前言
在机器学习建模中,单一模型往往难以兼顾预测精度 和泛化能力,要么易过拟合,要么拟合效果不足。而集成学习凭借 "组合多个弱学习器形成强学习器" 的核心思路,完美解决了这一痛点,成为工业界落地、算法竞赛夺冠的主流方法。
随机森林作为集成学习中Bagging 流派的经典代表,凭借高准确率、强抗过拟合、易实现等优势,成为分类 / 回归任务的 "万金油" 模型,也是入门集成学习的必学算法。本文将从集成学习基础入手,清晰梳理 Bagging 与 Boosting 两大核心流派的区别,再深入解析随机森林的设计精髓、构建过程及特性,为实战落地奠定扎实的理论基础,同时也为面试高频考点做精准总结。
一、集成学习基础:从 "弱学习器联盟" 到 "强学习器"
在深入随机森林前,我们先明确集成学习的核心概念,理解其 "化弱为强" 的底层逻辑,这是掌握所有集成算法的前提。
1. 什么是集成学习?
集成学习是一种机器学习范式,核心思想是:构建多个独立的弱学习器(性能略优于随机猜测的简单模型,如单层决策树、简单逻辑回归),通过特定的组合策略融合其预测结果,最终形成一个精度远高于单一弱学习器的强学习器。
训练时,用训练集依次训练多个弱学习器;预测时,让多个弱学习器联合判断,综合输出结果。其底层逻辑就是我们常说的 "三个臭皮匠,顶个诸葛亮"------ 单一弱学习器可能存在偏差或方差问题,但多模型的差异性融合,能有效抵消单一模型的极端误差,既提升预测精度,又降低过拟合风险。
2. 集成学习的核心价值:为什么 "联盟" 比 "个体" 更强?
单一复杂模型(比如 9 次多项式函数)容易出现 "能力过强但易过拟合" 的问题,对训练集拟合极好,对未知测试集却表现拉胯;而集成学习通过组合多个简单模型(比如多个 1 次函数),能实现 **"能力变强且不易过拟合"** 的效果。
具体来说,集成学习的核心价值体现在三点:
- 降低过拟合风险:多个模型的独立判断能抵消单一模型的主观偏差;
- 提升泛化能力:融合后模型对未知数据的适应能力、稳定性大幅提升;
- 适配性更广:无需对数据做复杂预处理,能应对不同质量、不同维度的数据集。
二、Bagging 与 Boosting:集成学习两大核心流派的核心区别
集成学习根据弱学习器的生成方式 、组合策略 的不同,主要分为Bagging(装袋法)和 Boosting(提升法)两大流派。随机森林是 Bagging 的经典实现,而 Adaboost、GBDT、XGBoost 则属于 Boosting,二者的区别是面试高频考点,也是理解随机森林设计逻辑的关键。
1. 核心维度全方位对比
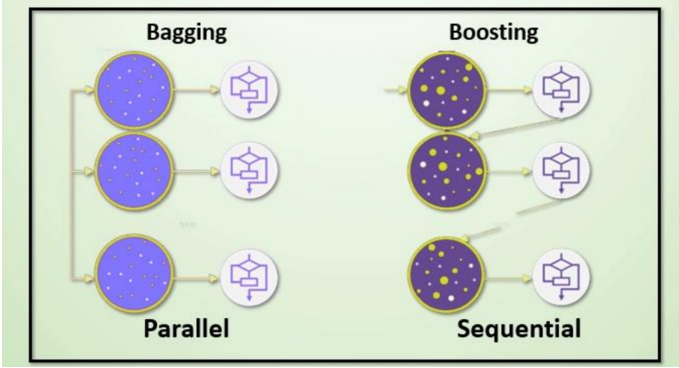
为了让大家更直观的理解,我整理了二者在核心思想、数据采样、学习顺序等 8 个核心维度的对比表,建议收藏备用:
表格
| 对比维度 | Bagging(装袋法) | Boosting(提升法) |
|---|---|---|
| 核心思想 | 对训练集有放回抽样生成多个子集,独立训练弱学习器,融合以降低方差、抗过拟合 | 用全量样本训练,根据前一个学习器的预测错误调整样本权重,聚焦难分样本,以降低偏差、提精度 |
| 数据采样 | 有放回的 Bootstrap 抽样,生成多个不同训练子集,子集间有样本重叠 | 全程使用全量训练样本,动态调整样本权重(错误样本权重升高,正确样本权重降低) |
| 学习顺序 | 并行训练,各弱学习器无依赖、可同时训练 | 串行训练,各弱学习器有先后依赖,后一个基于前一个的结果优化 |
