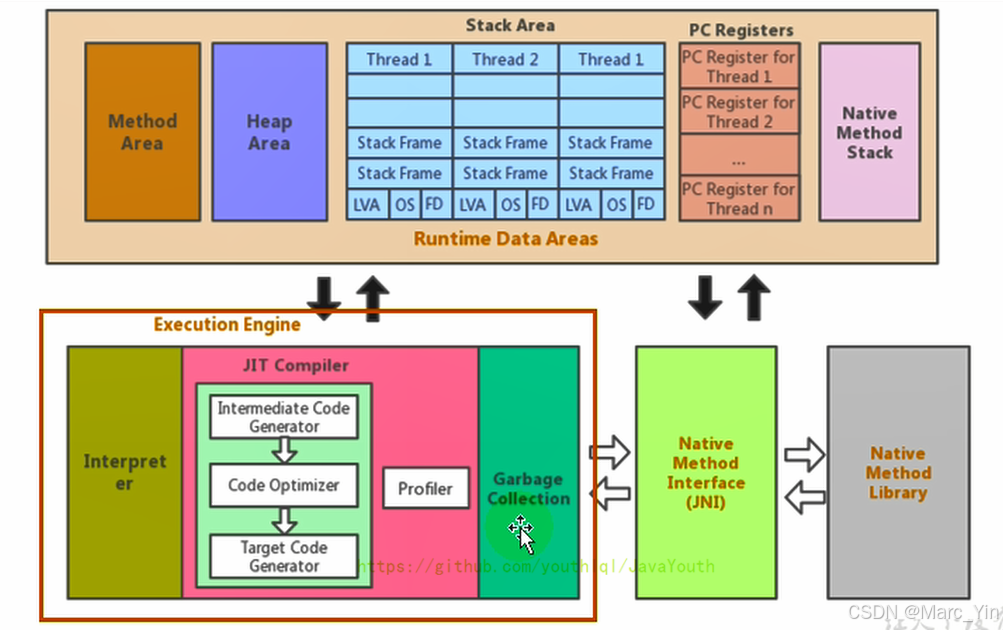
执行引擎概述
执行引擎Execution Engine 是 Java虚拟机 的核心组件之一
负责执行JVM运行时数据区当中的字节码指令,并将其转换为可以在底层硬件上执行的操作
-
虚拟机 Vitrual Machine 是相对于物理机 Physical Machine 的概念
两者都具备代码执行能力,但是实现方式不同:
-
物理机执行依赖于:
-
CPU
-
指令集架构
-
寄存器
-
缓存
-
操作系统
-
-
CPU直接执行机器指令(Machine Instruction)
- Java虚拟机的指向性引擎是通过软件实现的,并不直接执行CPU指令,而是执行Java字节码(ByteCode)
JVM通过解释器或JIT即时编译器将字节码转换为当前平台本地机器指令,再由CPU执行
- JVM主要任务之一就是加载并运行字节码程序
Java源代码首先会通过Java编译器(EX:JavaC)编译为字节码文件
这些字节码文件不能在CPU/OS上执行,因为:
-
字节码指令并不是CPU机器指令
-
它是一种面向JVM的中间指令集
字节码文件当中主要包含:
-
字节码指令
-
常量池
-
符号引用
-
方法信息
-
字段信息
-
其它类信息
- Java程序运行时,执行引擎负责执行这些字节码指令
执行引擎主要有两种执行方式:
-
解释执行(Interpretation):逐条读取字节码指令,将其翻译为对应的机器指令
-
即时编译执行(JIT Compilation):将热点代码编译为本地机器码,并缓存起来,下一次执行的时候直接执行本地机器码,从而提高性能。
-
从整体上来看,Java程序的执行过程可以分为两个阶段:
- 前端编译
指的是:Java源代码→Java字节码
由Java编译器(例如javac)完成
例如:Hello.java→Hello.class
- 运行时/即时编译
指:字节码→本地机器码
由JVM在运行期间完成
运行方式可能是解释执行或者是JIT编译执行
因此可以总结为:
Java源码
↓ 前端编译
字节码
↓ JVM执行引擎
机器指令
↓
CPU执行
执行引擎工作过程
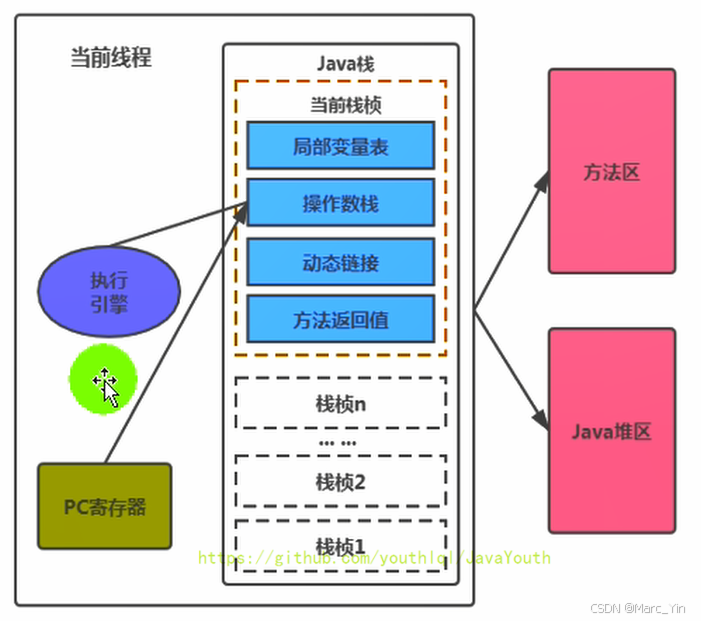
执行引擎&PC寄存器之间的关系
执行引擎执行字节码时,需要按照当前线程PC寄存器所指示的位置获取下一条需要执行的字节码指令。
执行引擎根据地址读取对应字节码指令并执行。
指令执行与PC寄存器更新
当执行完一条字节码指令之后:
- 若该指令并没有改变控制流(例如
goto、if、invoke等)
则PC寄存器会自动更新为下一条字节码指令地址
- 若执行的是控制转移指令(例如跳转、方法调用、异常处理等)
PC寄存器会被更新为:目标指令地址
也就是PC寄存器作用是抗旨字节码指令执行顺序
