这几个论文都是增量式重建的方法,TTT3R是建立在CUT3R上的改进,区别于VGGT那一类全局重建的方法。
全局重建是离线、批处理、需要一次收集所有图像的,模型通过全局注意力(Transformer)共同处理所有视图,并同时输出所有帧的位姿和几何。虽然全局重建能够实现所有帧可交互,全连接,充分利用所有帧上下文,但复杂度为,内存与计算量随总帧数平方级增长,几十帧以上就很难推理。
增量式在线重建是基于RNN循环机制的网络,维护一个固定长度的隐式记忆状态,新帧只与当前状态交互,并更新他。是一种在线、流式、增量式的方法,图像一帧一帧输入,模型实时输出当前帧的位姿和几何,随输入演化,支持无限长度的视频流。增量式方法是单向的,因果的,当前帧只能访问过去和现在信息,无法利用未来信息,并且复杂度仅为,不随序列长度增长,内存占用恒定且低。
目录
一、Spann3R
1、概述
Spann3R 的目标是基于 DUSt3R 的范式 ,构建一个能够进行在线、增量式 密集3D重建的模型。其核心创新在于引入了一个外部空间记忆 ,用于跟踪和存储所有先前的相关3D信息。模型通过查询这个记忆来预测下一帧在全局坐标系中的3D结构,从而无需进行基于优化的全局对齐,实现了单次前向传播即可完成的增量重建。
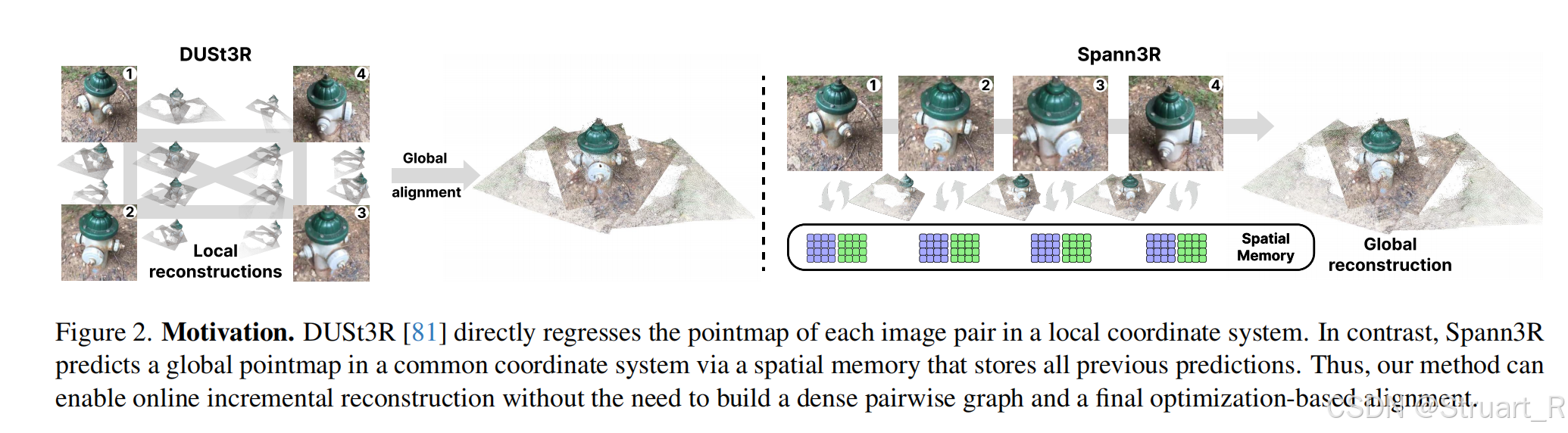
2、pipeline
(1)第一帧:
第一帧只过ViT encoder编码,得到(包括视觉特征,位置编码,图像尺寸)

(2)第一次DUSt3R过程:
第二帧经过ViT编码得到 ,(包括视觉特征,位置编码,图像尺寸),然后把这两个特征输入到DUSt3R的解码器中,输出dec1,dec2。(这就是个解码后的隐式空间)
dec1, dec2 = self.decode(feat1, pos1, feat2, pos2)
