word_index)
# {'<UNK>': 1, '.': 2, 'je': 3, 'suis': 4, 'est': 5, 'vous': 6, ...}
print(france_tokenizer.index_word)
# {1: '<UNK>', 2: '.', 3: 'je', 4: 'suis', 5: 'est', 6: 'vous', ...}
print(france_tokenizer.word_index['START_OF_SENTENCE'], # 4345
france_tokenizer.word_index['END_OF_SENTENCE']) # 43463、合并字典
使用 | 运算符(Python 3.9+)
python
dict1 = {'a': 1, 'b': 2}
dict2 = {'c': 3, 'd': 4}
merged = dict1 | dict2
print(merged) # 输出: {'a': 1, 'b': 2, 'c': 3, 'd': 4}- 特点:返回新字典,不修改原字典。
- 同样,右边的字典值会覆盖左边重复的键。
还可以就地合并(修改原字典):
python
dict1 |= dict2
print(dict1) # dict1 被修改4、构建词表
python
# 2.读取数据集,构建平行语料的词典
def my_data():
# 每行数据的格式是【英文\t法文】,现在要把每行变成【[英文, 法文]】,即每行有一个列表分别把英文和法文装起立
# 最后把每行放到一个大列表中:[{[英文1, 法文1], [英文2, 法文2], [英文3, 法文3], ...]
with open(r'./data/eng-fra-v2.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
mydata = [[normalizeString(sentence) for sentence in line.split('\t')] for line in lines]
print(mydata[: 2])
# [['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
# 构建词表: word: index
eng_word_index = {} | special_tokens # 英文词表 【合并字典:使用 | 运算符(Python 3.9+)】
fran_word_index = {} | special_tokens # 法文词表
for line in mydata:
# line[0]: 英文句子 line[1]: 法文句子
# 英文词表
for eng_word in line[0].split(' '):
if eng_word not in eng_word_index:
# 可以再使用一个变量记录编号的变化,再 eng_word_index[eng_word] = cnt
eng_word_index[eng_word] = len(eng_word_index)
# 法文词表
for fran_word in line[1].split(' '):
if fran_word not in fran_word_index:
fran_word_index[fran_word] = len(fran_word_index)
print(eng_word_index) # {'START_OF_SENTENCE': 0, 'END_OF_SENTENCE': 1, 'UNK': 2, 'i': 3, 'm': 4, ...}
print(fran_word_index) # {'START_OF_SENTENCE': 0, 'END_OF_SENTENCE': 1, 'UNK': 2, 'j': 3, 'ai': 4, ...}
# 构建词表: index: word
eng_index_word = {value: key for key, value in eng_word_index.items()}
fran_index_word = {value: key for key, value in fran_word_index.items()}
print(eng_index_word) # {0: 'START_OF_SENTENCE', 1: 'END_OF_SENTENCE', 2: 'UNK', 3: 'i', 4: 'm', ...}
print(fran_index_word) # {0: 'START_OF_SENTENCE', 1: 'END_OF_SENTENCE', 2: 'UNK', 3: 'j', 4: 'ai', ...}
return (mydata, # 每行 英文+法文,[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
eng_word_index, # 英文词表 word: index
fran_word_index, # 法文词表 word: index
eng_index_word, # 英文词表 index: word
fran_index_word, # 法文词表 index: word
len(eng_word_index), # 英文词表长度
len(fran_word_index) # 法文词表长度
)5、get(str, default) 安全取值
一、字典的 .get() 方法是什么?
Python 中,字典(dict)提供了一个安全取值的方法:.get(key, default)。
它的语法是:
python
dict.get(key, default_value)- 如果
key存在于字典中,就返回对应的值; - 如果
key不存在 ,就返回你指定的default_value(默认值),而不会报错。
💡 对比:如果直接用
dict[key]取值,当key不存在时,会抛出KeyError异常!
二、举个简单例子
python
d = {'apple': 10, 'banana': 20}
# 正常取值
print(d.get('apple', -1)) # 输出: 10
# key 不存在,返回默认值
print(d.get('orange', -1)) # 输出: -1
# 如果不用 .get(),直接 d['orange'] 会报错:
# KeyError: 'orange'6、避免在 Dataset 中使用 .to(device)
📌 PyTorch 数据加载最佳实践:避免在 Dataset 或 collate_fn 中使用 .to(device)
❌ 问题
在自定义 Dataset 的 __getitem__ 方法中,或在 collate_fn 中直接调用 .to(device)(例如将张量移至 GPU)。
✅ 正确做法
Dataset和collate_fn应始终返回 CPU 上的张量。- 在 训练/验证循环中 (即主进程中),再统一将 batch 数据通过
.to(device)移动到目标设备(如 GPU)。
🔍 原因
- 当
DataLoader启用多进程(num_workers > 0)时,每个子进程会独立尝试初始化 CUDA 上下文。 - CUDA 不支持在多个进程间安全共享 GPU 上下文,容易引发 CUDA initialization error、死锁、显存泄漏或程序崩溃。
- PyTorch 官方明确建议:数据加载和预处理应在 CPU 上完成,设备迁移应在主训练循环中进行,以确保兼容性和稳定性。
💡 示例
python
# Dataset 中(正确):
def __getitem__(self, idx):
data = torch.tensor(...) # 默认在 CPU
return data
# 训练循环中(正确):
for batch in dataloader:
batch = batch.to(device) # 在主进程中统一移到 GPU
output = model(batch)⚠️ 即使设置
num_workers=0(单进程),也不推荐 在Dataset或collate_fn中使用.to(device),因为这会降低代码的可移植性和可维护性。保持数据加载与设备逻辑解耦是更稳健的设计。
7、构建数据集 Dataset
python
# 3.构建 DataSet
class MyDataset(Dataset):
def __init__(self, mydata, eng_word_index, fran_word_index):
super().__init__()
self.mydata = mydata # 英文+法文,[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
self.eng_word_index = eng_word_index
self.fran_word_index = fran_word_index
def __len__(self):
return len(self.mydata)
def __getitem__(self, index):
if index < 0 or index >= len(self.mydata):
print('MyDataset 中 getitem 的 index 下标越界')
index = min(max(0, index), len(self.mydata) - 1)
eng_sentence = self.mydata[index][0] # 英文句子 i m .
fran_sentence = self.mydata[index][1] # 法文句子 j ai ans .
# 句子用 ID 替换
# 可以安全取值: 如果 word 不在词表中,则用 eng_word_index['UNK']
eng_sentence = [self.eng_word_index.get(word, self.eng_word_index['UNK']) for word in eng_sentence.split(' ')]
fran_sentence = [self.fran_word_index.get(word, self.fran_word_index['UNK']) for word in fran_sentence.split(' ')]
# eng_sentence = [self.eng_word_index[word] for word in eng_sentence.split(' ')]
# fran_sentence = [self.fran_word_index[word] for word in fran_sentence.split(' ')]
# 重点:给我每个 法文 句子后面加上结束符,模型才能学到结束符
# 但:不在 Dataset 里给 法文 句子添加 SOS
fran_sentence.append(special_tokens['END_OF_SENTENCE'])
# print(eng_sentence) # [3, 4, 5]
# print(fran_sentence) # [3, 4, 5, 6, 1]
# 把句子转成张量
# Dataset中 返回 CPU 张量,在训练循环中统一 .to(device)。
# 避免 DataLoader 多进程时 GPU 冲突(PyTorch 官方推荐)
# tensor_eng_sentence = torch.tensor(data=eng_sentence, device=device)
tensor_eng_sentence = torch.tensor(data=eng_sentence)
tensor_fran_sentence = torch.tensor(data=fran_sentence)
return tensor_eng_sentence, tensor_fran_sentence
if __name__ == '__main__':
(mydata,
eng_word_index,
fran_word_index,
eng_index_word,
fran_index_word,
len_eng_word_index,
len_fran_word_index) = my_data()
a = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
print(a[0])
# (tensor([3, 4, 5], device='cuda:0'), tensor([3, 4, 5, 6, 1], device='cuda:0'))
8、构建数据加载器 DataLoader
python
# 4.构建DataLoader
def get_dataloader(mydata, eng_word_index, fran_word_index):
my_dataset = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
for eng_sen, fran_sen in my_dataloader:
print('构建DataLoader:', eng_sen) # 比如: tensor([[130, 79, 304, 45, 5]], device='cuda:0')
print('构建DataLoader:', eng_sen.shape) # torch.Size([1, 5])
print('构建DataLoader:', fran_sen) # 比如: tensor([[119, 215, 122, 63, 6, 1]], device='cuda:0')
print('构建DataLoader:', fran_sen.shape) # torch.Size([1, 6])
break
return my_dataloader
if __name__ == '__main__':
(mydata,
eng_word_index,
fran_word_index,
eng_index_word,
fran_index_word,
len_eng_word_index,
len_fran_word_index) = my_data()
get_dataloader(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
3.3 构建基于GRU的编码器和解码器
1、构建GRU 编码器 模型并测试
python
# 5.构建 GRU 编码器
class EncoderGRU(nn.Module):
def __init__(self, eng_vocabulary_size: int, embed_dim: int, gru_hid_dim: int):
super().__init__()
self.eng_vocabulary_size = eng_vocabulary_size
self.embed_dim = embed_dim
self.gru_hid_dim = gru_hid_dim
# 词嵌入层
# Embedding: 输入形状:`(序列长度,)` → 比如 `(3,)`
# 输出形状:`(序列长度, embedding_dim)` → 比如 `(3, 64)`
self.embed = nn.Embedding(num_embeddings=self.eng_vocabulary_size, embedding_dim=self.embed_dim)
# GRU层
self.gru = nn.GRU(input_size=self.embed_dim, hidden_size=self.gru_hid_dim, batch_first=True)
def forward(self, x, hidden=None):
# 比如: x.shape = (1, 5), 表示 N=1, T=5
x = self.embed(x) # 经过词嵌入,x.shape= (1, 5, self.embed_dim),符合 GRU 输入
# output: (batch, seq_len, D × H_out)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# hn: (num_layers × num_directions, batch, hidden_size)
output, hn = self.gru(x, hidden)
