
本章内容聚焦大模型时代人形机器人的感知体系升级,系统介绍了视觉---语言模型、多模态Transformer与3D大模型在机器人中的核心作用,详细讲解了文本、视觉、点云与语音等信息的语义对齐与融合机制,介绍了从语言指令到视觉目标的Grounding、任务分解与意图理解方法,并通过闭环感知与决策联动,展示了大模型支撑机器人在复杂真实场景中的理解、规划与实时行动的用法。
10.1 视觉-语言模型在机器人中的应用
视觉---语言模型(Vision-Language Model,VLM)通过统一建模视觉与自然语言,使机器人具备"看懂并理解语言"的能力,是大模型时代机器人感知与认知融合的核心技术。VLM不仅能够完成图像识别、目标检测等传统感知任务,还可以直接理解语言指令、进行语义推理,并将高层语义映射为可执行的感知与行动目标,在人形机器人中广泛应用于交互理解、场景认知和任务执行等环节。
10.1.1 CLIP/BLIP/Flamingo等模型简介
随着大规模多模态数据与Transformer架构的发展,视觉---语言模型逐渐从"跨模态对齐"演进为"多模态理解与推理"。CLIP、BLIP与Flamingo分别代表了这一演进路径中的三个关键阶段,在机器人感知系统中承担着不同层级的功能。
- CLIP:基于对比学习的视觉---语言对齐模型
CLIP(Contrastive Language--Image Pretraining)通过对数亿级图文对进行对比学习训练,其核心目标是学习一个共享的语义嵌入空间。模型采用双塔结构:图像编码器(ResNet或ViT)与文本编码器(Transformer)相互独立,仅在嵌入空间进行相似度计算。这种设计使 CLIP 在推理阶段计算高效、泛化能力强。
在机器人应用中,CLIP 的最大价值在于零样本与开放世界感知。机器人可以直接使用自然语言描述(如"蓝色塑料瓶""靠近桌子的工具")作为查询,实现目标定位与语义筛选,而无需针对每个新物体重新训练分类器。这一能力显著降低了机器人部署和维护成本,使其更适合真实、动态的环境。
- BLIP:统一视觉理解与语言生成的多任务模型
BLIP(Bootstrapping Language-Image Pretraining)在CLIP的对齐思想之上,引入了更完整的"理解---生成"闭环。其架构通常包含图像编码器、文本编码器与文本解码器,并通过多任务训练同时优化图文匹配、图像描述生成和视觉问答等任务。
在机器人系统中,BLIP更强调语义表达与解释能力。例如,机器人不仅能识别"桌子上有一个杯子",还可以生成结构化或自然语言描述,向人类解释当前环境状态,或为上层任务规划提供可读的语义信息。这使 BLIP 特别适合人机协作、服务机器人和需要可解释感知结果的场景。
- Flamingo:面向推理与长期上下文的多模态大模型
Flamingo 代表了多模态模型向"大模型化"和"推理化"发展的方向。它将冻结的大语言模型作为核心,通过跨模态注意力模块接入视觉特征,实现视觉信息对语言推理过程的动态调制。Flamingo支持多图输入、长序列上下文和多轮对话,使模型能够在时间维度上整合感知信息。
在机器人领域,Flamingo更适合用于高层认知与任务推理,例如结合历史观察、当前视觉输入和语言指令,推断下一步行动策略。这类模型往往与规划模块、记忆模块协同工作,承担"认知中枢"的角色,而非仅仅作为感知前端。
- 模型差异与机器人系统中的分工
从系统视角看,CLIP 更偏向底层语义感知与快速匹配,BLIP 承担语义理解与表达功能,而Flamingo则位于高层认知与推理层。它们并非相互替代,而是可以在机器人系统中形成分层协同结构,共同支撑从感知到决策的完整链路。
总之,CLIP、BLIP与Flamingo展示了视觉---语言模型从语义对齐、语义理解到多模态推理的演进路径。在大模型时代,这些模型为人形机器人提供了开放世界感知、语言驱动理解和高层认知能力,成为构建通用智能机器人感知体系的重要基础。
10.1.2 文本与视觉的语义对齐机制
文本与视觉的语义对齐,是视觉---语言模型能够"看懂语言、理解画面"的核心基础。其本质目标是将来自不同模态的异构信息------自然语言符号与高维视觉特征------映射到一个统一、可比较、可推理的语义空间中,使模型能够建立"词---物""句---场景"之间的稳定对应关系。在机器人系统中,这种能力直接决定了机器人能否根据语言指令准确理解环境、定位目标并执行任务。
- 统一语义嵌入空间的构建
主流VLM通常通过独立的视觉编码器与文本编码器,将图像与文本分别映射为向量表示,并在高维嵌入空间中进行对齐。通过大规模图文对数据训练,模型学习到不同模态在语义层面的一致性,例如"cup""红色杯子"和对应的图像区域在向量空间中具有高度相似性。
在数学上,该过程可表示为两个映射函数:
v = f img*(I),* t = f text*(T)* 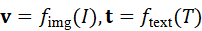
