目录
- 背景:流处理引擎的历史困境
- [Spark 微批次架构原理](#Spark 微批次架构原理)
- [Real-Time Mode:混合执行模型](#Real-Time Mode:混合执行模型)
- [RTM 的三大核心技术创新](#RTM 的三大核心技术创新)
- [RTM 的优缺点分析](#RTM 的优缺点分析)
- [Apache Flink 架构原理](#Apache Flink 架构原理)
- [Spark RTM vs Apache Flink 全面对比](#Spark RTM vs Apache Flink 全面对比)
- 如何选型
- 总结
背景:流处理引擎的历史困境
长久以来,流处理领域存在一个经典的"鱼和熊掌"难题:
- 高吞吐 还是 低延迟?
- Apache Spark (微批次) 还是 Apache Flink(真流处理)?
工程团队不得不为同一条数据管道维护两套完全不同的引擎------用 Spark 跑批量 ETL,用 Flink 做毫秒级响应。这不仅带来了运维复杂度,也提高了学习成本。
随着 Apache Spark 4.1 Real-Time Mode(RTM) 的发布,这一局面正在改变。
┌─────────────────────────────────────────────────────┐
│ 流处理引擎选择困境(历史) │
├─────────────────────┬───────────────────────────────┤
│ 高吞吐 ETL │ 低延迟实时处理 │
│ Apache Spark │ Apache Flink │
│ (秒级延迟) │ (毫秒级延迟) │
