【48、ElasticSearch搜索技术深入与聚合查询实战】4.12 什么是相关性
相关性的概述:
描述一个文档与查询语句匹配程度的衡量标准.ES有一个评分算法,根据查询条件与索引文档的匹配程度来计算相关性.
评分算法:Okapi BM25(RAGFlow关键词搜索也有这个算法)
4.14.1 Index Boost在索引层面修改相关性
 5种策略
5种策略
|-------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------|
| Index Boost:索引层面,比如一批数据有3个标签,现在想在查询的时候让A,B,C的顺序展示标签. 每个标签独占一个索引 查询也是针对索引别名.这样可以做到优先查询某个索引.让有限的返回结果中以指定的索引为主. 场景: 多标签,冷热数据分离 | 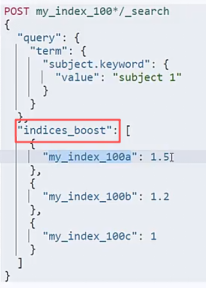 |
|
| boosting: 文档级别,默认是1,设为0到1之间就是降低评分. 构造查询条件的时候指定某个字段的权重. 适用于某些特定场合的查询.比如查询时需要以某某条件为主 场景: 给热门产品更多权重 | 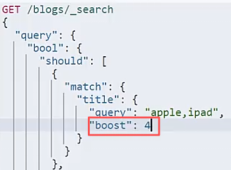 |
|
| megative_boost:降低相关性,对某些返回结果不满意但是又不能使用must_not过滤掉. 仅对查询中定义的negative部分生效. negative的评分在0到1之间. 场景: 商品查询结果中想突出苹果手机,可以这么设置,对于苹果派,苹果汁等需要降低相关性 |  |
|
| Function_score: 自定义评分. 比如结合有些关键业务字段的值来计算得分.如商品的销量和浏览人数.文章的阅读量和点赞收藏人数 场景: ①融合业务指标(销量,浏览量,点赞量)②时间衰减,新闻,博客等内容随时间推移降权,让新内容优先展示; ③地理位置衰减;④人工干预:置顶,精选 | 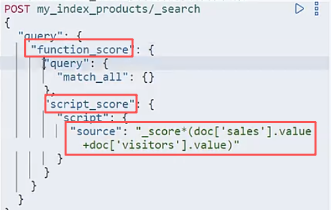 |
|
| rescore query查询后二次打分. 原先已经有复杂的查询条件了,只是查询结果不太满意想调整得分; 在原来结果的基础上重新对查询结果按字段设置权重. 场景:精排,适用于实现Learning to Rank等高级排序模型. 结合机器学习模型或者复杂脚本最终返回top N条. |  |
|
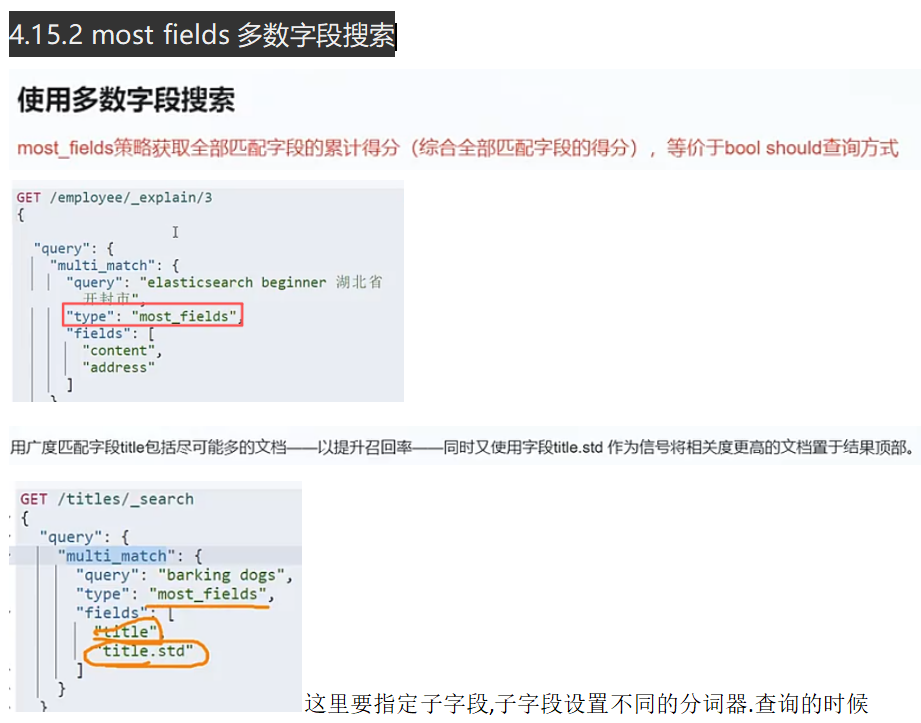
4.15.1 dis max&best fields最佳字段搜索
多字段搜索场景优化

