前言
如果觉得此处的主题看起来不舒服可以尝试以下链接
由于笔者部分图片大小过大平台限制无法上传,或者出于其他原因导致上传失败,(标有 图片过大平台限制无法上传 )大概有四五张图片左右,如果影响观看也可以去下面链接
drf笔记与源码解析
面向对象知识补充
1、getattr(self)
-
用于反射属性和方法
pythonclass Foo(object): def __init__(self, name, age): self.name = name self.age = age def show(self): return "这是 show 方法的返回值" obj = Foo("小明", 21) v1 = getattr(obj, 'name') print(v1) v2 = getattr(obj, 'show')() print(v2)结果:
bash小明 这是 show 方法的返回值
2、getattr(self, item)
-
在面向对象当你获取不存在的属性时执行
pythonclass Foo(object): def __init__(self, name, age): self.name = name self.age = age def __getattr__(self, item): print("不存在的属性----->",item) return "这是 getattr 的返回值" obj = Foo("小明", 21) print(obj.xxxxx)结果:
bash不存在的属性-----> xxxxx 这是 getattr 的返回值如果没有getattr方法的话打印不存在的属性时会报错
3、getattribute(self, item)
-
在面向对象中访问属性时执行无论是否存在都会执行
pythonclass Foo(object): def __init__(self, name, age): self.name = name self.age = age def __getattribute__(self, item): print("无论是否存在的属性----->",item) return "这是 getattribute 的返回值" obj = Foo("小明", 21) print(obj.name) print(obj.age) print(obj.xxxxx)结果:
bash无论是否存在的属性-----> name 这是 getattribute 的返回值 无论是否存在的属性-----> age 这是 getattribute 的返回值 无论是否存在的属性-----> xxxxx 这是 getattribute 的返回值
4、@property
python
@property
def user(self):
return 123-
此时可以直接使用属性的调用方式调用
pythonobj.user
drf(纯净版项目)
settings.py基本配置,可参考
python
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent.parent
SECRET_KEY = 'django-insecure-6t452+ox7@$=!#-jgywyo*7$fy3&2*x^0xaqtg25k74k51j8bf'
DEBUG = True
ALLOWED_HOSTS = []
INSTALLED_APPS = [
# 'django.contrib.admin',
# 'django.contrib.auth',
# 'django.contrib.contenttypes',
# 'django.contrib.sessions',
# 'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'api.apps.ApiConfig'
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
# 'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware',
# 'django.contrib.auth.middleware.AuthenticationMiddleware',
# 'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'blog.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
# 'django.contrib.auth.context_processors.auth',
# 'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = 'blog.wsgi.application'
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
LANGUAGE_CODE = 'en-us'
TIME_ZONE = 'UTC'
USE_I18N = True
USE_TZ = True
STATIC_URL = 'static/'
DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
REST_FRAMEWORK = {
"UNAUTHENTICATED_USER": None
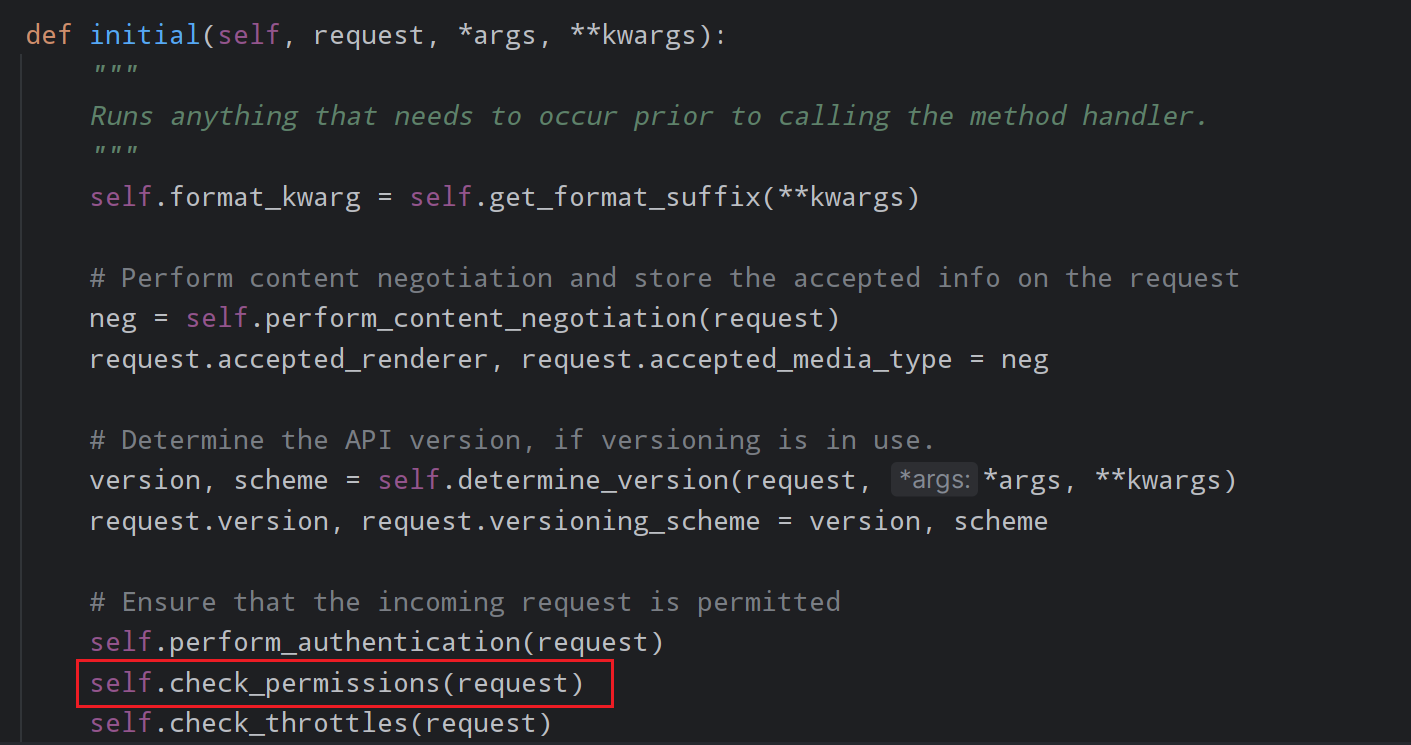
}drf(认证)
对匿名用户添加配置防止报错
-
源码入口
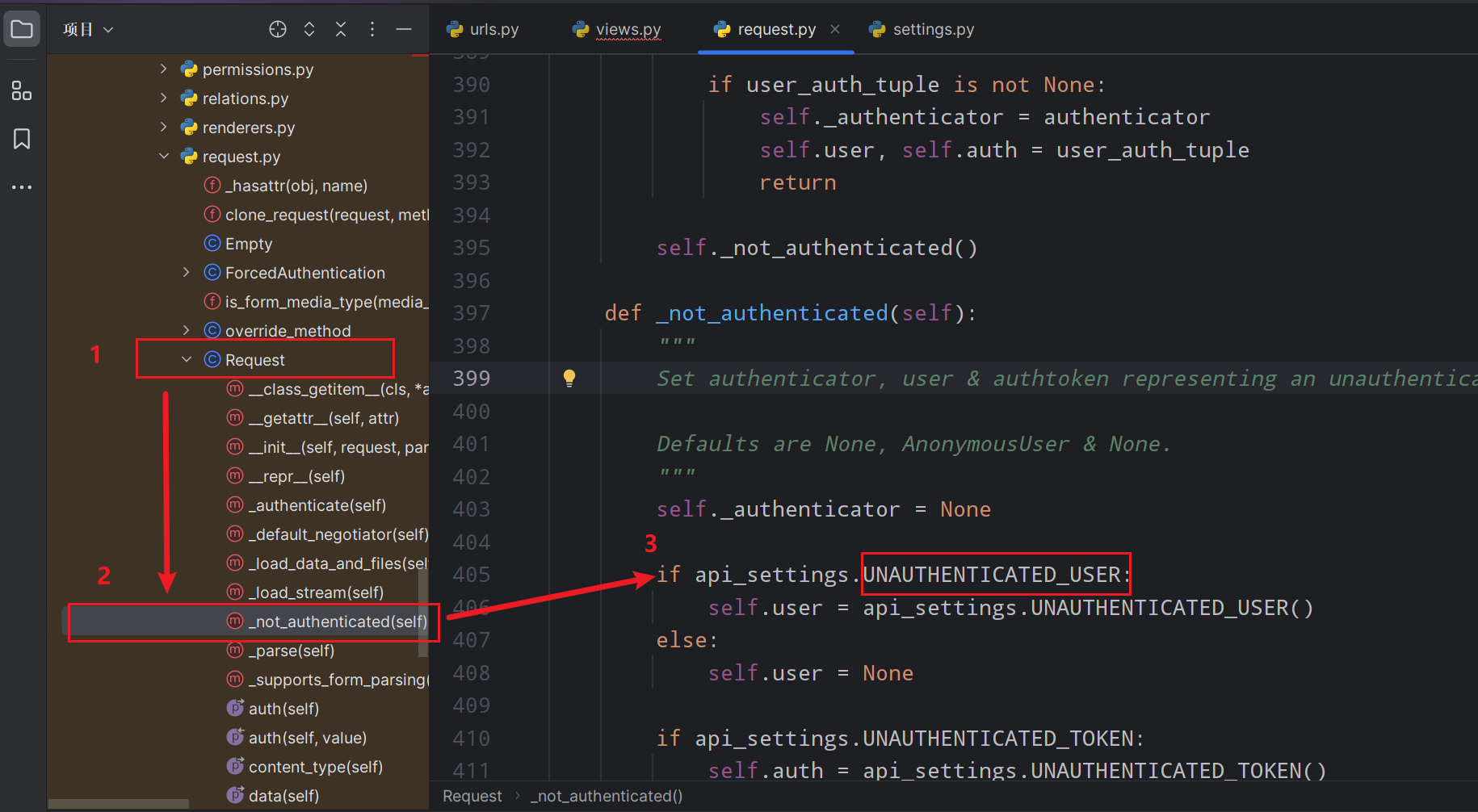
在settings.py中添加
pythonREST_FRAMEWORK = { "UNAUTHENTICATED_USER": None, }
这样的话就从源码从分析,会走下面的这个,如果走上面那个会调用drf的默认值,使页面报错
如何进行用户的认证
-
基础实现
pythonfrom rest_framework.response import Response from rest_framework.views import APIView from rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailed class MyAuthentication(BaseAuthentication): def authenticate(self, request): token = request.query_params.get("token") if token: return "JELEE", token # raise AuthenticationFailed("认证失败") raise AuthenticationFailed({"code": 2000, "message": "认证失败"}) class loginView(APIView): def get(self, request): print(request.user,request.auth) # None None return Response("loginView") class userView(APIView): authentication_classes = [MyAuthentication, ] # 添加验证的类,可以填写多个 def get(self, request): print(request.user,request.auth) # JELEE xxxx 这里打印的是上面返回的两个值 return Response("userView") class orderView(APIView): authentication_classes = [MyAuthentication, ] def get(self, request): return Response("orderView")-
解释代码
raise AuthenticationFailed()如果里面填写的是字符串,那他会自动添加detail拼接成字典
如果里面直接填写的字典,那他就会返回字典在页面上显示
return "JELEE", token这里面的两个分别会赋值给
request.user和request.auth
就可以在方法里面获取这两个的值
-
添加全局验证配置
-
添加配置
pythonREST_FRAMEWORK = { "UNAUTHENTICATED_USER": None, "DEFAULT_AUTHENTICATION_CLASSES": ["位置", ] }"DEFAULT_AUTHENTICATION_CLASSES": ["位置", ]的意思是添加全局验证配置,列表中填写验证的规则位置
如果两个地方都写了配置,会执行视图的配置注意:
理解方式:优先执行全局的配置后执行视图的配置后会覆盖全局的配置
真实实现原理(面向对象的继承):
pythonclass APIView(object): authentication_classes = 读取配置文件中的列表 def dispatch(self): self.authentication_classes class UserView(APIView): authentication_classes = [] obj = UserView() obj.dispatch()源码解析:
图片过大平台限制无法上传
此图较大,看不清的话就下载下来看
-
验证的位置
如果是全局的验证,不能编写在视图中
如果是在视图中编写全局的应用类,会出现循环引用的问题
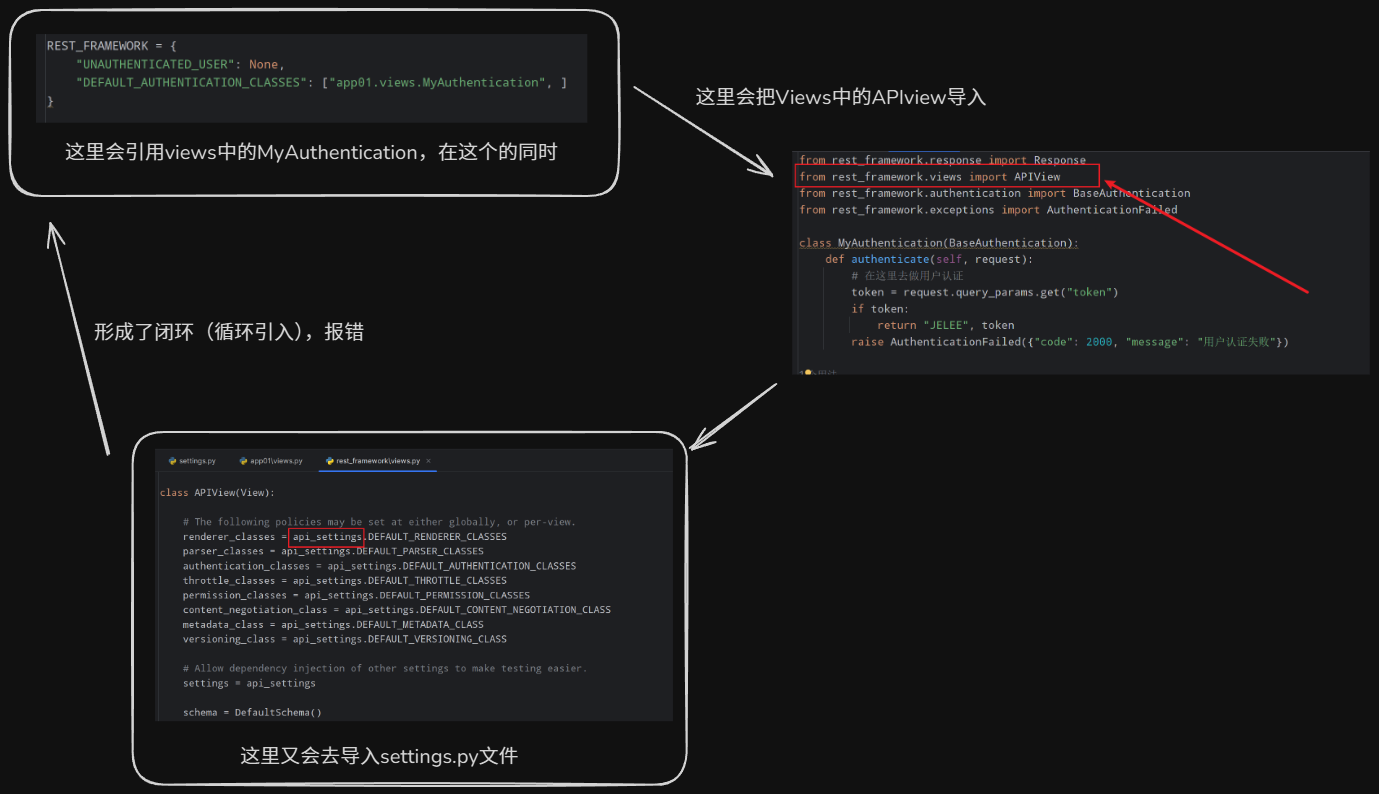
如果有多个认证组件,认证组件中如果没有抛出异常的话,那视图函数依然会执行
如果抛出了异常,那视图函数就不会执行
最佳实践:
将所有的验证类都编写在一个统一的文件中
解决状态码一致问题
-
在AuthenticationFailed抛出异常以后此处状态码应该是401的

-
但是实际上的状态码

这个现象需要在源码中解释

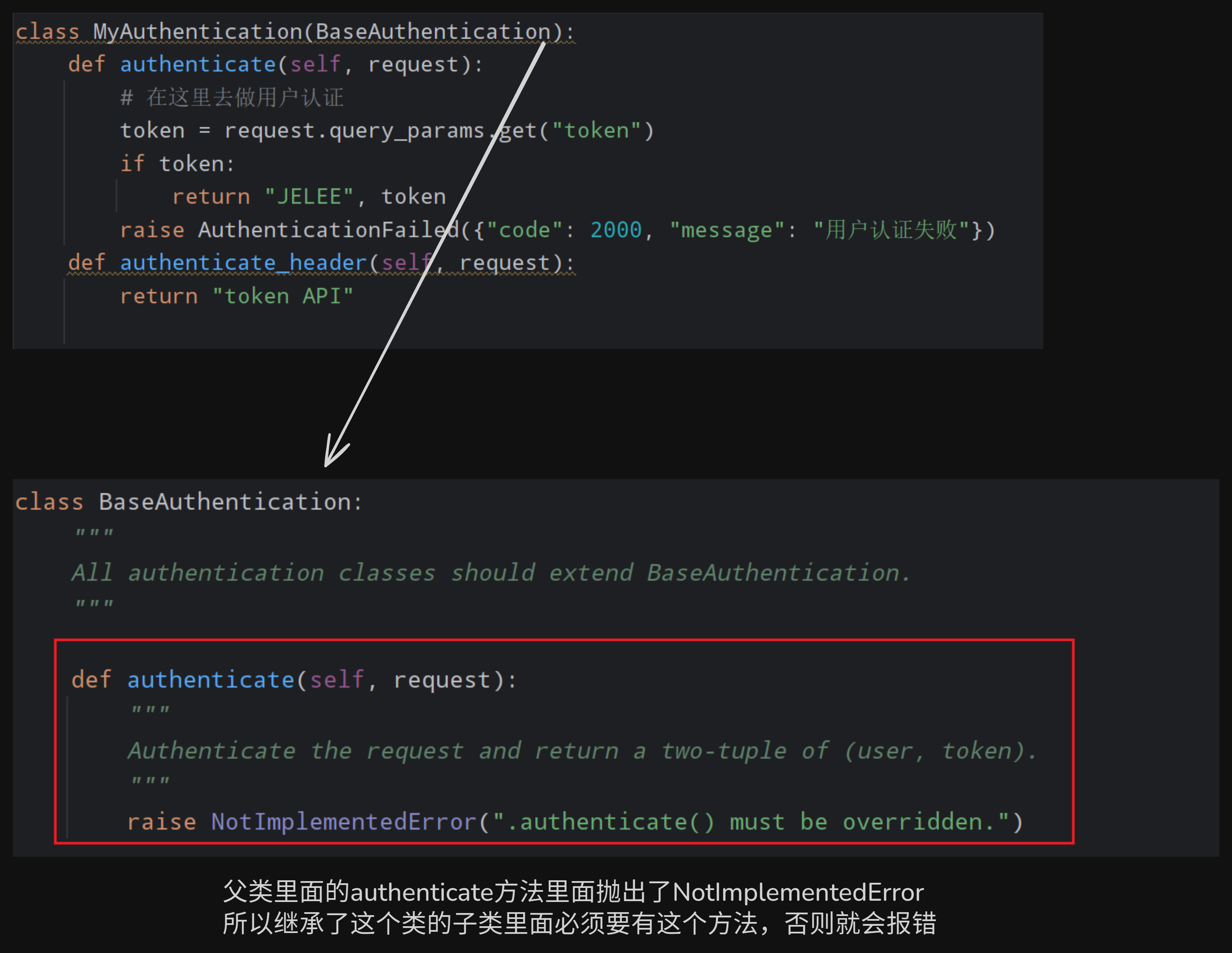
拓展:子类约束
需要让自己的子类里面必须有某个方法的时候
使用
raise NotImplementedError
python
class Foo(object):
def f1(self):
raise NotImplementedError("")
class New(Foo):
pass此时的New里面必须有f1方法,否则就会报错
在drf中的体现:
案例:用户登录注册
-
request.data可以获取用户发过来的请求体中的数据pythondef post(self, request): print(request.data) print(request.query_params) return Response("loginView") # 通过这两个可以把请求体中的数据和用户在url中携带的数据都拿到

-
案例代码
pythonfrom rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailed from app01 import models class QueryParamsAuthentication(BaseAuthentication): def authenticate(self, request): token = request.query_params.get("token") if not token: return user_object = models.UserInfo.objects.filter(token=token).first() if user_object: return user_object, token def authenticate_header(self, request): return "token API" class MetaAuthentication(BaseAuthentication): def authenticate(self, request): token = request.META.get("HTTP_AUTHORIZATION") # 获取请求头中的 Authorization if not token: return user_object = models.UserInfo.objects.filter(token=token).first() if user_object: return user_object, token def authenticate_header(self, request): return "token API" class NoAuthentication(BaseAuthentication): def authenticate(self, request): raise AuthenticationFailed({"code": 10001, "msg": "认证失败"}) def authenticate_header(self, request): return "token API"pythonfrom rest_framework.response import Response from rest_framework.views import APIView from app01 import models import uuid class loginView(APIView): authentication_classes = [] def post(self, request): user = request.data.get("username") pwd = request.data.get("password") user_object = models.UserInfo.objects.get(username=user, password=pwd) if user_object: token = str(uuid.uuid4()) user_object.token = token user_object.save() return Response({"code": 0, "token": token}) return Response({"code": 1001, "msg": "用户名或密码错误"}) class userView(APIView): def get(self, request): return Response("userView") class orderView(APIView): def get(self, request): return Response("orderView")
