MySQL 高可用灾备:Keepalived + VIP 方案详解
适用场景 :中小规模业务,两台 MySQL 服务器(一主一备),要求故障自动切换、业务中断时间秒级以内。
核心组件:MySQL 主从复制 + Keepalived + VRRP 虚拟 IP(VIP)
1. 方案原理
1.1 整体架构
应用程序只连接一个固定的虚拟 IP(VIP),不感知底层哪台机器在提供服务。Keepalived 通过 VRRP 协议在两台服务器之间协商出一个 MASTER,MASTER 节点将 VIP 绑定在自己的网卡上。当主节点发生故障时,VIP 自动漂移到备节点,整个过程对应用透明。
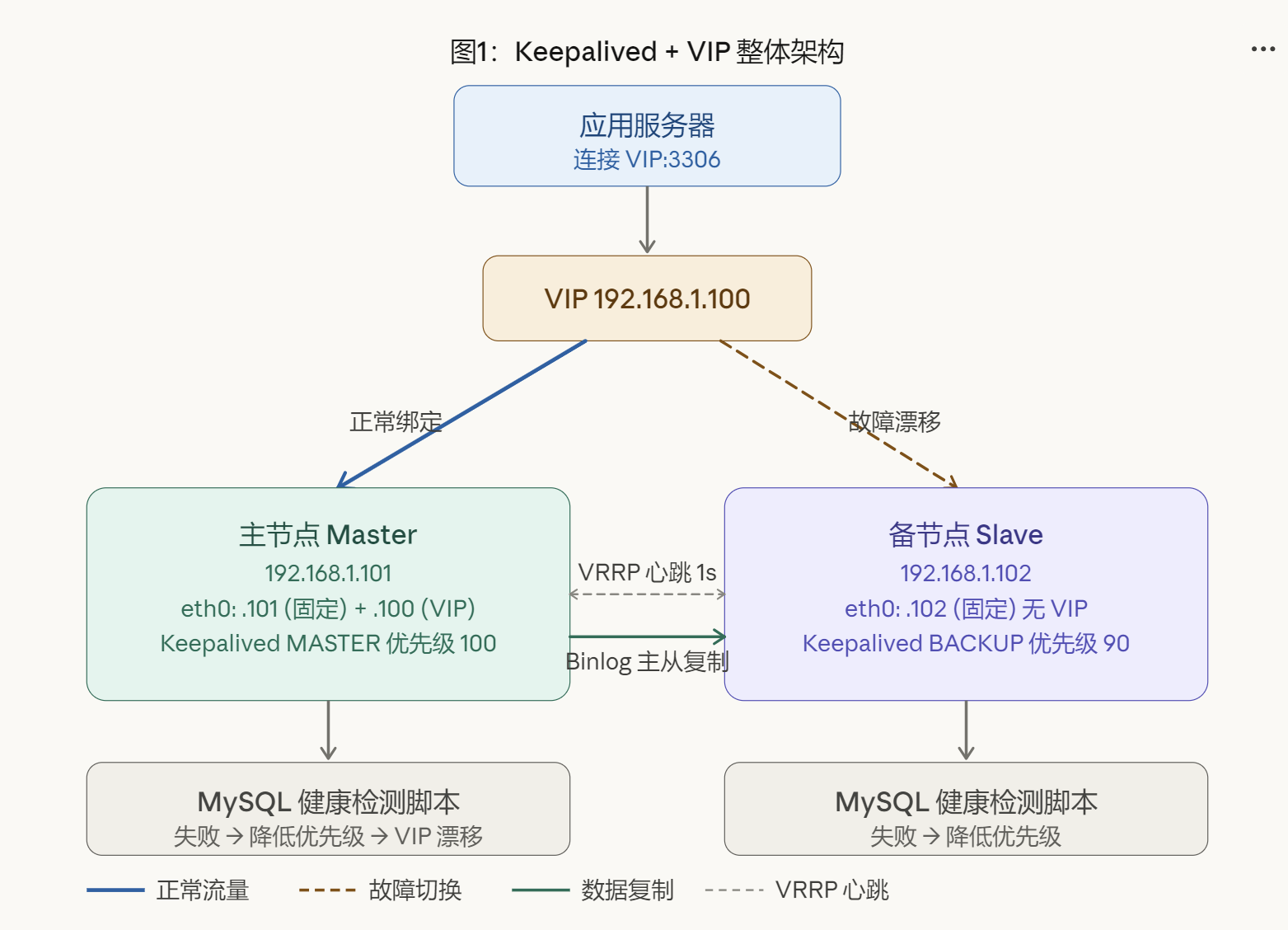
三个核心要素:
- VIP(Virtual IP):一个在局域网内未被占用的 IP 地址,应用程序始终连接这个地址。它本质上是绑定在网卡上的一个 secondary IP,由 Keepalived 自动管理其归属。
- VRRP 心跳:两台机器每秒互发心跳,确认对方存活。心跳中断超过阈值(默认 3s),备节点认定主节点故障并接管 VIP。
- MySQL 主从复制:数据层面的同步,与 VIP 切换相互独立,负责保证备节点上有可用数据。
1.2 网卡 IP 的实际状态
一张网卡可以同时绑定多个 IP,这是 VIP 机制的底层基础。正常运行时主节点同时持有固定 IP 和 VIP,备节点只有自己的固定 IP。故障切换后 VIP 从主节点删除并添加到备节点。
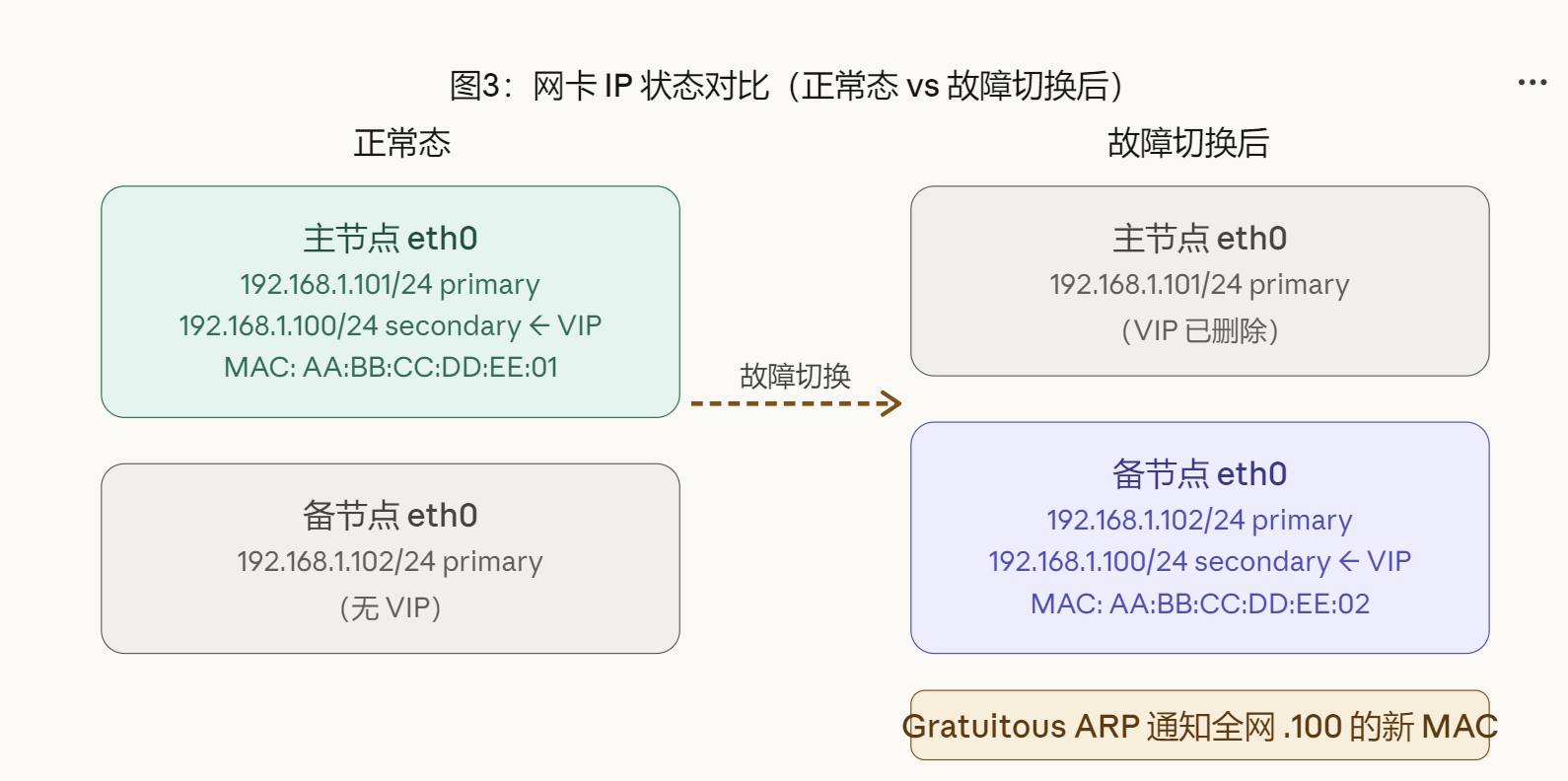
