目录
一、非比较排序:计数排序
(一)基本思想
计数排序又称 "鸽巢原理",是对哈希 "直接定址法" 的变形,无需比较元素大小,通过统计元素出现次数实现排序:
1、统计频次:遍历原数组,统计每个元素出现的次数。
2、回填序列:根据频次将元素按顺序回填到原数组,得到有序数组。
3、统计每个元素出现次数的Count数组
我们使用 Count 数组去统计,每个元素出现的次数。
常规计数排序按 "最大值 + 1" 申请空间(如元素范围 100,109,需申请 110 个空间),存在空间浪费,因为此时数组前面100个空间是没有用处的。
我们要进行优化,优化后按 "数据范围" 申请空间。
找原数组的最小值min和最大值max,计算范围range = max - min + 1 。申请大小为range的计数数组count,元素 ai 映射到 counta\[i - min] ,从而避免空间浪费。
也就是说元素范围为100,109时,count数组,开辟 (109-100+1) 个,即10个空间。
假如遍历到 a1=101,此时映射到count101-100,即count1的位置,此时count1++,即该元素出现次数加1。
(二)算法步骤
1、找极值:遍历原数组,找到最大值 max 和最小值 min,确定数据范围 range = max - min + 1。
2、初始化计数数组:申请大小为range的计数数组count,初始化为 0。
3、统计频次:遍历原数组,countarr\[i - min]++(将元素映射到count下标)。
4、回填原数组:遍历count数组,若counti > 0,将i + min(原元素大小)依次写入原数组,counti--,直至counti == 0。接着对count数组下一个位置进行遍历,直至遍历完全。
(三)代码实现
cpp
void CountSort(int* arr, int n)
{
if (n <= 1)
return;
// 1. 找原数组的min和max
int min = arr[0];
int max = arr[0];
for (int i = 1; i < n; i++)
{
if (arr[i] < min)
min = arr[i];
if (arr[i] > max)
max = arr[i];
}
// 2. 计算范围,申请计数数组,并初始化为0
int range = max - min + 1;
int* count = (int*)calloc(range, sizeof(int)); // 初始化为0
if (count == NULL) {
perror("calloc fail");
return;
}
// 3. 统计每个元素出现次数
for (int i = 0; i < n; i++)
count[arr[i] - min]++; // 元素映射到count下标
// 4. 回填原数组(按顺序写入)
int j = 0;
for (int i = 0; i < range; i++)
{
// 数据出现的次数为count[i],下标原数据为i + min
while (count[i]--)