drf(权限)
-
概述:

-
代码:
编写一个权限类
pythonfrom rest_framework.permissions import BasePermission from random import randint class MyPermissions(BasePermission): def has_permission(self, request, view): v = randint(1,3) if v == 2: return False return True全局应用
pythonREST_FRAMEWORK = { "UNAUTHENTICATED_USER": None, # ------------------------------------- "DEFAULT_PERMISSION_CLASSES": [ "ext.per.MyPermissions" ] }局部应用
pythonclass loginView(APIView): authentication_classes = [] permission_classes = []应用的场景和生效的场景和认证组件一样
自定义错误信息
-
默认情况下的错误信息

-
在定义权限类的时候添加message类变量
pythonfrom rest_framework.permissions import BasePermission from random import randint class MyPermissions(BasePermission): message = {"status": False, "msg": "无权访问"} def has_permission(self, request, view): v = randint(1,3) if v == 2: return False return True -
此时的错误信息

权限组件的源码流程
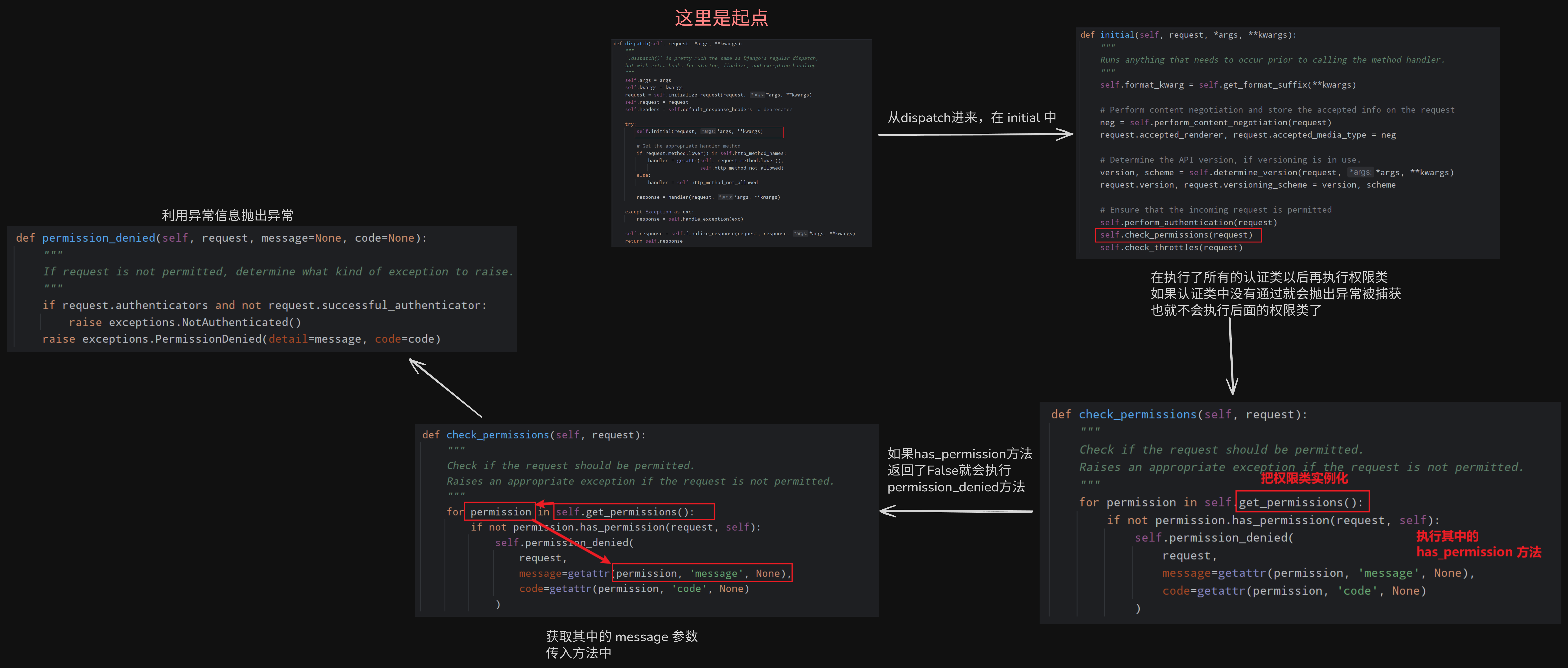
从源码也可以看出,当进行权限认证时
遇到一个报错了后面的就不会再执行了
当有一个返回了False就会执行permission_denied报错拦截
我们可以通过更改这个逻辑来实现不一样的效果:
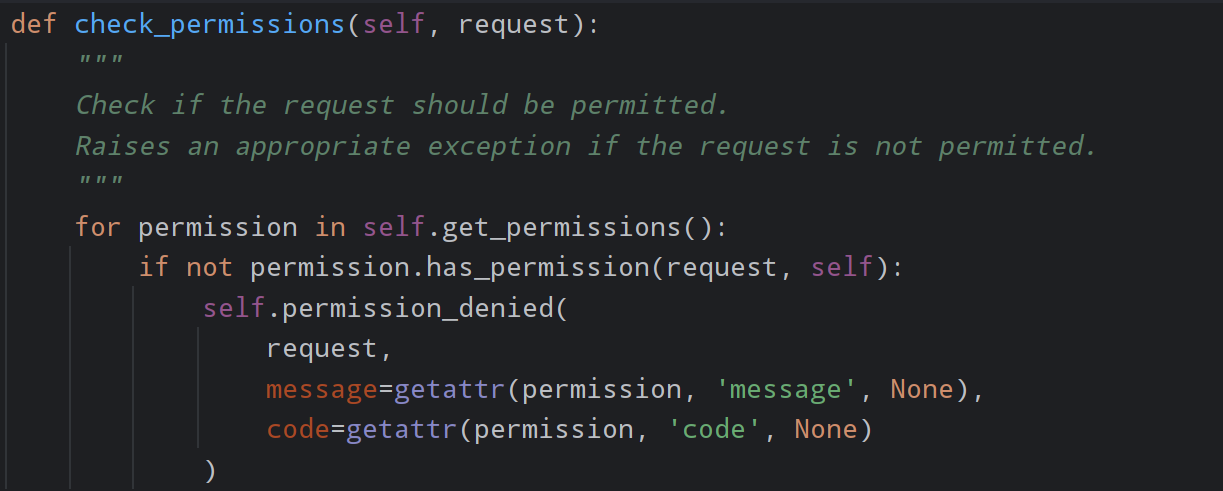
权限组件的拓展(更改逻辑)
在执行的过程中会优先在自己的方法里面寻找check_permissoins
如果自己的方法里面没有的话才会去父类中找
所以可以在自己的类里面定义一个check_permissoins方法
达到重写逻辑的目的
python
class orderView(APIView):
authentication_classes = []
permission_classes = [MyPermissions, MyPermissions1, MyPermissions2]
def check_permissions(self, request):
for permission in self.get_permissions():
if permission.has_permission(request, self):
return
else:
self.permission_denied(
request,
message=getattr(permission, 'message', None),
code=getattr(permission, 'code', None)
)在类里面添加方法修改
改为只要有一个返回为True就通过验证
都返回False才会报错
-
错误信息也可以自定义
pythondef check_permissions(self, request): no_permissions_list = [] for permission in self.get_permissions(): if permission.has_permission(request, self): return else: no_permissions_list.append(permission) else: self.permission_denied( request, message=getattr(no_permissions_list[0], 'message', None), code=getattr(no_permissions_list[0], 'code', None) ) -
甚至可以自己写
pythonmessage = {"code": 1000, "message": "这是自己写的错误信息"}
-
如果想对多个视图函数使用的话可以编写一个类,让其他的类继承他,这样就可以实现多个类共用
pythonclass NbAPIView(APIView): def check_permissions(self, request): no_permissions_list = [] for permission in self.get_permissions(): if permission.has_permission(request, self): return else: no_permissions_list.append(permission) else: self.permission_denied( request, message=getattr(no_permissions_list[0], 'message', None), code=getattr(no_permissions_list[0], 'code', None) )让其他的类继承NbAPIView
案例:权限处理
-
认证处理
pythonfrom rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailed from app01 import models class QueryParamsAuthentication(BaseAuthentication): def authenticate(self, request): token = request.query_params.get("token") if not token: return user_object = models.UserInfo.objects.filter(token=token).first() if user_object: return user_object, token def authenticate_header(self, request): return "token API" class MetaAuthentication(BaseAuthentication): def authenticate(self, request): token = request.META.get("HTTP_AUTHORIZATION") # 获取请求头中的 Authorization if not token: return user_object = models.UserInfo.objects.filter(token=token).first() if user_object: return user_object, token def authenticate_header(self, request): return "token API" class NoAuthentication(BaseAuthentication): def authenticate(self, request): raise AuthenticationFailed({"code": 10001, "msg": "认证失败"}) def authenticate_header(self, request): return "token API" -
权限处理
pythonfrom rest_framework.permissions import BasePermission from random import randint class UserPermissions(BasePermission): message = {"status": False, "msg": "无权访问"} def has_permission(self, request, view): if request.user.role == 3: return True return False class ManagePermissions1(BasePermission): message = {"status": False, "msg": "无权访问"} def has_permission(self, request, view): if request.user.role == 2: return True return False class BossPermissions2(BasePermission): message = {"status": False, "msg": "无权访问"} def has_permission(self, request, view): if request.user.role == 1: return True return False -
视图
pythonfrom ext.view import NbAPIView # 上文中提到过 class userView(NbAPIView): permission_classes = [ManagePermissions1, BossPermissions2] def get(self, request): print("访问成功,只有管理员或老板可以访问") return Response("userView") class orderView(NbAPIView): permission_classes = [UserPermissions, ManagePermissions1, BossPermissions2] def get(self, request): print("访问成功,都可以访问") return Response("orderView")
这样就可以实现识别用户的权限,并且根据权限拦截访问
-
多个权限组件与多个认证组件的区分
组件类型 进行下一个判断的条件 退出判断的条件 逻辑 认证组件 返回None 返回user和auth或者raise AuthenticationFailed 接收到值或者报错就退出校验 权限组件(默认逻辑) 返回True 返回False 默认全部为True才通过,返回一个False即结束 权限组件(修改为或逻辑) 返回False 返回True 返回False即说明不符合这个权限,进行下一个权限验证,返回True说明权限校验成功,退出验证 -
或逻辑权限校验
pythonfrom rest_framework.views import APIView class NbAPIView(APIView): def check_permissions(self, request): no_permissions_list = [] for permission in self.get_permissions(): if permission.has_permission(request, self): return else: no_permissions_list.append(permission) else: self.permission_denied( request, message=getattr(no_permissions_list[0], 'message', None), code=getattr(no_permissions_list[0], 'code', None) )
-
补充
django中的中间件执行时机在认证组件,权限组件之前
drf(限流)
快速上手
-
限制访问的次数频率(一分钟多少次?)