return output, hn
# 测试编码器
def taste_encoder(eng_vocabulary_size, embed_dim, gru_hid_dim, mydata, eng_word_index, fran_word_index):
my_dataset = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
encoder_gru = EncoderGRU(eng_vocabulary_size=eng_vocabulary_size, embed_dim=embed_dim, gru_hid_dim=gru_hid_dim)
encoder_gru.to(device=device)
for eng_sen, fran_sen in my_dataloader:
print('测试编码器:', eng_sen) # 比如: tensor([[ 76, 16, 471, 746, 5]], device='cuda:0')
print('测试编码器:', eng_sen.shape) # 比如: torch.Size([1, 5])
print('测试编码器:', fran_sen) # 比如: tensor([[ 120, 116, 249, 1384, 871, 6, 1]], device='cuda:0')
print('测试编码器:', fran_sen.shape) # 比如: torch.Size([1, 7])
output, hn = encoder_gru(eng_sen)
print('测试编码器:', output.shape) # torch.Size([1, 5, 128])
print('测试编码器:', hn.shape) # torch.Size([1, 1, 128])
break
if __name__ == '__main__':
(mydata,
eng_word_index,
fran_word_index,
eng_index_word,
fran_index_word,
len_eng_word_index,
len_fran_word_index) = my_data()
taste_encoder(len_eng_word_index, 64, 128, mydata, eng_word_index, fran_word_index)
2、构建不带注意力的 GRU 解码器 模型并测试
注意,这里简化了的,没有那些张量拼接操作
python
# 6.构建不带注意力的 GRU 解码器
class DecoderGRU(nn.Module):
def __init__(self, fran_vocabulary_size: int, embed_dim: int, gru_hid_dim: int):
super().__init__()
self.fran_vocabulary_size = fran_vocabulary_size
self.embed_dim = embed_dim
self.gru_hid_dim = gru_hid_dim
# 词嵌入层
self.embed = nn.Embedding(num_embeddings=self.fran_vocabulary_size, embedding_dim=self.embed_dim)
# GRU层
self.gru = nn.GRU(input_size=embed_dim, hidden_size=self.gru_hid_dim, batch_first=True)
# linear层,用作输出 logits 进行分类
# 因为要进行分类,所以输出大小就是词表大小
self.linear = nn.Linear(in_features=self.gru_hid_dim, out_features=self.fran_vocabulary_size)
def forward(self, x, hidden=None):
# 解码器的输入只有一个词,即 x.shape = (1, 1)
x = self.embed(x) # x.shape = (1, 1, self.embed_dim)
# 注意,在词嵌入层后面,通常不需要(也不应该)添加ReLU激活函数
# 词嵌入本身可以包含负值,这是合理的
# output: (batch, seq_len, D × H_out)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# hn: (num_layers × num_directions, batch, hidden_size)
output, hn = self.gru(x, hidden)
x = output[0] # (1, hidden_size)
logits = self.linear(x) # 原始得分, (1, self.fran_vocabulary_size)
return logits, hn # 一定要返回 hn,因为预测下一个词需要hn
# 测试不带注意力的 GRU 解码器(没有进行完整的训练)
def taste_DecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index):
my_dataloader = get_dataloader(mydata, eng_word_index, fran_word_index)
# 编码器
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=64, gru_hid_dim=128)
my_encoder.to(device=device)
# 解码器
my_decoder = DecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=64, gru_hid_dim=128)
my_decoder.to(device=device)
for eng_sen, fran_sen in my_dataloader:
# 编码器 对 英文 就行处理
output, hn = my_encoder(eng_sen)
# 对于 解码器,是把 法文 句子里的每个单词拿来一个一个喂给模型, 不是一次性喂完整个句子
# 遍历法文句子
print('法文句子形状:', fran_sen.shape) # torch.Size([1, 7])
for i in range(fran_sen.size(dim=1)): # tensor.size(dim) 取第 dim 维的数值
word_id = fran_sen[0, i] # 取第0维 第i个 数
print('遍历法文句子,单个 token:', word_id, word_id.shape) # tensor(146, device='cuda:0') torch.Size([]) 这是标量张量,是0维,不是1维
# 由于模型输入得是 (1, 1), 即 N=1, T=1, 得改变形状
word_id = word_id.reshape(1, 1)
print('改变法文 token 形状:', word_id, word_id.shape) # tensor([[146]], device='cuda:0') torch.Size([1, 1])
# 首次时,把 编码器 的最后一个隐藏状态当作中间张量 c
# 返回的隐藏状态直接覆盖原来的 hn,下次传入的隐藏状态就是解码器上次的隐藏状态了
# 所以传入的隐藏状态 和 返回的隐藏状态,两者变量名必须一致
logits, hn = my_decoder(word_id, hn)
# 接下来就可以用 logits 进行分类任务,得出下一个词
# 再进行损失函数计算、反向传播、...
break
break
3、torch.nn.functional.relu 和 torch.relu
✅ 结论(先说答案):
torch.relu和torch.nn.functional.relu是完全相同的函数对象。它们不仅功能一样,在内存中就是同一个东西。
torch.sum 并不属于 torch.nn.functional(通常简写为 F),而是属于 torch 顶层命名空间 的张量操作函数。
原因解释:
-
torch.nn.functional(即torch.nn.functional或F)主要包含的是 神经网络相关的函数式操作,比如:- 激活函数:
F.relu,F.sigmoid,F.softmax - 损失函数:
F.cross_entropy,F.mse_loss - 卷积、池化等:
F.conv2d,F.max_pool2d
这些函数的特点是:无状态(不包含可学习参数),用于构建网络层的函数式版本。
- 激活函数:
-
而
torch.sum是一个 通用的张量数学/归约操作,和神经网络没有直接关系。类似的还有:torch.meantorch.maxtorch.mintorch.prodtorch.norm
这些都属于 张量操作(tensor operations) ,定义在
torch主命名空间下。
正确用法:
python
import torch
import torch.nn.functional as F
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
# ✅ 正确:使用 torch.sum
s = torch.sum(x)
# ❌ 错误:torch.nn.functional 中没有 sum
# s = F.sum(x) # AttributeError!小技巧:
如果你不确定某个函数在哪儿,可以:
- 查官方文档:https://pytorch.org/docs/stable/
- 在 Python 中用
dir(torch)或dir(F)看有哪些属性 - 直接尝试
torch.sum------ 大多数张量操作都在torch.下
你可以用代码验证:
python
import torch
import torch.nn.functional as F
print(torch.relu is F.relu) # 输出: True
print(torch.relu is torch.nn.functional.relu) # 输出: True所以:
torch.relu(x)F.relu(x)torch.nn.functional.relu(x)
这三种写法完全等价,没有任何性能、功能或实现上的差异。
🔍 那为什么要有两个名字?
这是 PyTorch 的便利性设计(syntactic sugar):
| 写法 | 优点 | 适用场景 |
|---|---|---|
torch.relu(x) |
更短,无需额外 import | 快速脚本、交互式调试(如 Jupyter) |
F.relu(x) |
语义清晰,表明这是"神经网络功能函数" | 正式代码、模型实现(社区惯例) |
PyTorch 把 torch.nn.functional 中最常用的函数(如 relu, softmax, cross_entropy 等)直接暴露到 torch 顶层命名空间,方便用户快速调用。
💡 类似地:
torch.softmax≡F.softmaxtorch.dropout≡F.dropouttorch.sigmoid≡F.sigmoid
但注意:不是所有 F.xxx 都有 torch.xxx 别名。例如:
python
torch.adaptive_avg_pool2d # ❌ 不存在
F.adaptive_avg_pool2d # ✅ 存在所以为了代码可读性和一致性 ,官方教程和社区更推荐使用 F.relu 这种写法------因为它明确告诉你:"这是一个神经网络相关的函数操作"。
✅ 总结
| 问题 | 答案 |
|---|---|
torch.relu 和 F.relu 有区别吗? |
❌ 完全没有区别,是同一个函数 |
| 哪个更好? | - 快速测试用 torch.relu- 正式代码用 F.relu(更规范) |
| "不保存参数"是什么意思? | 它们都是纯函数 :输入张量 → 输出张量,不维护任何内部状态或配置,调用完就结束 |
📝 所以你完全可以把
torch.relu看作F.relu的一个快捷方式,就像np.array和numpy.array的关系一样。
4、构建带注意力的 GRU 解码器
注意,这里面设计的许多公式、张量维度操作,都在**《交叉注意力(Cross-Attention) (最常见)》**中
python
# 7.构建带注意力的 GRU 解码器
class AttnDecoderGRU(nn.Module):
def __init__(self, fran_vocabulary_size: int, embed_dim: int, encoder_hid_dim: int, decoder_hid_dim: int):
super().__init__()
self.fran_vocabulary_size = fran_vocabulary_size # 法文词表大小
self.embed_dim = embed_dim # 词嵌入维度
self.encoder_hid_dim = encoder_hid_dim # 编码器隐藏状态
self.decoder_hid_dim = decoder_hid_dim # 解码器隐藏状态
# 词嵌入层, 负责把输入的 词ID 转成向量
self.embed = nn.Embedding(num_embeddings=self.fran_vocabulary_size, embedding_dim=self.embed_dim)
# 解码器 GRU 层
# 详情在: 《为什么建议 编码器隐藏状态 = 解码器隐藏状态 = 解码器输入词嵌入维度》
# 但这里展示了原理: 编码器隐藏状态、解码器隐藏状态、解码器输入词嵌入维度 这是三个变量,他们完全可以互不相同
self.gru = nn.GRU(input_size=self.encoder_hid_dim + self.embed_dim,
hidden_size=self.decoder_hid_dim,
batch_first=True)
# linear 层,用于输出预测词的 logits
self.linear = nn.Linear(in_features=self.decoder_hid_dim, out_features=self.fran_vocabulary_size)
def forward(self, x, q, k, v):
# 使用的是【缩放点积注意力】
# x: 当前输入的词, 使用 Teaching Forcing, 所以只有一个词, x.shape = (N, T) = (1, 1)
# q: 解码器上一个隐藏状态, (num_layers × num_directions, batch, hidden_size) = (1, 1, self.decoder_hid_dim)
# k: 编码器的所有隐藏状态, (batch, seq_len, D × H_out) = (1, seq_len, self.encoder_hid_dim)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# v: 编码器的所有隐藏状态,当前计算方式下, v = k
hidden = q # 保存原始 q 用于 解码器GRU 的 hidden 输入
# 1. 词嵌入:将词 ID 转为向量
x = self.embed(x) # 得到词向量, x.shape = (N, T, self.embed_dim) = (1, 1, self.embed_dim)
# 2. 准备 Query 向量
# 矩阵形式,高效并行: e = Kq
# 第 0 维(即 num_layers × num_directions)不是注意力计算的重点,它只是 RNN 模型结构的副产品。
# 真正参与注意力计算的 Query 向量,只关心 (batch, d) 这两维。
q = q.squeeze(dim=0) # (batch, self.decoder_hid_dim)
q = q.unsqueeze(dim=-1) # (batch, self.decoder_hid_dim, 1) 便于与 K 做 bmm