然后生成查询键,也就是将dec与对应的feat拼接,进行编码。
feat_k1 = self.encode_feat_key(feat1, dec1-1, 1)
feat_k2 = self.encode_feat_key(feat2, dec2-1, 2)
之后进行3D回归和输出,但是此时res1是第一帧的点云pts3d和置信度conf,这个是初步预测的,res2是第二帧的点云,初步预测的。
res1 = self.downstream_head(dec1, shape1, 1)
res2 = self.downstream_head(dec2, shape2, 2)
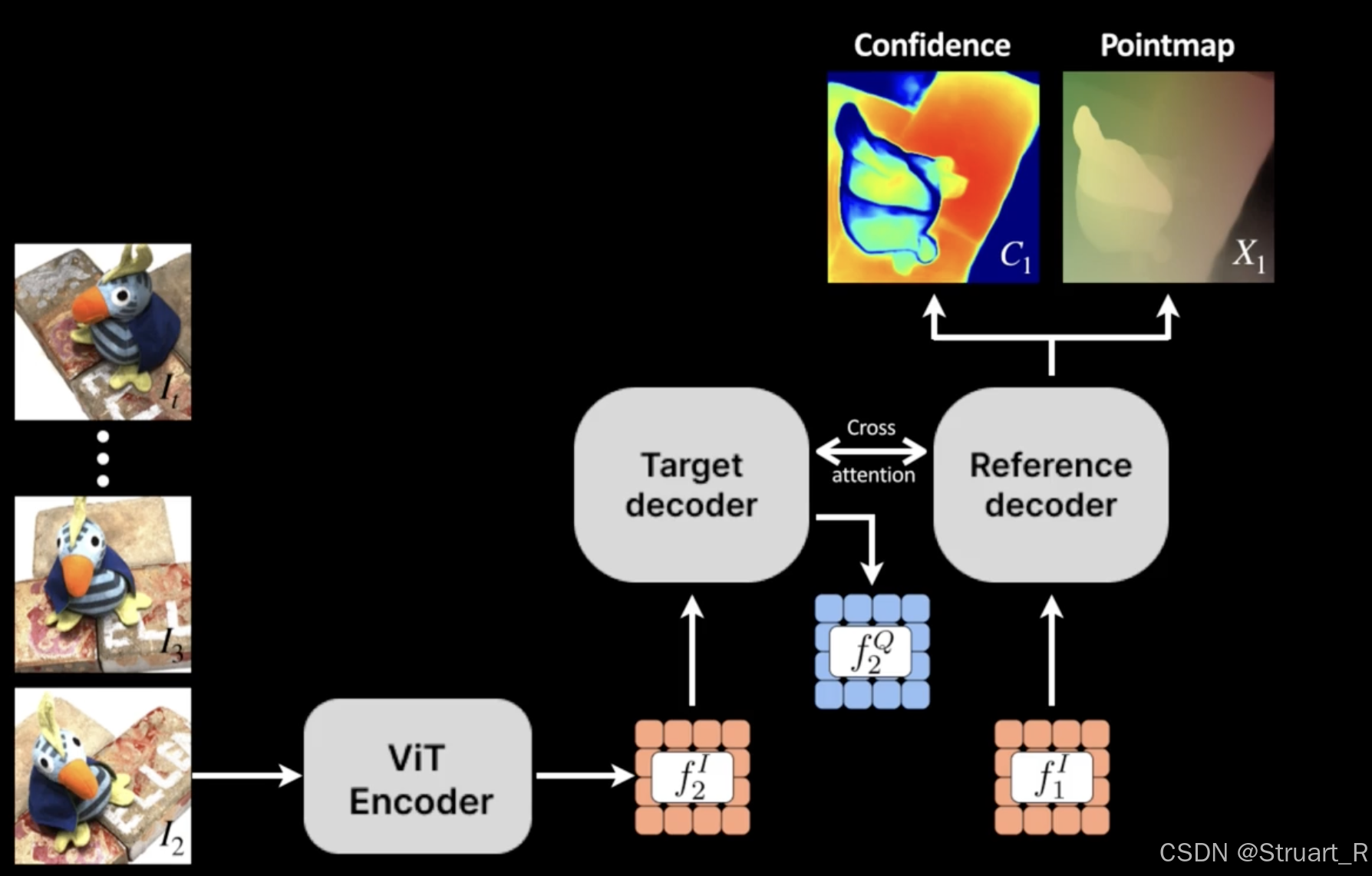
然后进行记忆编码,把第一帧的解码特征,与第一帧的回归点云信息编码为记忆值cur_v。并且将(feat_k1, cur_v+feat_k1)存入记忆库中,
cur_v = self.encode_cur_value(res1, dec1, pos1, shape1)
if self.training:
sp_mem.add_mem(feat_k1, cur_v+feat_k1)
最后保存结果res1到preds列表中。
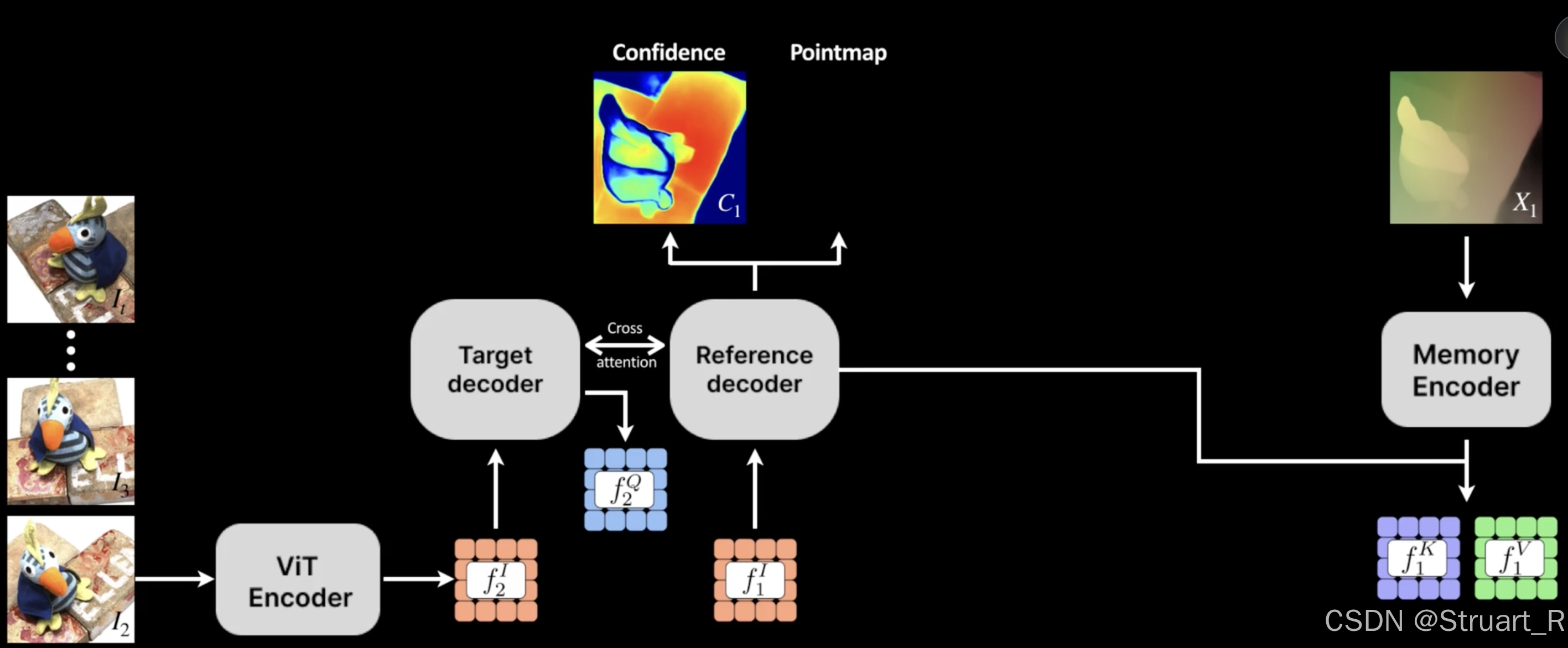
(3)第二次DUSt3R过程:
输入第三帧经过编码得到,复用第一次DUSt3R过程中的feat_k2查询,查询mem得到feat_fuse,融合特征feat_fuse与第三帧
过DUSt3R编码器。得到新的dec1和dec2。
dec1, dec2 = self.decode(feat_fuse, pos1, feat2, pos2)
再次编码查询,得到feat_k1,feat_k2.