-
使用示例:
先安装模块
bashpip install django-redispythonfrom rest_framework.throttling import SimpleRateThrottle from django.core.cache import cache as default_cache class MyThrottle(SimpleRateThrottle): scope = "XXX" # 配置节流器的名称 THROTTLE_RATES = {"XXX": "5/m"} # 键是节流器名称 值是限制的频率 cache = default_cache # 配置redis作为cache将访问记录缓存起来 def get_cache_key(self, request, view): if request.user: # 如果是已经认证的用户 ident = request.user.pk # 就把id设置为主键 else: ident = self.get_ident(request) # 没有认证用户就使用ip地址 return self.cache_format % {'scope': self.scope, 'ident': ident}from django.core.cache import cache as default_cache这里引入的cache默认读取的是settings文件中CACHES中的 default ,如果没没有配置default,这个cache默认是用不了的
python# 导入组件 class loginView(APIView): throttle_classes = [MyThrottle, ] # 编写 throttle_classes 应用类-
配置redis作为默认缓存(settings.py)
pythonCACHES = { # 默认缓存 "default": { "BACKEND": "django_redis.cache.RedisCache", # 项目上线时,需要调整这里的路径 # "LOCATION": "redis://:密码@IP地址:端口/库编号", "LOCATION": "redis://:@192.168.207.100:6379/0", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 10} } } }配置了以后在redis中会记录访问的频率
前五次正常访问
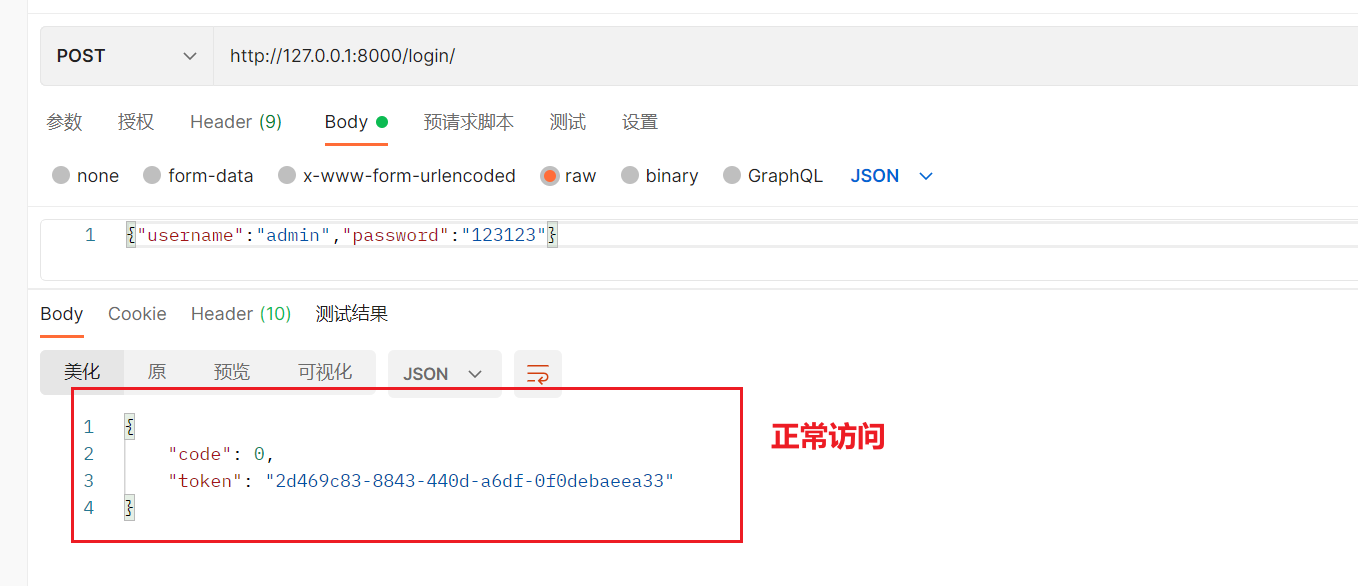
超过频率后
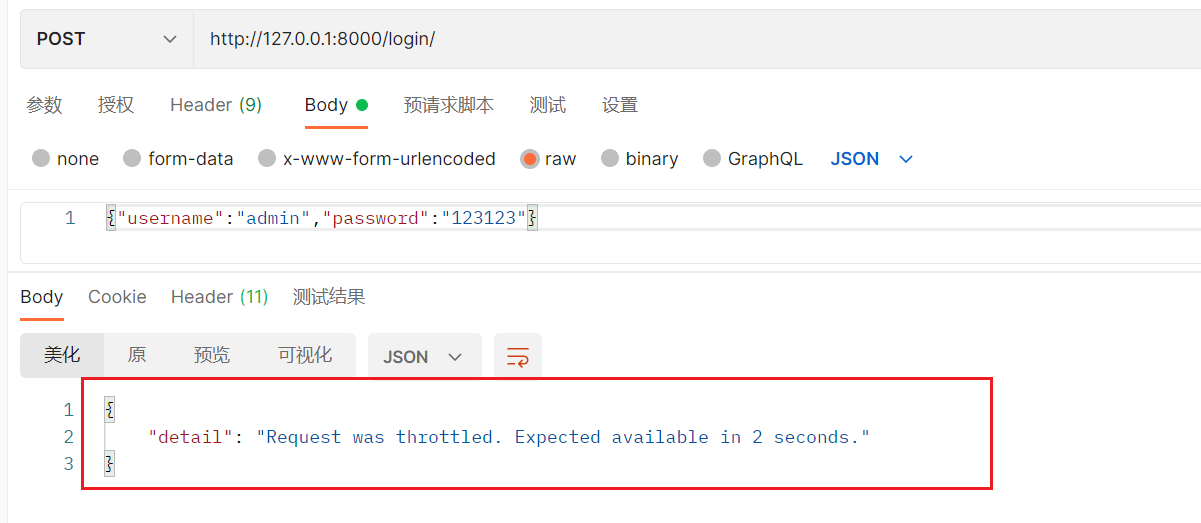
提示超过频率限制
-
源码和具体实现
-
获取时间间隔、访问次数
图片过大平台限制无法上传
此时得到
self.num_requests和self.duration
-
源码执行流程
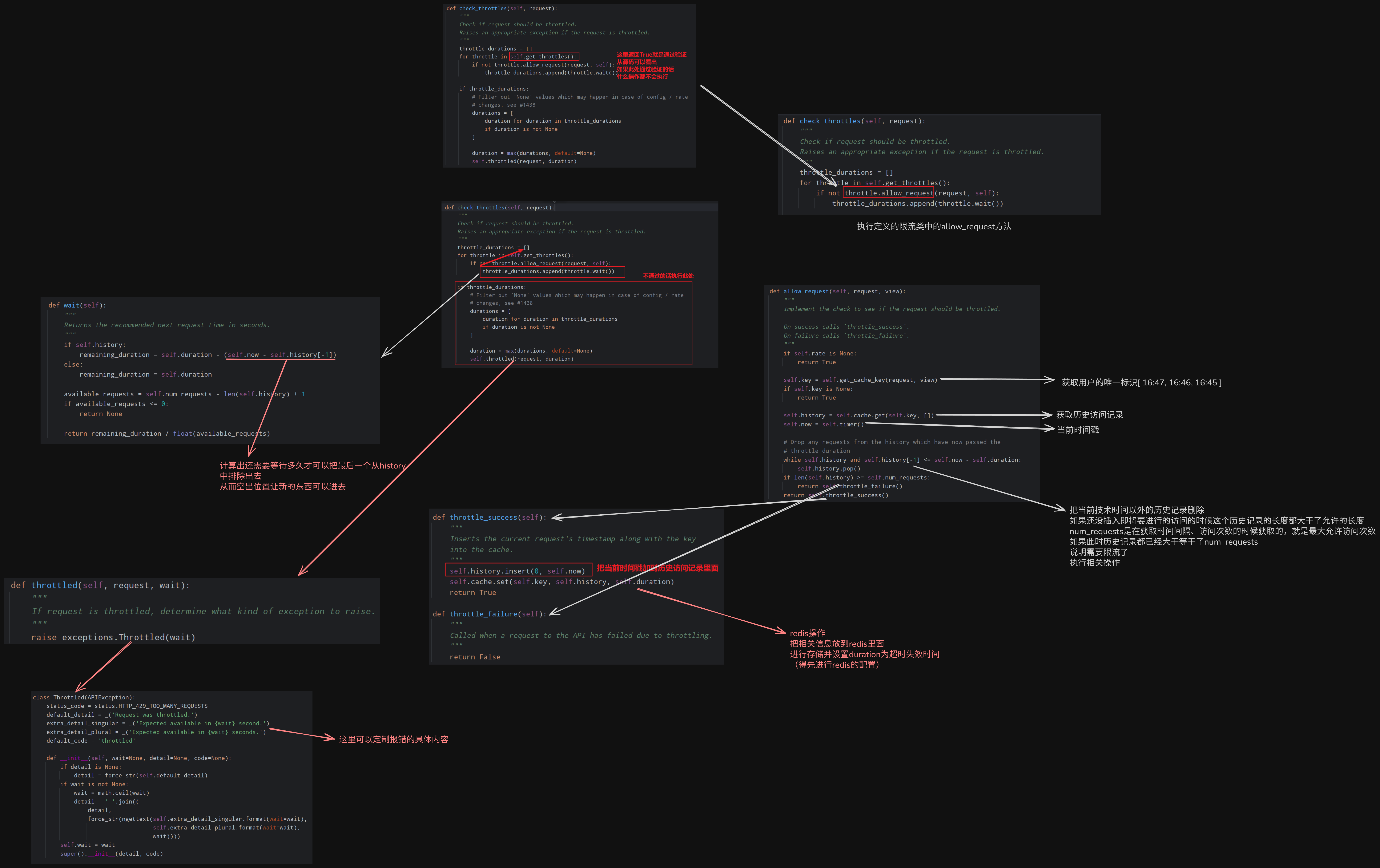
案例
python
from rest_framework.throttling import SimpleRateThrottle
from django.core.cache import cache as default_cache
from rest_framework.exceptions import Throttled
class IPThrottle(SimpleRateThrottle):
scope = "ip"
cache = default_cache
def get_cache_key(self, request, view):
ident = self.get_ident(request)
return self.cache_format % {'scope': self.scope, 'ident': ident}
class UserThrottle(SimpleRateThrottle):
scope = "user"
cache = default_cache
def get_cache_key(self, request, view):
ident = request.user.pk
return self.cache_format % {'scope': self.scope, 'ident': ident}
def wait(self):
"""
重写wait方法,返回自定义信息
"""
if self.history:
remaining_duration = self.duration - (self.now - self.history[-1])
else:
remaining_duration = self.duration
raise Throttled(
detail={
"message": "请求过于频繁,请稍后再试",
"retry_after": int(remaining_duration),
"code": 429
}
)拓展(自定义限流类抛出的异常信息)
在分析源码执行流程时可以看出请求被限制时会进入wait方法
如果想要自定义异常信息的话只需要重写wait方法即可
python
class UserThrottle(SimpleRateThrottle):
scope = "user"
cache = default_cache
def get_cache_key(self, request, view):
ident = request.user.pk
return self.cache_format % {'scope': self.scope, 'ident': ident}
# --------------------- 在throttle类里面重写wait方法
def wait(self):
"""
重写wait方法,返回自定义信息
"""
if self.history:
remaining_duration = self.duration - (self.now - self.history[-1])
else:
remaining_duration = self.duration
raise Throttled(
detail={
"message": "请求过于频繁,请稍后再试",
"retry_after": int(remaining_duration),
"code": 429
}
)关注源码的流程,只有当请求收到限制的时候,也就是超过了限流类允许的最大次数时,wait方法才会被调用,所以当需要自定义抛出的异常信息时,只需要在wait方法里面抛出自定义的错误信息就可以了
drf(版本)
参数传递
方式一(基于GET参数)
python
from rest_framework.versioning import QueryParameterVersioning
class homeView(APIView):
versioning_class = QueryParameterVersioning
def get(self, request):
# http://127.0.0.1:8000/home/?version=v2
print(request.version) # v2
return Response({"code": 0, "message": "成功"})此时会自动的读取query请求头中携带的版本信息
比如此时
?name=vhsj&age=20&version=v2此时会自动读取请求头中的version信息
并赋值给request.version

从源码中可以看出,获取的请求头中的名字取决于配置文件中的VERSION_PARAM
可以通过配置这个信息来自定义获取的参数名
python
REST_FRAMEWORK = {
"UNAUTHENTICATED_USER": None,
"VERSION_PARAM": "v",
# ----------- 如果获取不到的话就会获取DEFAULT_VERSION
"DEFAULT_VERSION": "v",
# ----------- 填写已有的版本号信息 如果用户发送了不存在的版本号则报错
"ALLOWED_VERSIONS": ['v1']
}此时就可以使用v来传递版本参数
最佳实践:
使用默认的version来传递参数名称
反向生成url
首先分析源码流程
图片过大平台限制无法上传
了解源码流程以后就可以执行以下操作反向生成url
python
from django.urls import path
from api import views
urlpatterns = [
path("home/", views.homeView.as_view(), name="hh")
]
python
class homeView(APIView):
versioning_class = QueryParameterVersioning
def get(self, request):
# http://127.0.0.1:8000/home/?version=v1
print(request.version) # v1
url = request.versioning_scheme.reverse("hh", request=request)
print("反向生成的url:", url)
return Response({"code": 0, "message": "成功"})
注意此时反向生成的url是只会携带你的版本号参数,如果有其他参数他不会自动携带
方式二(基于路由URL)
python
from django.urls import path
from api import views
urlpatterns = [
path("api/<str:version>/home/", views.homeView.as_view(), name="hh")
]
python
from rest_framework.versioning import QueryParameterVersioning, URLPathVersioning
class homeView(APIView):
versioning_class = URLPathVersioning
def get(self, request, *args, **kwargs):
print(request.version)
return Response({"code": 0, "message": "成功"})
"""
class homeView(APIView):
versioning_class = URLPathVersioning
def get(self, request, version):
print(version) 直接获取
return Response({"code": 0, "message": "成功"})
"""方式三(Accept请求头)
python
from django.urls import path
from api import views
urlpatterns = [
path("api/home/", views.homeView.as_view(), name="hh")
]
python
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.versioning import AcceptHeaderVersioning
class homeView(APIView):
versioning_class = AcceptHeaderVersioning
def get(self, request, *args, **kwargs):
print(request.version)
print(request.versioning_scheme.reverse("hh", request=request))
return Response({"code": 0, "message": "成功"})
这样也可以获取到版本信息,且同样可以反向生成URL
最佳实践
以上三种传递参数的方式
最常用的是方式二
其次是方式一
方式三几乎不使用
补充
为了方便可以这样写
python
REST_FRAMEWORK = {
"UNAUTHENTICATED_USER": None,
"DEFAULT_VERSIONING_CLASS": "rest_framework.versioning.URLPathVersioning"
}在定义类的时候就不用每次都写一遍版本信息的相关配置了
drf(解析器)