执行过程当中对象访问
方法执行过程当中,执行引擎可能选哦访问对象实例
对象++引用++通常存储在栈帧中的局部变量表当中
当执行引擎需要访问对象时:
-
通过局部变量表中的对象引用找到对象实例(HotSpot JVM当中通常直接指向对象实例地址)
-
通过对象的对象头可以获得
-
对象运行时信息Mark Word
-
类元数据指针 Klass Pointer
-
通过Klass Pointer能够访问该类元数据,可以确定:
-
对象类型
-
字段结构
-
方法信息
-
虚方发表
-
-
-
执行引擎的输入、处理、输出
整体架构上看,JVM执行引擎工作流程可以抽象为:
输入
输入字节码指令
这些字节码源于:.class文件
由类加载子系统加载到JVM当中
处理过程
执行引擎对字节码处理主要包括:
-
字节码解释执行
-
JIT即时编译
-
运行时优化
具体流程(通常):
字节码
↓
解释执行
↓
检测热点代码
↓
JIT编译成本地机器码
↓
直接执行机器码输出
执行引擎执行字节码之后,最终产生结果:
-
程序状态状态
-
栈帧和内存数据变化
-
方法返回值
-
程序控制流变化
注意:
执行引擎并不会产生统一的输入输出数据流
而是通过执行指令改变JVM 运行时数据区状态改变体现指令执行结果
机器码 指令 汇编语言 字节码
计算机最终执行的是CPU指令
为了让程序更加容易编写,发展出了 机器语言→汇编语言→高级语言→字节码→虚拟机执行等一系列抽象层
整体关系可以概括为:
高级语言
↓ 编译/解释
汇编语言(可选)
↓ 汇编
机器码(Machine Code)
↓
CPU执行在虚拟机体系当中还会出现:
高级语言
↓
字节码
↓
虚拟机
↓
机器码
↓
CPU执行机器码
定义
CPU可以直接执行的二进制指令序列
EX:10110000 01100001
CPU根据指令集架构解析这些二进制位并执行响应操作
特点
-
CPU可以直接执行
- CPU控制单元会解析指令的操作码、操作数,执行相应操作
-
与硬件架构强相关
因此不同CPU机器码互不兼容
-
不同的CPU架构有不同的机器指令:
-
x86
-
ARM
-
-
-
可读性极差
-
机器码是纯二进制数据,人类几乎无法直接理解
-
早期通过机器码编写指令非常困难、易出错
-
指令&指令集
指令
CPU可以执行的一条基本曹祖
一条指令通常包含:
-
操作码(Opcode):执行什么操作
-
操作数(Oprand):操作的数据
指令集
CPU架构所支持的全部指令集合
常见架构&指令集:
-
x86架构:x86指令集
-
ARM架构:ARM指令集
指令集规定了:
-
指令格式
-
寄存器结构
-
寻址方式
-
数据类型
汇编语言
定义
机器语言的符号化表达形式
使用助记符(Mnemonic)标识机器指令
特点
-
比机器码更加易读
-
汇编语言使用助记符:
mov (移动)
add (加法)