├─────────────────────┴───────────────────────────────┤
│ 需要维护两套系统,成本极高 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Spark 4.1 Real-Time Mode(RTM) │
│ 一套引擎,同时支持高吞吐 + 毫秒延迟 │
└─────────────────────────────────────────────────────┘Spark 微批次架构原理
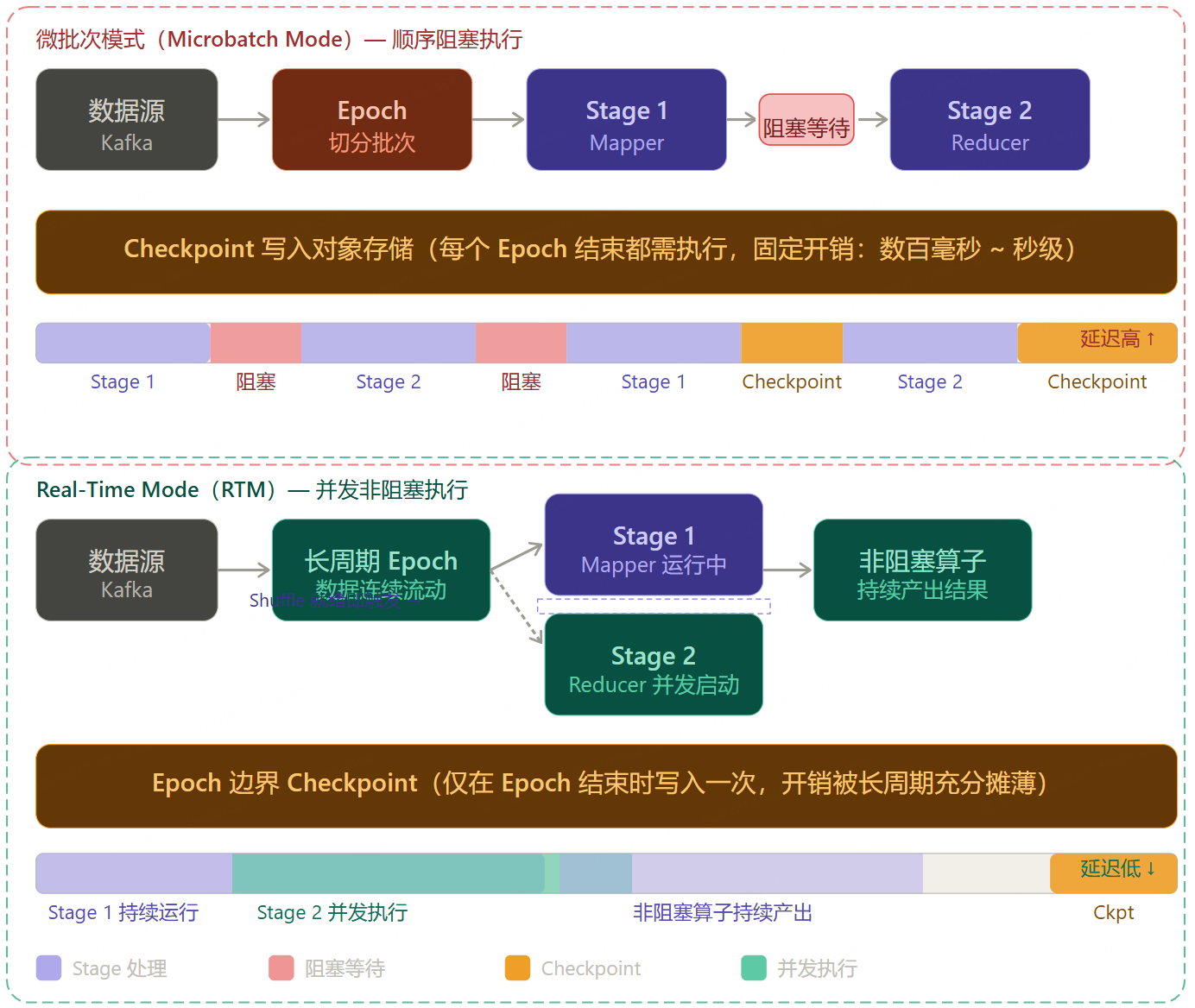
Spark Structured Streaming 的核心是微批次(Microbatch)架构。其工作机制如下:
持续输入
按时间/数据量
写 Shuffle 文件
顺序执行
数据源
Kafka/Kinesis
Epoch 切分器
Epoch 1
Epoch 2
Epoch N
Stage 1
Mapper
Stage 2
Reducer
写 Checkpoint
持久化存储
输出结果
微批次的执行流程:
- Epoch 划分:系统接收输入数据,根据数据可用性和最大批次大小配置,将数据切分为离散批次(Epoch)
- 顺序执行:Stage 1(Mapper)完全执行完毕后,Stage 2(Reducer)才能启动
- Checkpoint 写入:每个微批次执行前后,系统向持久化对象存储(如 S3)写入日志文件,并将状态上传
- 输出结果:结果以连续批次流的形式输出
微批次的核心优势:
- 多条记录批量处理,固定开销被分摊,吞吐极高
- 向量化执行(Vectorized Execution)进一步提升性能
