目录
[2、Transformer 中常用的正则化方法](#2、Transformer 中常用的正则化方法)
[1. Dropout(最基础且核心的正则化)](#1. Dropout(最基础且核心的正则化))
[在 Transformer 中的应用位置](#在 Transformer 中的应用位置)
[2. 权重衰减(Weight Decay)](#2. 权重衰减(Weight Decay))
[1. 核心参数](#1. 核心参数)
[2. 多通道卷积](#2. 多通道卷积)
[3. 感受野](#3. 感受野)
[1. 词嵌入(Word Embedding)](#1. 词嵌入(Word Embedding))
[2. RNN(循环神经网络)](#2. RNN(循环神经网络))
[3. 潜空间](#3. 潜空间)
一:从函数到神经网络
(1)神经网络是什么?
首先明确一切都可以用函数来表示,人工智能一开始是符号主义,认为任何关系都可以找到精确的函数,但是后面我们发现这样实在是有限,于是就有了连蒙带猜去猜出函数,努力的去接近它,
激活函数是把线性关系外面套一个函数,变成非线性关系,这就是激活函数,弯的不够灵活就会继续套,但是写出来太难看了,于是有神经网络这样的表达形式
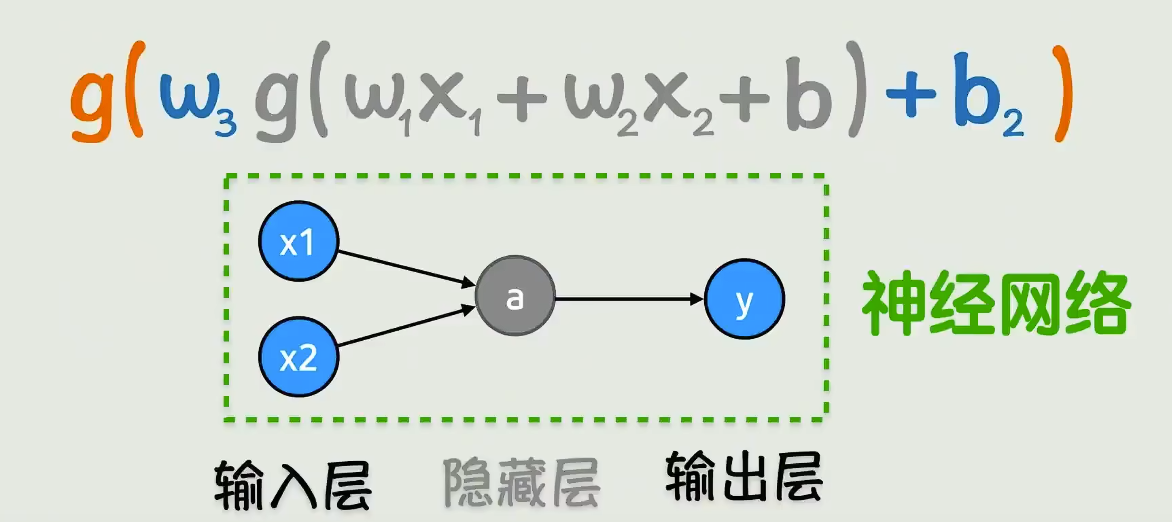
根据已知的x和y,猜出每个w是多少
(2)计算神经网络的参数
什么样的w,b是好的?------让函数的输出尽可能的去拟合真实值
如何判断好不好,我们有了损失函数的概念
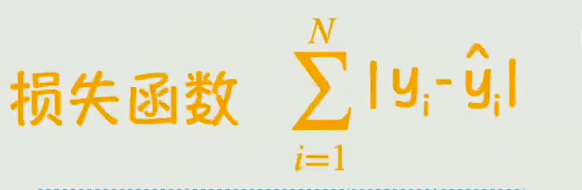
调整一下之后,
 目的就是让这个损失函数最小,导数等于求极值点。
目的就是让这个损失函数最小,导数等于求极值点。
这个过程就是一个线性回归。
笨方法就是不断地尝试,向损失函数变小的地方进行调整,这里可以在偏导数前乘上一个学习率
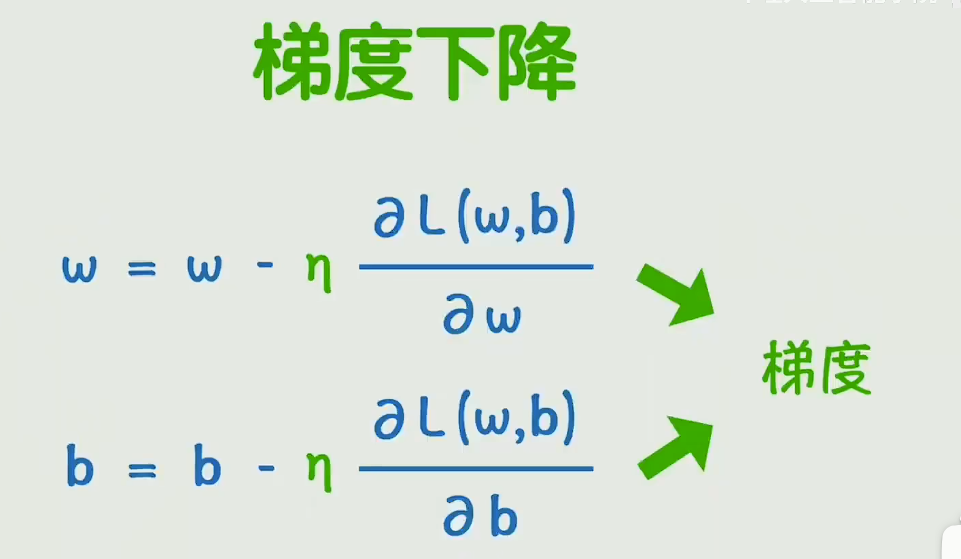
- 梯度:「往哪走更陡」的方向 + 陡峭程度
通俗定义:梯度是一个「向量」(有方向、有大小),它指向损失函数值上升最快的方向;反过来,梯度的反方向就是损失函数值下降最快的方向。
- 梯度下降(Gradient Descent):「一步步下山」找最小误差
通俗定义:沿着「梯度的反方向」,小步慢走,逐步降低损失函数值,最终找到损失最小的点(山底)------ 也就是模型参数最优的位置。
transferom 里的意义:
迁移学习中,预训练模型的参数不是完美适配新任务的,梯度下降就是调整这些参数的核心方法:
计算当前参数下损失函数的梯度(知道「往哪走误差降得最快」);
以「学习率(步长)」为步幅,沿着梯度反方向更新参数;
重复上述步骤,直到损失函数不再下降(走到山底)。
1.总结