最佳字段:比如博客的标题和内容字段,都含有查询关键词的话,结果得分是求和的.(多字段查询一般是should查询)
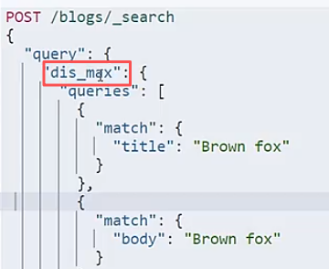 dis_max,只取条件字段中得分最大的字段。如果只用dis_max效果还不好:
dis_max,只取条件字段中得分最大的字段。如果只用dis_max效果还不好:

这里是在最佳匹配的基础上再加一个调整参数.
 这里有2个字段,一个必然是最佳字段,另一个就是其它字段.带入上面计算公式.
这里有2个字段,一个必然是最佳字段,另一个就是其它字段.带入上面计算公式.

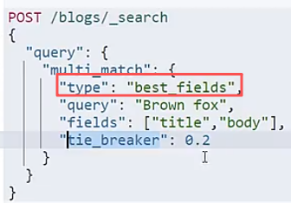 语法更简洁.
语法更简洁.
4.15.3 cross fields 跨字段搜索
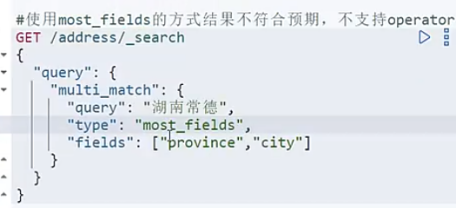 这种的查询一般是想要province里出现湖南,city里出现常德.但是这么查询会导致province或者city里只有一个满足条件的也被查出来.不是我们想要的结果.
这种的查询一般是想要province里出现湖南,city里出现常德.但是这么查询会导致province或者city里只有一个满足条件的也被查出来.不是我们想要的结果.
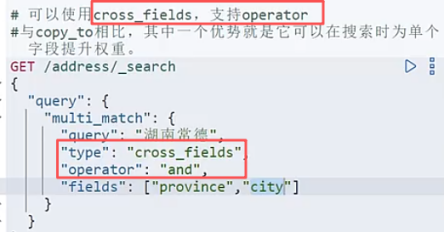
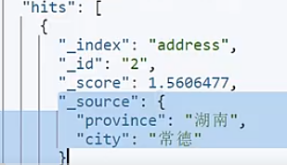
还可以使用 copy to.(额外增加一些存储空间,但是查询效果很好)
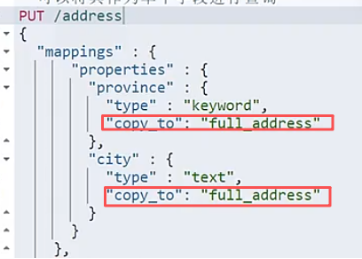
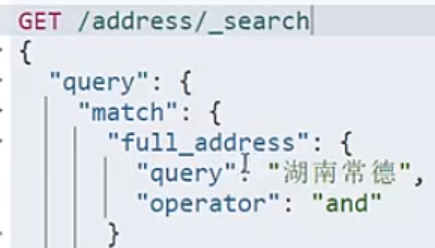