- 基于 血统(Lineage)的容错机制,提供强精确一次(Exactly-Once)语义
微批次的致命弱点:
每个微批次都携带固定开销,当批次变小时,这些固定开销开始主导执行时间:
固定开销项(每个微批次都需要支付):
┌─────────────────────────────────────────────────┐
│ • 写 WAL 日志到对象存储(前后各一次) │
│ • 状态数据上传到对象存储 │
│ • Logical/Physical Plan 规划 │
│ • Task 序列化与调度 │
│ → 总计可能达到 数百毫秒 ~ 秒级 │
└─────────────────────────────────────────────────┘关键结论: 批次越小,固定开销占比越高,端到端延迟反而越大。这就是为什么"缩小批次"无法实现毫秒级延迟的根本原因。
Real-Time Mode:混合执行模型
RTM 的核心思想是:保留微批次架构的容错优势,同时消除导致高延迟的阻塞等待环节。
整体架构对比
🟢 Real-Time Mode (RTM)
非阻塞,数据立即流下
非阻塞算子
数据源
长周期 Epoch
数据连续流动
Stage 1 Mapper
持续产出数据
Stage 2 Reducer
并发处理,不等 Stage 1 完成
Checkpoint
在 Epoch 边界批量处理
输出
🔴 微批次模式(传统)
阻塞等待
阻塞等待
数据源
Epoch 切分
Stage 1 Mapper
等待全部完成
Stage 2 Reducer
等待全部完成
Checkpoint 写入
输出
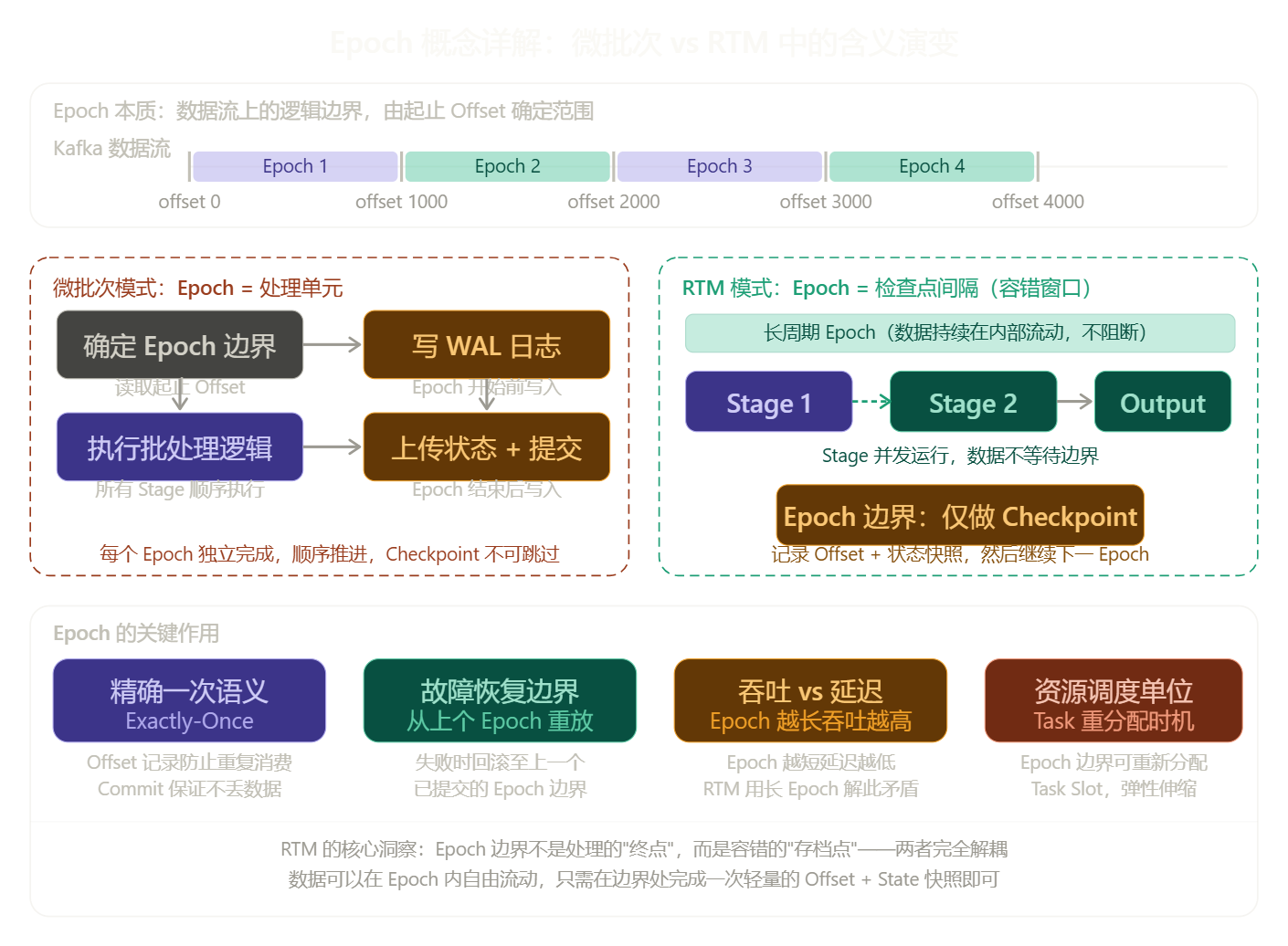
Epoch 是什么?
