****论文题目:****DEEP GRAPH INFOMAX(深度图信息)
会议:ICLR2019
****摘要:****我们提出了深度图信息(Deep Graph Infomax, DGI),这是一种以无监督方式学习图结构数据中的节点表示的通用方法。DGI依赖于最大化补丁表示和相应的图的高级摘要之间的相互信息,两者都是使用已建立的图卷积网络架构派生的。学习到的补丁表示总结了以感兴趣的节点为中心的子图,因此可以在下游节点智能学习任务中重用。与大多数先前使用GCNs进行无监督学习的方法相比,DGI不依赖于随机漫步目标,并且很容易适用于传导和归纳学习设置。我们在各种节点分类基准上展示了具有竞争力的性能,有时甚至超过了监督学习的性能。
DGI------用互信息最大化实现图的无监督表示学习
为什么需要无监督图学习?
在现实世界中,大多数图数据都是无标签的:
- 社交网络中的用户关系
- 生物网络中的基因调控
- 知识图谱中的实体关系
- 文档的词共现网络
传统的监督学习需要大量标注数据,代价高昂。那么,能否像Word2Vec学习词表示那样,从图结构本身学习有意义的节点表示呢?
现有方法的问题
随机游走方法的局限
DeepWalk和Node2Vec通过在图上进行随机游走,将图问题转化为序列问题:
- 在图上采样随机游走路径
- 将路径视为"句子",节点视为"单词"
- 用Word2Vec学习节点embedding
但这种方法有三大问题:
- 过分强调proximity:倾向于让相邻节点embedding相似,但忽视了结构角色(如两个远距离的"桥节点"可能功能相似)
- 超参数敏感:游走长度、窗口大小等选择对结果影响很大
- 与GCN不匹配:GCN本身已经有邻域聚合的归纳偏置,随机游走可能是多余的
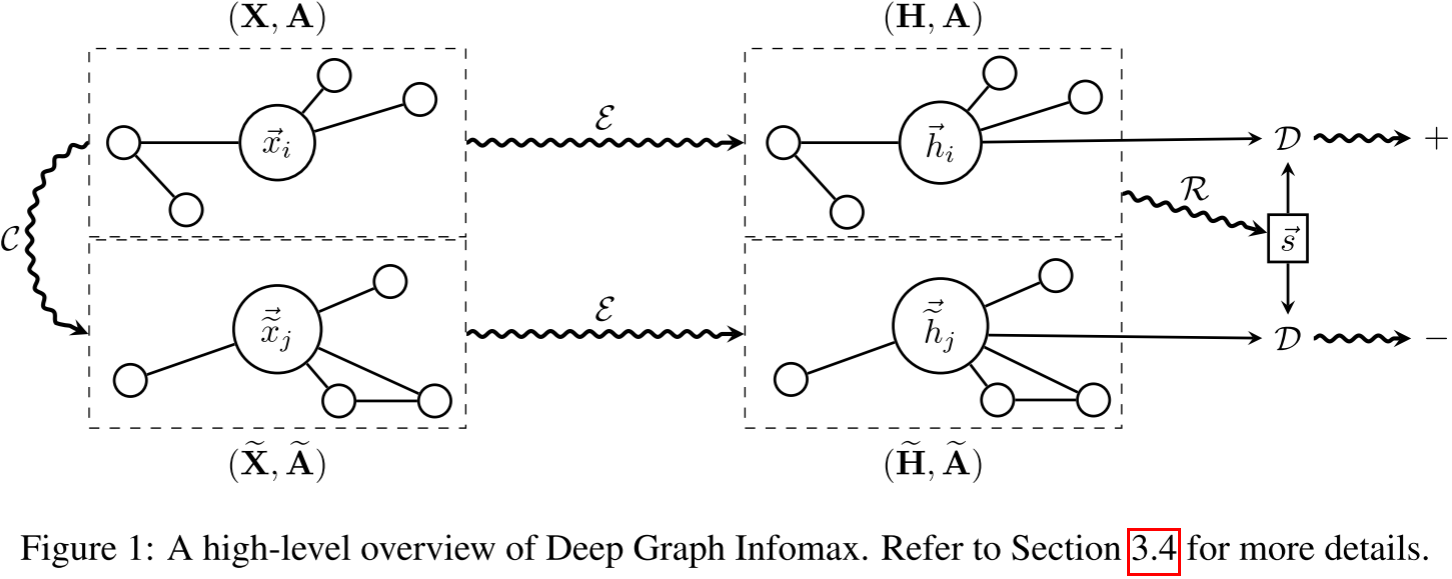
DGI的核心思想:局部-全局互信息最大化
DGI的灵感来自Deep InfoMax (DIM),后者在图像上取得了成功。核心思想简洁而深刻:
好的节点表示应该包含整个图的全局信息。
具体来说:
- Patch representations h_i:节点i及其邻域的表示(通过GCN得到)
- Graph summary s:整个图的全局表示(通过readout函数得到)
- 目标:最大化h_i和s的互信息
技术细节
1. 如何计算互信息?
