Kafka再平衡:从"深夜救火"到"优雅控场"的全链路解析
Pain Point Alert :监控大屏红了!消费者组每小时触发17次再平衡,消息堆积破10万... 本文撕开Rebalance的"黑盒",用原理+实战双视角,终结你的焦虑。
一、什么是再平衡?何时触发?------ 别再被"神秘抖动"吓到
Rebalance(再平衡) 是Kafka消费者组的"动态调度中枢":当组内成员或分区关系变化时,GroupCoordinator(组协调器) 通过心跳机制感知变化,触发全组重新分配分区,确保每个Partition同一时刻仅被一个消费者处理。
🔥 5大触发导火索(附底层逻辑)
| 触发场景 | 底层机制 | 血泪现场 |
|---|---|---|
| 消费者上下线 | 心跳超时(session.timeout.ms)或主动Leave |
GC停顿30秒 → 被Coordinator踢出 → 全组重平衡 |
| Topic分区扩容 | Coordinator检测到元数据变更 | 运维手抖kafka-topics --alter --partitions 20 → 全组停摆 |
| 订阅Topic变化 | 消费者提交的订阅列表差异 | 动态正则匹配新Topic → 触发重分配 |
| 消费者组扩容/缩容 | JoinGroup请求成员列表变化 | 滚动发布时未等稳定 → 连续触发3次Rebalance |
| Coordinator迁移 | Broker故障导致Coordinator切换 | 集群节点宕机 → 重新选举Coordinator → 全组重加入 |
💡 关键认知 :
Rebalance不是Bug,是分布式一致性代价。但高频触发 = 配置缺陷 + 代码隐患!
二、撕开黑盒:Rebalance三阶段全流程(附序列图)
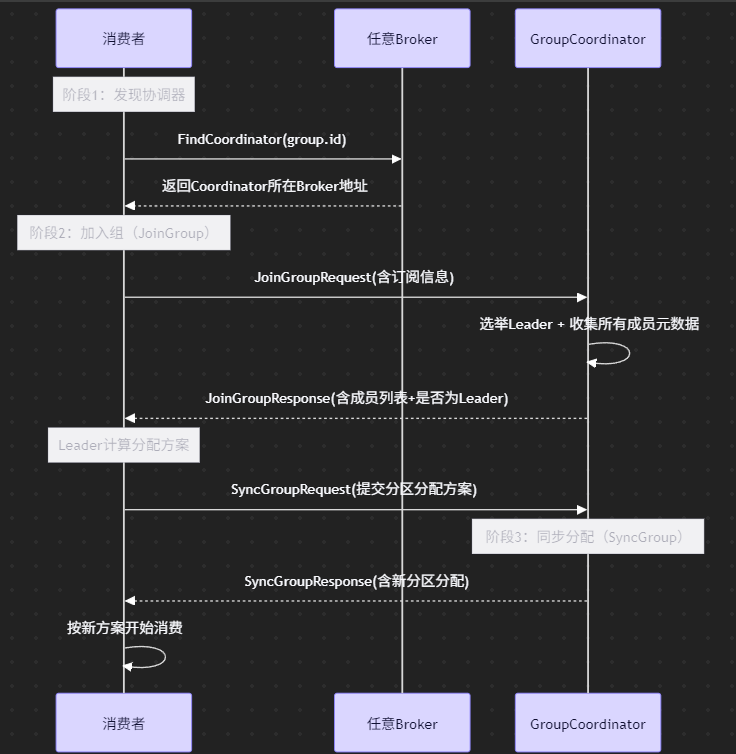
📌 三阶段致命痛点
- 全组STW :JoinGroup/SyncGroup期间所有消费者暂停拉取(旧协议)
- 单点瓶颈:Leader需计算全量分配方案,组规模大时耗时飙升
- 雪崩风险:一次Rebalance未完成 → 新变化触发二次Rebalance → 恶性循环
三、痛点暴击:为什么Rebalance总在"搞事情"?