copy to的缺点,增大系统开销,存储和cpu消耗, copy to字段无法精细控制各字段权重.
只能在同一个索引的字段之间操作.
4.17 指标聚合操作详解
|----------------------------------------------------------------------------|-------------------------------------------------------------------|
|  | 指标聚合: 最大,最小,count,求和,平均 桶聚合: group by,range,直方图 管道聚合:基于上一次聚合的二次聚合 |
| 指标聚合: 最大,最小,count,求和,平均 桶聚合: group by,range,直方图 管道聚合:基于上一次聚合的二次聚合 |

举例子:
先对员工工种进行分组,再对分组后的结果计算平均工资
 min_bucket(最小值),percentitles_bucket(百分位),cumulative_sum(累计求和)
min_bucket(最小值),percentitles_bucket(百分位),cumulative_sum(累计求和)
4.21 ES聚合分析不精准原因分析
数据量,精确度,实时性 只有2者能同时满足.
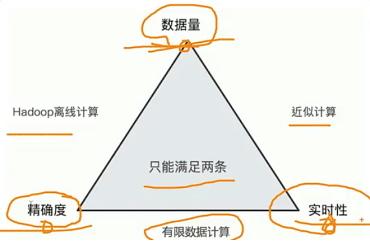 ES就是选择了海量数据+实时性,牺牲了精确度.
ES就是选择了海量数据+实时性,牺牲了精确度.
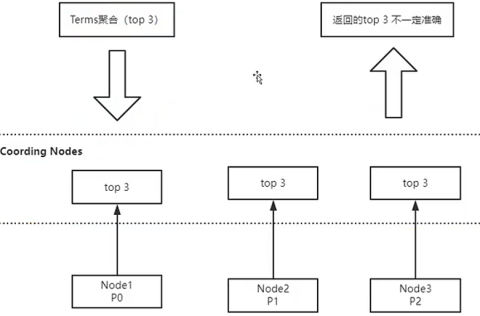 多分片汇总,单分片获取数据可能会漏
多分片汇总,单分片获取数据可能会漏
4.22 ES聚合不精准的解决方案
 方案3不考虑
方案3不考虑