feat_k1 = self.encode_feat_key(feat_fuse, dec1-1, 1)
feat_k2 = self.encode_feat_key(feat2, dec2-1, 2)
其中dec1和dec2再次解码,得到第二帧的优化后点云,和第三帧未优化点云。
res1 = self.downstream_head(dec1, shape1, 1)
res2 = self.downstream_head(dec2, shape2, 2)
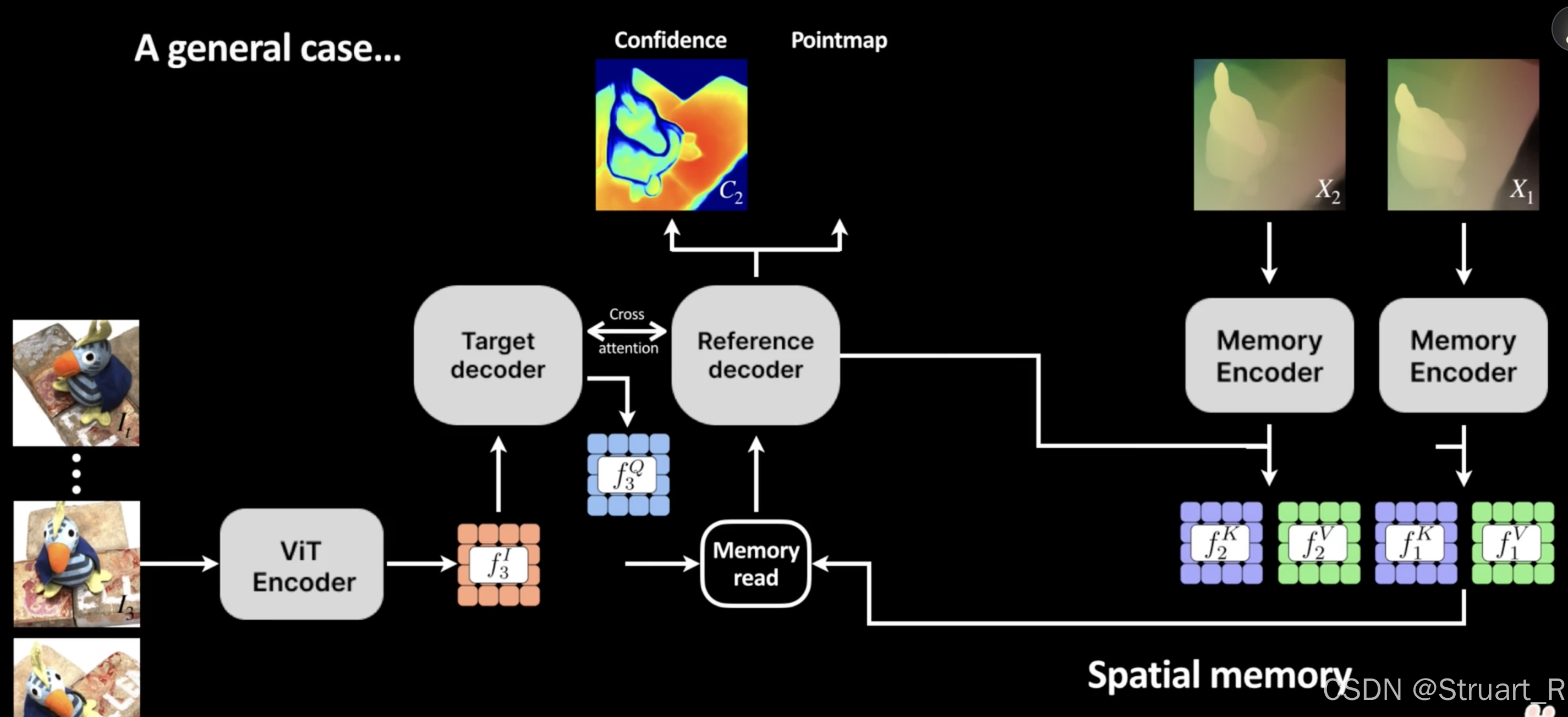
之后重复同样的操作。
流程表格:
|-------|----------|----------|------------|------------|--------------------|
| 循环(i) | 本循环view1 | 本循环view2 | 本循环输出的res1 | 本循环输出的res2 | 备注 |
| 0 | f0 | f1 | f0初步点云 | f1初步点云 | 初始化,记忆库存入f0 |
| 1 | f1 | f2 | f1优化点云 | f2初步点云 | 利用f0记忆优化f1,存入f1 |
| 2 | f2 | f3 | f2优化点云 | f3优化点云 | 利用f0,f1记忆优化f2,存入f2 |
这里解释一下查询工作是怎么做的
feat_fuse = sp_mem.memory_read(feat_k2, res=True)
输入查询特征feat_k2(Query),这里有点矛盾,明明是Query,但是代码叫feat_k2。
查询实现就是cross-attn.方法,feat_k2(Query)与记忆库中的mem_k(key)计算点积相似度affinity,并经过softmax归一化得到注意力权重attn,该权重形状为batch, num_query_tokens, num_memory_tokens,精确量化了当前查询的每一个token与记忆库中每一个token的关联程度 。
之后进行einsum运算,决定从mem_v中提取多少,提取哪些信息来合成输出查询结果out,也就是论文中这个公式。
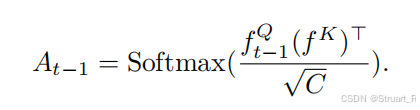
python
def memory_read(self, feat, res=True): # feat 就是"查询特征"
# 1. 计算相似度(Affinity/Attention权重)
affinity = torch.einsum('bpc,bxc->bpx',
self.norm_q(feat), # 对查询特征(Q)做归一化
self.norm_k(self.mem_k.reshape(...)) # 对记忆键(K)做归一化
)
affinity /= torch.sqrt(torch.tensor(feat.shape[-1]).float())
# 2. 生成注意力权重 (attn)
attn = torch.softmax(affinity, dim=-1) # 在记忆序列维度归一化
# 3. 使用attn作为权重,对记忆值(V)进行加权求和,完成"读取"
out = torch.einsum('bpx,bxc->bpc',
attn, # 注意力权重:决定每个记忆值的重要性
self.norm_v(self.mem_v.reshape(...)) # 记忆值
)
if res:
out = out + feat # 残差连接
return out这里解释一下存储记忆是怎么做的
存储记忆核心是add_mem_check函数,以避免冗余 和管理内存大小 为核心原则,来决定是否及如何将新的记忆存入 mem_k和 mem_v。以sp_mem.add_mem_check(feat_k1, cur_v+feat_k1)调用为例。
首先调用check_sim函数判断新来的记忆键feat_k1与最近几帧的记忆中的键对比是否相似,如果高度相似,那么我们选择跳过存储。
python
def check_sim(self, feat_k, thresh=0.7):
# 与工作记忆(最近 W 帧)中的所有键计算余弦相似度
corr = torch.einsum('bpc,btpc->btp', feat_k_norm, wm_norm)
mean_corr = torch.mean(corr, dim=-1)
# 如果最大平均相似度超过阈值,则认为冗余,返回True
return mean_corr.max() > threshadd_mem函数,将feat_k直接拼接到self.mem_k张量末尾,feat_v也拼接到self.mem_v张量末尾。