直接计算互信息很难,DGI采用对比学习:训练一个discriminator D(h_i, s)来判断:
- 正样本:(h_i, s)来自同一个图
- 负样本:(h̃_j, s)其中h̃_j来自corrupted图
损失函数(Binary Cross-Entropy):
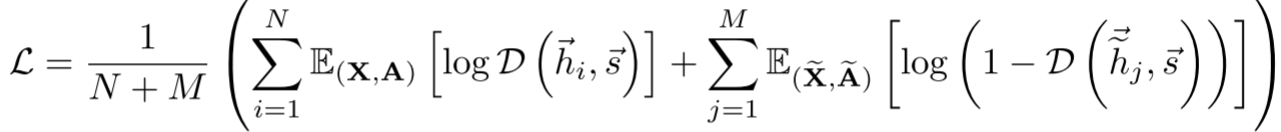
这实际上在最小化Jensen-Shannon散度,进而最大化互信息!
2. 如何生成负样本?
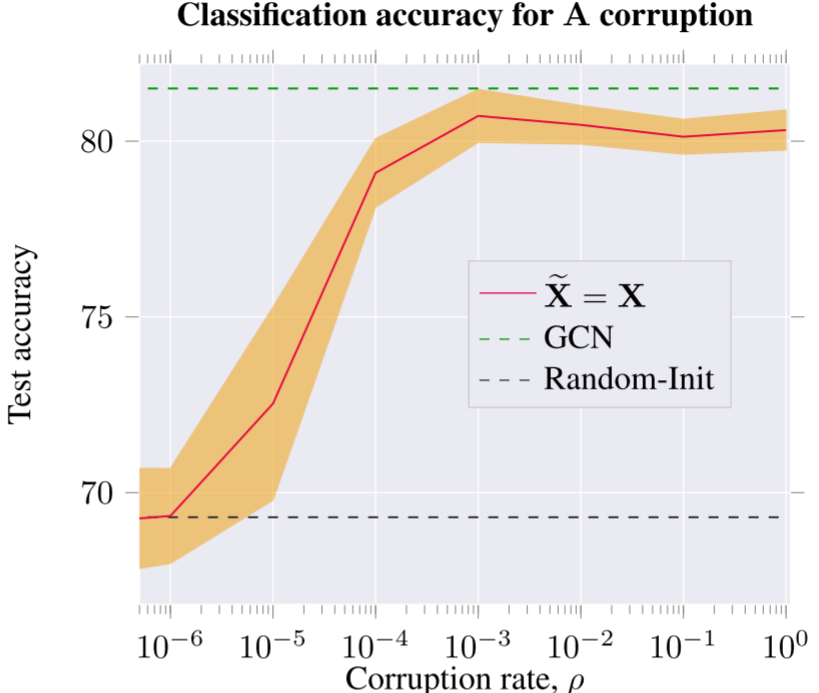
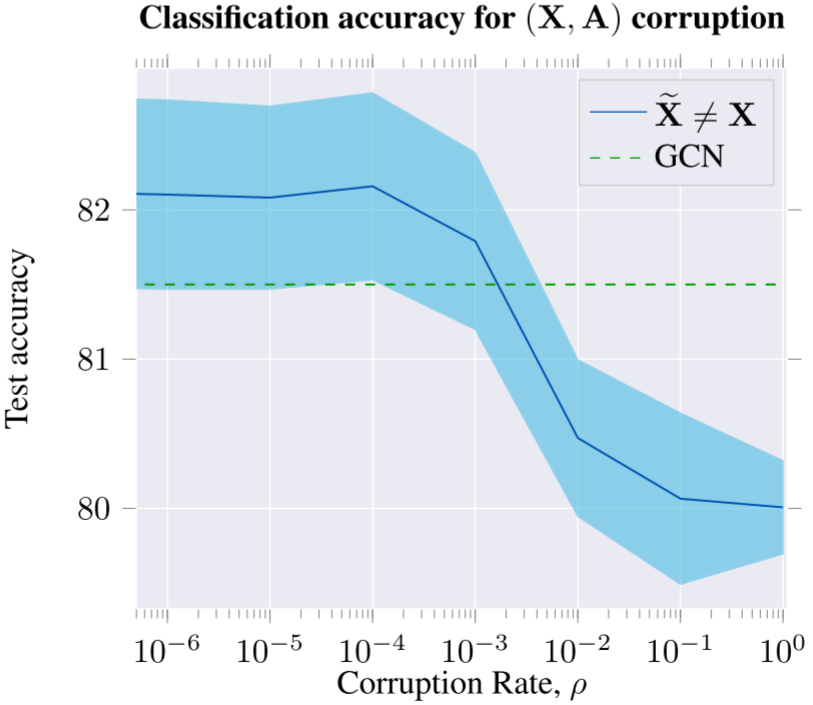
这是DGI的关键设计选择。论文探索了几种corruption策略:
Transductive设置(如Cora):
- 保持邻接矩阵A不变
- 打乱特征矩阵X的行(即节点特征)
- 这样节点出现在不同的图结构位置,获得不同的patch
Inductive设置(如Reddit):
- 对于大图,每个minibatch采样一个子图
- 子图内部进行特征打乱
- 或者直接使用不同的子图作为负样本
Multiple graphs(如PPI):
- 直接从训练集中采样不同的图作为负样本
- 对采样的图的特征进行dropout增强多样性