4.23 ES聚合性能优化
|---------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------|
| ①插入数据的时候做预排序(不建议,会影响写入性能) | 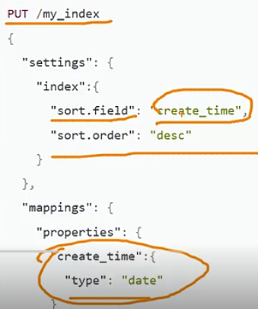 |
|
| ②使用filter过滤器,带有缓存功能 | 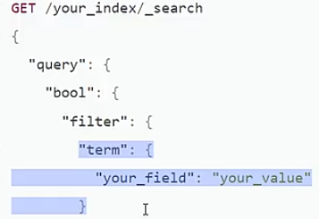 |
|
| ③统计的时候设置size=0也会缓存结果. | 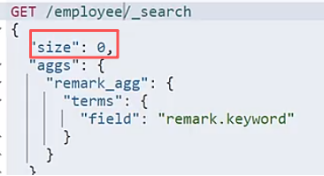 |
|
| ④拆分聚合,是聚合并行化.借助msearch实现 | 
 |
|
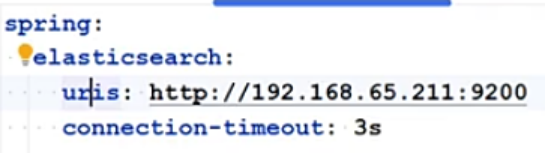
5.1 SpringBoot整合ElasticSearch
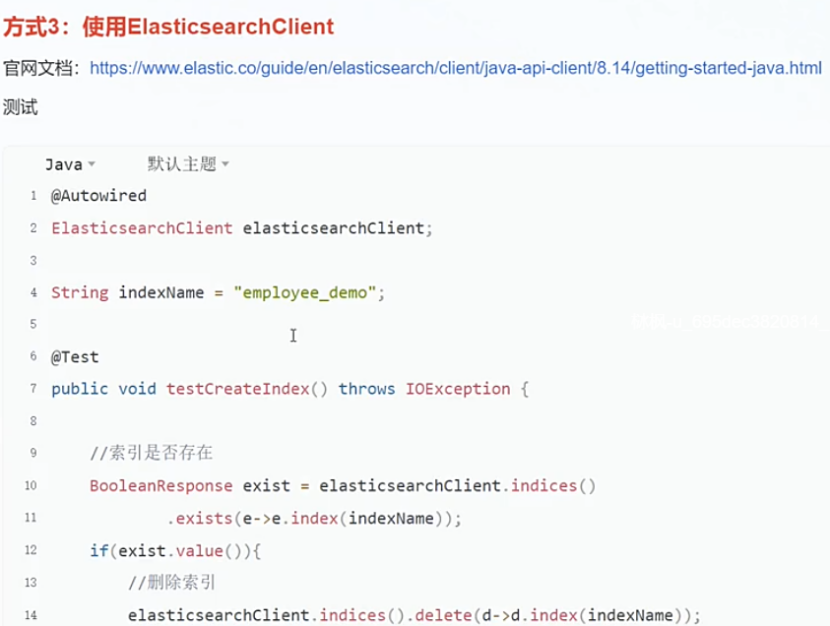
复杂业务用方式3
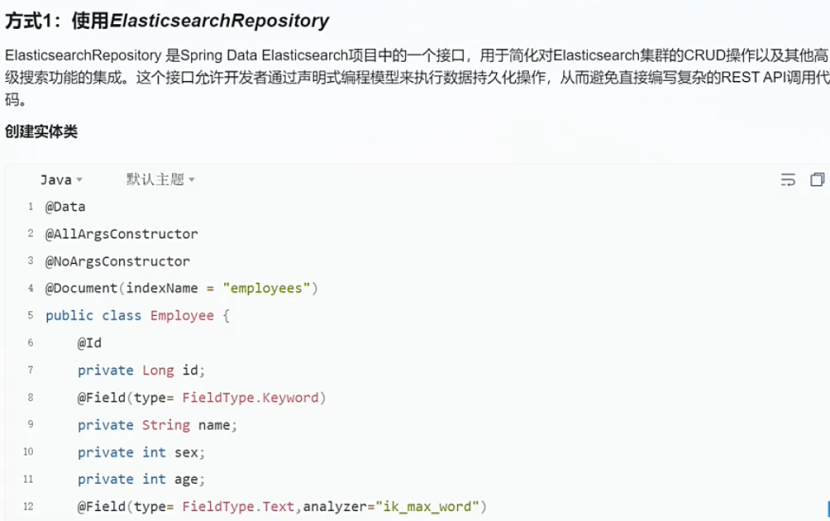
方式一(repository):(简单场景可以简化开发)

 创建实体->定义接口方法
创建实体->定义接口方法
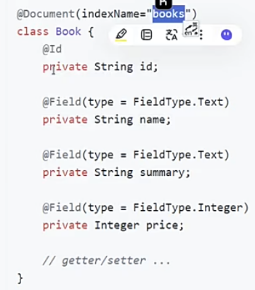
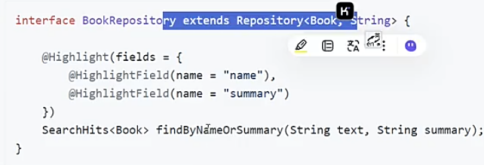
接口中的方法会被自动翻译成下面这样的语句:

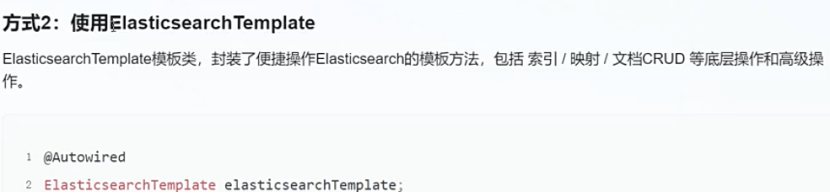
方式2(template): 也是封装了一些简单的方法.但是更灵活一点.复杂查询要构建Query对象

方式3(Client): 适合lambda表达式
【50、ElasticSearch深分页详解与自定义分词器实战】6.1深分页会带来什么问题
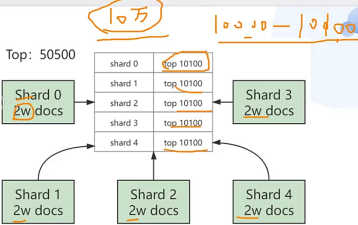 深分页不推荐使用from+size
深分页不推荐使用from+size

①在多分区模式下,深分页查询的数据太多了会导致FullGC;
②使用from...size必须查询结果小于10000条;

方案一:谷歌百度都不做跳页了你还有啥理由要支持深分页;翻那么深才找到想要的数据是不是你搜索做的不通人性?
方案二:使用scroll_search,缺点是只能一页一页往后翻.

方案三:search_after,会创建一个时间点来形成一个视图,保证查询一致性.(像Mysql)

7.1 分词的概述
有些时候IK分词器不适用,需要自定义分词器.
分词发生的阶段是在索引的时候,先分词再构建倒排索引.
检索过程也会使用分词器.
7.2 分词器的组成
字符过滤器(过滤标点符号)->切词器(真正分词)->词项过滤器(比如做大小写转换)
模式上看就是在真正切词操作的前后加上预处理和后处理,类似AOP
3个部分可以单独设置的.
各种字符过滤器:
|----------------------------------------------------------------------------|-------------------------|
| 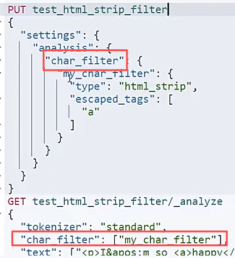 | 这里是设置了a字符过滤,结果是保留文本+a字符 |
| 这里是设置了a字符过滤,结果是保留文本+a字符 |
| 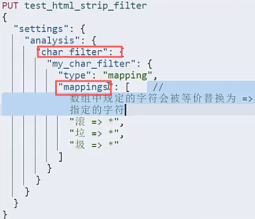 | 这里是设置了屏蔽,很实用的功能. |
| 这里是设置了屏蔽,很实用的功能. |
|  | 还可以按正则规则来替换,很有用. |
| 还可以按正则规则来替换,很有用. |
各种分词器
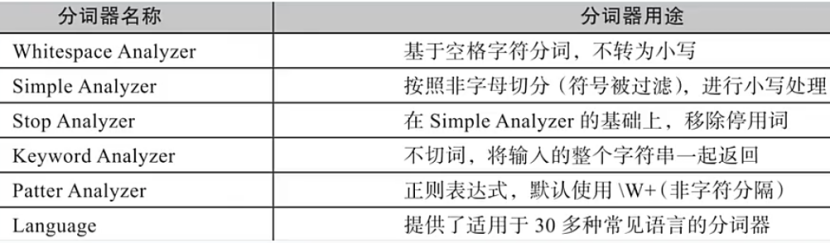
词项过滤器:
可以用来做大小写转换,还有停用词(过滤掉and,or之类的)
7.4 Ngram自定义分词实战
需求背景:

还有查手机号,只对匹配到的输入数字进行高亮,而不是整个手机号高亮
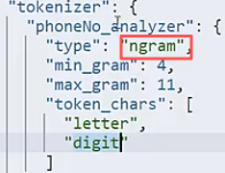 最小4,最大11.也就是说会有4个数字的,5个数字的,6个数字的...
最小4,最大11.也就是说会有4个数字的,5个数字的,6个数字的...