python
def add_mem(self, feat_k, feat_v, pts_cur=None, img_cur=None):
# 首次调用时初始化计数器和注意力累加器
if self.mem_count is None:
self.mem_count = torch.zeros_like(feat_k[:, :, :1])
self.mem_attn = torch.zeros_like(feat_k[:, :, :1])
else:
# 已有记忆时,旧记忆的"年龄"+1,并为新记忆初始化计数
self.mem_count += 1
self.mem_count = torch.cat((self.mem_count, torch.zeros_like(feat_k[:, :, :1])), dim=1)
self.mem_attn = torch.cat((self.mem_attn, torch.zeros_like(feat_k[:, :, :1])), dim=1)
# 核心操作:将新的键和值拼接到现有记忆的末尾
self.add_mem_k(feat_k) # 更新 self.mem_k
self.add_mem_v(feat_v) # 更新 self.mem_v
# ... (保存点和图像用于可视化等)对于长期记忆tokens数超过long_mem_size(4000个)时触发,根据历史累积注意力权重和访问次数来计算权重,被频繁查询的tokens被认为重要,另外对于新记忆赋于最大值,保证最近帧不被提出。只保留全局最重要的top_k个tokens,丢弃其余。
python
def memory_prune(self):
# 计算每个记忆令牌的"重要性分数":平均注意力权重
weights = self.mem_attn / self.mem_count
# 确保工作记忆中的令牌(较新的)不被剔除(通过赋予极大权重)
weights[self.mem_count < self.work_mem_size+5] = 1e8
# 保留重要性最高的 top_k 个令牌
top_k_values, top_k_indices = torch.topk(weights, self.top_k, dim=1)
# 根据索引,从 mem_k, mem_v, mem_attn, mem_count 中收集保留的令牌
self.mem_k = torch.gather(self.mem_k, -2, top_k_indices_expanded)
self.mem_v = torch.gather(self.mem_v, -2, top_k_indices_expanded)
# ...模型损失:DUSt3R的累积损失(依赖置信度的重建损失)+尺度损失(鼓励预测的尺度小于真实尺度)
DUSt3R的累积损失:加权回归损失 。模型被鼓励为预测更准确的区域(通常对应较小的深度值)分配更高的置信度,因为深度值大的区域不确定性通常更高。损失的第二项
作为一个正则项,防止模型将所有置信度都设为零来作弊。
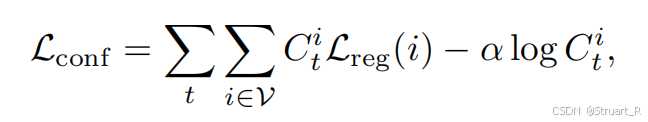
尺度损失:单向铰链损失 。它仅当预测的点云平均尺度大于真实尺度时才产生惩罚。这"鼓励预测的尺度小于真实尺度",目的是防止模型在训练初期为难以拟合的像素预测一个极大的深度值作为平凡解。
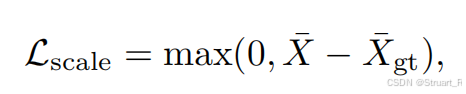
3、训练推理
训练过程:每个视频5帧,memory最多4帧,为了让模型适应不同相机运动和长时间特征匹配,视频采样窗口随着训练过程增加,最后25%epochs再逐渐减小。
推理过程:有序图像以此推理,无序图片先DUSt3R两两推理,其余图像依次通过贪心策略寻找最大置信度图进行推理,或者构造最小生成树构建推理顺序。
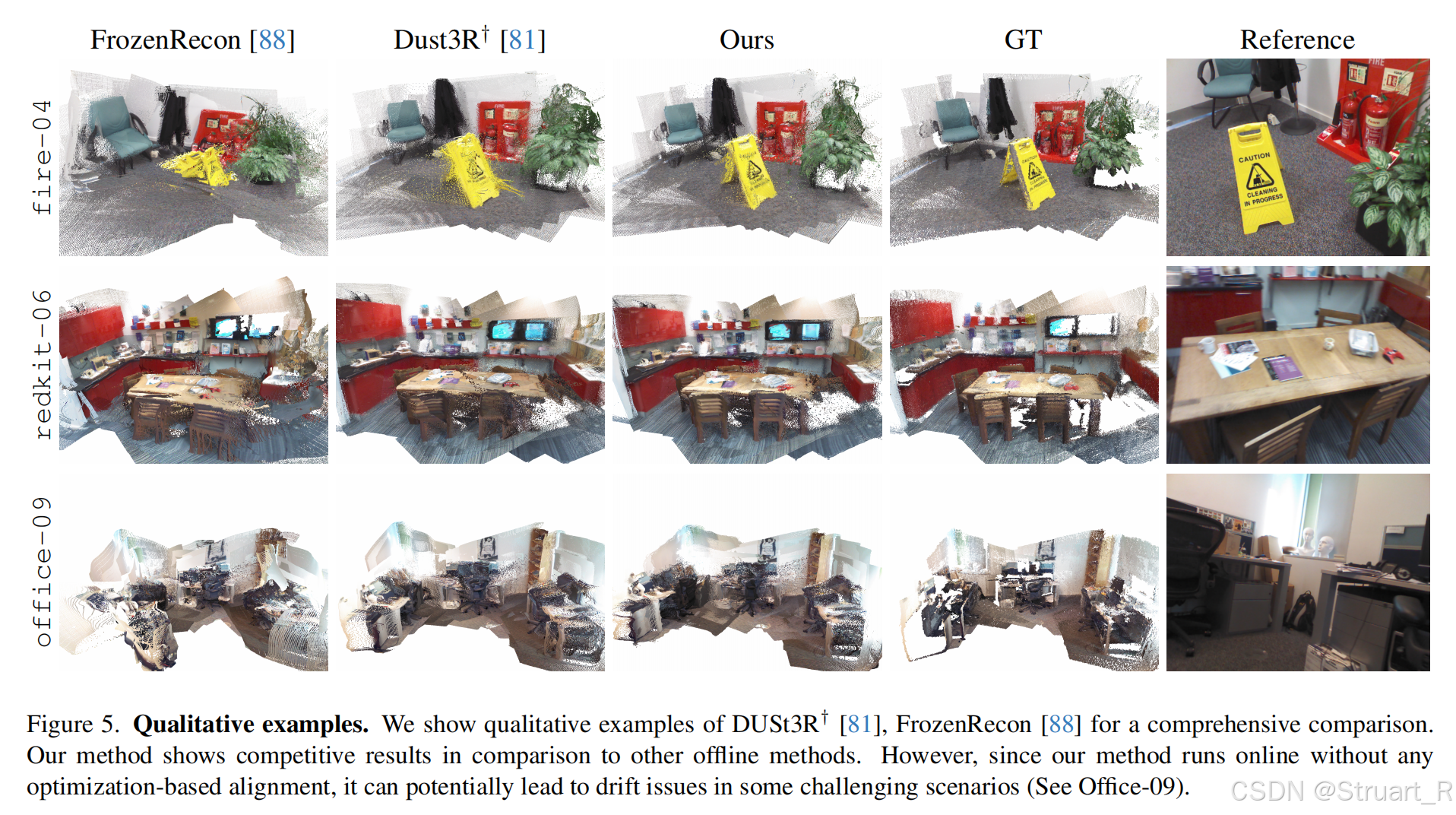
二、MUSt3R
1、概述
MUSt3R与DUSt3R和MASt3R都是Naver的工作,由于DUSt3R需要两两对齐,所以需要n^2个图像对,无法扩展到大的图像集,而且预测的点图都是以每对图像首帧定义的局部坐标系下,如果要合并到一个全局坐标系下,就需要一个离线的全局对齐,不能保证实时性。
motivation:如何绕过图像对的组合爆炸和繁琐的全局对齐,让模型能够直接、高效地从任意数量的图像(无论是无序集合还是有序视频流)中,预测出统一在全局坐标系下的3D结构?
