部分数学理论基础
1、凸函数性质
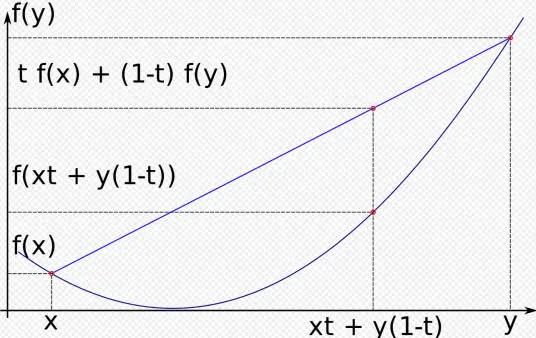
在区间x,y上的变量可以表示成xt+y(1-t),t越大越靠近x,很好理解。
那么这个图就很好理解这个不等式:
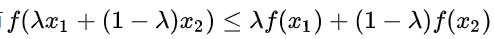
x1就是图里的x,y就是x2。这个理解不了可以直接用直线计算公式推。
2、hoeffding不等式
霍夫丁不等式 适用于有界的随机变量。设有两两独立的一系列随机变量
。假设对所有的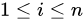
都是几乎有界的变量,即满足: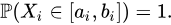
那么这n个随机变量的经验期望: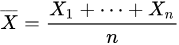
满足以下的不等式: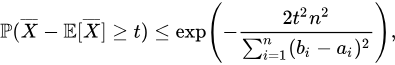
具体推到:统计学习--详解Hoeffding不等式 - 知乎
至于这个公式怎么推导,看了半天我也不会,不是高手建议大家还是不要为难自己。
3、泛化误差上界
当我们训练一个模型时,我们通常使用一个有限的训练数据集。模型在这个训练集上的表现(例如分类错误率或回归的损失)被称为训练误差或经验风险。但我们真正关心的是模型在面对从未见过的、新的数据(来自同一个数据分布)时的表现。通过理论上的概率方法,对模型在已知数据上的误差进行放缩,来表示模型在新数据上的期望误差被称为泛化误差或期望风险。有以下作用:
避免过拟合: 训练误差可能很低,但模型可能只是记住了训练数据(过拟合),导致在新数据上表现很差。泛化误差上界提醒我们,模型过于复杂(相对于数据量)可能导致泛化能力下降。
理论保证: 提供了一种理论框架,用于分析学习算法的性能,并指导模型设计(例如模型复杂度的选择)。很多论文里面都会用它来说明模型在未知数据上的理论能力期望。
样本复杂度: 揭示了需要多少训练样本才能以较高的概率保证泛化误差较小。
泛化误差计算公式:
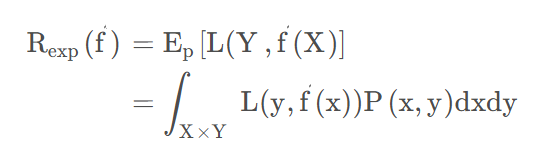
P(x,y)可以理解成取到并测试这个数据的概率,就比如说有100个数据,每个数据被取到的概率相等,那么就是1%,这样积分出来的结果很明显可以发现是在0,1之间,实际上P一般不可知。
我们期望泛化误差在未知数据上被经验误差限制在一个范围(泛化误差上界,下面不等式左边的R(f)就是上面的Rexp(f)):
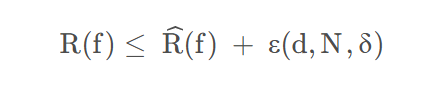
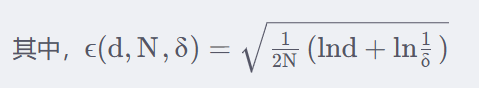 ,在该论文环境下,d可以看着不同模态的数量(也就是f的数量),N为测试样本数量。
,在该论文环境下,d可以看着不同模态的数量(也就是f的数量),N为测试样本数量。
这个放缩的量就是这个。上式成立的概率为1-
。计算上就是用的上面的霍夫丁不等式。
推导1
我们需要经验误差(已知计算出的损失)和泛化误差(在未知数据上的损失)的差尽量的小,这样也就可以确定模型在未知数据上的大致误差。下面只考虑f1分类器:
我们期望Rexp(f1)-Remp(f1)尽量的小。
也就是Rexp(f)-Remp(f)<,
尽量的接近0。
根据霍夫丁不等式,Rexp(f1)-Remp(f1)<成立的概率,即P(Rexp(f)-Remp(f)<
),应当限制在多少呢。
我们再看一眼不等式先,不会爆炸的: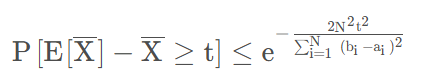
注意到:把t看成,R是限制在0-1之间的,那么b-a就是1,n个累加就是n,和上面的n方约掉一个n;再把n看作N
得到:
对条件取反,得到
考虑多个f:f1,f2...fd,各个分类器工作相互独立,P(f1f2)=P(f1)*P(f2),那么所有f同时满足条件的概率为:
右边这个有:。不理解的话可以对
=X这个整体变量求偏导看单调性,其中:变量X在0-1之间,d是正整数。
可以得到:,其中
得证。
推导2
参考:泛化误差上界-CSDN博客:3.4
由于损失函数为 0-1 损失,因此损失函数取值范围为 0,1。从而对任意
f in F,有
根据 Hoeffding 不等式可得
由于假设空间 F为有限集合,因此有
因此有
令
则
即至少以概率 有
,其中
命题得证。