| 融合 / 投票方式 | 平权投票(分类:多数表决;回归:均值),所有弱学习器权重相同 | 加权投票,表现好的弱学习器赋予更高权重,表现差的赋予更低权重 |
| 模型目标 | 提升泛化能力,防止过拟合,适合解决高方差问题 | 提升预测精度,解决欠拟合,适合解决高偏差问题 |
| 代表算法 | 随机森林(RF)、Bagging 决策树 | Adaboost、GBDT、XGBoost、LightGBM |
| 过拟合风险 | 风险极低,树 / 模型数量增加后性能趋于稳定 | 风险较高,训练轮数过多易过拟合,需严格调参 |
| 训练效率 | 效率高,支持多核并行训练 | 效率较低,串行训练无法并行,训练耗时更长 |
2. 通俗理解:两种流派的核心逻辑差异
如果用生活中的场景类比,能更轻松理解二者的本质区别:
- Bagging:如同多个评委独立给选手打分,最终取多数票或平均分。评委之间互不干扰、独立判断,通过 "多人智慧" 避免单一评委的主观偏差,核心是 **"众智成城"**;
- Boosting:如同一个学生不断做练习题,第一次做错的题目,第二次会重点练习(权重升高),做错的题越练越熟,通过 "知错就改、重点突破" 不断提升成绩,核心是 **"循序渐进"**。
3. 关键结论
随机森林作为 **"Bagging+CART 决策树"的结合体,完美继承了 Bagging 的核心优势:并行训练、抗过拟合、泛化能力强。并且在 Bagging 的基础上,随机森林还增加了特征随机选择 **,让弱学习器的差异性更大,融合后的效果更优,这也是它能成为工业界 "万金油" 模型的关键。
三、随机森林核心原理:Bagging + 双重随机的完美结合
随机森林(Random Forest, RF)是以 CART 决策树为弱学习器的 Bagging 集成算法 ,在 Bagging 的 "样本随机抽样" 基础上,创新性的增加了 "特征随机选择",通过样本随机 + 特征随机的双重随机性,让每棵决策树的差异性最大化,最终融合后的模型性能远优于单一决策树。
1. 随机森林的定义
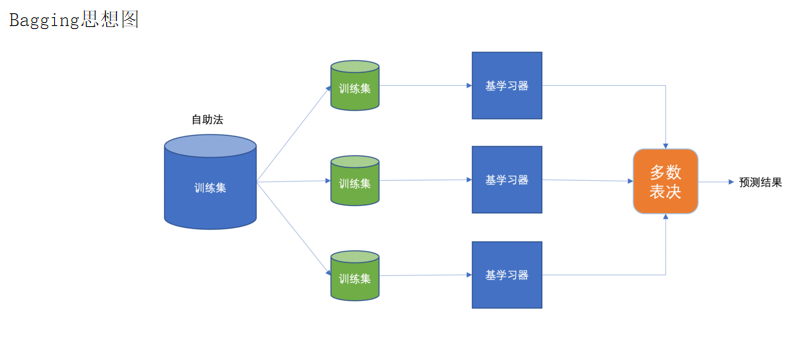
随机森林是由多棵独立训练 的 CART 决策树组成的集成模型,训练时对样本和特征进行双重随机抽样,预测时通过多棵决策树的 ** 平权投票(分类任务)或均值(回归任务)** 得到最终结果,是 Bagging 思想的极致体现和落地。
2. 随机森林的四大核心特点
随机森林的所有特性都围绕 "随机" 和 "森林" 展开,这也是其区别于单一决策树和普通 Bagging 的关键,缺一不可:
- 数据采样随机:采用 Bootstrap 有放回抽样,从原始数据集中生成多个不同的训练子集,每棵决策树使用一个子集训练,子集间存在样本重叠;
- 特征选取随机:训练每棵决策树时,对每个节点分裂,并非使用所有特征,而是随机选取部分特征作为候选特征,仅在候选特征中选择最优分裂特征;
- 基学习器为 CART 决策树:以简单的 CART 决策树为弱学习器,决策树的简洁性让随机森林易于实现、且支持并行化训练;
- 森林式平权融合:由多棵独立的决策树组成 "森林",最终结果通过所有决策树的平权投票 / 均值融合,少数服从多数,无任何权重差异。
3. 双重随机的设计精髓:为什么要 "随机抽样 + 随机选特征"?
随机森林的 "双重随机" 是其核心优势的来源,也是面试常考的难点,理解以下两个问题,就能彻底掌握其设计逻辑:
问题 1:为什么要随机抽样训练集,且必须是 "有放回" 的?