contribution:对称化设计和添加工作记忆机制,扩展DUSt3R架构,同时保持较低复杂度提升。
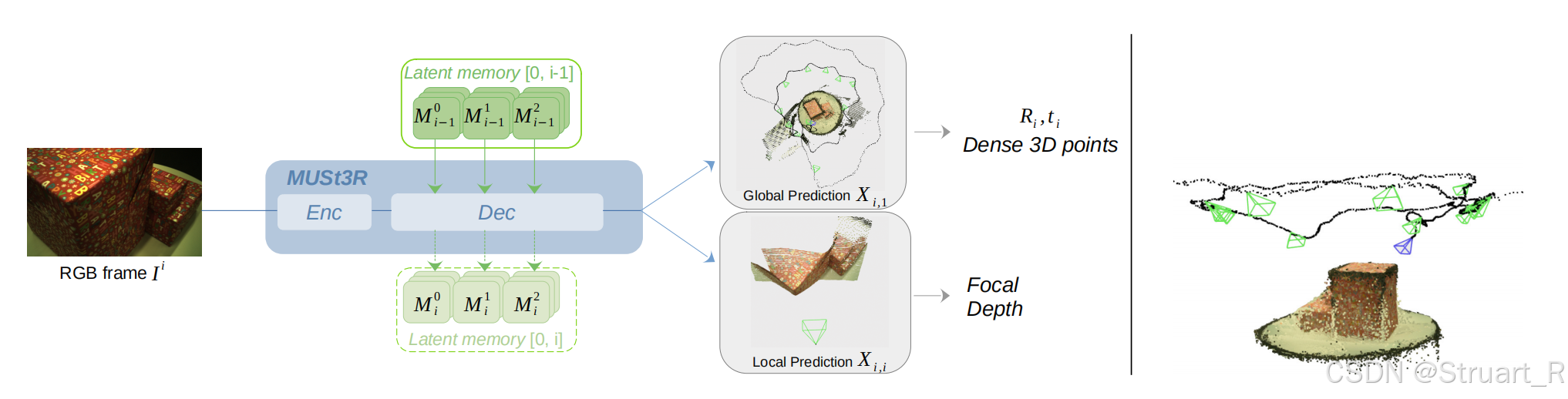 2、pipeline
2、pipeline
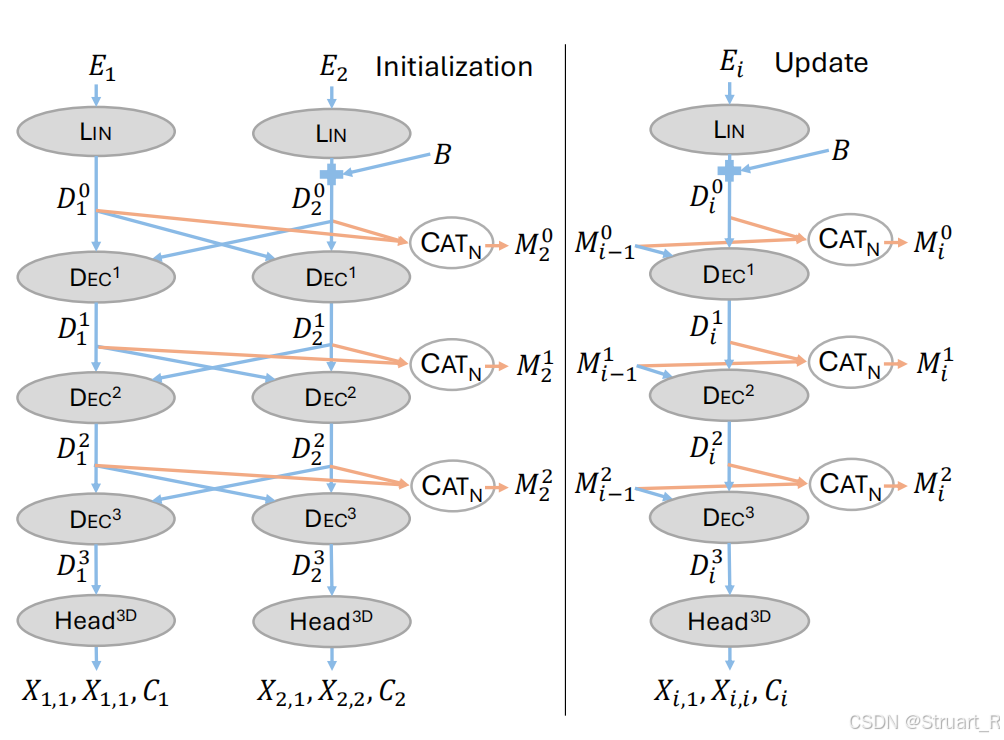
首先MUSt3R与DUSt3R、Spann3R最大的区别是只有一个解码器模块。
相比于Spann3R那种对于每一帧都大费周章的在每一次DUSt3R中一次作为view1,一次作为view2来说。MUSt3R对第一二帧是不做优化的,对第三帧之后每一帧执行同样的操作,将该帧与mem做cross attn,从而得到pointmaps。
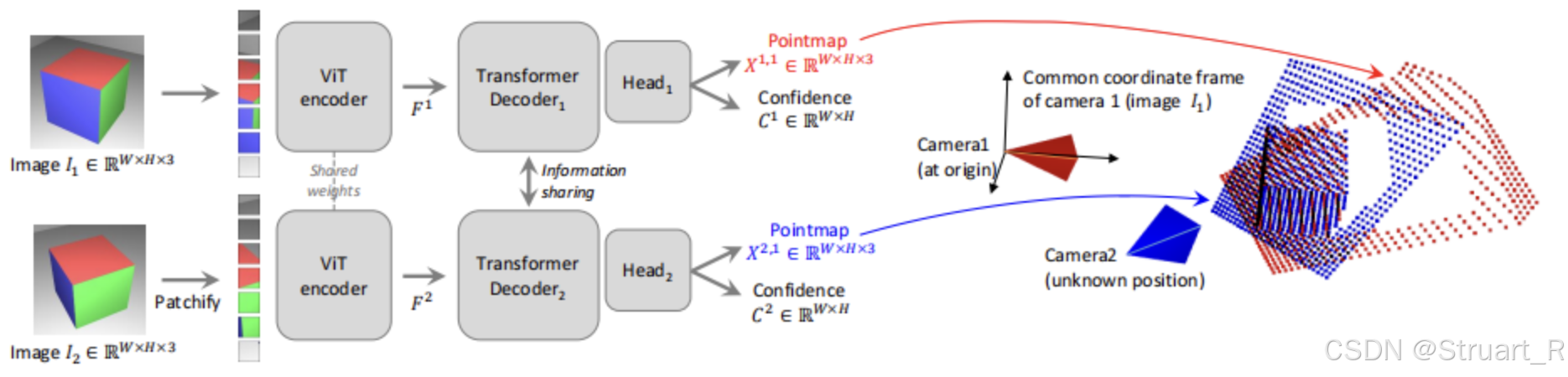
下图是DUSt3R的图,他是两个decoder共享权重,Spann3R也是采用相同的结构
(1)初始化阶段:
对每一帧都经过编码器(DUSt3REncoder),得到视觉特征和位置编码。
然后利用第一二帧的特征计算一个pointsmap,并且把此时Decoder的每一层block的输入tokens都存下来作为mem。
(2)增量阶段:
第三帧之后的操作都不使用DUSt3RDecoder,只有一个单输入的Decoder,而我们知道Decoder中是是有Cross-attn层的,对于第三帧的Cross-attn层,Query我们采用当前帧的自注意力处理后的特征,K,V采用内存中该层Cross-attn的数值。这样最终解码后进行回归得到的就是第三帧的点云信息。
其实这样做要比Spann3R更优一点,Spann3R时在查询记忆时做了一次crossattn,进行decoder时的crossattn又进行了一次,而MUSt3R只进行一次crossattn.