# 3. 计算注意力分数:score = K @ q (点积)
# K: (N, src_len, encoder_hid_dim), q: (N, decoder_hid_dim, 1)
# ⚠️ 要求 encoder_hid_dim == decoder_hid_dim,否则矩阵乘法失败
# (batch, seq_len, self.encoder_hid_dim) x (batch, self.decoder_hid_dim, 1) = (batch, seq_len, 1)
# 根号下的 d 是点积注意力中 Query 和 Key 向量的共同维度
score = torch.bmm(k, q).squeeze(dim=-1) # 最后一个 `1` 是因为 Q 被当成列向量引入的冗余维度
score = score / math.sqrt(self.decoder_hid_dim) # 缩放点积,防梯度消失
# print('注意力分数形状:', score.shape) # (batch, seq_len) = torch.Size([1, 4]), 表示: 1个样本, 对解码器的 7 隐藏状态的分数
# 可以一行搞定
# score = torch.bmm(k, q.squeeze(0).unsqueeze(-1)).squeeze(dim=-1) / math.sqrt(self.decoder_hid_dim)
# 4. 计算注意力权重
# 计算每个 batch 中的每个隐藏状态的权重
attn = F.softmax(score, dim=1)
# print(f'注意力权重: {attn}') # tensor([[0.2143, 0.2231, 0.2563, 0.3062]], device='cuda:0', grad_fn=<SoftmaxBackward0>)
# print('注意力权重形状:', attn.shape) # torch.Size([1, 4])
# 5. 加权融合 Value 得到上下文张量 c
# 目的: 对每个 batch: seq_len 个权重 分别乘以每个隐藏状态得到 seq_len 个变化的隐藏状态,再把这 seq_len 个变化的隐藏状态相加, 得到上下文张量c
# v: (batch, seq_len, self.encoder_hid_dim)
# attn: (batch, seq_len)
# 为了能进行计算, 需要对 attn 进行升维度 -> (batch, 1, seq_len), 维度中的 1 就是冗余维度
# 使用矩阵乘法,(1, n) x (n, m) = (1, m) 向量级理解,融合向量
c = torch.bmm(attn.unsqueeze(dim=1), v)
# print('上下文张量 c 形状:', c.shape) # torch.Size([1, 1, 128]),1 个样本,产生了 1 个上下文向量,该向量是 128 维
# 6. 拼接词嵌入与上下文向量,作为 GRU 输入
# 移除注意力融合产生的冗余维度(不是时间步维度)
c = c.squeeze(dim=1) # 从[batch, 1(fusion), hidden]到[batch, hidden]
# print(c.shape) # torch.Size([1, 128])
# 为拼接添加时间步维度。将给解码器输入的词(1, 1, self.embed_dim) 和 上下文张量c(1, 128) 进行拼接
c_expanded = c.unsqueeze(dim=1) # 从[batch, hidden]到[batch, 1(time), hidden]
x = torch.cat([x, c_expanded], dim=-1) # 拼接输入的词向量、上下文张量c
# print('拼接 上下文张量c、当前输入的词 形状:', x.shape) # torch.Size([1, 1, 256]),这个256就是解码器的输入维度
# 7. GRU 前向传播
# output: (batch, seq_len, D × H_out)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# hn: (num_layers × num_directions, batch, hidden_size)
output, hn = self.gru(x, hidden)
# 8. 用当前隐藏状态预测下一个词
# 如果 num_layers=1 → hn.shape = (1, N, H) → reshape 后 (N, H) ✅
# 如果 num_layers=2 → hn.shape = (2, N, H) → reshape 后 (2*N, H) ❌(多出一层)
# 正确做法:只取最后一层的隐藏状态(解码器不用双向RNN)
logits = self.linear(hn[-1])
# 返回注意力权重 attn, 便于可视化和分析注意力机制
return logits, hn, attn # logits预测下一个词的原始分, hn 当前时间步的隐藏状态
# 测试待注意力的 GRU 解码器
def taste_AttnDecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index):
my_dataloader = get_dataloader(mydata, eng_word_index, fran_word_index)
# 编码器
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=64, gru_hid_dim=128)
my_encoder.to(device=device)
# 解码器
my_decoder = AttnDecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=128, encoder_hid_dim=128, decoder_hid_dim=128)
my_decoder.to(device=device)
for eng_sen, fran_sen in my_dataloader:
# 编码器 对 英文 就行处理
output, hn = my_encoder(eng_sen)
# 对于 解码器,是把 法文 句子里的每个单词拿来一个一个喂给模型, 不是一次性喂完整个句子
# 遍历法文句子
# print(fran_sen.shape) # torch.Size([1, 8])
for i in range(fran_sen.size(dim=1)): # tensor.size(dim) 取第 dim 维的数值
word_id = fran_sen[0, i] # 取第0维 第i个 数值
print('测试注意力解码器:', word_id, word_id.shape) # tensor(119, device='cuda:0') torch.Size([]),这是标量张量,是0维,不是1维
# 由于模型输入得是 (1, 1), 即 N=1, T=1, 得改变形状
word_id = word_id.reshape(1, 1)
print('测试注意力解码器:', word_id, word_id.shape) # tensor([[119]], device='cuda:0') torch.Size([1, 1])
# 首次时,把 编码器 的最后一个隐藏状态当作中间张量 c
# 返回的隐藏状态直接覆盖原来的 hn,下次传入的隐藏状态就是解码器上次的隐藏状态了
# 所以传入的隐藏状态 和 返回的隐藏状态,两者变量名必须一致
logits, hn, attn = my_decoder(word_id, hn, output, output)
# 接下来就可以用 logits 进行分类任务,得出下一个词
# 再进行损失函数计算、反向传播、...
break
break
if __name__ == '__main__':
(mydata,
eng_word_index,
fran_word_index,
eng_index_word,
fran_index_word,
len_eng_word_index,
len_fran_word_index) = my_data()
taste_AttnDecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index)
3.4 构建模型训练函数, 并进行训练
1、teacher_forcing 介绍
在《训练过程(Teacher Forcing 模型优化方法)》有详情
链接:从 Encoder-Decoder 到 Teacher Forcing:Seq2Seq 机器翻译的完整原理与实现细节全解析
2、teacher_forcing的作用
- 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大.
- teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳.
3、Seq2Seq架构的优化器需要几个------1个即可
❓ 核心疑问
在 Seq2Seq(如带注意力的 GRU)模型中,损失函数只在解码器输出端 计算,那为什么还要给编码器设置优化器 ?
到底应该用 一个优化器 还是 两个优化器(分别用于编码器和解码器)?
✅ 核心结论
- 梯度能自动从解码器反向传播到编码器 ,因为编码器的输出(如隐藏状态
hn或所有时间步的output)是解码器前向计算的输入。 - 是否使用一个或两个优化器,不影响梯度计算,也不影响最终训练效果------只要所有需要训练的参数都被某个优化器覆盖。
.backward()负责计算梯度,.step()负责更新参数,.zero_grad()负责清零梯度,这是三个独立但连贯的操作阶段。
🔍 原理详解
- 梯度是如何传到编码器的?
尽管损失仅在解码器端计算:
python
loss = criterion(decoder_output, target)但解码器的输入依赖于编码器的输出:
python
encoder_outputs, hn = encoder(src) # ← 编码器前向
logits, _ = decoder(tgt, hn, encoder_outputs) # ← 解码器用到了编码器结果
score = torch.bmm(k, q).squeeze(dim=-1) # k 是来自编码器的结果
c = torch.bmm(attn.unsqueeze(dim=1), v) # v 也是来自编码器的结果,那么 c 就跟编码器相关,计算图就会构建
c_expanded = c.unsqueeze(dim=1)
x = torch.cat([x, c_expanded], dim=-1)
output, hn = self.gru(x, hidden) # 解码器的输入都跟 c 有关,那么 output、hn 结根编码器有关PyTorch 的自动微分系统会构建完整计算图:
src → [Encoder] → (hn, outputs) → [Decoder] → logits → loss调用 loss.backward() 后,梯度会沿此图自动回传至编码器的所有可训练参数 (前提是 requires_grad=True,默认满足)。
✅ 关键 :只要张量未被
.detach(),且参与了前向计算,梯度就能回传。
更具体地说:
-
loss.backward()计算损失对logits的梯度 -
logits来自decoder_hidden(通过self.linear(hn[-1])) -
decoder_hidden来自GRU层,而GRU的输入包含:x(词嵌入)c(上下文向量)
-
关键 :
c来自encoder_output的加权和:pythonc = torch.bmm(attn.unsqueeze(dim=1), v) # v = encoder_output -
因此,梯度通过
c→encoder_output→encoder_parameters
- 优化器的作用是什么?
| 步骤 | 函数 | 作用 |
|---|---|---|
| 清零梯度 | optimizer.zero_grad() |
将参数的 .grad 置为 None 或 0,防止梯度累积 |
| 计算梯度 | loss.backward() |
遍历计算图,为所有参与前向的参数计算并累加 .grad |
| 更新参数 | optimizer.step() |
读取 .grad,按优化算法(如 Adam)更新参数值 |
⚠️ 注意:优化器不参与梯度计算 ,它只负责"应用"已算好的梯度。
同样,梯度计算与优化器数量无关,只取决于计算图是否连通。
- 一个 vs 两个优化器:有区别吗?
方案一:单优化器(推荐,简洁安全)
python
optimizer = torch.optim.Adam(
list(encoder.parameters()) + list(decoder.parameters()), # 编码器、解码器 的参数放在一个优化器里
lr=1e-3
)
optimizer.zero_grad()
loss.backward() # 计算完梯度,编码器和解码器的梯度已经算好了,就存在各自模型里
optimizer.step() # 一次性更新所有参数,这里只是把已经算好的梯度拿来更新,这一步不计算任何梯度!方案二:双优化器(合法,灵活但需谨慎)
python
enc_opt = torch.optim.Adam(encoder.parameters(), lr=1e-3)
dec_opt = torch.optim.Adam(decoder.parameters(), lr=1e-3)
enc_opt.zero_grad()
dec_opt.zero_grad()
loss.backward()
enc_opt.step()
dec_opt.step() # 必须两个都调用!对比总结:
| 维度 | 单优化器 | 双优化器 |
|---|---|---|
| 训练效果 | ✅ 完全相同 | ✅ 完全相同 |
| 代码简洁性 | ✅ 更高 | ❌ 稍冗余 |
| 超参控制 | ❌ 统一学习率等 | ✅ 可设不同学习率、权重衰减等 |
| 出错风险 | ❌ 极低 | ⚠️ 可能漏掉 .zero_grad() 或 .step() |
| 适用场景 | 大多数情况 | 需要差异化训练(如迁移学习、冻结部分网络) |
📌 当前任务建议 :用一个优化器即可,除非你明确需要对编码器/解码器使用不同学习率或训练策略。
💡 类比理解
loss.backward()→ 测量员:走完全程,记录每段路要填土(+梯度)还是挖土(-梯度),并把数据写在施工图上(.grad)。optimizer.zero_grad()→ 清空旧图纸,避免新旧数据混在一起。optimizer.step()→ 施工队:按最新图纸施工(更新参数)。- 一个施工队修整条路(单优化器);
- 两个施工队分工修(双优化器);
- 只要图纸完整、两队都干活,结果一样。
✅ 最佳实践建议
- 默认使用单优化器,代码更简洁、不易出错。
- 仅在需要时使用双优化器 ,例如:
- 编码器是预训练模型,只需微调解码器;
- 编码器和解码器使用不同学习率(如
enc_lr=1e-5,dec_lr=1e-3); - 想对不同组件应用不同优化策略(如不同 weight decay)。
- 永远确保 :
- 所有需要训练的参数都被某个优化器包含;
- 每次迭代都调用对应的
.zero_grad()和.step()。
🔚 总结一句话
梯度由
loss.backward()计算,参数由.step()更新,优化器数量只决定"如何分组执行更新",不影响梯度是否能传到编码器,也不改变训练结果。
4、1个优化器装多个模型的参数
python
optimizer = optim.Adam(params=...) # params=?✅ 简明版:
optimizer的params参数确实要求是Iterable[torch.Tensor]或Iterable[dict],而model.parameters()返回的是一个generator(属于Iterable[torch.Tensor]),所以你可以把多个模型的参数列表拼接成一个列表传入。
🔍 详细解释
model.parameters()是什么?
