本文对 Shrishti Saha Shetu 等人于 2024 年在 ICASSP 上发表的论文进行简单地学习。如有表述不当之处欢迎批评指正。欢迎任何形式的转载,但请务必注明出处。
论文链接 :https://arxiv.org/pdf/2312.08132
目录
- 摘要
- [1. 介绍](#1. 介绍)
- [2. 方法](#2. 方法)
-
- [2.1. 输入预处理](#2.1. 输入预处理)
- [2.2. 两阶段处理和干净语音估计](#2.2. 两阶段处理和干净语音估计)
- [2.3. 模型设计](#2.3. 模型设计)
- [3. 实验和结果](#3. 实验和结果)
-
- [3.1. 实现细节](#3.1. 实现细节)
-
- [3.1.1 数据集](#3.1.1 数据集)
- [3.1.2 算法参数](#3.1.2 算法参数)
- [3.1.3 损失函数和训练](#3.1.3 损失函数和训练)
- [3.2. 结果](#3.2. 结果)
-
- [3.2.1. 计算复杂度和参数](#3.2.1. 计算复杂度和参数)
- [3.2.2. 客观评价](#3.2.2. 客观评价)
- [3.2.3. 主观测试](#3.2.3. 主观测试)
- [3.2.4. 讨论](#3.2.4. 讨论)
- [4. 总结](#4. 总结)
摘要
作者提出了一种降低语音增强模型计算复杂度的方法。该方法使用两阶段处理框架,采用通道特征重定向(reorientation)来降低卷积操作的计算量。通过将其与改进的幂率压缩技巧相结合,提出的方法在保持与最先进的模型降噪性能相当的同时,显著降低了计算量和参数量。
1. 介绍
最先进的语音增强方法通常使用基于 encoder-decoder 的 DNN 架构,并且作用在时频域。但这种方法基本都需要大量的计算资源。
为了克服这个问题,已经提出了很多方法,包括通道维频率划分,多带处理以及使用分析滤波器组。PercepNet 和 DeepFilternet2 为了克服该问题使用 ERB(triangular equivalent rectangular bandwidth) 滤波器组。然而,该方法只能估计 ERB 带上的实数增益。为了进一步增强语音的相位成分,有些研究使用了梳妆滤波器(comb filter)和深度滤波(deep filtering)方法。
然而,这些方法虽然降低了计算复杂度,但与此同时也牺牲了效果。因此,这项工作在前人的基础上,提出了两阶段的处理框架来解决该问题。在第一个阶段,使用 CRN 结构来估计一个实数幅度 mask。在第二个阶段,使用一个更小的 CNN 结构来增强语音的相位信息。为了降低 CRN 中卷积的计算复杂度,作者使用了前人提出的 channelwise feature reorientation 方法。与文献中常见方法不同的是,作者没有使用 decoder 来估计幅度 mask。进一步,为了确保输入特征和训练目标的鲁棒性,作者还使用了一种改进的幂律压缩方法。
文章提出的模型只有 688K 参数量,计算复杂度为 0.098 GMACS。
2. 方法
2.1. 输入预处理
令 X ( n , k ) , S ( n , k ) , N ( n , k ) X(n,k), S(n,k), N(n,k) X(n,k),S(n,k),N(n,k) 分别表示 STFT 域的含噪信号,语音信号和噪声信号, n , k n,k n,k 分别表示帧索引和频率索引。模型的输入是从含噪信号的实部和虚部计算出的幅度和相位特征。含噪信号可以被表示为:
X ( n , k ) = X r ( n , k ) + j X i ( n , k ) = ∣ X ( n , k ) ∣ e j θ X \begin{align} X(n,k) = X_r(n,k) + jX_i(n,k) = |X(n,k)|e^{j\theta_X} \end{align} X(n,k)=Xr(n,k)+jXi(n,k)=∣X(n,k)∣ejθX
X r ( n , k ) , X i ( n , k ) , ∣ X ( n , k ) ∣ , θ X X_r(n,k), X_i(n,k), |X(n,k)|, \theta_X Xr(n,k),Xi(n,k),∣X(n,k)∣,θX 分别表示含噪信号的实部,虚部,幅度和相位。后续章节的介绍中将省略 ( n , k ) (n,k) (n,k)。
一般来说,幂律压缩是只在幅度 ∣ X ∣ |X| ∣X∣ 上施加一个压缩因子 α ∈ 0 , 1 \alpha \in 0,1 α∈0,1 。然而,在这项工作中,作者打算通过估计复数 mask 来直接估计干净语音的实部( S r S_r Sr)和虚部( S i S_i Si)。因此,对 X X X 的实部和虚部分别使用幂律压缩:
X ~ r = sign ( X r ) ∣ X r ∣ α ; X ~ i = sign ( X i ) ∣ X i ∣ α ; \begin{align} \tilde{X}_r = \text{sign}(X_r)|X_r|^{\alpha}; \; \tilde{X}_i = \text{sign}(X_i)|X_i|^{\alpha}; \end{align} X~r=sign(Xr)∣Xr∣α;X~i=sign(Xi)∣Xi∣α;
其中 sign ( X r / i ) \text{sign}(X_{r/i}) sign(Xr/i) 表示 X r / i X_{r/i} Xr/i 的符号。接着,计算以下两个特征:
X ~ m = X ~ r 2 + X ~ i 2 ; X ~ p = arctan X ~ i X ~ r ; \begin{align} \tilde{X}_m = \sqrt{\tilde{X}_r^2 + \tilde{X}_i^2};\; \tilde{X}_p = \text{arctan}\frac{\tilde{X}_i}{\tilde{X}_r}; \end{align} X~m=X~r2+X~i2 ;X~p=arctanX~rX~i;
最后,将 X ~ m \tilde{X}_m X~m 和 X ~ p \tilde{X}_p X~p 作为特征输入给模型。
2.2. 两阶段处理和干净语音估计
