视频讲解1:https://www.bilibili.com/video/BV1UkwTz9Eux/?pop_share=1&spm_id_from=333.40164.0.0
视频讲解2:https://www.douyin.com/video/7617390988373380404
论文下载:https://arxiv.org/abs/2104.00567
代码下载:https://github.com/wtliao/text2image
论文GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis详解(代码详解)
论文Generative Adversarial Text to Image Synthesis详解
论文DF-GAN: ASimple and Effective Baseline for Text-to-Image Synthesis详解
论文StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks详解
论文HDGAN(Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network)详解
论文AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks详解
论文MirrorGAN: Learning Text-to-image Generation by Redescription详解
基于GAN的文生图(DM-GAN:Dynamic MemoryGenerative Adversarial Networks for Text-to-Image Synthesis)
基于监督对比学习的统一图像生成框架(A Framework For Image Synthesis Using Supervised Contrastive Learning)
本文系统研究了文本到图像生成模型的关键技术与改进方向。针对现有方法的局限性,包括条件批归一化的空间感知不足、文本编码器固定训练的限制、文本-图像融合机制不够深入等问题,提出了一种端到端的可训练框架。创新性地设计了语义-空间感知卷积网络(SSACN),包含弱监督掩码预测器、语义-空间条件批归一化和残差块结构,实现文本信息的精准空间注入。采用单阶段生成架构避免了多阶段模型的缺陷,并结合DAMSM损失提升生成质量。实验验证了该方法在图像质量和文本-图像一致性方面的优势。