Linux 中 IP 有 primary 和 secondary 之分。删除 primary IP 会同时删除同网段所有 secondary IP,因此两台机器的固定 IP 绝不能被删除,Keepalived 只操作 VIP 这个 secondary IP。
1.3 VIP 切换的完整时序
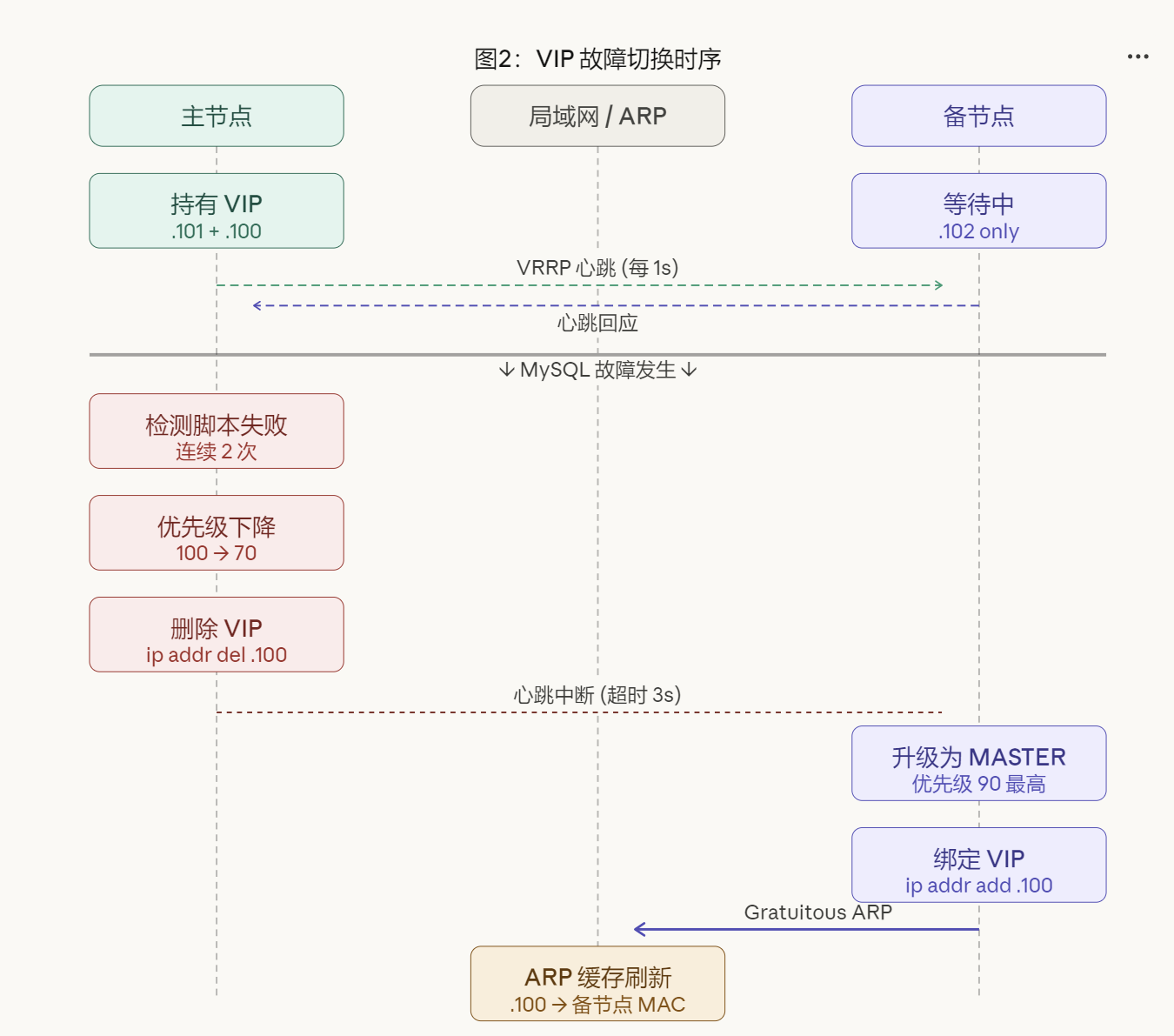
切换过程分为以下步骤:
- 主节点的 Keepalived 每 2 秒执行一次 MySQL 健康检测脚本
- 连续 2 次检测失败后,将自身优先级从 100 降至 70(低于备节点的 90)
- Keepalived 从主节点网卡上删除 VIP(
ip addr del) - 备节点收不到心跳,等待超时(约 3s)后将自己升级为 MASTER
- 备节点将 VIP 绑定到自己的网卡(
ip addr add) - 备节点广播 Gratuitous ARP,强制刷新局域网内所有设备的 ARP 缓存,将 VIP 对应的 MAC 地址更新为备节点的 MAC
整个切换通常在 5~10 秒内完成。
2. 环境准备
2.1 服务器规划
| 角色 | 主机名 | 固定 IP | MySQL 角色 | Keepalived 优先级 |
|---|---|---|---|---|
| 主节点 | db-master | 192.168.1.101 | Master | 100 |
| 备节点 | db-slave | 192.168.1.102 | Slave | 90 |
| VIP | --- | 192.168.1.100 | --- | --- |
2.2 前提条件
- MySQL 主从复制已配置完成,Binlog 和 GTID 正常同步
- 两台机器在同一个二层局域网(VIP 需要 ARP 通信)
- 确认 VIP 地址未被使用:
bash
# 确认无响应才可以使用
ping -c 3 192.168.1.100
arping -c 3 -I eth0 192.168.1.1002.3 安装 Keepalived
bash
# CentOS / RHEL
yum install -y keepalived
# Ubuntu / Debian
apt install -y keepalived3. 完整配置
3.1 MySQL 检测账号
在 MySQL 中创建一个专用检测账号,权限最小化:
sql
CREATE USER 'keepalived_check'@'127.0.0.1' IDENTIFIED BY 'your_password';
GRANT SELECT ON *.* TO 'keepalived_check'@'127.0.0.1';
FLUSH PRIVILEGES;3.2 健康检测脚本(两台机器都要部署)
bash
# /etc/keepalived/check_mysql.sh
#!/bin/bash
MYSQL_HOST="127.0.0.1"
MYSQL_PORT="3306"
MYSQL_USER="keepalived_check"
MYSQL_PASS="your_password"
mysql -h$MYSQL_HOST -P$MYSQL_PORT -u$MYSQL_USER -p$MYSQL_PASS \
-e "SELECT 1" > /dev/null 2>&1
if [ $? -ne 0 ]; then
# MySQL 不可用,停止 keepalived 触发 VIP 漂移
logger "check_mysql: MySQL is down, stopping keepalived"
systemctl stop keepalived
exit 1
fi
exit 0
bash
chmod +x /etc/keepalived/check_mysql.sh3.3 主节点配置(192.168.1.101)
nginx
# /etc/keepalived/keepalived.conf
global_defs {
router_id MySQL_HA_Master
# 脚本执行用户,避免用 root
script_user root
enable_script_security
}
vrrp_script check_mysql {
script "/etc/keepalived/check_mysql.sh"
interval 2 # 每 2 秒检测一次
weight -30 # 检测失败则优先级降低 30
fall 2 # 连续失败 2 次才触发
rise 1 # 成功 1 次即恢复
}
vrrp_instance VI_MYSQL {
state BACKUP # 配合 nopreempt,两台都写 BACKUP
interface eth0 # 网卡名,用 ip a 确认
virtual_router_id 51 # 两台必须一致,范围 1-255
priority 100 # 主节点优先级高
advert_int 1 # VRRP 心跳间隔(秒)
nopreempt # 禁止自动抢占(见第4节)
authentication {
auth_type PASS
auth_pass mysql_ha_2024 # 两台必须相同
}
virtual_ipaddress {
192.168.1.100/24 dev eth0 label eth0:vip
}
# ARP 优化,加快切换时的局域网感知
garp_master_delay 1
garp_master_repeat 3
garp_master_refresh 10
track_script {
check_mysql
}
# 状态变更通知脚本(可选,用于防脑裂)
# notify /etc/keepalived/notify.sh
}3.4 备节点配置(192.168.1.102)
nginx
# /etc/keepalived/keepalived.conf
global_defs {
router_id MySQL_HA_Slave
script_user root
enable_script_security
}
vrrp_script check_mysql {
script "/etc/keepalived/check_mysql.sh"
interval 2
weight -30
fall 2
rise 1
}
vrrp_instance VI_MYSQL {
state BACKUP
interface eth0
virtual_router_id 51
priority 90 # 低于主节点
advert_int 1
nopreempt # 备节点同样加上
authentication {
auth_type PASS
auth_pass mysql_ha_2024
}
virtual_ipaddress {
192.168.1.100/24 dev eth0 label eth0:vip
}
garp_master_delay 1
garp_master_repeat 3
garp_master_refresh 10
track_script {
check_mysql
}
}3.5 启动与验证
bash
# 两台机器均执行
systemctl enable keepalived
systemctl start keepalived
# 确认 VIP 在主节点上
ip addr show eth0 | grep "192.168.1.100"
# 实时查看 keepalived 日志
journalctl -u keepalived -f故障切换测试(重要,上线前必做):
bash
# 在主节点停止 MySQL,模拟故障
systemctl stop mysqld
# 约 5~10 秒后,在备节点确认 VIP 出现
ip addr show eth0 | grep "192.168.1.100"
# 恢复主节点 MySQL,确认 VIP 不会自动漂移回来(nopreempt 生效)
systemctl start mysqld4. 常见问题与解决方案
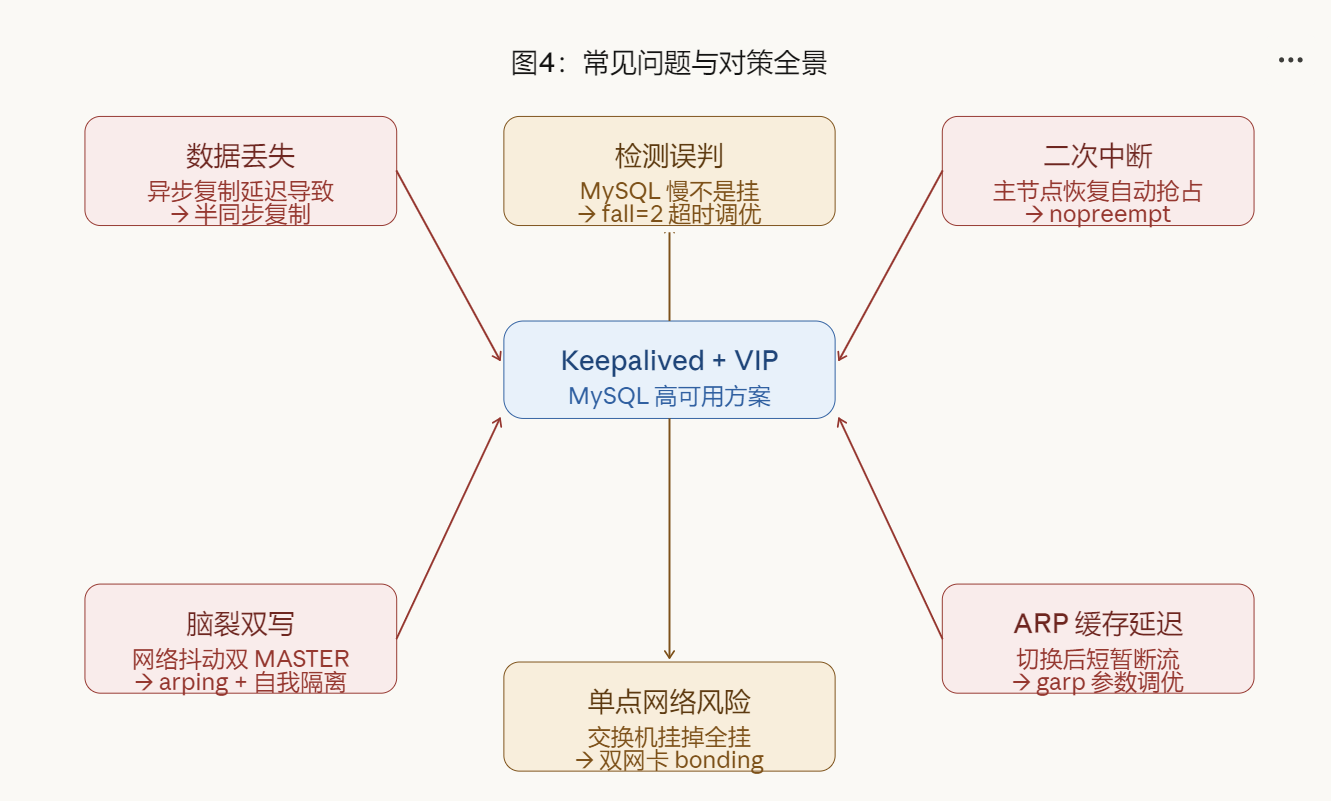
图4:常见问题与对策全景图
4.1 问题一:二次中断(nopreempt 抢占)
问题描述:默认情况下,主节点 MySQL 恢复后,Keepalived 会自动将 VIP 抢回。这个"抢回"动作本身是一次额外的 VIP 切换,业务再次出现短暂中断。
根因:Keepalived 默认是抢占模式(preempt),高优先级节点一旦恢复就会重新夺回 MASTER 角色。
解决方案 :在配置中加入 nopreempt,并将两台机器的 state 都改为 BACKUP,由优先级决定谁在启动时先成为 MASTER。
nginx
vrrp_instance VI_MYSQL {
state BACKUP # 两台都改为 BACKUP
nopreempt # 禁止自动抢回
...
