1.网络通信的本质
我们平时说两台设备在通信,原理上听起来像是机器和机器在对话,但本质根本不是这样。
日常生活中用手机刷抖音,点开抖音这个软件,它一旦启动,就会被加载到内存里,在操作系统中变成一个进程。
你刚开始刷视频时,本地是没有视频数据的,所以抖音这个进程就会通过系统里的网络协议栈,向远方的抖音服务器发送请求。
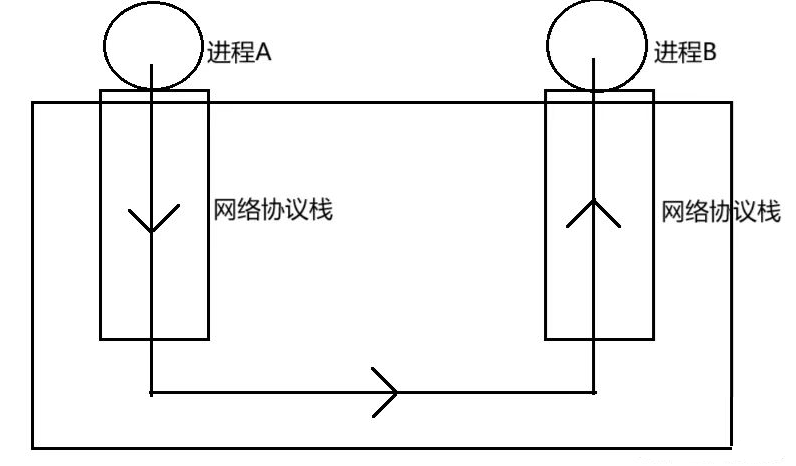
而另一边的抖音服务器,看起来是一台强大的机器,但真正干活的同样是运行在内存里的服务进程。
服务器进程会一直循环等待、被动接收外面发来的请求,收到后再处理、返回数据。
所以整个流程其实是:
你这边的进程 → 通过网络协议栈发请求 → 对方服务器的进程接收 → 再返回数据。
也就是说,网络通信的本质,其实就是跨设备的进程间通信。
网络通信,本质就是进程间通信。
2.端口号
比如你在自己电脑上打开微信,想给别人发消息。
流程很简单:你的微信先把数据发给微信服务器,服务器再帮你转发给对方,最后还给你一个"发送成功"的反馈。数据的传输:你的微信客户端 → 微信服务端 → 服务端再把结果传回你的客户端。
之前我们已经知道,IP地址是用来标识一台主机的。数据打包时,会带上源IP(你的机器)和目的IP(服务器机器),依靠IP,数据就能准确送到目标主机。
但问题来了:
服务器收到数据后,知道是发给自己的。可一台服务器上同时跑着很多应用------微信服务端、抖音服务端、网易云服务端...... 传输层拿到数据后,怎么知道该把数据交给哪一个应用?
这时候,端口号就出现了。端口号是传输层里的概念,占2字节(16位),是一个整数。它的作用非常明确:标识同一台主机里,具体是哪个网络进程在通信。 使用方式就是:把端口号和进程绑定。
服务器在启动时,早就把服务进程和固定端口号绑好了。当数据到达传输层,解包后会看到包头里有源端口、目的端口。只要目的端口和服务器上微信服务绑定的端口一致,传输层就知道:这个数据是给微信服务的,于是把内容上交给应用层的微信服务进程。
这样,微信服务端就成功拿到了你发的数据。
那服务器处理完后,怎么把结果传回你的微信呢?
很简单:你发过去的报文里,已经带上了你的IP + 你的微信进程绑定的端口。你的微信启动后就是一个进程,只要进行网络通信,系统就会给它分配端口,方便对方回复。
服务器拿到你的IP和端口后:
- 把自己的IP当源IP
- 自己的端口当源端口
- 你的IP当目的IP
- 你的端口当目的端口
再通过协议栈发回给你,你的机器收到后,同样根据端口号,把数据交给微信客户端。
所以我们可以总结:
IP地址:在整个互联网里,唯一标识一台主机。
端口号:在一台主机里,唯一标识一个网络进程。
合在一起:
IP + 端口 = 互联网上唯一的一个网络进程
而socket(套接字),本质就是封装了IP和端口,只要两边都有(客户端IP:端口、服务端IP:端口),就能完成稳定的网络通信。
系统里不是已经有PID(进程号)可以唯一标识进程了吗?为什么还要专门搞一个端口号?