目录
[1. 条件批归一化的空间感知不足](#1. 条件批归一化的空间感知不足)
[2. 文本编码器固定训练的限制](#2. 文本编码器固定训练的限制)
[3. 文本-图像融合机制不够深入](#3. 文本-图像融合机制不够深入)
[4. 多阶段生成结构的缺陷](#4. 多阶段生成结构的缺陷)
[1. 端到端的可训练框架](#1. 端到端的可训练框架)
[2. 语义-空间感知卷积网络](#2. 语义-空间感知卷积网络)
[3. 单阶段生成架构](#3. 单阶段生成架构)

现有方法的局限性
1. 条件批归一化的空间感知不足
现有方法在应用条件批归一化时,通常在整个图像特征图上均匀地进行变换,忽视了不同局部区域的语义差异。这种"一刀切"的处理方式无法精确地将文本信息注入到相关的图像区域。
2. 文本编码器固定训练的限制
大多数T2I模型在训练过程中固定预训练文本编码器的参数,这限制了文本表示能力的进一步优化,无法与图像生成器进行协同学习。
3. 文本-图像融合机制不够深入
现有融合方法存在三个主要问题:
简单拼接:早期方法仅将文本向量与图像特征简单连接,融合效果有限
注意力机制计算成本高:随着图像尺寸增大,计算复杂度急剧增加
融合深度不足:条件批归一化仅在少数层应用,文本与图像特征融合不充分
4. 多阶段生成结构的缺陷
堆叠式GAN结构虽然能生成高分辨率图像,但存在训练不稳定、计算资源需求大、误差累积等问题。
提出的方法

1. 端到端的可训练框架
提出完整的端到端训练架构,允许文本编码器与图像生成器协同优化,从而学习更适合图像生成任务的文本表示。
2. 语义-空间感知卷积网络
核心创新是SSACN块,包含三个关键组件:
弱监督掩码预测器:根据当前图像特征预测空间掩码图以弱监督方式训练,无需额外标注动态指导文本信息在 空间上的注入位置和强度
语义-空间条件批归一化:将传统的条件批归一化的拓展
残差块结构: 保持文本无关区域的图像内容不变,防止文本信息过度主导图像生成过程。
3. 单阶段生成架构
采用单生成器-判别器对结构,避免多阶段模型的训练不稳定性和误差累积问题。
具体方法
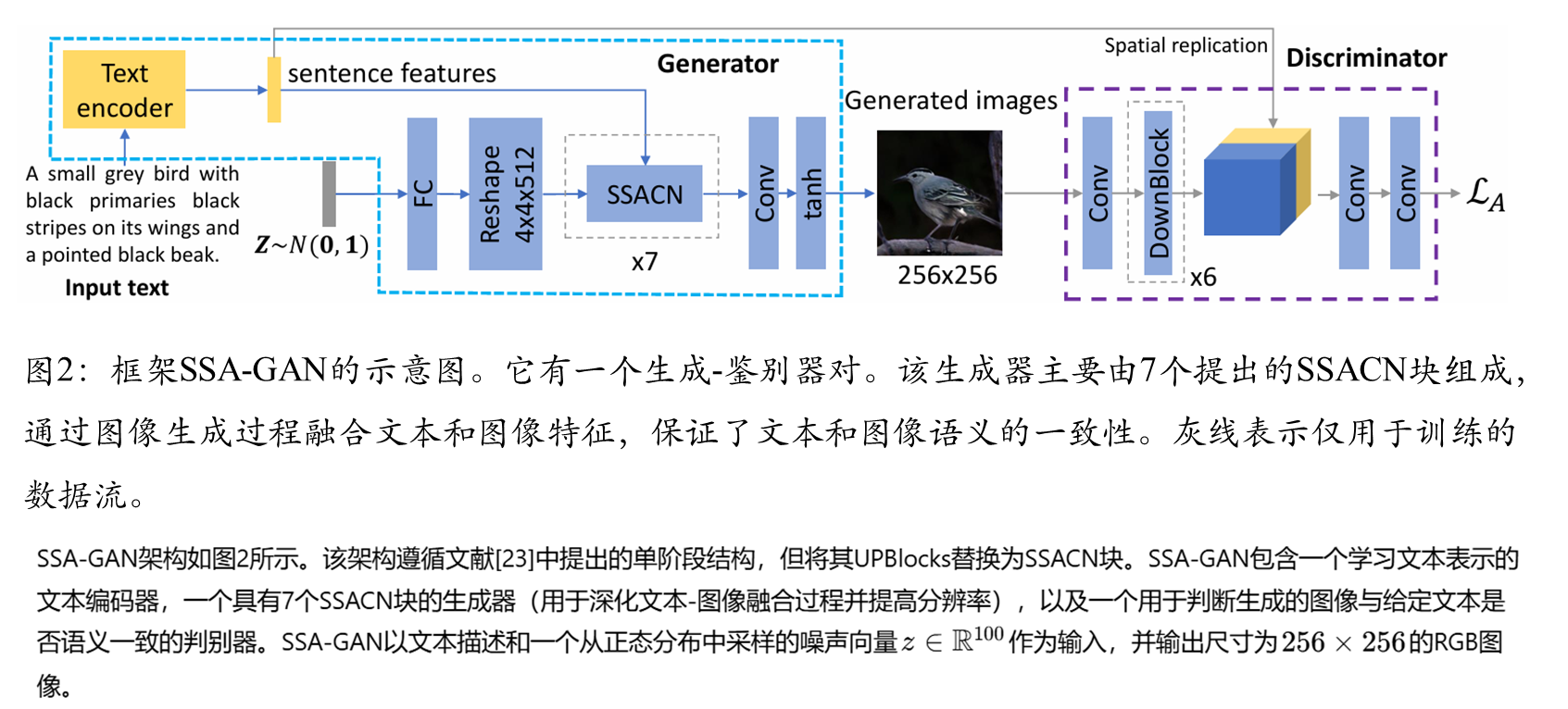
文本编码器
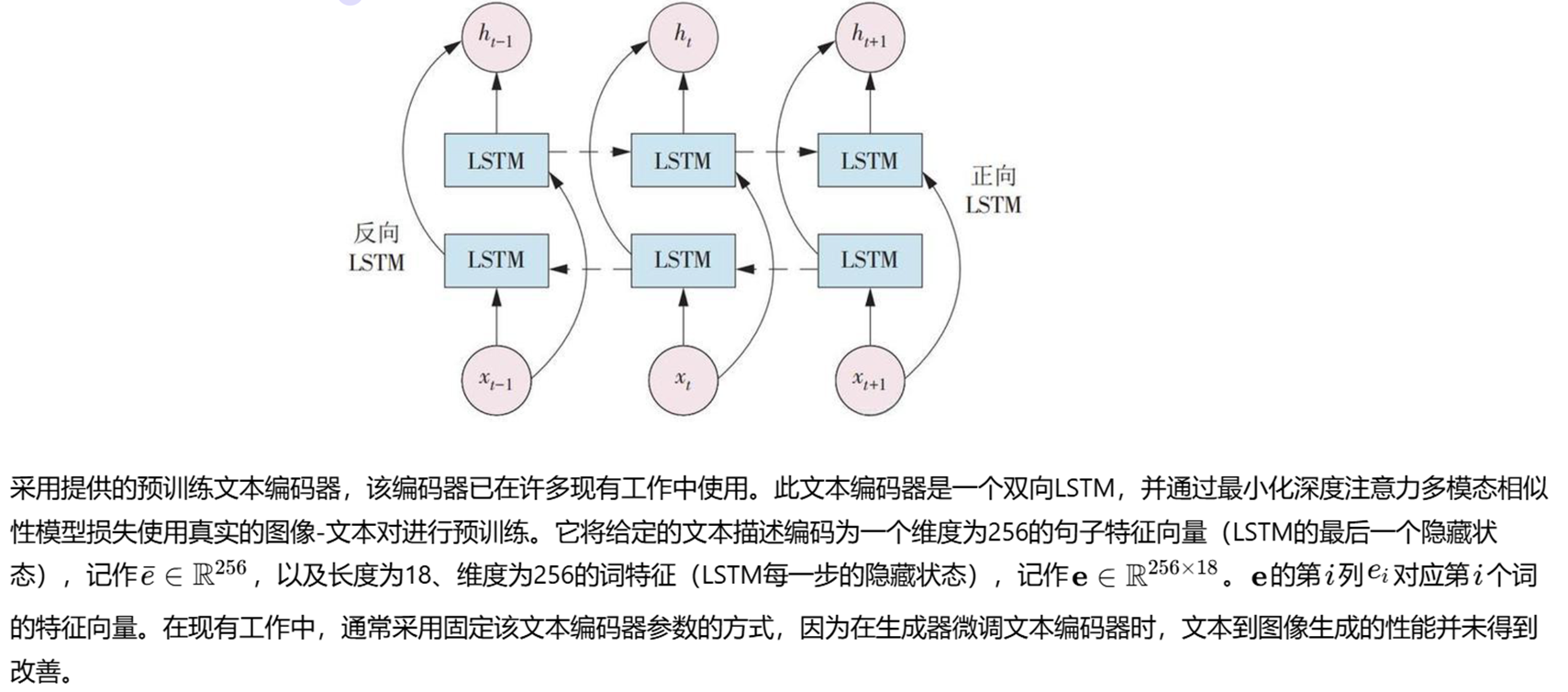
语义空间感知卷积网络
