作者 :巴忠杰*†§、郑天航‡§、张新宇*、秦展*、李葆春‡、刘旭†、任奎*
*浙江大学网络空间安全学院
邮箱:xinyuzhang53@zju.edu.cn,qinzhan@zju.edu.cn,kuiren@zju.edu.cn
†麦吉尔大学计算机科学学院
邮箱:zhongjie.ba@mcgill.ca,xueliu@cs.mcgill.ca
‡多伦多大学电气与计算机工程系
邮箱:th.zheng@mail.utoronto.ca,bli@ece.toronto.edu
摘要
当前智能手机的运动传感器因对振动高度敏感,已被用于音频窃听。然而,这一威胁被认为风险较低,原因是存在两个被广泛认可的局限性:第一,与麦克风不同 ,运动传感器仅能捕捉通过固体介质传播的语音信号 。因此,此前报道的唯一可行方案是利用智能手机陀螺仪,对放置在同一桌面上的扬声器进行窃听。第二个局限性源于一种普遍认知,即受200Hz采样上限的限制,这些传感器仅能捕捉85-100Hz窄频带的语音信号 。本文重新审视了运动传感器对语音隐私构成的威胁,提出了一种名为AccelEve的新型边信道攻击方法 ,该方法利用智能手机的加速度计,对同一台手机的扬声器发出的声音进行窃听。具体而言,该方法通过对加速度计的测量数据进行分析,识别扬声器发出的语音并重建对应的音频信号。与以往研究不同,本研究的实验设置使语音信号能通过共享的主板,在加速度计测量数据中产生强烈响应,成功解决了第一个局限性,使此类攻击能够渗透到实际应用场景中。针对采样率的局限性,与普遍认知相反,我们发现新款智能手机的加速度计采样率最高可达500Hz,这一频率几乎覆盖了成年人语音的整个基频带(85-255Hz) 。基于这些关键发现,我们设计了一套新型的深度学习系统,该系统能够从加速度信号的频谱图表示中,学习识别并重建语音信息。该系统在带有残差连接的深度神经网络上采用自适应优化策略,结合鲁棒且具有泛化性的损失函数,实现了稳定的语音识别与重建性能。大量实验验证表明,该攻击方法在不同场景下均具有有效性和高准确率。
一、引言
智能手机已深度融入人们的日常生活,成为与外界沟通不可或缺的交互工具。在各类沟通方式中,语音通信始终是首选方式之一。正因如此,在大多数操作系统中,麦克风的使用权限默认被设置为最高级别 2。现有研究中,大量工作聚焦于如何利用通信协议的漏洞,或通过植入后门获取麦克风使用权限,从而窃听用户的电话通话内容。
本文研究的问题是,在无需获取敏感系统权限的情况下,通过边信道攻击对智能手机扬声器的语音进行窃听。该方法无需入侵操作系统或获取管理员权限,而是通过分析同一台智能手机上运动传感器 的测量数据,识别并重建扬声器发出的语音信号。此类攻击的可行性源于以下原因:第一,加速度计和陀螺仪被认为是低风险传感器 ,通常被设置为零权限传感器,应用程序可在不向用户发出任何提醒的情况下对其进行访问。第二,运动传感器能够对外部振动做出响应,这使其可以捕捉特定的音频信号。此外,人类语音的基频与智能手机传感器的采样频率存在重叠区域。因此,理论上零权限的运动传感器能够捕捉到语音信号。
在现有研究中,基于运动传感器的语音识别已吸引了众多学者的关注。Michalevsky等人32是该研究方向的开创者,他们利用智能手机的陀螺仪,捕捉由放置在同一桌面的独立扬声器产生的表面振动,随后通过分析捕捉到的振动信号,识别扬声器播放的语音信息。该方法存在可行性不足和识别准确率低 的问题,例如,在区分单个数字发音时,准确率仅为26%。另一类研究则聚焦于以空气为传播介质 ,而非固体表面。Zhang等人44将加速度计作为"麦克风",检测智能手机的语音输入。近期,Anand等人5(2018年安全与隐私研讨会)研究了通过固体表面(如桌面)或空气检测语音信号的问题。其实验结果表明,在所有测试的音频源和传播介质中,只有放置在桌面上的扬声器,能产生足够的能量并通过合适的声音传播路径,将振动传递至运动传感器。基于这一发现,文献5指出,所研究的此类威胁不会超出文献32中提出的扬声器实验设置范畴。
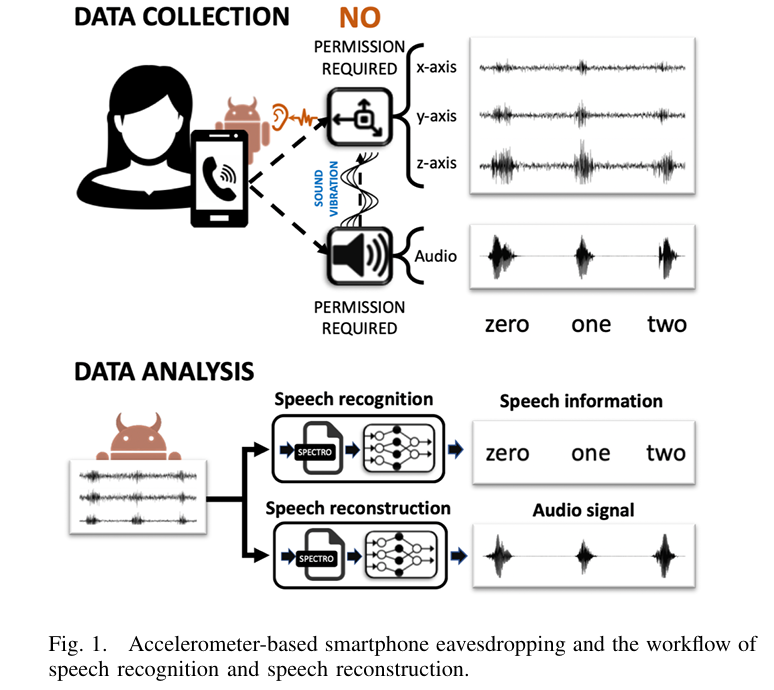
然而,上述所有研究均未涉及一种最具威胁性的场景,即利用运动传感器作为边信道,捕捉同一台智能手机扬声器发出的语音信号。在该场景下,运动传感器与扬声器物理接触于同一电路板,且二者距离极近。因此,与文献5的结论相反,无论智能手机被放置在何处、以何种方式放置(桌面或手持),扬声器发出的语音信号都会对陀螺仪和加速度计等运动传感器产生显著影响。
此外,以往所有相关研究都存在一个误导性的普遍认知 ,即安卓智能手机中加速度计和陀螺仪的采样率无法超过200Hz32,44,5。由于成年人语音的典型基频范围为85-255Hz38,7,此前公认的采样上限导致学界形成共识:运动传感器仅能捕捉85-100Hz范围内极窄的人类语音频段。但我们的研究表明,实际情况并非如此。根据安卓官方文档2,选择SENSOR_DELAY_FASTEST模式的安卓应用,将以尽可能快的速度接收传感器测量数据。因此,运动传感器的实际采样率由智能手机的性能决定,这一点已得到我们实验的验证。具体而言,对于2018年发布的部分智能手机,我们测得其采样频率最高可达500Hz,这意味着加速度计能够捕捉85-250Hz范围内的语音信息,几乎覆盖了成年人语音的整个基频带(85-255Hz)。
本文通过提出一种新型的实用实验设置,以及一套基于深度学习的语音识别与重建系统,解决了以往研究的局限性,其性能优于所有同类相关研究。在我们的实验设置中,攻击者为一款间谍应用,其目标是对同一台智能手机的扬声器进行窃听。当扬声器发出语音信号时(如通话过程中),该间谍应用在后台收集加速度计的测量数据,并利用这些数据识别和重建播放的语音信号。值得注意的是,由于访问加速度计无需任何权限,该间谍应用可伪装成任何类型的移动应用。
本系统的主要目标是从加速度计的测量数据中识别并重建语音信号。原始加速度信号通常会捕捉到多个"语音单词",且易受人体运动的严重干扰,因此,我们的系统首先实现了一个预处理模块,能够自动消除加速度信号中的显著干扰,并将长信号分割为单个单词的信号片段。随后,将每个单单词加速度信号转换为频谱图表示,并将其输入识别模块和重建模块进行进一步分析。
识别模块以密集卷积网络(DenseNet)24为基础网络,从加速度信号的频谱图中识别其所包含的语音信息(文本)。大量实验验证表明,我们的识别模块在不同场景下均取得了全新的最优性能。具体而言,当智能手机放置在桌面上时,该识别模块对10个数字的识别准确率达到78%,对20位说话人的识别准确率达到70%,而此前的最优结果为:数字识别准确率26%,仅对10位说话人的识别准确率50%。此外,在不同噪声环境下的实验验证,证明了我们识别模型的鲁棒性。除数字和字母外,我们还验证了所提出的识别和重建模型,能够识别电话通话中的敏感关键词。借助说话人识别模型,攻击者可将多次通话中识别出的敏感关键词与特定通话者关联,从而获取该通话者联系人的多项敏感信息。此外,我们还基于识别模型,在实际对话场景中实现了端到端的攻击。
在重建模块中,我们设计了一个重建网络,用于学习加速度计测量数据与智能手机扬声器播放的音频信号之间的映射关系。由于高频段的大部分语音信息是基频的谐波,该重建模块能够将加速度信号转换为采样率提升至1500Hz的音频(语音)信号。实验结果表明,该重建模块能够恢复几乎所有的元音信息,包括低频段的基频分量及其在高频段的谐波分量。清辅音信息未能被恢复,原因是这些分量在2000Hz以下的频带中无有效信息分布。
本文的主要贡献总结如下:
- 提出了AccelEve,一种基于加速度计的针对智能手机扬声器的边信道攻击方法。与以往认知相反,该方法的实验设置使此类攻击能够渗透到日常生活的常见场景中,如接听电话、接收语音消息等。通过全面的实验验证了该设置的可行性。
- 首次发现一个重要现象:新款智能手机的加速度计采样频率几乎覆盖了成年人语音的整个基频带。
- 设计了一套基于深度学习的系统,仅利用加速度计的测量数据即可实现语音信号的识别与重建。在现有数据集和自研数据集上的大量实验表明,该系统的性能显著且持续优于现有解决方案¹。据我们所知,该系统首次实现了基于加速度计的语音重建。
¹ 本文相关代码和收集的数据集可在以下网址获取:https://github.com/tianzheng4/learning speech from accelerometer。
二、研究背景与相关工作
本节首先介绍当前智能手机中运动传感器的设计原理,随后综述利用运动传感器捕捉语音信号的现有研究,以及与AccelEve相关的其他研究方向。
2.1 微机电系统运动传感器
现代智能手机通常配备三轴加速度计和三轴陀螺仪,这些传感器对设备的运动高度敏感,已被广泛应用于感知设备的方向、振动、冲击等状态。
- 加速度计:三轴加速度计是一种捕捉设备沿三个感应轴加速度的装置。每个感应轴通常由一个传感单元构成,该单元包含可移动的惯性质量块、若干固定电极和若干弹性支脚,如图2(a)所示。当加速度计沿某一感应轴受到加速度作用时,对应的惯性质量块会向相反方向偏移,导致电极之间的电容发生变化。该电容变化会产生模拟信号,随后被映射为加速度测量值。
- 陀螺仪 :智能手机中的陀螺仪通常利用科里奥利力1,测量绕三个轴的角速度。如图2(b)所示,每个轴的传感单元结构与加速度计相似,不同之处在于其质量块持续振动,且可沿两个轴移动。当陀螺仪受到外部角速度作用时,由于科里奥利效应,质量块会保持在原平面内振动,并产生一个垂直于旋转轴和质量块运动方向的科里奥利力。该力会使质量块发生位移,导致电极之间的电容变化,通过测量电容变化即可得到设备的角速度。
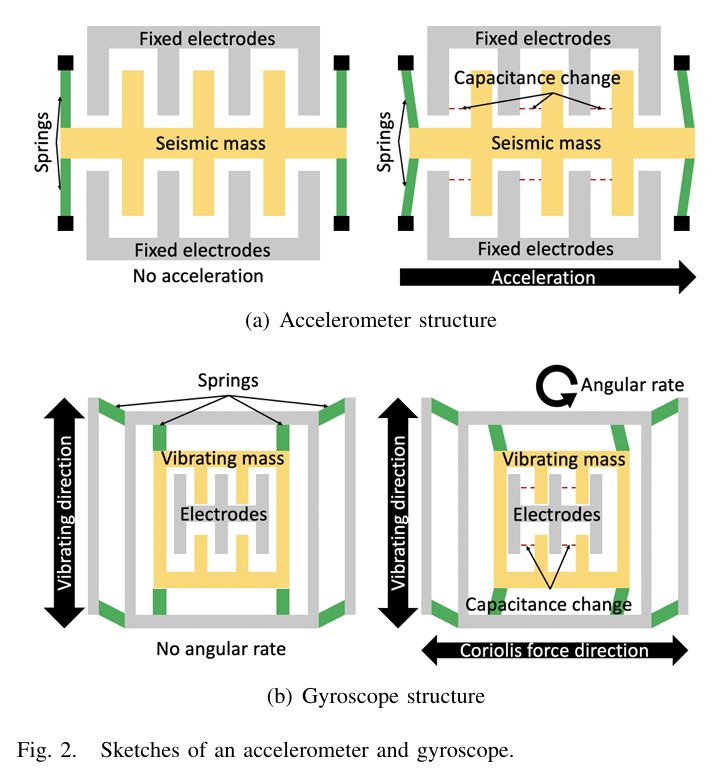
图2 加速度计和陀螺仪结构示意图
(a) 加速度计结构:无加速度/有加速度状态下的固定电极、惯性质量块与电容变化
(b) 陀螺仪结构:无角速度/有角速度状态下的弹性结构、振动质量块、科里奥利力方向与电容变化
在实际应用中,运动传感器捕捉的信息不仅取决于其对周围环境的灵敏度,还取决于采样频率。在安卓智能手机中,访问运动传感器时有四种延迟选项,如表1所示。每种选项指定了传感器测量数据发送至应用程序的时间间隔。具体而言,若应用程序选择SENSOR_DELAY_FASTEST模式,传感器测量数据将以最快速度发送至该应用,实际采样率主要由智能手机的性能决定。2014年,运动传感器的实际采样率达到200Hz32,根据奈奎斯特采样定理,该采样率使运动传感器能够准确捕捉100Hz以下的频率分量。
表1 安卓系统支持的采样频率2
| 延迟选项 | 延迟时间 | 采样率 |
|---|---|---|
| SENSOR_DELAY_NORMAL(标准延迟) | 200ms | 5Hz |
| SENSOR_DELAY_UI(界面延迟) | 20ms | 50Hz |
| SENSOR_DELAY_GAME(游戏延迟) | 60ms | 16.7Hz |
| SENSOR_DELAY_FASTEST(最快延迟) | 0ms | 尽可能快 |
2.2 基于运动传感器的语音识别
人类语音信号的基频承载着重要的语言和非语言信息,如自然度、情绪和说话人特征18。基频定义为声带的振动频率,其数值因年龄、性别、个体生理特征等因素存在较大差异13,19。通常,成年男性和成年女性的语音基频范围分别为85-180Hz和165-255Hz38,7。由于该基频范围与智能手机传感器的频率范围存在部分重叠,加速度计和陀螺仪已被用于捕捉低频段中一小部分的语音信号。
Michalevsky等人32(2014年USENIX安全研讨会)研究了将智能手机与扬声器放置在同一固体表面的场景,他们利用智能手机的陀螺仪"捕捉"扬声器发出的语音信号,并通过分析捕捉到的信息进行语音识别和说话人识别。在该场景中,陀螺仪捕捉的信号实际上是表面振动。由于陀螺仪对表面振动的灵敏度较低,且受采样率限制(200Hz),该方法难以在识别任务中取得较高的成功率。