另外同时对每一个非参考帧都加了一个前置token标记,这样可以实现因果cross-attn。
3、训练推理
首先训DUSt3R,学习从图像对 回归出度量尺度(metric-scale)的3D点图。这一步继承了DUSt3R的能力,但采用了MUSt3R的对称共享权重架构。另外使用对数空间回归损失。相比于原始DUSt3R的尺度不变损失,这种损失函数能更好地处理大尺度场景中距离较远的点,提升模型在更广阔场景下的收敛性和性能。
之后训练增量式学习。
数据:从训练视频或场景中,采样包含 N=10帧 的图像序列作为一个训练样本。对于物体中心数据集,随机选取N帧;对于场景数据集,则从一个有重叠的图像对开始,逐步添加与已选帧有重叠的新帧,确保序列的连贯性。
训练:从一个随机数量的帧开始(2 ≤ n ≤ N)。模型以这些帧初始化其内存。这模拟了在线系统启动时积累初始记忆的状态。用当前内存"渲染"所有N帧视图 。这意味着,模型基于建立的内存,重新处理(渲染)序列中的每一帧(包括那些用于初始化内存的帧和后续帧)。最终,模型会得到 n + N个预测结果。
损失:在所有这些预测上计算回归损失。具体是每个预测帧的两个点图(X_{i,1}和 X_{i,i})的损失之和。
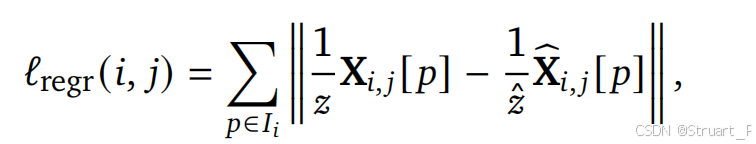
下图左侧为DUSt3R,或者说MUSt3R的初始化过程,右侧为增量式过程。增量式过程也需要把进行初始化的帧最后丢进去。
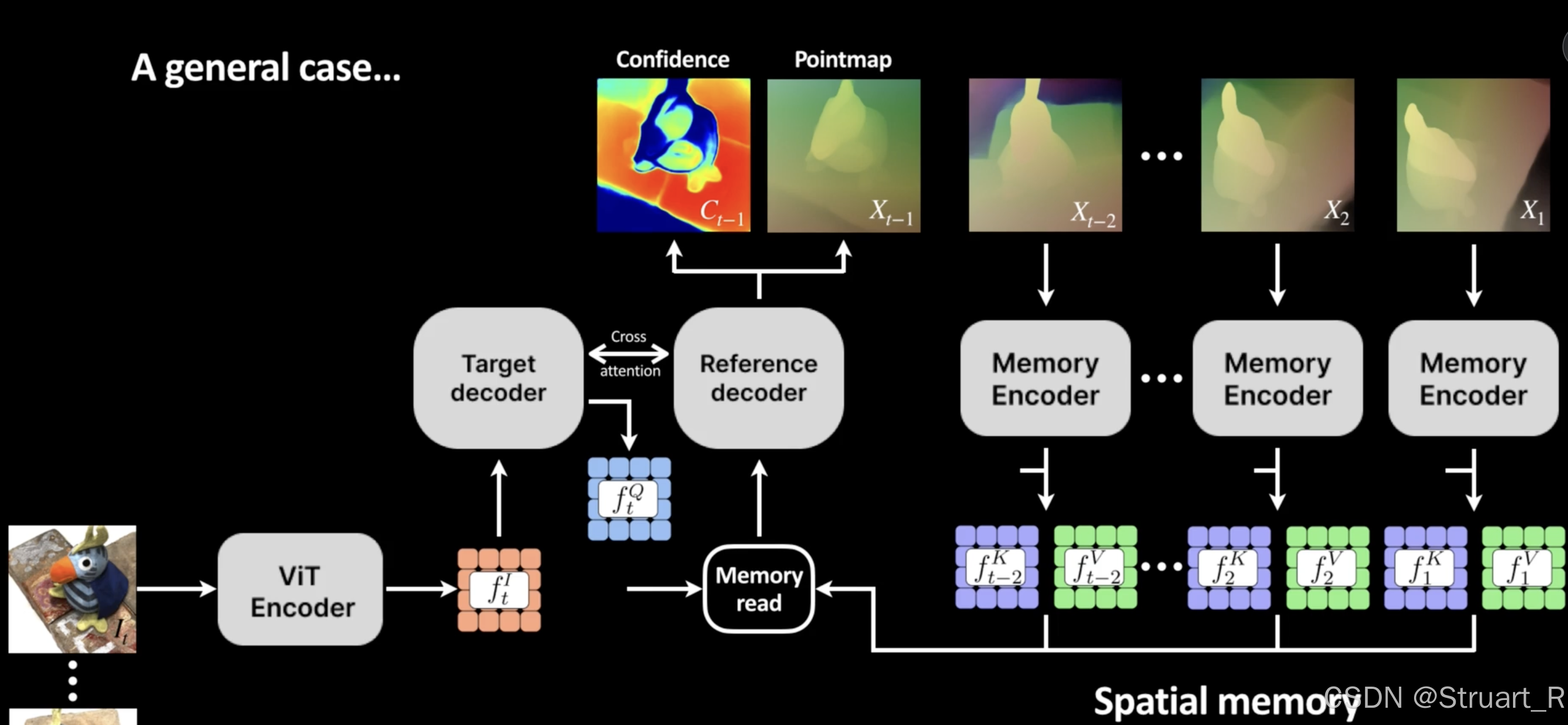
三、Cut3R
1、概述
motivation:与MUSt3R同时期工作,同样为了克服DUSt3R只能处理图像对难以扩展到多视图的问题。
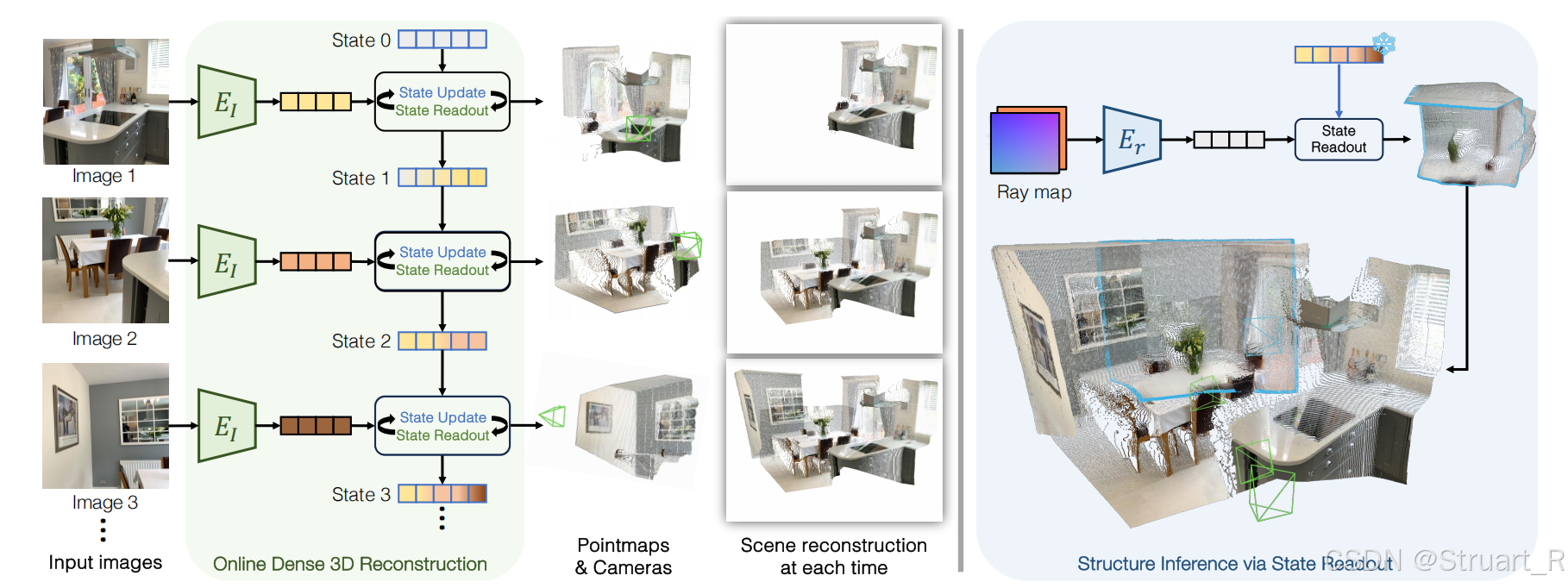
contribution:不仅实现MUSt3R的在线增量式重建,同样可以实现推理,比如少量观测,单张图的3D重建,可以实现想象预测未拍摄的3D点云和颜色,补全场景中未被观察到的部分,以及动态场景下的重建。

2、pipeline
(1)模型架构
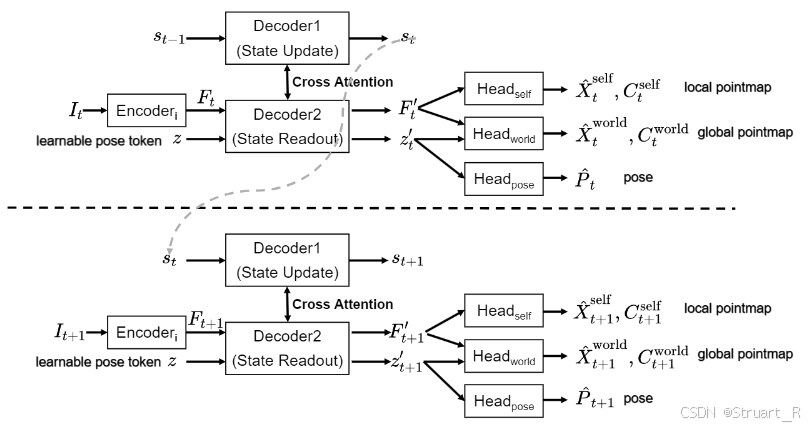
模型架构如下:
首先我们初始化一个,你可以理解为是记忆,但这里是一组可学习参数,并经过了预训练,另外定义一个可学习tokens
,他是用于学习位姿信息的。
对于任意一个图片输入ViT Encoder后,得到特征
,然后与可学习tokens
拼接后
输入到Decoder2(State Readout)记忆读取模块中,同时上一步的记忆
