一、查壳
1、使用工具
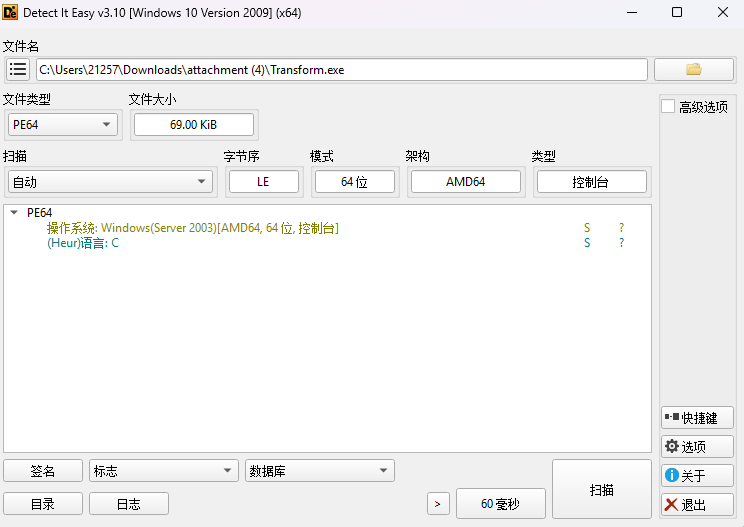
2、检查结果
这表明程序未加壳,我们可以直接进行下一步的代码分析。
二、分析代码
1、静态分析
用IDA Pro打开程序,等待自动分析完成。
F5反汇编得到
cs
// local variable allocation has failed, the output may be wrong!
int __fastcall main(int argc, const char **argv, const char **envp)
{
char input[104]; // [rsp+20h] [rbp-70h] BYREF
int i; // [rsp+88h] [rbp-8h]
int j; // [rsp+8Ch] [rbp-4h]
// 调用子函数sub_402230,参数包括argc、argv和envp
sub_402230(*(_QWORD *)&argc, argv, envp);
// 提示用户输入代码
printf("Give me your code:\n");
// 从标准输入读取字符串到input数组
scanf("%s", input);
// 检查输入字符串长度是否为33个字符,如果不是则输出错误信息并退出程序
if ( strlen(input) != 33 ) // 33个字符
{
printf("Wrong!\n");
system("pause");
exit(0);
}
// 遍历输入字符串的每个字符,进行特定的字符操作
for ( j = 0; j <= 32; ++j ) // 遍历数组
{
a[j] = input[b[j]];
a[j] ^= LOBYTE(b[j]);
}
// 再次遍历数组,检查a数组和c数组对应位置的字符是否相同,如果不同则输出错误信息并退出程序
for ( i = 0; i <= 32; ++i )
{
if ( c[i] != a[i] ) // a==c
{
printf("Wrong!\n");
system("pause");
exit(0);
}
}
// 如果所有检查都通过,则输出成功信息和flag
printf("Right!Good Job!\n");
printf("Here is your flag: %s\n", input);
system("pause");
return 0;
}先来看大概的过程,输入33个字符的input
接下来是核心的加密方法:遍历数组input将inputb\[j]的元素赋值给a数组,然后a数组异或LOBYTE(bj)
最后将a与c数组进行对照,如果不一样就输出错误,反之得到a==c得到正确
其中疑点在b数组的内容,c数组的内容
双击b数组可以看到
我们需要提取具体内容,选中需要提取的内容,点击上方导航栏的edit
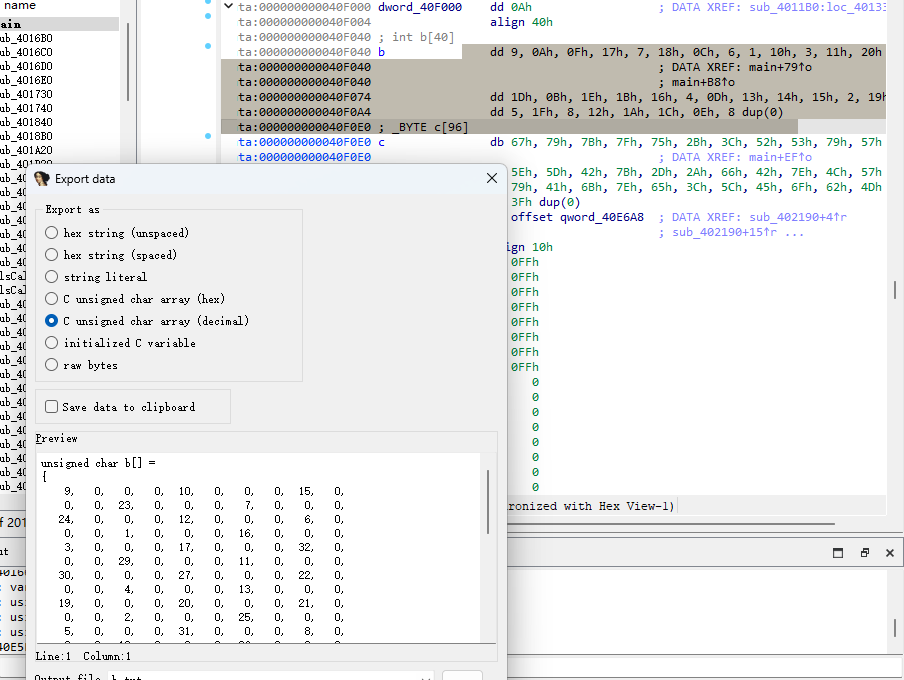
b数组就是这样了
b=[9, 0, 0, 0, 10, 0, 0, 0, 15, 0, 0, 0, 23, 0, 0, 0, 7, 0, 0, 0, 24, 0, 0, 0, 12, 0, 0, 0, 6, 0, 0, 0, 1, 0, 0, 0, 16, 0, 0, 0, 3, 0, 0, 0, 17, 0, 0, 0, 32, 0, 0, 0, 29, 0, 0, 0, 11, 0, 0, 0, 30, 0, 0, 0, 27, 0, 0, 0, 22, 0, 0, 0, 4, 0, 0, 0, 13, 0, 0, 0, 19, 0, 0, 0, 20, 0, 0, 0, 21, 0, 0, 0, 2, 0, 0, 0, 25, 0, 0, 0, 5, 0, 0, 0, 31, 0, 0, 0, 8, 0, 0, 0, 18, 0, 0, 0, 26, 0, 0, 0, 28, 0, 0, 0, 14, 0, 0, 0,0,0,0,0]