其中,I 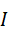 表示图像输入,T
表示图像输入,T 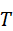 表示文本输入,v , t ∈ Rd
表示文本输入,v , t ∈ Rd 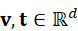 为映射到统一语义空间中的嵌入向量。通常对向量进行归一化处理,使其仅反映语义方向信息:
为映射到统一语义空间中的嵌入向量。通常对向量进行归一化处理,使其仅反映语义方向信息:
v = v ∥v ∥, t = t ∥t ∥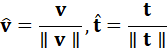
这种统一嵌入空间为跨模态检索、匹配和推理提供了基础,使机器人能够用语言直接查询视觉世界。
- 对比学习驱动的跨模态对齐
对比学习是实现语义对齐的关键手段之一。模型通过最大化匹配图文对的相似度、最小化不匹配对的相似度,迫使视觉与文本表示在语义上靠近或分离。这种训练方式不依赖精细标注,而是利用大规模弱标注数据,具备良好的扩展性。
在实现上,常用的对比学习目标函数可形式化为:
L=- log exp ( v i ⊤t i /τ ) j=1 N exp ( v i ⊤t j /τ) 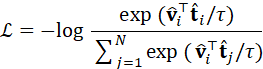
其中,τ 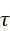 为温度系数,用于调节相似度分布的平滑程度。该损失函数促使正确图文对在嵌入空间中靠近,而错误配对被拉远。
为温度系数,用于调节相似度分布的平滑程度。该损失函数促使正确图文对在嵌入空间中靠近,而错误配对被拉远。
在机器人应用中,这种机制赋予系统开放词汇能力,使其能够理解未见过的新物体、新概念和组合描述。
- 跨模态注意力与细粒度对齐
仅有全局语义对齐往往不足以支持复杂任务。为此,许多模型引入跨模态注意力机制,将文本中的词或短语与图像中的局部区域进行关联。
设图像被划分为若干视觉token:
V ={ v 1 , v 2 ,..., v M} 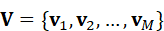
文本被表示为词token序列:
T ={ t 1 , t 2 ,..., t N} 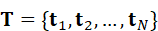
跨模态注意力可表示为:
Attention*(* T , V )= softmax Q T K V ⊤d V 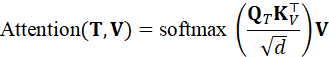
该机制使语言中的关键词(如"左侧""红色")能够关注到对应的视觉区域。这种细粒度对齐机制对于机器人执行抓取、导航和交互任务尤为重要,因为它支持精确定位和空间关系理解。
- 从语义对齐到Grounding(落地绑定)
在机器人场景中,语义对齐最终需要转化为可执行的感知结果,即将语言符号Grounding到真实世界中的具体对象、位置和状态。这一过程不仅涉及视觉特征,还结合几何信息、深度数据和时序观测,使语义理解与物理世界紧密绑定。
在形式上,Grounding 可被建模为条件概率最大化问题:
o * = arg max o∈OP(o∣T,I,S) 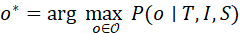
其中,O 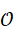 表示环境中的候选对象集合,S
表示环境中的候选对象集合,S 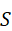 表示空间或几何状态信息。成功的语义对齐使机器人能够理解抽象指令,并将其映射为具体的感知目标。
表示空间或几何状态信息。成功的语义对齐使机器人能够理解抽象指令,并将其映射为具体的感知目标。
- 对齐机制在动态环境中的挑战
真实环境中存在光照变化、遮挡、视角变化以及语言歧义等问题,对语义对齐提出了更高要求。现代 VLM 通常结合上下文信息、历史观测和多模态融合策略,提高对齐的鲁棒性与稳定性。
在时间维度上,这一过程可表示为对历史观测的联合建模:
h t =f( v 1:t , t ) 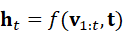
使机器人在连续感知与决策过程中保持语义一致性。这对于人形机器人在长期运行和复杂交互中的可靠性至关重要。
总而言之,文本与视觉的语义对齐机制是视觉---语言模型的核心能力,它通过统一嵌入空间、对比学习和跨模态注意力,实现语言概念与视觉实体的精准绑定。对人形机器人而言,这一机制是语言指令理解、目标定位和智能决策的关键基础,直接支撑其在开放世界中的感知与行动能力。
10.1.3 基于语言的视觉任务控制