第一阶段将 X ~ m \tilde{X}_m X~m 作为输入,在幅度域进行计算。所使用的网络结构如图 1 所示,这将生成一个实数幅度 mask M ˉ m ∈ 0 , 1 \bar{M}_m \in 0,1 Mˉm∈0,1.
作者用 M ˉ m \bar{M}_m Mˉm 和 X ~ p \tilde{X}_p X~p 来计算第二阶段的输入:
Y ~ r = M ˉ m ∗ cos X ~ p ; Y ~ i = M ˉ m ∗ sin X ~ p ; \begin{align} \tilde{Y}_r = \bar{M}_m * \text{cos} \tilde{X}_p; \; \tilde{Y}_i = \bar{M}_m * \text{sin} \tilde{X}_p; \end{align} Y~r=Mˉm∗cosX~p;Y~i=Mˉm∗sinX~p;
作者还尝试了将该 mask 与含噪语音的幅度和相位相结合,但实验结果表明 ( 4 ) (4) (4) 中的特征对第二阶段是有益的。
接着,将 Y ~ r \tilde{Y}_r Y~r 和 Y ~ i \tilde{Y}_i Y~i 在通道维进行拼接(如图 1 所示),并输入给一个复数 CNN 网络来估计复数 mask M M M。
为了估计干净语音 S S S,作者参考 DCCRN 中的做法,将含噪信号 X ~ \tilde{X} X~ 和 M M M 相乘。由于使用了幂律压缩,因此也需要逆过程:
S ^ r / i = sign ( S ~ r / i ) ∣ S ~ r / i ∣ 1 / α ; S ^ = S ^ r + j S ^ i \begin{align} \hat{S}{r/i} = \text{sign}(\tilde{S}{r/i})|\tilde{S}_{r/i}|^{1/\alpha}; \; \hat{S} = \hat{S}_r + j\hat{S}_i \end{align} S^r/i=sign(S~r/i)∣S~r/i∣1/α;S^=S^r+jS^i
2.3. 模型设计
第一阶段使用 CRN 架构,第二阶段使用 CNN 架构。在 CRN 架构的卷积部分,作者设计了一个包含了 4 4 4 层二维深度可分离卷积层的卷积块。该卷积块的目标是对输入特征在频率维度降采样,然后进行有效地特征提取。
尽管使用了深度可分离卷积,但作者发现在 CRN 架构中,卷积操作的计算复杂度仍然最高。为了解决该问题,作者使用了前人提出的通道特征重定向方法。该方法被证明能在高分辨率音乐中提高声音分离的性能,并降低计算复杂度。作者发现与传统的卷积相比,将该方法与可分离卷积相结合,计算复杂度能降低 5 5 5 倍左右。
在卷积块的后面接了一个频率维度的双向 GRU(FGRU),用以增加感受野并促进频域维度的信息共享,其后接了一层逐点卷积层。接着,将得到的特征划分到子带,并使用子带 temporal GRU 块进行处理。然后,使用两个全连接层来得到幅度 mask M ˉ m ∈ 0 , 1 \bar{M}_m \in 0,1 Mˉm∈0,1,如图 1 所示。