原因主要有两点:
- 不是所有进程都需要联网,但所有进程都必须有PID。端口号只给需要网络通信的进程用,更精准。
- PID是操作系统内核层面的概念,属于系统模块。如果网络协议直接依赖PID,那系统一旦改了PID规则,整个网络模块都要改。网络和操作系统是两个独立模块,我们希望它们低耦合、互不干扰。所以网络层专门设计了自己的"端口号"来标识进程,不管操作系统怎么变,网络层都不受影响。
这也就是端口号存在的意义。
一个进程可以绑定多个端口号,一个端口号不能被多个进程绑定。
3.UDP协议和TCP协议
TCP 协议
TCP(传输控制协议)是一种面向连接、可靠且基于字节流的传输层协议。
特点:
- (1)传输层协议
- (2)建立连接
- (3)可靠传输
- (4)面向字节流
使用 TCP 进行通信时,双方必须先建立连接。只有连接成功建立,数据才能开始传输。它保证了三件事:
- 数据一定能送到对方主机
- 数据不会丢失
- 数据会按顺序整齐到达
TCP 是基于字节流传输的,也就是说,数据会被拆成一个个字节,再逐个发送给对方。因为它的安全性和可靠性非常高,所以常用于支付、银行系统等对数据准确性要求极高的场景。
但它的代价是 效率较低。为了保证可靠,TCP 需要三次握手建立连接,四次挥手断开连接,还要做确认机制、超时重传、乱序修复等等。这些操作都会消耗系统资源,也会拖慢传输速度。
UDP 协议
UDP(用户数据报协议)则是另一种风格,它是一个无连接、不可靠、面向数据报的协议。
特点:
- (1)传输层协议
- (2)无连接
- (3)不可靠传输
- (4)面向数据报
使用 UDP 时,双方不需要建立连接,发送方把数据准备好就可以直接发出去,不等待对方的状态,也不做任何检查。一旦数据发出,本地就不再保留,因此它速度很快、延迟低。
缺点是:它不保证数据一定到达,也不保证顺序是否正确。丢包、乱序、重复,它都不会处理。
正因为不做任何"可靠工作",UDP 的效率非常高,适合实时场景。比如视频通话、直播、游戏、网络监控、日志传输等都经常用 UDP。
4.网络字节序
在网络通信里,有一个必须解决的"硬件歧义"问题:不同主机在内存里存储多字节数据的顺序是不一样的。
一边是大端机(高位在前),一边是小端机(低位在前)。如果两边直接按各自的内存格式发数据,接收方解读出来就会是乱码。即使数据包里带了"我是大端/小端"的标识,也没用,因为接收方不知道怎么反解析,看不懂对方的字节流格式。所以,网络协议直接做了统一规定:所有数据在网络上传输时,必须统一成大端字节序。 这就叫网络字节序。
什么是大端与小端
大端:数据的高位字节放在内存的低地址,像"正常读数"一样,从大到小排列。
小端:数据的低位字节放在内存的低地址,更接近硬件的"直白存储"方式。
记忆方式只记一个就行:
小小小(低位 → 低地址) = 小端。
剩下的情况,统统是大端。
网络传输规则
TCP/IP 协议规定:
-
发送方从缓冲区低地址到高地址依次发送字节。
-
接收方从网络收到的字节,也是按低地址到高地址的顺序存进缓冲区。
-
所以网络字节流的顺序 = 大端字节序。
无论你本地是大端还是小端,发数据前都必须转换成网络字节序(大端),收数据时再根据需要转回本地字节序(大端或者小端)。
主机字节序与网络字节序的转换
在 socket 编程里,系统提供了专门的转换函数,命名非常直观:
h = host(主机字节序)
n = network(网络字节序)
s = short(16 位,例如端口号)
l = long(32 位,例如 IP 地址)
函数如下:
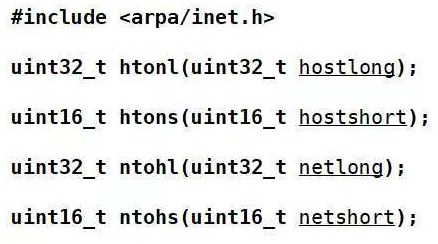
当你在小端机上调用 htonl 时,它会自动把你的小端数据转换成大端,再发出去;
如果在大端机上调用,它则直接返回原数据。
5.套接字

套接字在网络编程里不是单一类型,而是根据使用场景分成了三类。它们虽然功能不同,但系统为了方便开发者,统一了一套接口,使得在三种套接字上都可以用 socket 、 bind 等函数来操作。
三种主要的套接字类型
- 域间套接字(AF_UNIX / AF_LOCAL)
这种套接字只用于 同一台主机内 的进程通信。它不需要网络协议栈,而是通过一个文件路径来标识,两个进程只要看到同一个"文件"就能通信。
- 原始套接字(Raw Socket)
原始套接字权限更高,可以绕过传输层,直接访问到 网络层、数据链路层。常用于抓包、协议分析、网络诊断工具等。
- 网络套接字(AF_INET / AF_INET6)
这是最常用的,用于 跨主机网络通信。基于 IP 地址和端口号,实现 TCP/UDP 网络编程。
为什么三套套接字要共用一套 API?