python
encoder.parameters() # <generator object Module.parameters at 0x...>- 它是一个 生成器(generator) ,每次
yield一个nn.Parameter(即torch.Tensor的子类)。 - 虽然是生成器,但它属于 可迭代对象(Iterable) ,满足
Iterable[torch.Tensor]的要求。
- 为什么能拼接?
python
list(encoder.parameters()) + list(decoder.parameters())list(...)将两个生成器转为普通 Python 列表;- 列表中的每个元素都是
nn.Parameter(即torch.Tensor); - 最终得到一个
List[torch.Tensor],完全符合Iterable[torch.Tensor]的类型要求。
✅ 所以以下写法合法:
python
optimizer = torch.optim.Adam(
list(encoder.parameters()) + list(decoder.parameters()),
lr=1e-3
)⚠️ 注意:不要直接拼接生成器!
❌ 错误写法(不会报错但行为错误):
python
# 千万别这样写!
optimizer = torch.optim.Adam(
encoder.parameters() + decoder.parameters(), # ❌ generator 不支持 `+`
lr=1e-3
)generator没有__add__方法,会直接报错:TypeError: unsupported operand type(s) for +: 'generator' and 'generator'
✅ 正确做法:先转成 list 再拼接。
🧩 补充:也可以用 itertools.chain 【推荐】
更高效(避免创建中间列表)的方式:
python
from itertools import chain
optimizer = torch.optim.Adam(
chain(encoder.parameters(), decoder.parameters()),
lr=1e-3
)chain返回一个惰性迭代器,内存更省,效果等价。
✅ 总结
| 写法 | 是否合法 | 说明 |
|---|---|---|
list(enc.parameters()) + list(dec.parameters()) |
✅ | 简单直观,推荐初学者使用 |
itertools.chain(enc.parameters(), dec.parameters()) |
✅ | 更高效,适合大模型 |
enc.parameters() + dec.parameters() |
❌ | 会报错,generator 不支持 + |
所以:
python
optimizer = torch.optim.Adam(
list(encoder.parameters()) + list(decoder.parameters()),
lr=1e-3
)完全正确且推荐!
5、训练一个样本的函数
python
# 9. 每 batch 样本训练(是先有 train_attn_decoder_gru 函数,才有 train_batch 函数)
def train_batch(eng_sen, fran_sen, my_encoder, my_decoder, optimizer, criterion, teacher_forcing_ratio):
# 把 英文 句子给 编码器
encoder_output, encoder_hn = my_encoder(eng_sen)
# 解码器 第一次解码,需要在句子开头加 START_OF_SENTENCE = 0
# 但不是真的把 START_OF_SENTENCE 拼接到句子上,而是 解码器 输入的 词 就是 START_OF_SENTENCE
# decoder_input: 解码器的输入
decoder_input = torch.tensor(data=[[special_tokens['START_OF_SENTENCE']]], device=device)
# print('训练batch中: 解码器 SOS 输入:', decoder_input.shape) # torch.Size([1, 1])
# 编码器最后的隐藏状态 当作解码器最开始的隐藏状态
decoder_hid = encoder_hn
# Teacher Forcing: 随机生成一个数,一个大于0.5就用该策略,否则不用
# Teacher Forcing 通常作用于句子。当然,也可以作用时间步
is_use_tf = random.random() < teacher_forcing_ratio
seq_sum_loss = 0.0 # 所有时间步的总损失
# 梯度清零
optimizer.zero_grad()
# 遍历 法文token,即遍历时间步
for i in range(fran_sen.size(dim=1)):
# 最重要的的一点: 当前 token 是 "目标",不是输入
# 改变 解码器 的隐藏状态, 使解码器能使用上一步得到的隐藏状态
logits, decoder_hid, attn = my_decoder(decoder_input, q=decoder_hid, k=encoder_output, v=encoder_output)
# print('原始得分 logits 形状:', logits.shape) # torch.Size([1, 4346]), 即 N=1, 类别=4346
# 获取当前标签,即 y 是当前的真实值
y = fran_sen[0, i].reshape(-1) # CrossEntropyLoss 的真实值输入:`(N,)` (当 input 为(N, C)
# print(f'真实值索引 {y}, 真实值 {fran_index_word[y.item()]}') # tensor([119]), vous
# print('真是值形状:', y.shape) # torch.Size([1])
# 计算损失值
seq_sum_loss += criterion(logits, y) # softmax + 损失
# 根据 is_use_tf 决定下一个时间步的输入是 真实值 还是 预测值
if is_use_tf:
decoder_input = fran_sen[0, i].reshape(1, 1)
else:
# 获取当前时间步的预测值
topv, topi = torch.topk(input=logits, k=1, dim=-1) # 获取值的大 值+索引
# print(f'topv, topi = {topv, topi}') # tensor([[0.6119]], tensor([[737]]))
# print(f'topi.shape = {topi.shape}') # torch.Size([1, 1])
# print(f'预测值: {fran_index_word[topi.item()]}') # saint
# 下一个时间步的输入使用预测值。 topi.shape 已经和输入一致了
# 待测试,加与不加 detach(),看运行时间
# 加不加 detach() ,时间运行时间几乎不变
decoder_input = topi
# print(topi.requires_grad) # False。 使用 argmax、topk 这种,默认是不可微的
# 在训练中,无论是否使用 Teacher Forcing,都要遍历完整的目标序列长度
# 训练中是没有这个 if 的!预测中才有
# if topi.item() == special_tokens['END_OF_SENTENCE']:
# break
# 反向传播
seq_sum_loss.backward()
# 梯度更新
optimizer.step()
return seq_sum_loss.item() / fran_sen.size(1) # 返回每个 token 损失,即平均损失6、构建模型训练函数
python
# 8.训练带注意力的 GRU 解码器
def train_attn_decoder_gru(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index):
# 数据集
my_dataset = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
# 数据加载器
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
# 编码器模型、解码器模型
DIM = 128 # embed_dim = encoder_hid_dim = decoder_hid_dim = DIM = 128
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=DIM, gru_hid_dim=DIM)
my_decoder = AttnDecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=DIM, encoder_hid_dim=DIM, decoder_hid_dim=DIM)
my_encoder.to(device=device)
my_decoder.to(device=device)
# 开启训练模式
my_encoder.train()
my_decoder.train()
# 把模型都放到 GPU 上(如果有 GPU 就会放在 GPU 上,如果没有 GPU 就仍然在 CPU 上)
my_encoder.to(device=device)
my_decoder.to(device=device)
# 梯度由 `loss.backward()` 计算,参数由 `.step()` 更新,
# 优化器数量只决定"如何分组执行更新",不影响梯度是否能传到编码器,也不改变训练结果。
# 详情在《Seq2Seq架构的优化器需要几个------1个即可》笔记中
optimizer = optim.Adam(params=chain(my_encoder.parameters(), my_decoder.parameters()), lr=0.001)
# 损失函数
criterion = nn.CrossEntropyLoss()
epochs = 5 # 本人电脑训练一轮需要 10~14分钟,太慢了,呜呜呜
plot_loss_list_y = [] # 记录平均损失
plot_loss_list_x = [] # 记录平均损失
plot_total_loss = 0.0 # 用于画图的总损失
print_total_loss = 0.0 # 用控制台打印的总损失
ite_num = 0 # 已训练样本个数
print_step = 1000 # 每隔 1000 个样本在屏幕上打印一次日志
save_step = 100 # 每隔 100 个样本保存一次平均损失
for epoch in range(1, epochs + 1):
# 随着 epoch 增加,逐渐减少 Teacher Forcing 的使用
teacher_forcing_ratio = max(0.0, 1.0 - epoch * 0.25) # 线性衰减,下限为 0
start_time = time.perf_counter() # 第 epoch 轮训练的起始时间
for eng_sen, fran_sen in tqdm(my_dataloader):
# 张量不会就地修改张量,而是返回一个新的张量
eng_sen = eng_sen.to(device=device) # 返回 CPU 张量,在训练循环中统一 .to(device)
fran_sen = fran_sen.to(device=device) # 返回 CPU 张量,在训练循环中统一 .to(device)
# print('句子:',eng_sen) # 比如: tensor([[ 3, 4, 304, 12, 5]], device='cuda:0')
# print('句子:',fran_sen) # 比如: tensor([[ 7, 12, 122, 21, 6, 1]], device='cuda:0')
# 返回的 loss 是值,不是张量
loss = train_batch(eng_sen, fran_sen, my_encoder, my_decoder, optimizer, criterion, teacher_forcing_ratio)
# print(f'每个 token 的平均损失: {loss}') # 8.3589(第1轮)
ite_num += eng_sen.size(0) # 获取当前 batch 样本个数
print_total_loss += loss
plot_total_loss += loss
if ite_num % print_step == 0: # 控制台打印
avg_loss = print_total_loss / ite_num # 每隔 1000 个样本,每个样本的平均损失
consume_time = time.perf_counter() - start_time # 当前 epoch 轮已耗时
print(f'当前 epoch = {epoch}, 已训练样本个数: {ite_num}, 每隔1000个样本的平均损失: {avg_loss}, 本轮轮已耗时: {consume_time}')
# 当前 epoch = 1, 已训练样本个数: 1000, 每隔1000个样本的平均损失: 4.044587318411708, 本轮轮已耗时: 9.336827200000698
print_total_loss = 0 # 每隔 1000 个样本让总损失清零
if ite_num % save_step == 0: # 保存平均损失
avg_loss = plot_total_loss / ite_num
plot_loss_list_y.append(avg_loss) # 已训练样本的平均损失
plot_loss_list_x.append(ite_num) # 已训练样本个数
torch.save(my_encoder.state_dict(), f=r'./model/my_encoder.pth')
torch.save(my_decoder.state_dict(), f=r'./model/my_decoder.pth')
plt.plot(plot_loss_list_x, plot_loss_list_y)
plt.title('engTofran')
plt.xlabel('训练样本个数')
plt.ylabel('训练样本平均损失')
plt.show()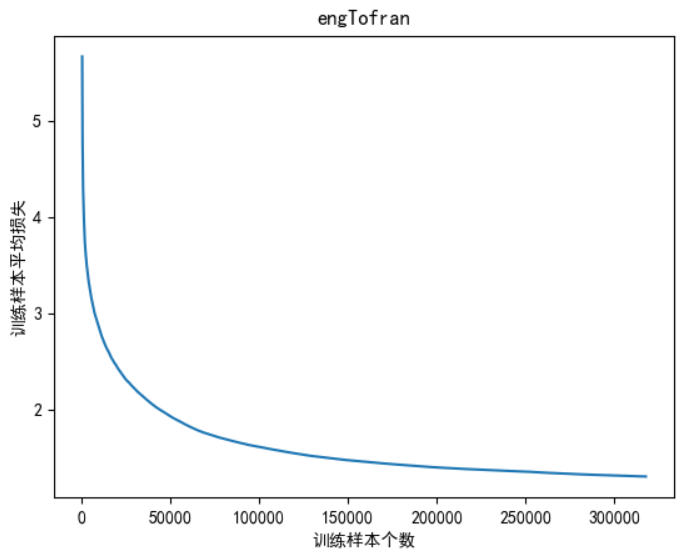
3.5 构建模型评估函数并测试
python
# 11.每个 batch 样本预测(现有 eval_attn 函数,才有这个函数的)
def predict_batch(eng_sen, fran_sen, my_encoder, my_decoder):
# 预测时,不计算任何梯度
with torch.no_grad():
encoder_output, encoder_hn = my_encoder(eng_sen)
# 在 法语 开头加特殊符,作为 解码器 的初始输入,即输入 SOS 这个词
decoder_input = torch.tensor(data=[[special_tokens['START_OF_SENTENCE']]], device=device)
# 用 编码器 最后的隐藏状态 当作 解码器 的初始隐藏状态
decoder_hn = encoder_hn
# 这是预测,当前隐藏状态为上一步的隐藏状态,而不是 Teacher Forcing 了
# 开始预测
predict_list = [] # 存储预测出来的单词
for _ in range(MAX_LENGTH): # 预测的法文长度最大长度不超过 MAX_LENGTH,防止无限预测
# attn 做一个注意力图,但那只是个展示而已,不重要。故没有做注意力图
logits, decoder_hn, attn = my_decoder(decoder_input, decoder_hn, encoder_output, encoder_output)
# print(logits.shape) # torch.Size([1, 4346])
# 使用 logits 进行预测
predict_id = logits.argmax(dim=-1)
# print(f'预测结果的id: {predict_id}') # tensor([7], device='cuda:0')
predict_word = fran_index_word[predict_id.item()]
# print(f'预测结果: {predict_word}') # je
if predict_id == special_tokens['END_OF_SENTENCE']:
# 遇到 EOS,停止生成,且不加入结果
break
predict_list.append(predict_word)
# 用当前 预测的词 作为下一时间步的输入
decoder_input = predict_id.reshape(1, 1) # 需符合解码器输入
# 训练时,是使用 空格 做了切分,所以模型是学不到空格的。故这里要用空格隔开!
return ' '.join(predict_list) # 返回预测的法文句子
# 10.预测函数
def eval_attn():
# 创建模型
DIM = 128 # embed_dim = encoder_hid_dim = decoder_hid_dim = DIM = 128
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=DIM, gru_hid_dim=DIM)
my_decoder = AttnDecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=DIM, encoder_hid_dim=DIM,
decoder_hid_dim=DIM)
my_encoder.to(device=device) # 把模型放到 设备 上
my_decoder.to(device=device) # 把模型放到 设备 上
# 加载模型
my_encoder.load_state_dict(torch.load(r'./model/my_encoder.pth', map_location=device))
my_decoder.load_state_dict(torch.load(r'./model/my_decoder.pth', map_location=device))
# 推理模式
my_encoder.eval()
my_decoder.eval()
test_data = [
['i m impressed with your french .', 'je suis impressionne par votre francais .'],
['i m more than a friend .', 'je suis plus qu une amie .'],
['she is beautiful like her mother .', 'elle est belle comme sa mere .']
]
for i, (eng_sen, fran_sen) in enumerate(test_data):
# 把句子映射到 ID
eng_sen_id = [eng_word_index.get(word, special_tokens['UNK']) for word in eng_sen.split(' ')]
fran_sen_id = [fran_word_index.get(word, special_tokens['UNK']) for word in fran_sen.split(' ')]
eng_sen_id = torch.tensor(data=eng_sen_id, device=device).reshape(1, -1) # 形状需要符合模型的输入
fran_sen_id = torch.tensor(data=fran_sen_id, device=device).reshape(1, -1) # 形状需要符合模型的输入
print(eng_sen_id) # tensor([[ 3, 4, 384, 678, 351, 85, 5]], device='cuda:0')
print(fran_sen_id) # tensor([[ 7, 12, 1676, 2312, 646, 139, 6]], device='cuda:0')
predict_fran_sen = predict_batch(eng_sen=eng_sen_id, fran_sen=fran_sen_id, my_encoder=my_encoder, my_decoder=my_decoder)
print(f'输入的英文句子: {eng_sen}')
print(f'模型预测的句子: {predict_fran_sen}')
print(f'真实的法文句子: {fran_sen}')
print('-' * 30)
# 输入的英文句子: i m impressed with your french .
# 模型预测的句子: je suis impressionnee par ton francais .
# 真实的法文句子: je suis impressionne par votre francais .
# ------------------------------
# tensor([[ 3, 4, 1207, 1167, 43, 470, 5]], device='cuda:0')
# tensor([[ 7, 12, 153, 1364, 299, 1199, 6]], device='cuda:0')
# 输入的英文句子: i m more than a friend .
# 模型预测的句子: je suis plus qu amie amie .
# 真实的法文句子: je suis plus qu une amie .
# ------------------------------
# tensor([[ 76, 41, 367, 744, 723, 1174, 5]], device='cuda:0')
# tensor([[ 120, 26, 666, 1287, 2261, 2075, 6]], device='cuda:0')
# 输入的英文句子: she is beautiful like her mother .
# 模型预测的句子: elle est mere a mere mere .
# 真实的法文句子: elle est belle comme sa mere .
if __name__ == '__main__':
(mydata,
eng_word_index,
fran_word_index,
eng_index_word,
fran_index_word,
len_eng_word_index,
len_fran_word_index) = my_data()
eval_attn()3.6、整体代码:
python
# coding: utf-8
import torch
import re
# from tensorflow.keras.preprocessing.text import Tokenizer
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import math
import torch.nn.functional as F
import torch.optim as optim
from itertools import chain
import time
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
from torchinfo import summary
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # ←←← 关键!放在最前面(解决报错)
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False # 设置正常显示符号
# 能用 GPU 就用,否则用 CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # cuda
print(f'当前设备: {device}')
# 编码器 起始符号、结束符号
special_tokens = {'START_OF_SENTENCE': 0, 'END_OF_SENTENCE': 1, 'UNK': 2}
MAX_LENGTH = 10 # 每个句子的最大长度
# 1.文本清洗工具函数(注意,本次案例中的数据是已经通过该函数处理过后的数据)
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串, 是一句英文或者一句法文"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
