
💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》
🌸Yupureki🌸的简介:

目录
[1. 项目整体框架设计](#1. 项目整体框架设计)
[2. threadcache框架设计](#2. threadcache框架设计)
[3. 内存对齐算法](#3. 内存对齐算法)
[4. 下标映射算法](#4. 下标映射算法)
[5. ThreadCache类初步实现](#5. ThreadCache类初步实现)
1. 项目整体框架设计
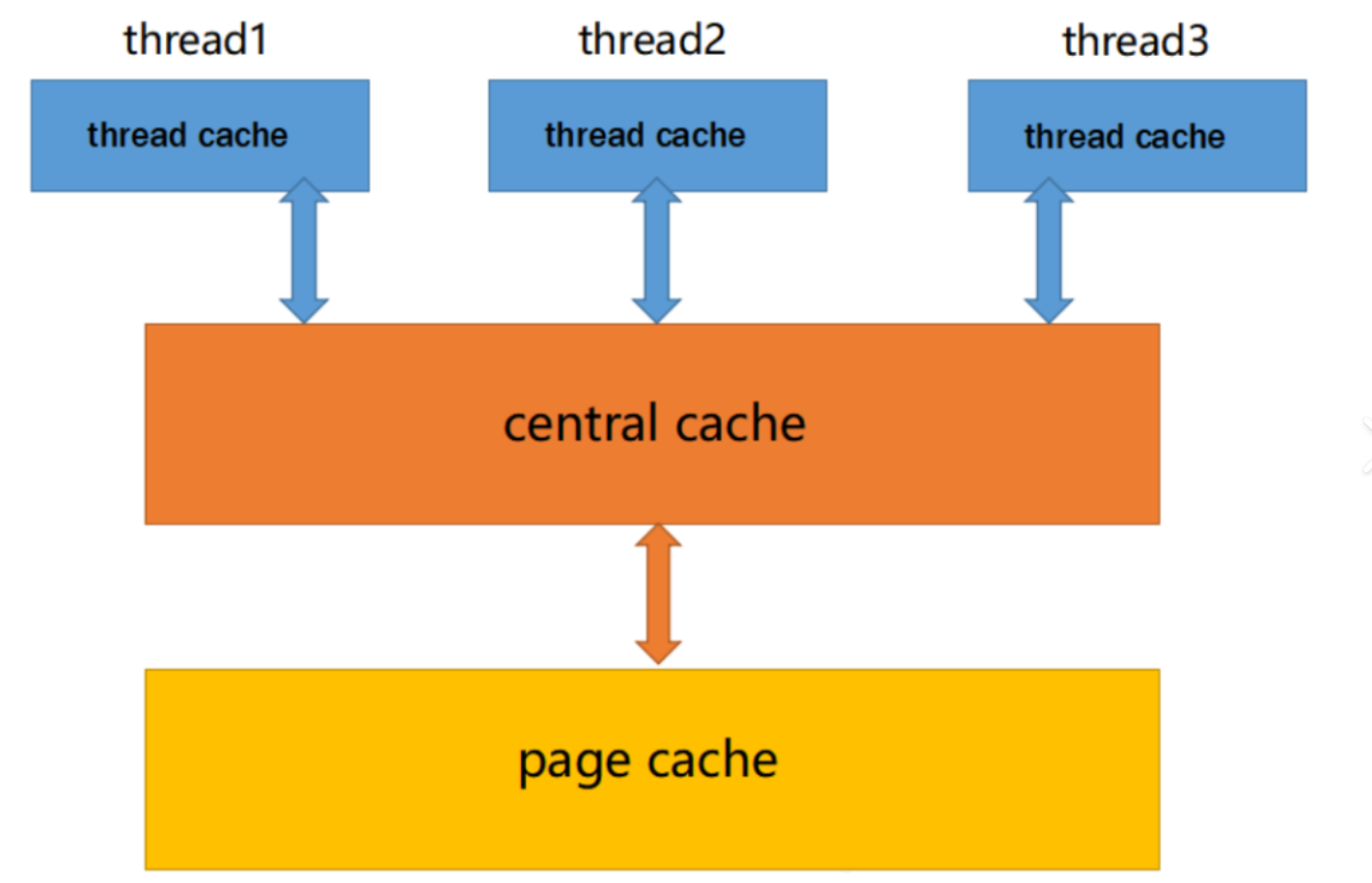
concurrent memory pool主要由以下3个部分构成:
- threadcache :线程缓存是每个线程独有的 ,用于小于256kB 的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
- centralcache:中心缓存是所有线程所共享的。当threadcache中内存不够用时,会向centralcache申请资源。因此centralcache存在多个线程共同访问的问题,需要加锁
- pagecache:页缓存是在centralcache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的。当centralcache内存不够用时,会向pagecache申请资源。如果pagecache中也没有足够的资源,会向系统申请。因此pagecache也存在多个线程共同访问的问题,需要加锁。
2. ThreadCache框架设计
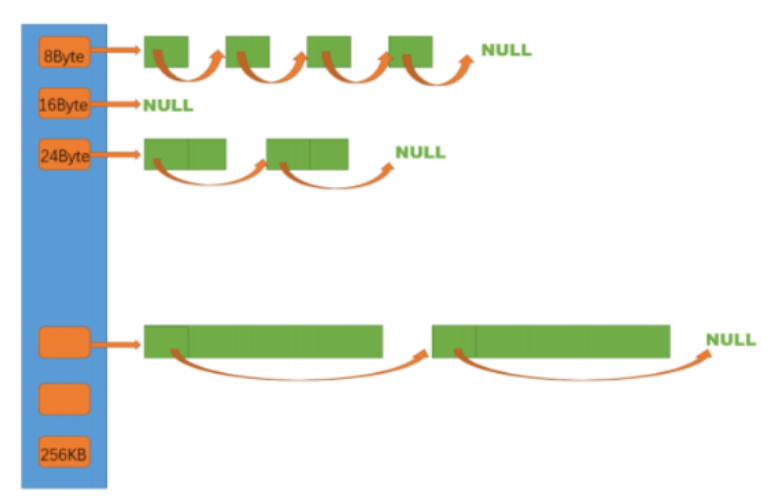
threadcache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表。每个线程都会有一个threadcache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
申请内存:
- 当内存申请size<=256KB,先获取到线程本地存储的threadcache对象,计算size映射的哈希桶自由链表下标i。
- 如果自由链表_freeListsi中有对象,则直接Pop一个内存对象返回。
- 如果_freeLists[ij中没有对象时,则批量从centralcache中获取一定数量的对象,插入到自由链表并返回一个对象。
释放资源:
- 当释放内存小于256k时将内存释放回threadcache,计算size映射自由链表桶位置i,将对象Push到_freeListsi。
- 当链表的长度过长,则回收一部分内存对象到central cache。
注意:
由于哈希桶所对应的内存大小不是连续的,比如一开始的是8字节,而下一个是16字节。那么假设我要11字节的内存大小怎么给?这样就必须给16字节,对其到第一个大于其的桶那。因此这种算法我们必须得实现一下。
ThreadCache整体框架:
cpp
class ThreadCache
{
public:
// 申请和释放内存对象
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
// 从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t size);
private:
FreeList _freeLists[NFREELIST];//哈希桶
};3. 内存对齐算法
谷歌的大佬们对哈希桶大小分布进行了研究,实现整体控制在最多10%左右的内碎片浪费
具体方案:
- 1,128 8byte对齐 freelist[0,16)
- 128+1,1024 16byte对齐 freelist[16,72)
- 1024+1,8\*1024 128byte对齐 freelist[72,128)
- 8\*1024+1,64\*1024 1024byte对齐 freelist[128,184)
- 64\*1024+1,256\*1024 8*1024byte对齐 freelist[184,208)
例如前128字节内实现8字节对齐,那么从头到尾为8字节,16字节,24字节....一直到128字节大小的桶,一共有16个。
加上后面的就一共有208个桶,因此_freeLists数组的大小应该是208
cpp
#define NFREELIST 208我们先实现一个算法:给定原大小和对齐数,计算出对齐后的大小
cpp
static inline size_t _RoundUp(size_t bytes/*原大小*/, size_t alignNum/*对齐数*/)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}示例验证
-
例1:
bytes = 13,alignNum = 8
13 + 7 = 20(二进制10100)
~7 = 0xFFFFFFF8(低 3 位为 0)
20 & 0xFFFFFFF8 = 16(二进制10000) → 向上取整到 8 的倍数 16。 -
例2:
bytes = 16,alignNum = 8
16 + 7 = 23(二进制10111)
23 & 0xFFFFFFF8 = 16→ 保持 16 不变。 -
例3:
bytes = 0,alignNum = 8
0 + 7 = 7(二进制111)
7 & 0xFFFFFFF8 = 0→ 对齐后仍为 0。
实现了这个函数之后,我们就能以这个函数为基础,设计出完整的对齐函数计算
- 1,128 8byte对齐 freelist[0,16)
- 128+1,1024 16byte对齐 freelist[16,72)
- 1024+1,8\*1024 128byte对齐 freelist[72,128)
- 8\*1024+1,64\*1024 1024byte对齐 freelist[128,184)
- 64\*1024+1,256\*1024 8*1024byte对齐 freelist[184,208)
cpp
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8*1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64*1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8*1024);
}
else//大于256kb的情况暂时不考虑
{
assert(false);
return -1;
}
}然后把这些函数都封装到SizeClass的类中,方便使用
cpp
class SizeClass
{
public:
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
......