Zhang等人44研究了用户手持或放置在桌面上的智能手机接收语音输入的场景,在该设置中,作者利用加速度计捕捉通过空气传播的语音信号,并将获取的加速度计读数用于关键词检测(如"Okay Google"和"Hi Galaxy")。然而,文献5的实验结果表明,通过空气传播的语音信号,难以对运动传感器产生明显影响。因此,加速度计无法通过空气振动收集到足够的语音信息。
为了更深入地理解运动传感器对语音隐私的威胁,Anand等人5(2018年安全与隐私研讨会)系统地研究了加速度计和陀螺仪在不同场景下对语音信号的响应。他们利用人类发声、笔记本电脑发声和扬声器发声的语音信号,分别通过空气和固体表面传播,对两种传感器进行刺激实验。其实验结果表明,只有扬声器发声并通过固体表面传播的语音信号,能对运动传感器产生明显影响。基于这一发现,Anand等人5指出,所研究的此类威胁不会超出Michalevsky等人32提出的"扬声器-同一表面"实验设置范畴。
然而,上述所有研究均未涉及一种最具威胁性的场景:运动传感器与目标扬声器位于同一台智能手机中。在该场景下,运动传感器与扬声器物理接触于同一电路板,且二者距离极近。因此,与文献5的结论相反,无论智能手机被放置在桌面(固体表面)、床上(软表面)还是手持状态,扬声器发出的语音信号都会对陀螺仪和加速度计产生显著影响。此外,与独立扬声器相比,智能手机扬声器更有可能泄露敏感信息。例如,当用户进行电话通话时,在后台运行的应用程序可访问零权限的运动传感器,并利用收集到的信号恢复敏感的语音信息。本文针对该场景展开研究,探索利用深度学习技术,实现基于加速度计的语音识别与重建。
在一项并行且独立的研究中,Anand等人(2019年arXiv)6也研究了加速度计与扬声器位于同一台智能手机时,基于加速度计的语音识别问题。Anand等人采用的是适用于小数据集的现有特征选择和分类工具,而我们实现的是基于深度学习的语音识别方法,取得了更高的准确率。此外,我们通过研究一系列综合影响因素,并采用有效的预处理方法解决这些问题,使所提出的模型具有更强的鲁棒性。同时,我们首次实现了基于加速度计的语音重建,并发现新款智能手机的加速度计几乎覆盖了成年人语音的整个基频带。
2.3 与AccelEve相关的其他研究方向
现有研究中,加速度计和陀螺仪已被广泛用于在各类应用场景中感知振动。Marquardt等人29利用智能手机中的加速度计,收集并解码附近键盘按键产生的振动信号,从而推断用户输入的文本。Owusu等人34、Miluzzo等人33、Xu等人42和Cai等人10的研究表明,智能手机的运动传感器可用于推断其触摸屏上的按键操作。Matovu等人31的研究表明,智能手机的加速度计测量数据可用于检测和分类其扬声器播放的歌曲。Son等人37探索了通过产生与无人机陀螺仪共振频率相同的噪声,使无人机失去工作能力的可能性。Feng等人17提出了一种基于加速度计的语音助手连续认证系统(如Siri和Google Now),该系统通过将语音输入与附着在用户皮肤上的无线加速度计数据进行交叉验证,使语音助手能够区分用户本人的指令和他人发出的语音信号。VibWrite28利用振动电机产生的振动信号,在通用表面上实现指纹输入,研究表明,固体表面的振动信号可用于提取反映用户手指按压位置和力度的独特特征。另一类研究聚焦于基于加速度计的轨迹恢复和人体行为识别,Han等人21的研究表明,若设备持有者在车辆中行驶,可通过设备上的加速度计确定其运动轨迹和位置。文献27,30,35探索了如何利用智能手机的加速度计和陀螺仪,检测和识别用户的行为(如行走、慢跑、骑自行车等)。
三、问题建模
本文研究的是一种新型的针对智能手机扬声器的边信道攻击问题:利用同一台设备上的加速度计,识别并重建智能手机扬声器播放的语音信号。由于安卓系统作为开源移动操作系统的普及性,我们的攻击主要针对安卓系统(不包括其变体)。需要说明的是,所提出的方法也可扩展至iOS系统,因为iOS系统中加速度计的最大采样率同样由硬件支持的最高频率决定。我们选择使用加速度计的原因是,其对振动的灵敏度高于陀螺仪,陀螺仪与加速度计的性能对比如图3所示。
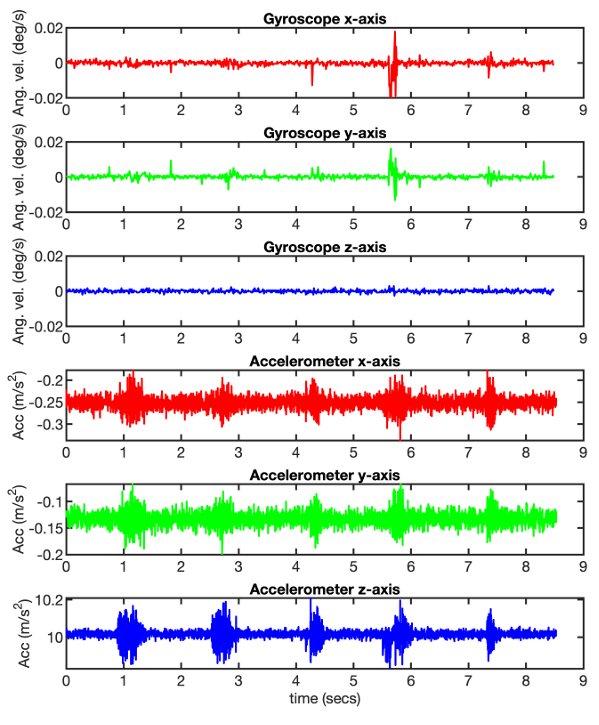
图3 智能手机陀螺仪和加速度计对同一音频信号的响应
陀螺仪同样能对同一设备扬声器发出的语音信号做出响应,但其对音频信号的响应强度远低于加速度计。
3.1 威胁模型
我们假设受害者使用一款高端智能手机,该手机播放包含隐私信息的语音信号。本文聚焦于由数字、字母和敏感关键词构成的隐私信息,如社保号码、密码、信用卡号码等。智能手机可能被放置在桌面上,也可能由用户手持。
攻击者为一款间谍应用,其目标是提取语音信号中包含的隐私信息。该间谍应用在后台持续收集加速度计的测量数据,并在智能手机扬声器播放音频信号时(如通话或接收语音消息时),尝试提取语音信息。可通过检测收集到的加速度计测量数据中的高频分量,判断扬声器是否处于播放状态。尽管加速度计也会受到日常活动的影响,但这些活动几乎不会对80Hz以上的频率分量产生影响(如第四节C部分所示)。
为了提取隐私信息,我们实现了基于加速度计的语音识别和语音重建。语音识别将加速度信号转换为文本,使攻击者能够从加速度计测量数据中,识别出预先训练的数字、字母和敏感关键词;语音重建从加速度信号中重建语音信号,使攻击者能够通过人耳对识别结果进行交叉验证。由于重建模型主要学习信号之间的映射关系,而非语义信息,与识别模型相比,其对未训练过的词汇具有更强的泛化能力。
由于访问加速度计无需任何权限,该间谍应用可伪装成在智能手机上运行的任何应用。为了不失一般性,本文通过一款在后台运行的第三方安卓应用AccDataRec,收集加速度计的读数(信号),该应用无需任何权限,即可记录三轴加速度计的读数及对应的时间戳。本文未考虑听筒和耳机的情况,因为其几乎不会对加速度计产生影响。
3.2 攻击场景
本文提出的边信道攻击,使攻击者能够通过分析智能手机的加速度计测量数据,识别其扬声器播放的预先训练的敏感关键词。该攻击不仅会对智能手机持有者造成影响,还会波及与其有通信联系的人。
对于智能手机持有者,设备上的间谍应用可能窃取以下信息:1)语音备忘录:当用户收听语音备忘录时,间谍应用可捕捉到预先训练的关键词。由于语音备忘录通常用于记录重要的隐私信息(如密码、电话号码、邮政编码等),部分关键词的泄露可能导致严重的隐私泄露;2)位置信息:由于当前大多数智能手机导航应用支持语音导航,间谍应用可通过分析智能手机扬声器播放的地理信息,追踪用户的位置;3)音乐和视频偏好:我们的攻击方法可扩展至检测智能手机播放的音乐或视频,进而分析并构建用户的视听习惯。
该间谍应用还可窃听与受害者进行电话通话或发送语音消息的远程通话者。例如,爱丽丝(受害者)与鲍勃进行电话通话,并向其索要信用卡号码及验证码,由于鲍勃的声音会通过爱丽丝的智能手机扬声器播放,爱丽丝手机上的间谍应用能够提取出通话中说出的数字和敏感关键词。在该攻击场景中,攻击者仅能窃听远程通话者的声音,因为智能手机持有者的声音不会由其自身设备的扬声器播放。尽管仅监听通话的一方,可能会遗漏单次通话中的重要上下文信息,但攻击者可通过分析加速度计测量数据识别远程通话者(如第六节B部分所示),从而将多次通话中提取的隐私信息与特定通话者关联。一旦攻击者收集到特定联系人的多项信息(如社保号码、信用卡号码、电话号码、密码等),该联系人的隐私将受到严重威胁。
四、可行性研究
如前所述,本文的核心思想是将智能手机的加速度计作为零权限"麦克风",对同一设备的扬声器进行窃听。本节从显著性、有效性和鲁棒性三个方面,通过实验验证该攻击的可行性(威胁程度)。
需要说明的是,第四节A部分和C部分中呈现的所有加速度信号,均采用第五节提出的插值方法进行预处理。我们利用该方法解决采样间隔不稳定的问题,以便进行频谱分析,处理后的加速度信号采样率固定为1000Hz。
4.1 显著性
该攻击的核心原理是:同一设备的加速度计与扬声器物理接触于同一电路板,且二者距离极近,因此语音信号总能在加速度计测量数据中产生显著响应。
为了验证这一假设,我们评估了智能手机加速度计在不同音量水平下,对其扬声器发出声音的响应。具体而言,我们生成一个200Hz的单音信号,在三星S8手机上以最大音量的20%、40%、60%、80%和100%进行播放。对于每种设置,将智能手机放置在桌面上,播放语音信号1秒,同时通过在后台运行的AccDataRec应用收集加速度计读数。
记录加速度信号后,对每个轴的信号进行连续小波变换,生成对应的尺度图,该图展示了频率分量的幅值随时间的变化情况,所得尺度图如图4所示。尺度图中亮度越高的区域,表示对应的频率分量越强。可以观察到,从20%音量开始,200Hz附近区域的亮度逐渐增加(尤其是z轴),表明加速度计成功捕捉到了扬声器发出的语音信号。
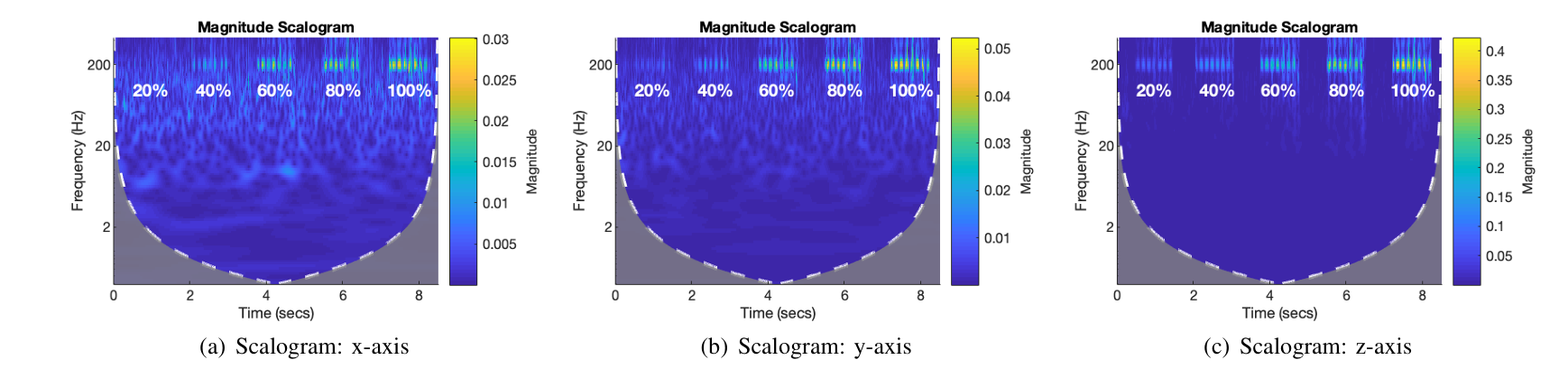
图4 智能手机加速度计对其扬声器以不同音量播放200Hz单音信号的响应
为了便于展示和对比,将不同音量下获取的加速度信号进行拼接,请注意不同尺度图的幅值范围存在差异。
(a) x轴尺度图 (b) y轴尺度图 © z轴尺度图
为了对不同设置下加速度计的音频响应进行定量比较,我们将加速度计的音频响应量化为:
ARdB=10log10(P(S)P(N))AR_{dB}=10\log_{10}\left(\frac{P(S)}{P(N)}\right)ARdB=10log10(P(N)P(S))
其中,PPP为幅值的平方和,SSS和NNN分别为扬声器播放和未播放语音信号时记录的加速度信号。该ARdBAR_{dB}ARdB与信噪比(SNR)的定义相似,不同之处在于此处的信号(SSS)是捕捉到的语音信号与噪声的混合信号。在理想情况下,若噪声信号随时间保持恒定,音频响应ARdBAR_{dB}ARdB大于0表明所研究的语音信号对加速度计产生了影响。然而,由于噪声的时变性,纯噪声信号(无任何音频信息)计算得到的ARdBAR_{dB}ARdB也可能在0附近小范围波动。通过对多款智能手机加速度计的纯噪声信号进行研究,我们发现将阈值设置为3,可有效判断加速度计是否受到语音信号的显著影响。
表2列出了每种特定设置下计算得到的音频响应,可以观察到,加速度计的音频响应随轴的不同存在显著差异,且随音量的增大而增强。x轴、y轴和z轴的传感单元,分别在音量达到60%、60%和20%以上时,能够捕捉到语音信号。一个重要的发现是,对于所研究的任意语音信号,被测加速度计的z轴响应始终最强,其次是y轴,最后是x轴。事实上,无论智能手机是放置在桌面上还是由用户手持,这一规律均保持不变。这一一致性可通过图2(a)所示的加速度计传感单元结构解释:对于每个传感单元,惯性质量块仅沿其感应轴振动,因此对来自其他方向的振动信号灵敏度较低。由于智能手机扬声器产生的振动,始终通过主板从同一方向传递至加速度计,因此加速度计的同一轴始终会产生最显著的音频响应。这一一致性具有重要意义,有助于确定从每个传感轴捕捉到的语音信息占比。本文将响应最强的轴称为智能手机的主导轴。
表2 图4中各设置下的音频响应
| 音量 | 20% | 40% | 60% | 80% | 100% |
|---|---|---|---|---|---|
| x轴音频响应(dB) | 1.0593 | 1.1715 | 4.2761 | 4.1370 | 5.2496 |
| y轴音频响应(dB) | 0.5710 | 2.0818 | 7.1051 | 8.8069 | 9.5171 |
| z轴音频响应(dB) | 14.8148 | 18.6134 | 23.0665 | 25.6657 | 27.1832 |
4.2 有效性
