图解VHM:多功能且诚实的遥感视觉语言模型
开篇导读
在遥感图像分析领域,一个令人兴奋的突破正在发生:视觉语言模型(VLMs)正在学习"看懂"卫星图像。但问题也随之而来------现有的模型要么"看"得不够全面,要么容易"说谎"。
今天我们要深入解读的论文《VHM: Versatile and Honest Vision Language Model for Remote Sensing Image Analysis》提出了一种创新的解决方案。武汉大学和上海人工智能实验室的研究团队开发了VHM模型,它不仅能够全面理解遥感图像,还能在面对无意义问题时诚实地说"我不知道"。
本文将带你深入理解这项研究,通过论文中的关键图表详细解析VHM的核心思想、技术实现和实验结果,让你在15分钟内掌握这项前沿遥感AI技术的精髓。
论文信息卡
- 论文标题:VHM: Versatile and Honest Vision Language Model for Remote Sensing Image Analysis
- 作者团队:Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Jiaxing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, Conghui He
- 研究机构:武汉大学、上海人工智能实验室、中山大学、商汤科技
- 发表会议:AAAI 2025
- 研究方向:计算机视觉、遥感图像分析、视觉语言模型
- 核心关键词:遥感视觉语言模型、多功能性、诚实性、图像理解、视觉问答
- 一句话总结:通过构建详细标注的遥感图像-文本数据集和包含欺骗性问题的指令数据集,VHM实现了对遥感图像的全面理解并具备诚实回答的能力。
1. 论文想解决什么问题?
!Figure 1(a):VersaD数据集与传统数据集标注对比(https://i-blog.csdnimg.cn/img_convert/13fd2e488e239393a3f98f9a3052ba39.jpeg)!Figure 1(b):多功能性与诚实性展示(https://i-blog.csdnimg.cn/img_convert/76bb5e43d560c60d70b24106fea25377.jpeg)
Figure 1:VHM论文整体框架图------左侧展示数据集对比,右侧展示模型多功能性与诚实性
研究背景:遥感AI的"视觉-语言"鸿沟
遥感图像(卫星图像、航拍图像)与普通自然图像有着本质区别:
- 视场广阔:一张图像可能包含数十平方公里区域
- 对象密集:包含建筑、道路、水体、植被等多种要素
- 尺度多变:从宏观地形到微观物体都需要识别
近年来,视觉语言模型在自然图像理解方面取得了显著进展,但将这些模型迁移到遥感领域面临两大挑战:
实际痛点一:现有数据集标注太"简陋"
传统遥感图像-文本数据集(如RS5M)存在严重问题:
- 标注过于简单:通常只描述几个显著物体(如"两个房子和一个灯塔")
- 缺乏细节:忽略物体颜色、形状、空间关系等关键信息
- 多样性不足:无法支持复杂的遥感分析任务
后果:模型只能看到图像的"皮毛",无法深入理解场景内涵。
实际痛点二:模型容易"说谎"
现有遥感指令数据集(如GeoChat-Instruct)只包含事实性问题:
- "图中有几个网球场?" → "2个"
- "建筑物的屋顶是什么颜色?" → "红色"
但现实中,用户可能提出无意义的问题:
- "图中的游泳池是什么颜色?"(图像是黑白的)
- "有多少只恐龙在图像里?"(根本没有恐龙)
由于训练数据中全是"有问必答"的样本,模型会强行编造答案而不是诚实地说"我不知道"。
已有方法的不足
现有方法通常采用"预训练+微调"的两阶段策略:
- 在自然图像-文本对上预训练
- 在遥感指令数据上微调
但这种方法存在领域偏移问题------自然图像与遥感图像差异巨大,导致模型性能受限。
2. 这篇论文的核心思路是什么?
VHM的核心创新可以概括为:数据驱动的方法论革命。
与传统的"模型架构创新"不同,VHM从数据源头解决问题:
- 构建VersaD数据集:包含详细描述的遥感图像-文本对
- 构建HnstD数据集:包含事实性和欺骗性问题
- 两阶段训练策略:在高质量数据上训练专用模型
直观理解:想象一下教AI看卫星图像。传统方法是给AI看很多"简笔画说明书"(简单标注),然后期望它成为专家。VHM的方法是:给AI看"详细工程图纸"(丰富标注),同时教它在不确定时说"我不知道"。
3. 方法详解
整体框架
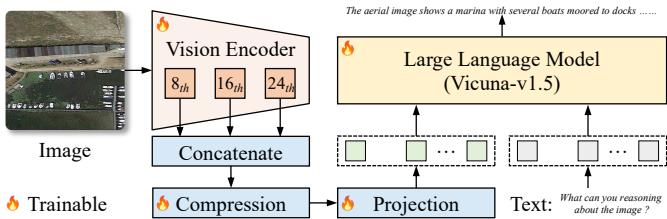
Figure 2:VHM模型整体架构------多层次视觉表示与两阶段训练策略
VHM采用经典的两阶段视觉语言模型架构:
文本输入 → 文本编码器 → 多模态融合 → 文本解码器 → 答案输出
↑
图像输入 → 视觉编码器(多层次特征)各关键模块详解
模块0:整体方法图示