如果三套套接字分别用三套完全不同的接口,学习成本会很高,代码也不统一。
因此操作系统设计者把三类套接字统一到一套通用接口中,也就是三个套接字的操作都可以使用socket来操作。
socket 参数
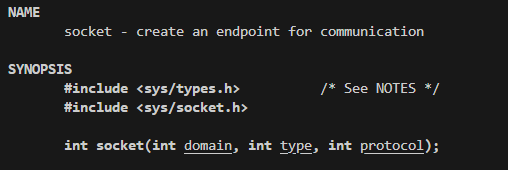
创建套接字时,必须指定一个 协议族(Domain),告诉系统你想用哪类套接字:
如果是本机通信: AF_UNIX 或 AF_LOCAL
如果是网络通信: AF_INET (IPv4)或 AF_INET6 (IPv6)
第二个参数指定类型:
UDP: SOCK_DGRAM
TCP: SOCK_STREAM
第三个参数一般填 0。
创建成功后返回一个 文件描述符。
这也符合 Linux "一切皆文件" 的设计------套接字本质上也是一个文件对象。
6.bind (兼容三种结构体)
网络套接字要绑定 IP 和端口。
域间套接字要绑定文件路径。
原始套接字又有别的结构。
但是bind 的接口必须统一,所以系统做了两件事:
(1)使用通用结构体 struct sockaddr 作为统一接口,虽然它是"通用容器",但内部真正的数据取决于协议族。
(2)用具体结构体填充内容,再强制转换成 struct sockaddr*
比如:
cpp
网络套接字用: struct sockaddr_in
域间套接字用: struct sockaddr_un 它们前 16 个字节都存放"家族信息"(如 AF_INET、AF_UNIX)。
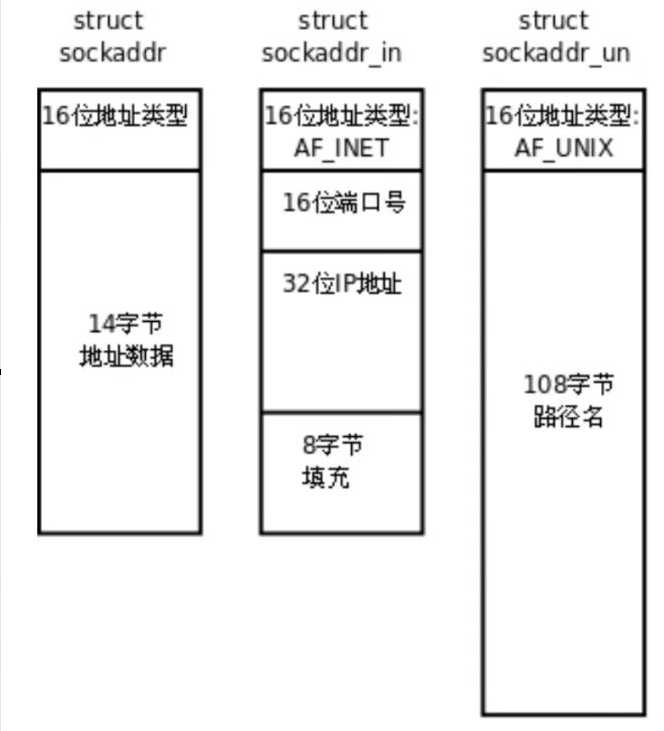
这样内核在 bind 内部就能判断:"你传进来的是哪类套接字,我应该进入哪套处理逻辑"。
内核内部的逻辑类似:
cpp
if (addr->family == AF_INET) {
// 处理网络套接字
} else if (addr->family == AF_UNIX) {
// 处理域间套接字
}