现有研究中存在一个普遍认知:安卓智能手机中加速度计和陀螺仪的采样率无法超过200Hz32,44,5。由于成年男性和成年女性的语音典型基频范围分别为85-180Hz和165-255Hz38,7,该普遍认知意味着,传感器仅能捕捉85-100Hz频率范围内极小部分的人类语音(根据奈奎斯特定理),因此该攻击的有效性受到限制。然而,如第二节A部分所述,根据安卓官方文档2,若安卓应用选择SENSOR_DELAY_FASTEST模式,传感器测量数据将以最快速度发送至该应用。在此背景下,我们假设新款智能手机的最快采样率可能超过200Hz。
为了验证上述假设,我们对8款不同年份发布的智能手机进行了测试,表3列出了其加速度计的实际采样率。实验结果证实,加速度计的实际采样率随智能手机型号的发展迅速提升。对于2017年后发布的高端智能手机,其加速度计的采样频率已超过400Hz,因此能够捕捉到相当范围的人类语音。具体而言,华为P20 Pro和华为Mate 20的加速度计采样率高达500Hz,使其能够捕捉到250Hz以下的频率分量。由于成年人语音的最高基频仅为255Hz,这两款智能手机几乎可以覆盖成年人语音的整个基频带。这一发现表明,运动传感器对语音隐私的威胁已成为一个严重问题,且随着智能手机型号的不断更新,该威胁将持续加剧。
表3 配置为SENSOR_DELAY_FASTEST模式时,不同智能手机的实际采样率
| 手机型号 | 发布年份 | 中央处理器(CPU) | 采样率 |
|---|---|---|---|
| 摩托罗拉G4 | 2016 | 4核1.5GHz + 4核1.2GHz | 100Hz |
| 三星J3 | 2016 | 4核1.3GHz | 100Hz |
| LG G5 | 2016 | 2核2.15GHz + 2核1.6GHz | 200Hz |
| 华为Mate 9 | 2016 | 4核2.4GHz + 4核1.8GHz | 250Hz |
| 三星S8 | 2017 | 4核2.35GHz + 4核1.9GHz | 420Hz |
| 谷歌Pixel 3 | 2018 | 4核2.5GHz + 4核1.6GHz | 410Hz |
| 华为P20 Pro | 2018 | 4核2.4GHz + 4核1.8GHz | 500Hz |
| 华为Mate 20 | 2018 | 2核2.6GHz + 2核1.92GHz + 4核1.8GHz | 500Hz |
4.3 鲁棒性
智能手机的加速度计对环境噪声高度敏感,在本文研究的攻击场景中,噪声可能来源于以下方面:硬件失真、声学噪声、人体活动、固有噪声和表面振动。我们对所有类型的噪声进行了研究,发现除智能手机扬声器播放的音频信号中包含的声学噪声外,其余大部分噪声要么难以对加速度计读数产生影响,要么可被有效消除。声学噪声对识别准确率的影响将在第六节C部分进行评估。
硬件失真 是由制造缺陷引起的系统性失真,机电结构的微小差异(如固定电极之间的间隙、弹性支脚的柔韧性)会导致测量值略有不同15。为了进行说明,我们将四款智能手机放置在同一桌面上,记录其沿六个方向(+x、-x、+y、-y、+z、-z)对重力的响应,如表4所示。不同方向测得的重力值存在细微差异,表明硬件失真的存在。对于特定的加速度计,其沿第iii轴的实际测量值可建模为16:
aiM=Si(ai)+Oia_{i}^{M}=S_{i}\left(a_{i}\right)+O_{i}aiM=Si(ai)+Oi
其中,aia_{i}ai为实际加速度,SiS_{i}Si和OiO_{i}Oi分别表示增益误差和偏移误差。因此,沿第iii轴的实际加速度信号可通过下式恢复:
ai=(aiM−Oi)/Sia_{i}=\left(a_{i}^{M}-O_{i}\right) / S_{i}ai=(aiM−Oi)/Si
其中,SiS_{i}Si和OiO_{i}Oi可通过分析加速度计对重力的响应计算得到12,9。
在本文提出的攻击中,攻击者甚至无需恢复实际的加速度信号,原因是加速度计捕捉的语音信息主要分布在85Hz以上的频率分量中,而偏移误差仅会影响直流(0Hz)分量;对于增益误差,其仅会影响捕捉到的语音信号的"响度",不会扭曲其频谱。因此,我们仅通过消除捕捉到的信号中的直流分量,即可解决硬件失真问题。
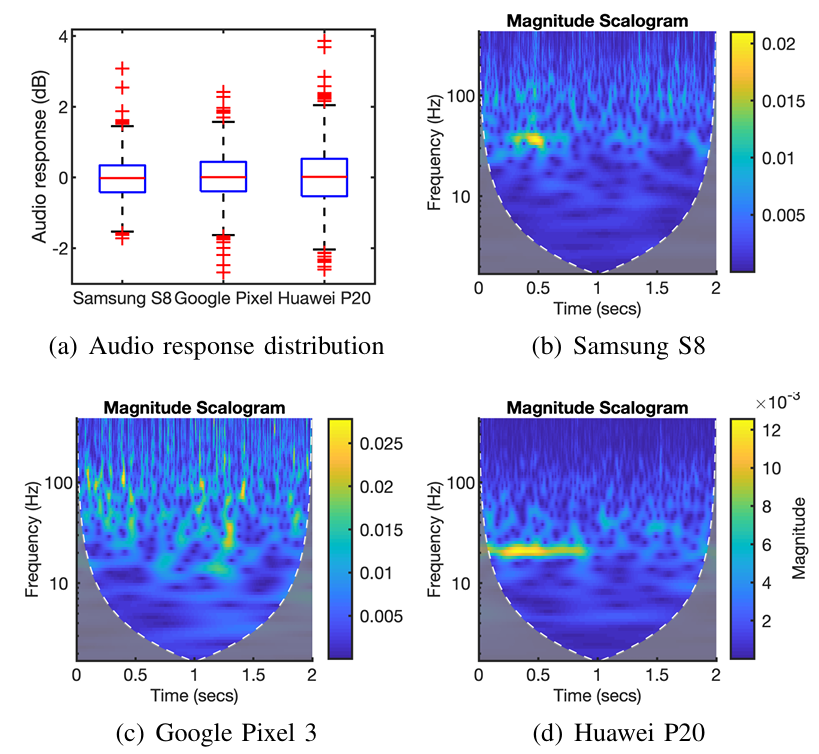
图5 共振频率检测
(a) 不同智能手机加速度计对空气传播语音信号的音频响应分布:空气传播信号为1000Hz至22000Hz、间隔50Hz的一系列单音信号;(b) 三星S8;© 谷歌Pixel 3;(d) 华为P20:分别展示对应智能手机加速度计产生最高音频响应时的尺度图。
声学噪声指周围环境中所有不必要的声音信号,可能来源于说话声、音乐、车辆、工业设备等。在本文提出的攻击中,声学噪声主要来源于受害者智能手机的周围环境,以及扬声器播放的音频信号中的噪声分量,即远程通话者周围的噪声。
对于受害者智能手机周围的声学噪声,声音通过空气传播至加速度计。现有研究中,Anand等人5的研究表明,即使在高声压级下,空气传播的语音信号也无法对加速度计测量数据产生明显影响。为了研究其他噪声信号的影响,我们将智能手机置于三种噪声环境中(酒吧、拥挤的公交车站、地铁站),各收集30秒的加速度计测量数据。在所有三种环境中,均未观察到对加速度计测量数据的显著影响,z轴的ARdBAR_{dB}ARdB值分别仅为0.1900、0.0724和-0.0431。
随后,我们评估了共振频率的影响。加速度计质量-弹簧系统的共振频率通常在几千赫兹26至几十万赫兹4之间。根据现有研究40,14,39,在高声压级下,接近微机电系统运动传感器共振频率的空气传播音频信号,会对其测量数据产生影响。为了探究共振频率对本系统的影响,我们测试了三星S8、谷歌Pixel 3和华为P20的加速度计,对1000Hz至22000Hz范围内空气传播音频信号的响应。对于每款被测智能手机,使用调至最大音量的华为Mate 20扬声器对其加速度计进行刺激,将扬声器与加速度计放置在两张不同的桌面上,间距10厘米,以消除表面振动的影响,并最大化施加在加速度计上的声压。音频信号为一系列时长2秒的单音信号,频率范围1000Hz至22000Hz,步长50Hz。我们计算了加速度计在每个频率下的音频响应,并绘制了所得ARdBAR_{dB}ARdB值的分布(图5(a))。结果表明,每款智能手机的ARdBAR_{dB}ARdB值均呈正态分布,无明显异常值,大多数记录的加速度信号ARdBAR_{dB}ARdB值低于3。三星S8、谷歌Pixel 3和华为P20分别在4150Hz(z轴)、9450Hz(z轴)和11450Hz(x轴)时达到最高ARdBAR_{dB}ARdB值。图5(b)、5©和5(d)展示了在这些频率下记录的加速度信号的尺度图。对于三星S8和谷歌Pixel 3,加速度计在任何特定频率下均无恒定响应,表明高ARdBAR_{dB}ARdB值是由环境振动的变化引起的;对于华为P20,其加速度计在20Hz时似乎有恒定但微弱的响应,我们使用相同的刺激信号重复实验10次,均未成功复现该响应,表明该ARdBAR_{dB}ARdB值同样由环境振动引起。基于这些实验结果可以得出结论:在常规频率(22000Hz以下)和声压级下,空气传播的声学噪声难以扭曲加速度计的测量数据,本文提出的攻击不会受到受害者智能手机周围声学噪声的影响。
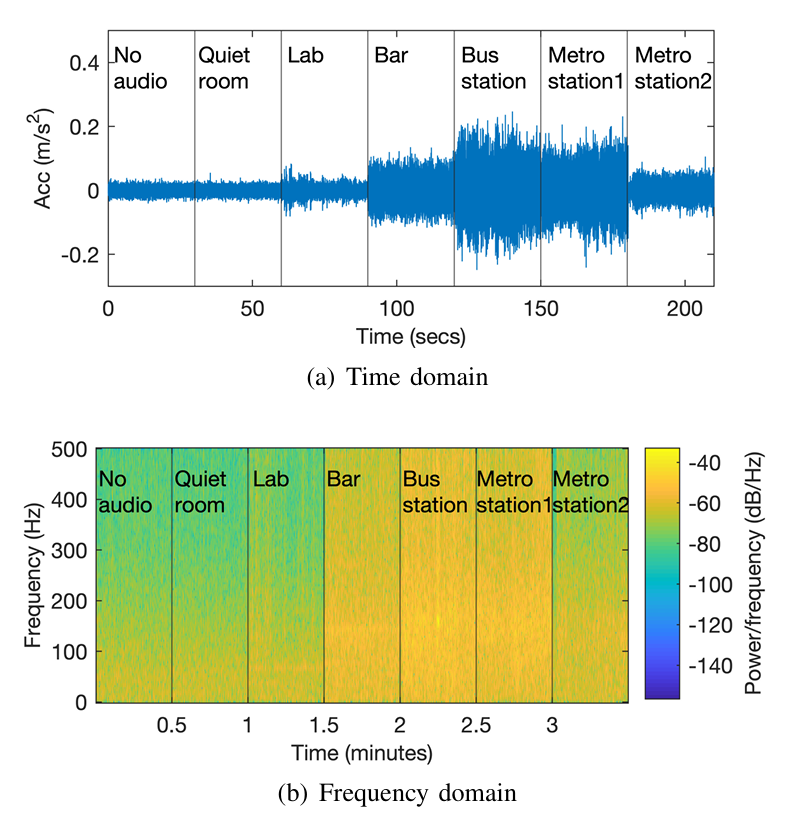
图6 远程通话者周围声学噪声的影响
我们消除了加速度信号的直流分量,并将其拼接以便于比较,第一段为加速度计的固有噪声。
(a) 时域图 (b) 频域图
对于远程通话者周围的声学噪声,由于该噪声信号会进入通话者的智能手机,并通过受害者的设备扬声器播放,因此受害者智能手机的加速度计可能会受到影响。为了研究此类噪声的影响,我们将受害者的智能手机调至最大音量,与在六种不同噪声水平的实际环境中的志愿者进行电话通话:1)安静的房间;2)有人交谈的实验室;3)播放音乐的酒吧;4)拥挤的公交车站;5)有列车运行的地铁站;6)无列车运行的地铁站。对于每种环境,收集30秒的加速度计测量数据,并计算z轴的平均ARdBAR_{dB}ARdB值,六种环境下的ARdBAR_{dB}ARdB值分别为-0.85、1.67、9.15、13.87、12.18和4.89。图6绘制了收集到的加速度计测量数据的时域和频域图,可以观察到,环境3、4、5中的噪声信号,对加速度计测量数据的所有频率分量均产生了显著影响;环境1、2、6中的噪声信号对加速度计测量数据的影响较小,且主要影响低频段,因此可通过高通滤波器进行显著抑制。由于远程通话者周围的声学噪声会对加速度计测量数据产生显著影响,我们将在第六节C部分评估其对语音识别的影响。
人体活动 会对智能手机加速度计的测量数据产生显著影响,因此可能会扭曲攻击者推断的语音信息。为了评估人体活动的影响,我们研究了加速度计对五种人体活动的响应:行走、上下楼梯、站起与坐下、挥手和打字。在每次测试中,用户手持运行着AccDataRec应用的三星S8手机,进行约10秒的对应活动。由于加速度计沿三个轴的响应极为相似,我们将获取的加速度信号进行拼接,并展示y轴的尺度图(图7)。可以观察到,每种被测活动都会在加速度信号中产生相对独特且恒定的模式,但所有这些活动均未对80Hz以上的频率分量产生显著影响。由于成年人语音的典型基频范围为85-255Hz,使用截止频率为80Hz的高通滤波器,可消除人体活动引起的大部分失真(如图7所示)。剩余的失真主要表现为高频域中的短时脉冲,根据我们的观察,其对语音识别/重建几乎没有影响,但会影响第五节A部分介绍的信号分割方式。
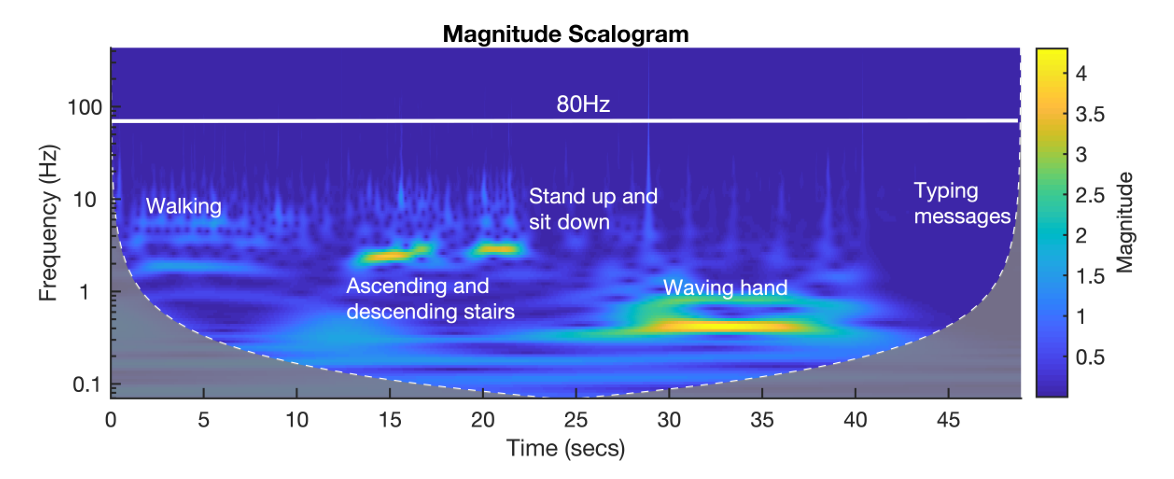
图7 智能手机加速度计对五种人体活动的响应
为了便于比较,将获取的加速度信号进行拼接。
固有噪声和表面振动 :固有噪声指智能手机加速度计在无外部刺激时输出的噪声信号,是加速度计本身的固有特性,也是本系统的主要噪声分量。由于几乎不可能使加速度计处于完全无外部刺激的状态,我们研究了固有噪声与表面振动的综合影响。当智能手机放置在桌面上时,表面振动会沿z轴影响加速度计的测量数据。为了测量这两种噪声源的影响,我们将三星S8手机放置在一张桌面上,记录330秒的加速度计测量数据。该桌面为固体表面,能将振动有效传递至智能手机,且放置在一栋正在施工的建筑内。加速度计的输出信号如图8(a)所示,可以观察到,加速度计沿x轴和y轴输出恒定的噪声信号,其中固有噪声占主导;沿z轴,加速度计除输出恒定的噪声信号外,还受到表面振动的影响。三个轴的加速度信号频率分布相似,为了进行说明,图8(b)绘制了z轴信号的频谱图(已去除直流偏移)。在该频谱图中,约57%的能量分布在80Hz以下。由于成年人语音的典型基频范围为85-255Hz,我们通过消除80Hz以下的频率分量,解决固有噪声和表面振动的问题。剩余噪声信号的影响将在第六节进行评估。
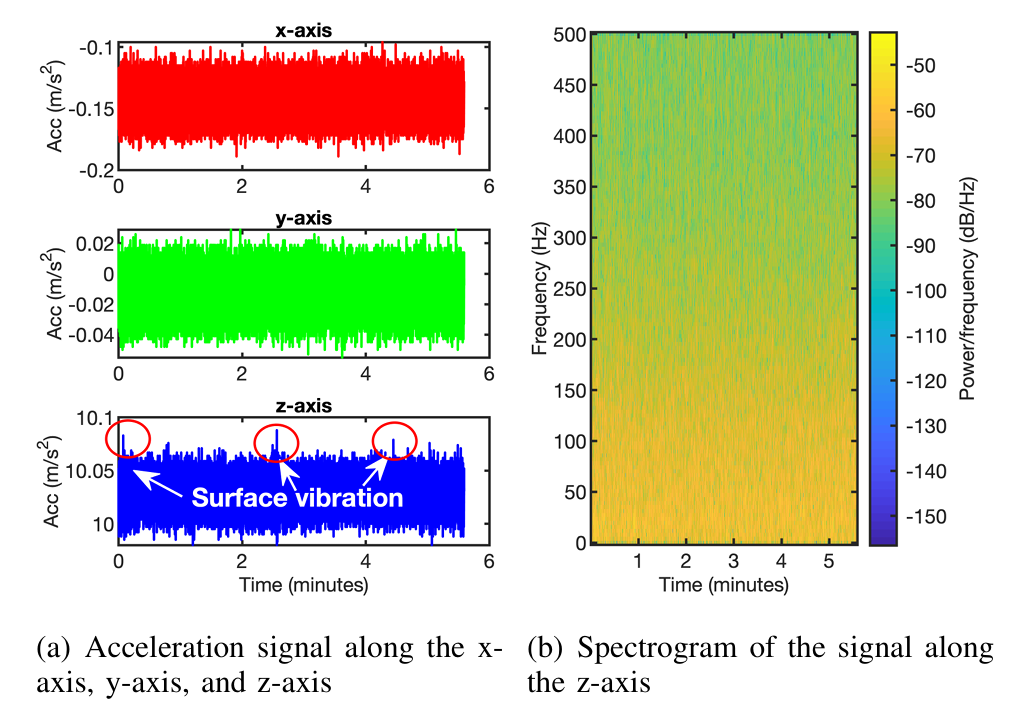
图8 固有噪声和表面振动的影响
加速度计放置在桌面上,仅受到表面振动的影响。
(a) x轴、y轴和z轴的加速度信号 (b) z轴信号的频谱图
五、所提出的系统
本节将详细介绍本文提出的系统,该系统主要包括三个模块:预处理模块、识别模块和重建模块。
5.1 预处理
本系统的主要目标是识别并重建智能手机加速度计捕捉到的语音信息。与分析原始波形数据相比,分析语音信号的频谱图表示是一种更普遍且更有效的语音识别方法23,8,该表示方式能够展示信号的频率分量及其强度随时间的变化情况。在传统的基于音频信号的语音识别任务中,通常会在梅尔标度上对频谱图进行进一步处理,计算梅尔频率倒谱系数(MFCC),原因是梅尔标度模拟了人耳的非线性感知特性,有利于丢弃冗余和无关的信息。然而,在本系统中,梅尔标度表示的作用微乎其微,因为现代智能手机的加速度计仅能捕捉低频段的语音信号。因此,在本文提出的系统中,我们将加速度信号预处理为频谱图,用于语音识别和重建。频谱图表示能够清晰反映信号在频域中的多尺度信息,使我们能够采用计算机视觉任务中广泛使用的一些网络结构,如残差网络(ResNet)和密集卷积网络(DenseNet)。