Figure 3:VHM数据构建流程与训练策略详细图示
模块1:VersaD数据集(多功能性的基础)
- 规模:大规模遥感图像-文本对
- 特点 :每条标注都包含丰富信息:
- 图像整体属性(拍摄角度、分辨率等)
- 物体详细属性(颜色、形状、大小、材质)
- 空间关系和场景描述
- 示例对比 :
- 传统标注:"两个房子和一个灯塔"
- VersaD标注:"航拍图像显示一个码头,有几艘船停靠在码头旁。有一条狭长的陆地条带,一侧是绿色植被,另一侧是水域。陆地上有几栋建筑,包括一栋长条形绿顶建筑和几栋小白顶建筑..."
模块2:HnstD数据集(诚实性的保证)
- 结构 :包含两种类型的问题:
- 事实性问题:针对图像中真实存在的物体
- 欺骗性问题:针对图像中不存在的物体
- 设计理念:通过负样本训练,让模型学会说"我不知道"
- 示例 :
- 事实性问题:"图中顶部船只的颜色是什么?" → "红色"
- 欺骗性问题:"遥感图像中小型车辆的实际颜色是什么?" → "图像中看不到小型车辆,因此无法提供答案"
模块3:两阶段训练策略
- 预训练阶段:在VersaD数据集上训练,学习遥感图像的全面理解
- 微调阶段:在HnstD数据集上微调,学习诚实回答
模块4:多层次视觉表示
- 全局特征:捕捉图像整体信息
- 局部特征:关注关键物体和区域
- 细节特征:提取颜色、纹理等细粒度信息
与现有方法的关键区别
| 对比维度 | 传统遥感VLM | VHM |
|---|---|---|
| 数据质量 | 简单标注 | 详细、丰富的标注 |
| 问题类型 | 仅事实性问题 | 事实性+欺骗性问题 |
| 模型行为 | 总是尝试回答 | 知道时说,不知道时承认 |
| 任务范围 | 有限任务 | 多样化任务 |
| 理解深度 | 表面理解 | 深入理解 |
4. 图解论文(重点)
Figure 1(a):数据集对比图

Figure 1(a):传统数据集与VersaD数据集的标注对比示意图
原始caption:(a) Datasets for VLM construction
中文解释:传统数据集与VersaD数据集的标注对比示意图
【这张图想表达什么】
这张图直观展示了传统遥感数据集标注的"简陋"与VersaD数据集标注的"丰富"之间的巨大差异。左侧是传统数据集(如RS5M)的简单标注,右侧是VersaD的详细标注。
【应该重点看哪里】
- 标注内容对比:注意传统标注只有一句话,而VersaD标注是详细的段落描述
- 信息密度差异:VersaD包含了物体属性、空间关系、场景描述等多层次信息
- 标注风格:传统标注像"简笔画",VersaD标注像"工笔画"
Figure 1(b):多功能性与诚实性展示图

Figure 1(b):VHM模型的多功能性和诚实性展示图
原始caption:(b) Versatility and honesty of VLM
中文解释:VHM模型的多功能性和诚实性展示图
【这张图想表达什么】
这张图展示了VHM的两个核心特性:多功能性(能处理多种任务)和诚实性(能识别无意义问题)。
【应该重点看哪里】
- 任务类型展示:注意VHM支持的各种遥感图像理解任务
- 诚实性对比:观察传统模型与VHM在面对欺骗性问题时的不同反应
- 输入-输出示例:关注具体的问答示例,理解模型的工作原理
Figure 4:遥感图像示例与模型推理结果