arr[j++] = i + min; // 映射回原元素
}
free(count);
count = NULL;
}(四)复杂度与稳定性
1、时间复杂度
(1)找 min 和 max:遍历数组一次,时间复杂度为 O(n)。
(2)统计元素出现次数:遍历数组一次,时间复杂度为 O(n)。
**(3)**回填原数组:遍历计数数组(大小为 range),并处理每个元素的出现次数,总操作次数为 range + n(每个元素最终被回填一次),时间复杂度为 O(n + range)。
综上,整体时间复杂度由上述步骤中耗时最长的部分决定,即O(n + range)。
2、空间复杂度
空间复杂度为 O(range)。
主要消耗空间的部分:申请了大小为 range 的计数数组 count,用于存储每个元素的出现次数。其他变量(如 min、max、i、j 等)仅占用常数空间 O(1)。
因此,整体空间复杂度由计数数组的大小决定,即 O(range)。
3、稳定性分析
该实现 不具备稳定性。
在回填原数组时(步骤 4),代码通过 while (counti--) 将相同元素连续写入原数组,但并未区分这些元素在原数组中的原始位置。
二、各排序实际用时测量
(一)代码实现
cpp
// 测试排序的性能对⽐
void TestOP()
{
srand(time(0));
const int N = 100000;
int* arr1 = (int*)malloc(sizeof(int) * N);
int* arr2 = (int*)malloc(sizeof(int) * N);
int* arr3 = (int*)malloc(sizeof(int) * N);
int* arr4 = (int*)malloc(sizeof(int) * N);
int* arr5 = (int*)malloc(sizeof(int) * N);
int* arr6 = (int*)malloc(sizeof(int) * N);
int* arr7 = (int*)malloc(sizeof(int) * N);
int* arr8 = (int*)malloc(sizeof(int) * N);
int* arr9 = (int*)malloc(sizeof(int) * N);
int* arr10 = (int*)malloc(sizeof(int) * N);
int* arr11 = (int*)malloc(sizeof(int) * N);
int* arr12 = (int*)malloc(sizeof(int) * N);
if (arr1 == NULL) { perror("malloc failed"); return; }
if (arr2 == NULL) { perror("malloc failed"); return; }
if (arr3 == NULL) { perror("malloc failed"); return; }
if (arr4 == NULL) { perror("malloc failed"); return; }