sub (减法)
jmp (跳转)
-
-
与硬件强相关
-
不同CPU架构都有不同的汇编语言
-
汇编语言通常只能在特定平台运行
-
-
汇编程序需要通过汇编器转换为机器码(CPU只能执行机器码)
高级语言
为了提升开发效率,发明了高级语言
例如:
C、C++、Python、GOLang、Rust
特点
-
更接近自然语言和数学表达
-
与硬件细节解耦
-
更易维护和开发
高级语言必须通过编译器或者解释器转换为机器码才能运行
字节码
定义
一种介于高级语言和机器码的中间表示形式
字节码通常是面向虚拟机设计的字节码指令集
Java字节码
Java程序执行流程:
Java源码
↓ javac
Java字节码(.class)
↓ JVM
机器码
↓ CPU执行Java字节码特点:
-
平台无关
-
面向JVM
-
不能被CPU直接执行
JVM通过解释器/JIT即时编译器将字节码转换为机器码
C/C++程序执行过程
C/C++程序通常经过以下步骤:
源码
↓
预处理
↓
编译
↓
汇编
↓
链接
↓
可执行文件
↓
机器码运行具体流程:
预处理
处理:
-
宏展开
-
头文件包含
-
条件编译
生成预处理之后的源码
编译
编译器将高级语言转换为汇编代码
同时进行:
-
词法分析
-
语法分析
-
语义分析
-
代码优化
汇编
汇编器将汇编代码转换为机器指令(目标文件,EX:hello.o)
链接
链接器将多个目标文件+库文件合并生成最终可执行代码
例如:hello.exe
JVM解释器
解释器是JVM执行引擎重要组成部分
负责在程序运行时解释执行Java字节码指令
现代JVM当中,解释器通常和JIT编译器共同工作,构成JVM的混合执行模式。
为什么需要解释器
Java程序执行流程通常如下:
Java源码
↓ 编译器(javac)
Java字节码 (.class)
↓ JVM
机器码
↓
CPU执行字节码通常有以下特点:
-
与平台无关
-
面向JVM指令集
-
CPU并不能直接执行
JVM需要一种机制将字节码转换为可以在当前平台执行的操作
设计背景
Java设计的时候强调:"Write Once, Run Anywhere"(一次编写到处运行)
为了实现这个目标:
-
Java程序不会直接编译为平台相关的机器码
-
先编译为平台无关的字节码
后由JVM运行时执行字节码
解释器就是JVM当中最基础的执行机制
解释器作用
核心作用:读取字节码指令,按照JVM规范执行对应操作
大概执行流程:
PC寄存器定位当前字节码
↓
解释器读取该字节码
↓
执行对应操作
↓
更新PC寄存器
↓
继续执行下一条指令例如执行最简单的 int c=a+b
对应的字节码可能是:
iload_1
iload_2
iadd
istore_3解释器会:
读取 iload_1 → 从局部变量表加载
读取 iload_2 → 从局部变量表加载
读取 iadd → 执行加法