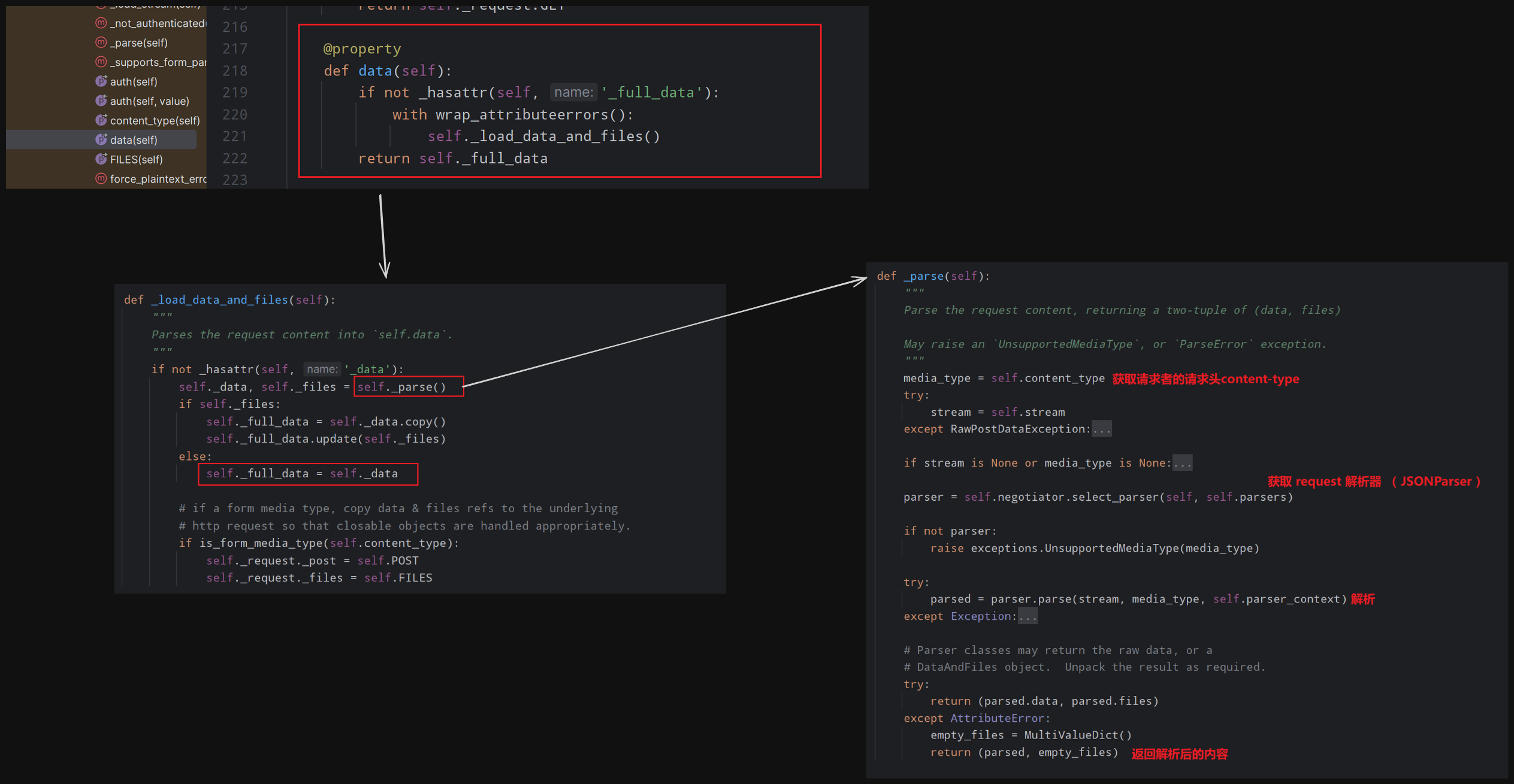
解析器:解析请求者发送过来的数据,根据请求头的类型匹配类,然后在类里面对不同的数据进行解析之后赋值给request.data
基本用法和流程
python
from rest_framework.parsers import JSONParser, FormParser
from rest_framework.negotiation import DefaultContentNegotiation
class homeView(APIView):
# 所有的解析器
parser_classes = [JSONParser, FormParser]
# 根据请求 匹配对应的解析器
content_negotiation_class = DefaultContentNegotiation
def get(self, request, *args, **kwargs):
print(request.version)
print(request.versioning_scheme.reverse("hh", request=request))
return Response({"code": 0, "message": "成功"})
def post(self, request, *args, **kwargs):
return Response("OK")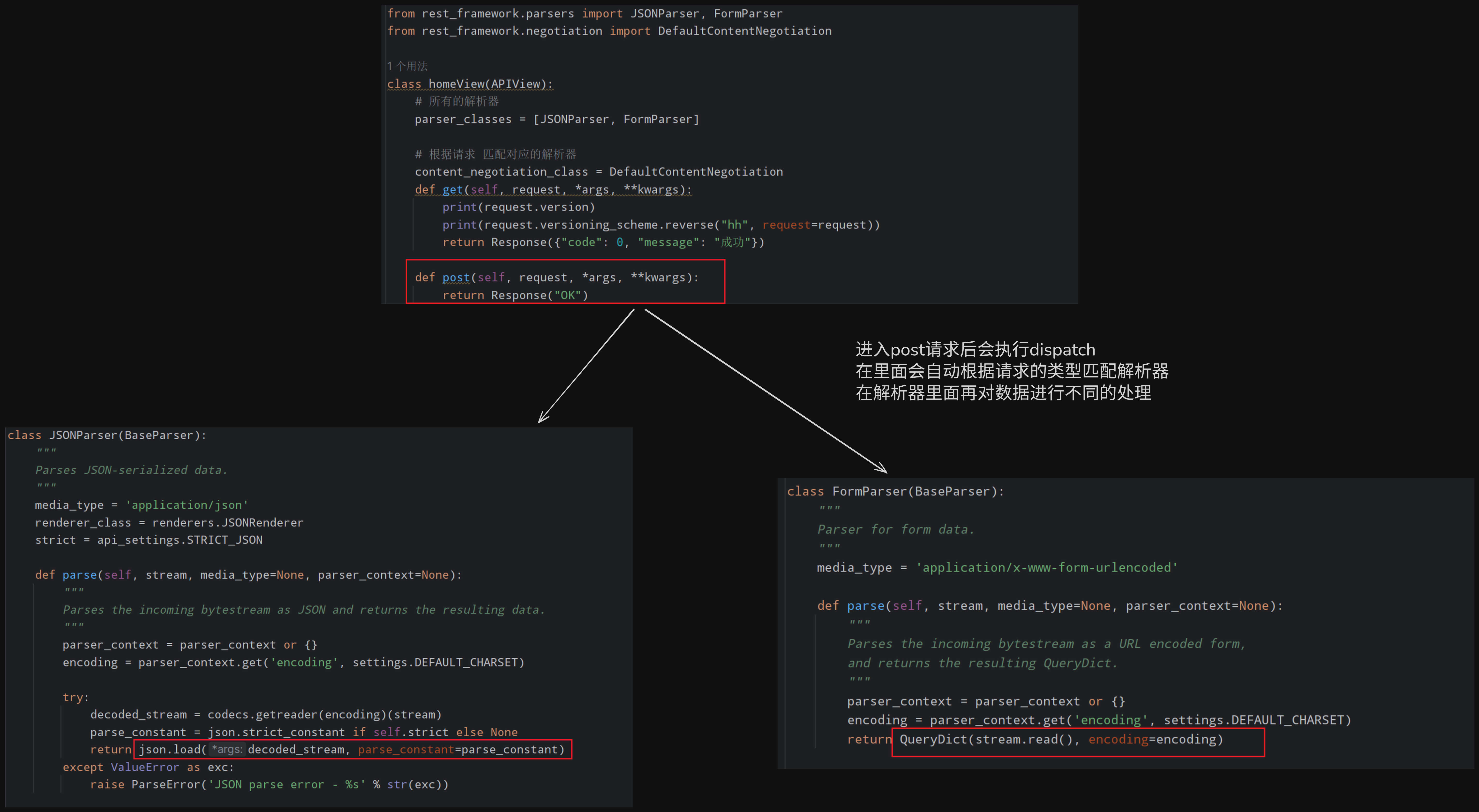
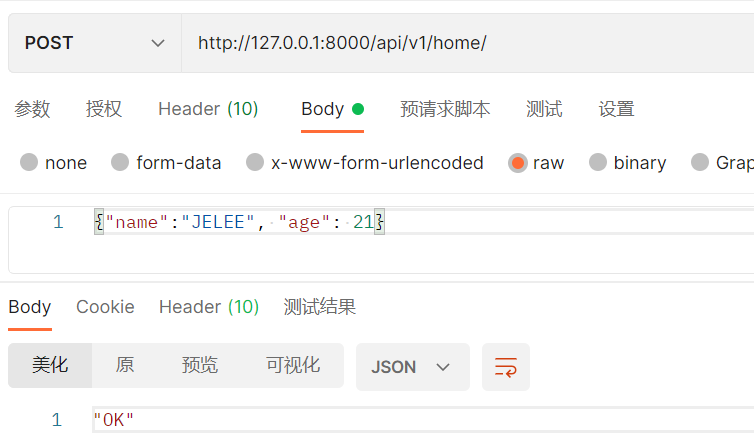
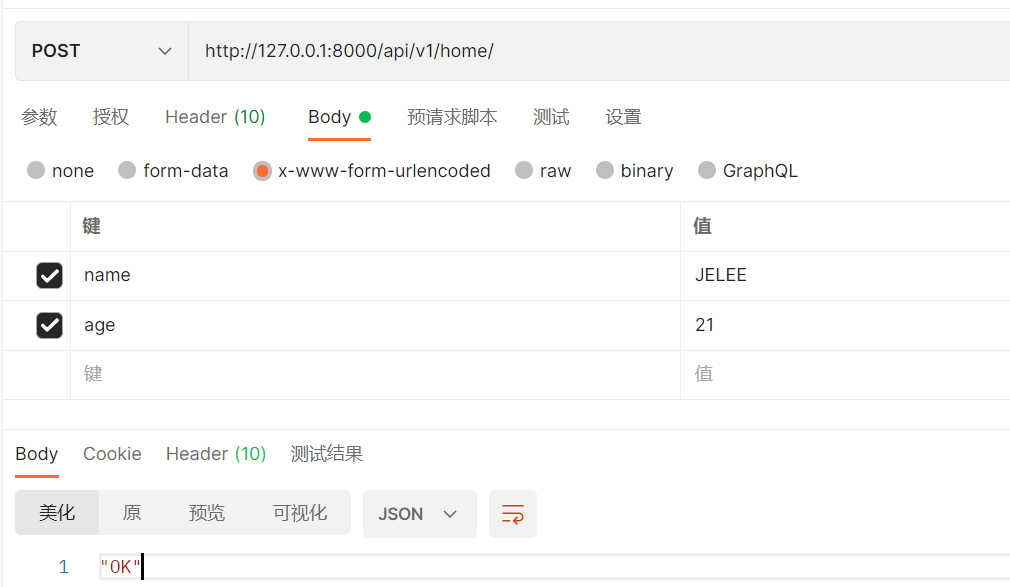
此时可以通过request.data打印获取到的数据
最佳实践:
使用JSONParser
因为JSON对于多层嵌套的格式易于处理
源码流程
在执行request.data时才会去触发解析器的动作
如果调用多次
pythonrequest.data request.data那只会解析一次
文件上传
-
FileUploadParser
此方法为手动写入文件且写入的路径是项目的根路径
pythonfrom rest_framework.parsers import FileUploadParser class homeView(APIView): parser_classes = [FileUploadParser] content_negotiation_class = DefaultContentNegotiation def post(self, request, *args, **kwargs): print(request.content_type) print(request.data) file_object = request.data.get('file') with open(file_object.name, mode='wb') as target_file_object: for chunk in file_object: target_file_object.write(chunk) file_object.close() return Response("OK")FileUploadParser 最佳实践
default_storage.save会将文件保存到media目录下
default_storage.url会返回文件的相对路径(相对根目录)
缺点:
此方法只能传输文件,不能同时传输其他类型的数据,导致了在传输时必须携带Header

(前端一般默认会携带)
在某些场景下会显得不方便
pythonfrom rest_framework.parsers import FileUploadParser from django.core.files.storage import default_storage class homeView(APIView): parser_classes = [FileUploadParser] content_negotiation_class = DefaultContentNegotiation def post(self, request, *args, **kwargs): file_object = request.data.get('file') file_name = default_storage.save(file_object.name, file_object) file_url = default_storage.url(file_name) print(file_url) return Response("OK") -
MultiPartParser 最佳实践
这种解析可以允许多种数据的携带
可以在上传文件的同时上传其他的东西
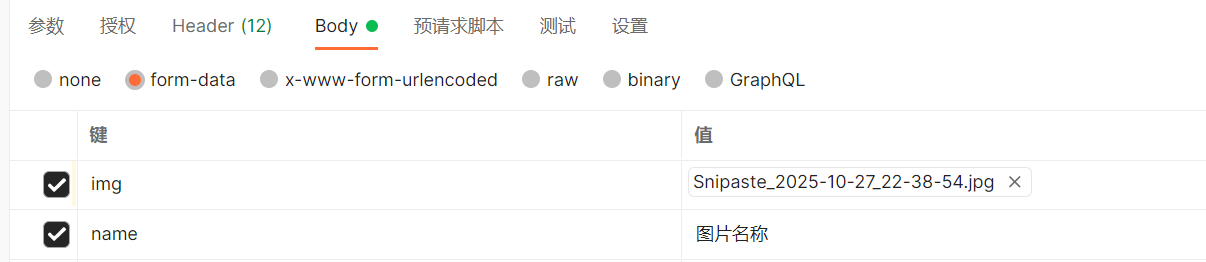 python
pythonfrom rest_framework.parsers import MultiPartParser from django.core.files.storage import default_storage class homeView(APIView): parser_classes = [MultiPartParser] content_negotiation_class = DefaultContentNegotiation def post(self, request, *args, **kwargs): print(request.data) file_object = request.data.get('file') default_storage.save(file_object.name, file_object) return Response("OK")
拓展(自定义解析器配置)
许多开发者一般都不写解析器的配置,drf内部有默认值
在学习阶段建议手动编写配置
python
class homeView(APIView):
# 所有的解析器
content_negotiation_class = DefaultContentNegotiation
def post(self, request, *args, **kwargs):
print(self.parser_classes)
return Response("OK")输出结果
bash
[<class 'rest_framework.parsers.JSONParser'>, <class 'rest_framework.parsers.FormParser'>, <class 'rest_framework.parsers.MultiPartParser'>]可以通过在settings.py中通过配置来修改这一项
python
REST_FRAMEWORK = {
"DEFAULT_PARSER_CLASSES": ['rest_framework.parsers.JSONParser']
}输出结果
bash
[<class 'rest_framework.parsers.JSONParser'>]drf(序列化)
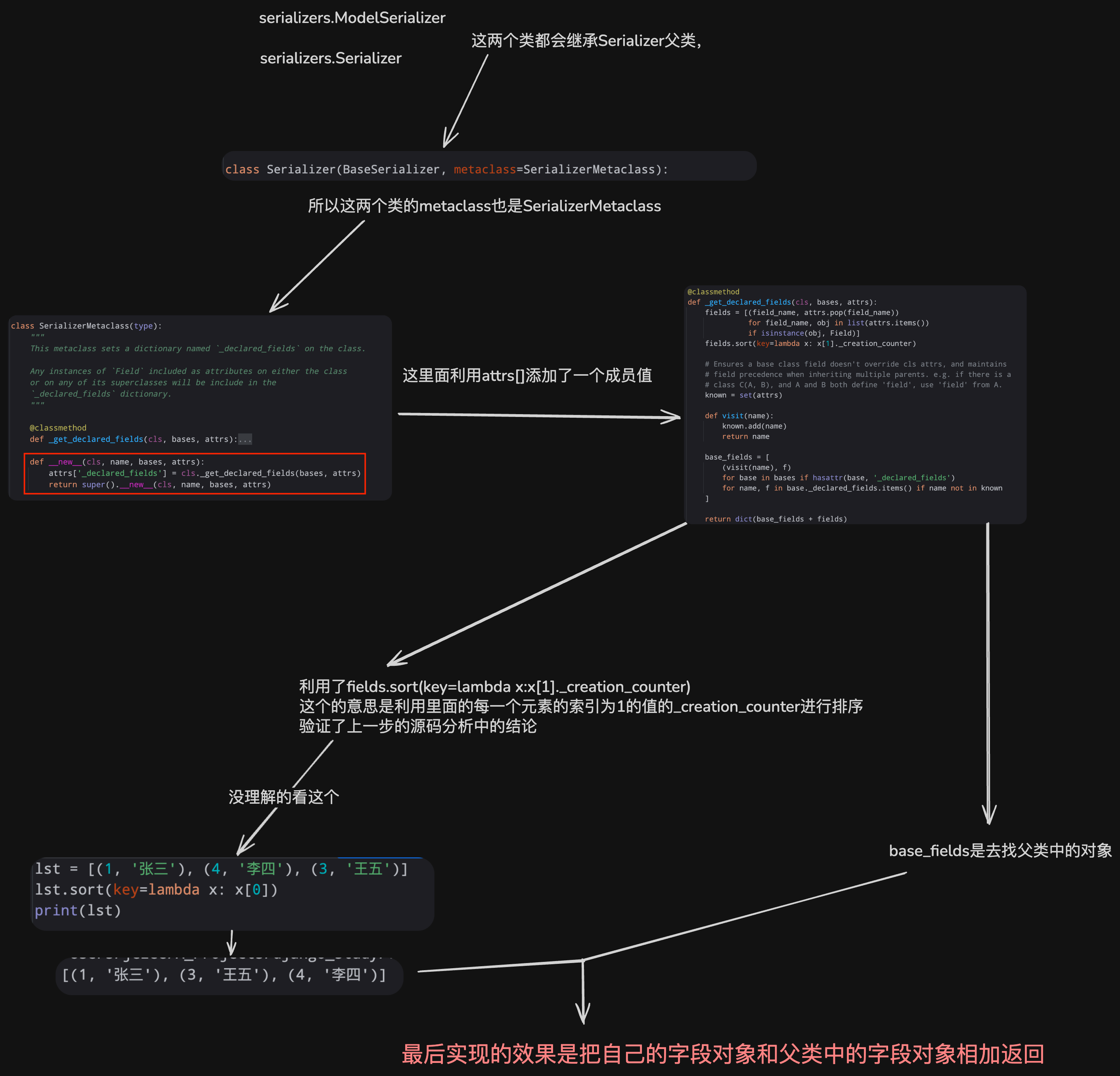
前置知识(元类)
以下两部分的创建类的效果完全一样
都是使用的type创建类,只是表现的形式不一样
python
# class Foo(object):
# v1 = 123
# def func(self):
# return 999
Foo = type("Foo", (object,), {"v1": 123, "func": lambda self: 999})
obj = Foo()
print(obj.v1)
print(obj.func())
type("Foo", (object,), {"v1": 123, "func": lambda self: 999})会去执行这个类里面的
__init__方法所有的类在执行
__init__方法之前会先执行一个__new__方法
__new__方法会先创建一个空值,然后再让__init__方法去这个空值里面去初始化数据所以创建类本质上是在
__new__方法中执行的
演示:
python
class MyType(type):
def __new__(cls, *args, **kwargs):
xx = super().__new__(cls, *args, **kwargs)
print(xx)
return xx
Foo = MyType("Foo", (object,), {"v1": 123, "func": lambda self: 999})
print(Foo)
print("--------------- 下面是测试类产生的")
obj = Foo()
print(obj.v1)
print(obj.func())-
new方法的应用
pythonclass MyType(type): def __new__(cls, name, bases, attrs): del attrs['v1'] xx = super().__new__(cls, name, bases, attrs) print(name, bases, attrs) return xx class Foo(object, metaclass=MyType): v1 = 123 def __init__(self): self.age = 20 def func(self): pass print(Foo.v1)可以在创建之前就把属性删除
注意此时删除的不能是init方法里面创建的属性
要在参数传递到super里面之前删除否则传递到super里面以后删除也没用了
可以删除属性东西同样也可以往里面添加东西
-
继承的子类也由父类的决定
pythonclass MyType(type): def __new__(cls, name, bases, attrs): xx = super().__new__(cls, name, bases, attrs) return xx class Base(object, metaclass=MyType): pass class Foo(Base): pass此时Foo也由MyType创建
类或父类中如果指定了metaclass则当前类和子类也由指定的metaclass创建
-
在类加载的时候可以通过元类对类进行一些操作
python# 利用attrs获取里面的数据 def __new__(cls, name, bases, attrs): for k, v in list(attrs.items()): if isinstance(v, int): del attrs[k]像这样的操作
基本使用(快速功能演示)
序列化的本质是把数据库中获取到的数据转换成JSON格式
并返回给用户, 已有的json.dumps()方法由于使用类型受限,只能转换原生的python中的数据类型
所以需要用到drf的序列化

这是用于测试的数据库表
python
class DepartSerializers(serializers.Serializer):
title = serializers.CharField()
count = serializers.IntegerField()
class DepartView(APIView):
def get(self, request):
depart_obj = models.Depart.objects.all().first()
ser = DepartSerializers(instance=depart_obj)
print(ser.data)
return Response("这是成功的消息")想要使用序列化首先要定义一个类
这个类里面的字段使用serializers.字段类型(定义时的数据类型)
这里面有哪些字段,后面的对象就可以获取到哪些字段
上面的演示代码会输出
bash{'title': '开发部', 'count': 10}
基本使用(支持QuerySet)
在上一节点中使用的depart_obj是一个字典类型的对象
在实际开发中我们遇到的不一定是这样简简单单的对象,可能是queryset类型的
python
class DepartSerializers(serializers.Serializer):
title = serializers.CharField()
count = serializers.IntegerField()
class DepartView(APIView):