Epoch 本质上是 Spark Structured Streaming 对"时间片"的抽象。你可以把它理解为一段连续数据的逻辑边界。
在微批次模式下,系统会不断地问数据源:"从上次处理到现在,有多少新数据?"然后把这批数据划为一个 Epoch,完整地处理完、写完
Checkpoint,再开始下一个 Epoch。每个 Epoch 都有明确的起止 Offset(比如 Kafka 的 offset 范围),这就是它的"边界"。
在 RTM 中,Epoch 的概念被保留,但语义变了------它从"处理单元"变成了"检查点间隔"。数据在 Epoch 内部是连续流动的,不再等到 Epoch 结束才处理,只有到 Epoch 边界时才做一次 Checkpoint 登记。所以 RTM 里 Epoch 更像一个容错的时间窗口,而不是一个批次。
RTM 的三大核心技术创新
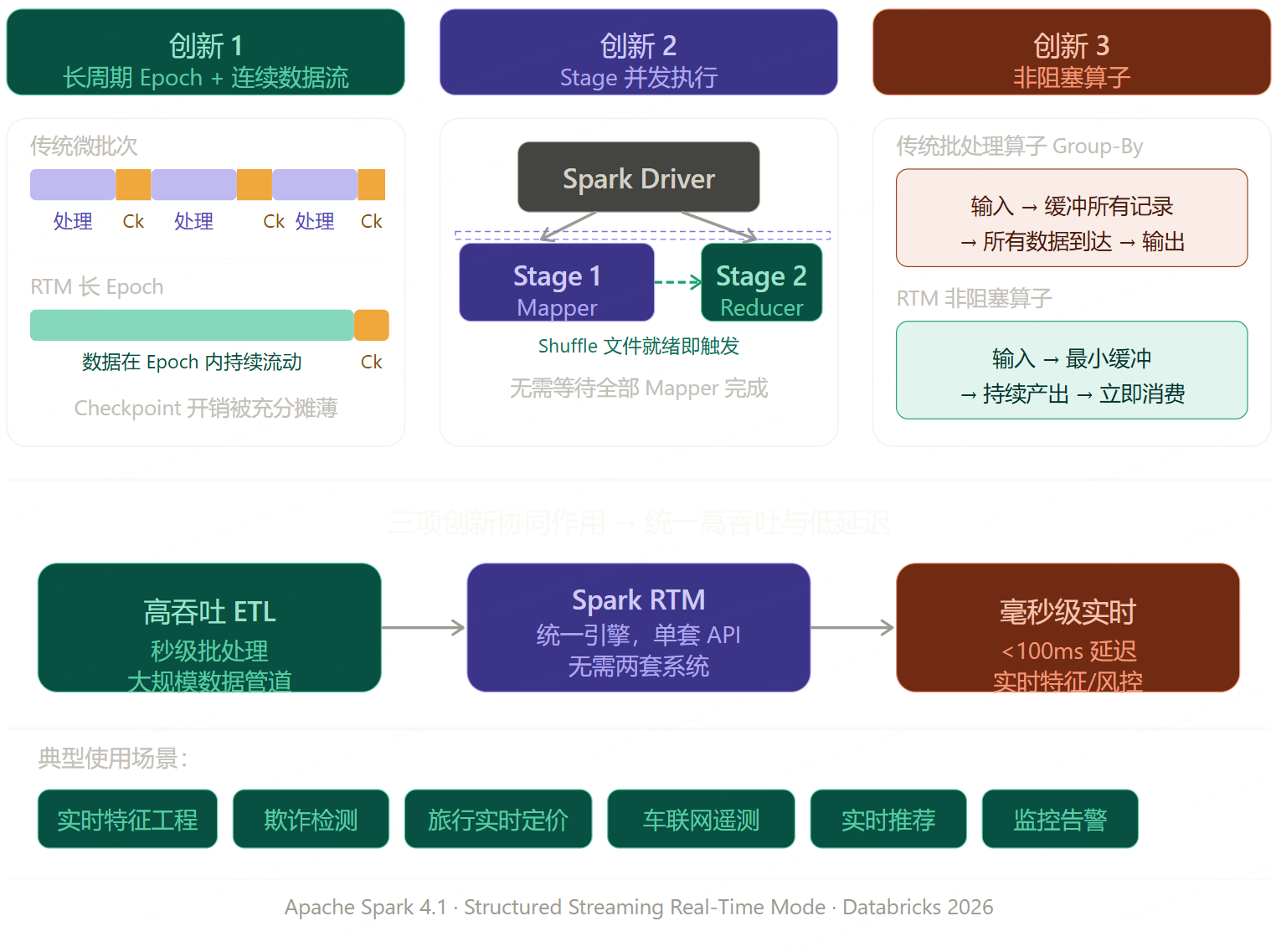
创新 1:长周期 Epoch + 连续数据流
传统微批次:
[Epoch 1: 处理→Checkpoint] [Epoch 2: 处理→Checkpoint] [Epoch 3: 处理→Checkpoint]
↑ 每个 Epoch 都有完整的 Checkpoint 开销
RTM:
[─────────────── 长周期 Epoch ──────────────── Checkpoint]
数据在 Epoch 内部连续流动,不阻塞
↑ Checkpoint 开销被长周期摊薄,Epoch 边界演变为检查点间隔原理: RTM 使用更长的 Epoch 周期,将 Checkpoint 的固定开销在时间上充分摊薄。Epoch 边界从"处理单元"演变为"检查点间隔",数据在 Epoch 内部持续流动,不再被 Checkpoint 阻断。
创新 2:Stage 并发执行
对象存储 Stage 2 (Reducer) Stage 1 (Mapper) Driver 对象存储 Stage 2 (Reducer) Stage 1 (Mapper) Driver 🔴 传统微批次模式 🟢 RTM 并发模式 调度 Mapper 任务 处理全部数据 写入所有 Shuffle 文件 等 Stage1 全部完成后才调度 处理数据 Checkpoint 调度 Mapper 任务 部分 Shuffle 文件就绪,立即触发 Reducer 持续产出,Reducer 持续消费(并发运行) Epoch 边界 Checkpoint