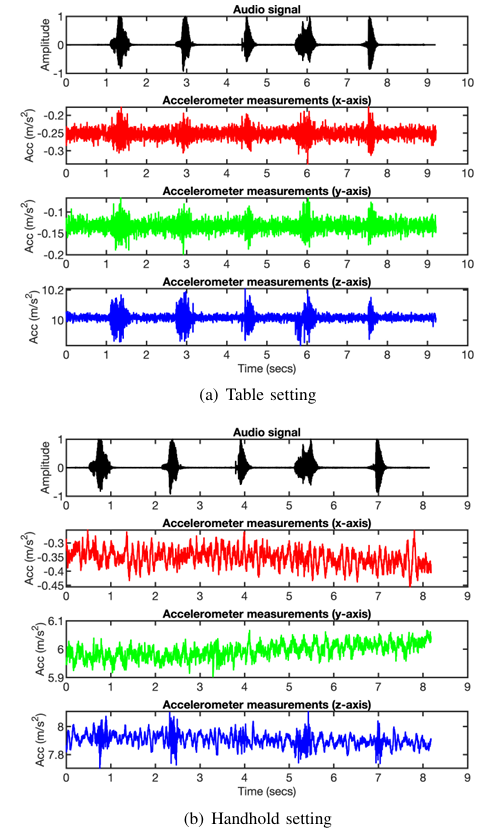
图9 智能手机加速度计捕捉的原始加速度信号
(a) 桌面放置场景 (b) 手持场景
为了不失一般性,我们以三星S8手机为例,说明如何从原始加速度测量数据生成频谱图。图9(a)和图9(b)展示了在两种不同场景下收集的原始加速度信号:在桌面放置场景中,将智能手机放置在桌面上,通过其扬声器播放包含五个独立数字(0-4)的语音信号,该场景下收集的加速度信号沿所有轴均表现出强烈的音频响应;在手持场景中,用户手持智能手机播放相同的语音信号,由于手部的无意移动,加速度信号受到严重扭曲。
原始加速度信号存在三个主要问题:1)由于系统被配置为以最快速度将加速度计测量数据发送至应用程序,原始加速度计测量数据的采样间隔不固定(图10);2)原始加速度计测量数据易受人体运动的严重扭曲;3)原始加速度计测量数据捕捉到多个数字的语音,需要进行分割。为了解决这些问题,我们通过以下步骤将原始加速度信号转换为频谱图。
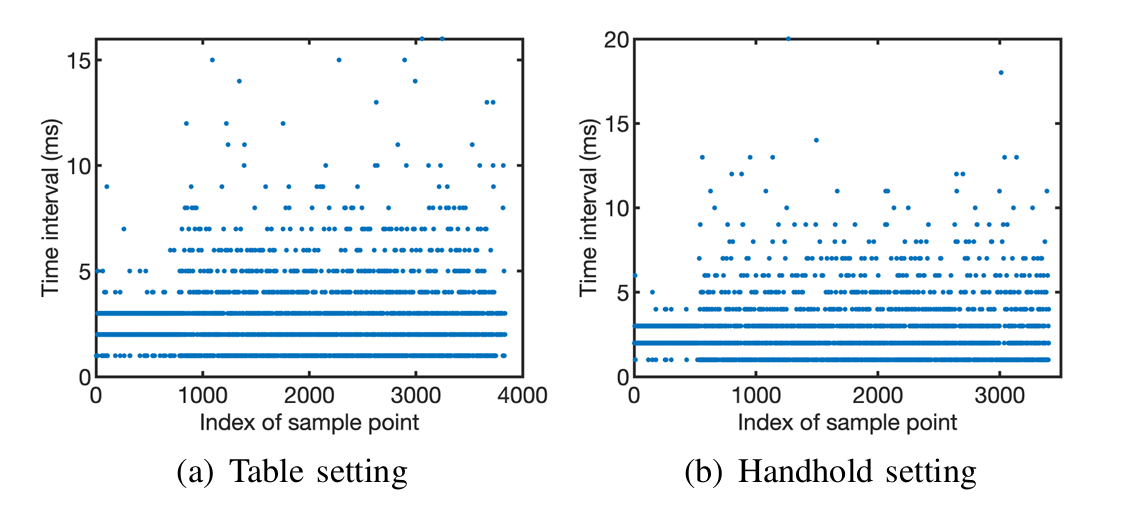
图10 相邻加速度计读数的时间间隔
由于系统被配置为以最快速度将测量数据发送至应用程序,原始加速度计读数的采样间隔不稳定。
(a) 桌面放置场景 (b) 手持场景
-
插值:首先,我们使用线性插值处理加速度计测量数据的间隔不稳定问题。由于传感器测量数据的时间戳精度为毫秒级,解决间隔不稳定问题的一种自然方法是将加速度计测量数据上采样至1000Hz。因此,我们利用时间戳定位所有无加速度计测量数据的时间点,并通过线性插值填补缺失数据,处理后的信号采样率固定为1000Hz。需要说明的是,该插值(上采样)过程不会增加加速度信号的语音信息,其主要目的是生成采样率固定的加速度信号。
-
高通滤波 :随后,我们使用高通滤波器消除重力、硬件失真(偏移误差)和人体活动引起的显著失真。具体而言,首先通过短时傅里叶变换(STFT)将沿每个轴的加速度信号转换至频域,该变换将长信号分割为等长的片段(存在重叠),并对每个片段分别进行傅里叶变换;然后,将所有截止频率以下的频率分量系数设置为零;最后,通过逆短时傅里叶变换将信号转换回时域。由于成年男性和女性的语音基频通常高于85Hz,且人体活动几乎不会对80Hz以上的频率分量产生影响(如图7所示),为了最大限度地降低噪声分量的影响,将语音识别的截止频率设置为80Hz。对于语音重建,由于重建网络主要学习加速度信号与音频信号之间的映射关系,为了保留更多的语音信息,将截止频率设置为20Hz。图11(a)和11(b)展示了截止频率为20Hz的滤波后加速度信号,在桌面放置场景中,所有加速度信号的均值均移至零,表明偏移误差和重力(z轴)被成功消除;在手持场景中,高通滤波器也消除了手部移动的影响,该步骤处理后的滤波信号主要由目标语音信息和加速度计的固有噪声构成。
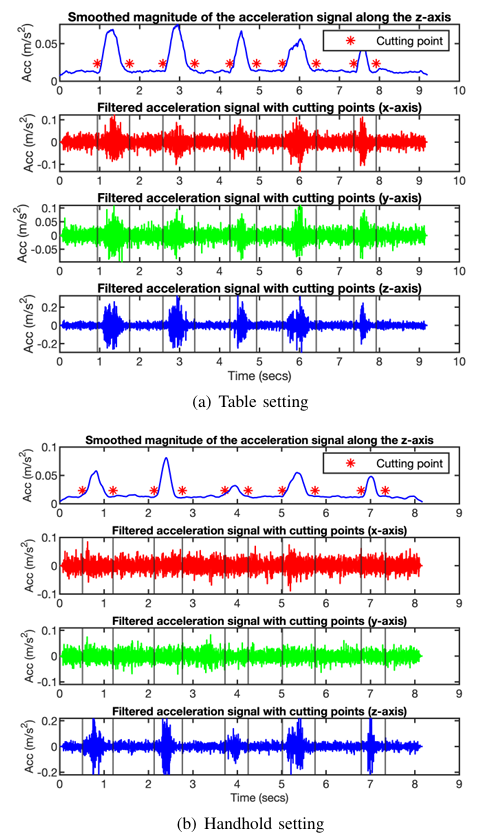
图11 经插值、高通滤波和分割处理后的加速度信号
高通滤波的截止频率为20Hz,幅值序列由滤波后的信号直接计算得到,因未涉及剧烈的人体运动。
(a) 桌面放置场景 (b) 手持场景
-
分割 :由于沿三个轴的加速度信号完全同步,我们利用第四节中描述的主导轴(z轴)定位分割点,然后利用所得分割点,对沿三个轴的滤波后加速度信号进行分割。分割点的定位方法如下:首先,对沿主导轴的加速度信号,使用截止频率为160Hz的高通滤波器再次进行净化处理。通过对噪声实验设置中收集的信号进行研究,我们发现该截止频率能够消除大量噪声分量,包括人体运动引起的短时脉冲,该步骤通常仅在智能手机受到外部振动或剧烈移动时需要;然后,计算净化后信号的幅值(绝对值),并通过两轮移动平均对所得幅值序列进行平滑处理,第一轮和第二轮的滑动窗口大小分别为200和30,两种场景下的平滑后幅值序列如图11所示;接下来,找到平滑后幅值序列的最大值MmaxM_{max}Mmax和最小值MminM_{min}Mmin,该过程中丢弃前100个和后100个幅值值,因这些值没有足够的相邻样本用于平均,所得最小值近似为噪声信号的幅值;随后,遍历平滑后幅值序列,定位所有幅值高于阈值0.8Mmin+0.2Mmax0.8 M_{min}+0.2 M_{max}0.8Mmin+0.2Mmax的区域,每个定位到的区域表示存在一个语音信号;为了确保分割后的信号能够覆盖整个语音信号,将每个定位到区域的起始点和结束点分别向前和向后移动100个和200个样本,每种场景下计算得到的分割点均标记在图11中;最后,利用所得分割点,将滤波后加速度信号分割为多个短信号,每个短信号对应一个单单词。
-
信号转频谱图 :为了生成单单词信号的频谱图,首先将信号分割为多个存在固定重叠的短片段,片段长度和重叠长度分别设置为128和120;然后,对每个片段施加汉明窗,并通过短时傅里叶变换计算其频谱,为每个片段生成一系列复系数;此时,沿每个轴的信号被转换为一个短时傅里叶变换矩阵,记录每个时间和频率对应的幅值和相位;最后,通过下式计算二维频谱图:
spectrogram{x(n)}(m,w)=∣STFT{x(n)}(m,w)∣2(1)spectrogram\{x(n)\}(m,w)=|STFT\{x(n)\}(m,w)|^{2} \tag{1}spectrogram{x(n)}(m,w)=∣STFT{x(n)}(m,w)∣2(1)其中,x(n)x(n)x(n)和∣STFT{x(n)}(m,w)∣|STFT\{x(n)\}(m,w)|∣STFT{x(n)}(m,w)∣分别表示单轴加速度信号及其对应的短时傅里叶变换矩阵的幅值。由于我们拥有沿三个轴的加速度信号,因此每个单单词信号可得到三个频谱图。为了进行说明,图12绘制了两种场景下第一个单单词信号(z轴)的频谱图,由于高通滤波处理,20Hz以下的频率分量接近零。
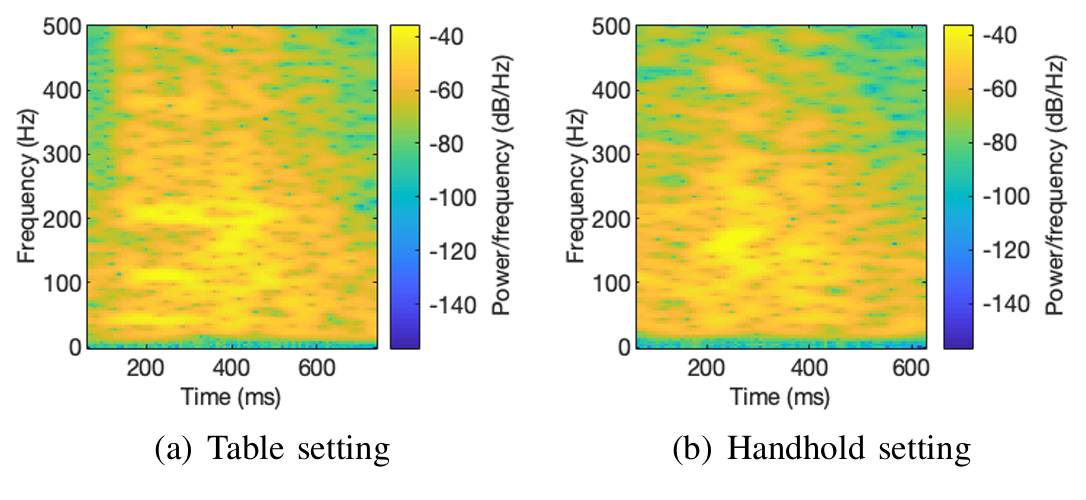
图12 第一个单单词信号(z轴)的频谱图
(a) 桌面放置场景 (b) 手持场景
- 频谱图转图像 :为了将频谱图直接输入计算机视觉任务中使用的神经网络,我们进一步将一个信号的三个二维频谱图,转换为一张PNG格式的RGB图像。具体步骤为:首先,将三个m×nm×nm×n的频谱图拟合为一个m×n×3m×n×3m×n×3的张量;然后,对张量中的所有元素取平方根,并将所得值映射为0到255之间的整数,取平方根的原因是原始二维频谱图中的大多数元素值非常接近零,直接将其映射为0到255之间的整数会导致大量信息丢失;最后,将m×n×3m×n×3m×n×3的张量导出为PNG格式的图像。在所得的频谱图图像中,红、绿、蓝三个通道分别对应加速度信号的x轴、y轴和z轴。对于识别任务,为了降低固有噪声的影响,将频谱图图像裁剪至80Hz至300Hz的频率范围。图13绘制了两种场景下第一个单单词信号的频谱图图像,图像中亮度越高的区域,表示该时间段内加速度信号在对应频率范围内的能量越强,可以观察到,在两种场景下,蓝色通道(沿z轴的加速度信号)均提供了最多的语音信息。

图13 第一个单单词信号的频谱图图像
这些图像覆盖的频率范围为80Hz至300Hz。
(a) 桌面放置场景 (b) 手持场景
5.2 识别
通过上述预处理操作,所得的加速度频谱图图像经缩放后,可输入至各种标准化的神经网络,如视觉几何组网络(VGG)36、残差网络(ResNet)22、宽残差网络(Wide-ResNet)43和密集卷积网络(DenseNet)24。本节将详细介绍识别模块的设计。
-
频谱图图像缩放 :为了将频谱图图像输入标准化的计算机视觉网络,最好将其缩放为n×n×3n×n×3n×n×3的图像。需要注意的是,加速度频谱图的细粒度信息和相关性,可能对识别结果产生影响,尤其是说话人识别的结果。为了保留足够的信息,将频谱图图像缩放为224×224×3224×224×3224×224×3。
-
网络选择 :总体而言,我们选择密集卷积网络(DenseNet)作为所有识别任务的基础网络。与视觉几何组网络(VGG)和残差网络(ResNet)等传统深度网络相比,密集卷积网络在每一层与其所有前层之间建立连接,即在一个L层网络中,共有(L+1)L2\frac{(L+1)L}{2}2(L+1)L个连接。例如,如图14(a)所示的密集卷积网络常见模块示意图中,第一层至第四层均与第五层有直接连接,换言之,第lll层将第0层(输入图像)至第l−1l-1l−1层的特征图拼接作为输入,其数学表达式为:
xl=Hl(x0,x1,...,xl−1)(2)x_{l}=\mathcal{H}_{l}(x_{0},x_{1},...,x_{l-1}) \tag{2}xl=Hl(x0,x1,...,xl−1)(2)其中,Hl\mathcal{H}{l}Hl和xix{i}xi分别表示第lll层的函数和特征图,x0,x1,...,xl−1x_{0},x_{1},...,x_{l-1}x0,x1,...,xl−1表示第0层至第l−1l-1l−1层特征图的拼接。这些直接连接使所有层都能接收并重用其前层的特征,因此密集卷积网络无需使用一些冗余的参数或节点,即可保留前层的信息。因此,密集卷积网络能够使用更少的节点(参数),实现与视觉几何组网络和残差网络相当的性能。此外,网络中信息和梯度的流动得到改善,也缓解了梯度消失问题,使密集卷积网络更易于训练。通过实验发现,在我们的识别任务中,密集卷积网络确实以更少的参数和计算成本,取得了最佳的准确率(与视觉几何组网络和残差网络相比)。图14(b)展示了我们使用的整体网络结构,该结构由多个图14(a)所示的密集模块构成。
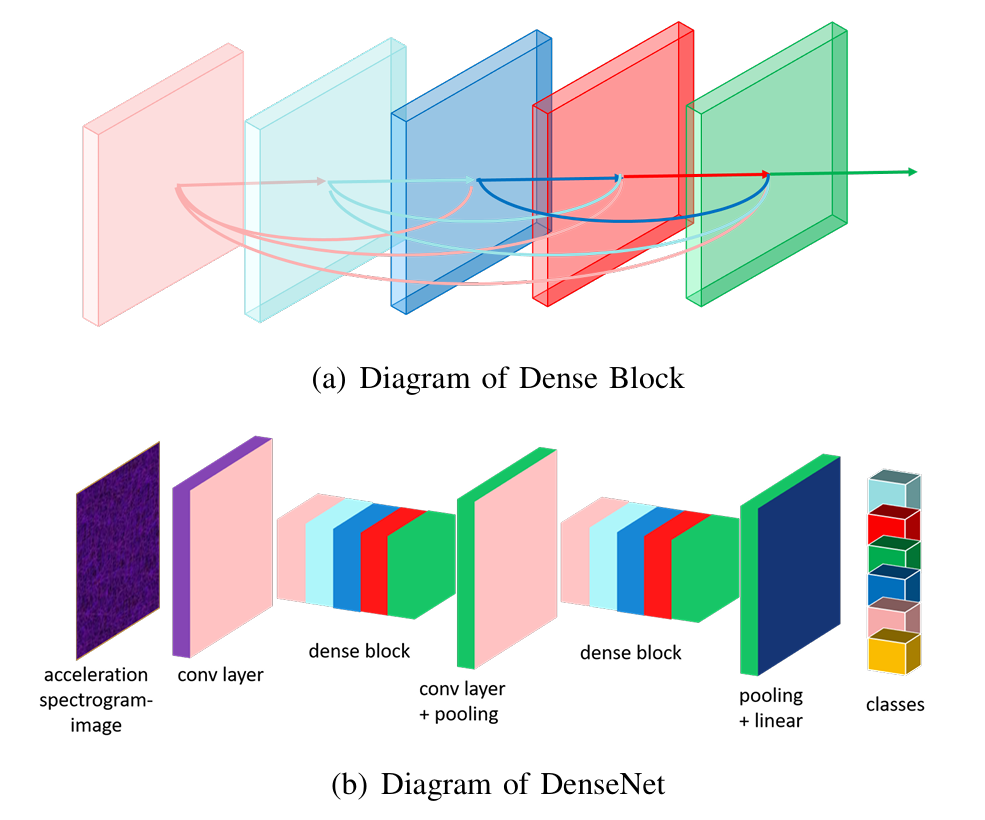
图14 密集卷积网络的网络结构
层与层之间建立直接连接,以改善信息流动。
(a) 密集模块示意图 (b) 密集卷积网络示意图
- 训练过程:在训练阶段,使用交叉熵作为训练损失函数,并通过分段动量优化器优化模型权重,以学习更具泛化性的特征,同时促进模型收敛。具体而言,首先通过大的步长(如0.1)执行自适应动量优化过程,学习泛化性特征,然后通过更小的步长进行微调,促进模型收敛。我们还在训练损失中加入权重衰减,并将丢弃率设置为0.3,以增强模型的泛化性。
5.3 重建
除识别外,本系统还希望实现从对应的加速度信号(频谱图)中重建语音信号的功能,因为该功能可用于对识别结果进行交叉验证。需要说明的是,尽管当前智能手机的加速度计仅能捕捉低频分量,但高频段的许多分量主要是基频的谐波,这使得从对应的加速度信号中,重建采样率提升的语音信号成为可能。为了实现语音信号重建,首先以加速度频谱图图像为输入,通过以下重建网络重建语音频谱图,然后通过文献20中提出的格里芬-林算法(Griffin-Lim),从重建的语音频谱图中估计语音信号。接下来,将详细介绍重建网络和语音信号估计方法。
5.3.1 重建网络
重建网络由三个子网络构成:编码器、残差模块和解码器。重建网络的输入是一张128×128×3128×128×3128×128×3的频谱图图像,覆盖的频率分量为20Hz至500Hz,每个通道对应加速度信号的一个轴。然而,此处标准化输入尺寸存在一个问题:由于不同说话人的语音信号时长不同,加速度信号的时长也可能不同,但重建过程中最好保持时间尺度信息,因此不希望对频谱图图像进行缩放。一种简单的解决方案是将语音信号重复,直至达到预先定义的时长,该方案是有效的,因为与上述识别模块不同,重建任务对语音/加速度信号(频谱图)的内容没有限制,识别模块的输入必须是单单词频谱图图像。重建网络的输出是一张384×128384×128384×128的灰度图像,代表对应的语音频谱图,因为语音信号仅有一个轴。由于加速度计的采样率有限,我们的重建网络仅旨在重建0Hz至1500Hz频率范围内的语音信号分量。