- 若不随机抽样:所有决策树的训练集完全相同,训练出的树结构、预测结果也会完全一致,融合后没有任何意义,无法发挥集成学习的优势;
- 若 "无放回" 抽样:每棵树的训练样本无交集,会导致每棵树 "有偏"(对部分样本拟合好,对另一部分拟合差),投票表决无法弥补这种偏差,融合效果大打折扣;
- 关键结论:有放回抽样让弱学习器的训练样本 **"既有交集又有差异"**,才能让投票表决真正发挥作用,有效降低模型方差、提升抗过拟合能力。
问题 2:为什么要随机选择特征?
单一决策树在训练时,会优先选择区分度高的特征进行节点分裂。如果所有树都使用全量特征,会导致多棵树的分裂方式高度相似(树结构趋同),相当于 "多个相同的评委打分",融合后提升效果有限。
随机选择特征让每棵树的分裂依据不同,树结构的 **"差异性最大化"**,融合后的模型能覆盖更多的样本特征,抗过拟合能力、泛化能力都会大幅提升。
4. 随机森林的完整构建步骤
随机森林的构建流程非常清晰,分为 5 步,这也是其底层实现逻辑,从抽样到融合一气呵成,理解后能更好的掌握其调参思路:
- 随机选样本 :从原始训练集中通过有放回抽样(Bootstrap),选取 m 条样本,生成一个独立的训练子集;
- 随机选特征:从所有特征中随机选取 k 个特征(k < 总特征数),作为当前决策树的训练特征;
- 训练单棵 CART 树:用上述样本子集和特征子集,训练一棵 CART 决策树(默认不剪枝,保持弱学习器的特性);
- 重复构建多棵树:重复步骤 1-3,构建 n 棵独立的决策树,形成真正的 "森林";
- 平权投票融合结果 :
- 分类任务:将测试样本输入所有决策树,以多数表决的方式确定最终类别;
- 回归任务:将测试样本输入所有决策树,以所有预测值的均值作为最终结果。
四、随机森林的局限性与适用边界
任何模型都有其适用范围,没有 "万能模型",了解随机森林的局限性和适用场景,能帮助我们在实战中合理选择模型,避免盲目使用。
1. 随机森林的主要局限性
- 黑盒模型,可解释性差:单一决策树的可解释性强(能清晰看到决策路径),但随机森林由多棵树融合而成,无法直观展示预测的决策过程,在金融、医疗等对可解释性要求高的场景中受限;
- 训练成本随树数量增加而升高:当决策树数量过多时,模型训练需要占用更大的内存和更长的时间,尤其是处理超大规模数据集时,耗时会明显增加;
- 对少数类样本不友好:在不平衡数据集中,预测结果会偏向多数类样本,需要通过过采样、欠采样或样本权重调整等方式优化;
- 对连续特征拟合精度有限:随机森林对连续特征的分裂是离散化处理,相比 XGBoost、LightGBM 等 Boosting 模型,对连续特征的拟合精度略有不足。
2. 随机森林的适用 & 不适用场景
✅ 适用场景
- 分类 / 回归任务的快速基线模型搭建,快速得到高性能基准;
- 高维、多特征、数据质量一般的数据集,无需复杂的特征预处理;
- 对建模效率有要求,需要并行化训练的大数据集场景;
- 需要做特征重要性分析,辅助特征工程的场景;
- 对模型可解释性要求不高的工业界实战场景。
❌ 不适用场景
- 对模型可解释性要求极高的场景(如银行信贷审批、医疗诊断结果解释);
- 数据集规模极小的场景(易导致模型过拟合,失去集成意义);
- 对连续特征拟合精度要求极高的纯回归任务;
- 嵌入式设备等对模型体积、推理速度有严格限制的场景。
五、本文核心知识点总结
本文从集成学习基础入手,梳理了 Bagging 与 Boosting 的核心区别,深入解析了随机森林的原理和特性,核心知识点可总结为 3 点,方便大家快速记忆:
- 流派定位:随机森林是 **"Bagging+CART 决策树 + 双重随机"** 的集成算法,完美继承了 Bagging 并行训练、抗过拟合、泛化能力强的优势;
- 核心设计:双重随机(有放回样本抽样 + 随机特征选择)是其精髓,通过最大化弱学习器的差异性,实现 "1+1>2" 的融合效果;
- 核心优势:抗过拟合、抗噪声、易并行化、通用性强,是工业界快速搭建高性能模型的首选,也是入门集成学习的必学算法。
后续预告
掌握了随机森林的核心原理,接下来就是最关键的实战落地 !下一篇文章我将聚焦 Sklearn 随机森林的 API 详解、核心调参技巧,并结合经典的泰坦尼克号生存预测案例,手把手教你实现从数据预处理、模型训练到超参数调优的完整流程,所有代码均可直接运行,敬请期待!
创作不易,欢迎点赞、收藏、关注! 我会持续更新机器学习 / 集成学习系列干货,从原理到实战,帮你彻底掌握工业界常用算法。有问题可以在评论区留言,一起交流学习~