def get(self, request):
queryset = models.Depart.objects.all()
ser = DepartSerializers(instance=queryset, many=True)
print(ser.data)
return Response(ser.data)通过指定many=True就可以让他支持queryset类型的数据

注意此处的名称类型需要对应
此时输出的内容:
bash
[{'title': '开发部', 'count': 10}, {'title': '运营部', 'count': 20}]基本使用(Model)
每次使用Serializer都需要把需要的字段都重新写一遍显得有点麻烦
我们可以使用ModelSerializer来简化写法
就像这样:
python
from rest_framework.views import APIView
from rest_framework.response import Response
from api.auth import MyAuthentication
from api import models
from rest_framework import serializers
class DepartSerializers(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = "__all__"
class DepartView(APIView):
def get(self, request):
queryset = models.Depart.objects.all()
ser = DepartSerializers(instance=queryset, many=True)
print(ser.data)
return Response(ser.data)输出示例:
bash
[{'id': 1, 'title': '开发部', 'order': 1, 'count': 10}, {'id': 2, 'title': '运营部', 'order': 2, 'count': 20}]基本使用(source和时间)
首先创建一个模型
pythonclass UserInfo(models.Model): name = models.CharField(verbose_name="姓名", max_length=32) age = models.IntegerField(verbose_name="年龄") gender = models.SmallIntegerField(verbose_name="性别", choices=((1, '男'), (2, '女'))) depart = models.ForeignKey(verbose_name="部门", to="Depart", on_delete=models.CASCADE) ctime = models.DateTimeField(verbose_name="时间", auto_now_add=True)插入两条数据
现在
pythonclass UserSerializers(serializers.ModelSerializer): class Meta: model = models.UserInfo fields = "__all__" class UserView(APIView): def get(self, request): models.UserInfo.objects.all().update(ctime=datetime.datetime.now()) queryset = models.UserInfo.objects.all() ser = UserSerializers(instance=queryset, many=True) return Response(ser.data)发送请求后得到的返回的数据是这样的:
bash[ { "id": 1, "name": "a", "age": 21, "gender": 1, "ctime": "2026-03-07T07:08:12.571546Z", "depart": 1 }, { "id": 2, "name": "b", "age": 21, "gender": 2, "ctime": "2026-03-07T07:08:12.571546Z", "depart": 2 } ]

gender字段如何显示名称
利用source指定,利用Django中的知识
python
class UserSerializers(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender"]指定
source="get_gender_display"注意此时获取到的"男"/"女"是CharField,所以需要改成CharField
如果说同字段类型重名,则会报错,比如如果我model中定义的是CharField,我这里再自定义一个CharFIeld,那就会报错,不同类型重名则会覆盖
bash
[
{
"name": "a",
"age": 21,
"gender": "男"
},
{
"name": "b",
"age": 21,
"gender": "女"
}
]depart外键怎么显示名称
python
class UserSerializers(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart"]指定
source="depart.title"本质上:
pythonobj.get_gender_display() obj.depart.title
ctime时间字段怎么格式化
python
class UserSerializers(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title")
ctime = serializers.DateTimeField(format="%Y年%m月%d日")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "ctime"]利用
format=""将时间格式格式化
输出:
bash[ { "name": "a", "age": 21, "gender": "男", "depart": "开发部", "ctime": "2026年03月07日" }, { "name": "b", "age": 21, "gender": "女", "depart": "运营部", "ctime": "2026年03月07日" } ]
自定义字段内容
python
class UserSerializers(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title")
ctime = serializers.DateTimeField(format="%Y年%m月%d日")
xxx = serializers.SerializerMethodField()
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "ctime", "xxx"]
def get_xxx(self, obj):
return f'{obj.name}-{obj.age}-{obj.gender}'自定义字段名称是
xxx的话方法就是get_xxx方法里面的obj就是当前的字段对象
示例返回:
bash[ { "name": "a", "age": 21, "gender": "男", "depart": "开发部", "ctime": "2026年03月07日", "xxx": "a-21-1" }, { "name": "b", "age": 21, "gender": "女", "depart": "运营部", "ctime": "2026年03月07日", "xxx": "b-21-2" } ]
基本使用(如何处理ManyToManyField类型)
方法一
示例model:
python
class Depart(models.Model):
title = models.CharField(verbose_name="部门", max_length=64)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
class UserInfo(models.Model):
name = models.CharField(verbose_name="姓名", max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(verbose_name="性别", choices=((1, '男'), (2, '女')))
depart = models.ForeignKey(verbose_name="部门", to="Depart", on_delete=models.CASCADE)
ctime = models.DateTimeField(verbose_name="时间", auto_now_add=True)
tags = models.ManyToManyField(verbose_name="标签", to="Tag")
class Tag(models.Model):
caption = models.CharField(verbose_name="标签", max_length=32)此时由于UserInfo中返回的tags字段是一个queryset类型的数据,无法利用source解决
可以使用自定义方法处理
处理实例:
python
class UserSerializers(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title")
ctime = serializers.DateTimeField(format="%Y年%m月%d日")
tags = serializers.SerializerMethodField()
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "ctime", "tags"]
def get_tags(self, obj):
result = [{"id": item.id, "tag": item.caption} for item in obj.tags.all()]
return result方法二(最佳实践)
python
class D1(serializers.ModelSerializer):
class Meta:
model = models.Depart()
fields = "__all__"
class D2(serializers.ModelSerializer):
class Meta:
model = models.Tag()
fields = "__all__"
class UserSerializers(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
depart = D1()
ctime = serializers.DateTimeField(format="%Y年%m月%d日")
tags = D2(many=True)
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "ctime", "tags"]利用类的嵌套
在新创建的类里面对于这种类型的数据添加
many=True实现获取到所有对应的数据返回示例:
bash[ { "name": "a", "age": 21, "gender": "男", "depart": { "id": 1, "title": "开发部", "order": 1, "count": 10 }, "ctime": "2026年03月08日", "tags": [ { "id": 1, "caption": "暖男" }, { "id": 2, "caption": "渣男" } ] }, ... ]注意上述的D1和D2类里面的字段也可以自定义,和普通的类里面自定义的方法一致
小技巧
对于两个类里面都需要使用同一个字段的情况,可以使用继承
示例:
python
class Base(serializers.ModelSerializer):
xx = ...