-
编码器 :第一个子网络是编码器,用于对加速度频谱图图像进行编码(即图15(b)中的卷积层)。编码器以一个包含32个9×9×39×9×39×9×3卷积核的卷积层开始,学习大尺度特征,随后是两个卷积层,分别包含64个3×3×323×3×323×3×32卷积核和128个3×3×643×3×643×3×64卷积核,学习小尺度特征。此外,在前两层中采用步长为2的卷积进行下采样。
-
残差模块 :受文献25架构的启发,我们在编码器后加入五个残差模块(如图15(a)所示),明确让特征拟合残差映射H(⋅)\mathcal{H}(·)H(⋅),即:
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: ..._{i})+x \tag{3}其中,F(x,Wi){\mathcal{F}}(x,W_{i})F(x,Wi)是由卷积层学习到的非线性映射。考虑到加速度信号频谱图与语音信号频谱图之间的结构相似性,恒等映射很可能是建立某些特征关联的最优/近优映射。当最优映射是或接近恒等函数时,优化H\mathcal{H}H比优化无参考的模块F\mathcal{F}F更容易,因为将F\mathcal{F}F的参数推向零,比将F\mathcal{F}F优化为恒等映射更容易。因此,我们在重建网络的中间部分加入了多个残差模块H\mathcal{H}H(即图15(b)中的残差模块)。
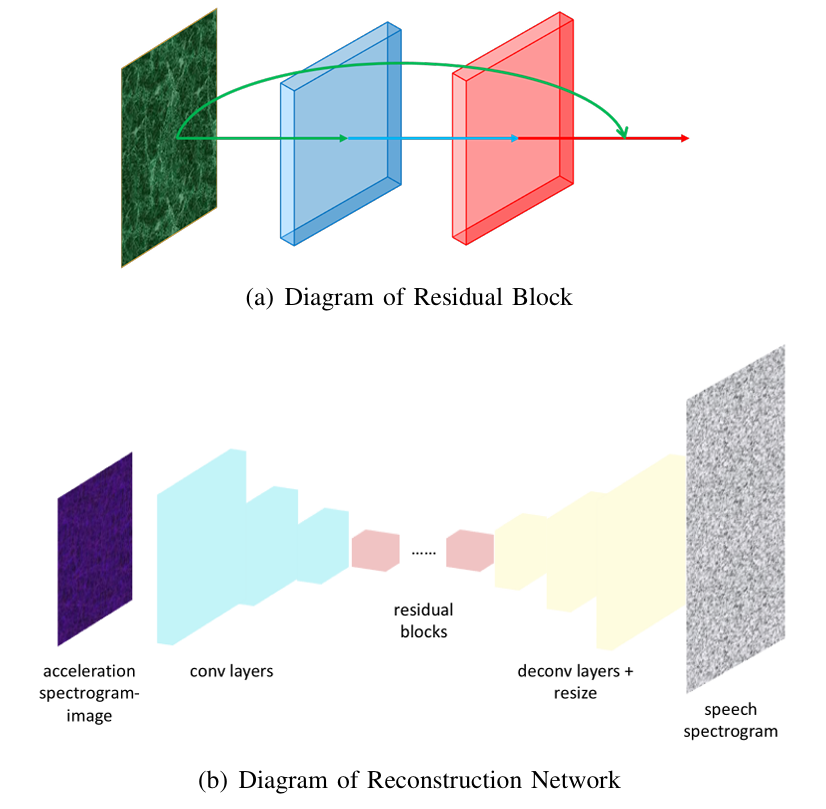
图15 重建网络的网络结构
通过残差模块,更容易优化公式(3)中的残差映射。
(a) 残差模块示意图 (b) 重建网络示意图
-
解码器 :最后,通过解码器(即图15(b)中的反卷积层),从编码器和残差模块学习到的特征中解码出语音频谱图。解码器同样包含3个反卷积层,分别包含64个3×3×1283×3×1283×3×128卷积核、32个3×3×643×3×643×3×64卷积核和3个9×9×329×9×329×9×32卷积核。在前两层中采用步长为1/21/21/2的反卷积进行上采样。解码器的初始输出是一个128×128×3128×128×3128×128×3的矩阵,随后该矩阵被进一步缩放为384×128384×128384×128的灰度图像,作为对应的语音频谱图。
-
训练过程 :与识别任务相比,重建任务的训练过程更不稳定,且计算成本更高。不稳定性问题可能源于训练小批量数据中的稀疏异常值,这是由频谱图的稀疏性导致的。为了解决该问题,我们使用重建图像与目标图像之间的L1L_1L1距离作为训练损失函数,而非文献41中使用的均方误差(MSE)损失函数,原因是L1L_1L1损失函数对异常值的鲁棒性更强11。此外,我们还在L1L_1L1损失函数中加入权重衰减,以增强模型的泛化性。为了降低计算成本,我们通过基于时间的学习率衰减来加速优化过程,具体而言,使用带有学习率调度器的动量优化器,每个训练周期的学习率衰减系数为0.9。
5.3.2 语音信号估计
格里芬-林算法是一种从频谱图中估计信号的迭代算法,每次迭代包含两个步骤:第一步是通过频谱图修改当前信号估计的短时傅里叶变换;第二步是通过修改后的短时傅里叶变换更新当前信号估计。接下来,将详细介绍这两个步骤。
-
修改短时傅里叶变换 :给定第iii次迭代中语音信号的当前估计值xinx^{i}nxin,以及重建的幅值(频谱图的平方根)∥Y(m,w)∥\|Y(m,w)\|∥Y(m,w)∥,xinx^{i}nxin的短时傅里叶变换Xi(m,w)X^{i}(m,w)Xi(m,w)被修改为:
X^i+1(m,w)=Xi(m,w)⋅∥Y(m,w)∥∥Xi(m,w)∥(4)\hat{X}^{i+1}(m,w)=X^{i}(m,w) \cdot \frac{\|Y(m,w)\|}{\|X^{i}(m,w)\|} \tag{4}X^i+1(m,w)=Xi(m,w)⋅∥Xi(m,w)∥∥Y(m,w)∥(4)以确保修改后的短时傅里叶变换X^i+1(m,w)\hat{X}^{i+1}(m,w)X^i+1(m,w)的幅值,与重建的幅值∥Y(m,w)∥\|Y(m,w)\|∥Y(m,w)∥相同。
-
更新信号估计 :需要注意的是,若不存在短时傅里叶变换为X^i+1(m,w)\hat{X}^{i+1}(m,w)X^i+1(m,w)的信号,则修改后的短时傅里叶变换X^i+1(m,w)\hat{X}^{i+1}(m,w)X^i+1(m,w)可能不是有效的短时傅里叶变换。因此,我们希望找到一个序列xi+1(n)x^{i+1}(n)xi+1(n),其短时傅里叶变换Xi+1(m,w)X^{i+1}(m,w)Xi+1(m,w)与修改后的短时傅里叶变换X^i+1(m,w)\hat{X}^{i+1}(m,w)X^i+1(m,w)最接近,这可通过最小化Xi+1(m,w)X^{i+1}(m,w)Xi+1(m,w)与X^i+1(m,w)\hat{X}^{i+1}(m,w)X^i+1(m,w)之间的均方误差实现:
∑m=−∞+∞∑w=−∞+∞Xi+1(m,w)−X\^i+1(m,w)2\sum_{m=-\infty}^{+\infty} \sum_{w=-\infty}^{+\infty} \leftX\^{i+1}(m,w)-\\hat{X}\^{i+1}(m,w)\\right^{2}m=−∞∑+∞w=−∞∑+∞Xi+1(m,w)−X\^i+1(m,w)2
上述最小化问题的解为:
xi+1(n)=∑m=−∞+∞w(n−mS)x^i+1(m,w)∑m=−∞+∞w2(n−mS)x^{i+1}(n)=\frac{\sum_{m=-\infty}^{+\infty} w(n-mS) \hat{x}^{i+1}(m,w)}{\sum_{m=-\infty}^{+\infty} w^{2}(n-mS)}xi+1(n)=∑m=−∞+∞w2(n−mS)∑m=−∞+∞w(n−mS)x^i+1(m,w)
其中,x^i+1(m,w)=12π∫w=−ππX^i+1(m,w)e−jwndw\hat{x}^{i+1}(m,w)=\frac{1}{2\pi} \int_{w=-\pi}^{\pi} \hat{X}^{i+1}(m,w) e^{-jwn} dwx^i+1(m,w)=2π1∫w=−ππX^i+1(m,w)e−jwndw,SSS表示相对于nnn的采样周期。重复上述两个步骤多次,直至收敛,最终输出的xi(n)x^{i}(n)xi(n)即为语音信号的估计值。
六、实现与评估
6.1 实验设置与数据集
我们主要在三星S8手机收集的加速度计测量数据上,对所提出的系统进行评估,所提出模型的可扩展性将在第六节D部分进行评估。对于每种特定设置,在智能手机上播放一系列语音信号,并通过在后台运行的第三方安卓应用AccDataRec收集加速度计读数。
语音信号主要来自两个数据集:第一个数据集包含来自20位说话人的10,000个单数字信号,来源于AudioMNIST数据集²;为了模拟受害者告知他人密码的场景,将该数据集中的信号拼接成长音频信号,信号之间的间隔为0.1秒。第二个数据集包含从志愿者处收集的36×260个数字+字母语音信号;我们从大学招募志愿者,在实验室环境中收集数据,要求志愿者手持智能手机,以告知他人密码时的语速,朗读一长串数字和字母;该数据集共包含36个类别,包括10个数字(0-9)和26个字母(A-Z),每个类别包含来自10位说话人的260个样本。我们从这两个语音源收集加速度计读数,并在不同设置下对所提出的系统进行评估。需要说明的是,本文呈现的所有实验结果均为用户无关的,对于每个所研究的设置,将所有收集到的信号随机分为80%的训练数据和20%的测试数据,下文仅报告测试准确率。
6.2 识别
如前所述,现有最优模型32利用智能手机的陀螺仪,捕捉放置在同一固体表面的扬声器发出的语音信号。为了进行公平比较,我们首先在类似的设置(即将智能手机放置在桌面上)下,评估我们模型的性能。表5列出了我们的系统在数字识别、数字+字母识别和说话人识别任务中的Top1、Top3、Top5(测试)准确率。Top N准确率是指正确标签位于我们网络预测的前N个类别中的概率。值得注意的是,在用户无关的设置下,我们的模型在数字识别任务中的Top1准确率,甚至比用户相关设置下的现有最优准确率高出13%;我们的系统在10个数字+26个字母(共36个类别)的识别任务中,取得了55%的Top1准确率和87%的Top5准确率;在说话人识别任务中,我们的系统在20位说话人的分类任务中,取得了70%的准确率,而此前的最优模型在10位说话人的分类任务中,仅取得了50%的准确率。总体而言,我们的模型在所有任务中均取得了新的最优结果。准确率的提升不仅得益于先进模型的使用,还得益于采样率的提高和所提出的实验设置。我们的实验设置使语音信号能够对运动传感器产生更显著的影响,因此与现有最优实验设置相比,加速度信号的信噪比显著提高。如表格7和表格12所示,识别准确率随加速度信号的信噪比和加速度计的采样率平稳提升。
表5 我们的结果与现有最优结果32的对比
| 任务 | 我们的模型(密集卷积网络) | 现有最优(用户相关) | 现有最优(用户无关) | ||
|---|---|---|---|---|---|
| Top1准确率 | Top3准确率 | Top5准确率 | |||
| 数字 | 78% | 96% | 99% | 65% | 26% |
| 数字+字母 | 55% | 78% | 87% | - | - |
| 说话人 | 70%(20位) | 88%(20位) | 95%(20位) | 50%(10位说话人) | - |
除桌面放置场景外,我们的系统还适用于其他场景,例如更常见的用户手持智能手机场景。与桌面放置场景相比,手持场景下加速度计沿x轴和y轴的信噪比更低,因此应给予z轴更多的关注(权重)。表6展示了我们的模型在"桌面放置"和"手持"场景下的测试准确率。如表6所示,若我们的模型仅使用"桌面放置"或"手持"训练集进行训练,则在另一种测试集上的准确率不超过20%,这是由上述两种场景之间的差异导致的。然而,若我们使用"桌面放置"和"手持"两种训练集对模型进行训练,则模型在两种测试集上的准确率均提升至60%以上。
表6 我们的模型在不同场景下的Top1准确率(所有情况均为用户无关)
| 训练集(80%)\测试集(20%) | 桌面放置 | 手持 | 桌面放置+手持 |
|---|---|---|---|
| 桌面放置 | 78% | 17% | 47% |
| 手持 | 19% | 77% | 48% |
| 桌面放置+手持 | 69% | 63% | 66% |
6.3 噪声的影响
如第四节C部分所述,所提出的攻击可能会受到加速度计固有噪声和远程通话者周围声学噪声的影响。
对于加速度计的固有噪声,尽管该噪声分量的功率在整个频带内均呈下降趋势,但它仍可能削弱加速度信号中的特征,从而降低识别准确率。为了测试我们识别模型对该固有噪声的鲁棒性,我们利用高斯白噪声模拟该噪声,生成不同信噪比的加速度信号,所得信号模拟了在较低音量下收集的加速度计测量数据。数字识别和说话人识别任务的结果如表7所示,尽管准确率随信噪比的降低而下降,但实际上我们的系统具有很强的鲁棒性,在信噪比=2的数据集上,数字识别的准确率甚至超过了现有最优模型在干净数据上的准确率。
表7 我们的识别模型在带噪声的加速度信号(频谱图)上的性能
| 信噪比\任务 | 数字识别(0-9) | 说话人识别(20位说话人) | ||
|---|---|---|---|---|
| Top1准确率 | Top3准确率 | Top1准确率 | Top3准确率 | |
| 信噪比=2 | 42% | 73% | 34% | 64% |
| 信噪比=4 | 52% | 82% | 43% | 71% |
| 信噪比=6 | 61% | 87% | 51% | 77% |