if (arr5 == NULL) { perror("malloc failed"); return; }
if (arr6 == NULL) { perror("malloc failed"); return; }
if (arr7 == NULL) { perror("malloc failed"); return; }
if (arr8 == NULL) { perror("malloc failed"); return; }
if (arr9 == NULL) { perror("malloc failed"); return; }
if (arr10 == NULL) { perror("malloc failed"); return; }
if (arr11 == NULL) { perror("malloc failed"); return; }
if (arr12 == NULL) { perror("malloc failed"); return; }
for (int i = 0; i < N; ++i)
{
arr1[i] = rand();
arr2[i] = arr1[i];
arr3[i] = arr1[i];
arr4[i] = arr1[i];
arr5[i] = arr1[i];
arr6[i] = arr1[i];
arr7[i] = arr1[i];
arr8[i] = arr1[i];
arr9[i] = arr1[i];
arr10[i] = arr1[i];
arr11[i] = arr1[i];
arr12[i] = arr1[i];
}
int begin1 = clock();
InsertSort(arr1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(arr2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(arr3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(arr4, N);
int end4 = clock();
int begin5 = clock();
BubbleSort(arr5, N);
int end5 = clock();
int begin6 = clock();
QuickSort(arr6, 0, N - 1);
int end6 = clock();
int begin7 = clock();
QuickSortThree(arr7, 0, N - 1);
int end7 = clock();
int begin8 = clock();
QuickSortNonR(arr8, 0, N - 1);
int end8 = clock();
int begin9 = clock();
introsort(arr9, N);
int end9 = clock();
int begin10 = clock();
MergeSort(arr10, N);
int end10 = clock();
int begin11 = clock();