| 问题 | 根源 | 真实案例 |
|---|---|---|
| 消费STW | 三阶段同步阻塞 | 大促扩容10实例 → 全组停摆15秒 → 订单积压告警 |
| 消息堆积 | STW期间生产持续 | 消费停顿5秒 → 堆积从0飙至8万条 |
| 重复消费 | Offset提交与Rebalance时序冲突 | onPartitionsRevoked未提交Offset → 新实例重消费 |
| 分配倾斜 | RangeAssignor策略缺陷 | 3消费者+5分区 → 2个消费者扛3个分区 |
🌰 经典翻车现场 :
消费者处理单条消息需120秒,
max.poll.interval.ms=300s。网络抖动导致心跳延迟 → Coordinator误判宕机 → 触发Rebalance →
新消费者接手后同样超时 → 组内持续震荡3小时!
四、破局三重奏:防 + 控 + 容
✅ 防:减少触发频率
# 心跳参数黄金组合(按业务调整!)
session.timeout.ms=30000 # Coordinator判定宕机阈值(建议10-30s)
heartbeat.interval.ms=10000 # 心跳发送间隔(≤ session.timeout.ms/3)
max.poll.interval.ms=300000 # 单次poll最大处理时间(防慢处理误踢)- 代码防御:消费逻辑中禁用耗时操作(DB慢查询、RPC调用)
- 发布规范:滚动更新时"先扩后缩",避免成员频繁变动
✅ 控:缩短Rebalance耗时
📊 分区分配策略对比表
| 策略 | 原理 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
| RangeAssignor | 按Topic连续分配 | 简单 | 分区倾斜严重 | ❌ 避免使用 |
| RoundRobin | 轮询均匀分配 | 均衡 | 变化时全量重分配 | 小规模组 |
| StickyAssignor | 最小变动迁移 | 保留原有分配+均衡 | 计算稍复杂 | ✅ 生产首选 |
🌟 协作再平衡(Kafka 2.4+ 革命性改进)
// Spring Kafka配置示例
@Bean
public Map<String, Object> consumerConfigs() {
return Map.of(
ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
"org.apache.kafka.clients.consumer.StickyAssignor", // 启用协作模式
ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 30000,
ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 10000
);
}效果 :
Rebalance分两阶段 → 消费者边释放旧分区边获取新分区 → 停机时间从"秒级"降至"毫秒级",消费几乎无感!
✅ 容:降低业务影响
-
Offset管理 :
// 实现ConsumerRebalanceListener精准控制 consumer.subscribe(topics, new ConsumerRebalanceListener() { public void onPartitionsRevoked(Collection<TopicPartition> partitions) { consumer.commitSync(); // 立即提交Offset,防重复 } public void onPartitionsAssigned(Collection<TopicPartition> partitions) { // 初始化消费位点/缓存 } }); -
业务层幂等:唯一ID去重、数据库唯一索引、状态机校验
-
监控告警 :
rebalance.rate.per.hour > 5→ 企业微信告警
rebalance.latency.avg > 2000ms→ 链路追踪介入
五、避坑 Checklist(运维/开发双视角)
- 参数三连 :
session.timeout.ms、heartbeat.interval.ms、max.poll.interval.ms按业务校准 - 策略锁定 :生产环境强制使用
StickyAssignor - 代码守卫 :消费循环内无阻塞操作,实现
ConsumerRebalanceListener - 发布纪律:扩容→观察10分钟→缩容旧实例
- 监控覆盖 :
kafka.consumer:type=consumer-coordinator-metrics→ rebalance频率/耗时
kafka.consumer:type=consumer-fetch-manager-metrics→ 消息堆积量 - 严禁操作:生产环境随意修改Topic分区数!
六、结语:与Rebalance"共生共荣"
Rebalance不是敌人,无知才是 。
它是Kafka守护数据一致性的"守夜人",而我们的任务是:
🔹 用参数调优减少误触发
🔹 用协作协议压缩停机时间
🔹 用幂等设计拥抱不确定性
下次监控告警响起时,你可以从容打开日志:
"这次Rebalance耗时287ms,分配方案仅变动2个分区------一切尽在掌控。"
你在Rebalance上踩过哪些坑?评论区交换"救命稻草"👇 💬