输入到Decoder1(State Update)记忆更新模块中,这两个Decoder进行cross-attn,也就是互相交换q与k,v参数,Decoder1输出了
用于下一帧的记忆输入,Decoder2输出解码特征和位姿特征
。
定义三个预测头,局部点图预测头,全局点图预测头,位姿头,分别输入,
,
可以得到local pointmap,global pointmap ,pose。
下一帧重复相同的工作,将记忆s传递下去。
为什么多了一个局部点云,他有什么作用?
扩大数据的多样性,对于哪些单目深度数据集,他们只有每一张图片的深度,并且每一张深度之间没有全局对齐,所以我们可以把他们转化成local pointmap作为GT进行回归。
对于这一部分的回归损失,与MASt3R,DUSt3R相同,也就是位姿损失+基于置信度的点云损失。
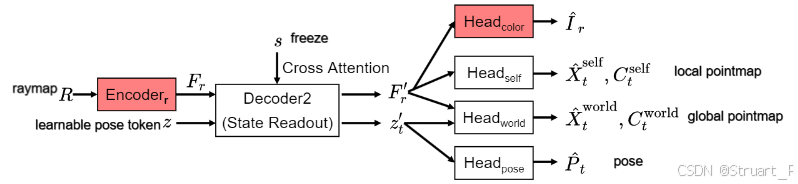
(2)新视角预测
这一部分可以看下图的蓝色区域。
定义一个虚拟相机,他是一个6通道的图像,每一个像素存储了一个6维向量,编码虚拟相机光心道该像素的3D光线起点和3D方向。
编码器E_r:虚拟相机的光线图R通过一个轻量级的独立编码器 被转换为特征令牌。这个编码器与处理真实图像的编码器是分开的,更新编码器权重。
状态查询:这里我们只保持查询,并不更新记忆,也就是Decoder的权重不更新。
视角预测头:定义一个预测颜色的预测头,最终回归RGB图,我们更新预测头的权重。
3、训练和推理过程
(1)训练过程
数据源 :混合使用32个数据集,涵盖静态/动态、室内/外、真实/合成、场景级/物体中心化数据,以及带有不同标注类型(完整3D、仅深度、仅姿态、仅RGB)的数据。
序列构建:从一个数据集中采样一个图像序列(例如N=10帧)。对于视频,按时间顺序采样;对于图像集,可能按重叠度或随机顺序采样。这使模型适应不同输入结构。
训练阶段****由易到难:
-
阶段一:用短序列(4视图)在静态数据集上训练,学习基础几何和姿态回归。
-
阶段二:加入动态场景数据和仅有部分标注的数据,提升泛化能力。
-
阶段三:提高分辨率至512像素,适应多种宽高比。
-
阶段四 :冻结图像编码器,专注于在更长序列(4-64视图)上训练解码器和预测头,强化长期依赖和场景级推理能力。
对于新视角预测的图片,我们在默认(80%) 输入当前帧的真实RGB图像。虚拟查询模式(20%, 且仅当该帧有真实3D标注时触发,通常排除第一帧) 不输入真实RGB图,而是输入一个光线图 。这个光线图是使用该帧的真实相机参数生成的,代表一个"已知位姿但未知图像"的虚拟查询。