3. 编码器和Readout设计
编码器E(transductive):
h_i = σ(D̃^(-1/2) ÃD̃^(-1/2) XΘ)这是一层GCN,其中Ã = A + I(加自环),使用PReLU激活。
Readout函数R:
s = σ(1/N Σ h_i)简单的平均pooling + sigmoid。虽然简单,但实验表明在多数情况下效果很好。对于超大图,可考虑更复杂的readout如Set2Vec。
Discriminator D:
D(h_i, s) = σ(h_i^T W s)双线性评分函数,非常高效。
理论分析的亮点
论文提供了严格的理论分析(Section 3.3),核心结论:
Lemma 1: 最优分类器的错误率上界为 Err* = 1/2 Σ p(s^(k))²
Theorem 1: 当readout函数R是单射时,最小化分类错误等价于最大化互信息MI(X; s)
Theorem 2: 对于局部patch,最优表示h_i同样最大化MI(X_i; h_i)
这为DGI的有效性提供了理论支撑。
实验结果深度分析
Transductive节点分类
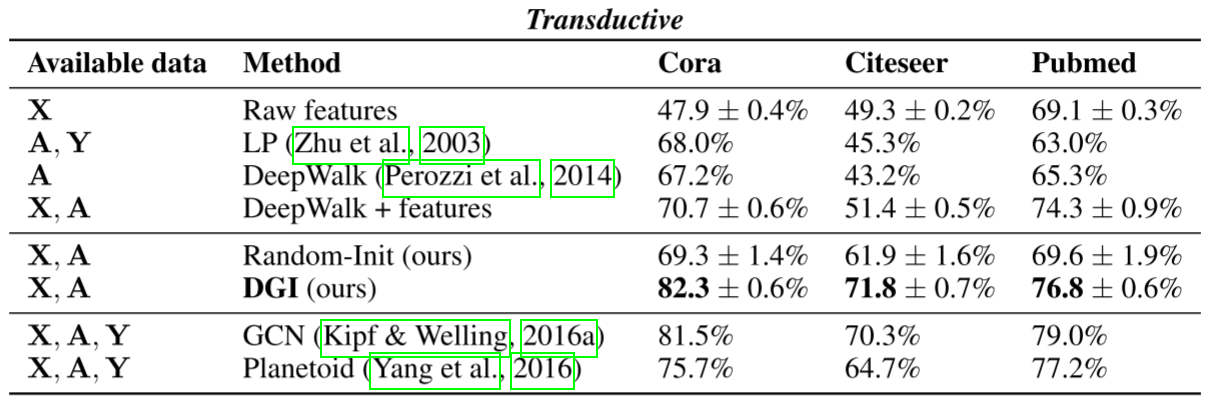
令人惊讶的发现:
- DGI超越监督GCN (Cora和Citeseer上)!
