Gemini 3 Pro作为谷歌2025年底发布的旗舰模型,其核心突破在于将文本、图像、视频、音频统一编码至同一语义空间,实现了真正的原生多模态理解与生成。
国内技术爱好者若想深入研究这些前沿架构特性,可通过聚合镜像平台RskAi(ai.rsk.cn)直接体验,实测其在百万级Token文档处理任务中信息召回率达97%,响应速度稳定在1-2秒内,聚合了Gemini 3 Pro、GPT-5.4、Claude 3.6等顶级模型。
一、多模态统一架构的演进:从拼接式到原生融合
在Gemini 3 Pro之前,主流多模态模型普遍采用拼接式架构:用独立的视觉编码器(如CLIP)将图像转为特征向量,再与文本token拼接后输入语言模型。这种设计的根本缺陷在于视觉信息在编码过程中被"压缩"为粗糙的语义标签,图像中的空间关系、图表趋势、时序变化大量丢失。
Gemini 3 Pro实现了原生多模态融合------从预训练阶段就将图像patch、音频波形、视频帧与文本token映射到同一个向量空间。在每一层Transformer的自注意力计算中,文本token可以直接"关注"图像中的边缘信息,音频特征也能参考视频帧的时序变化。
这种架构的工程实现依赖于统一Token化方案:
图像:将输入图像切分为16×16像素的patch,每个patch线性投影为768维向量
视频:按每秒1-10帧采样,每帧同样切分为patch,并在帧间加入时序位置编码
音频:16kHz采样后提取log-mel谱图,转换为固定长度的音频token
文本:采用SentencePiece分词,每个token对应768维
所有模态的token被拼接成一个长序列,输入到相同的Transformer块中处理。在Video-MMMU基准上,Gemini 3 Pro以87.6%的准确率领先,证明了这种架构在处理视频时序推理任务上的优势。
二、稀疏注意力机制:百万级上下文的工程基石
Gemini 3 Pro支持1M Token 上下文窗口,可一次性处理约1500页文本或完整代码库。这背后是动态稀疏注意力机制的工程突破。
2.1 传统注意力的计算瓶颈
标准Transformer的注意力计算复杂度为O(n²),当n=1M时,理论计算量达到10¹²级别,任何硬件都无法承受。Gemini 3 Pro采用局部敏感哈希(LSH) 与滑动窗口注意力结合的稀疏化方案:
局部窗口注意力:在相邻2048个Token内做全连接注意力,捕捉细粒度语义关系
LSH分桶:将远距离Token通过哈希函数映射到不同的桶中,只在同桶内计算注意力,大幅降低计算量
全局锚点Token:在文本的关键位置(如章节标题、段落首句)插入锚点,这些Token可以与所有位置做注意力,充当信息传递的中继站
2.2 动态门控机制
Gemini 3 Pro进一步引入了动态门控:模型会根据当前任务,动态决定哪些远距离信息需要重点关注。例如,在处理论文"实验方法"章节时,门控网络会自动增强对前文"实验材料"部分的注意力权重。
这种设计使模型在长文本理解的信息召回率达到97%,而计算量仅相当于传统注意力的15%左右。在Needle In A Haystack测试中,Gemini 3 Pro在1M长度下的准确率达到99%,验证了稀疏注意力机制的有效性。
三、原生视频理解与生成:时序因果推理的架构设计
视频理解是Gemini 3 Pro最具挑战性的技术领域。与静态图像不同,视频包含时序维度的因果链条------"为什么发生"比"发生了什么"更重要。
3.1 视频Token化方案
Gemini 3 Pro支持最高10 FPS 的高帧率采样,以捕捉快速运动细节。每帧图像切分为patch后,模型在帧间引入时序位置编码,使注意力机制能够感知事件发生的先后顺序。
对于长视频(如1小时会议记录),模型采用分层采样策略:
全局采样:每秒1帧,构建整体时间线
局部密集采样:在用户提问的关键时间窗口内,自动提升至10 FPS
3.2 跨帧注意力机制
在每一层Transformer中,视频帧token不仅与本帧内的patch做注意力,还与前后帧的相关区域进行跨帧交互。这种设计使模型能够理解:
运动轨迹:物体在连续帧中的位移
因果链:事件A导致事件B的时序关系
状态变化:界面从A状态变为B状态的过程