class D(serializers.ModelSerializer, Base):
...这样在D类里面就自带了xx这个字段,就不用再自己重新写了
源码解析
创建字段对象
图片过大平台限制无法上传
创建类
上一步中创建了字段了,按照执行的流程,这一步到了创建类
序列化过程
数据校验
基本校验
写法一(最佳实践)
python
class DepartSerializers(serializers.Serializer):
username = serializers.CharField(required=True)
password = serializers.CharField(required=True)
class DepartView(APIView):
def post(self, request, *args, **kwargs):
# 1. 获取原始数据
# print(request.data)
# 2. 校验
ser = DepartSerializers(data=request.data)
if ser.is_valid():
print(ser.validated_data)
else:
print(ser.errors)
return Response("...")写法二
python
class DepartSerializers(serializers.Serializer):
username = serializers.CharField(required=True)
password = serializers.CharField(required=True)
class DepartView(APIView):
def post(self, request, *args, **kwargs):
ser = DepartSerializers(data=request.data)
ser.is_valid(raise_exception=True)
return Response("成功")第二种写法关键在于传递了
raise_exception=True这样的话如果校验成功他就会继续往下执行
如果校验失败就会抛出异常,并且让异常信息返回,drf会自动捕获这个异常,不会中断程序
演示:
校验成功:
bash"成功"校验失败:
bash{ "password": [ "该字段是必填项。" ] }这种写法的坏处在于抛出的异常信息不方便控制
内置校验和正则校验
内置校验
python
class DepartSerializers(serializers.Serializer):
title = serializers.CharField(required=True, max_length=20, min_length=6)
order = serializers.IntegerField(required=False, max_value=100, min_value=10)
level = serializers.ChoiceField(choices=[("1", "高级"), (2, "中级")])
class DepartView(APIView):
def post(self, request, *args, **kwargs):
# 1. 获取原始数据
# print(request.data)
# 2. 校验
ser = DepartSerializers(data=request.data)
if ser.is_valid():
print(ser.validated_data)
else:
print(ser.errors)
return Response("...")在创建类的时候添加校验规则
上面的level里面定义的choices中数字的类型程序会自动帮我们处理,实际开发中建议保持规则
比如在上述实例中:
输入
bash{"title": "afsdfsd", "order": "11", "level": 1}程序打印
bash{'title': 'afsdfsd', 'order': 11, 'level': '1'}会自动处理类型
正则校验
上述中有一种特殊的
python
class DepartSerializers(serializers.Serializer):
email = serializers.EmailField()这种写法几乎等价于:
python
from django.core.validators import EmailValidator
class DepartSerializers(serializers.Serializer):
email = serializers.CharField(validators=[EmailValidator(message="邮箱格式错误")])邮箱可以用内置的校验规则,也可以自己编写校验规则
python
from django.core.validators import RegexValidator
class DepartSerializers(serializers.Serializer):
email = serializers.CharField(validators=[RegexValidator(r'\d+', message="格式错误")])钩子校验
对于Serializer
在定义字段的时候,可以在下面定义
validate_字段名的钩子方法,会进行相应的校验
python
from django.core.validators import RegexValidator
from rest_framework import exceptions
class DepartSerializers(serializers.Serializer):
title = serializers.CharField(required=True, max_length=20, min_length=6)
order = serializers.IntegerField(required=False, max_value=100, min_value=10)
level = serializers.ChoiceField(choices=[("1", "高级"), (2, "中级")])
email = serializers.CharField(validators=[RegexValidator(r'\d+', message="邮箱格式错误")])
def validate_email(self, value):
if len(value) > 6:
raise exceptions.ValidationError("钩子校验失败")
return valuevalue是传进去的旧值,返回的值是校验后的,如果在最后修改了返回的值,他会反映到validated_data里面
上面说的是局部的字段的钩子,还有全局的钩子,全局的钩子会在所有局部的钩子校验通过后执行
python
from django.core.validators import RegexValidator
from rest_framework import exceptions
class DepartSerializers(serializers.Serializer):
title = serializers.CharField(required=True, max_length=20, min_length=6)
order = serializers.IntegerField(required=False, max_value=100, min_value=10)
level = serializers.ChoiceField(choices=[("1", "高级"), (2, "中级")])
email = serializers.CharField(validators=[RegexValidator(r'\d+', message="邮箱格式错误")])
def validate_email(self, value):
if len(value) > 6:
raise exceptions.ValidationError("钩子校验失败")
return value
def validate(self, attrs):
print(attrs)
return attrs # 在这里面同样可以像上面一样抛出异常在这里面和Django一样,attrs和validated_data名字不同但是所指向的内存地址是相同的,在执行完了所有的校验方法后,attrs会直接引用到validated_data
小拓展(异常字段名)
如果抛出了异常,全局的钩子的异常和局部的钩子的异常的信息不一样
bash
{'non_field_errors': [ErrorDetail(string='全局钩子校验失败', code='invalid')]}
bash
{'email': [ErrorDetail(string='钩子校验失败', code='invalid')]}一个是字段名,一个是non_field_errors
后者可以在配置中修改(settings.py)
python
REST_FRAMEWORK = {
"NON_FIELD_ERRORS_KEY": "ALL_ERROR"
}此时:
bash
{'ALL_ERROR': [ErrorDetail(string='全局钩子校验失败', code='invalid')]}一般不用
对于ModelSerializer
python
class DepartModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = ["title", "order", "count"]
extra_kwargs = {
"title": {"max_length": 5, "min_length": 1},
"order": {"min_value": 5},
# "count": {"validators": [RegexValidator(r"\d+", message="格式错误")]},
}这里面同样可以添加钩子方法,主要区别在于校验的参数需要通过字典的形式放进去
数据存储(普通字段)
对于Serializer
可以把数据打散放进去
python
ser = DepartSerializer(data=request.data)
ser.validated_data
models.Depart.objects.create(**ser.validated_data)对于ModelSerializer
可以直接调用save方法
python
ser = DepartModelSerializer(data=request.data)
ser.validated_data
ser.save()调用save方法直接存储会面临两个小问题
问题一:
如果数据库中有三个字段,但是用户只传了两个字段
就需要通过save方法传参自定义字段
ser.save(count=100)像这样问题二:
如果数据库中只有三个字段,但是用户传了四个字段
就需要在最后删除字段
ser.validated_data.pop('more')像这样,在保存的时候就不会提交多余的字段
数据存储(ForeignKey和ManyToManyField)
对于ForeignKey,直接传入对应的关联的id即可,如果传入的id不存在,会报错,存在则自动创建
bash
{'depart': [ErrorDetail(string='无效主键 "10" - 对象不存在。', code='does_not_exist')]}如果有更多的校验规则,可以通过添加钩子函数来完成,此时的钩子函数里面的value是depart中的一个对象
对于ManyToManyField,传入一个列表,列表里面是需要关联的表中的id即可
bash
{"name": "test1", "age": "21", "gender": "1", "depart": "1", "tags": [1, 2]}像这样传入,会自动关联相关的信息以及映射关系
如果添加了钩子方法,钩子方法里面的value是一个列表,列表里面是符合规则的对象
拓展(ListField字段)
如果对于ManyToManyField存储希望进行自定义,那接受数据类型的时候可以选择serializers.ListField()
示例:
python
class UsSerializer(serializers.ModelSerializer):
tags = serializers.ListField()
class Meta:
model = models.UserInfo
fields = ['name', 'age', 'gender', 'depart', 'tags']
def validate_tags(self, value):
queryset = models.Tag.objects.filter(id__in=value)
print(queryset)
return queryset像这样也可以和之前一样实现功能,还可以在里面加入自己想要自定义的内容
唯一的区别是原生的是传递的list类型的,现在传递的是QuerySet类型的,效果一样
校验的同时进行序列化
python
class DpModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = "__all__"
class Dp2ModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = ["id", "title", "order"]
class DpView(APIView):
def post(self, request, *args, **kwargs):
ser = DpModelSerializer(data=request.data)
if ser.is_valid():
instance = ser.save()
xx = Dp2ModelSerializer(instance=instance)
return Response(xx.data)
else:
print(ser.errors)
return Response("...")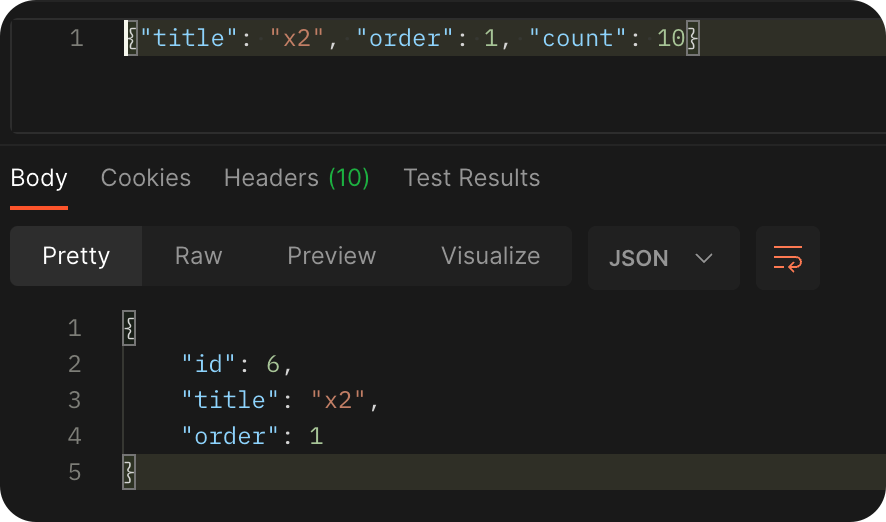
从而拿到返回的数据,也可以不单独写一个Serializer,共用一个Serializer,只不过这样的话返回的东西就不可以自定制了,显得很局限,但是每次都写两个类就显得很麻烦,此时就可以使用两个参数来控制
python
class DpModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = ["id", "order", "title", "count"]
extra_kwargs = {
"id": {"read_only": True},
"count": {"write_only": True}
}
read_only看字面意思就是只读的,用这里的场景来解释就是只能在序列化(读取查看)的时候使用,写的时候不能写(此处的原因是因为他是自动生成的)
write_only看字面意思就是只写的,用这里的场景来解释的话就是只能在校验(写入)的时候使用,读的时候不能读
实际使用场景:
给用户返回性别信息时返回性别的信息而不是返回数字
python
class UserModelSerializer(serializers.ModelSerializer):
gender_info = serializers.CharField(source="get_gender_display", read_only=True)
class Meta:
model = models.UserInfo
fields = ["id", "name", "age", "gender", "gender_info"]
extra_kwargs = {
"id": {"read_only": True},
"gender": {"write_only": True}
}
class UserView(APIView):
def post(self, request, *args, **kwargs):
ser = UserModelSerializer(data=request.data)
if ser.is_valid():
instance = ser.save(depart_id=1)
xx = UserModelSerializer(instance=instance)
return Response(xx.data)
else:
print(ser.errors)
return Response("...")还可以这样实现:
python
class UserModelSerializer(serializers.ModelSerializer):
gender_info = serializers.SerializerMethodField()
class Meta:
model = models.UserInfo
fields = ["id", "name", "age", "gender", "gender_info"]
extra_kwargs = {
"id": {"read_only": True},
"gender": {"write_only": True}
}
def get_gender_info(self, obj):
return obj.get_gender_display()对于外键类型的可以通过嵌套实现数据的显示,但是如果要让名字的对应关系不出问题可以使用source参数
python
class UserModelSerializer(serializers.ModelSerializer):
gender_info = serializers.SerializerMethodField()
v1 = P1Serializer(read_only=True, source="depart")
class Meta:
model = models.UserInfo
fields = ["id", "name", "age", "gender", "gender_info", "v1"]
extra_kwargs = {
"id": {"read_only": True},
"gender": {"write_only": True}
}
def get_gender_info(self, obj):
return obj.get_gender_display()注意
当只写了一个类的时候,就可以不这样写了
pythonclass UserView(APIView): def post(self, request, *args, **kwargs): ser = UserModelSerializer(data=request.data) if ser.is_valid(): instance = ser.save(depart_id=1) xx = UserModelSerializer(instance=instance) return Response(xx.data) else: print(ser.errors) return Response("...")直接这样写:
pythonclass UserView(APIView): def post(self, request, *args, **kwargs): ser = UserModelSerializer(data=request.data) if ser.is_valid(): ser.save() return Response(ser.data) else: print(ser.errors) return Response("...")当只写一个的时候内部会自动处理,两个的效果都是一样的
拓展(重写to_representation方法)
在上述校验的同时序列化的时候,会遇到一个问题,当编写一个类的时候,以gender举例,怎么实现一个类的情况下,让gender在写的时候用choices,读的时候为"男"/"女"呢?
首先将Serializer类中to_representation方法源码复制过来准备修改
python
from rest_framework.fields import SkipField
from rest_framework.relations import PKOnlyObject
from rest_framework import serializers
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["id", "name", "age", 'gender']
extra_kwargs = {
"id": {"read_only": True}
}
def to_representation(self, instance):
"""
Object instance -> Dict of primitive datatypes.
"""
ret = {}
fields = self._readable_fields
for field in fields:
try:
attribute = field.get_attribute(instance)
except SkipField:
continue
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
ret[field.field_name] = field.to_representation(attribute)
return ret修改后:
python
from rest_framework.fields import SkipField
from rest_framework.relations import PKOnlyObject
from rest_framework import serializers
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["id", "name", "age", 'gender']
extra_kwargs = {
"id": {"read_only": True}
}
def to_representation(self, instance):
"""
Object instance -> Dict of primitive datatypes.
"""
ret = {}
fields = self._readable_fields
for field in fields:
# ---------------- 修改部分
if hasattr(self, 'nb_%s' % field.field_name):
value = getattr(self, 'nb_%s' % field.field_name)(instance)
ret[field.field_name] = value
else:
# ----------------
try:
attribute = field.get_attribute(instance)
except SkipField:
continue
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
ret[field.field_name] = field.to_representation(attribute)
return ret
def nb_gender(self, obj):
return obj.get_gender_display()上述的里面是自定义的
nb_方法名,实际开发中可以自己自定义也可以自己自定义一个基类,避免每次都重新编写
to_representation方法
案例学习补充
参数的传递
python
path('api/blog/<int:pk>/', views.BlogDetailView.as_view())获取参数的方法:(两种,分情况使用)
python
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
python
def get(self, request, pk):
pk = pk校验时常用的数据
initial_data未经处理的原始数据(从前端接收到的)【钩子校验里面使用】
validated_data经过了所有验证方法后的数据【钩子钩子校验流程之后使用】
attrs在全局验证函数中的经过了字段级校验的所有参数【全局钩子校验函数中使用】
request.data前端传递过来的body中的数据(请求体参数)
request.query_params.get('')获取url链接中携带的参数(类似?name=jelee)
确认密码的坑
我们在编写确认密码字段的时候,由于数据库中并没有这个字段
所以在保存的时候需要先把
validated_data里面的这个字段pop掉且需要添加
write_only=True
代码示例:
python
class UserSerializer(serializers.ModelSerializer):
confirm_password = serializers.CharField(write_only=True)
class Meta:
model = models.UserInfo
fields = ["username", "password", "confirm_password"]
extra_kwargs = {
"password": {"write_only": True}
}
def validate(self, attrs):
if attrs['password'] == attrs['confirm_password']:
attrs.pop('confirm_password')
return attrs
raise ValidationError("两次输入密码不一致")添加
write_only的原因是如果不添加的话,虽然在写入的时候已经删除了,但是在后面查看的时候会默认去数据库中读取这个字段,但是这个字段在数据库中是没有的,就会报错
登陆案例中应该用instance还是data
案例场景:
python
class LoginSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["username", "password"]
class LoginView(APIView):
def post(self, request):
ser = LoginSerializer(data=request.data)此处如果错误的使用了instance,会导致问题,容易疑惑的点是:
登陆不是比较已有的信息吗,为什么要用data
校验也要用data,因为此时你不知道用户输入的账号密码是否正确,如果不正确,那怎么找到已有信息
save()方法中不受序列化影响
利用这一点可以实现一些功能
比如:如果需要外键用户名输入到数据库里面的时候是id,序列后期输出的时候是用户名
python
class BlogCommentSerializer(serializers.ModelSerializer):
user = serializers.CharField(source="user.username", read_only=True)
class Meta:
model = models.Comment
fields = ["id", "user", "content"]然后在保存的时候
python
ser.save(user=request.user, blog=instance)这样指定保存的时候的某些字段就可以避免序列化器的影响
drf(分页)
防止数据过多时一次性请求量过大
PageNumberPagination
基本使用方式
首先需要在配置中配置每页显示几条数据
settings.py
python
REST_FRAMEWORK = {
"UNAUTHENTICATED_USER": None,
"PAGE_SIZE": 3 # 添加配置
}然后处理数据
处理示例:
python
from rest_framework.pagination import PageNumberPagination导入类以后:
python
def get(self, request, *args, **kwargs):
""" 博客列表 """
flag = models.Blog.objects.all().order_by('id')
# -------- 处理代码
pager = PageNumberPagination()
queryset = pager.paginate_queryset(flag, request, self)
# --------
ser = BlogSerializer(instance=queryset, many=True)
return Response(ser.data)利用这个类实例化一个方法,然后调用这个方法的paginate_queryset方法传入参数
待分页的queryset、request对象、self
演示:
bash
http://127.0.0.1:8000/api/blog/?page=1传入需要第几页就会返回第几页的数据,所以数据必须是有序的,也就是数据必须经过order_by排序
默认情况不支持传入一页多少条数据(page_size)不过可以自己配置
自定义page_size
配置示例:
python
class MyPageNumberPagination(PageNumberPagination):
page_size_query_param = "size"
page_size = 2
max_page_size = 5
class BlogView(APIView):
def get(self, request, *args, **kwargs):
""" 博客列表 """
flag = models.Blog.objects.all().order_by('id')
# -------- 写成自己编写的类
pager = MyPageNumberPagination()
# --------
queryset = pager.paginate_queryset(flag, request, self)
ser = BlogSerializer(instance=queryset, many=True)
return Response(ser.data)注意,如果这里写了page_size配置,全局也写了page_size配置,drf内部会先读取全局的配置,然后再读取局部的配置,在读取局部的配置时会把全局的配置覆盖,所以最终生效的是局部的配置
LimitOffsetPagination
这种分页方式与PageNumberPagination最大的区别是:
PageNumberPagination是告诉他需要第几页,每页几条数据
LimitOffsetPagination是告诉他前面有多少条数据,我需要多少条
基本使用方式
limit和offset的默认值都是0
python
from rest_framework.pagination import LimitOffsetPagination
python
class BlogView(APIView):
def get(self, request, *args, **kwargs):
""" 博客列表 """
flag = models.Blog.objects.all().order_by('id')
# ---------- 配置区域
pager = LimitOffsetPagination()
queryset = pager.paginate_queryset(flag, request, self)
# ----------
ser = BlogSerializer(instance=queryset, many=True)
return Response(ser.data)然后就可以使用了
bash
http://127.0.0.1:8000/api/blog/?limit=2&offset=4就会返回两条数据,这两条数据的前面有四条数据,也就是返回第五条和第六条数据
自定义配置
python
class CustomLimitOffsetPagination(LimitOffsetPagination):
# 默认要多少条数据
default_limit = 3
# URL 中指定条数的参数名(默认就是 limit,可自定义)
limit_query_param = 'limit'
# URL 中指定偏移量的参数名(默认就是 offset,可自定义)
offset_query_param = 'offset'
# 限制最大条数
max_limit = 20使用:
python
class CustomLimitOffsetPagination(LimitOffsetPagination):
default_limit = 3
limit_query_param = 'limit'
offset_query_param = 'offset'
max_limit = 20
class BlogView(APIView):
def get(self, request, *args, **kwargs):
""" 博客列表 """
flag = models.Blog.objects.all().order_by('id')
pager = CustomLimitOffsetPagination()
queryset = pager.paginate_queryset(flag, request, self)
ser = BlogSerializer(instance=queryset, many=True)
return Response(ser.data)drf(视图)
GenericAPIView
原始代码
使用示例:
使用GenericAPIView对下面的代码进行简化
python
class BlogView(APIView):
authentication_classes = [BlogAuthentication, ]
def get(self, request, *args, **kwargs):
""" 博客列表 """
flag = models.Blog.objects.all().order_by('id')
pager = CustomLimitOffsetPagination()
queryset = pager.paginate_queryset(flag, request, self)
ser = BlogSerializer(instance=queryset, many=True)
return Response(ser.data)
def post(self, request):
if not request.user:
return Response({"code": 1, "error": "认证失败"})
ser = BlogSerializer(data=request.data)
if not ser.is_valid():
return Response({"code": 2, "error": ser.errors})
ser.save(creator=request.user)
return Response({"code": 1000, "data": ser.data})参数讲解
python
from rest_framework.generics import GenericAPIView
class BlogView(GenericAPIView):
authentication_classes = [BlogAuthentication, ] # 认证类 还可写其他的类
queryset = models.Blog.objects.all().order_by('id') # queryset 需要的原始数据
pagination_class = CustomLimitOffsetPagination # 分页类
serializer_class = BlogSerializer # 序列化类利用这些类就可以简化操作
方法讲解
python
self.get_queryset() # 获取queryset 前面已经配置过了queryset信息 这里可以直接获取
self.paginate_queryset() # 构造分页后的数据 需要传入前面获取的queryset
self.get_serializer() # 获取序列化数据完整流程
python
from rest_framework.generics import GenericAPIView
class BlogView(GenericAPIView):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def get(self, request, *args, **kwargs):
""" 博客列表 """
queryset = self.get_queryset()
page = self.paginate_queryset(queryset)
ser = self.get_serializer(page, many=True)
return Response(ser.data)
def post(self, request):
if not request.user:
return Response({"code": 1, "error": "认证失败"})
ser = self.get_serializer(data=request.data)
if not ser.is_valid():
return Response({"code": 2, "error": ser.errors})
ser.save(creator=request.user)
return Response({"code": 1000, "data": ser.data})最大的意义:
将数据库查询、序列化类提取到类变量中,简化操作
GenericViewSet
查看源码:
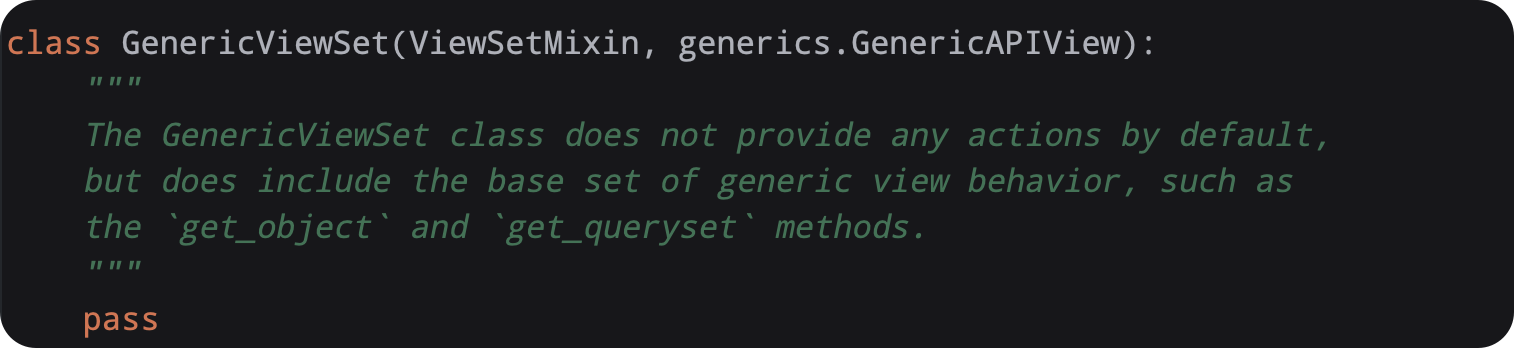
可以看出这个类里面类中没有定义任何代码,他就是继承
ViewSetMixin和GenericAPIView那他的功能也就是这两个类融合到一起
示例原始代码
python
path('api/blog/', views.BlogView.as_view())
python
from rest_framework.viewsets import GenericViewSet
class BlogView(GenericViewSet):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def get(self, request, *args, **kwargs):
""" 博客列表 """
queryset = self.get_queryset()
page = self.paginate_queryset(queryset)
ser = self.get_serializer(page, many=True)
return Response(ser.data)
def post(self, request):
if not request.user:
return Response({"code": 1, "error": "认证失败"})
ser = self.get_serializer(data=request.data)
if not ser.is_valid():
return Response({"code": 2, "error": ser.errors})
ser.save(creator=request.user)
return Response({"code": 1000, "data": ser.data})完整代码
python
path('api/blog/', views.BlogView.as_view({"get": "list", "post": "create"}))
python
from rest_framework.viewsets import GenericViewSet
class BlogView(GenericViewSet):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def list(self, request, *args, **kwargs):
""" 博客列表 """
queryset = self.get_queryset()
page = self.paginate_queryset(queryset)
ser = self.get_serializer(page, many=True)
return Response(ser.data)
def create(self, request):
if not request.user:
return Response({"code": 1, "error": "认证失败"})
ser = self.get_serializer(data=request.data)
if not ser.is_valid():
return Response({"code": 2, "error": ser.errors})
ser.save(creator=request.user)
return Response({"code": 1000, "data": ser.data})别看着改了这么多,实际上就是把get、post这些方法名对应到了具体的方法上
通过「路由映射」把 HTTP 方法(GET/POST/PUT/DELETE)关联到对应的操作(列表 / 创建 / 详情 / 更新 / 删除),能让路由配置更简洁
五大类
GenericViewSet 体系下的 5 个核心 Mixin 扩展类
所以使用的时候都必须继承GenericViewSet
ListModelMixin
原始代码
python
path('api/blog/', views.BlogView.as_view({"get": "list"}))
python
class BlogView(GenericViewSet, ListModelMixin):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def list(self, request, *args, **kwargs):
""" 博客列表 """
queryset = self.get_queryset()
page = self.paginate_queryset(queryset)
ser = self.get_serializer(page, many=True)
return Response(ser.data)完整代码
python
path('api/blog/', views.BlogView.as_view({"get": "list"}))
python
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
class BlogView(GenericViewSet, ListModelMixin):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer这样更改之后效果一样,只不过返回的数据不一样了,但是可以通过重写list方法达成自定制返回的数据
重写方法(自定义响应格式)
python
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
class BlogView(GenericViewSet, ListModelMixin):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def list(self, request, *args, **kwargs):
""" 博客列表 """
response = super().list(request, *args, **kwargs)
return Response({"code": 100, "data": response.data})CreateModelMixin
原始代码(手动编写create方法)
python
path('api/blog/', views.BlogView.as_view({"get": "list", "post": "create"})),
python
class BlogView(GenericViewSet, ListModelMixin): # 注意这里现在还没有继承其他的类
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def create(self, request):
if not request.user:
return Response({"code": 1, "error": "认证失败"})
ser = self.get_serializer(data=request.data)
if not ser.is_valid():
return Response({"code": 2, "error": ser.errors})
ser.save(creator=request.user)
return Response({"code": 1000, "data": ser.data})完整代码(含重写方法)
python
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin, CreateModelMixin
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def perform_create(self, serializer):
serializer.save(creator=self.request.user)
def create(self, request, *args, **kwargs):
try:
if not self.request.user:
return Response({"code": 1, "error": "认证失败"})
response = super().create(request, *args, **kwargs)
return Response({"code": 1000, "data": response.data})
except ValidationError as e:
return Response({"code": 2000, "errors": e.detail})拓展(执行流程)
方法会在调用super.create(request, *args, **kwargs)的时候调用perform_create
此处由于有认证组件的需求,所以重写了create方法,如果没有此需求,代码将会非常简洁:
pythonclass BlogView(GenericViewSet, ListModelMixin, CreateModelMixin): authentication_classes = [BlogAuthentication, ] queryset = models.Blog.objects.all().order_by('id') pagination_class = CustomLimitOffsetPagination serializer_class = BlogSerializer def perform_create(self, serializer): serializer.save(creator=self.request.user)他会自动校验字段(
ser.is_valid())
RetrieveModelMixin
原始代码
python
path('api/blog/<int:pk>/', views.BlogDetailView.as_view())
python
class BlogDetailView(APIView):
def get(self, request, *args, **kwargs):
""" 获取详细的博客信息 """
pk = kwargs.get('pk')
queryset = models.Blog.objects.filter(id=pk).first()
if not queryset:
return Response({"code": 1001, "error": "不存在"})
ser = BlogSerializer(instance=queryset)
return Response({"code": 1000, "data": ser.data})完整代码
python
path('api/blog/<int:pk>/', views.BlogDetailView.as_view({"get": "retrieve"}))
python
class BlogDetailView(GenericViewSet, RetrieveModelMixin):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer拓展配置
在这种写法中,如果url中的参数名不想写成pk的话就需要添加额外配置
python
class BlogDetailView(GenericViewSet, RetrieveModelMixin):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
lookup_url_kwarg = 'id' # 改成id就可以这样写:
python
path('api/blog/<int:id>/', views.BlogDetailView.as_view({"get": "retrieve"}))UpdateModelMixin
完整代码
python
path('api/blog/<int:pk>/', views.BlogDetailView.as_view({ put": 'update', 'patch': 'partial_update'})),
python
class BlogDetailView(GenericViewSet, RetrieveModelMixin, UpdateModelMixin):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializerdrf会自动处理请求,包括了put(全量更新)/patch(局部更新)
put:必须传入所有字段内容更新
patch:传入多少更多少
拓展配置
python
class BlogDetailView(GenericViewSet, RetrieveModelMixin, UpdateModelMixin):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
def perform_update(self, serializer):
# ---------- 可以在这里面执行一些操作
print(serializer.validated_data)
# ----------
serializer.save()DestroyModelMixin
完整代码
python
path('api/blog/<int:pk>/', views.BlogDetailView.as_view({'delete': 'destroy'}))
python
from rest_framework.mixins import ListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin
class BlogDetailView(GenericViewSet,RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer拓展配置
如果按照上面的进行配置,删除数据后没有任何提示,可以通过重写方法自定制
python
class BlogDetailView(GenericViewSet, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
def perform_destroy(self, instance):
print("可以在这里做一些额外的操作")
instance.delete()
def destroy(self, request, *args, **kwargs):
super().destroy(request, *args, **kwargs)
return Response({"message": "删除成功"})类的汇总(ModelViewSet)
通过上述代码可以看出如果每次编写类都要继承
pythonListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin, GenericViewSet那代码显得很冗余,可不可以封装起来呢, drf已经帮我们做了这个事了
python
from rest_framework.viewsets import ModelViewSetModelViewSet
查看他的源码
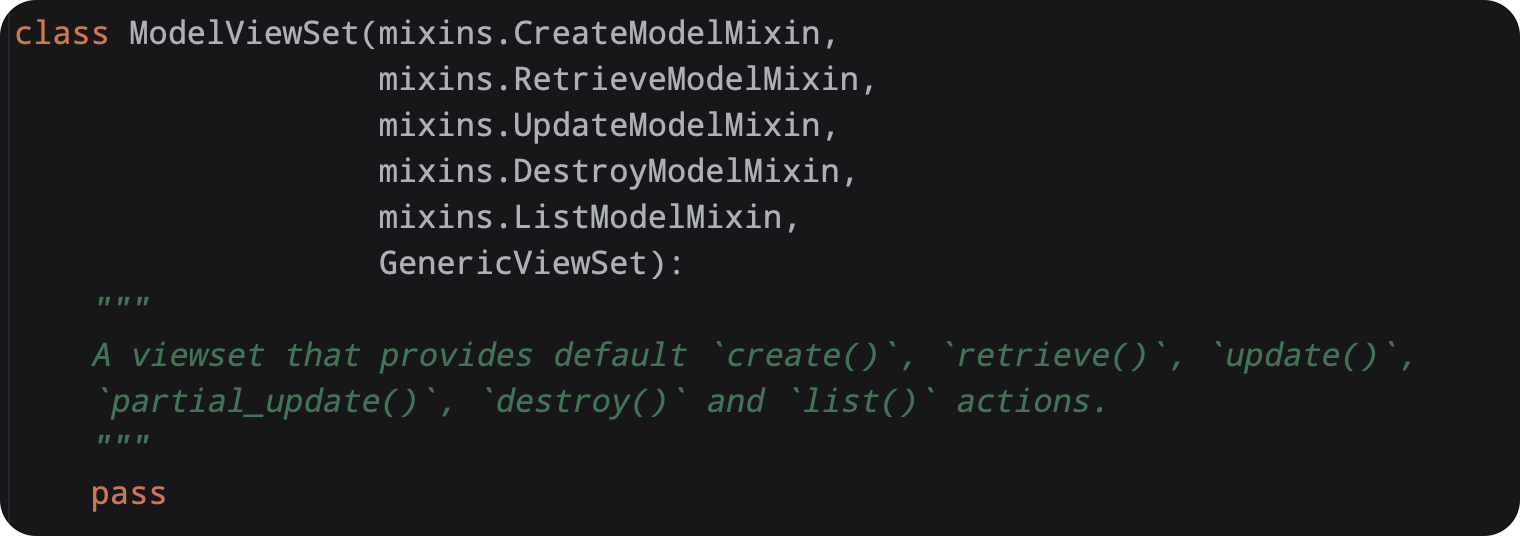
就是帮我们汇总了,以后需要就只需要写一个类就可以了
最佳实践
这么多方法怎么取舍呢
如果操作与数据库接口无关,那就直接继承APIView,如果有关,那就继承ModelViewSet,如果功能不够用,就通过重写某些方法进行拓展,根据习惯选择五大类或者ModelViewSet
拓展(自己编写处理方法)
编写url匹配到change_title这个方法
python
path('api/blog/<int:pk>/', views.BlogDetailView.as_view({"'post': 'change_title' }))编写change_title方法对应post请求
python
class BlogDetailView(ModelViewSet):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
@action(detail=True, methods=['post'])
def change_title(self,request, pk=None):
"""
自定义动作:修改博客标题(手动URL映射版)
:param pk: URL中的主键(对应你写的 <int:pk>)
"""
# 1. 查指定pk的博客(自动处理404)
blog = self.get_object()