神经网络的参数(权重 w、偏置 b)计算,核心是先前向传播算预测、再反向传播更新参数:先随机初始化参数,通过输入数据逐层计算得到预测值,用损失函数算出预测误差;再利用链式法则从输出层往输入层反向求梯度,得到每个参数对误差的影响,最后通过梯度下降,按学习率沿梯度反方向更新 w 和 b,不断迭代让误差变小,最终算出合适的参数。构成了一次训练
(3)调教神经网络的方法------正则化
首先明确概念:
1.过拟合:模型在训练数据上学得太细,把噪声也当成规律,训练表现好,测试表现差。
2.泛化能力:模型对新的、没见过的数据也能准确预测的能力。
一句话:"过拟合就是死记硬背,泛化就是真正学会。"
正则化(Regularization)是深度学习中防止模型过拟合、提升泛化能力的核心手段。在 Transformer 架构中,正则化策略既沿用了深度学习的通用方法,也针对自注意力机制的特性做了专门设计。
1、正则化的核心目标
在 Transformer 训练中,模型参数规模大(如 BERT-base 有 1.1 亿参数),极易出现过拟合(训练集效果好、测试集效果差)。正则化的核心作用:
- 限制模型复杂度,避免参数过度拟合训练数据中的噪声;
- 提升模型对未见过的数据的泛化能力;
- 稳定训练过程,防止梯度爆炸/消失。
2、Transformer 中常用的正则化方法
1. Dropout(最基础且核心的正则化)
原理
在训练过程中,以一定概率 p 随机将部分神经元的输出置为 0,迫使模型不依赖单一神经元,学习更鲁棒的特征。测试时恢复所有神经元,输出按概率 p 缩放(或训练时缩放)。
在 Transformer 中的应用位置
Transformer 几乎在所有关键层后都加入了 Dropout,核心位置包括:
- 自注意力层的输出(Attention Output)后;
- 前馈神经网络(FFN)的输出后;
- 词嵌入(Embedding)层后(含位置编码);
- 层归一化(Layer Normalization)前/后(不同实现略有差异)。
关键参数
Transformer 论文中默认 dropout=0.1,实际应用中可根据数据集大小调整
2. 权重衰减(Weight Decay)
原理
也叫 L2 正则化,在损失函数中加入参数的 L2 范数惩罚项,迫使参数值尽可能小(避免参数过大导致模型对输入敏感)。
损失函数公式:Loss = Loss_{original} + \\lambda \\times \\sum \|\|w\|\|\^2(\\lambda 为权重衰减系数)。
二:从矩阵到CNN
在没有卷积核之前,全连接网络虽然也能改权重,但有三个致命问题:参数太多、破坏图像空间结构、每个位置都要单独学一套权重,根本没法高效学图像。
(1)卷积核本质
而卷积核就是给"改权重"加了两个关键规则:局部连接 + 权重共享------只看图片一小块区域、同一套小权重在整张图上反复用,这样参数极少、能学到边缘/纹理等图像特征、计算量小到能真正训练,所以CNN是用更聪明、更适合图像的方式改权重,这就是卷积核必须存在的原因。
卷积核是带权重的滑动窗口矩阵,CNN中通过互相关运算(元素相乘求和)提取局部特征,区别于纯数学卷积(无需翻转)。