Figure 4:VHM在遥感图像上的推理示例
实验结果图表
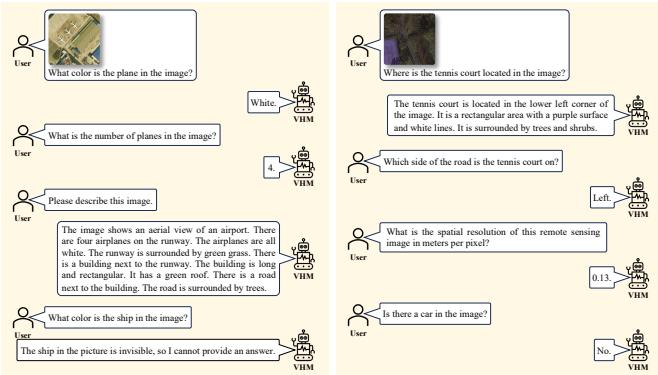
Table 4: 遥感视觉语言模型能力对比表
原始caption:Capabilities comparison of VLMs tailored for RS image analysis
中文解释:这张表格系统对比了VHM与其他遥感VLM在多个任务上的能力。VHM在任务覆盖范围上明显更广。
5. 实验结果说明了什么?

Figure 5:VHM与基线方法的定性对比结果
主结果:全面超越现有方法
VHM在多个标准遥感数据集上进行了全面评估:
- 场景分类任务:在NWPU、METER-ML、SIRI-WHU等5个数据集上达到最优
- 视觉问答任务:在RSVQA-LR和RSVQA-HR数据集上显著优于基线
- 视觉定位任务:在DIOR-RSVG数据集上表现优异
与基线对比:优势明显
- 精度提升:在多个任务上相对现有方法有显著提升
- 任务扩展:支持建筑矢量化、多标签分类等新任务
- 鲁棒性:在不同类型、不同难度的任务上表现稳定
消融实验:验证各组件重要性

消融实验:验证VersaD、HnstD数据集和多层次视觉表示的贡献
论文进行了系统的消融实验,验证了各个组件的贡献:
- VersaD数据集:对模型多功能性的提升贡献最大
- HnstD数据集:是模型诚实性的关键保证
- 多层次视觉表示:提升了模型的细粒度理解能力
6. 这篇论文的亮点与局限
亮点
- 数据创新:构建了首个详细标注的大规模遥感图像-文本数据集
- 诚实性设计:首次在遥感VLM中引入欺骗性问题和诚实性训练
- 多功能实现:支持传统任务和新兴任务,扩展了VLM的应用范围
- 实用价值:在国防安全、资源监测等关键领域有重要应用前景
- 开源精神:代码和数据公开,推动领域发展
局限
- 像素级感知缺失:目前无法进行语义分割或变化检测
- 实时性限制:推理速度可能不适合实时应用
- 数据偏见:数据集的覆盖范围和多样性仍有提升空间
- 复杂推理:对于需要深度推理的复杂问题仍有挑战
适用场景
- 国防安全:需要诚实、可靠的图像分析
- 城市规划:建筑识别、土地利用分析
- 环境监测:植被覆盖、水体变化检测
- 灾害评估:灾后损失快速评估
- 农业管理:作物生长监测、产量预估
7. 总结
VHM代表了遥感视觉语言模型发展的一个重要里程碑。它通过数据驱动的方法,从根本上解决了传统方法的两个核心问题:理解深度不足和诚实性缺失。
这项工作的价值不仅在于技术指标的提升,更在于方法论上的创新:
- 证明了高质量数据是提升模型能力的关键
- 展示了模型诚实性可以通过数据设计来实现
- 拓展了视觉语言模型在遥感领域的应用边界
对于遥感AI领域的研究者和实践者来说,VHM提供了宝贵的启示:有时候,最好的算法改进不是修改模型架构,而是重新思考数据本身。
附:适合发布的摘要版
武汉大学与上海人工智能实验室联合开发的VHM模型,为遥感图像分析带来了革命性突破。该模型基于两个创新数据集:VersaD提供详细图像标注,HnstD包含欺骗性问题训练模型诚实性。VHM不仅在地物分类、视觉问答等传统任务上超越现有方法,还率先支持建筑矢量化、多标签分类等新任务。更重要的是,它能识别无意义问题并诚实回应"我不知道",避免了AI模型"胡说八道"的风险。这项研究为国防安全、城市规划等关键领域的可靠AI应用提供了坚实技术基础。
核心创新:1)构建详细标注的遥感数据集VersaD;2)引入欺骗性问题训练模型诚实性;3)实现遥感图像的全面深度理解。
应用价值:可用于国土安全监测、城市规划管理、环境变化检测等需要可靠图像分析的场景。
资源开放:代码和数据已在GitHub开源,推动遥感AI领域共同发展。
本文基于论文《VHM: Versatile and Honest Vision Language Model for Remote Sensing Image Analysis》进行解读,旨在传播前沿AI技术知识。论文发表于AAAI 2025,代码和数据开源地址:https://github.com/opendatalab/VHM