读取 istore → 写回局部变量表可以认为解释器本质上是一个字节码执行器
解释器并不是逐行解释程序,而是逐条字节码指令执行
需要注意的是:
系统本身是无法执行字节码的,
但是:
解释器执行字节码时,并不是把字节码"编译"为机器码,
而是执行已经存在的解释器机器代码来完成字节码语义。
解释器实现方式
JVM发展过程当中,解释器实现方式经历了改进
早期字节码解释器
早期JVM使用简单解释器
基本实现方式类似:
switch(opcode){
case IADD:
// 执行加法
break;
}这种实现方式:
-
完全使用软件逻辑模拟字节码
-
每条指令都要进行分支判断
缺点:
-
性能较低
-
分支开销大
-
CPU利用率极低
模板解释器
现代HotSpot JVM使用的是:
模板解释器Template Interpreter
核心思想:
为每条字节码准备一段预定义的机器码模板
执行流程:
字节码
↓
找到对应模板
↓
执行该模板机器代码例如:iadd命令,会跳转到iadd_template
这段代码本身已经是本地机器指令
优点:
-
减少分支判断
-
提升执行效率
-
更好利用CPU
模板解释器性能比简单解释器性能更高
HotSpot中解释器结构
HotSpot JVM当中,解释器属于执行引擎一部分
核心组件包括:
-
Template Interpreter
-
Bytecode Dispatch
-
Runtime Support
虽然解释执行性能通常低于编译执行,但是解释器仍然有重要作用:
-
提供程序启动能力(JIT编译需要时间,程序刚启动时依赖解释器执行)
-
提供JVM语义保证:解释器是JVM最标准的执行模型,严格按照JVM规范执行字节码语义
-
支持动态编译策略:解释器可以收集方法调用次数、循环执行次数、热点信息,为JIT编译提供数据
JIT编译器
相关概念
Java编译过程的三个阶段
Java代码从源码到最终在CPU上执行,通常涉及三个不同编译/转换阶段,他们在时间点、输入输出以及作用上有着明确的区别:
-
前端编译 Compile Time:
这是传统意义上的"编译期"。指由前端编译器将
.java源代码文件转换为符合JVM规范的字节码(.class文件的过程)。此过程主要进行语法分析、语义分析&字节码生成,不涉及具体机器码生成也不依赖虚拟机运行。 -
即时编译 Runtime-JIT COmpilation:
这是虚拟机运行期的核心优化手段。指在JVM在程序运行时,通过内置的JIT即时编译器将热点带啊的字节码动态编译为本地机器码的过程。HotSpotVM 采用分层编译策略,根据代码的热度在解释执行、C1编译(轻量优化)、C2编译(深度优化)之间动态切换,以平衡启动速度&运行性能。
-
提前编译 Ahead Of Time Compillation AOT:
指在程序运行事前,直接将.
