了解AI到理解AI
以下是个人学习的总结(二),干货满满,还望仔细阅读,如有问题,欢迎留言。
------转载、引用请标明出处
核心层:LLM 怎么工作(内部机制)
工作流程
先建立一个核心认知:
LLM 每次生成一个词,内部经历的完整流程是:
文字 → 词元(token) → 数字(Embedding) → 理解上下文(Attention) → 预测下一个词对于图像、音视频等,流程基本一样,只是不同模态的切割(Token化}方式不同。
第一步:分词(Tokenization)- 以文字切成Token为例
文本输入进来之后,第一件事不是直接转模型认识的数字,而是先切割成一个个 Token。
Token 不等于"一个词",它是模型处理文字的最小单位,切割规则大概是:
css
常见词 → 一个词 = 一个 Token
"cat" → [cat]
较长的词 → 一个词被拆成几个 Token
"unhappiness" → [un] [happiness]
中文 → 通常每个字 = 一个 Token
"今天天气" → [今天] [天气]
或 [今] [天] [天] [气]为什么不直接按字母/字切?
如果每个字母都是一个 Token,序列会极长,计算量爆炸。如果整个词是一个 Token,词表会无限大(新词、专有名词都处理不了)。 按子词切割是一个平衡点。
总结:让模型学会将用户目标切割为最小单位
第二步:向量(Embedding)
模型不认识文字,只能处理数字。
但简单编号不行------你不能说"猫=1,狗=2,苹果=3",因为这样 1 和 2 的距离,跟 2 和 3 的距离一样,完全体现不出"猫和狗都是动物、苹果是水果"这种语义关系。
所以 Embedding 的做法是:把每个词映射成一串很长的数字(比如 768 个),让这串数字在空间里的位置,能反映这个词的语义。
向量的位置在空间里是有意义的------意思相近的词,向量方向相近。
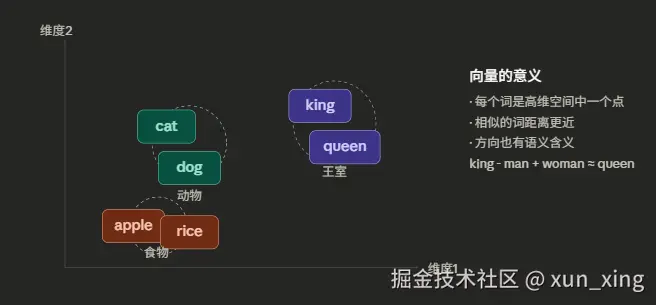
这样每个 Token 都有一个对应的编号(比如"今天" = 3721),然后通过 Embedding 表,把这个编号转换成一串数字向量。
arduino
"猫" → [0.2, 0.8, 0.1, -0.3, ...]
"狗" → [0.19, 0.75, 0.15, -0.28, ...] ← 和猫很接近
"苹果"→ [-0.5, 0.1, 0.9, 0.6, ...] ← 和猫、狗差的远类比:
就像地图上的坐标。北京和天津的坐标很接近,北京和纽约的坐标很远。Embedding 就是给每个词在"语义地图"上标一个坐标。
但 Embedding 有一个致命缺陷:
每个词的坐标是固定的,不管它出现在什么句子里,坐标都一样。
arduino
"我去银行取钱" ← 这里"银行"= 金融机构
"河的银行边很美" ← 这里"银行"= 河岸(bank)这就是 Embedding 解决不了的问题------它只能给词一个"初始坐标",不能理解语境。
这个问题要靠后面的步骤 Attention 来解决。
总结:让模型学会将Token 变成向量(数字)
第三步:注意力机制(Attention)+FFN
- 注意力机制(Attention)
注意力机制(Attention)的任务是:让每个词的向量,根据它周围的词,更新自己的含义(向量)。
具体怎么做?对句子里的每一个词,Attention 都会让它去问其他所有词:"你和我有多相关?"