- Cora: 82.3% vs 81.5%
- Citeseer: 71.8% vs 70.3%
这可能是因为:DGI让每个节点间接访问了整个图的信息,而监督GCN受限于2层邻域(否则会过拟合)。
- 远超无监督基线 :
- DeepWalk + features (Cora): 70.7%
- DGI (Cora): 82.3% ↑11.6%
Inductive学习
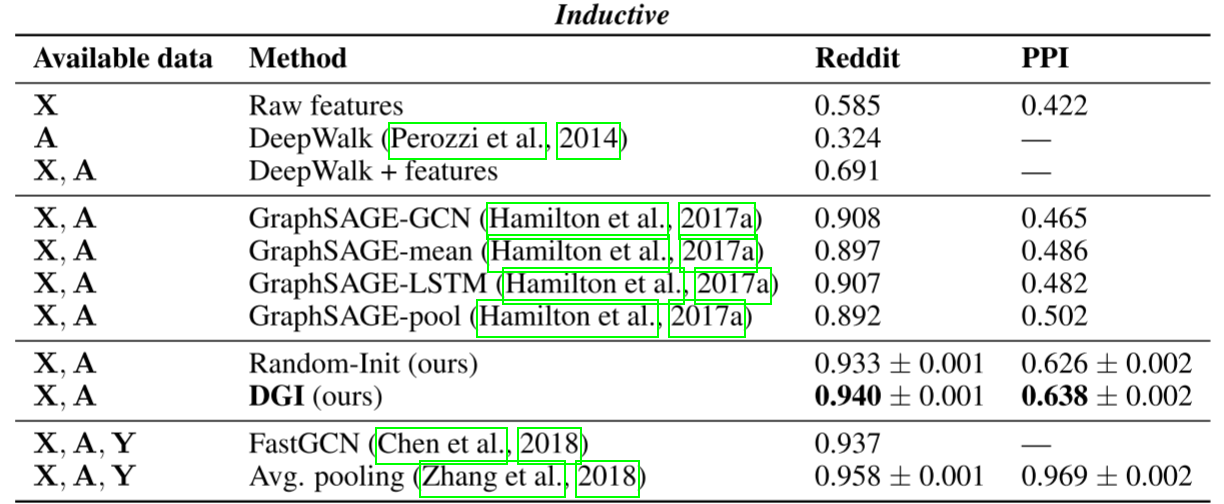
Reddit(大规模图):
- DGI: 94.0%
- GraphSAGE-GCN: 90.8%
- 提升3.2%,同时注意这是无监督 vs 有监督!
PPI(多图学习):
- DGI: 63.8%
- GraphSAGE-pool: 50.2%
- 提升13.6%,差距巨大!