核心公式(二维):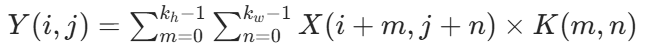
(2)基础矩阵运算示例(2×2卷积核)
输入X(3×3) 卷积核K(2×2) 输出Y(2×2)
[[1,2,3], [[1,0], [[6,8],
[4,5,6], [0,1]] [12,14]]
[7,8,9]]计算逻辑:滑动卷积核,逐位置元素相乘后求和(如左上角:1×1+2×0+4×0+5×1=6)。
(3)CNN中的卷积核扩展
1. 核心参数
|-----------------|-----------------------|
| 参数 | 作用 |
| stride | 滑动步长(默认1,步长2输出尺寸减半) |
| padding | 边缘补0(避免边缘特征丢失,控制输出尺寸) |
| in/out_channels | 输入/输出通道数(卷积核数量=输出通道数) |
2. 多通道卷积
输入:H×W×C_in(如RGB图224×224×3),卷积核:k×k×C_in,多个卷积核输出堆叠为H'×W'×C_out。
3. 感受野
特征图1个像素对应输入的区域大小,多层小卷积核(3×3)堆叠可扩大感受野,且参数更少。
(4)卷积核参数状态(核心区分)
|-----------|----------|-----------------|
| 场景 | 参数状态 | 关键说明 |
| 传统图像处理 | 完全已知 | 人工设计固定值(如边缘检测核) |
| CNN训练前 | 完全未知 | 随机初始化,无实际意义 |
| CNN训练中 | 逐步确定 | 反向传播更新,适配任务 |
| CNN推理/训练后 | 固定已知 | 加载保存的参数,用于预测 |
- 卷积核核心是滑动窗口的矩阵相乘求和,CNN中通过多通道、步长/填充适配图像特征提取;
- 传统卷积核参数人工预设已知,CNN卷积核参数训练前随机未知,训练后固定已知;
- 小卷积核堆叠是CNN的核心设计,兼顾感受野和参数效率。
三:从词嵌入到RNN
1. 词嵌入(Word Embedding)
把单词变成向量,让计算机能处理语言。
- 作用:
- 把 one-hot 这种稀疏向量,变成低维、稠密、有意义的向量
- 语义相近的词,向量距离近
- 本质:把语言映射到连续向量空间。
2. RNN(循环神经网络)
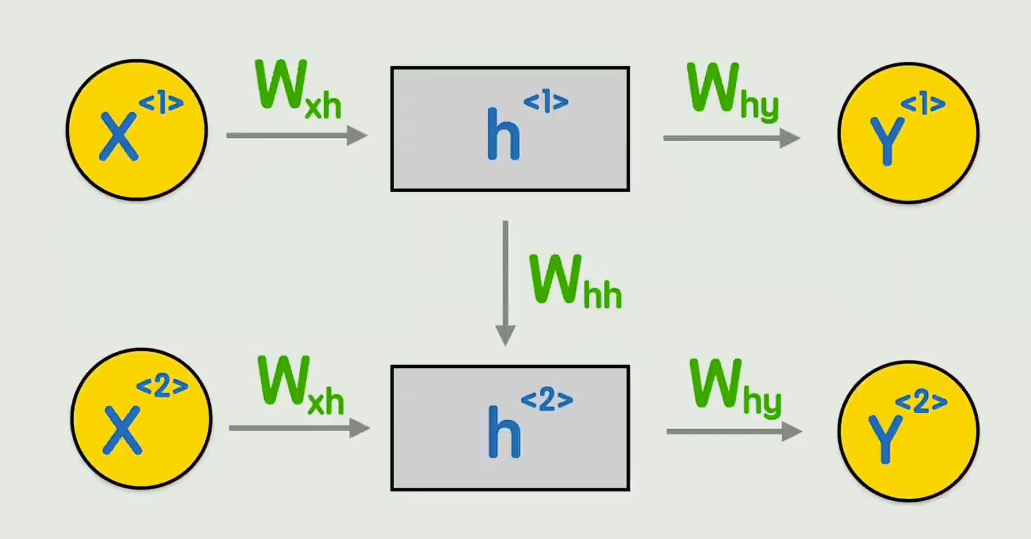
- 专门处理序列数据:文字、语音、时间序列。
- 核心思想:
- 每一步输入当前词 + 上一步的状态
- 把过去信息记在状态里,传给下一步
- 问题:长序列容易梯度消失,记不住很早的信息。
3. 潜空间
- 就是 RNN 里隐藏状态所在的向量空间。
- 作用:
- 把整段序列的语义压缩成一个向量
- 相当于模型对句子的理解、记忆、总结
- 可以理解为:语言在模型脑子里的抽象。
词嵌入把单词变成向量,RNN 一步步把序列信息压缩进隐藏状态,最终得到的潜空间向量,就是模型对整段语言的理解。