然后根据相关程度,把其他词的信息融合进来,更新自己的向量。
用"我去银行取钱"举例:
arduino
"银行"这个词问其他词:
→ "我" 相关度:低
→ "去" 相关度:低
→ "取钱" 相关度:非常高 ✦
→ "河" 相关度:低(如果有的话)发现"取钱"和自己高度相关,于是"银行"把"取钱"的信息大量融合进来,向量更新之后,它就明确指向"金融机构"的含义了。
换到"河的银行边很美":
arduino
"银行"这个词问其他词:
→ "河" 相关度:非常高 ✦
→ "美" 相关度:中等
→ "取钱" 不存在这次融合了"河"的信息,向量更新之后,就指向"河岸"的含义。
同一个词,在不同句子里,经过 Attention 之后,向量就不一样了。 这就是 Attention 解决了 Embedding 那个缺陷的原因。
类比:
每个词就像一个人站在人群里开会。Embedding 给了每个人一张"自我介绍卡片"(初始含义)。Attention 是让每个人去听其他人说话,根据谁说的话跟自己最相关,更新自己的理解。
开完会之后,每个人的理解都充分融合了上下文。
总结:让模型学会"注意"句子里哪些地方重要------每个词去参考周围的其他词,更新自己的向量
- FFN(Feed-Forward Network,前馈神经网络)
FFN 是 Attention 之后紧跟的一个处理步骤。
注意力负责词与词之间的信息交换,FFN(Feed-Forward Network,前馈神经网络)负责对每个词的向量单独做深度加工。
类比:
Attention 是开会讨论(大家互相交流信息),FFN 是每个人回去之后独立消化整理(把讨论结果内化成自己的理解)。两步缺一不可。
第五步:Transformer
Transformer 就是把 Embedding 和 Attention 组装起来,再反复叠加很多层的完整架构。
makefile
输入文字:"今天天气真好"
↓
【Tokenization分词 层】:[今天],[天气],[真],[好]
↓
【Embedding 向量层】
每个词变成一个初始向量
"今天"→[...], "天气"→[...], "真"→[...], "好"→[...]
↓
【第一层 Transformer】
├─ Attention:四个词互相参考,更新向量
│ "天气" ←→ "好" 关联度高 → 互相融合信息
│ "今天" ←→ "天气" 关联度高 → 互相融合信息
└─ FFN:每个词独立消化,提炼向量
→ 理解基础关联:"今天"修饰"天气"
↓
【第二层 Transformer】
├─ Attention:在上一层基础上再次互相参考
└─ FFN:再次独立提炼 → 理解语义:"天气真好"是一个正面评价
↓
【第三层 Transformer】
├─ Attention:继续
└─ FFN → 理解语气:这是一句感叹句
↓
【第四层 ... 第 N 层 Transformer】
每层 Attention + FFN 重复一次
越深的层,理解越抽象、越高级(GPT-2: 12层 / LLaMA-7B: 32层 / GPT-3: 96层)
↓
【LM Head 输出层】
把最后一层的最终向量映射成词表里所有 Token 的原始分数
"!" → 8.2
"," → 6.1
"呀" → 5.3
"飞机"→ 0.4
...(词表里每个词都有一个分数,即 Logits)
↓
【采样】
按概率选出下一个Token(不是每次都选最高概率,而是加权随机)
↓
【输出 Token,拼接后重复】
选出"!"→ 拼到句子后面
"今天天气真好!"→ 重新进入流程预测下一个词
直到生成结束标志或达到长度上限如果上述例子不够清晰,可以访问Transformer Explainer
这是一个GPT-2模型的真实例子------你输入一段文字,可以实时看到 Embedding、Attention、每层的数据流动全过程,数值会随你的输入实时更新。
三者关系一句话总结:
Embedding → 给每个词一个"初始数字坐标"
Attention → 让每个词根据上下文更新自己的坐标
Transformer → 把上面两步反复叠加 N 层的完整架构
这三个不是并列的独立模块,而是从小到大的包含关系:Embedding 和 Attention 是零件,Transformer 是用这些零件组装出来的引擎。
温度(temperate)
LLM中的温度是什么?(详见:详解LLM 中的温度------Predictable Random(可预测↔随机) - 知乎))
较低的 temperate 值会从 LLM 产生相同的响应,但是高温度值会产生胡言乱语。
Temperature 就是卡在输出层和采样之间的一个调节旋钮。
Transformer 最后一层处理完之后,输出的是词表里每个 Token 的原始分数 ,叫做 Logits:
arduino
"今天天气真好"之后:
"!" → Logits: 8.2
"," → Logits: 6.1
"呀" → Logits: 5.3
"飞机" → Logits: 0.4
...(词表里所有词都有一个分数)这些分数还不是概率,只是原始的"倾向强度"。要变成概率,需要经过一个叫 Softmax 的函数,把所有分数压缩成加起来等于 100% 的概率分布:
erlang
"!" → 45%
"," → 30%
"呀" → 20%
"飞机" → 1%
...Temperature 就插在 Logits → Softmax 这一步之间。
Temperature 具体做什么?