原理: 在传统模式下,Reducer 必须等待所有 Mapper 完成。RTM 让 Reducer 在第一批 Shuffle 文件就绪后即刻启动,两个 Stage 并发运行,大幅缩短端到端延迟。
创新 3:非阻塞算子(Non-Blocking Operators)
传统批处理 Group-By 算子:
输入流 → [缓冲所有记录] → [预聚合] → [批量输出]
↑ 必须等待所有数据到达才能输出
RTM 非阻塞算子:
输入流 → [最小化缓冲] → [持续产出中间结果] → [下游立即消费]
↑ 数据流过就处理,无需等待RTM 重构了 Shuffle、Group-By 等关键算子,将其从批处理语义改为流式语义------最小化缓冲,持续产出结果,让数据在 Pipeline 中自由流动。
RTM 的优缺点分析
✅ 优势
| 优势 | 说明 |
|---|---|
| 统一引擎 | 一套 Spark 同时处理高吞吐 ETL 和毫秒级实时场景,无需维护两套系统 |
| 学习成本低 | 开发者只需掌握 Spark API,无需额外学习 Flink 的 DataStream API |
| 强容错保证 | 继承微批次架构的血统容错机制,保持 Exactly-Once 语义 |
| 毫秒级延迟 | 部分场景实测优于 Flink,延迟可达 100ms 以下 |
| 生态成熟 | 可复用 Spark SQL、MLlib、Delta Lake 等完整生态 |
| Databricks 平台集成 | 在 Databricks 上已生产可用,支持金融、旅游等多个行业客户 |
❌ 局限与挑战
| 局限 | 说明 |
|---|---|
| Epoch 边界仍存在 | 并非真正的"无界流",Epoch 边界处仍有 Barrier 操作用于故障恢复 |
| 算子重构复杂度 | 并非所有算子都已完成非阻塞化改造,复杂拓扑支持需时间完善 |
| 依赖对象存储性能 | Checkpoint 写入对象存储(如 S3)的延迟仍是潜在瓶颈 |
| 成熟度有限 | Apache Spark 4.1 较新,RTM 在极端场景下的稳定性需更多生产验证 |
| 调优复杂 | Epoch 长度、并发度等参数调优需要深入理解底层原理 |
Apache Flink 架构原理
Flink 是原生的真流处理(True Streaming)引擎,以记录为单位处理数据。
Apache Flink 架构
逐条/小批
管道传输
管道传输
状态读写
周期性注入 Barrier
数据源
算子 1
Map/Filter
算子 2
KeyBy/Window
算子 3