可视化分析

对比三种表示:
- Raw features:混乱,无明显聚类
- Random-Init GCN:有一定结构但不清晰
- DGI learned:7个类别清晰分离,Silhouette score 0.234(vs Embedding Propagation的0.158)
这直观展示了DGI学到了语义上有意义的表示。
Discriminator分析
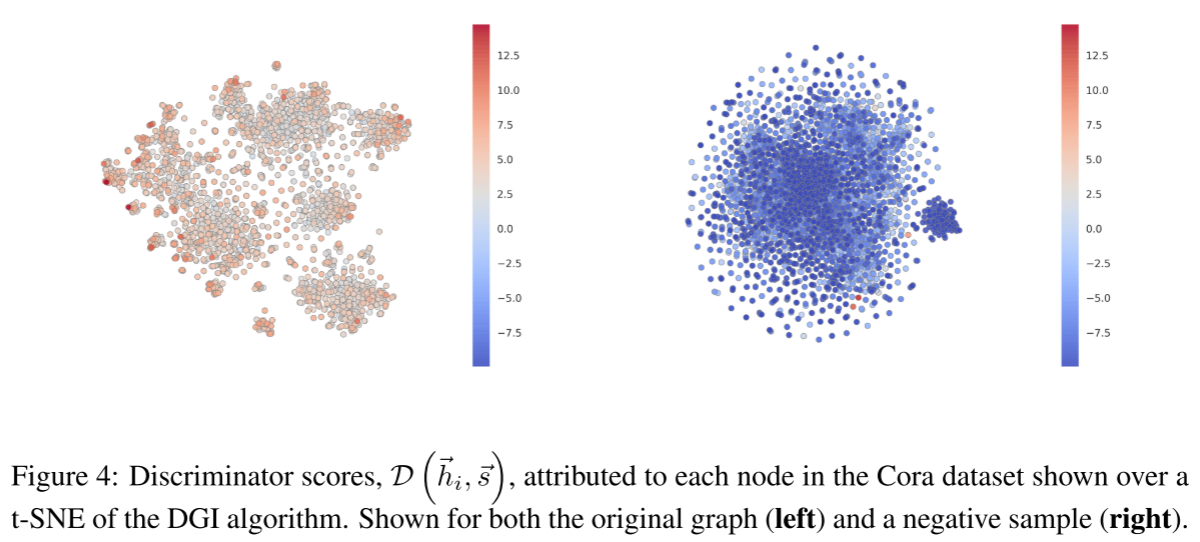
有趣的观察:
- 正样本图上,只有少数"hot"节点获得高分
- 说明某些维度专门用于区分正负样本
- 其他维度用于编码有用的分类信息
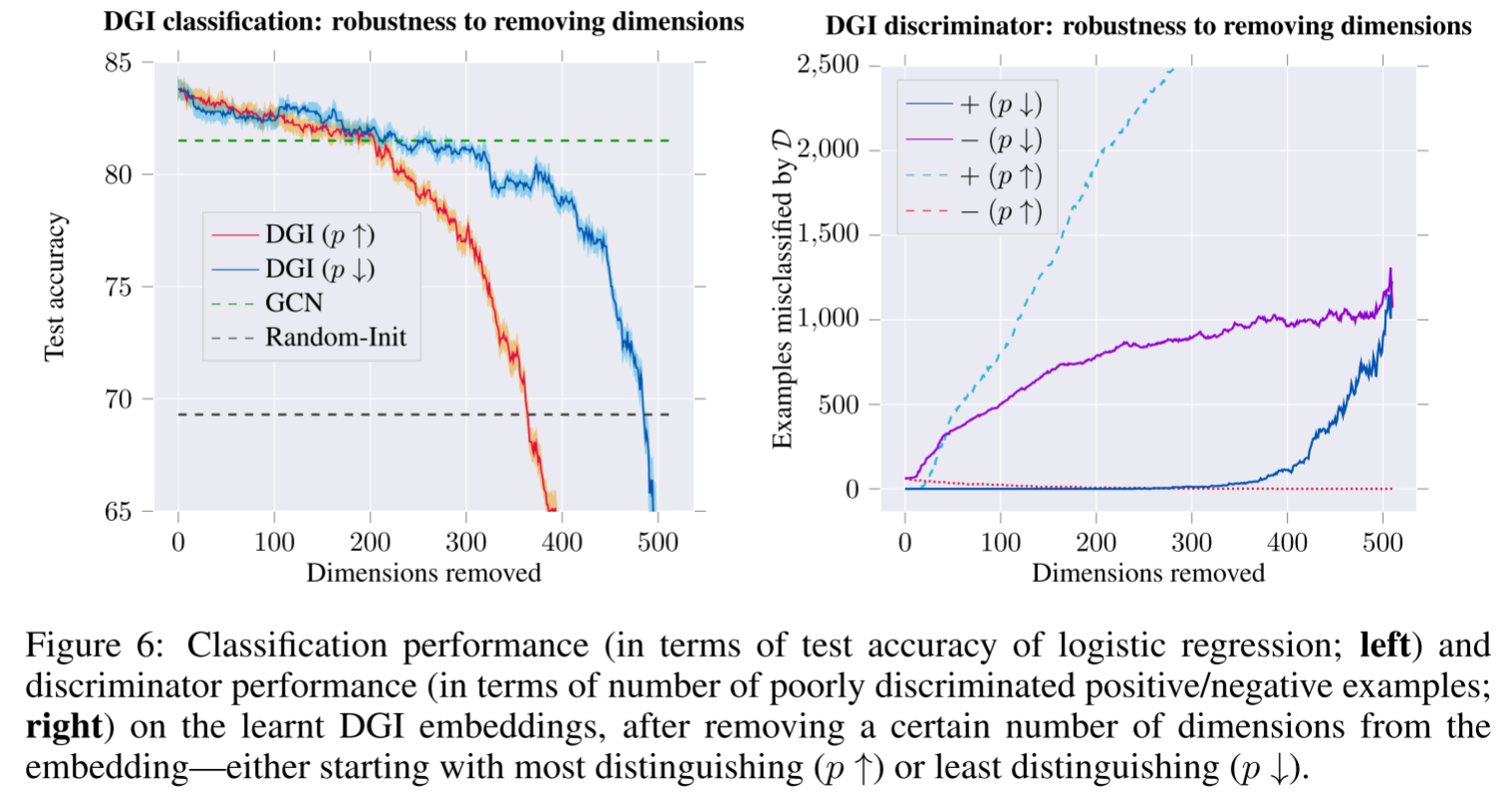
论文进一步实验(Appendix B)表明:
- 移除最可区分的维度对分类影响不大
- 可以去掉一半维度仍保持竞争力!
与其他方法的对比
| 方法 | 目标 | 局限性 | DGI优势 |
|---|---|---|---|
| DeepWalk/Node2Vec | 随机游走邻近性 | 忽视结构,超参数敏感 | 无需随机游走 |
| GCN (supervised) | 监督分类 | 需要标签 | 无监督 |
| GraphSAGE | 邻域聚合 | 需要标签 | 性能更优 |
| Spectral methods | 图自编码 | 不可扩展 | 线性复杂度 |
实现技巧