| 信噪比=8 | 66% | 91% | 58% | 81% |
对于远程通话者周围的声学噪声,我们招募了四名志愿者(两名女性和两名男性),要求他们在四种不同噪声水平的实际环境中,向受害者的智能手机发送语音消息:1)无噪声(安静的房间);2)低噪声(有人交谈的实验室);3)中噪声(播放音乐的酒吧);4)高噪声(拥挤的公交车站)。这些环境是根据图6中的实验结果选择的。随后,在桌面放置场景下播放收到的语音消息,并记录加速度计测量数据。每种环境的数据集包含来自四名说话人的200×10个数字频谱图。表8列出了数字识别的结果,令人惊讶的是,我们的识别模型在前三类环境中的准确率均超过80%;在高噪声环境中,由于分割算法难以区分语音信号和突发的高声噪声,识别准确率大幅下降。为了探究我们的识别模型是否能识别分割良好的高噪声信号,我们手动调整了信号的分割点,并重复实验。使用手动分割的信号,我们的模型在高噪声环境中的Top1准确率达到78%,这表明我们的识别模型对环境声学噪声具有很强的鲁棒性。由于所提出的攻击在大多数环境中都能取得较高的准确率,且很少有人会在高噪声环境中进行电话通话,因此我们认为所提出的攻击具有实用性。
表8 实际噪声环境下的识别准确率
无噪声环境下的识别准确率略高于表5中的准确率,原因是本实验仅涉及四名说话人(两名女性和两名男性)。
| 噪声水平 | Top1准确率 | Top3准确率 | Top5准确率 |
|---|---|---|---|
| 无噪声 | 86% | 97% | 100% |
| 低噪声 | 86% | 98% | 99% |
| 中噪声 | 80% | 96% | 99% |
| 高噪声 | 47% | 73% | 88% |
6.4 可扩展性研究
不同的智能手机可能具有不同的采样率和主导轴,这使得在一种智能手机上训练的识别模型,难以推广到其他智能手机型号。为了研究所提出攻击的可扩展性,我们从三款不同型号的六台智能手机中收集加速度信号:1)三星S8:采样率为420Hz,主导轴为z轴;2)华为Mate 20:采样率为500Hz,主导轴为z轴;3)OPPO R17:采样率为410Hz,三款智能手机的三个轴具有相似的音频响应。我们从每个智能手机型号中收集10,000个数字加速度信号,并评估部署一个全局模型的可能性。我们观察到,从华为Mate 20和OPPO R17收集的加速度信号,比从三星S8收集的加速度信号噪声更少。如表9所示,由于不同智能手机型号的硬件特征存在差异,使用一种智能手机型号的数据训练的识别模型,难以推广到其他智能手机。然而,当使用OPPO R17和华为Mate 20的数据共同训练识别模型时,我们观察到三星S8的准确率提高了5%。因此,我们推测,若使用足够多能覆盖硬件特征多样性的智能手机型号的数据对识别模型进行训练,则该识别模型能够扩展到未见过的智能手机。此外,表9还表明,我们的识别模型的容量足够大,能够拟合来自多个智能手机型号的数据,且不会损失准确率。
表9 多设备训练与测试(Top1准确率)
| 训练集\测试集 | 三星S8 | 华为Mate 20 | OPPO R17 |
|---|---|---|---|
| 三星S8 | 80% | 15% | 20% |
| 华为Mate 20 | 12% | 82% | 21% |
| OPPO R17 | 21% | 23% | 91% |
| OPPO R17+华为Mate 20 | 26% | 83% | 90% |
| 三星S8+OPPO R17+华为Mate 20 | 79% | 84% | 90% |
6.5 重建
我们的重建网络的性能通过两个指标进行评估:平均测试L1L_1L1误差和均方误差。给定重建的语音频谱图x~\tilde{x}x~和真实语音频谱图xxx,L1L_1L1误差可通过L1=∑i∣x~i−xi∣L_1=\sum_{i} |\tilde{x}{i}-x{i}|L1=∑i∣x~i−xi∣计算(其中iii表示像素索引),最终测试L1L_1L1误差接近10310^3103,即每个像素的绝对误差约为0.02(像素范围为-1,1);均方误差可通过∑i(x~i−xi)2N\frac{\sum_{i} (\tilde{x}{i}-x{i})^2}{N}N∑i(x~i−xi)2计算(其中NNN表示每个图像的像素数),最终测试均方误差约为3.5×1033.5×10^33.5×103。这些结果表明,我们的重建网络能够以极小的误差,从加速度频谱图中重建语音频谱图。
我们进一步使用格里芬-林算法,从重建的频谱图中估计语音信号,并在图16(a)中展示了结果。为了进行比较,第一行展示了原始语音信号;第二行展示了去除1500Hz以上频率分量的原始语音信号,这实际上是我们试图重建的真实(目标)音频信号。尽管由于加速度信号的频率范围有限,该频率截断可能导致某些辅音信息丢失,但1500Hz几乎是此处语音信号能够重建的最高(谐波)频率;第三行展示了原始加速度信号,与截断后的音频信号相比,其结构相似但细节完全不同,这表明从加速度信号中重建语音信号是一项复杂的任务;第四行展示了通过我们的重建网络和格里芬-林算法重建的语音信号,该信号已经捕捉到了截断后语音信号的大部分结构和细节。我们认为,重建信号与截断信号之间的剩余差异主要源于格里芬-林算法引起的误差,因为若我们将截断后语音信号的相位,简单地应用于我们的重建网络重建的幅值(频谱图),则能够恢复出与截断后音频信号几乎相同的信号,如第五行所示。
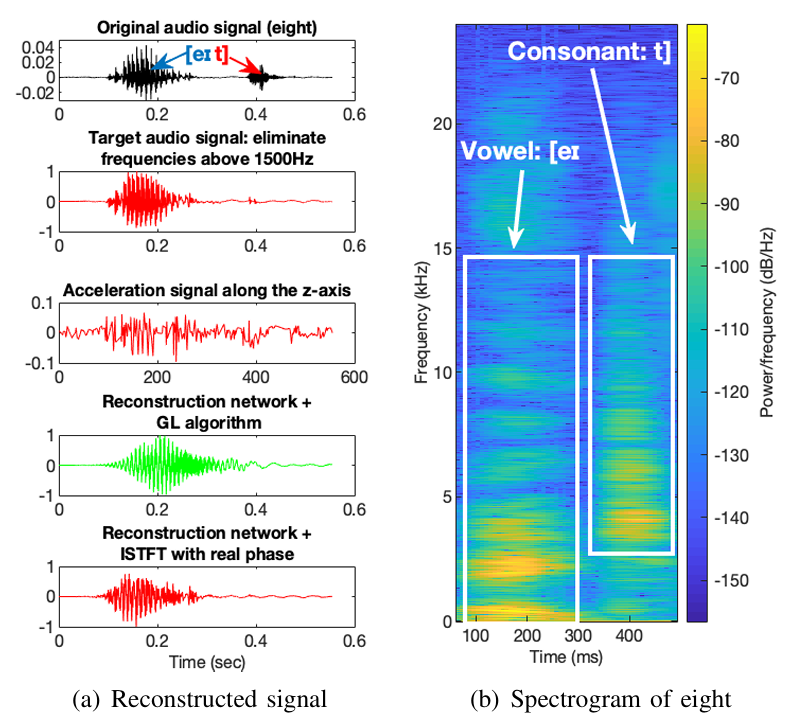
图16 目标语音信号与重建语音信号的对比
语音信息为"eight"(八)。
(a) 重建信号 (b) "eight"的频谱图
据我们所知,我们的重建模块是首次尝试从加速度信号中重建语音信号,且取得了成功,能够大致恢复语音信号的大部分结构和细节。然而,该模块仍存在两个局限性:一是我们的重建模块能够恢复的最高(谐波)频率为1500Hz,这可能导致辅音信息丢失;二是局限性源于格里芬-林算法,该算法可能不是补偿相位信息的最优选择。我们将在第七节中详细介绍这两个局限性以及改进潜力。
6.6 敏感关键词搜索:识别与重建
本节通过实验验证,我们的模型还可用于从句子中搜索敏感关键词。在该实验中,首先使用敏感关键词搜索模型,从句子中识别出预先训练的敏感关键词;然后使用重建模型重建音频信号,并通过人耳对识别出的敏感关键词进行交叉验证。该实验使用了从四名志愿者(两名男性和两名女性)处收集的200个短句子,每个短句子包含若干非敏感词和一至三个表10中列出的敏感关键词。
敏感关键词搜索模型基于一个识别模型,该识别模型能够区分八个敏感关键词(如表10所示)和其他非敏感词。为了训练该模型,我们从志愿者处收集了一个训练数据集,包含128×8个敏感关键词和2176个非敏感词(负样本)。可以观察到,该数据集存在类别不平衡问题,因为每个敏感关键词类别的样本数,远少于负样本的数量。为了解决该问题,我们对九个类别的损失进行了重新加权。由于负样本的总数是每个敏感关键词类别样本数的17倍,我们将敏感关键词样本计算的损失加权为17α,将负样本计算的损失加权为α(α是超参数,在训练过程中设置为0.1)。随后,将测试句子的加速度信号分割为单单词频谱图,并使用敏感关键词搜索模型对其进行识别。如表10所示,我们的识别模型在这八个敏感关键词上的平均识别准确率超过90%,略高于在10个数字上的识别准确率。需要说明的是,这是因为该识别任务仅包含九个类别,且与数字和字母相比,这八个敏感关键词的频谱图更具区分性。
表10 每个敏感关键词的真阳性率(TPR)和假阳性率(FPR)
| 关键词 | 真阳性率 | 假阳性率 | 交叉验证假阳性率 |
|---|---|---|---|
| Password(密码) | 94% | 0.4% | 0.2% |
| Username(用户名) | 97% | 0.4% | 0.3% |
| Social(社会) | 100% | 0.3% | 0.0% |
| Security(安全) | 91% | 0.0% | 0.0% |
| Number(数字) | 88% | 0.1% | 0.0% |
| Email(电子邮件) | 88% | 1.4% | 0.8% |
| Credit(信用) | 88% | 0.3% | 0.3% |
| Card(卡片) | 97% | 1.4% | 0.3% |
随后,我们实现了一个能够从加速度信号中重建完整句子音频信号的重建模型。由于重建模型主要学习信号之间的映射关系,而非语义信息,因此它不需要进行信号分割,且与识别模型相比,其对未见过的(未训练过的)数据具有更强的泛化能力。为了训练该模型,我们收集了6480个加速度频谱图和音频频谱图,对应的句子与测试句子不同。加速度频谱图和音频频谱图的分辨率分别为128×1280×3128×1280×3128×1280×3和384×1280384×1280384×1280,这使得重建模型能够重建长达12秒的音频信号。我们使用该模型和格里芬-林算法,重建了所有测试句子的音频信号,并邀请两名志愿者进行收听。在该过程中,首先对每位志愿者进行基础训练,让他们收听20个句子及其重建版本;然后要求志愿者收听重建的信号(句子),并对识别模型误识别的敏感关键词进行重新标记。在此过程中,除非两名志愿者均同意修改,否则不会更改敏感关键词的标签。结果表明,志愿者能够轻松判断一个敏感关键词是否被误识别,所有敏感关键词的假阳性率均降至1%以下,且真阳性率保持不变。这主要是因为收听完整的句子,使攻击者能够利用有价值的上下文信息。
6.7 端到端案例研究:从电话通话中窃取密码
本节通过电话通话中的端到端攻击,对所提出的模型进行评估。我们考虑一个实际场景:受害者与远程通话者进行电话通话,并在通话过程中索要密码,攻击者的目标是从受害者的加速度计测量数据中定位并识别该密码。在该攻击中,我们假设密码前带有敏感关键词"password (is)"(密码是)。如第六节F部分所示,该攻击可轻松扩展至支持其他敏感关键词。
在实验中,受害者的智能手机在三种不同场景下,与四名志愿者(两名女性和两名男性)进行电话通话:1)桌面放置场景:受害者的智能手机放置在桌面上;2)手持坐姿场景:受害者坐在椅子上,手持智能手机;3)手持行走场景:受害者手持智能手机,四处行走。在每种场景下,每人进行16次脚本化通话和4次自由通话(总共240次通话)。在所有通话过程中,要求志愿者在说出短语"password is"(密码是)后,告知一个随机的8位数字密码。
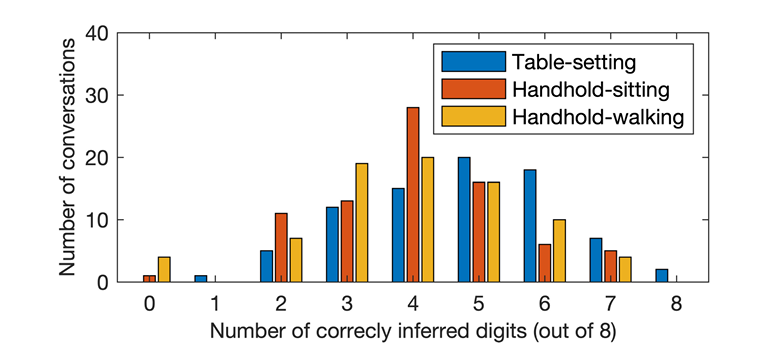
图17 每次通话中正确推断的数字个数
记录一次通话的加速度信号后,首先将加速度信号转换为多个单单词频谱图,并使用密码搜索模型查找与敏感关键词"password"(密码)对应的频谱图;然后使用数字识别模型识别其后的8位数字密码。
密码搜索模型通过一个分类器,在记录的加速度信号中搜索关键词"password"(密码),该分类器能够区分"password"(密码)和其他单词。为了训练该分类器,我们收集了一个训练数据集,包含200个"password"(密码)样本和2200个负样本(包括数字和其他一些单词)。如第六节F部分所示,我们同样通过重新加权损失,解决类别不平衡问题,具体而言,将"password"(密码)样本计算的损失加权为11α,将负样本计算的损失加权为α。若模型在一次通话中识别出多个"password"(密码),则报告置信度最高的那个。使用该模型,我们在所有场景下的85%以上的通话中,成功定位了密码,如表11所示。
表11 每个模型推断出的正确数字百分比
| 场景 | 密码搜索准确率 | 数字识别 | ||
|---|---|---|---|---|
| Top1准确率 | Top3准确率 | Top5准确率 | ||
| 桌面放置场景 | 92% | 59% | 84% | 92% |