Aggregate/Sink
输出 Sink
State Backend
RocksDB/Heap
Checkpoint
Coordinator
Flink 关键设计:
- Pipeline 执行:所有算子并行运行,数据在算子间以网络传输方式流动,无需等待上游完成
- Chandy-Lamport 算法:通过在数据流中注入 Barrier(屏障)实现分布式快照,完成 Exactly-Once Checkpoint
- State Backend:支持 RocksDB(磁盘)或 Heap(内存)存储状态,适合大规模有状态计算
- 事件时间(Event Time):原生支持乱序事件处理,Watermark 机制成熟
- 背压(Backpressure):下游处理慢时自动反压上游,系统自适应调节
Spark RTM vs Apache Flink 全面对比
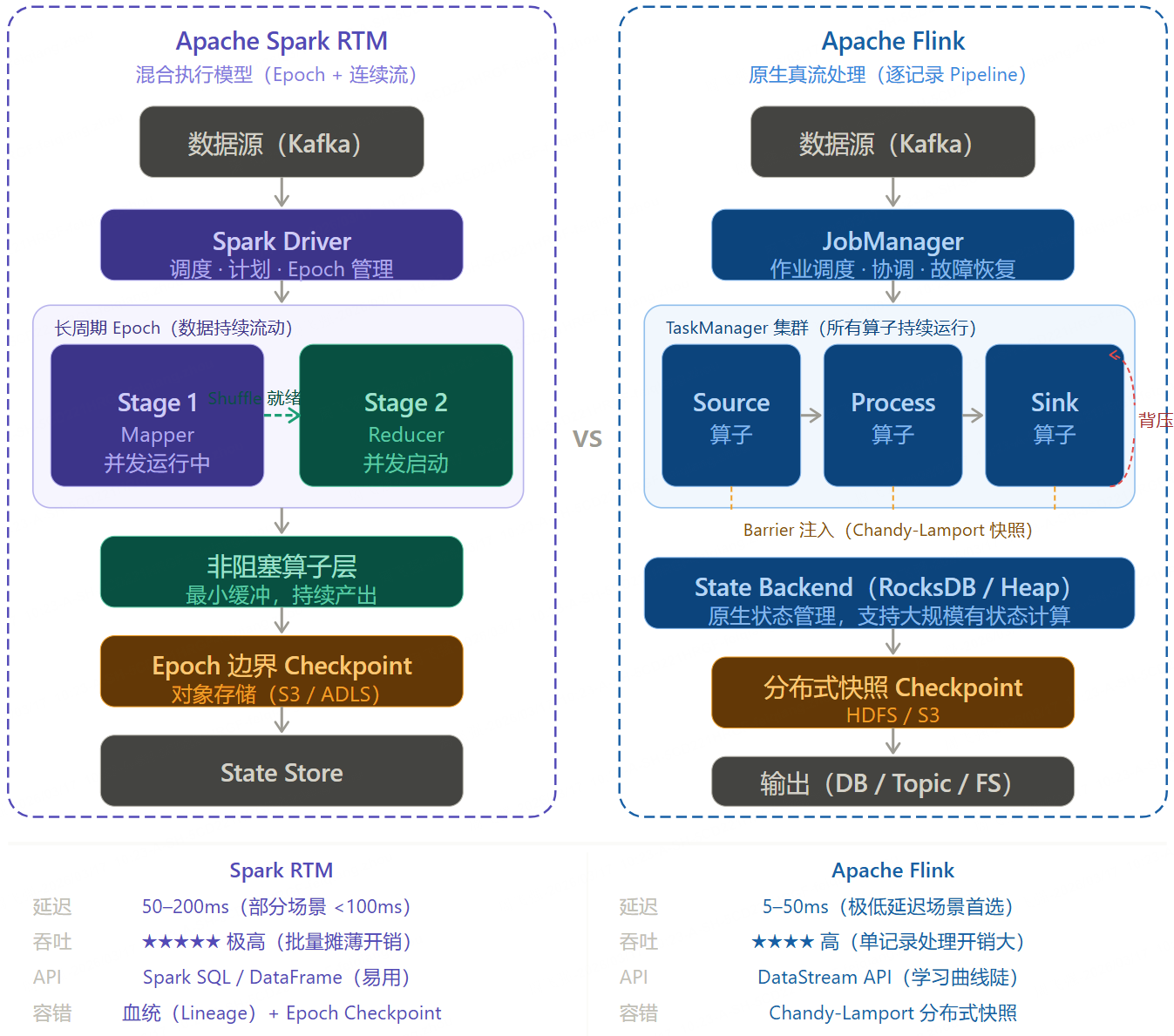
核心维度详细对比
| 对比维度 | Apache Spark RTM | Apache Flink |
|---|---|---|
| 处理模型 | 混合模型(长周期 Epoch + 连续流) | 原生真流处理(逐记录 Pipeline) |
| 延迟 | 毫秒级(部分场景 < 100ms) | 毫秒级(通常 < 10ms) |
| 吞吐 | ⭐⭐⭐⭐⭐ 极高(批量处理摊薄开销) | ⭐⭐⭐⭐ 高(但单记录处理开销更大) |
| 容错机制 | 血统(Lineage)+ Epoch Checkpoint | Chandy-Lamport 分布式快照 |
| Exactly-Once | ✅ 支持 | ✅ 支持 |
| 状态管理 | 基于 RocksDB / Delta Lake | 原生 State Backend(RocksDB/Heap),成熟度高 |
| 事件时间 & 乱序 | 支持(Watermark) | ✅ 原生支持,成熟度更高 |
| 窗口操作 | 支持常见窗口类型 | ✅ 窗口类型丰富,语义更完备 |
| API 易用性 | Spark SQL / DataFrame(SQL 友好) | DataStream API(Java/Scala,学习曲线较陡) |
| 生态系统 | ⭐⭐⭐⭐⭐ 超大(MLlib、Delta、Photon等) | ⭐⭐⭐⭐ 大(Flink SQL、Iceberg 等) |
| 批流一体 | ✅ 天然统一(同一套 API) | ✅ 支持(Flink SQL 层面统一) |
