学习笔记|B 站 UP 主 刘二大人 《PyTorch深度学习实践》视频知识点总结
结尾附上老师代码
传送门 PyTorch深度学习实践------加载数据集
视频中截图
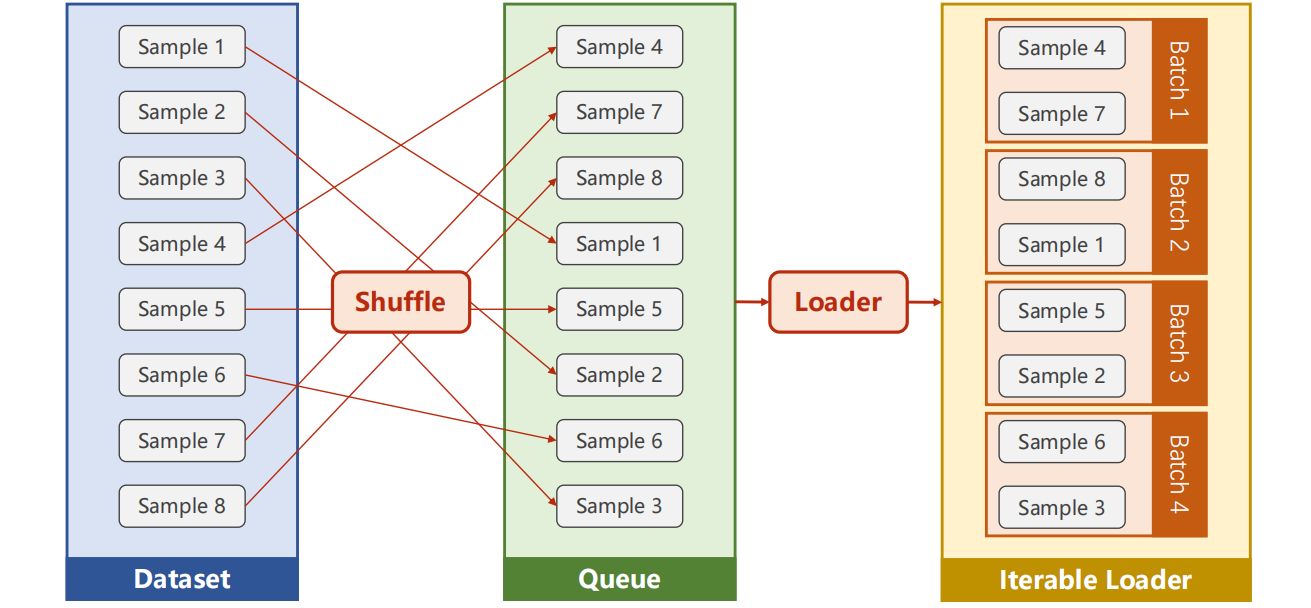
- DataSet 是抽象类 ,不能实例化对象,主要是用于构造我们的数据集
- DataLoader 需要获取DataSet提供的索引i和len;用来帮助我们加载数据,比如说做shuffle(提高数据集的随机性),batch_size,能拿出Mini-Batch进行训练。它帮我们自动完成这些工作。DataLoader可实例化对象。DataLoader is a class to help us loading data in Pytorch.
- __getitem__目的是为支持下标(索引)操作
1. 核心概念回顾
1.1 Dataset 与 DataLoader 核心作用
- Dataset :抽象类,用于定义数据的读取逻辑 ,需实现
__len__()(返回数据集总长度)和__getitem__()(按索引读取单条数据)两个核心方法; - DataLoader :基于 Dataset 封装,实现批量加载、数据打乱、多线程读取等功能,是训练时获取数据的核心接口;
- 核心目标:将数据读取与模型训练解耦,提升代码复用性和训练效率。
1.2 关键参数说明
- DataLoader - batch_size :每个批次的样本数量(核心参数),需根据显卡显存大小灵活调整,显存不足时可适当减小该值;
- DataLoader - shuffle:是否在每个训练轮次(epoch)打乱数据顺序,训练集建议设为 True(避免模型学习数据顺序规律),测试集建议设为 False(保证评估结果可复现);
- DataLoader - num_workers:用于数据加载的子进程数量,作用是多线程加速数据读取,Windows 系统下建议设为 0(避免进程报错),Linux/macOS 可根据CPU核心数设为 4/8 等;
- DataLoader - drop_last :是否丢弃最后一个不足
batch_size的批次,设置为 True 可保证每个批次的样本数量统一,避免维度不匹配问题。
2. PyTorch 加载数据集的实践
方式1:加载自定义数据集(TensorDataset)
适用于数据已转为 Tensor 格式的场景(如自定义生成/预处理的数据):
python
import torch
import numpy as np
from torch.utils.data import TensorDataset, DataLoader
# 1. 生成模拟数据(多维特征+标签)
torch.manual_seed(42)
features = torch.randn(1000, 5) # 1000个样本,5维特征
labels = torch.randn(1000, 1) # 1000个标签(回归任务)
# 2. 构建 Dataset
dataset = TensorDataset(features, labels) # 直接封装特征和标签
# 3. 构建 DataLoader
train_loader = DataLoader(
dataset,
batch_size=32, # 每个批次32个样本
shuffle=True, # 训练集打乱数据
num_workers=0, # Windows 下设为0,Linux/macOS 可设为4/8
drop_last=True # 丢弃最后不足32个的批次
)
# 4. 遍历 DataLoader 获取数据
for epoch in range(2): # 模拟2个训练轮次
print(f"===== Epoch {epoch+1} =====")
for batch_idx, (batch_features, batch_labels) in enumerate(train_loader):
# batch_features: (32, 5),batch_labels: (32, 1)
print(f"Batch {batch_idx+1} | 特征维度: {batch_features.shape} | 标签维度: {batch_labels.shape}")
# 此处可添加模型前向传播、反向传播逻辑
if batch_idx == 2: # 仅打印前3个批次
break方式2:自定义 Dataset 类(加载本地文件)
适用于加载 CSV/图片等本地文件的场景:
python
import torch
import pandas as pd
from torch.utils.data import Dataset, DataLoader
# 1. 自定义 Dataset 类
class CustomDataset(Dataset):
def __init__(self, csv_path):
# 初始化:读取数据
self.data = pd.read_csv(csv_path)
self.features = torch.tensor(self.data.iloc[:, :-1].values, dtype=torch.float32)
self.labels = torch.tensor(self.data.iloc[:, -1].values, dtype=torch.float32).unsqueeze(1)