}故障恢复后如需手动切回,在备节点执行:
bash
# 重启备节点 keepalived,它会主动放弃 MASTER
systemctl restart keepalived注意 :
nopreempt只在state BACKUP时生效。如果state MASTER,该参数无效。
4.2 问题二:数据丢失(异步复制延迟)
问题描述:MySQL 默认是异步主从复制。主节点写入数据后立即返回成功,备节点的同步是异步进行的。主节点宕机的瞬间,备节点可能还有几秒的数据未同步,这部分数据永久丢失。
数据丢失窗口 = 主从复制延迟,在业务写入繁忙时可能达到数十秒。
解决方案:半同步复制(Semi-Synchronous Replication)
半同步要求主节点在写入后,等待至少一个备节点确认收到 Binlog,才向客户端返回成功。数据丢失窗口从"主从延迟"降低到接近 0。
sql
-- 主节点安装并启用半同步
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
SET GLOBAL rpl_semi_sync_master_enabled = 1;
-- 等待 ACK 的超时时间(毫秒),超时后降级为异步,保证可用性
SET GLOBAL rpl_semi_sync_master_timeout = 1000;
-- 备节点安装并启用
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
-- 重启 Slave IO 线程使配置生效
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;写入 my.cnf 永久生效:
ini
# 主节点 my.cnf
[mysqld]
rpl_semi_sync_master_enabled = 1
rpl_semi_sync_master_timeout = 1000
# 备节点 my.cnf
[mysqld]
rpl_semi_sync_slave_enabled = 1权衡 :半同步每次写操作需等待备节点 ACK,会增加 1~5ms 的写延迟。rpl_semi_sync_master_timeout 是安全阀------备节点不可用时自动降级为异步,主节点不会被拖死。
验证是否生效:
sql
SHOW STATUS LIKE 'Rpl_semi_sync%';
-- Rpl_semi_sync_master_status = ON 表示运行正常
-- Rpl_semi_sync_master_no_tx = 0 表示没有走异步的事务4.3 问题三:脑裂(Split-Brain)
问题描述:这是最危险的场景。当两台机器之间的网络发生中断(但各自的 MySQL 都还正常运行),双方都收不到对方的 VRRP 心跳,于是各自认为自己应该成为 MASTER,同时持有 VIP。结果局域网内存在两个相同的 IP,写流量被随机分发到两台机器,数据从此永久分叉,几乎无法合并。
解决方案一:arping 探测(简单有效)
备节点在升级为 MASTER 之前,先用 arping 探测 VIP 是否仍有响应。如果有响应,说明主节点还活着(只是网络抖动),此时不应接管:
bash
# /etc/keepalived/notify.sh
#!/bin/bash
STATE=$3 # MASTER / BACKUP / FAULT
if [ "$STATE" = "MASTER" ]; then
# 探测 VIP 是否还活着
arping -q -c 3 -W 1 -I eth0 192.168.1.100
if [ $? -eq 0 ]; then
logger "notify: VIP still alive, possible split-brain, stepping down"
systemctl stop keepalived
exit 1
fi
logger "notify: Becoming MASTER, VIP is free"
fi在 keepalived.conf 中挂载:
nginx
vrrp_instance VI_MYSQL {
...
notify /etc/keepalived/notify.sh
}解决方案二:主节点自我隔离(防双写)
在检测脚本中,不只是降低优先级,而是将 MySQL 设置为只读,从根本上防止双写:
bash
# /etc/keepalived/check_mysql.sh(增强版)
#!/bin/bash
mysql -h127.0.0.1 -u keepalived_check -pyour_password -e "SELECT 1" > /dev/null 2>&1
if [ $? -ne 0 ]; then
systemctl stop keepalived
exit 1
fi
# 如果当前节点不持有 VIP,强制设为只读
ip addr show eth0 | grep "192.168.1.100" > /dev/null 2>&1
if [ $? -ne 0 ]; then
mysql -h127.0.0.1 -uroot -pyour_root_pass \
-e "SET GLOBAL read_only=1; SET GLOBAL super_read_only=1;"
fi
exit 0解决方案三:第三方仲裁(生产推荐)
引入一台独立的仲裁节点(配置极低即可),结合 consul、etcd 或 ZooKeeper 进行投票。只有获得仲裁节点认可、拿到多数票的节点才能持有 VIP。这个方案复杂度更高,但可靠性最好,适合对数据一致性要求严格的金融、电商等业务。
实际建议:方案一 + 方案二组合使用,可以覆盖绝大多数生产场景。
4.4 问题四:ARP 缓存延迟导致切换后短暂断流
问题描述:VIP 漂移到备节点后,局域网内其他服务器的 ARP 缓存里还记录着旧的 MAC 地址(主节点的 MAC),会在缓存过期前继续把流量发往已宕机的主节点,导致切换后有短暂的连接失败。
解决方案:优化 Keepalived 的 Gratuitous ARP 参数:
nginx
vrrp_instance VI_MYSQL {
...