| 运维复杂度 | 低(Databricks 平台托管) | 中(需要管理 JobManager/TaskManager) |
| 成熟度 | RTM 较新(Spark 4.1,2025+) | ⭐⭐⭐⭐⭐ 生产成熟(多年大规模验证) |
| 典型延迟场景 | 实时特征工程(< 100ms) | 金融交易风控(< 10ms) |
Checkpoint 机制深度对比:Spark vs Flink
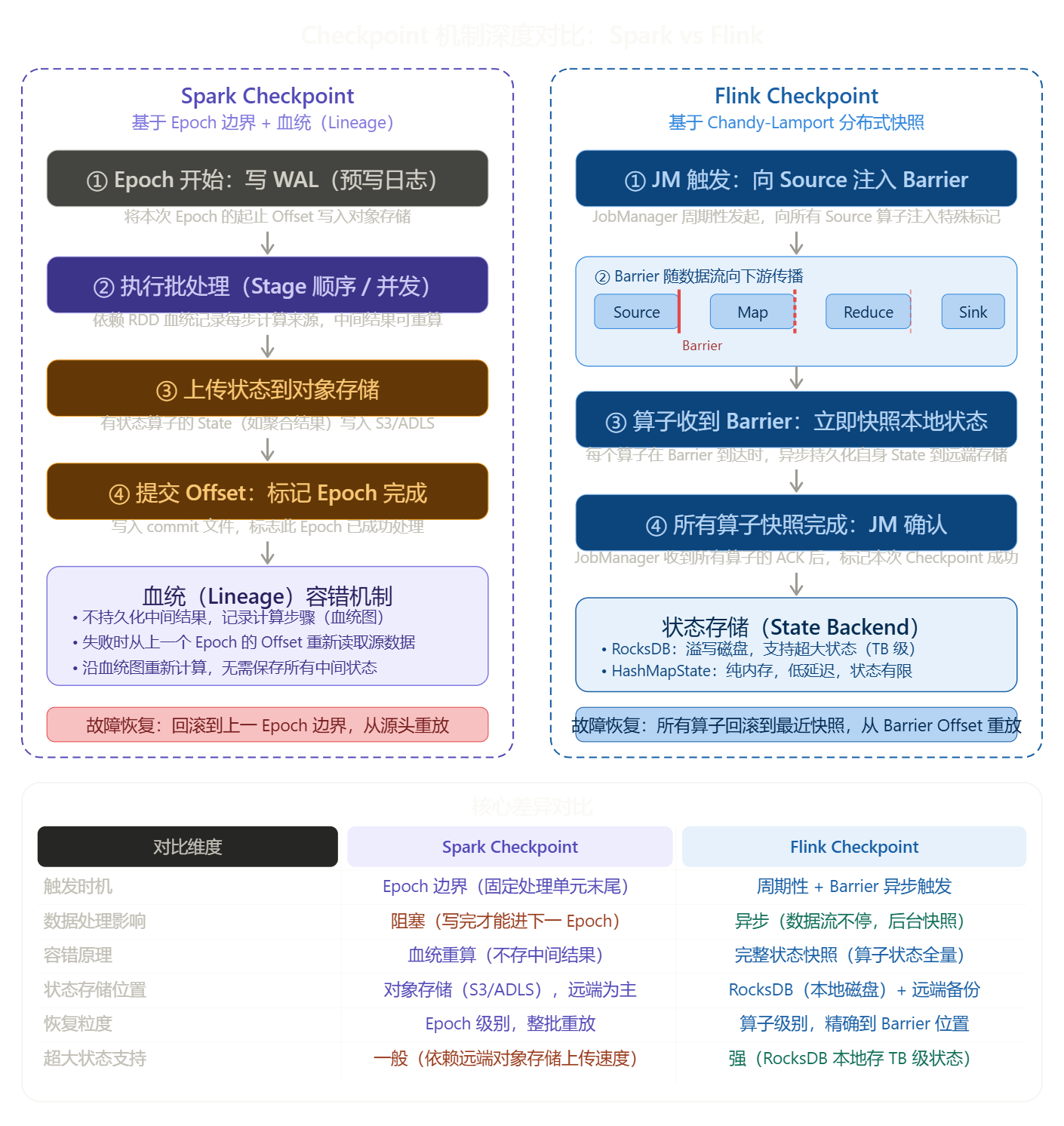
补充几个关键点:
Spark 血统(Lineage)容错的本质:
Spark 从不主动保存中间计算结果,而是记录"这个数据是怎么算出来的"这条链路。一旦某个节点挂了,只需从源头重新拉数据,按血统图重算一遍即可。这在批处理里很优雅,但在实时场景下"重算"代价就高了,所以才需要
Epoch 边界的 State 快照来缩短重放范围。
Flink Barrier 的精妙之处:Barrier 是一条插入数据流中的"隐形消息",它和真实数据一起流动。每个算子看到 Barrier
时,先把自己当前的状态快照异步存到 RocksDB,然后继续处理后续数据------这意味着 Checkpoint
和数据处理是同时进行的,互不阻塞。这也是 Flink 能做到低延迟 Checkpoint 的根本原因。
最大的设计哲学差异在于:Spark 信任"重算能力",用血统来避免存储中间态;Flink 信任"状态本身",把每个算子的精确状态都持久化下来。前者存储开销小但恢复慢,后者恢复快但状态管理复杂。RTM 的进步在于让 Spark 的 Checkpoint 从"每批必做"变成了"长窗口末尾才做",但血统+对象存储这条路子本身没变。
延迟对比示意
延迟量级对比(示意,实际取决于场景和硬件):
Apache Storm |██| 1-5ms (低吞吐,无状态)
Apache Flink |████| 5-50ms (原生流,有状态)
Spark RTM |██████| 50-200ms (混合模型,高吞吐)
Spark Microbatch |████████████████| 500ms-5s (高吞吐 ETL)
注:Databricks 报告特定特征工程场景中 RTM 优于 Flink架构设计哲学对比
Flink 的设计哲学:
"一切皆流,批处理是流处理的特殊情况"
数据源 → [op1] → [op2] → [op3] → 输出
↑ 所有算子持续运行,无 Barrier 等待
Spark RTM 的设计哲学:
"在微批次的框架内模拟流处理行为"