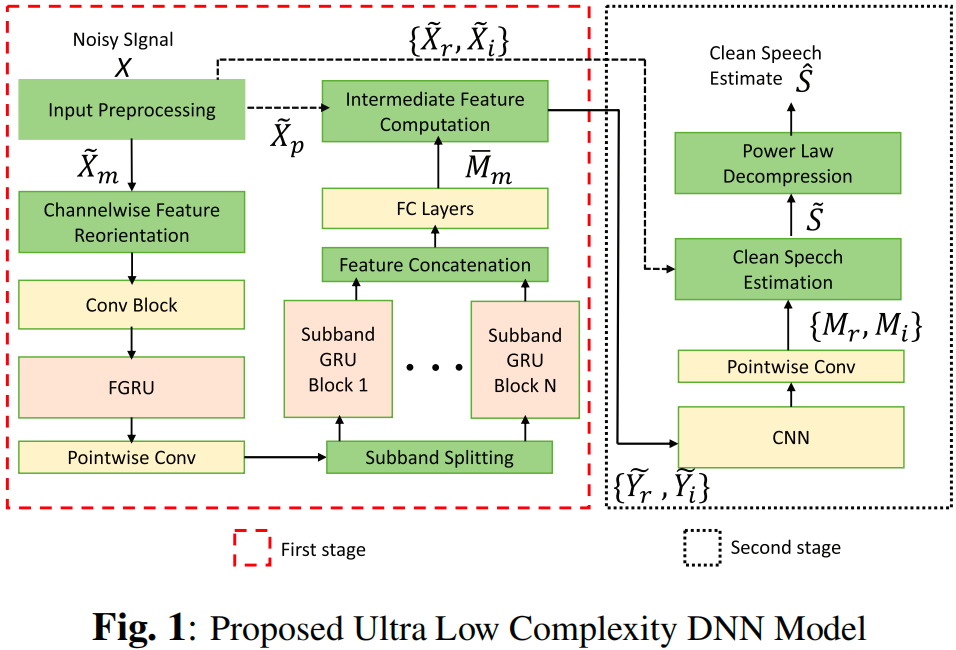
在第二阶段,使用 CNN 架构得到最终的复数 mask M M M。而且该 CNN 架构的参数量仅为全部参数量的 0.5 % 0.5\% 0.5%。
3. 实验和结果
3.1. 实现细节
3.1.1 数据集
使用 Interspeech 2020 DNS 挑战赛的数据集来训练模型。训练集和验证集中的含噪语音是通过随机选取干净语音数据集和噪声数据集中的语料,并将它们按照 − 10 dB -10\text{dB} −10dB 到 30 dB 30\text{dB} 30dB 的信噪比随机进行混合得到的,且采样率限制为 16 kHz 16 \text{kHz} 16kHz。总共生成了约 1000 1000 1000 小时的训练集。将训练集和验证集中 50 % 50\% 50% 的数据卷积上 RIR。在数据增强阶段,作者使用了随机低通滤波,上采样和不同的 STFT 窗。
3.1.2 算法参数
计算 STFT 的过程中,使用的窗长为 32 ms 32\text{ms} 32ms,帧移为 16 ms 16\text{ms} 16ms,FFT 长度为 512 512 512,总共生成 257 257 257 个有效频点。对于通道特征重定向,作者使用一个重叠的矩形窗,其频率分辨率为 1.5 kHz 1.5\text{kHz} 1.5kHz( 48 48 48 个频点),重叠因子为 0.33 0.33 0.33,这总共会生成 8 8 8 个子带。卷积块中的四个可分离卷积层只在频率维度进行卷积,其使用的 kernel size 为 ( 1 × 3 ) (1\times3) (1×3),卷积滤波器个数分别为 { 32 , 64 , 96 , 128 } \{32,64,96,128\} {32,64,96,128}。除了第一个卷积层外,其它三个卷积层使用因子为 2 2 2 的 max-pooling 进行下采样。FGRU 层包含 64 64 64 个单元,其后的逐点卷积输出通道数为 64 64 64。作者使用两个子带 temporal GRU 块,每个块包含两层 GRU,每层包含 128 128 128 个单元。其后的两层 FC 的节点数均为 257 257 257。第二阶段的 CNN 架构包含两层二维卷积层,其输出通道数为 32 32 32,kernel size 为 ( 1 , 3 ) (1,3) (1,3),以及一层逐点卷积层,其输出通道数为 2 2 2。
3.1.3 损失函数和训练
作者使用各种损失函数来训练模型。实验结果表明 MSE 和多尺度(multi-scale,MS)损失函数对于作者提出的网络结构更加有效。作者使用这两个损失函数训练了两个模型,每个模型使用不同的因子。第一个模型是 ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq,损失函数为 MSE,且 α = 0.3 \alpha=0.3 α=0.3,损失是在幂律压缩的干净语音 S S S 和估计的干净语音 S ~ \tilde{S} S~ 上进行计算的。第二个模型是 ULCNet MS \text{ULCNet}{\text{MS}} ULCNetMS,不使用幂律压缩( α = 1 \alpha=1 α=1),仅使用 MS 损失函数。在训练过程中,使用 Adam 优化器,初始学习率为 4 × 10 − 4 4 \times 10^{-4} 4×10−4,且每三个 epoch 学习率就会变为 1 / 10 1/10 1/10。
