💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》
🌸Yupureki🌸的简介:

目录
[1. 使用基数树进行优化](#1. 使用基数树进行优化)
[2. 性能测试](#2. 性能测试)
完整项目链接![]() https://github.com/Yupureki-code/ConcurrentMemoryPool
https://github.com/Yupureki-code/ConcurrentMemoryPool
1. 使用基数树进行优化
现内存池中存在一个比较严重的性能问题:PageCache需要加锁。特别是查找页ID到Span的映射时
因为PageCache中不断存在修改的情况,如果在一个线程查询的过程中,另一个线程同时把这个Span给拿走了,那就出大问题了。同时这把锁直接把整个PageCache给锁住了,因此对锁的竞争会很严重,同时没抢到锁的线程会一直在外面干瞪眼,这造成了严重的性能浪费
因此,Google的大佬们使用了一个新的数据结构:基数树
感兴趣的可以了解:Linux Kernel:内核数据结构之基数树(Radix Tree) - 知乎
基数树,写之前会提前开好空间,写数据过程中,不会动结构。
因为读写是分离的。线程1对一个位置读写的时候,线程2不可能对这个位置读写。
TCMalloc源码中有三个基数树的模板,适用于不同的场景,这里我们只使用前两个模板
注意:该项目暂时只能在32位平台下使用基数树
TCMalloc基数树(略微修改):
cpp
#pragma once
#include "Common.h"
#include "ObjectPool.h"
// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:
static const int LENGTH = 1 << BITS;
void** array_;
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {
explicit TCMalloc_PageMap1() {
//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));
size_t size = sizeof(void*) << BITS;
size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);
array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);
memset(array_, 0, sizeof(void*) << BITS);
}
// Return the current value for KEY. Returns NULL if not yet set,
// or if k is out of range.
void* get(Number k) const {
if ((k >> BITS) > 0) {
return NULL;
}
return array_[k];
}
// REQUIRES "k" is in range "[0,2^BITS-1]".
// REQUIRES "k" has been ensured before.
//
// Sets the value 'v' for key 'k'.
void set(Number k, void* v) {
array_[k] = v;
}
};
// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:
// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.
static const PAGE_ID ROOT_BITS = 5;
static const PAGE_ID ROOT_LENGTH = (PAGE_ID)1 << ROOT_BITS;
static const PAGE_ID LEAF_BITS = BITS - ROOT_BITS;
static const PAGE_ID LEAF_LENGTH = (PAGE_ID)1 << LEAF_BITS;
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes
void* (*allocator_)(size_t); // Memory allocator
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {
explicit TCMalloc_PageMap2() {
//allocator_ = allocator;
memset(root_, 0, sizeof(root_));
PreallocateMoreMemory();
}
void* get(Number k) const {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 || root_[i1] == NULL) {
return NULL;
}
return root_[i1]->values[i2];
}
void set(Number k, void* v) {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
// Defensive checks: k must fit in BITS and i1 must be within root range
if ((k >> BITS) != 0 || i1 >= ROOT_LENGTH) {
// Out of range key: ignore or handle as appropriate
return;
}
// Ensure leaf exists. Ensure() is responsible for allocating the leaf
// and zero-initializing it. If Ensure fails, avoid writing.
if (root_[i1] == NULL) {
if (!Ensure(k, 1)) {
return;
}
}
// Final bounds check for i2 to avoid corrupting memory if constants
// are misconfigured or subject to UB elsewhere.
if (i2 >= LEAF_LENGTH) {
return;
}
root_[i1]->values[i2] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS;
// Check for overflow
if (i1 >= ROOT_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_[i1] == NULL) {
//Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
//if (leaf == NULL) return false;
static ObjectPool<Leaf> leafPool;
Leaf* leaf = (Leaf*)leafPool.New();
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
// Allocate enough to keep track of all possible pages
Ensure(0, (PAGE_ID)1 << BITS);
}
};
// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:
// How many bits should we consume at each interior level
static const int INTERIOR_BITS = (BITS + 2) / 3; // Round-up
static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;
// How many bits should we consume at leaf level
static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Interior node
struct Node {
Node* ptrs[INTERIOR_LENGTH];
};
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Node* root_; // Root of radix tree
void* (*allocator_)(size_t); // Memory allocator
Node* NewNode() {
Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));
if (result != NULL) {
memset(result, 0, sizeof(*result));
}
return result;
}
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {
allocator_ = allocator;
root_ = NewNode();
}
void* get(Number k) const {
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 ||
root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {
return NULL;
}
return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3];
}
void set(Number k, void* v) {
ASSERT(k >> BITS == 0);
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
// Check for overflow
if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_->ptrs[i1] == NULL) {
Node* n = NewNode();
if (n == NULL) return false;
root_->ptrs[i1] = n;
}
// Make leaf node if necessary
if (root_->ptrs[i1]->ptrs[i2] == NULL) {
Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
if (leaf == NULL) return false;
memset(leaf, 0, sizeof(*leaf));
root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
}
};我们使用基数树替换SpanMap原本的哈希表结构
cpp
TCMalloc_PageMap2<32 - PAGE_SHIFT> _id_span_map;同时部分接口也需要替换:
set(key,value)
如:
cpp
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0);
if (k > NPAGES - 1)
{
......