基于语言的视觉任务控制(Vision Instruction Following,VIF)是指机器人能够根据自然语言指令,动态调度视觉感知过程,并将语言语义直接转化为感知目标、约束条件与控制意图。这一能力使机器人不再依赖固定的感知流程,而是能够在任务驱动下主动"看什么、怎么看、何时看",是大模型时代通用人形机器人感知与行动融合的关键技术。
- 从语言指令到视觉任务的语义解析
在VIF框架中,语言不再只是交互接口,而是直接参与感知控制的高层信号。机器人首先需要对输入语言指令进行语义解析,将其拆解为若干可用于视觉感知的任务要素,如目标类别、属性约束、空间关系与操作意图。
设输入语言指令为T 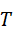 ,语言模型可将其映射为高层语义表示:
,语言模型可将其映射为高层语义表示:
z T = f LLM*(T)* 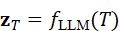
其中,z T 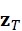 包含与任务相关的语义信息,如目标对象描述、动作类型和优先级。这一表示为后续视觉任务的生成提供了统一语义基础。
包含与任务相关的语义信息,如目标对象描述、动作类型和优先级。这一表示为后续视觉任务的生成提供了统一语义基础。
- 语言驱动的视觉目标生成
在视觉任务控制中,语言语义会进一步被转化为对视觉感知模块的显式约束,例如"查找某一类别对象""关注特定区域"或"验证某种状态"。这一过程可以形式化为从语言语义到视觉查询的映射:
q v =g( z T) 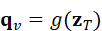
其中,q v 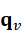 表示视觉查询向量,用于与当前视觉特征进行匹配。通过与视觉---语言模型的嵌入空间对齐,机器人可以根据语言指令,在当前视觉输入中主动筛选相关目标,而非被动处理全部视觉信息。
表示视觉查询向量,用于与当前视觉特征进行匹配。通过与视觉---语言模型的嵌入空间对齐,机器人可以根据语言指令,在当前视觉输入中主动筛选相关目标,而非被动处理全部视觉信息。
- 语言调制的视觉注意与感知策略
为了高效完成任务,VIF通常通过语言调制视觉注意机制,使感知资源集中在与任务相关的区域和特征上。设当前视觉特征为V ={ v 1 ,..., v M} 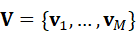 ,语言引导下的注意权重可表示为:
,语言引导下的注意权重可表示为:
α i = softmax*(* q v ⊤v i) 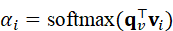
加权后的视觉表示为:
v * = i=1 M α i v i 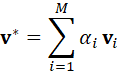
这种机制使机器人能够根据指令动态调整"看哪里"和"关注什么",例如在执行抓取任务时重点关注可操作物体,在导航任务中优先感知空间结构与障碍物。
- 视觉感知结果到行动意图的映射
VIF并不仅停留在感知层面,其最终目标是为动作决策提供直接支持。感知模块输出的结果会与语言语义联合,用于推断下一步行动意图。该过程可建模为:
a * = arg max a P(a∣ v * , z T) 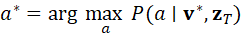
其中,a 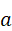 表示候选动作或子任务。通过这种方式,语言、视觉与控制形成一条连续的信息流,使机器人能够根据语言指令,在复杂环境中执行连贯且可解释的行为。
表示候选动作或子任务。通过这种方式,语言、视觉与控制形成一条连续的信息流,使机器人能够根据语言指令,在复杂环境中执行连贯且可解释的行为。
- 闭环Vision Instruction Following
在真实环境中,语言驱动的视觉任务控制通常以闭环方式运行。机器人在执行过程中不断获取新的视觉观测,并根据指令和当前状态动态调整感知与行动策略。该闭环过程可概括为:
(T, I t )→ v t * → a t → It+1 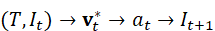
通过这一闭环,机器人能够处理指令中的不确定性,并在执行过程中进行自我修正,提高任务完成的鲁棒性与成功率。
总之,基于语言的视觉任务控制打破了传统感知与控制的静态分离模式,使语言成为驱动视觉感知和行动决策的核心因素。通过语言语义解析、视觉目标生成、注意力调制与闭环执行,Vision Instruction Following使人形机器人具备在开放环境中理解指令、主动感知并完成复杂任务的能力,是通向通用机器人智能的重要一步。