MergeSortNonR(arr11, N);
int end11 = clock();
int begin12 = clock();
CountSort(arr12, N);
int end12 = clock();
printf("直接插入排序:%d\n", end1 - begin1);
printf("希尔排序:%d\n", end2 - begin2);
printf("直接选择排序:%d\n", end3 - begin3);
printf("堆排序:%d\n", end4 - begin4);
printf("冒泡排序:%d\n", end5 - begin5);
printf("快速排序:%d\n", end6 - begin6);
printf("快速排序(三路排序):%d\n", end7 - begin7);
printf("快速排序(非递归版本):%d\n", end8 - begin8);
printf("快速排序(自省排序):%d\n", end9 - begin9);
printf("归并排序:%d\n", end10 - begin10);
printf("归并排序(非递归版本):%d\n", end11 - begin11);
printf("计数排序:%d\n", end12 - begin12);
free(arr1);
free(arr2);
free(arr3);
free(arr4);
free(arr5);
free(arr6);
free(arr7);
free(arr8);
free(arr9);
free(arr10);
free(arr11);
free(arr12);
}(二)运行结果
为了避免误差,我们将代码运行3次。
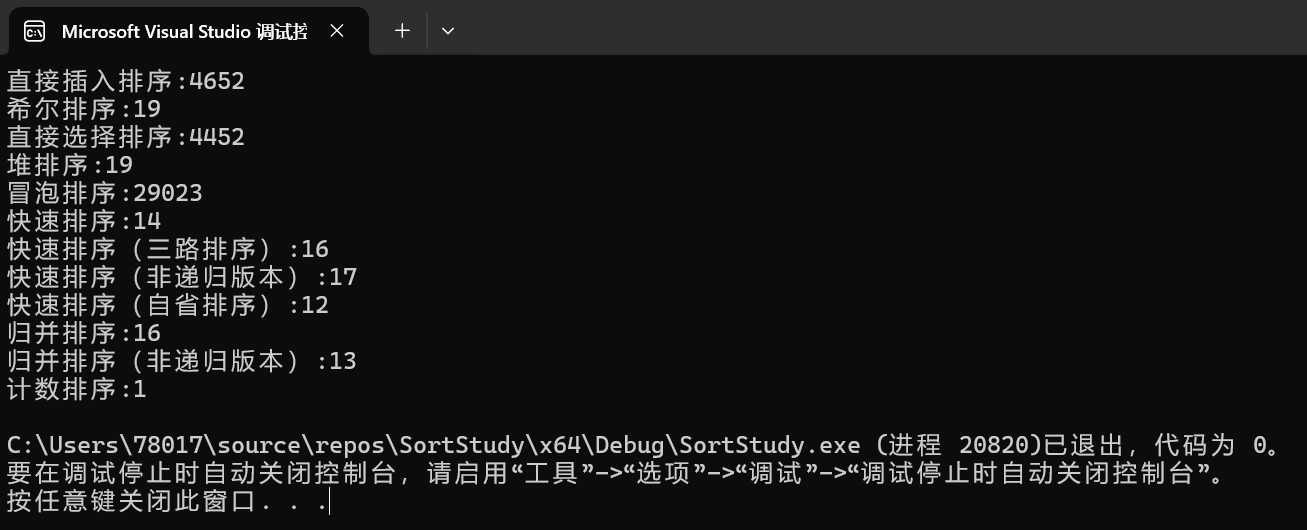
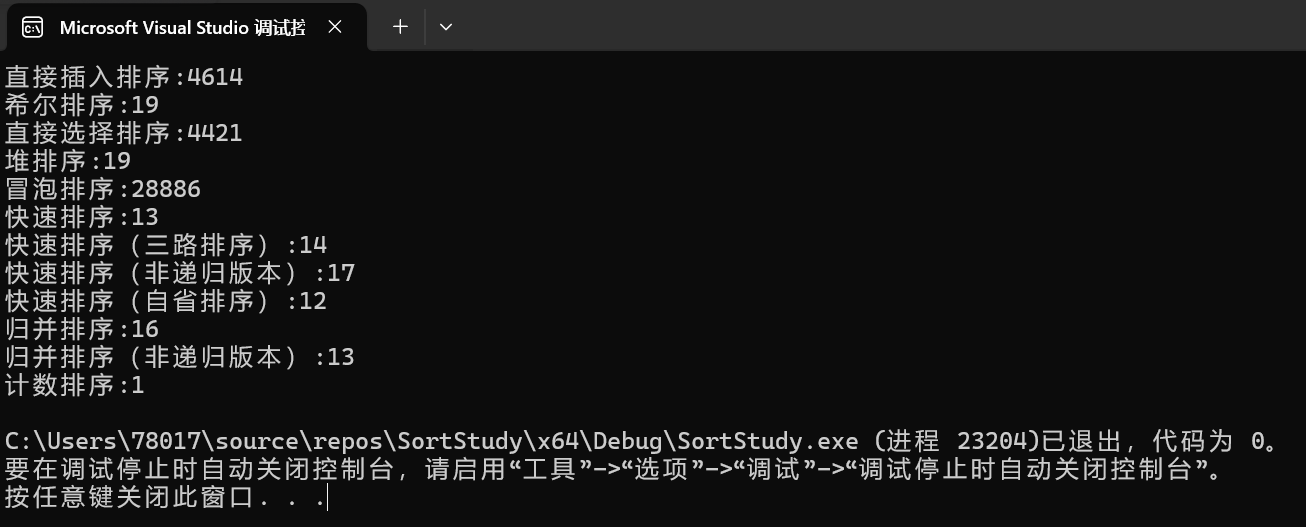
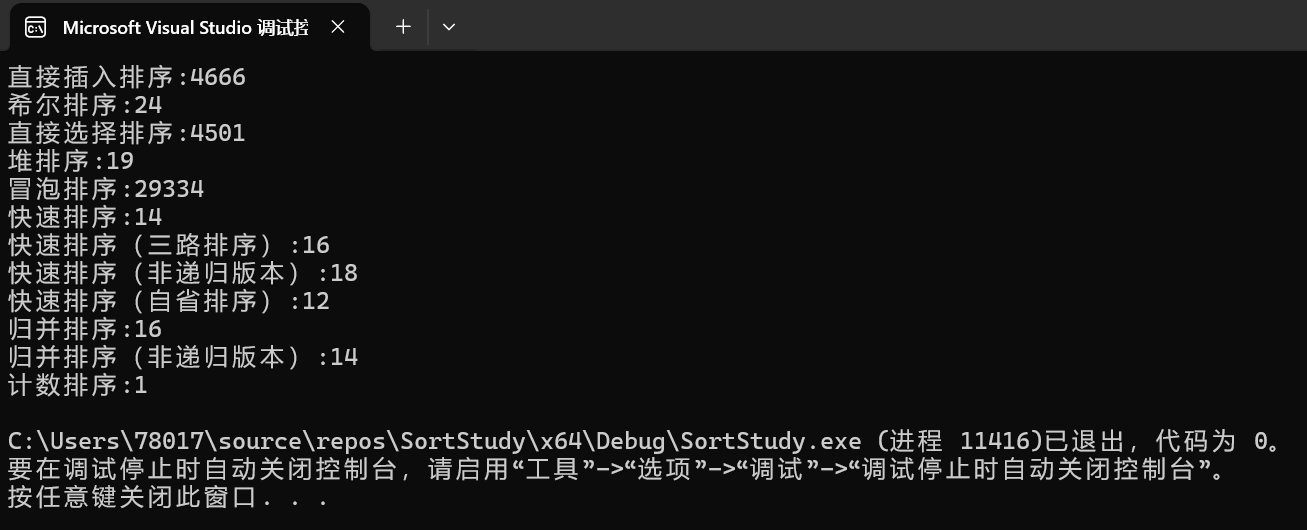
其中直接插入排序、直接选择排序、冒泡排序 是一个量级的,平均时间复杂度都是O(n²)。但是直接插入排序和冒泡排序,最好情况下可以达到O(n),
我们发现希尔排序,堆排序、快速排序、归并排序是一个量级的。希尔排序时间复杂度为O(n^1.3),剩下三个时间复杂度为O(nlogn)。
快速排序中,分区方法的改变、基准值选值的改变,会略微影响快速排序的时间,但整体上趋于相同。而且这个影响有时候是正面的,有时候是负面的,我们只要保证这个量级即可。
比如说将arr1i = rand();改为arr1i = rand()+1;,此时结果如下:
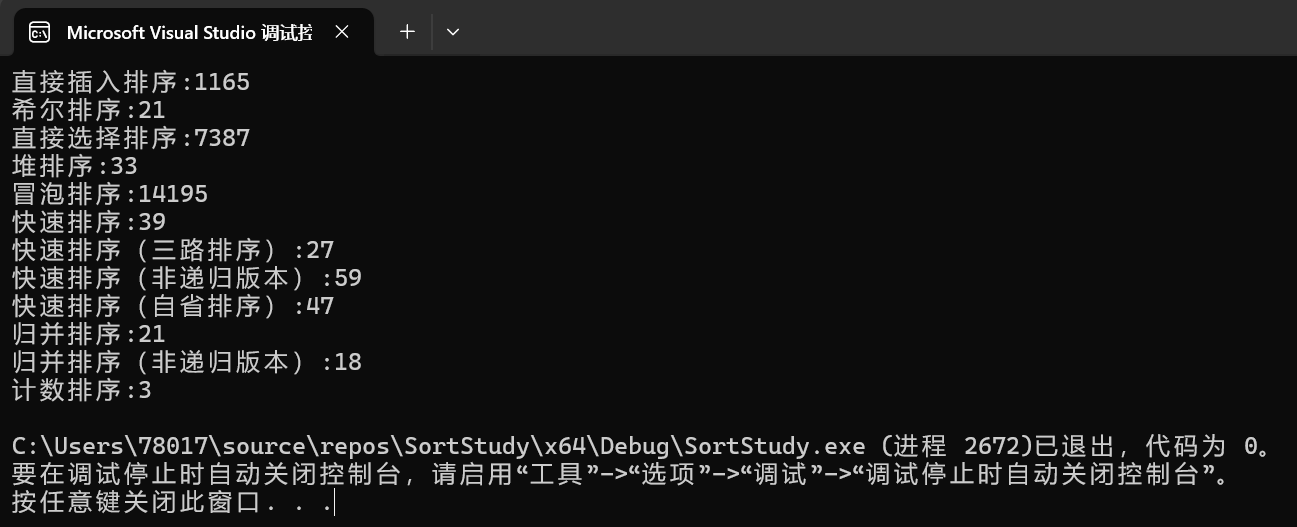
还有一个计数排序,因为时间复杂度为O(n+range),只要极大值与极小值的差值,不会远远大于数据个数,那么计数排序的时间复杂度就是最快的,就可以看成O(n)。
所以,我们只有分析数据特征,才能选择出最符合情况的排序方法。
三、排序算法性能对比与稳定性总结
(一)性能对比