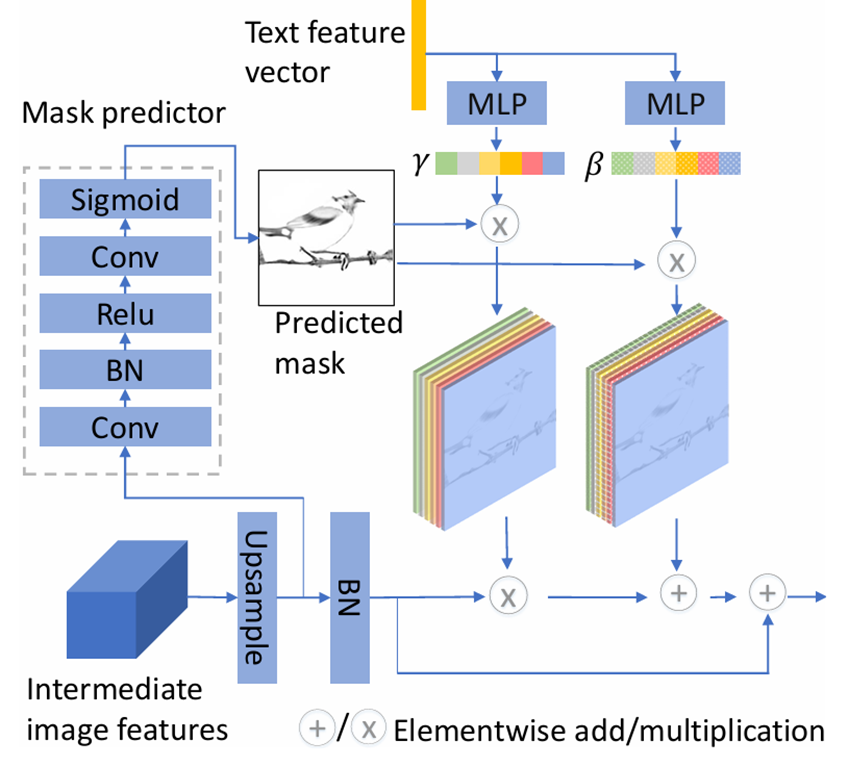

弱监督的掩码预测器

语义条件批量归一化

语义空间条件批量归一化

判别器
基于已有的单向判别器,因其有效且结构简洁。判别器的结构如图2中紫色虚线框所示。它将从生成图像中提取的特征与编码后的文本向量进行拼接,通过两个卷积层计算对抗损失。结合匹配感知零中心梯度惩罚(MA-GP),引导生成器合成更逼真且文本-图像语义一致性更高的图像。为进一步提升生成图像的质量和文本-图像一致性,并辅助文本编码器与生成器联合训练,在框架中加入了广泛应用的深度注意力多模态相似性模型(DAMSM)。
损失函数

MA-GP
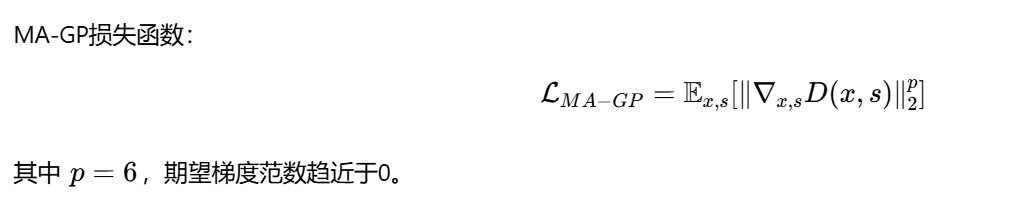
-
稳定训练:防止判别器梯度爆炸
-
改善模式覆盖:帮助生成器学习更好的分布
-
提高匹配质量:增强图像-文本语义对齐
-
零中心约束:避免梯度幅值过大
适用于条件GAN,因为它同时对图像和文本输入的梯度进行约束。
python
interpolated = (imgs.data).requires_grad_() # 启用梯度计算
sent_inter = (sent_emb.data).requires_grad_()