3.2. 结果
作者将提出的模型与 NSNet2、PercepNet、FullSubNet+、DeepFilterNet 和 Deep-FilterNet2 进行了比较。
3.2.1. 计算复杂度和参数
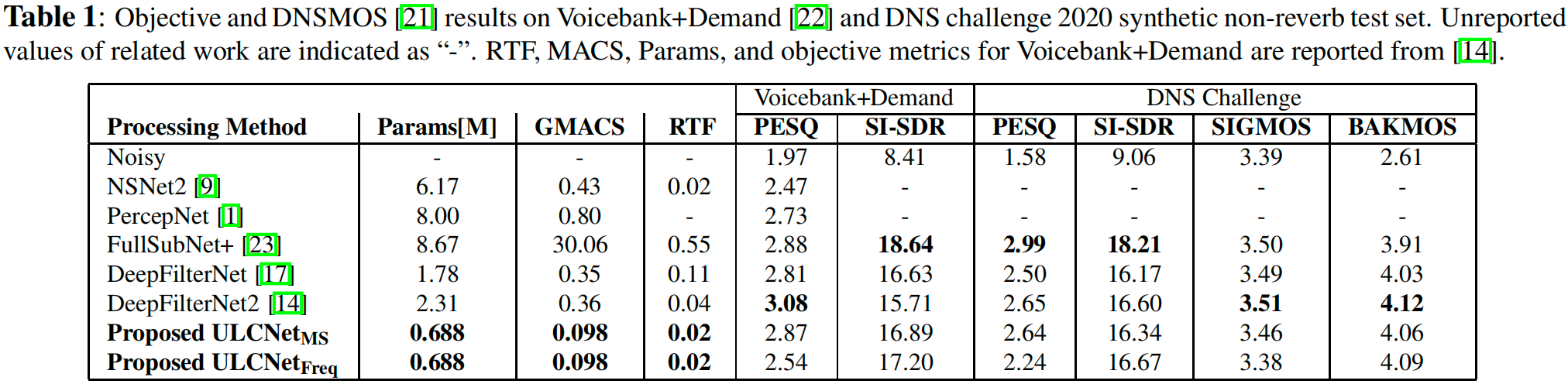
表 1 给出了 ULCNet 模型的计复杂度指标,参数量为 688 K 688\text{K} 688K。
3.2.2. 客观评价
作者在 Voicebank+Demand 测试集上,计算 PESQ 和 SI-SDR 指标,结果如表 1 所示。FullSubNet+ 的 SI-SDR 最高。 ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq 的 SI-SDR 第二高,但其 PESQ 较低。DeepFilterNet2 的 PESQ 最高,但其 SI-SDR 最低。 ULCNet MS \text{ULCNet}{\text{MS}} ULCNetMS 的 PESQ 和 SI-SDR 与其它算法相当。
在 DNS 挑战赛测试集上,FullSubNet+ 在 PESQ 和 SI-SDR 的提升上均优于其它算法。其余算法的结果均相当,除了 ULCNet Freq \text{ULCNet}_{\text{Freq}} ULCNetFreq,其 PESQ 最低。
3.2.3. 主观测试
客观指标可以对不同算法的性能进行初步的比较分析。然而,最近的研究表明,这些客观指标与人类在噪声抑制任务中的主观评价的相关性有限,因为每个人对噪声和失真的感知都是独特的。作者所做的非正式主观评价经验也与此观点相符,尽管 ULCNet Freq \text{ULCNet}_{\text{Freq}} ULCNetFreq 在 PESQ 提升上表现不佳,但在降噪方面却很有效。因此,作者进行了两项主观评估实验,要求测试者从降噪量和语音失真度两方面,对不同算法进行对比。共有 32 位测试者参加了此次评估,包含专业听众和非专业听众。
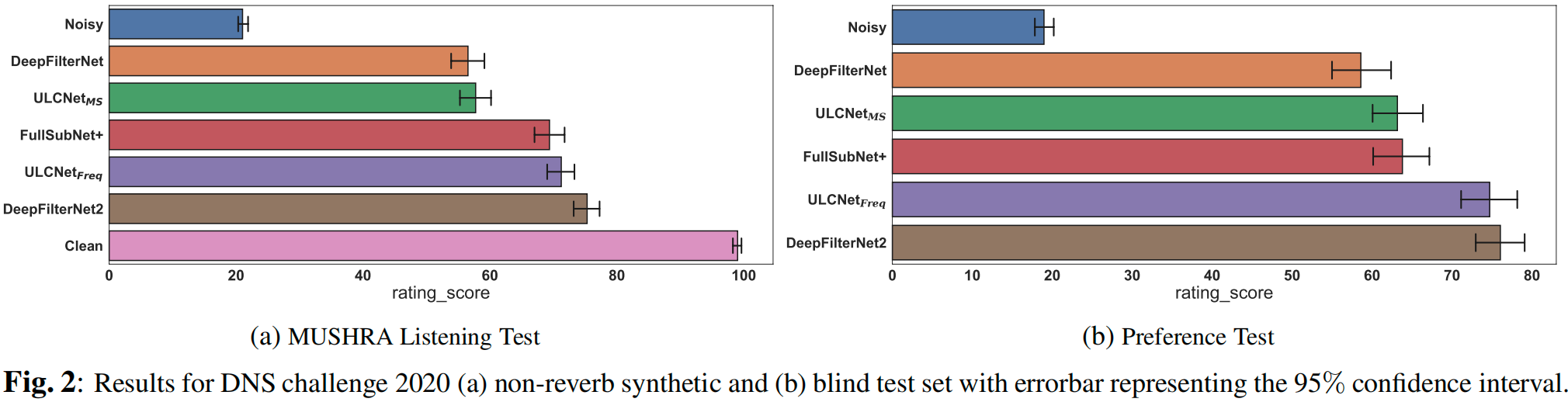
MUSHRA: 在 MUSHRA 测听实验中,作者从 DNS 2020 测试集中选取 10 条含噪语音,将未处理过的干净语音作为参考,将未处理过的含噪语音作为锚定信号。测试者被要求对干净语音打 100 分(这是 MUSHRA 评分标准的最高分)。在图 2.a 给出的结果中,DeepFilterNet2 和 ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq 是表现最好的,分数分别为 75.46 和 71.72。FullSubNet+ 要优于 ULCNet MS \text{ULCNet}{\text{MS}} ULCNetMS and DeepFilterNet。