class字节码(或者.java源码)预先编译为本地机器码的过程。-
在标准的HotSpot VM(Java 9+)中,提供了基于Graal 编译器的AOT支持(通过jaotc工具),可将部分类库预编译为本地代码以缩短启动时间,但运行时仍主要依赖JIT进行动态优化
-
在GraalVM Native Image等新技术中,AOT成为主导,能将Java应用直接构建为独立的可执行文件,但这属于特定发行版本特性,并不是标准HotSpot默认行为
-
典型编译器实现
-
前端编译器
-
javac:OpenJDK/Oracle JDK自带的标准编译器
-
ECJ(Eclipse Compiler for Java):Eclips JDT使用的增量式编译器,支持在IDE当中边写边编译
-
-
JIT编译器
-
C1(Client Compiler):客户端编译器。 编译速度快,优化策略保守,适用于对启动速度敏感的场景。
-
C2(Server Compiler):服务端编译器。编译耗时长,但执行激进的深度优化(EX:逃逸分析、标量替换、锁消除等),适用于长期运行的服务端应用。
-
Graal(可选):新一代模块化JIT编译器,可替代C2,提供更高的优化上线(需特定参数开启)
-
-
AOT编译器(提前生成机器码)
-
jaotc(HotSpot AOT Compiler):HotSpot VM(Java 9+)自带的AOT工具,基于Graal编译器,用于将java类库编译为共享库(
.so/.dll),供JVM启动时加载。 -
GraalVM Native Image :当前主流的AOT解决方案,能将Java应用静态编译为原生可执行文件,无需JVM即可运行(注意:这已经超出HotSpot VM范畴,属于是 Graal VM发行版特性)
-
热点代码&探测方式
JIT编译的触发条件
JVM并不会将所有字节码立刻编译为本地机器码。为了平衡启动速度和运行效率,JIT编译器仅针对执行频率高的代码段进行编译。是否需要启动JIT编译,取决于代码在运行时的热度(Hotness)
热点代码定义
那些在运行时被频繁执行的字节码片段称为热点代码。JIT编译器会识别这些代码,对其进行深度优化(内联、逃逸分析、锁消除等)并将其编译为特定平台的本地机器指令,从而显著提升执行性能
热点代码主要分为两类:
-
高频调用的方法:整个方法被频繁执行
-
高频执行的循环体:方法内部包含执行次数极多的循环结构
-
栈上替换On-Stack Replacement(注意和对象的栈上分配 Stack Allocation进行区分)
-
普通编译:对高频调用的方法,JVM通常在下一次调用的时候直接执行已经编译好的本地代码
-
OSR编译:对于一个正在执行中且包含长循环的方法,若该循环本身成为了热点,但是由于方法还未返回,无法通过"下次调用"切换为本地代码。这时,JIT编译器会将方法执行过程中动态编译循环体的本地代码,并替换当前解释器栈帧中正在执行的字节码,使程序直接从解释执行切换为本地代码执行
-
注意:并非所有热点代码编译都叫OSR,只有针对当前正在运行栈帧当中循环体执行的动态替换编译才是。
-
热点探测阈值
一个方法被调用多少次/一个循环体需要执行多少次回边(Back Edge)才会被判定为热点?这由热点探测阈值决定:
- 该阈值并非不变,HotSpot VM会根据当前编译队列负载、CPU核心数以及分层
HotSpot VM热点探测方式
目前HotSpot主要采用基于计数器的热点探测机制。 在分层编码模式下,JVM会为每个方法维护相关的计数信息(通常存储在MethodCounters/MethodData结构当中),主要包含两类计数逻辑:
-
方法调用计数器 Invocation Counter
-
用于统计该方法被调用入口命中次数
-
当此计数器达到阈值时,触发该方法的常规JIT编译/C1升到C2编译
-
-
回边计数器 Back Edge Counter