# # 2.读取数据集,构建平行语料的词典(用 Tokenizer 构建词表,特殊token不能固定,所以本案例中没有用这种方法
# def my_data_abandon():
# # 每行数据的格式是【英文\t法文】,现在要把每行变成【[英文, 法文]】,即每行有一个列表分别把英文和法文装起立
# # 最后把每行放到一个大列表中:[{[英文1, 法文1], [英文2, 法文2], [英文3, 法文3], ...]
#
# with open(r'./data/eng-fra-v2.txt', mode='r', encoding='utf-8') as f:
# lines = f.readlines()
#
# mydata = [[normalizeString(sentence) for sentence in line.split('\t')] for line in lines]
# # print(mydata[: 2])
# # [['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
#
# special_tokens = ['START_OF_SENTENCE', 'END_OF_SENTENCE'] # 编码器 起始符号、结束符号
#
# english_tokenizer = Tokenizer(
# num_words=None,
#
# # 因为 起始/结束符号 有下划线,所以不需要用默认的过滤
# # filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', # 要自动过滤的字符(注意:不含中文标点!)
#
# filters='', # 不设置过滤,则为空串,不是None!
# lower=False, # normalizeString 已转小写,此处无需重复;但起始/结束符号为大写,故不能统一转小写。
# split=' ',
# oov_token='<UNK>' # 未登录词的占位符,如 '<UNK>'(必须是字符串)
# )
#
# france_tokenizer = Tokenizer(
# num_words=None,
#
# # 因为 起始/结束符号 有下划线,所以不需要用默认的过滤
# # filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', # 要自动过滤的字符(注意:不含中文标点!)
#
# filters='', #
# lower=False, # normalizeString 已转小写,此处无需重复;但起始/结束符号为大写,故不能统一转小写。
# split=' ',
# oov_token='<UNK>' # 未登录词的占位符,如 '<UNK>'(必须是字符串)
# )
#
# # `Tokenizer` 接收的是 list[str](英文) 或者 list[list[str]](中文)
# # 比如:texts = ["I love deep learning", "Deep learning is powerful"]
#
# # 1.构建英文的词表
# eng_list = [line[0] for line in mydata] # line[0]是英文,line[1]是法文
# eng_list.extend(special_tokens) # 加上编码器 起始符号、结束符号
# english_tokenizer.fit_on_texts(eng_list)
#
# print(english_tokenizer.word_index)
# # {'<UNK>': 1, '.': 2, 'i': 3, 're': 4, 'you': 5, 'm': 6, ...}
# print(english_tokenizer.index_word)
# # {1: '<UNK>', 2: '.', 3: 'i', 4: 're', 5: 'you', 6: 'm', ...}
# print(english_tokenizer.word_index['START_OF_SENTENCE'], # 2803
# english_tokenizer.word_index['END_OF_SENTENCE']) # 2804
#
# # 2. 构建法文的词表
# fran_list = [line[1] for line in mydata]
# fran_list.extend(special_tokens) # 加上编码器 起始符号、结束符号
# france_tokenizer.fit_on_texts(fran_list)
#
# print(france_tokenizer.word_index)
# # {'<UNK>': 1, '.': 2, 'je': 3, 'suis': 4, 'est': 5, 'vous': 6, ...}
# print(france_tokenizer.index_word)
# # {1: '<UNK>', 2: '.', 3: 'je', 4: 'suis', 5: 'est', 6: 'vous', ...}
# print(france_tokenizer.word_index['START_OF_SENTENCE'], # 4345
# france_tokenizer.word_index['END_OF_SENTENCE']) # 4346
#
# # return ...
# 2.读取数据集,构建平行语料的词典
def my_data():
# 每行数据的格式是【英文\t法文】,现在要把每行变成【[英文, 法文]】,即每行有一个列表分别把英文和法文装起立
# 最后把每行放到一个大列表中:[{[英文1, 法文1], [英文2, 法文2], [英文3, 法文3], ...]
with open(r'./data/eng-fra-v2.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
mydata = [[normalizeString(sentence) for sentence in line.split('\t')] for line in lines]
print(mydata[: 2])
# [['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
# 构建词表: word: index
eng_word_index = {} | special_tokens # 英文词表 【合并字典:使用 | 运算符(Python 3.9+)】
fran_word_index = {} | special_tokens # 法文词表
for line in mydata:
# line[0]: 英文句子 line[1]: 法文句子
# 英文词表
for eng_word in line[0].split(' '):
if eng_word not in eng_word_index:
# 可以再使用一个变量记录编号的变化,再 eng_word_index[eng_word] = cnt
eng_word_index[eng_word] = len(eng_word_index)
# 法文词表
for fran_word in line[1].split(' '):
if fran_word not in fran_word_index:
fran_word_index[fran_word] = len(fran_word_index)
print(eng_word_index) # {'START_OF_SENTENCE': 0, 'END_OF_SENTENCE': 1, 'UNK': 2, 'i': 3, 'm': 4, ...}
print(fran_word_index) # {'START_OF_SENTENCE': 0, 'END_OF_SENTENCE': 1, 'UNK': 2, 'j': 3, 'ai': 4, ...}
# 构建词表: index: word
eng_index_word = {value: key for key, value in eng_word_index.items()}
fran_index_word = {value: key for key, value in fran_word_index.items()}
print(eng_index_word) # {0: 'START_OF_SENTENCE', 1: 'END_OF_SENTENCE', 2: 'UNK', 3: 'i', 4: 'm', ...}
print(fran_index_word) # {0: 'START_OF_SENTENCE', 1: 'END_OF_SENTENCE', 2: 'UNK', 3: 'j', 4: 'ai', ...}
return (mydata, # 每行 英文+法文,[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
eng_word_index, # 英文词表 word: index
fran_word_index, # 法文词表 word: index
eng_index_word, # 英文词表 index: word
fran_index_word, # 法文词表 index: word
len(eng_word_index), # 英文词表长度
len(fran_word_index) # 法文词表长度
)
# 3.构建 DataSet
class MyDataset(Dataset):
def __init__(self, mydata, eng_word_index, fran_word_index):
super().__init__()
self.mydata = mydata # 英文+法文,[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .']]
self.eng_word_index = eng_word_index
self.fran_word_index = fran_word_index
def __len__(self):
return len(self.mydata)
def __getitem__(self, index):
if index < 0 or index >= len(self.mydata):
print('MyDataset 中 getitem 的 index 下标越界')
index = min(max(0, index), len(self.mydata) - 1)
eng_sentence = self.mydata[index][0] # 英文句子 i m .
fran_sentence = self.mydata[index][1] # 法文句子 j ai ans .
# 句子用 ID 替换
# 可以安全取值: 如果 word 不在词表中,则用 eng_word_index['UNK']
eng_sentence = [self.eng_word_index.get(word, self.eng_word_index['UNK']) for word in eng_sentence.split(' ')]
fran_sentence = [self.fran_word_index.get(word, self.fran_word_index['UNK']) for word in fran_sentence.split(' ')]
# eng_sentence = [self.eng_word_index[word] for word in eng_sentence.split(' ')]
# fran_sentence = [self.fran_word_index[word] for word in fran_sentence.split(' ')]
# 重点:给我每个 法文 句子后面加上结束符,模型才能学到结束符
# 但:不在 Dataset 里给 法文 句子添加 SOS
fran_sentence.append(special_tokens['END_OF_SENTENCE'])
# print(eng_sentence) # [3, 4, 5]
# print(fran_sentence) # [3, 4, 5, 6, 1]
# 把句子转成张量
# Dataset中 返回 CPU 张量,在训练循环中统一 .to(device)。避免 DataLoader 多进程时 GPU 冲突(PyTorch 官方推荐)
# tensor_eng_sentence = torch.tensor(data=eng_sentence, device=device)
tensor_eng_sentence = torch.tensor(data=eng_sentence)
tensor_fran_sentence = torch.tensor(data=fran_sentence)
return tensor_eng_sentence, tensor_fran_sentence
# 4.构建DataLoader
def get_dataloader(mydata, eng_word_index, fran_word_index):
my_dataset = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
for eng_sen, fran_sen in my_dataloader:
print('构建DataLoader:', eng_sen) # 比如: tensor([[130, 79, 304, 45, 5]], device='cuda:0')
print('构建DataLoader:', eng_sen.shape) # torch.Size([1, 5])
print('构建DataLoader:', fran_sen) # 比如: tensor([[119, 215, 122, 63, 6, 1]], device='cuda:0')
print('构建DataLoader:', fran_sen.shape) # torch.Size([1, 6])
break
return my_dataloader
# 5.构建 GRU 编码器
class EncoderGRU(nn.Module):
def __init__(self, eng_vocabulary_size: int, embed_dim: int, gru_hid_dim: int):
super().__init__()
self.eng_vocabulary_size = eng_vocabulary_size
self.embed_dim = embed_dim
self.gru_hid_dim = gru_hid_dim
# 词嵌入层
# Embedding: 输入形状:`(序列长度,)` → 比如 `(3,)`
# 输出形状:`(序列长度, embedding_dim)` → 比如 `(3, 64)`
self.embed = nn.Embedding(num_embeddings=self.eng_vocabulary_size, embedding_dim=self.embed_dim)
# GRU层
self.gru = nn.GRU(input_size=self.embed_dim, hidden_size=self.gru_hid_dim, batch_first=True)
def forward(self, x, hidden=None):
# 比如: x.shape = (1, 5), 表示 N=1, T=5
x = self.embed(x) # 经过词嵌入,x.shape= (1, 5, self.embed_dim),符合 GRU 输入
# output: (batch, seq_len, D × H_out)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# hn: (num_layers × num_directions, batch, hidden_size)
output, hn = self.gru(x, hidden)
return output, hn
# 测试编码器
def taste_encoder(eng_vocabulary_size, embed_dim, gru_hid_dim, mydata, eng_word_index, fran_word_index):
my_dataset = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
encoder_gru = EncoderGRU(eng_vocabulary_size=eng_vocabulary_size, embed_dim=embed_dim, gru_hid_dim=gru_hid_dim)
encoder_gru.to(device=device)
for eng_sen, fran_sen in my_dataloader:
print('测试编码器:', eng_sen) # 比如: tensor([[ 76, 16, 471, 746, 5]], device='cuda:0')
print('测试编码器:', eng_sen.shape) # 比如: torch.Size([1, 5])
print('测试编码器:', fran_sen) # 比如: tensor([[ 120, 116, 249, 1384, 871, 6, 1]], device='cuda:0')
print('测试编码器:', fran_sen.shape) # 比如: torch.Size([1, 7])
output, hn = encoder_gru(eng_sen)
print('测试编码器:', output.shape) # torch.Size([1, 5, 128])
print('测试编码器:', hn.shape) # torch.Size([1, 1, 128])
break
# 6.构建不带注意力的 GRU 解码器
class DecoderGRU(nn.Module):
def __init__(self, fran_vocabulary_size: int, embed_dim: int, gru_hid_dim: int):
super().__init__()
self.fran_vocabulary_size = fran_vocabulary_size
self.embed_dim = embed_dim
self.gru_hid_dim = gru_hid_dim
# 词嵌入层
self.embed = nn.Embedding(num_embeddings=self.fran_vocabulary_size, embedding_dim=self.embed_dim)
# GRU层
self.gru = nn.GRU(input_size=embed_dim, hidden_size=self.gru_hid_dim, batch_first=True)
# linear层,用作输出 logits 进行分类
# 因为要进行分类,所以输出大小就是词表大小
self.linear = nn.Linear(in_features=self.gru_hid_dim, out_features=self.fran_vocabulary_size)
def forward(self, x, hidden=None):
# 解码器的输入只有一个词,即 x.shape = (1, 1)
x = self.embed(x) # x.shape = (1, 1, self.embed_dim)
# 注意,在词嵌入层后面,通常不需要(也不应该)添加ReLU激活函数
# 词嵌入本身可以包含负值,这是合理的
# output: (batch, seq_len, D × H_out)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# hn: (num_layers × num_directions, batch, hidden_size)
output, hn = self.gru(x, hidden)
x = output[0] # (1, hidden_size)
logits = self.linear(x) # 原始得分, (1, self.fran_vocabulary_size)
return logits, hn # 一定要返回 hn,因为预测下一个词需要hn
# 测试不带注意力的 GRU 解码器(没有进行完整的训练)
def taste_DecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index):
my_dataloader = get_dataloader(mydata, eng_word_index, fran_word_index)
# 编码器
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=64, gru_hid_dim=128)
my_encoder.to(device=device)
# 解码器
my_decoder = DecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=64, gru_hid_dim=128)
my_decoder.to(device=device)
for eng_sen, fran_sen in my_dataloader:
# 编码器 对 英文 就行处理
output, hn = my_encoder(eng_sen)
# 对于 解码器,是把 法文 句子里的每个单词拿来一个一个喂给模型, 不是一次性喂完整个句子
# 遍历法文句子
print('法文句子形状:', fran_sen.shape) # torch.Size([1, 7])
for i in range(fran_sen.size(dim=1)): # tensor.size(dim) 取第 dim 维的数值
word_id = fran_sen[0, i] # 取第0维 第i个 数
print('遍历法文句子,单个 token:', word_id, word_id.shape) # tensor(146, device='cuda:0') torch.Size([]) 这是标量张量,是0维,不是1维
# 由于模型输入得是 (1, 1), 即 N=1, T=1, 得改变形状
word_id = word_id.reshape(1, 1)
print('改变法文 token 形状:', word_id, word_id.shape) # tensor([[146]], device='cuda:0') torch.Size([1, 1])
# 首次时,把 编码器 的最后一个隐藏状态当作中间张量 c
# 返回的隐藏状态直接覆盖原来的 hn,下次传入的隐藏状态就是解码器上次的隐藏状态了
# 所以传入的隐藏状态 和 返回的隐藏状态,两者变量名必须一致
logits, hn = my_decoder(word_id, hn)