garp_master_delay 1 # 成为 MASTER 后延迟 1s 发送(等网卡就绪)
garp_master_repeat 3 # 连续发送 3 次,提高到达率
garp_master_refresh 10 # 每 10s 刷新一次,防止缓存过期
}同时在操作系统层面降低 ARP 缓存超时:
bash
# 降低 ARP 缓存老化时间(秒),临时生效
echo 10 > /proc/sys/net/ipv4/neigh/eth0/base_reachable_time_ms
# 写入 /etc/sysctl.conf 永久生效
net.ipv4.neigh.default.gc_stale_time = 10配置优化后切换通常在 1~3 秒内对全网完全生效。
4.5 问题五:健康检测误判(MySQL 慢响应被当作故障)
问题描述:MySQL 在高负载时可能响应缓慢,健康检测脚本超时,被误判为故障,触发不必要的 VIP 切换。
解决方案:
- 调整检测脚本的
fall参数,要求连续多次失败才触发:
nginx
vrrp_script check_mysql {
script "/etc/keepalived/check_mysql.sh"
interval 2 # 检测间隔
fall 3 # 连续失败 3 次才触发(而非默认 1 次)
rise 2 # 连续成功 2 次才恢复
timeout 5 # 单次脚本超时时间(秒)
weight -30
}- 检测脚本加入超时控制:
bash
# 使用 timeout 命令限制 MySQL 连接时间
timeout 3 mysql -h127.0.0.1 -u keepalived_check -pyour_password \
-e "SELECT 1" > /dev/null 2>&14.6 问题六:单点网络风险
问题描述:如果两台机器连接同一台交换机,交换机故障会导致整个高可用方案失效,变成单点故障。
解决方案:使用网卡 bonding(绑定),将两块物理网卡做成一个逻辑网卡,同时接入两台交换机:
bash
# 创建 bond0 接口(active-backup 模式,主备切换)
nmcli con add type bond ifname bond0 bond.options "mode=active-backup,miimon=100"
nmcli con add type ethernet ifname eth0 master bond0
nmcli con add type ethernet ifname eth1 master bond0Keepalived 中将 interface 改为 bond0 即可。
5. 手动切换操作手册
| 操作 | 命令 | 说明 |
|---|---|---|
| 主动将 VIP 切到备节点 | 主节点执行 systemctl stop keepalived |
备节点自动接管 |
| 将 VIP 切回主节点 | 备节点执行 systemctl restart keepalived |
备节点放弃 MASTER |
| 查看当前 VIP 在哪台机器 | `ip addr show eth0 | grep 192.168.1.100` |
| 查看 Keepalived 状态 | journalctl -u keepalived --since "10 min ago" |
查看近期切换记录 |
| 查看主从延迟 | SHOW SLAVE STATUS\G |
关注 Seconds_Behind_Master |
6. 方案总结与局限性
优点
- 实现简单:纯开源组件,配置成本低,运维人员容易上手
- 切换快:正常情况下 5~10 秒完成故障切换,业务影响时间短
- 无需改造应用:应用只需更改数据库连接地址为 VIP,无其他改动
- 成本低:不需要额外的商业软件或云服务
局限性
| 局限 | 说明 |
|---|---|
| 无法自动数据补偿 | 切换后备节点上缺失的数据需要人工介入处理 |
| 只适用于二层网络 | VIP 依赖 ARP,无法跨路由器(跨机房)使用 |
| 无读写分离 | 备节点平时不提供服务,资源利用率偏低 |
| 故障切换非零中断 | 切换过程总有 5~10s 的连接失败,不适合对中断极敏感的业务 |
| 脑裂风险依赖脚本 | 防脑裂能力取决于自定义脚本质量,没有原生强一致保证 |
适合的场景
- 中小型业务,日活百万以下
- 对 RTO(恢复时间)要求在分钟级别
- 对 RPO(数据丢失容忍)配合半同步可接受接近 0 丢失
- 部署在同一数据中心的物理服务器或虚拟机
不适合的场景
- 跨机房、跨地域的异地容灾(建议使用 MySQL Group Replication 或 MGR)
- 对中断时间要求毫秒级(建议使用 ProxySQL + 多主方案)
- 大规模集群(建议使用 Orchestrator + MHA)