它的操作很简单------在 Softmax 之前,把所有 Logits 除以 Temperature 的值:
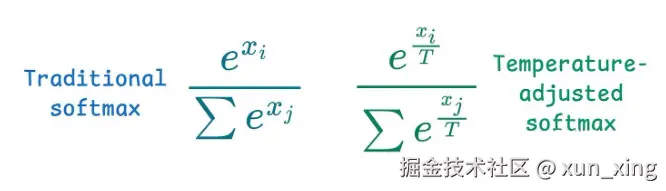
- Temperature 默认值(1,不影响)
arduino
Logits 不变 → Softmax → 正常概率分布
"!" 45% "," 30% "呀" 20% "飞机" 1%- Temperature 调低(拉大差距)
arduino
如 Logits ÷ 0.5 → 数值变大,高分和低分差距拉大
→ Softmax 后高概率的词更突出
"!" 80% "," 15% "呀" 4% "飞机" 0%-
这意味着采样过程几乎肯定会选择概率最高的 token,。
-
这使得生成过程变得贪婪且(几乎)具有确定性(输出更稳定)。
-
Temperature 调高(缩小差距)
arduino
如 Logits ÷ 2 → 数值变小,高分和低分差距缩小
→ Softmax 后概率分布更均匀
"!" 28% "," 25% "呀" 22% "飞机" 8%- 这意味着采样过程可以选择任何令牌。
- 这使得生成过程随机且高度随机。
快速说明:
在实践中,即使 temperature=0还是有可能生成不同的结果。
- 完整流程
makefile
......
【LM Head 输出层】
把最后一层的最终向量映射成词表里所有 Token 的原始分数
"!" → 8.2
"," → 6.1
"呀" → 5.3
"飞机"→ 0.4
...(词表里每个词都有一个分数,即 Logits)
↓
【Temperature 缩放】
所有 Logits ÷ Temperature 值
Temperature = 0.5 → 高分更突出 → 输出保守稳定
Temperature = 1.0 → 保持原样 → 正常输出
Temperature = 2.0 → 分差缩小 → 输出随机多样
↓
【Softmax 概率化】
把缩放后的 Logits 转换成概率(所有词加起来 = 100%) "!" → 45% "," → 30% "呀" → 20% "飞机"→ 1%
↓
【采样】
按概率选出下一个Token(不是每次都选最高概率,而是加权随机)
↓
【输出 Token,拼接后重复】
选出"!"→ 拼到句子后面
"今天天气真好!"→ 重新进入流程预测下一个词
直到生成结束标志或达到长度上限核心层:LLM 的局限
大语言模型(LLM)的主要缺点有三点:
-
新鲜度问题(训练数据有截止日期,不了解最新信息)
-
数据安全问题(企业敏感数据不敢上传公网)。
-
幻觉问题(一本正经地胡说八道)
其中新鲜度问题已基本被解决,像GPT-4 Turbo这样的最新大模型就有类似RAG(Retrieval Augmented Generation,检索增强生成)这样的技术,可以借助外挂快速吸收最新知识(世界知识)。
数据安全可通过本地化部署缓解,最棘手的就是幻觉。
新鲜度问题------数据时效
模型的知识来自训练数据,而训练数据有截止日期。GPT-4 的知识截止到某个时间点,之后发生的事它一概不知。
你问它"今天的股价"、"最新的政策法规"、"上周发生的新闻",它要么不知道,要么给你旧数据。
这个问题相对好处理,目前主要靠两种方式:
RAG(检索增强生成) :每次用户提问,先去实时检索最新的外部知识库或网络,把检索结果塞进 Prompt,再让模型基于最新信息回答。这是现在最主流的解法,本质上是给模型装了一双"实时查资料的眼睛"。
联网搜索:直接让模型调用搜索引擎工具,每次回答前先搜一遍,确保信息是最新的。
检索增强生成 (RAG)
检索增强生成(Retrieval Augmented Generation, RAG)是一种将信息检索(Retrieval)与文本生成(Generation)相结合的技术框架。
其核心思想是在LLM生成文本之前,先从一个外部知识库中检索相关的最新信息,并将这些信息作为上下文(context)提供给LLM,从而指导LLM生成更准确、更相关、更及时的内容。
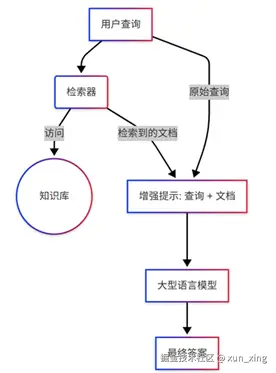
RAG系统通常包含以下三个主要步骤:
- 检索 (Retrieve) :当用户提出一个查询或提示时,RAG系统首先使用一个检索器(Retriever)从外部知识
- 增强 (Augment) :检索到的信息片段会与用户的原始查询或提示合并,形成一个增强的提示(augmented prompt)。
- 生成 (Generate) :增强的提示被输入到LLM中,LLM基于原始查询和检索到的上下文信息生成最终的回复。
RAG的优势
- 提高准确性和事实性:通过引入外部知识,减少幻觉。
- 增强知识的时效性:能够获取最新的信息。
- 降低训练成本:无需为获取新知识而频繁重新训练LLM。
- 提高透明度和可信度:可以追溯信息来源。
- 领域专业化:更容易适应特定领域的知识需求。
数据安全问题------隐私泄露
企业想用 AI 处理内部数据,但有三层顾虑:
-
训练数据泄露:模型可能因为"记忆效应",在输出中复述训练数据------比如用户的隐私信息、企业的商业机密被 AI 原样说出来。
-
数据上传风险:把公司的合同、财务数据、客户信息上传到第三方 AI 平台,万一平台把这些数据用于训练下一代模型怎么办?数据一旦上传,企业就失去了控制权。
-
合规风险:一家韩国初创公司曾因聊天中泄露敏感客户数据,被韩国政府罚款约 9.3 万美元。2023 年 Google 的 AI 聊天机器人因分享不准确信息,市值缩水了 1000 亿美元。在金融、医疗、政务等行业,数据合规是红线。
目前主要有三种解决方向:
| 方案 | 做法 | 适合场景 |
|---|---|---|
| 私有化部署 | 把模型部署在企业自己的服务器上,数据不出内网 | 对数据安全要求极高的金融、政务 |
| 数据脱敏 | 上传前把敏感信息替换掉(如把"张三"替换成"用户A") | 数据需要上云但有敏感字段 |
| 权限控制 | 不同级别的员工只能访问对应权限的数据,AI 也遵守这套规则 | 大型企业内部知识库 |
幻觉问题------棘手问题
前两个问题都有相对成熟的解法,而幻觉是三个里最棘手的,因为它根植于 LLM 的底层原理,无法彻底消除。
大语言模型采用自回归方式生成文本------每次根据已有内容预测下一个 Token,这个过程的直接目标是保证语言的连贯性,而不是保证事实的准确性。
换句话说,模型不是在"查找正确答案",而是在"预测听起来合理的下一个词"。这两件事大多数时候结果一致,但有时会产生流畅却错误的输出------这就是幻觉。
但是,彻底消灭随机性,模型就变成复读机;保留随机性,幻觉就永远存在。所以幻觉只能缓解,不能消灭。
幻觉的危害有多大?