| 手持坐姿场景 | 85% | 51% | 83% | 94% |
| 手持行走场景 | 91% | 50% | 81% | 91% |
每个场景的数字识别模型,均使用280×10个数字频谱图进行训练。表11列出了识别模型的总体准确率,我们还计算了每次通话中正确推断的数字个数,并绘制了其分布(图17)。可以观察到,电话通话场景下的识别准确率,低于录制-播放场景下的识别准确率,这主要是因为电话通话过程中传输的音频信号质量,低于录制应用程序录制的音频信号质量。一个重要的发现是,我们的识别模型在所有场景下的Top3识别准确率均超过80%。尽管所提出的攻击仅在少数通话中能够识别出完整的密码,但它将极大地帮助攻击者缩小对受害者密码的搜索范围。
七、进一步改进
如第六节E部分末尾所述,我们的重建模块的性能仍受到加速度信号的频率范围和格里芬-林算法准确性的限制。第一个局限性限制了能够重建的音频频率范围,因此主要分布在高频域的辅音信息会丢失(如图16(b)所示)。然而,我们相信,随着未来智能手机硬件的改进,这一局限性将得到缓解。第二个局限性可能源于格里芬-林算法,因为该算法试图从零开始补偿所有相位信息。为了提高性能,我们提议在算法中引入加速度信号的相位信息,这将在我们未来的工作中详细介绍。
八、防御措施
本节讨论防御所提出攻击的可能方向。由于典型人类语音的最低基频为85Hz,一种有前景的防御措施是限制加速度计的采样率。根据奈奎斯特定理,工作频率低于170Hz的加速度计,无法再现任何85Hz以上的频率分量。尽管加速度计仍会受到高频音频信号的影响,但捕捉到的信息将被扭曲,识别准确率可能会下降。
为了找到最优阈值,我们使用采样率分别为300Hz、200Hz、160Hz、100Hz和50Hz的加速度计测量数据,进行语音识别实验。表12列出了桌面放置场景下,在数字数据集(来自20位说话人的10,000个单数字信号)上的识别准确率。可以观察到,识别准确率随采样率的降低而下降,在50Hz时降至30%。在实际攻击中,由于25Hz以下的加速度信号会受到人体运动的显著影响,50Hz时的识别准确率可能会进一步下降。
表12 采样率的影响(桌面放置场景)
| 采样率 | 300Hz | 200Hz | 160Hz | 100Hz | 50Hz |
|---|---|---|---|---|---|
| 识别准确率 | 73% | 64% | 56% | 47% | 30% |
根据安卓开发者文档2,用户界面和移动游戏的推荐采样率分别为16.7Hz和50Hz。对于行为识别,50Hz也已足够,因为大多数人类活动的频率低于20Hz。因此,我们建议,采样率超过50Hz的应用程序应通过<uses-permission>请求权限,这将影响谷歌应用商店对它们的筛选3。
另一种有效的防御措施是,当某些应用程序在后台以高采样率收集加速度计读数时,向用户发出通知。例如,当某些应用程序在后台收集语音信号时,iOS系统会在状态栏上显示一个闪烁的"麦克风"图标。安卓系统也可部署类似的机制,提醒用户其加速度计读数的使用时间、使用地点和使用方式。
九、结论
本文重新审视了零权限运动传感器对语音隐私的威胁,提出了一种高度实用的针对智能手机扬声器的边信道攻击方法。首先,我们提出了两个重要发现,将基于运动传感器的音频窃听扩展到日常场景:第一,智能手机扬声器发出的语音信号,总会对同一台手机的加速度计产生显著影响;第二,新款安卓智能手机的加速度计,几乎能够覆盖成年人语音的整个基频带。基于这些关键发现,我们提出了AccelEve,一种基于学习的智能手机窃听攻击方法,无论智能手机被放置在何处、以何种方式放置,该方法都能识别并重建其扬声器发出的语音信号。通过深度网络、自适应优化器和鲁棒且具有泛化性的损失函数,我们的攻击在所有识别和重建任务中,均显著且持续地优于基准模型和现有解决方案。具体而言,AccelEve在数字识别任务中的准确率,达到了现有研究结果的三倍;在语音重建任务中,AccelEve能够重建采样率提升的语音信号,不仅覆盖了低频段的基频分量(元音),还覆盖了其在高频段的谐波分量。由于清辅音的频率(2000Hz以上)远超当前智能手机的采样率,因此未能被恢复。
致谢
感谢审稿人提出的有益意见。本研究得到了国家自然科学基金(项目编号:61772236)、浙江省重点研发计划(项目编号:2019C03133)、阿里巴巴-浙江大学前沿技术联合研究院、浙江大学网络空间治理研究院,以及麦吉尔大学威廉·道森学者讲座教授基金的部分支持。
参考文献
1 "Coriolis force," https://en.wikipedia.org/wiki/Coriolis force.
2 "Sensor Overview," https://developer.android.com/guide/topics/sensors/ sensors overview.
3 "uses-permission," https://developer.android.com/guide/topics/manifest/ uses-permission-element.
4 ANALOG DEVICES, "ADXL150/ADXL250," https://hibp.ecse.rpi. edu/∼connor/education/EIspecs/ADXL150 250 0.pdf.
5 S. A. Anand and N. Saxena, "Speechless: Analyzing the threat to speech privacy from smartphone motion sensors," in 2018 IEEE Symposium on Security and Privacy (SP). IEEE, 2018, pp. 1000--1017.
6 S. A. Anand, C. Wang, J. Liu, N. Saxena, and Y. Chen, "Spearphone: A speech privacy exploit via accelerometer-sensed reverberations from smartphone loudspeakers," arXiv preprint arXiv:1907.05972, 2019.
7 R. J. Baken and R. F. Orlikoff, Clinical measurement of speech and voice. Cengage Learning, 2000.
8 S. Becker, M. Ackermann, S. Lapuschkin, K.-R. M¨uller, and W. Samek, "Interpreting and explaining deep neural networks for classification of audio signals," arXiv preprint arXiv:1807.03418, 2018.
9 H. Bojinov, Y. Michalevsky, G. Nakibly, and D. Boneh, "Mobile device identification via sensor fingerprinting," arXiv preprint arXiv:1408.1416, 2014.
10 L. Cai and H. Chen, "Touchlogger: Inferring keystrokes on touch screen from smartphone motion." HotSec, vol. 11, no. 2011, p. 9, 2011.
11 R. Chen and I. C. Paschalidis, "A robust learning approach for regression models based on distributionally robust optimization," The Journal of Machine Learning Research, vol. 19, no. 1, pp. 517--564, 2018.
12 A. Das, N. Borisov, and M. Caesar, "Exploring ways to mitigate sensorbased smartphone fingerprinting," arXiv preprint arXiv:1503.01874, 2015.
13 A. De Cheveign´e and H. Kawahara, "Yin, a fundamental frequency estimator for speech and music," The Journal of the Acoustical Society of America, vol. 111, no. 4, pp. 1917--1930, 2002.
14 R. N. Dean, G. T. Flowers, A. S. Hodel, G. Roth, S. Castro, R. Zhou, A. Moreira, A. Ahmed, R. Rifki, B. E. Grantham et al., "On the degradation of mems gyroscope performance in the presence of high power acoustic noise," in 2007 IEEE International Symposium on Industrial Electronics. IEEE, 2007, pp. 1435--1440.
15 S. Dey, N. Roy, W. Xu, R. R. Choudhury, and S. Nelakuditi, "Accelprint: Imperfections of accelerometers make smartphones trackable," in NDSS, 2014.
16 J. Doscher and M. Evangelist, "Accelerometer design and applications," Analog devices, vol. 3, p. 16, 1998.
17 H. Feng, K. Fawaz, and K. G. Shin, "Continuous authentication for voice assistants," in Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking. ACM, 2017, pp. 343--355.
18 H. Fujisaki, "Dynamic characteristics of voice fundamental frequency in speech and singing," in The production of speech. Springer, 1983, pp. 39--55.
19 S. Grawunder and I. Bose, "Average speaking pitch vs. average speaker fundamental frequency--reliability, homogeneity, and self report of listener groups," in Proceedings of the International Conference Speech Prosody, 2008, pp. 763--766.
20 D. Griffin and J. Lim, "Signal estimation from modified short-time fourier transform," IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 32, no. 2, pp. 236--243, 1984.