-
用于统计方法内部循环回边(跳转到循环头部的指令)的执行次数
-
当此计数器达到阈值时,表明循环体是热点。若方法正在执行,将触发OSR编译;若方法未在执行,则视该方法整体变热,可能触发常规JIT编译
-
补充:分层编译的协同
现代HotSpot VM当中,这两个计数器不仅用于判断"是否编译",还配合分层编译策略:
-
低阈值触发C1编译器进行快速编译(可能带Profiling)
-
高阈值/收集到足够profile信息之后,触发C2编译器进行深度优化编译
-
OSR编译同样遵循分层策略,确保长循环能尽快获得优化
触发JIT之后的编译流程
当一个方法被调用时,HotSpot VM执行逻辑如下:
检查本地代码版本
虚拟机首先检查该方法是否已经有有效的、已编译的本地代码版本(Native Code)
-
若存在:直接执行编译后的本地机器指令(性能最优路径)
-
若不存在:进入解释执行模式,更新计数信息
计数&独立判定
解释执行过程当中,JVM会分别更新两个独立的计数器,绝不相加:
-
方法调用计数器:每次方法入口被调用时+1
- 若该值超过方法调用阈值→提交常规编译请求。这将导致该方法在下一次被调用的时候执行本地代码
-
回边计数器:每次方法内部的循环发生回跳(Back Edge)时+1
- 若该值超过回边阈值→执行OSR编译请求。这允许JVM在方法当前正在执行的过程当中将正在运行的驯悍提替换为编译后的本地代码,无需等待方法返回。
编译&切换
-
一旦编译请求被提交给后台编译线程(C1/C2),解释器将继续执行当前任务
-
当前编译完成之后:
-
对于常规编译:下次调用该方法时,直接跳转到新的本地代码入口
-
对于OSR编译:若方法仍在运行且循环到达安全点,立即执行流切换到新编译的本地代码块当中。
-
-
未达到任何阈值,继续使用解释器执行字节码
分层编译中的协同 Tiered Compliation
现代默认配置下,计数器阈值判定是分层的:
-
低阈值:触发C1编译器进行快速编译(可能包含简单的Profiling)
-
高阈值:C1编译版本运行时并收集到足够性能分析数据(Profile Data)后,若热度持续上升,触发C2编译器进行深度优化重编译,替换掉C1生成的代码。
通过这种机制,HotSpot VM既保证了程序的快速启动(解释器&C1),又在长时间运行后达到极致的执行效率(C2负责)
热度衰减机制
相对频率而非绝对次数
HotSpot VM当中,方法调用计数器和回边计数器统计的并非方法被调用的历史绝对总和,而是一个反映近期执行频率的相对值
-
目的:程序热点是动态变化的。某段代码可能在启动初期频繁执行,但在稳定运行之后不再使用。若计数器只增不减,这些"曾经热点"会永久占用JIT编译资源,甚至导致编译队列阻塞,影响真正的热点编译
-
机制:为了识别当前热点,JVM引入了热度衰减机制
衰减&半衰周期
-
触发方式:热度衰减不是在垃圾收集时进行的,而是基于时间流逝动态触发的
-
HotSpot内部委会这一个全局的时间纪元
-
每当计数器需要增加时,JVM会检查当前纪元与上次纪元的差值
-
若时间间隔超过一个预设的半衰周期,计数器会被右移一位(即除2,向下取整)
-
-
半衰周期定义:计数器数值自动减半所需的时间间隔
- 注意:在标准的HotSpot实现中,这个周期通常是硬编码在源码当中的常量(大致对应几秒~十几秒的逻辑时间片)
关闭衰减
-
历史参数:在旧版本的 HotSpot 或未开启分层编译的模式下,曾存在
-XX:-UseCounterDecay参数用于关闭此功能。 -
后果:如果关闭热度衰减,计数器将统计绝对调用次数。这意味着只要系统运行时间足够长,几乎所有被调用过的方法最终都会达到编译阈值。这会导致:
-
编译资源浪费:大量冷代码被编译。
-
代码缓存(Code Cache):本地代码区迅速被填满,可能导致 JIT 编译器停止工作(SW 回退到解释器)。
-
-