在法律领域,幻觉可能杜撰出不存在的判例法规;在医疗咨询中,可能提供错误的药物建议;在金融与军事决策中,一个基于幻觉的分析可能导致灾难性的后果。
还有一个更隐蔽的危害:AI 生成的虚假信息如果被大量传播,可能反过来被用作下一代模型的训练数据,导致新模型中产生更多幻觉------这是一个越来越严重的恶性循环。
四种缓解方法:
-
Prompt 工程:问题描述越具体,模型"自由发挥"的空间越小。与其说"帮我分析一下",不如说"基于以下三个数据,分析 XX 趋势,不要引用数据之外的信息"。
-
RAG(检索增强生成) :让模型回答前先查资料,有据可查就很难瞎编。这是目前商业场景中抑制幻觉最有效的方案。
-
微调(Fine-tuning) :在特定领域的专业数据上再训练一遍,让模型"更懂行",减少因知识不足导致的乱猜。缺点是数据是静态的,更新成本高。
-
幻觉检测(事后校验) :让模型对同一问题多次生成,如果每次答案差异很大,说明模型不确定,这条输出可信度低,需要人工复核或直接过滤。
核心层:Agent(智能体)
智能体(Agent)是一种能够感知其环境、进行思考和规划,并采取行动以实现特定目标的计算实体。
在学习 Agent 之前,先把已知的 LLM 知识和 Agent 连起来:
LLM、RAG 和 Agent 三者之间存在层层递进的关系:LLM 是基础,提供语言理解和生成能力;RAG 是 LLM 的增强插件,解决知识新鲜度和幻觉问题;Agent 是更高级的系统,以 LLM 为大脑,RAG 作为其中一个可调用的工具。
Agent的组件
一句话定义:Agent = LLM + 规划 + 记忆 + 工具调用
scss
┌─────────────────────────────┐
│ Agent │
│ │
│ ┌───────┐ ┌───────────┐ │
│ │ LLM │ │ 记忆 │ │
│ │ (大脑) │ │ (短期+长期)│ │
│ └───────┘ └───────────┘ │
│ │
│ ┌──────────────────────┐ │
│ │ 工具箱 │ │
│ │ 搜索 / 代码 / RAG ✦ │ │
│ └──────────────────────┘ │
└─────────────────────────────┘在当前的AI语境下,AI Agent通常以一个强大的LLM作为其核心"大脑",并辅以其他关键组件:
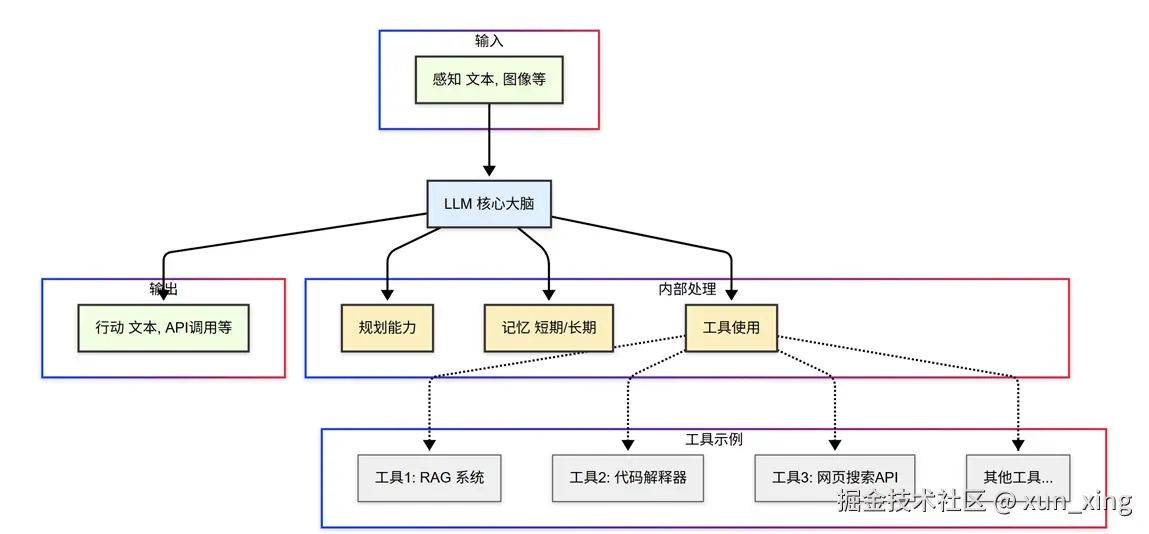
- LLM (大脑) :作为Agent的核心,负责理解用户指令、进行常识推理、制定计划、甚至生成行动指令。
- 规划能力 (Planning) :Agent能够将复杂的目标分解为一系列可执行的子任务,并制定行动计划。这可能涉及到多步推理和决策。
vbnet
例:用户说"帮我调研竞争对手并写一份报告"
Agent 的规划:
Step 1:搜索竞争对手的最新动态
Step 2:搜索竞争对手的产品信息
Step 3:整理搜索结果
Step 4:生成对比分析
Step 5:撰写报告
这个能力叫 **ReAct(Reasoning + Acting)** ,是目前最主流的 Agent 工作模式:
思考(Thought)→ 行动(Action)→ 观察结果(Observation)