}
static inline size_t RoundUp(size_t size)
{
......
}
};4. 下标映射算法
当我们得到了内存对齐的大小后,我们需要直到这个大小对应哪个哈希桶?因此我们需要设计出计算下标的函数
桶索引分布总览
| 分段范围 (bytes) | 对齐粒度 | 桶数 | 全局索引区间 |
|---|---|---|---|
| 1~128 | 8 | 16 | 0~15 |
| 129~1024 | 16 | 56 | 16~71 |
| 1025~8192 | 128 | 56 | 72~127 |
| 8193~65536 | 1024 | 56 | 128~183 |
| 65537~262144 | 8192 | 24 | 184~207 |
如果按对齐数分几个大类,那么对齐数8为一个大类,这个大类中一共有16个桶,以此类推
那么我们就能计算出每个大类的桶数
cpp
static int group_array[4] = { 16, 56, 56, 56 };之后为了方便理解计算的过程,我们举几个例子。
假设我的大小在0,128内,那我直接除8减1就可以
假设我的大小在(128,1024]内,那我知道他在对齐数为16的桶内,如果我计算出了他相当于第二个大类(对齐数为16)中的下标,再加上16即可。例如144在第二个大类中的下标为0,那么加上16,整体的下标就是16。
因此我们先设计这样一个函数:计算给定字节数 bytes 在固定对齐粒度(2^align_shift)下所属的桶索引(从 0 开始)。
cpp
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}计算过程:
-
(1 << align_shift)得到对齐粒度(例如align_shift=3时得到 8)。 -
(bytes + (1 << align_shift) - 1)实现向上取整,将bytes增加到下一个对齐粒度的整数倍(类似_RoundUp的效果)。 -
>> align_shift右移,相当于除以对齐粒度,得到向上取整后的"桶编号"(从 1 开始)。 -
- 1将编号转换为从 0 开始的桶索引。
示例:
-
若
align_shift=3(对齐 8 字节),bytes=13:
(13 + 7) >> 3 = 20 >> 3 = 2,减 1 得1。表示 13 字节应放在索引为 1 的桶中(该桶管理大小为 8~15 字节的对象,因为 8*1=8,8*2=16)。 -
若
bytes=8:
(8+7)>>3 = 15>>3 = 1,减 1 得0,即放入索引 0 的桶(管理 0~7 字节?但通常桶管理固定大小范围,索引 0 对应 8 字节块,具体要看设计)。
之后就能以此为基础得到这样一个函数:将不同范围的请求大小映射到全局连续的自由链表桶索引
cpp
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
// 每个区间有多少个链
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128){
return _Index(bytes, 3);
}
else if (bytes <= 1024){
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024){
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024){
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024){
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else{
assert(false);
}
return -1;
}再将这些函数封装到SizeClass类内
5. ThreadCache类初步实现
ThreadCache一共有三个函数:Allocate,Deallocate和FetchFromCentralCache
由于CentralCache我们还没有实现,因此先不做,等后面再实现
cpp
#include "ThreadCache.h"
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// ...
return nullptr;
}
void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
if (!_freeLists[index].Empty())//向哈希桶内拿
{
return _freeLists[index].Pop();
}
else
{
return FetchFromCentralCache(index, alignSize);//如果对应的哈希桶为空,则向CentralCache申请
}
}
void ThreadCache::Deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_BYTES);
// 找对映射的自由链表桶,对象插入进入
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
}