features = netD(interpolated)
out = netD.module.COND_DNET(features, sent_inter)
grads = torch.autograd.grad(
outputs=out, # 需要求导的输出
inputs=(interpolated, sent_inter), # 对这两个输入求导
grad_outputs=torch.ones(out.size()).cuda(), # 输出梯度设为1
retain_graph=True, # 保留计算图
create_graph=True, # 创建高阶导数计算图
only_inputs=True # 只计算对inputs的梯度
)
grad0 = grads[0].view(grads[0].size(0), -1) # 图像梯度展平
grad1 = grads[1].view(grads[1].size(0), -1) # 文本梯度展平
grad = torch.cat((grad0, grad1), dim=1) # 拼接梯度
grad_l2norm = torch.sqrt(torch.sum(grad ** 2, dim=1))
# 惩罚梯度范数偏离0的情况(零中心梯度惩罚)
d_loss_gp = torch.mean((grad_l2norm) ** 6)
d_loss = 2.0 * d_loss_gp
optimizerD.zero_grad()
d_loss.backward()
optimizerD.step()MA-GP与传统梯度惩罚的区别
| 特性 | 传统梯度惩罚 (WGAN-GP) | MA-GP |
|---|---|---|
| 目标 | 使梯度范数接近1 | 使梯度范数接近0 |
| 惩罚项 | (‖∇‖₂ - 1)² | ‖∇‖₂⁶ |
| 输入 | 真实-生成图像插值 | 真实图像+对应文本 |
| 目的 | 满足Lipschitz约束 | 稳定条件GAN训练 |
附录:DAMSM损失



实验结果
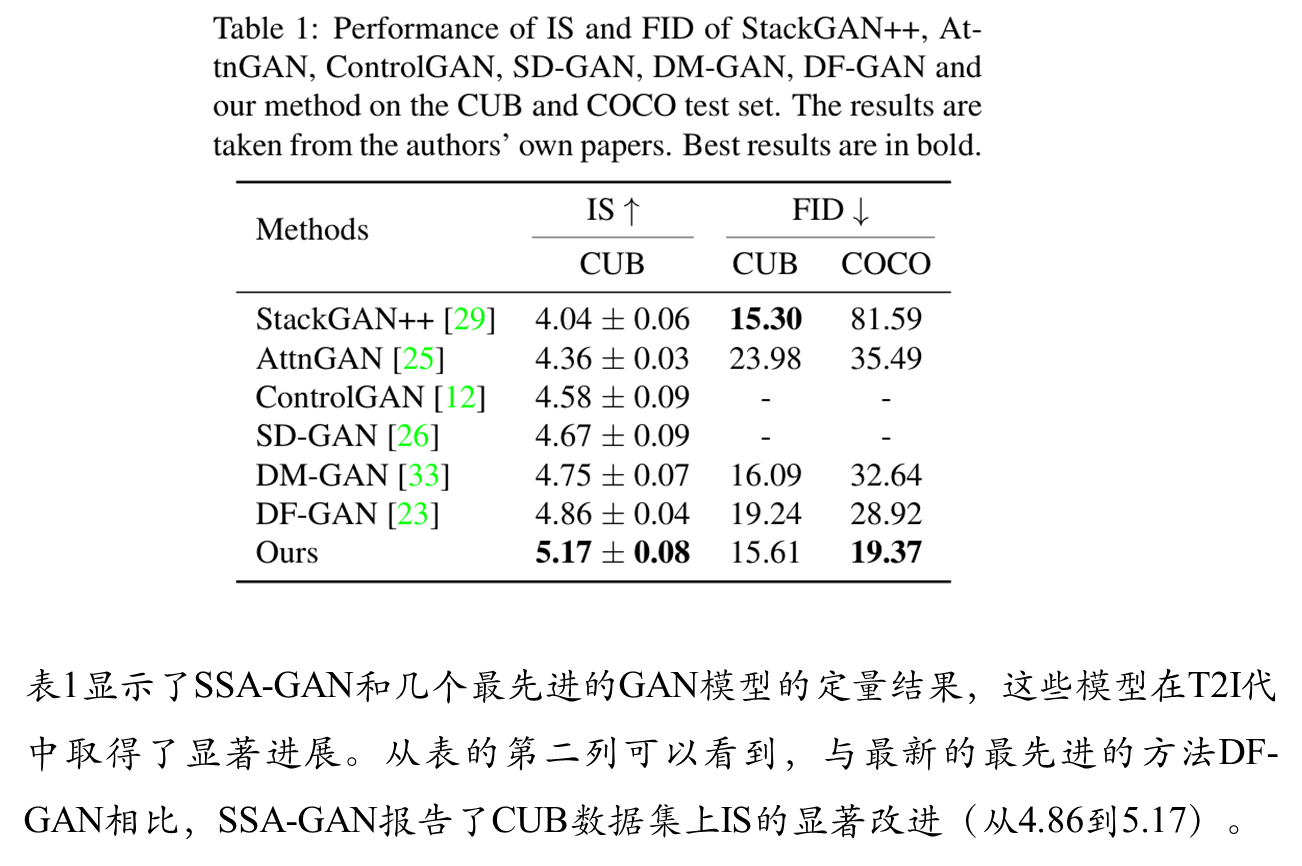
综合比较
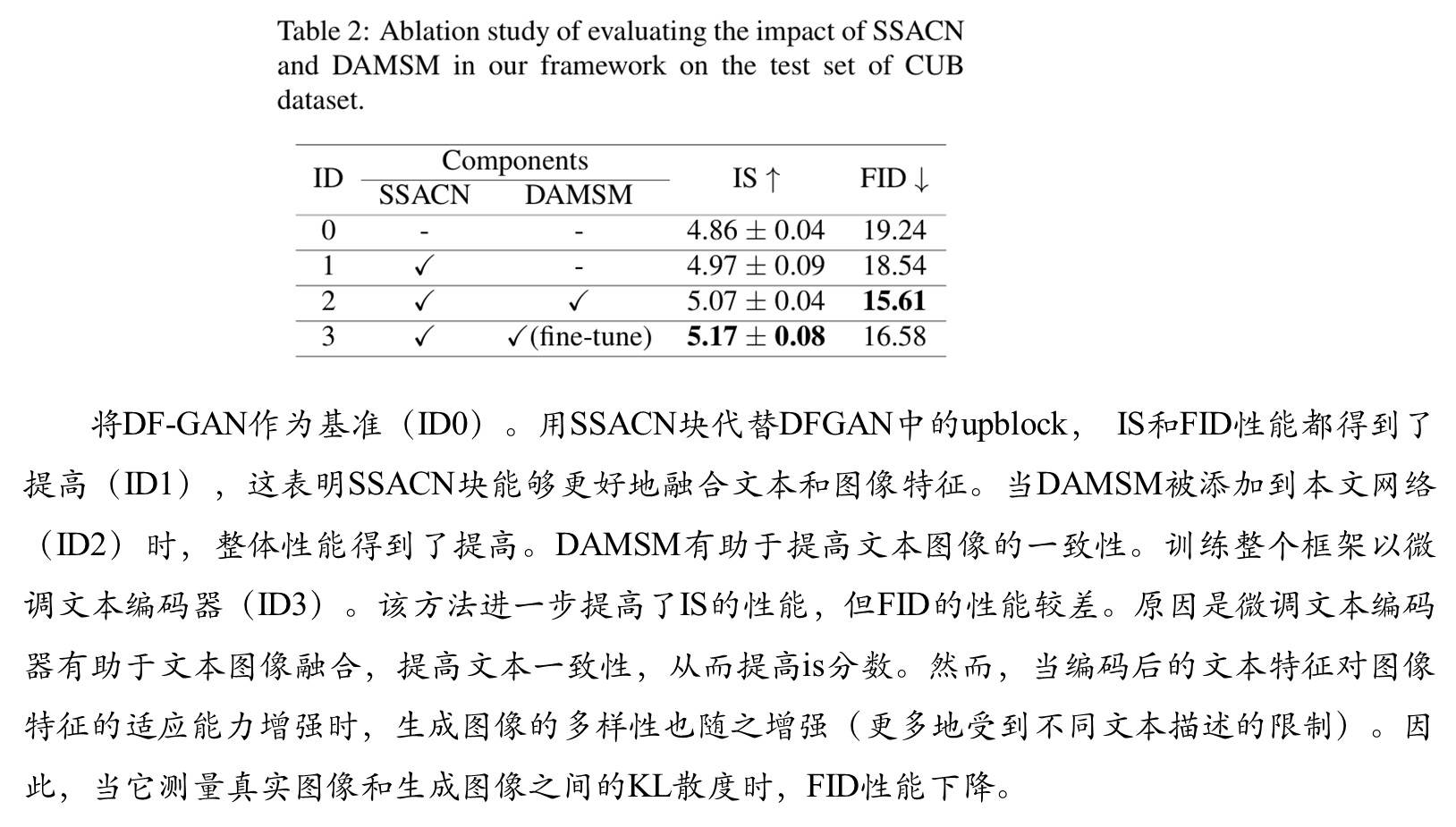
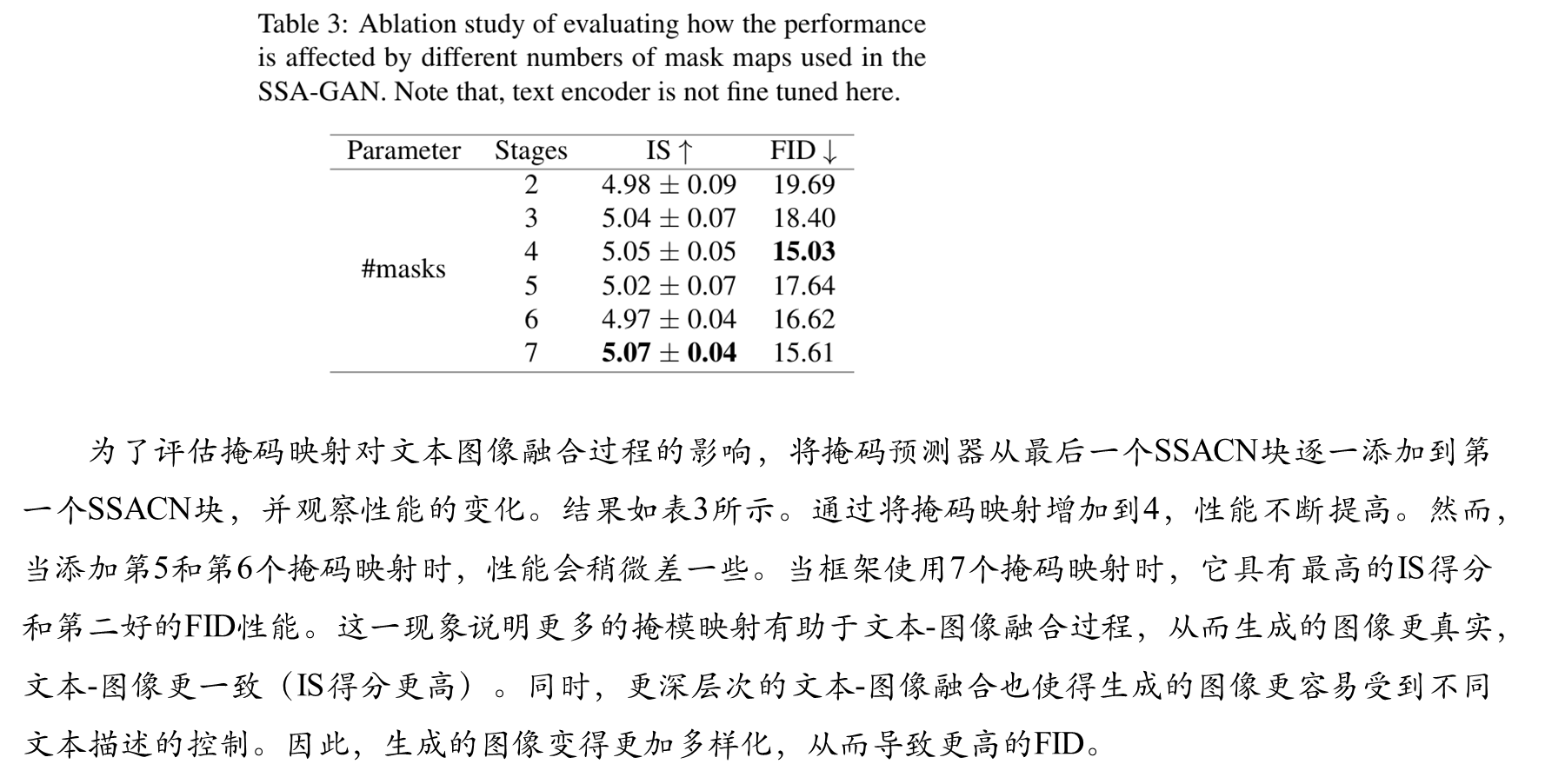
消融实验
可视化结果