# 2. 获取前端传的新标题
new_title = request.data.get('new_title')
if not new_title:
return Response(
{"error": "新标题不能为空"},
status=status.HTTP_400_BAD_REQUEST
)
# 3. 修改并保存
blog.title = new_title
blog.save()
# 4. 返回响应
return Response({
"code": 1000,
"msg": f"博客{pk}标题修改成功",
"new_title": blog.title
})detail=True的意思是标记为详情级动作,详细参照这个表格
参数值 detail=True detail=False URL 是否需 pk 是(/demo/1/single-action/) 否(/demo/batch-action/) 操作数据范围 单条数据(pk 对应的记录) 批量数据(所有记录) 能否用 get_object () 可以(获取单条数据) 不可以(无 pk,会报错) 函数参数 需接收 pk(pk=None) 无需接收 pk 典型场景 修改单条数据、删除单条数据、点赞单篇博客 查询数据列表、批量导出、批量创建
有时候还会需要接受url里面传递过来的参数
python
from django.urls import path, include
from api import views
from rest_framework import routers
router = routers.SimpleRouter()
router.register(r'calculator', views.CalculatorViewSet, basename='calculator')
urlpatterns = [
path('api/', include((router.urls, 'api'), namespace='namespace-example'))
]这样写的话
python
class CalculatorViewSet(ModelViewSet):
@action(detail=False, methods=['get'], url_path="add/(?P<num1>\d+)/(?P<num2>\d+)")
def add(self, request, num1, num2):
result = int(num1) + int(num2)
return Response({
"method": "add",
"num1": num1,
"num2": num2,
"result": result,
"url": request.path
})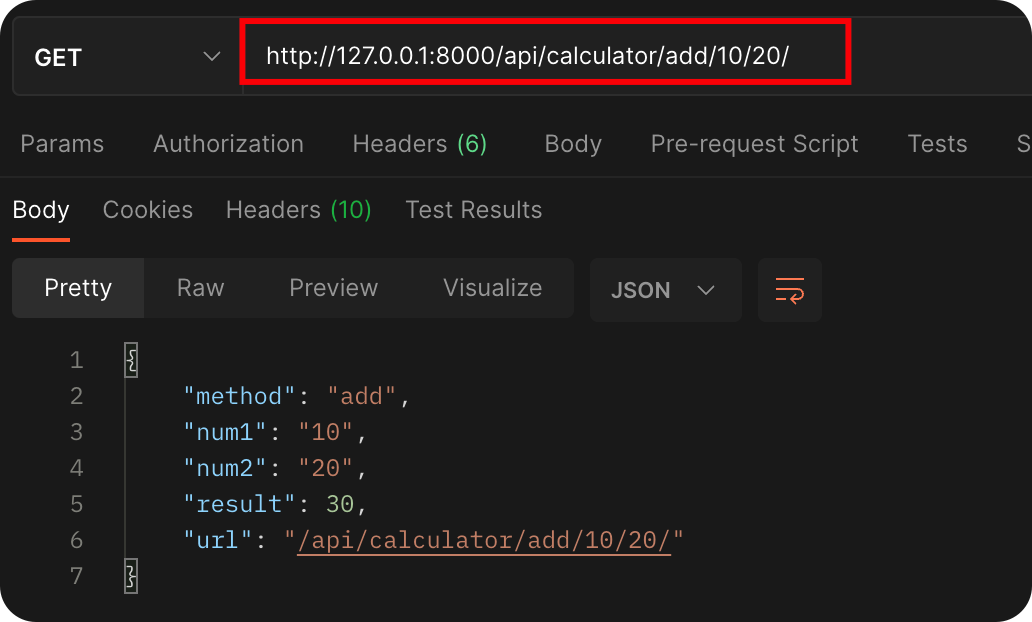
就可以达成这样的效果
补充:权限
在之前定义权限类时,类中可以定义两个方法:has_permission 和 has_object_permission
has_permission,在请求进入视图之前就会执行。has_object_permission,当视图中调用self.get_object时就会被调用(删除、更新、查看某个对象时都会调用),一般用于检查对某个对象是否具有权限进行操作。
python
class PermissionA(BasePermission):
message = {"code": 1003, 'data': "无权访问"}
def has_permission(self, request, view):
exists = request.user.roles.filter(title="员工").exists()
if exists:
return True
return False
def has_object_permission(self, request, view, obj):
return True所以,让我们在编写视图类时,如果是直接获取间接继承了 GenericAPIView,同时内部调用 get_object方法,这样在权限中通过 has_object_permission 就可以进行权限的处理。
drf(路由)
原始代码
python
path('api/blog/', views.BlogView.as_view('get': 'list', 'post': 'create'))
# 还可以添加别的put/patch等
python
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer
def perform_create(self, serializer):
serializer.save(creator=self.request.user)
def create(self, request, *args, **kwargs):
try:
if not self.request.user:
return Response({"code": 1, "error": "认证失败"})
response = super().create(request, *args, **kwargs)
return Response({"code": 1000, "data": response.data})
except ValidationError as e:
return Response({"code": 2000, "errors": e.detail})视图类
我们原来定义的url的写法如果里面的参数过多,比如get/post/put这些写的过多了就会显得比较麻烦
基础写法
python
from django.urls import path
from rest_framework import routers
router = routers.SimpleRouter()
router.register(r'api/blog', views.BlogView)
urlpatterns = [
# 这里编写你的其他url
]
urlpatterns += router.urls这样写了以后就相当于完成了和api/blog有关的所有方法的对应
| HTTP 方法 | URL 路径 | 视图方法 | 功能 |
|---|---|---|---|
| GET | /api/blog/ |
list | 博客列表 |
| POST | /api/blog/ |
create | 创建博客 |
| GET | /api/blog/<int:pk>/ |
retrieve | 博客详情 |
| PUT | /api/blog/<int:pk>/ |
update | 全量更新 |
| PATCH | /api/blog/<int:pk>/ |
partial_update | 部分更新 |
| DELETE | /api/blog/<int:pk>/ |
destroy | 删除博客 |
节省了很多时间
额外配置
python
from django.urls import path, include
from rest_framework import routers
router = routers.SimpleRouter()
router.register(r'blog', views.BlogView, basename='front_blog')
urlpatterns = [
path('api/', include((router.urls, 'api'), namespace="api"))
]参数说明:
register的第三个参数basename='front_blog'这个的意思是
给路由器自动生成的 URL 名称加「基础前缀」,最终形成
namespace:basename-action的完整 URL 名称(比如api:blog-list),用于反向解析如果对应的模型里面有queryset,例如此处制定了views.BlogView,如果BlogView里面制定了queryset,那basename就算不写也会默认指定为那个queryset的模型示例名称
python# views.py class BlogView(viewsets.ModelViewSet): queryset = Blog.objects.all() # 模型名是Blog serializer_class = BlogSerializer # urls.py router.register(r'blog', views.BlogView) # DRF自动推断basename='blog'
path()的第一个参数:'api/'这个的意思是前缀,就是所有通过后面的include挂载的url都会挂载到这个前缀下
include()的第一个参数:(router.urls, 'api')这是一个元组类型的对象,第一个时需要包含的url列表对象,也就是上面对router注册的url,用专业术语说就是要引入的「URL 模式列表」
include()的第二个参数:namespace="api"这是一个命名空间对象,用于反向解析url的时候不出问题,不会改变url的路径
python# urls.py urlpatterns = [ # 前台用户模块:namespace=user_front path('user/', include(('user.urls', 'user'), namespace='user_front')), # 后台管理员模块:namespace=user_admin path('admin/user/', include(('user.urls', 'user'), namespace='user_admin')), ]这种情况下就可以发挥作用:
python# 前台个人中心:/user/profile/ reverse('user_front:profile') # 后台个人中心:/admin/user/profile/ reverse('user_admin:profile')
basename和namespace都只在反向解析url的时候才有用:
pythonrouter = routers.SimpleRouter() router.register(r'blog', views.BlogView, basename='basename-example') urlpatterns = [ path('api/', include((router.urls, 'api'), namespace='namespace-example')) ]反向解析:
pythonfrom django.urls import reverse list_url = reverse('namespace-example:basename-example-list') print(list_url)
多URL写法
写法一(推荐):
python
from django.urls import path, include
from rest_framework import routers
from . import views # 假设你有BlogView、UserView、CommentView
# 1. 创建一个路由器实例(复用同一个即可)
router = routers.SimpleRouter()
# 2. 多次调用register,注册多个视图集
# 格式:router.register(URL前缀, 视图类, basename=URL名称前缀)
router.register(r'blog', views.BlogView, basename='blog') # 注册博客API
router.register(r'user', views.UserView, basename='user') # 注册用户API
router.register(r'comment', views.CommentView, basename='comment') # 注册评论API
# 3. 依然只需一行include,挂载所有注册的URL
urlpatterns = [
path('api/', include((router.urls, 'api'), namespace="api"))
]写法二:
python
blog_router = routers.SimpleRouter()
blog_router.register(r'blog', views.BlogView, basename='blog')
blog_router.register(r'comment', views.CommentView, basename='comment')
user_router = routers.SimpleRouter()
user_router.register(r'user', views.UserView, basename='user')
# 2. 合并所有路由器的URL
all_router_urls = blog_router.urls + user_router.urls
# 3. 挂载到api/下
urlpatterns = [
path('api/', include((all_router_urls, 'api'), namespace="api"))
]drf(条件搜索)
自定义搜索规则
python
from rest_framework.filters import BaseFilterBackend
class Filter1(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
category = request.query_params.get('category')
if not category:
return queryset
return queryset.filter(category=category)
class Filter2(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
id = request.query_params.get('id')
if not id:
return queryset
return queryset.filter(id__gt=id)
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
filter_backends = [Filter1, Filter2]
# 与其他配置项同级编写
authentication_classes = [BlogAuthentication, ]
queryset = models.Blog.objects.all().order_by('id')
pagination_class = CustomLimitOffsetPagination
serializer_class = BlogSerializer第三方Filter
在drf开发中有一个常用的第三方过滤器:
DjangoFilterBackend
安装配置
python
pip install django-filter
python
INSTALLED_APPS = [
...
'django_filters',
...
]基本使用
python
from django_filters.rest_framework import DjangoFilterBackend
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
filter_backends = [DjangoFilterBackend, ]
filterset_class = ["id", "category"]就可以实现id、category的筛选,但是此处只能筛选等于这个条件,不能用其他的
拓展配置
python
class MyFilter(FilterSet):
min_id = filters.NumberFilter(field_name='id', lookup_expr='gte')
category = filters.NumberFilter(field_name='category', lookup_expr='exact')
class Meta:
model = models.Blog
fields = ['min_id', 'category']
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
# ... 其他配置
filter_backends = [DjangoFilterBackend, ]
filterset_class = MyFilter此时发送
url
http://127.0.0.1:8000/api/blog/?min_id=21&category=2就会返回id大于等于21,并且category等于2的数据
当大于小于这些简单的逻辑不能满足我们的需求时,可以自定义一个过滤方法
python
class MyFilterSet(FilterSet):
# 1. 定义字段,通过 method 绑定方法名
custom_search = filters.CharFilter(method='my_custom_filter', distinct=False, required=False)
# 2. 实现该方法
def my_custom_filter(self, queryset, name, value):
# 逻辑处理...
return queryset参数说明:
self : 指向当前的 FilterSet 实例。
queryset: 尚未执行此过滤前的原始查询集(QuerySet)。
name : 字段的名称(在上面的例子中就是 "custom_search")。
value : 前端从 URL 传过来的具体数值(比如 ?custom_search=python,value 就是 "python")。
distinct=False:是否去重,默认值为False
比如一篇博文有两个标签
python和go现在需要搜索有python标签和有go标签的,这篇博文就会匹配两次,返回这样的数据
json[ { "id": 1, "title": "全栈开发笔记", "tags": ["Python", "Go"] }, { "id": 1, "title": "全栈开发笔记", "tags": ["Python", "Go"] }, { "id": 2, "title": "Java 核心技术", "tags": ["Java"] } ]此时如果添加这个参数就可以避免这个问题
required=False:是否必填,默认值为False
lookup_expr参数
| 表达式 | 说明 | 数据库 SQL 逻辑 (示例) | 常用业务场景 |
|---|---|---|---|
exact |
精确匹配 | WHERE col = 'val' |
匹配 ID、分类 ID、状态码 |
iexact |
精确匹配 (忽略大小写) | WHERE col ILIKE 'val' |
匹配用户名、验证码、颜色名 |
contains |
包含 (区分大小写) | WHERE col LIKE '%val%' |
搜索文章正文中的特定词汇 |
icontains |
包含 (忽略大小写) | WHERE col ILIKE '%val%' |
最常用:搜索标题、简介关键词 |
startswith |
以...开头 | WHERE col LIKE 'val%' |
搜索姓氏、特定号段的手机号 |
istartswith |
以...开头 (忽略大小写) | WHERE col ILIKE 'val%' |
搜索 URL 前缀、文件路径 |
endswith |
以...结尾 | WHERE col LIKE '%val' |
搜索特定后缀的邮箱 |
iendswith |
以...结尾 (忽略大小写) | WHERE col ILIKE '%val' |
搜索图片格式 (如 .JPG) |
gt |
大于 (>) |
WHERE col > 10 |
筛选价格高于 100 元的商品 |
gte |
大于等于 (>=) |
WHERE col >= 10 |
筛选 18 岁及以上的用户 |
lt |
小于 (<) |
WHERE col < 10 |
筛选库存低于 5 件的预警 |
lte |
小于等于 (<=) |
WHERE col <= 10 |
筛选今天之前创建的文章 |
in |
在集合中 | WHERE col IN (1, 2, 3) |
批量查询多个 ID 或特定分类列表 |
range |
在范围内 | WHERE col BETWEEN 1 AND 10 |
价格区间、日期段筛选 |
isnull |
是否为空 | WHERE col IS NULL |
筛选"未绑定手机号"或"未删除"的数据 |
regex |
正则匹配 | WHERE col ~ 'pattern' |
复杂的文本规则校验(区分大小写) |
iregex |
正则匹配 (忽略大小写) | WHERE col ~* 'pattern' |
复杂的文本规则校验(忽略大小写) |
全局配置
python
# settings.py 全局配置
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend',]
}这样以后
pythonclass BlogView(GenericViewSet, ListModelMixin, CreateModelMixin): filter_backends = [DjangoFilterBackend, ] # 这一行可以省略 filterset_class = MyFilter
pythonclass BlogView(GenericViewSet, ListModelMixin, CreateModelMixin): filterset_class = MyFilter但是如果你有多个配置项
pythonfrom rest_framework.filters import SearchFilter, OrderingFilter class UserView(ModelViewSet): # 局部配置会覆盖 settings 中的全局配置 # 注意:如果你在这里写了,记得把 DjangoFilterBackend 也带上,否则它会失效 filter_backends = [DjangoFilterBackend, SearchFilter, OrderingFilter] filterset_class = MyFilterSet
内置Filter
OrderingFilter(支持排序)
python
from rest_framework.filters import OrderingFilter
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
filter_backends = [OrderingFilter, ]
ordering_fields = ['id', 'category']此时他支持用id和category排序
url
?ordering=id
?ordering=-id
?ordering=age
?ordering=-age当你传入
url
http://127.0.0.1:8000/api/blog/?ordering=id的时候就会以id从小到大排序
SearchFilter(模糊匹配)
python
from rest_framework.filters import SearchFilter
class BlogView(GenericViewSet, ListModelMixin, CreateModelMixin):
filter_backends = [OrderingFilter, SearchFilter]
ordering_fields = ['id', 'category']
search_fields = ['title']此时就会支持以title模糊查询,可以写多个(你想在哪些字段里搜?)
url
?search=django例如我这里:
url
http://127.0.0.1:8000/api/blog/?search=django
json
{
"category": "Python全栈",
"image": "xxxx/xxxxx.png",
"title": "django开发",
"summary": "rqrqeqweqeq",
"ctime": "2026年03月12日",
"comment_count": 0,
"favor_count": 0,
"creator": {
"id": 3,
"username": "jelee"
}
}在这里我配置了title所以就模糊匹配到了title符合的这一项
search_fields里面的参数支持这些规则
| 符号 | 模式 | 说明 (SQL 逻辑) | 例子 |
|---|---|---|---|
| (无) | icontains |
模糊包含 (默认) | search_fields = ['title'] |
^ |
istartswith |
以...开头 | search_fields = ['^title'] |
= |
iexact |
完全匹配 | search_fields = ['=title'] |
$ |
iregex |
正则匹配 | search_fields = ['$title'] |
如果用户在搜索框输入了空格,比如 ?search=Python Django:
- 默认逻辑 :
SearchFilter会把关键词拆分成Python和Django。 - 匹配方式 :它会要求这条数据同时满足这两个词的搜索(相当于 AND 逻辑)
拓展(双下划线跨表)
| 特性 | SearchFilter (搜索) | OrderingFilter (排序) |
|---|---|---|
| 代码示例 | search_fields = ['creator__name'] |
ordering_fields = ['creator__age'] |
| 业务场景 | 根据"作者名"或"分类名"搜文章 | 按"作者活跃度"或"部门等级"排文章 |
| 深度支持 | 支持多级,如 creator__depart__title |
支持多级,如 creator__depart__level |
当你使用双下划线跨表排序或搜索时,Django 必须执行 JOIN 操作。如果你的 queryset 只是简单的 Blog.objects.all(),Django 在序列化每一条数据时,可能还会再去数据库查一次作者信息,导致性能差
解决方案:
配合 select_related 使用
只要涉及跨表(外键),就在 queryset 中提前"预加载":
python
class BlogView(ModelViewSet):
# 使用 select_related 提前把作者信息 JOIN 进来
# 这样排序和搜索时,数据库一次性就能把数据给全
queryset = models.Blog.objects.all().select_related('creator')
filter_backends = [SearchFilter, OrderingFilter]
search_fields = ['creator__username']
ordering_fields = ['creator__age']