同理可以得到c数组的内容
c=[103, 121, 123, 127, 117, 43, 60, 82, 83, 121, 87, 94, 93, 66, 123, 45, 42, 102, 66, 126, 76, 87, 121, 65, 107, 126, 101, 60, 92, 69, 111, 98, 77]
还有一点关于LOBYTEb\[j]
在C语言中,
lobyte 通常指一个多字节数据(如int,short)中的低字节(Low Byte),即最低有效字节。它不是一个标准C语言关键字或函数,而是一个在底层编程、硬件交互或数据协议处理中常用的概念 和操作。
核心概念
对于一个多字节整数(例如
uint16_t,int),它在内存中由多个连续字节存储。lobyte指的是这个值中权重最低的那个字节。示例:一个32位整数 0x12345678
在小端系统中,内存布局为:
地址0: 0x78 ← 这就是 **lobyte** (最低8位/低字节)
地址1: 0x56 ← 次低字节
地址2: 0x34 ← 次高字节
地址3: 0x12 ← 最高字节
都搞清楚了,接下来就是破解了
三、破解方法
python
c = [103, 121, 123, 127, 117, 43, 60, 82, 83, 121, 87, 94, 93, 66, 123, 45, 42, 102, 66, 126, 76, 87, 121, 65, 107, 126, 101, 60, 92, 69, 111, 98, 77]
b = [9, 0, 0, 0, 10, 0, 0, 0, 15, 0, 0, 0, 23, 0, 0, 0, 7, 0, 0, 0, 24, 0, 0, 0, 12, 0, 0, 0, 6, 0, 0, 0, 1, 0, 0, 0, 16, 0, 0, 0, 3, 0, 0, 0, 17, 0, 0, 0, 32, 0, 0, 0, 29, 0, 0, 0, 11, 0, 0, 0, 30, 0, 0, 0, 27, 0, 0, 0, 22, 0, 0, 0, 4, 0, 0, 0, 13, 0, 0, 0, 19, 0, 0, 0, 20, 0, 0, 0, 21, 0, 0, 0, 2, 0, 0, 0, 25, 0, 0, 0, 5, 0, 0, 0, 31, 0, 0, 0, 8, 0, 0, 0, 18, 0, 0, 0, 26, 0, 0, 0, 28, 0, 0, 0, 14, 0, 0, 0, 0, 0, 0, 0]
# 提取 b 中的索引(每4字节的低字节)
newb = b[::4] # 长度33,为0-32的排列
# 初始化 flag 字符数组
flag = [''] * 33
# 根据映射计算每个位置字符
for j in range(33):
idx = newb[j] # input 中的位置
flag[idx] = chr(c[j] ^ newb[j])
# 合并为字符串
flag_str = ''.join(flag)
print("Flag:", flag_str)解密的过程有点饶,我们要先异或因为异或过程是可逆的,然后把重排的顺序还原,这个我觉得很绕我举个例子吧
input="ABCD"
0 1 2 3
b=2,0,3,1
可以得到
a0=input2='C'
a1=input0='A'
a2=input3='D'
a3=input1='B'
反过来推
flag2='C'=a0
flag0='A'=a1
flag3='D'=a2
flag1='B'=a3
Flag: MRCTF{Tr4nsp0sltiON_Clph3r_1s_3z}
四、最终flag
flag{Tr4nsp0sltiON_Clph3r_1s_3z}