|----------|--------------|--------------|--------------|---------------|
| 排序算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 |
| 直接插入排序 | O(n²) | O(n) | O(n²) | O(1) |
| 希尔排序 | O(n^1.3) | O(n) | O(n²) | O(1) |
| 直接选择排序 | O(n²) | O(n²) | O(n²) | O(1) |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) |
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) |
| 快速排序(递归) | O(nlogn) | O(nlogn) | O(n²) | O(logn)~O(n) |
| 归并排序(递归) | O(nlogn) | O(nlogn) | O(nlogn) | O(n) |
| 计数排序 | O(n + range) | O(n + range) | O(n + range) | O(range) |
(二)稳定性总结
|----------|-------------|-----------------------------------------|
| 排序算法 | 稳定性 | 关键原因 |
| 直接插入排序 | 稳定 | 相等元素插入到后面 |
| 希尔排序 | 不稳定 | 分组排序改变相对顺序 |
| 直接选择排序 | 不稳定 | 极值交换可能覆盖相等元素 |
| 堆排序 | 不稳定 | 堆顶与堆尾交换改变顺序 |
| 冒泡排序 | 稳定 | 仅交换相邻且不等的元素 |
| 快速排序 | 不稳定 | 基准值归位交换改变顺序 |
| 归并排序 | 稳定 | 合并时优先选左子序列元素 |
| 计数排序 | 取决于怎么处理相同元素 | 回填数据时,不作处理,就不能保证相同数据的位置,此时就是不稳定,处理了就是稳定 |
(三)排序算法选择建议
1、小规模数据(n ≤ 1000)
(1)基本有序:直接插入排序(O(n))。
(2)乱序:希尔排序(O(n^1.3),性能优于O(n²)算法)。
2、中等规模数据(1000 < n ≤ 10 万)
(1)优先选择快速排序(平均性能最优,O(nlogn))。
(2)需稳定排序:归并排序(O(nlogn),但需额外空间)。
3、大规模数据(n > 10 万)
(1)需省空间:堆排序(O(nlogn),O(1)空间)。
(2)数据为整数且范围集中:计数排序(O(n + range),速度最快)。
(3)通用场景:快速排序(优化后避免最坏情况)。
4、特殊需求
(1)稳定排序:归并排序、计数排序(可以是);直接插入排序、冒泡排序。
(2)无额外空间:希尔排序、堆排序;直接插入 / 选择 / 冒泡排序。
**Tip:**直接选择排序和冒泡排序更多是教学意义,较为简单,可以更好入门,但是在实际案例中,不会使用这两种排序。
以上即为 排序(五)"计数排序" 与 "各排序实际用时测量" 的全部内容,创作不易,麻烦三连支持一下呗~