现代建议:在现代 HotSpot(开启分层编译)中,强烈不建议关闭热度衰减。JVM 需要依靠衰减机制来动态感知热点的变化,确保 C1 和 C2 编译器专注于当前最热的代码路径。
C1、C2编译器不同优化策略
C1:快速编译&基础优化
C1的设计目标:极快的编译速度,以便程序能快速启动进入本地代码执行状态。主要执行局部优化、轻量级全局优化
主要优化策略:
-
基础线性扫描寄存器分配:快速生成机器码
-
简单的常量折叠&传播:编译期计算常量表达式
-
死代码消除:剔除那些在控制流当中永远无法到达(执行)的代码
-
受限的方法内联:仅对
final方法、static方法或私有方法进行内联。对于虚方法,C1 通常不进行复杂的去虚拟化内联,而是保留调用指令,或者仅在 Profile 数据极度明确时做极简单的优化。 -
收集 Profile 数据:C1 生成的代码通常包含插桩(Instrumentation),用于收集方法调用频率、分支概率、对象类型分布等数据,为 C2 的深度优化提供依据。
C2:深度优化&全局分析
C2的设计目标:生成最高性能的机器码,不惜花费更多的编译时间。
核心基础:逃逸分析 (Escape Analysis) 逃逸分析是 C2 进行内存和同步优化的基石。它分析对象的作用域,判断对象是否会被线程外部访问(即是否"逃逸"出方法或线程)。基于此,C2 实施以下关键优化:
-
标量替换 (Scalar Replacement):
-
原理:如果一个对象没有逃逸,且其成员变量(标量)可以被单独访问,JVM 就不会在堆上创建该对象实例,而是直接将对象的字段拆解为独立的局部变量(标量)存储在栈帧中。
-
效果:消除了对象头开销,减少了 GC 压力,提高了缓存命中率。
-
-
栈上分配 (Stack Allocation):
-
原理:这是标量替换的一种特例或延伸。对于未逃逸的对象,直接将其内存分配在线程栈上,而非 Java 堆上。
-
效果:对象随栈帧销毁而自动回收,无需 GC 介入,极大提升内存分配效率。(注:HotSpot 实际实现中,主要通过标量替换达成此效果,而非传统的"整个对象压栈")。
-
-
同步消除 (Synchronization Elimination):
-
锁消除 (Lock Eliding):如果通过逃逸分析证明一个被
synchronized保护的对象只被当前线程访问(未逃逸),那么该锁操作是多余的,C2 会直接移除锁的获取和释放指令。 -
锁粗化 (Lock Coarsening):如果在一段连续代码中频繁地对同一对象加锁、解锁,C2 会将这些离散的锁操作合并为一个范围更大的锁,减少同步开销。
-
其他 C2 独有或更强的优化:
-
深度去虚拟化 (Devirtualization):利用 CHA(类层次分析)和 Profile 数据,判断虚方法调用的接收者类型是否唯一。如果是,将虚调用转换为直接调用,并进一步内联该方法体。这是提升 Java 多态性能的关键。
-
全局冗余消除:跨越多个基本块,识别并消除重复的计算逻辑。
-
循环优化:包括循环展开 (Loop Unrolling)、循环不变量外提等。
难懂概念解释
什么是"去虚拟化" (Devirtualization)?
背景:Java 是多态语言。当你调用
list.add()时,list可能是ArrayList,也可能是LinkedList。JVM 在编译时不知道具体是哪个,所以字节码使用invokevirtual指令,运行时需要通过查表(vtable)找到具体代码,这叫"虚调用"。查表有性能开销,且阻碍了内联。优化:如果 JIT 编译器通过分析发现,在当前运行环境下,
list100% 是ArrayList(或者 99% 是,剩下 1% 做罕见分支处理),它就会把"查表"这个过程去掉,直接调用ArrayList.add()的代码。意义:这就叫"去虚拟化"。一旦去虚拟化成功,编译器就能把
add方法的代码直接"复制粘贴"到调用处(内联),进一步消除方法调用的开销。