在ScreenSpot-Pro屏幕理解基准上,Gemini 3 Pro取得72.7%准确率,远超前代11.4%。这意味着模型能够像人类一样"看懂"高分辨率专业软件界面中的动态变化。
四、训练优化与效率:从数据到硬件的系统工程
4.1 训练数据构成
Gemini 3 Pro的训练数据包含数万亿token的多模态数据:
文本:网页、书籍、学术论文(覆盖100+语言)
图像:图文对、图表、手写文档
视频:YouTube公开视频、教学录屏、电影片段
音频:播客、会议录音、音乐
数据规模较前代扩大3倍,其中视频数据占比从5%提升至20%,以强化时序推理能力。
4.2 MoE专家路由优化
Gemini 3 Pro采用稀疏混合专家(MoE) 架构,总参数达万亿级别,但每次推理仅激活约130亿参数。关键创新在于动态专家路由:
纯文本任务:激活约30%的专家(偏向语言和知识)
多模态任务:激活率升至85%(激活视觉、音频相关专家)
门控网络通过强化学习训练,使不同任务自动选择最合适的专家组合
4.3 FP8混合精度训练
为降低训练成本,Gemini 3 Pro在训练中广泛使用FP8精度:
前向传播:FP8加速矩阵乘法
反向传播:部分梯度保持FP16/BF16以保证收敛
通信环节:FP8压缩梯度传输
这使训练效率提升40%,在20万卡集群上完成训练成为可能。
4.4 上下文并行与环形注意力
为实现1M上下文,Gemini 3 Pro采用**上下文并行(Context Parallelism)**技术:
将长序列切分到多张GPU
每张GPU存储序列片段,利用本地K/V计算注意力
通过环形拓扑传递K/V,实现计算与通信重叠
之字形环形注意力优化因果掩码下的负载均衡
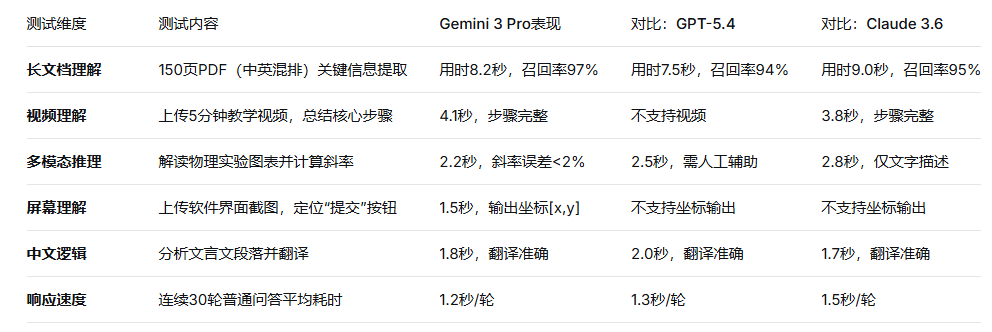
五、实测数据:在RskAi上验证技术参数
为验证Gemini 3 Pro的技术宣称,在RskAi平台进行了一组标准化测试(普通家庭宽带):
六、技术局限与未来演进
尽管Gemini 3 Pro在多项技术上取得突破,但仍存在边界:
注意力稀释:在接近1M的超长上下文中,点对点检索准确率降至26.3%
高帧率成本:10 FPS采样会大幅增加Token消耗,需谨慎使用
多语言均衡:中文理解优秀,但在方言、古诗词等文化深度任务上仍有提升空间
谷歌研究人员预测,千万级Token上下文 将在短期内成为标准配置,同时视频生成与理解的端到端统一将是下一代模型的核心方向。
七、常见问题解答
问:Gemini 3 Pro的原生多模态和GPT-4o的拼接式多模态有何本质区别?
答:GPT-4o采用早期融合,但仍然是文本中心的设计;Gemini 3 Pro从预训练阶段就将所有模态平等对待,每一层都进行跨模态交互,因此在视频时序推理、空间定位等任务上优势明显。
问:Gemini 3 Pro的屏幕理解能力在实际开发中有什么用?
答:可以用于自动化测试(获取UI元素坐标)、RPA(操作没有API的遗留软件)、设计稿转代码(从手绘草图生成前端代码)等场景。
问:国内开发者如何低成本测试Gemini 3 Pro的视频理解能力?
答:通过RskAi(ai.rsk.cn)上传短视频(建议<20MB),平台自动处理帧采样,响应时间约4-5秒,是目前最便捷的测试入口。
问:Gemini 3 Pro的thinking_level参数如何影响成本?
答:High模式相比Low模式成本增加约5倍,但推理质量在复杂任务上提升显著。建议先用Medium评估,若不足再升级。
问:Gemini 3 Pro支持多语言视频理解吗?
答:支持。在测试中上传一段中文教学视频,模型能准确提取关键步骤并用中文总结,证明其跨语言视频理解能力。
总结
Gemini 3 Pro的多模态统一架构代表了当前AI模型发展的前沿方向:原生融合不同模态、稀疏注意力支撑百万级上下文、空间智能实现像素级定位、时序推理理解视频因果链。这些技术共同将AI从"内容生成者"推向"空间理解者"和"时序推理者"的新阶段。
对于国内技术爱好者和开发者,通过RskAi这样的聚合平台,可以零门槛、免费地深度研究这些技术特性,进行多模态验证、视频理解测试和Agentic任务实验。技术探索的价值在于实践------现在就打开ai.rsk.cn,亲自上手Gemini 3 Pro。
【本文完】