词向量(Word Embedding)是自然语言处理(NLP)中核心的基础技术,它能将离散的文本词汇转化为连续的数值向量,让计算机能够"理解"文本的语义信息。本文将从简单的词向量转换小例子入手,逐步延伸到电商评价文本的实战分析,带你掌握词向量转换的核心思路与落地方法。
一、项目背景与技术栈
本次实战以苏宁易购商品评价为目标,实现"数据爬取→文本分词→停用词过滤"的全流程,核心技术栈包括:
• 数据爬取:Selenium(模拟浏览器操作,处理动态加载的分页评价)
• 文本处理:jieba(中文分词)、pandas(数据读写与处理)
• 辅助工具:sklearn(词向量转换基础,拓展用)
二、词向量转换入门:CountVectorizer小例子
在词向量转换的入门阶段,sklearn库中的CountVectorizer是最易理解的工具之一。它的核心逻辑是词袋模型(Bag of Words) ------忽略文本的语法和语序,只统计词汇在文本中出现的频次,最终将文本转化为稀疏矩阵形式的向量。
1. 核心代码实现
python
from sklearn.feature_extraction.text import CountVectorizer
# 定义待处理的简单文本列表
texts = ["dog cat fish", "dog cat cat", "fish bird", 'bird']
cont = []
# 初始化CountVectorizer,ngram_range=(1,1)表示只提取单个词汇
cv = CountVectorizer(ngram_range=(1,1))
# 拟合文本并完成向量化转换
cv_fit = cv.fit_transform(texts)
# 输出转换后的稀疏矩阵(节省内存,只存储非零值)
print(cv_fit)
# 输出文本中提取的所有特征词汇(即所有不重复的单词)
print(cv.get_feature_names_out())
# 将稀疏矩阵转为密集矩阵,直观展示每个文本的词频向量
print(cv_fit.toarray())- 结果解读
运行代码后,我们可以得到以下关键输出:
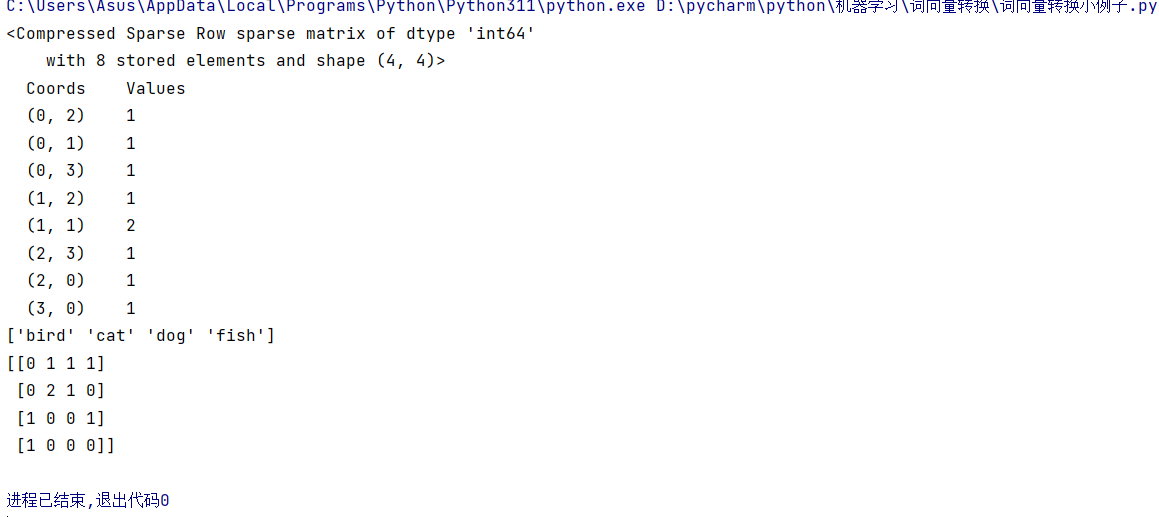
• 特征词汇:'bird', 'cat', 'dog', 'fish',即所有文本中出现的不重复单词;
• 词频矩阵:
\[0 1 1 1
0 2 1 0
1 0 0 1
1 0 0 0\]
每一行对应一个输入文本,每一列对应一个特征词,数值代表该词在对应文本中出现的次数。比如第二行0 2 1 0对应文本"dog cat cat",表示"cat"出现2次、"dog"出现1次,"bird"和"fish"未出现。
三、实战:电商评价文本的词向量转换
在实际场景中,我们面对的不是简单的英文单词,而是中文电商评价文本。完整的流程需要:爬取评价数据→中文分词→停用词过滤→词向量转换。
- 前期准备:爬取电商评价数据首先通过Selenium爬取苏宁商品的"优质评价"和"差评"文本,保存为本地文件(优质评价.txt、差评.txt)。核心代码逻辑如下:
python
import time
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
# 配置Edge浏览器选项
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
# 爬取优质评价
def crawl_reviews(url, save_file):
driver.get(url)
file = open(save_file, 'w', encoding='utf-8')
# 提取单页评价内容
def get_content(file):
content_elems = driver.find_elements(by=By.CLASS_NAME, value='body-content')
for elem in content_elems:
file.write(elem.text + '\n')
get_content(file)
# 翻页爬取
next_elems = driver.find_elements(By.XPATH, '//*[@class="next rv-maidian "]')
while next_elems != []:
time.sleep(1)
next_elems[0].click()
get_content(file)
next_elems = driver.find_elements(By.XPATH, '//*[@class="next rv-maidian "]')
file.close()
# 优质评价爬取地址
yzpj_url = 'https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-good.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166'
# 差评爬取地址
cp_url = 'https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-bad.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166'
crawl_reviews(yzpj_url, '优质评价.txt')
crawl_reviews(cp_url, '差评.txt')
driver.quit()
print("爬取完成!")