↑___________________________________|
循环直到完成- 记忆 (Memory) :和 Context 概念直接相关,Agent可以拥有短期记忆(用于跟踪当前任务的上下文)和长期记忆(用于存储过去的经验和知识,以便在未来任务中复用)。
| 记忆类型 | 对应概念 | 特点 |
|---|---|---|
| 短期记忆 | Context 窗口 | 当前对话内容,关闭即消失 |
| 长期记忆 | 外部向量数据库 | 持久保存,需要检索调取 |
-
工具使用 (Tool Use) :这是 Agent 和普通 LLM 最大的区别。Agent可以被赋予使用各种外部工具的能力,例如搜索引擎、计算器、代码解释器、API接口等。这使得Agent能够获取LLM本身不具备的信息或执行LLM无法完成的操作。
-
感知 (Perception) :虽然目前主要基于文本,但后续的Agent可能会拥有更丰富的感知能力,例如处理图像、音频等多模态信息。
Agent与LLM
Agent的核心通常是LLM,但两者之间存在关键区别:
| 特征 | 大型语言模型 (LLM) | 智能体 (Agent) |
|---|---|---|
| 主要功能 | 理解和生成文本 | 感知、思考、规划并采取行动以实现目标 |
| 交互方式 | 通常是被动响应用户输入 | 主动与环境交互,执行任务 |
| 决策能力 | 有限的决策能力,主要基于模式匹配和概率生成 | 具有更强的决策和规划能力,能够自主选择行动路径 |
| 工具使用 | 本身不直接使用外部工具(除非通过RAG等方式间接实现) | 可以主动调用和使用各种外部工具 |
| 目标导向 | 目标是生成连贯相关的文本 | 目标是完成用户指定的复杂任务或实现特定目标 |
| 自主性 | 较低 | 更高,可以在一定程度上自主行动 |
简单来说,LLM更像是一个强大的语言处理引擎,而Agent则是一个更完整的、具有自主行动能力的系统。
Agent 的工作循环
以一个示例来看Agent 的工作循环
任务:帮我规划一个去东京的三天旅行
erlang
【第一轮】
思考:需要了解东京的景点、天气、交通
行动:调用搜索工具,搜索"东京热门景点"
观察:拿到搜索结果
【第二轮】
思考:需要知道出行时间的天气
行动:调用天气 API,查询目标日期东京天气
观察:天气晴朗,适合户外活动
......
【第多轮】
思考:信息足够了,开始生成行程
行动:调用 LLM,整合所有信息生成三天行程
观察:行程草稿生成
【输出】
整理后的三天东京旅行计划LLM 作为Agent 大脑,始终是"决策者",而工具是"执行者",过程中记忆保存着每一步的结果供下一步使用。
多智能体(Multi-Agent)
单个 Agent 有能力上限,对于更复杂的任务,可以让多个 Agent 协作:
AI Agent 的核心在于将 LLM 的认知能力与工具调用能力深度耦合,通过感知---规划---行动的闭环实现复杂任务的自动化处理。 FME
多 Agent 系统就像一个公司:
markdown
协调者 Agent(CEO)
├── 搜索 Agent → 负责信息收集
├── 分析 Agent → 负责数据处理
├── 写作 Agent → 负责生成报告
└── 审核 Agent → 负责检查输出质量每个 Agent 专注自己的领域,协调者负责分配任务和整合结果。