# 接下来就可以用 logits 进行分类任务,得出下一个词
# 再进行损失函数计算、反向传播、...
break
break
# 7.构建带注意力的 GRU 解码器
class AttnDecoderGRU(nn.Module):
def __init__(self, fran_vocabulary_size: int, embed_dim: int, encoder_hid_dim: int, decoder_hid_dim: int):
super().__init__()
self.fran_vocabulary_size = fran_vocabulary_size # 法文词表大小
self.embed_dim = embed_dim # 词嵌入维度
self.encoder_hid_dim = encoder_hid_dim # 编码器隐藏状态
self.decoder_hid_dim = decoder_hid_dim # 解码器隐藏状态
# 词嵌入层, 负责把输入的 词ID 转成向量
self.embed = nn.Embedding(num_embeddings=self.fran_vocabulary_size, embedding_dim=self.embed_dim)
# 解码器 GRU 层
# 在笔记中有详情: 《为什么建议 编码器隐藏状态 = 解码器隐藏状态 = 解码器输入词嵌入维度》
# 但这里展示了原理: 编码器隐藏状态、解码器隐藏状态、解码器输入词嵌入维度 这是三个变量,他们完全可以互不相同
self.gru = nn.GRU(input_size=self.encoder_hid_dim + self.embed_dim,
hidden_size=self.decoder_hid_dim,
batch_first=True)
# linear 层,用于输出预测词的 logits
self.linear = nn.Linear(in_features=self.decoder_hid_dim, out_features=self.fran_vocabulary_size)
def forward(self, x, q, k, v):
# 使用的是【缩放点积注意力】
# x: 当前输入的词, 使用 Teaching Forcing, 所以只有一个词, x.shape = (N, T) = (1, 1)
# q: 解码器上一个隐藏状态, (num_layers × num_directions, batch, hidden_size) = (1, 1, self.decoder_hid_dim)
# k: 编码器的所有隐藏状态, (batch, seq_len, D × H_out) = (1, seq_len, self.encoder_hid_dim)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# v: 编码器的所有隐藏状态,当前计算方式下, v = k
hidden = q # 保存原始 q 用于 解码器GRU 的 hidden 输入
# 1. 词嵌入:将词 ID 转为向量
x = self.embed(x) # 得到词向量, x.shape = (N, T, self.embed_dim) = (1, 1, self.embed_dim)
# 2. 准备 Query 向量
# 矩阵形式,高效并行: e = Kq
# 第 0 维(即 num_layers × num_directions)不是注意力计算的重点,它只是 RNN 模型结构的副产品。
# 真正参与注意力计算的 Query 向量,只关心 (batch, d) 这两维。
q = q.squeeze(dim=0) # (batch, self.decoder_hid_dim)
q = q.unsqueeze(dim=-1) # (batch, self.decoder_hid_dim, 1) 便于与 K 做 bmm
# 3. 计算注意力分数:score = K @ q (点积)
# K: (N, src_len, encoder_hid_dim), q: (N, decoder_hid_dim, 1)
# ⚠️ 要求 encoder_hid_dim == decoder_hid_dim,否则矩阵乘法失败
# (batch, seq_len, self.encoder_hid_dim) x (batch, self.decoder_hid_dim, 1) = (batch, seq_len, 1)
# 根号下的 d 是点积注意力中 Query 和 Key 向量的共同维度
score = torch.bmm(k, q).squeeze(dim=-1) # 最后一个 `1` 是因为 Q 被当成列向量引入的冗余维度
score = score / math.sqrt(self.decoder_hid_dim) # 缩放点积,防梯度消失
# print('注意力分数形状:', score.shape) # (batch, seq_len) = torch.Size([1, 4]), 表示: 1个样本, 对解码器的 7 隐藏状态的分数
# 可以一行搞定
# score = torch.bmm(k, q.squeeze(0).unsqueeze(-1)).squeeze(dim=-1) / math.sqrt(self.decoder_hid_dim)
# 4. 计算注意力权重
# 计算每个 batch 中的每个隐藏状态的权重
attn = F.softmax(score, dim=1)
# print(f'注意力权重: {attn}') # tensor([[0.2143, 0.2231, 0.2563, 0.3062]], device='cuda:0', grad_fn=<SoftmaxBackward0>)
# print('注意力权重形状:', attn.shape) # torch.Size([1, 4])
# 5. 加权融合 Value 得到上下文张量 c
# 目的: 对每个 batch: seq_len 个权重 分别乘以每个隐藏状态得到 seq_len 个变化的隐藏状态,再把这 seq_len 个变化的隐藏状态相加, 得到上下文张量c
# v: (batch, seq_len, self.encoder_hid_dim)
# attn: (batch, seq_len)
# 为了能进行计算, 需要对 attn 进行升维度 -> (batch, 1, seq_len), 维度中的 1 就是冗余维度
# 使用矩阵乘法,(1, n) x (n, m) = (1, m) 向量级理解,融合向量
c = torch.bmm(attn.unsqueeze(dim=1), v)
# print('上下文张量 c 形状:', c.shape) # torch.Size([1, 1, 128]),1 个样本,产生了 1 个上下文向量,该向量是 128 维
# 6. 拼接词嵌入与上下文向量,作为 GRU 输入
# 移除注意力融合产生的冗余维度(不是时间步维度)
c = c.squeeze(dim=1) # 从[batch, 1(fusion), hidden]到[batch, hidden]
# print(c.shape) # torch.Size([1, 128])
# 为拼接添加时间步维度。将给解码器输入的词(1, 1, self.embed_dim) 和 上下文张量c(1, 128) 进行拼接
c_expanded = c.unsqueeze(dim=1) # 从[batch, hidden]到[batch, 1(time), hidden]
x = torch.cat([x, c_expanded], dim=-1) # 拼接输入的词向量、上下文张量c
# print('拼接 上下文张量c、当前输入的词 形状:', x.shape) # torch.Size([1, 1, 256]),这个256就是解码器的输入维度
# 7. GRU 前向传播
# output: (batch, seq_len, D × H_out)
# D = 2 if bidirectional=True else 1
# H_out = proj_size if proj_size > 0 else hidden_size
# hn: (num_layers × num_directions, batch, hidden_size)
output, hn = self.gru(x, hidden)
# 8. 用当前隐藏状态预测下一个词
# 如果 num_layers=1 → hn.shape = (1, N, H) → reshape 后 (N, H) ✅
# 如果 num_layers=2 → hn.shape = (2, N, H) → reshape 后 (2*N, H) ❌(多出一层)
# 正确做法:只取最后一层的隐藏状态(解码器不用双向RNN)
logits = self.linear(hn[-1])
# 返回注意力权重 attn, 便于可视化和分析注意力机制
return logits, hn, attn # logits预测下一个词的原始分, hn 当前时间步的隐藏状态
# 测试待注意力的 GRU 解码器
def taste_AttnDecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index):
my_dataloader = get_dataloader(mydata, eng_word_index, fran_word_index)
# 编码器
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=64, gru_hid_dim=128)
my_encoder.to(device=device)
# 解码器
my_decoder = AttnDecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=128, encoder_hid_dim=128, decoder_hid_dim=128)
my_decoder.to(device=device)
for eng_sen, fran_sen in my_dataloader:
# 编码器 对 英文 就行处理
output, hn = my_encoder(eng_sen)
# 对于 解码器,是把 法文 句子里的每个单词拿来一个一个喂给模型, 不是一次性喂完整个句子
# 遍历法文句子
# print(fran_sen.shape) # torch.Size([1, 8])
for i in range(fran_sen.size(dim=1)): # tensor.size(dim) 取第 dim 维的数值
word_id = fran_sen[0, i] # 取第0维 第i个 数值
print('测试注意力解码器:', word_id, word_id.shape) # tensor(119, device='cuda:0') torch.Size([]),这是标量张量,是0维,不是1维
# 由于模型输入得是 (1, 1), 即 N=1, T=1, 得改变形状
word_id = word_id.reshape(1, 1)
print('测试注意力解码器:', word_id, word_id.shape) # tensor([[119]], device='cuda:0') torch.Size([1, 1])
# 首次时,把 编码器 的最后一个隐藏状态当作中间张量 c
# 返回的隐藏状态直接覆盖原来的 hn,下次传入的隐藏状态就是解码器上次的隐藏状态了
# 所以传入的隐藏状态 和 返回的隐藏状态,两者变量名必须一致
logits, hn, attn = my_decoder(word_id, hn, output, output)