def __len__(self):
# 返回数据集总长度
return len(self.data)
def __getitem__(self, idx):
# 按索引返回单条数据(特征+标签)
return self.features[idx], self.labels[idx]
# 2. 生成测试CSV文件(实际场景替换为本地文件路径)
test_data = pd.DataFrame(np.random.randn(500, 6)) # 500行,前5列特征,最后1列标签
test_data.to_csv("test_data.csv", index=False)
# 3. 加载自定义数据集
dataset = CustomDataset(csv_path="test_data.csv")
test_loader = DataLoader(
dataset,
batch_size=16,
shuffle=False, # 测试集不打乱
num_workers=0
)
# 4. 遍历数据
print("\n===== 自定义Dataset加载结果 =====")
for batch_features, batch_labels in test_loader:
print(f"特征维度: {batch_features.shape} | 标签维度: {batch_labels.shape}")
break关键代码解析
TensorDataset:PyTorch 内置的简易 Dataset,适用于特征和标签均为 Tensor 的场景,无需自定义类,快速实现数据封装;__len__()和__getitem__():自定义 Dataset 必须实现的两个方法,分别用于返回数据集长度和按索引读取数据,是自定义数据加载逻辑的核心;shuffle=True:训练集开启打乱,能避免模型学习数据顺序规律,提升泛化能力;测试集关闭打乱,保证评估结果可复现;batch_size选择 :需根据显卡显存调整,显存不足时减小 batch_size,避免CUDA out of memory错误。
3. 进阶技巧
-
数据预处理集成 :可在自定义 Dataset 的
__getitem__()中集成数据增强、标准化等预处理逻辑:pythondef __getitem__(self, idx): feature = self.features[idx] label = self.labels[idx] # 标准化处理 feature = (feature - feature.mean()) / feature.std() return feature, label -
划分训练/测试集 :使用
random_split拆分 Dataset 为训练集和测试集:pythonfrom torch.utils.data import random_split train_dataset, test_dataset = random_split(dataset, [800, 200]) # 800个训练样本,200个测试样本 -
加载内置数据集 :PyTorch 提供
torchvision.datasets/torchtext.datasets加载经典数据集(如 MNIST、CIFAR10):pythonfrom torchvision.datasets import MNIST from torchvision.transforms import ToTensor mnist_dataset = MNIST(root="./data", train=True, download=True, transform=ToTensor())
老师代码
python
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# prepare dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # shape(多少行,多少列)
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0) #num_workers 多线程
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# training cycle forward, backward, update
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
- 需要mini_batch 就需要import DataSet和DataLoader
- 继承DataSet的类需要重写init,getitem,len魔法函数。分别是为了加载数据集,获取数据索引,获取数据总量。
- DataLoader对数据集先打乱(shuffle),然后划分成mini_batch。
- en函数的返回值 除以 batch_size 的结果就是每一轮epoch 中需要迭代的次数。
- nputs, labels = data中的inputs的shape是32,8,labels 的shape是32,1。也就是说mini_batch在这个地方体现的
- diabetes.csv数据集 老师给了下载地址,该数据集需和源代码放在同一个文件夹内。