数据源 → [长 Epoch 开始]
→ Stage1 运行中...
→ Stage2 并发启动...
→ [Epoch 边界: Checkpoint]
→ 下一个 Epoch如何选型
< 10ms 极低延迟
100ms 级别可接受
秒级即可
已有 Spark 团队
Flink 团队成熟
是
否
批流一体需求强
生态依赖 Spark
纯实时,需要丰富窗口语义
开始选型
延迟要求
选 Apache Flink
原生真流,延迟最优
技术栈现状
选 Spark Microbatch
高吞吐 ETL 首选
是否在 Databricks
继续用 Flink
选 Spark RTM
低成本迁移,统一引擎
业务场景
Spark RTM
自建集群
Apache Flink
选 Spark RTM 的场景
- 团队已深度使用 Spark,不希望引入新引擎
- 在 Databricks 平台上运营,可无缝开启 RTM
- 需要批流一体,同一套代码处理历史数据和实时数据
- 实时特征工程、风控评分等对延迟要求在 100ms 量级
- 需要复用 Spark ML、Delta Lake、Photon 等生态能力
选 Apache Flink 的场景
- 对延迟有极严苛要求(< 10ms),如高频交易、实时竞价
- 需要复杂事件时间语义和丰富的窗口类型(Session Window 等)
- 团队已有成熟的 Flink 运维体系
- 需要经过多年生产验证的稳定性
总结
Spark RTM 的发布是流处理领域一个重要的里程碑。它通过三个关键技术创新------长周期 Epoch 连续流、Stage 并发执行、非阻塞算子------在微批次架构的基础上实现了毫秒级延迟,直接挑战了 Flink 在低延迟领域的传统优势。
但这并不意味着 Flink 已经"过时"。在极低延迟(< 10ms)、复杂事件时间语义、成熟生产环境等场景下,Flink 依然是更可靠的选择。
流处理领域正在进入一个新阶段:统一引擎逐渐成为可能。对于新项目,如果你的团队已在 Spark 生态中深耕,RTM 提供了一条代价最小、收益最大的实时化路径。
参考资料
- Breaking the Microbatch Barrier: The Architecture of Apache Spark Real-Time Mode
- Real-Time Mode Technical Guide - Databricks Docs
- Apache Flink Official Documentation: https://flink.apache.org/