偏好性测试: 在偏好性测试中,作者从 DNS 2020 盲测集中选取 12 条含噪语音。该测试旨在盲测不同方法的性能。由于没有对应的干净语音,作者使用含噪语音作为隐藏参考。与 MUSHRA 测试结果类似,如图 2.b 所示,DeepFilterNet2 和 ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq 在此次测试中表现最佳。 ULCNet MS \text{ULCNet}{\text{MS}} ULCNetMS 取得了与 FullSubNet+ 相当的结果,并且优于 DeepFilterNet。
3.2.4. 讨论
可以看到,在主观评价中,作者提出的幂律压缩方法有助于在降噪过程中获得更好的主观感知质量。如图 2.b 和表 1 所示,在 DNS 挑战赛测试集上, ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq 相比 ULCNet MS \text{ULCNet}{\text{MS}} ULCNetMS(未使用幂律压缩方法)获得了更高的主观分(与 PESQ 相比)。这种改进源于作者的方法使用更激进的降噪策略,引入了一些人类听起来并不严重的失真。这一点也能从表 1 中的 BAKMOS 和 SIGMOS 两项指标看出。
也可以看到,当测试人员听到未经处理的干净语音时,他们对残余噪声和语音失真的分辨能力更强。因此,如图 2 所示, ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq 和 DeepFilterNet2 在偏好性测试和 MUSHRA 测试中的平均主观分差距从 1.34 略微增加到 4.07。然而 ULCNet Freq \text{ULCNet}{\text{Freq}} ULCNetFreq 的整体表现相当令人满意,与 DeepFilterNet2 相当,并且明显优于其它所有算法。可在 https://fhgainr.github.io/ULCNet/ 中主观评测算法处理完的样本效果。
4. 总结
值得借鉴的地方:
a. 两阶段处理框架 :先估计实数 mask, 然后在此基础上估计复数 mask;
b. 通道特征重定向(channelwise feature reorientation) :将频域维度的特征整合到通道维度,以降低频率维度的特征数,从而降低计算量;
c. 频率维度双向 GRU(FGRU) :增加频率维度的感受野和信息共享;
d. 时间维度子带 GRU : 每个子带单独处理,进一步降低计算复杂度;
e. 两维度 GRU 模块 :由上述两个频率维度的 GRU 和时间维度的子带 GRU 串联组成;
可以改进的地方:
a. CNN 参数优化:
- 增加时间维度的感受野(即令 kernel size 大于 1 1 1);
- 用 stride > 2 替代 max_pooling = 2;