# 接下来就可以用 logits 进行分类任务,得出下一个词
# 再进行损失函数计算、反向传播、...
break
break
# 9. 每 batch 样本训练(是先有 train_attn_decoder_gru 函数,才有 train_batch 函数)
def train_batch(eng_sen, fran_sen, my_encoder, my_decoder, optimizer, criterion, teacher_forcing_ratio):
# 把 英文 句子给 编码器
encoder_output, encoder_hn = my_encoder(eng_sen)
# 解码器 第一次解码,需要在句子开头加 START_OF_SENTENCE = 0
# 但不是真的把 START_OF_SENTENCE 拼接到句子上,而是 解码器 输入的 词 就是 START_OF_SENTENCE
# decoder_input: 解码器的输入
decoder_input = torch.tensor(data=[[special_tokens['START_OF_SENTENCE']]], device=device)
# print('训练batch中: 解码器 SOS 输入:', decoder_input.shape) # torch.Size([1, 1])
# 编码器最后的隐藏状态 当作解码器最开始的隐藏状态
decoder_hid = encoder_hn
# Teacher Forcing: 随机生成一个数,一个大于0.5就用该策略,否则不用
# Teacher Forcing 通常作用于句子。当然,也可以作用时间步
is_use_tf = random.random() < teacher_forcing_ratio
seq_sum_loss = 0.0 # 所有时间步的总损失
# 梯度清零
optimizer.zero_grad()
# 遍历 法文token,即遍历时间步
for i in range(fran_sen.size(dim=1)):
# 最重要的的一点: 当前 token 是 "目标",不是输入
# 改变 解码器 的隐藏状态, 使解码器能使用上一步得到的隐藏状态
logits, decoder_hid, attn = my_decoder(decoder_input, q=decoder_hid, k=encoder_output, v=encoder_output)
# print('原始得分 logits 形状:', logits.shape) # torch.Size([1, 4346]), 即 N=1, 类别=4346
# 获取当前标签,即 y 是当前的真实值
y = fran_sen[0, i].reshape(-1) # CrossEntropyLoss 的真实值输入:`(N,)` (当 input 为(N, C)
# print(f'真实值索引 {y}, 真实值 {fran_index_word[y.item()]}') # tensor([119]), vous
# print('真是值形状:', y.shape) # torch.Size([1])
# 计算损失值
seq_sum_loss += criterion(logits, y) # softmax + 损失
# 根据 is_use_tf 决定下一个时间步的输入是 真实值 还是 预测值
if is_use_tf:
decoder_input = fran_sen[0, i].reshape(1, 1)
else:
# 获取当前时间步的预测值
topv, topi = torch.topk(input=logits, k=1, dim=-1) # 获取值的大 值+索引
# print(f'topv, topi = {topv, topi}') # tensor([[0.6119]], tensor([[737]]))
# print(f'topi.shape = {topi.shape}') # torch.Size([1, 1])
# print(f'预测值: {fran_index_word[topi.item()]}') # saint
# 下一个时间步的输入使用预测值。 topi.shape 已经和输入一致了
# 待测试,加与不加 detach(),看运行时间
# 加不加 detach() ,时间运行时间几乎不变
decoder_input = topi
# print(topi.requires_grad) # False。 使用 argmax、topk 这种,默认是不可微的
# 在训练中,无论是否使用 Teacher Forcing,都要遍历完整的目标序列长度
# 训练中是没有这个 if 的!预测中才有
# if topi.item() == special_tokens['END_OF_SENTENCE']:
# break
# 反向传播
seq_sum_loss.backward()
# 梯度更新
optimizer.step()
return seq_sum_loss.item() / fran_sen.size(1) # 返回每个 token 损失,即平均损失
# 8.训练带注意力的 GRU 解码器
def train_attn_decoder_gru(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index):
# 数据集
my_dataset = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
# 数据加载器
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
# 编码器模型、解码器模型
DIM = 128 # embed_dim = encoder_hid_dim = decoder_hid_dim = DIM = 128
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=DIM, gru_hid_dim=DIM)
my_decoder = AttnDecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=DIM, encoder_hid_dim=DIM, decoder_hid_dim=DIM)
my_encoder.to(device=device)
my_decoder.to(device=device)
# 开启训练模式
my_encoder.train()
my_decoder.train()
# 把模型都放到 GPU 上(如果有 GPU 就会放在 GPU 上,如果没有 GPU 就仍然在 CPU 上)
my_encoder.to(device=device)
my_decoder.to(device=device)
# 梯度由 `loss.backward()` 计算,参数由 `.step()` 更新,
# 优化器数量只决定"如何分组执行更新",不影响梯度是否能传到编码器,也不改变训练结果。
# 详情在《Seq2Seq架构的优化器需要几个------1个即可》笔记中
optimizer = optim.Adam(params=chain(my_encoder.parameters(), my_decoder.parameters()), lr=0.001)
# 损失函数
criterion = nn.CrossEntropyLoss()
epochs = 5 # 本人电脑训练一轮需要 10~14分钟,太慢了,呜呜呜
plot_loss_list_y = [] # 记录平均损失
plot_loss_list_x = [] # 记录平均损失
plot_total_loss = 0.0 # 用于画图的总损失
print_total_loss = 0.0 # 用控制台打印的总损失
ite_num = 0 # 已训练样本个数
print_step = 1000 # 每隔 1000 个样本在屏幕上打印一次日志
save_step = 100 # 每隔 100 个样本保存一次平均损失
for epoch in range(1, epochs + 1):
# 随着 epoch 增加,逐渐减少 Teacher Forcing 的使用
teacher_forcing_ratio = max(0.0, 1.0 - epoch * 0.25) # 线性衰减,下限为 0
start_time = time.perf_counter() # 第 epoch 轮训练的起始时间
for eng_sen, fran_sen in tqdm(my_dataloader):
# 张量不会就地修改张量,而是返回一个新的张量
eng_sen = eng_sen.to(device=device) # 返回 CPU 张量,在训练循环中统一 .to(device)
fran_sen = fran_sen.to(device=device) # 返回 CPU 张量,在训练循环中统一 .to(device)
# print('句子:',eng_sen) # 比如: tensor([[ 3, 4, 304, 12, 5]], device='cuda:0')
# print('句子:',fran_sen) # 比如: tensor([[ 7, 12, 122, 21, 6, 1]], device='cuda:0')
# 返回的 loss 是值,不是张量
loss = train_batch(eng_sen, fran_sen, my_encoder, my_decoder, optimizer, criterion, teacher_forcing_ratio)
# print(f'每个 token 的平均损失: {loss}') # 8.3589(第1轮)
ite_num += eng_sen.size(0) # 获取当前 batch 样本个数
print_total_loss += loss
plot_total_loss += loss
if ite_num % print_step == 0: # 控制台打印
avg_loss = print_total_loss / ite_num # 每隔 1000 个样本,每个样本的平均损失
consume_time = time.perf_counter() - start_time # 当前 epoch 轮已耗时
print(f'当前 epoch = {epoch}, 已训练样本个数: {ite_num}, 每隔1000个样本的平均损失: {avg_loss}, 本轮轮已耗时: {consume_time}')
# 当前 epoch = 1, 已训练样本个数: 1000, 每隔1000个样本的平均损失: 4.044587318411708, 本轮轮已耗时: 9.336827200000698
print_total_loss = 0 # 每隔 1000 个样本让总损失清零
if ite_num % save_step == 0: # 保存平均损失
avg_loss = plot_total_loss / ite_num
plot_loss_list_y.append(avg_loss) # 已训练样本的平均损失
plot_loss_list_x.append(ite_num) # 已训练样本个数
torch.save(my_encoder.state_dict(), f=r'./model/my_encoder.pth')
torch.save(my_decoder.state_dict(), f=r'./model/my_decoder.pth')
plt.plot(plot_loss_list_x, plot_loss_list_y)
plt.title('engTofran')
plt.xlabel('训练样本个数')
plt.ylabel('训练样本平均损失')
plt.show()
# 11.每个 batch 样本预测(现有 eval_attn 函数,才有这个函数的)
def predict_batch(eng_sen, fran_sen, my_encoder, my_decoder):
# 预测时,不计算任何梯度
with torch.no_grad():
encoder_output, encoder_hn = my_encoder(eng_sen)
# 在 法语 开头加特殊符,作为 解码器 的初始输入,即输入 SOS 这个词
decoder_input = torch.tensor(data=[[special_tokens['START_OF_SENTENCE']]], device=device)
# 用 编码器 最后的隐藏状态 当作 解码器 的初始隐藏状态
decoder_hn = encoder_hn
# 这是预测,当前隐藏状态为上一步的隐藏状态,而不是 Teacher Forcing 了
# 开始预测
predict_list = [] # 存储预测出来的单词
for _ in range(MAX_LENGTH): # 预测的法文长度最大长度不超过 MAX_LENGTH,防止无限预测
# attn 做一个注意力图,但那只是个展示而已,不重要。故没有做注意力图
logits, decoder_hn, attn = my_decoder(decoder_input, decoder_hn, encoder_output, encoder_output)
# print(logits.shape) # torch.Size([1, 4346])
# 使用 logits 进行预测
predict_id = logits.argmax(dim=-1)
# print(f'预测结果的id: {predict_id}') # tensor([7], device='cuda:0')
predict_word = fran_index_word[predict_id.item()]
# print(f'预测结果: {predict_word}') # je
if predict_id == special_tokens['END_OF_SENTENCE']:
# 遇到 EOS,停止生成,且不加入结果
break
predict_list.append(predict_word)
# 用当前 预测的词 作为下一时间步的输入
decoder_input = predict_id.reshape(1, 1) # 需符合解码器输入
# 训练时,是使用 空格 做了切分,所以模型是学不到空格的。故这里要用空格隔开!
return ' '.join(predict_list) # 返回预测的法文句子
# 10.预测函数
def eval_attn():
# 创建模型
DIM = 128 # embed_dim = encoder_hid_dim = decoder_hid_dim = DIM = 128
my_encoder = EncoderGRU(eng_vocabulary_size=len_eng_word_index, embed_dim=DIM, gru_hid_dim=DIM)
my_decoder = AttnDecoderGRU(fran_vocabulary_size=len_fran_word_index, embed_dim=DIM, encoder_hid_dim=DIM,
decoder_hid_dim=DIM)
my_encoder.to(device=device) # 把模型放到 设备 上
my_decoder.to(device=device) # 把模型放到 设备 上
# 加载模型
my_encoder.load_state_dict(torch.load(r'./model/my_encoder.pth', map_location=device))
my_decoder.load_state_dict(torch.load(r'./model/my_decoder.pth', map_location=device))
# 推理模式
my_encoder.eval()
my_decoder.eval()
test_data = [
['i m impressed with your french .', 'je suis impressionne par votre francais .'],
['i m more than a friend .', 'je suis plus qu une amie .'],
['she is beautiful like her mother .', 'elle est belle comme sa mere .']
]
for i, (eng_sen, fran_sen) in enumerate(test_data):
# 把句子映射到 ID
eng_sen_id = [eng_word_index.get(word, special_tokens['UNK']) for word in eng_sen.split(' ')]
fran_sen_id = [fran_word_index.get(word, special_tokens['UNK']) for word in fran_sen.split(' ')]
eng_sen_id = torch.tensor(data=eng_sen_id, device=device).reshape(1, -1) # 形状需要符合模型的输入
fran_sen_id = torch.tensor(data=fran_sen_id, device=device).reshape(1, -1) # 形状需要符合模型的输入
print(eng_sen_id) # tensor([[ 3, 4, 384, 678, 351, 85, 5]], device='cuda:0')
print(fran_sen_id) # tensor([[ 7, 12, 1676, 2312, 646, 139, 6]], device='cuda:0')
predict_fran_sen = predict_batch(eng_sen=eng_sen_id, fran_sen=fran_sen_id, my_encoder=my_encoder, my_decoder=my_decoder)
print(f'输入的英文句子: {eng_sen}')
print(f'模型预测的句子: {predict_fran_sen}')
print(f'真实的法文句子: {fran_sen}')
print('-' * 30)
# 输入的英文句子: i m impressed with your french .
# 模型预测的句子: je suis impressionnee par ton francais .
# 真实的法文句子: je suis impressionne par votre francais .
# ------------------------------
# tensor([[ 3, 4, 1207, 1167, 43, 470, 5]], device='cuda:0')
# tensor([[ 7, 12, 153, 1364, 299, 1199, 6]], device='cuda:0')
# 输入的英文句子: i m more than a friend .
# 模型预测的句子: je suis plus qu amie amie .
# 真实的法文句子: je suis plus qu une amie .
# ------------------------------
# tensor([[ 76, 41, 367, 744, 723, 1174, 5]], device='cuda:0')
# tensor([[ 120, 26, 666, 1287, 2261, 2075, 6]], device='cuda:0')
# 输入的英文句子: she is beautiful like her mother .
# 模型预测的句子: elle est mere a mere mere .
# 真实的法文句子: elle est belle comme sa mere .
if __name__ == '__main__':
(mydata,
eng_word_index,
fran_word_index,
eng_index_word,
fran_index_word,
len_eng_word_index,
len_fran_word_index) = my_data()
# a = MyDataset(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
# print(a[0])
# (tensor([3, 4, 5], device='cuda:0'), tensor([3, 4, 5, 6, 1], device='cuda:0'))
# get_dataloader(mydata=mydata, eng_word_index=eng_word_index, fran_word_index=fran_word_index)
# taste_encoder(len_eng_word_index, 64, 128, mydata, eng_word_index, fran_word_index)
# taste_DecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index)
# taste_AttnDecoderGRU(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index)
# train_attn_decoder_gru(mydata, eng_word_index, fran_word_index, eng_index_word, fran_index_word, len_eng_word_index, len_fran_word_index)
eval_attn()