- 中文分词与停用词过滤中文文本无法直接按空格拆分词汇,需要借助jieba分词工具;同时要过滤"的""了""啊"等无意义的停用词,减少噪声。
python
import pandas as pd
import jieba
# 读取评价数据
cp_content = pd.read_table(r".\差评.txt", encoding='utf-8')
yzpj_content = pd.read_table(r".\优质评价.txt", encoding='utf-8')
# 定义分词函数
def jieba_cut(content_series):
segments = []
contents = content_series.iloc[:, 0].values.tolist()
for content in contents:
# 精准分词
words = jieba.lcut(content)
# 过滤长度为1的无意义词汇(可选)
if len(words) > 1:
segments.append(words)
return segments
# 对差评、优质评价分别分词
cp_segments = jieba_cut(cp_content)
yzpj_segments = jieba_cut(yzpj_content)
# 读取停用词并定义过滤函数
stopwords = pd.read_csv(r"StopwordscN.txt", encoding='utf8', engine='python')['stopword'].tolist()
def drop_stopwords(segments, stopwords):
clean_segments = []
for seg in segments:
clean_seg = [word for word in seg if word not in stopwords]
clean_segments.append(clean_seg)
return clean_segments
# 过滤停用词
cp_clean = drop_stopwords(cp_segments, stopwords)
yzpj_clean = drop_stopwords(yzpj_segments, stopwords)- 评价文本的词向量转换经过分词和停用词过滤后,我们需要将处理后的词汇列表转化为"句子格式"(以空格连接词汇),再用CountVectorizer完成词向量转换。
python
from sklearn.feature_extraction.text import CountVectorizer
# 将词汇列表转为空格连接的字符串
def seg_to_text(segments):
texts = []
for seg in segments:
text = ' '.join(seg)
texts.append(text)
return texts
cp_texts = seg_to_text(cp_clean)
yzpj_texts = seg_to_text(yzpj_clean)
# 合并所有评价文本,统一拟合词汇表
all_texts = cp_texts + yzpj_texts
cv = CountVectorizer(ngram_range=(1,2)) # 提取1-2个词的组合(如"物流慢""质量好")
cv_fit = cv.fit_transform(all_texts)
# 拆分差评、优质评价的词向量
cp_vec = cv_fit[:len(cp_texts)]
yzpj_vec = cv_fit[len(cp_texts):]
# 输出关键信息
print("评价文本特征词汇数量:", len(cv.get_feature_names_out()))
print("差评词向量维度:", cp_vec.shape)
print("优质评价词向量维度:", yzpj_vec.shape)
四、词向量转换的延伸与思考
-
从CountVectorizer到TF-IDF:CountVectorizer仅统计词频,而TfidfVectorizer会结合"词频(TF)"和"逆文档频率(IDF)",更能体现词汇的重要性(比如"差评"中高频的"卡顿"比通用词"商品"更有分析价值)。
-
进阶词向量模型:Word2Vec、BERT等模型能生成"语义向量",不仅统计频次,还能捕捉词汇的语义关系(如"好评"和"满意"向量距离更近),适合更复杂的语义分析场景。
-
实战价值:转换后的词向量可直接用于后续的机器学习任务,比如分类(区分好评/差评)、聚类(分析差评的核心问题)、情感分析等。
总结
词向量转换是连接文本与机器学习模型的桥梁:从简单的英文词频统计例子,到中文电商评价的完整处理流程,核心是将"非结构化文本"转化为"结构化数值向量"。掌握基础工具(如CountVectorizer)的使用,结合中文分词、停用词过滤等预处理步骤,就能快速落地文本分析的基础场景;而进阶的语义向量模型,则能进一步提升文本分析的深度和准确性。