_id_span_map.set(id, span);
return span;
}
if (!_spanlists[k].Empty())
{
Span* kspan = _spanlists[k].PopFront();
for (size_t i = 0; i < kspan->_num; i++)
_id_span_map.set(kspan->_page_id + i, kspan);
return kspan;
}
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanlists[i].Empty())
{
......
_id_span_map.set(nspan->_page_id,nspan);
_id_span_map.set(nspan->_page_id + nspan->_num - 1,nspan);
for (size_t i = 0; i < kspan->_num; i++)
_id_span_map.set(kspan->_page_id + i,kspan);
return kspan;
}
}
......
return NewSpan(k);
}get(key)返回值:value
如:
cpp
Span* PageCache::SpanMapFindObject(void* ptr)
{
PAGE_ID id = ((PAGE_ID)ptr >> PAGE_SHIFT);
Span* span = (Span*)_id_span_map.get(id);
assert(span != nullptr);
return span;
}2. 性能测试
cpp
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(malloc(16));
v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
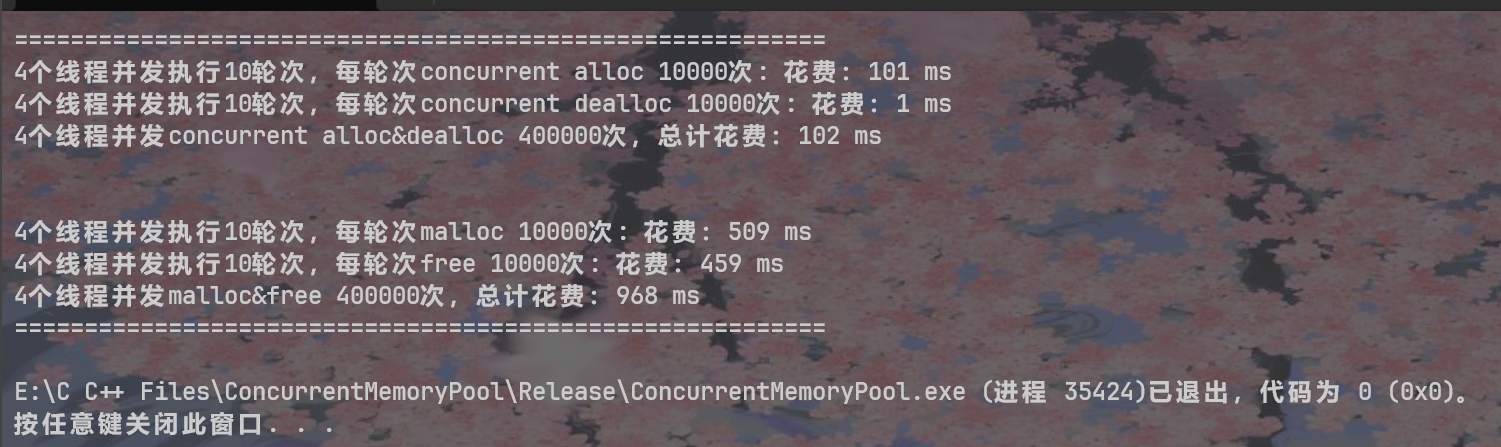
printf("%zu个线程并发执行%zu轮次,每轮次malloc %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%zu个线程并发执行%zu轮次,每轮次free %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%zu个线程并发malloc&free %zu次,总计花费:%zu ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(ConcurrentAlloc(16));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentDealloc(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%zu个线程并发执行%zu轮次,每轮次concurrent alloc %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%zu个线程并发执行%zu轮次,每轮次concurrent dealloc %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%zu个线程并发concurrent alloc&dealloc %zu次,总计花费:%zu ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
int main()
{
size_t n = 10000;
std::cout << "==========================================================" << std::endl;
BenchmarkConcurrentMalloc(n, 4, 10);
std::cout << std::endl << std::endl;
BenchmarkMalloc(n, 4, 10);
std::cout << "==========================================================" << std::endl;
return 0;
}