- Early stopping: 在transductive任务上用训练loss做early stopping,patience=20
- 优化器: Adam,学习率0.001
- 维度设置: F'=512(Pubmed因内存限制用256)
- 初始化: Glorot initialization
- 并行化: 纯矩阵运算,GPU友好
局限与展望
当前局限
- Corruption策略选择:不同任务的最佳corruption不同,需要实验确定
- Readout函数:简单平均pooling可能不适合超大图
- 理论-实践差距:理论假设有限样本,实际是连续表示
- 计算成本:虽然线性,但仍需多次前向传播
未来方向
- 自适应corruption:学习最优的负样本生成策略
- 层次化表示:结合不同尺度的图结构信息
- 动态图扩展:将DGI思想应用于时序图
- 迁移学习:预训练的DGI模型迁移到下游任务
核心要点总结
✅ 创新点 :用互信息最大化代替随机游走,捕捉全局图信息 ✅ 理论保证 :严格证明与互信息的联系 ✅ 性能突破 :无监督超越监督基线 ✅ 计算高效 :线性复杂度,GPU友好 ✅ 通用性强:适用于transductive和inductive场景
DGI为图的无监督学习开辟了新方向,证明了对比学习在图domain的巨大潜力。它不仅在多个benchmark上取得了优异成绩,更重要的是提供了一个优雅的理论框架,启发了后续一系列工作(如GraphCL、BGRL等)。