21 J. Han, E. Owusu, L. T. Nguyen, A. Perrig, and J. Zhang, "Accomplice: Location inference using accelerometers on smartphones," in 2012 Fourth International Conference on Communication Systems and Networks (COMSNETS 2012). IEEE, 2012, pp. 1--9.
22 K. He, X. Zhang, S. Ren, and J. Sun, "Deep residual learning for image recognition," in Proceedings of the IEEE conference on computer vision and pattern recognition. IEEE, 2016, pp. 770--778.
23 S. Hershey, S. Chaudhuri, D. P. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold et al., "CNN architectures for large-scale audio classification," in 2017 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2017, pp. 131--135.
24 G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, "Densely connected convolutional networks," in Proceedings of the IEEE conference on computer vision and pattern recognition. IEEE, 2017, pp. 4700--4708.
25 J. Johnson, A. Alahi, and L. Fei-Fei, "Perceptual losses for realtime style transfer and super-resolution," in European conference on computer vision. Springer, 2016, pp. 694--711.
26 T. Kaya, B. Shiari, K. Petsch, and D. Yates, "Design of a mems capacitive comb-drive accelerometer," in COMSOL Conference, Boston, 2011.
27 J. R. Kwapisz, G. M. Weiss, and S. A. Moore, "Activity recognition using cell phone accelerometers," ACM SigKDD Explorations Newsletter, vol. 12, no. 2, pp. 74--82, 2011.
28 J. Liu, C. Wang, Y. Chen, and N. Saxena, "Vibwrite: Towards fingerinput authentication on ubiquitous surfaces via physical vibration," in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 73--87.
29 P. Marquardt, A. Verma, H. Carter, and P. Traynor, "(sp) iphone: Decoding vibrations from nearby keyboards using mobile phone accelerometers," in Proceedings of the 18th ACM conference on Computer and communications security. ACM, 2011, pp. 551--562.
30 A. Matic, V. Osmani, and O. Mayora, "Speech activity detection using accelerometer," in 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE, 2012, pp. 2112-- 2115.
31 R. Matovu, I. Griswold-Steiner, and A. Serwadda, "Kinetic song comprehension: Deciphering personal listening habits via phone vibrations," arXiv preprint arXiv:1909.09123, 2019.
32 Y. Michalevsky, D. Boneh, and G. Nakibly, "Gyrophone: recognizing speech from gyroscope signals," in Proceedings of the 23rd USENIX conference on Security Symposium. USENIX Association, 2014, pp. 1053--1067.
33 E. Miluzzo, A. Varshavsky, S. Balakrishnan, and R. R. Choudhury, "Tapprints: your finger taps have fingerprints," in Proceedings of the 10th international conference on Mobile systems, applications, and services. ACm, 2012, pp. 323--336.
34 E. Owusu, J. Han, S. Das, A. Perrig, and J. Zhang, "Accessory: password inference using accelerometers on smartphones," in Proceedings of the Twelfth Workshop on Mobile Computing Systems & Applications. ACM, 2012, p. 9.
35 M. Shoaib, H. Scholten, and P. J. Havinga, "Towards physical activity recognition using smartphone sensors," in 2013 IEEE 10th international conference on ubiquitous intelligence and computing and 2013 IEEE 10th international conference on autonomic and trusted computing. IEEE, 2013, pp. 80--87.
36 K. Simonyan and A. Zisserman, "Very deep convolutional networks for large-scale image recognition," arXiv preprint arXiv:1409.1556, 2014.
37 Y. Son, H. Shin, D. Kim, Y. Park, J. Noh, K. Choi, J. Choi, and Y. Kim, "Rocking drones with intentional sound noise on gyroscopic sensors," in Proceedings of the 24th USENIX Conference on Security Symposium. USENIX Association, 2015, pp. 881--896.
38 I. R. Titze and D. W. Martin, "Principles of voice production," Acoustical Society of America Journal, vol. 104, p. 1148, 1998.
39 T. Trippel, O. Weisse, W. Xu, P. Honeyman, and K. Fu, "WALNUT: Waging doubt on the integrity of mems accelerometers with acoustic injection attacks," in 2017 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2017, pp. 3--18.
40 Y. Tu, Z. Lin, I. Lee, and X. Hei, "Injected and delivered: fabricating implicit control over actuation systems by spoofing inertial sensors," in Proceedings of the 27th USENIX Conference on Security Symposium. USENIX Association, 2018, pp. 1545--1562.
41 C. Xu, Z. Li, H. Zhang, A. S. Rathore, H. Li, C. Song, K. Wang, and W. Xu, "WaveEar: Exploring a mmwave-based noise-resistant speech sensing for voice-user interface," in Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services. ACM, 2019, pp. 14--26.
42 Z. Xu, K. Bai, and S. Zhu, "Taplogger: Inferring user inputs on smartphone touchscreens using on-board motion sensors," in Proceedings of the fifth ACM conference on Security and Privacy in Wireless and Mobile Networks. ACM, 2012, pp. 113--124.
43 S. Zagoruyko and N. Komodakis, "Wide residual networks," arXiv preprint arXiv:1605.07146, 2016.
44 L. Zhang, P. H. Pathak, M. Wu, Y. Zhao, and P. Mohapatra, "Accelword: Energy efficient hotword detection through accelerometer," in Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Services. ACM, 2015, pp. 301--315.