(2)推理过程
在线增量重建,新视角预测(需要添加一部分真实视角辅助)
四、TTT3R
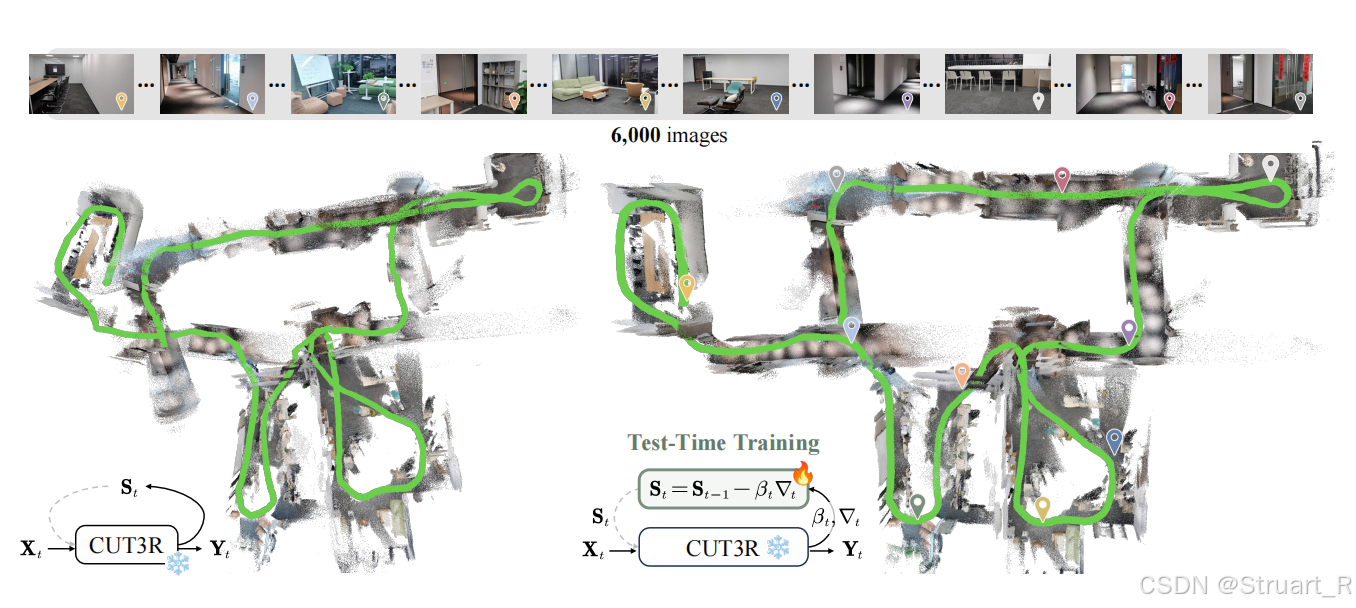
1、概述
TTT3R的矛盾来自于以往Cut3R这些方法,其实就是一种RNN的操作,而这种RNN的增量式3D重建模型在效率与长序列泛化能力之间存在不可调和的冲突。
因为训练过程中,Cut3R只训练了最多64帧,但是推理时处理上千帧,性能会因为误差增大而出现灾难性下降。核心问题是模型的"状态"在长序列的循环更新中,会过度适应最近的观测,而逐渐丢失早期关键的历史信息,导致相机位姿估计漂移、3D几何断裂。
motivation:能否在不重新训练模型、不增加计算开销的前提下,仅仅通过改进推理时的状态更新机制,来显著提升现有RNN模型(如CUT3R)的长度泛化能力?
contribution:提出了一个即插即用、无需训练的理论框架和优化方法 ,通过一个由注意力置信度驱动的自适应"调节阀",在推理时智能控制CUT3R模型对内部记忆的更新力度,从而显著减轻长序列处理中的遗忘问题。
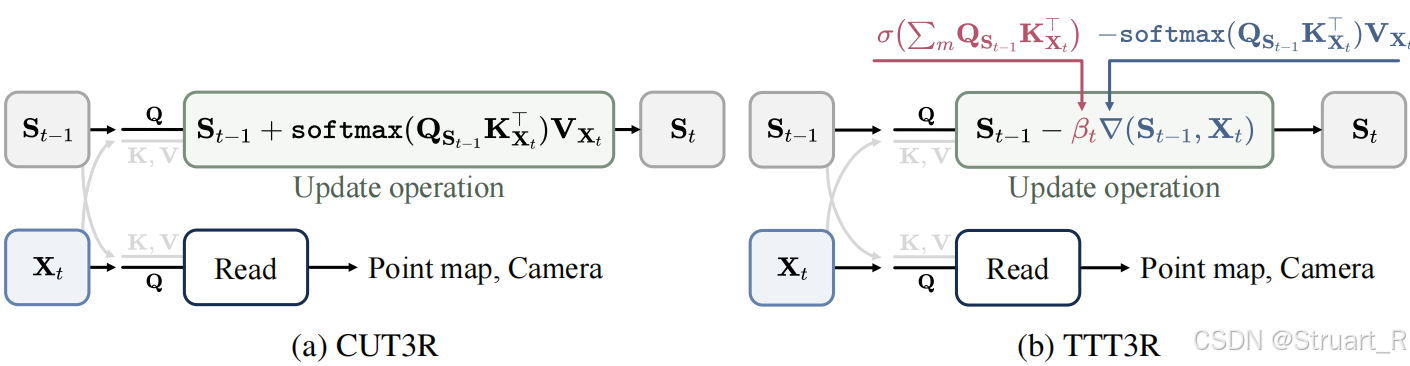
2、优化位置
CUT3R的原版更新公式:
S_t = S_{t-1} + softmax(Q_{S_{t-1}} K_{X_t}^T) V_{X_t}
TTT3R的改进更新公式:
S_t = S_{t-1} - β_t * [softmax(Q_{S_{t-1}} K_{X_t}^T) V_{X_t}]
其中,β_t是一个自适应的、逐令牌的学习率,它由当前观测X_t与状态S_{t-1}的匹配置信度实时计算得出(β_t = σ(mean(Q_{S_{t-1}}K_{X_t}^T)))
直观比喻:
CUT3R :每听到一句新话(X_t),就不加分辨地、完整地把它抄到笔记本最新一页,覆盖掉一些旧笔记。
TTT3R :每听到一句新话,先判断这句话和之前笔记的相关性和可信度(计算β_t)。如果非常相关且重要(β_t高),就认真记下;如果是无关噪音或重复信息(β_t低),就只轻轻带过,甚至不记,以保护之前的核心笔记不被冲掉。
方法对比:

参考文献:
https://arxiv.org/abs/2408.16061
https://arxiv.org/abs/2503.01661
https://arxiv.org/abs/2501.12387
https://arxiv.org/abs/2509.26645
参考博客: