2.RAG的详细流程

所以这时候,就需要RAG登场
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合外部知识库检索与大语言模型生成的技术方案,核心目标是让大模型 "基于事实作答" ,缓解原生大模型的幻觉问题,同时支持私有 / 实时知识的高效接入。
RAG 本质是
- 先从资料库里检索相关内容
- 再基于这些内容 来生成答案
- 即检索增强生成
为什么需要 RAG?
- 原生大模型知识存在时效性限制(训练数据截止前)
- 无法直接使用企业私有文档、内部知识库
- 容易编造不存在的信息(幻觉),可靠性不足
- 相比微调(Fine-tuning),RAG 成本更低、知识更新更灵活

下面介绍RAG的基本流程:
RAG 流程分为两大阶段:提问前(离线数据构建阶段) 和 提问后(在线问答阶段),整体流程如下:
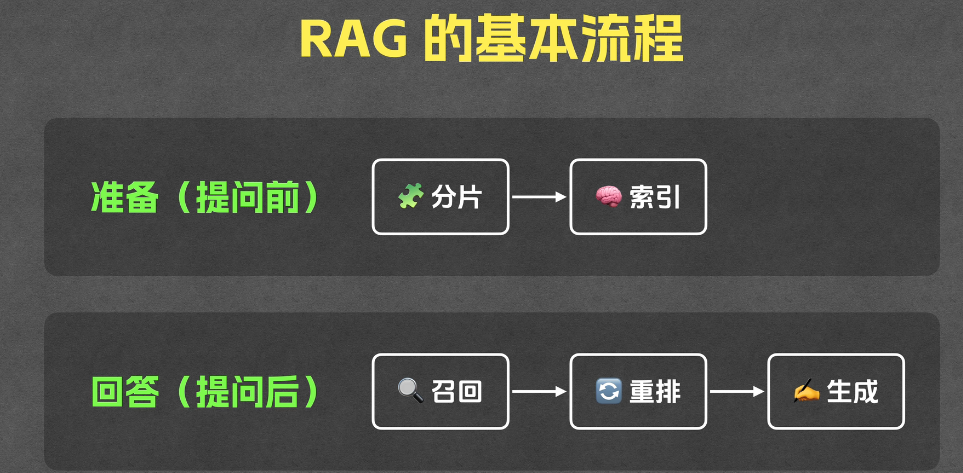
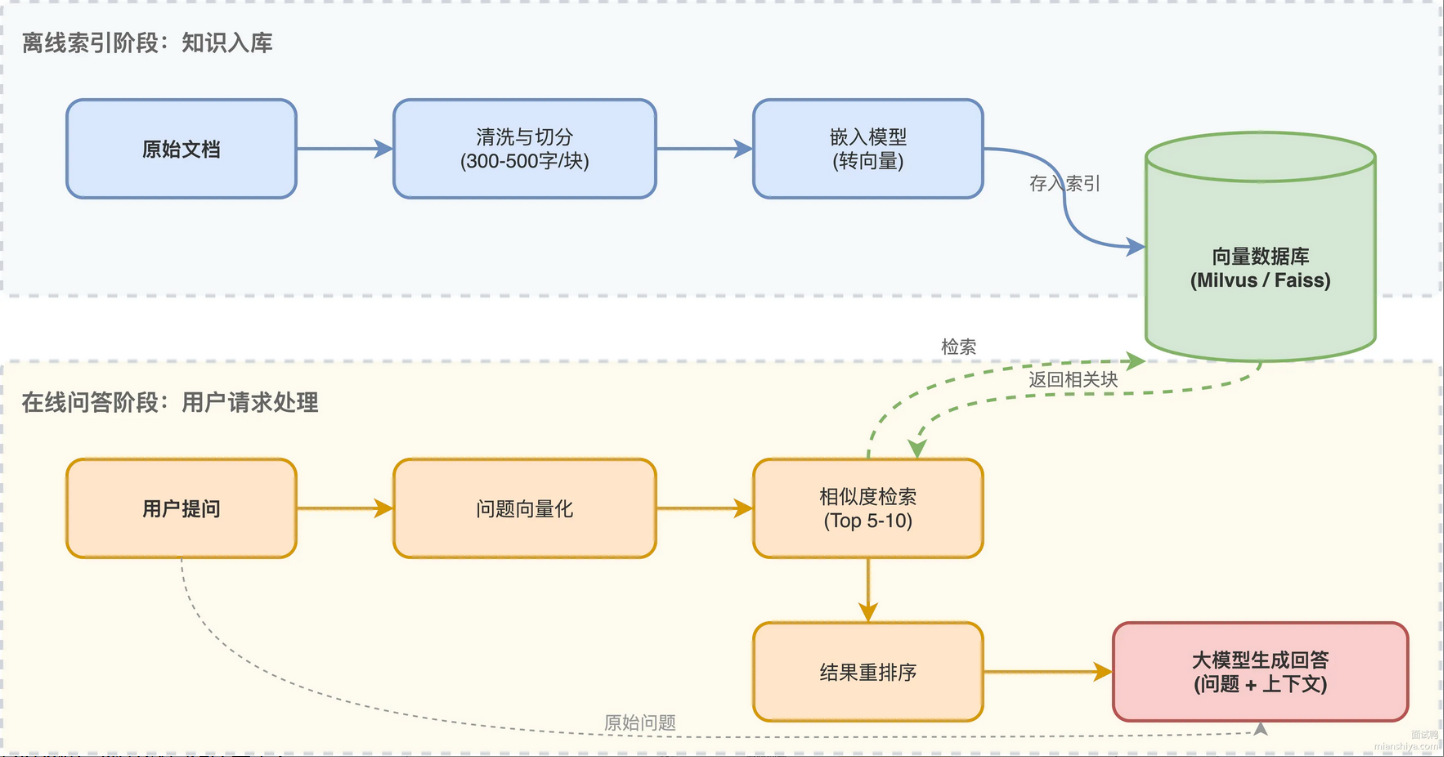
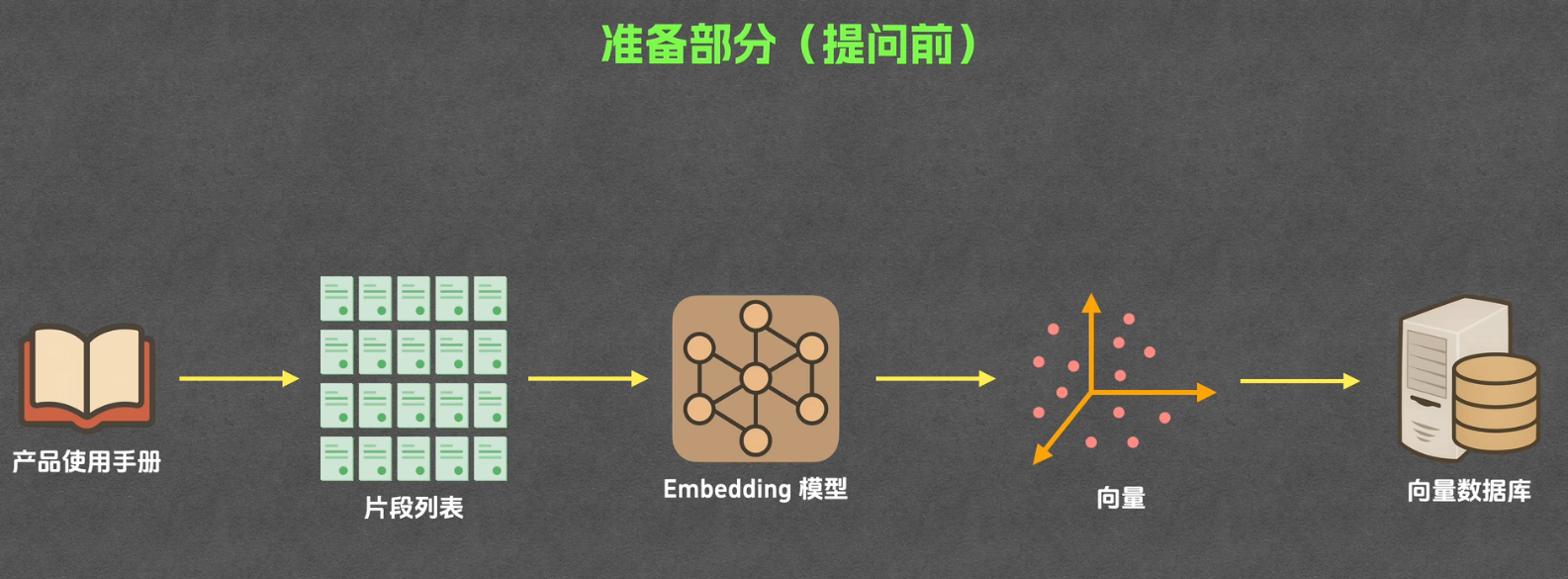
提问前:离线数据构建阶段
一步上传文件,会进行文档加载(知识入库)
-
场景:读取不同格式的私有文档(PDF/Word/Excel/Markdown/ 网页等)
-
技术实现:
-
- Java:使用 Apache POI、PDFBox、Tika 等库解析文档
- Python:使用 LangChain、LlamaIndex 提供的文档加载器
分片
核心作用:将长文档切分成合适大小的文本片段,避免超出大模型上下文窗口,同时保证语义完整性
文档分块策略
分块是RAG效果的关键,块太大检索不精准,块太小又丢失上下文。常见的三种切法:
- 1)语义切分:用SemanticSplitter这类工具,保证每个块语义完整独立,比如一个问答对不会被切成两半,如换行、标题、章节分隔符
- 2)结构切分:HTML、PDF这种有层级的文档 ,按标题层级切割,像HTMLHeaderTextSplitter 就能保留文档结构
- 3)**递归切分:**RecursiveCharacterTextSplitter 先按大的分隔符切 ,切不动了再按小的切,兼顾连贯性和长度限制,保留上下文
实际项目里,300-500字一块是比较通用的起点,具体要根据业务场景调。
当然也有人按下面这么划分:

关键参数:
- 片段长度:通常 256~512 Token(根据模型上下文调整)
- 重叠长度:设置 50~100 Token 重叠,避免语义被切断
索引
索引存储
-
核心作用 :将向量与原文本片段关联,存入向量数据库或搜索引擎,实现高效相似检索
-
常见存储方案:
-
- 向量数据库:Milvus、FAISS、Chroma、Pinecone(专门优化向量检索)
- 混合检索:Elasticsearch + 向量插件(支持全文检索 + 语义检索)
-
索引类型:
-
- 暴力检索(Flat):准确率最高,适合小规模数据
- 近似最近邻(ANN):如 HNSW、IVF,牺牲少量准确率换取百万级数据的毫秒级检索速度

向量化(Embedding)
-
核心作用 :将文本片段转换为高维向量 ,让计算机能通过 "相似度" 计算理解文本语义
-
技术实现:
-
- 开源模型:BGE、m3e、text2vec 等(适合中文场景)
- 商用服务:OpenAI Embedding、百度文心 Embedding 等
-
原理 :语义相近的文本,向量空间中的距离更近(如余弦相似度)

向量数据库

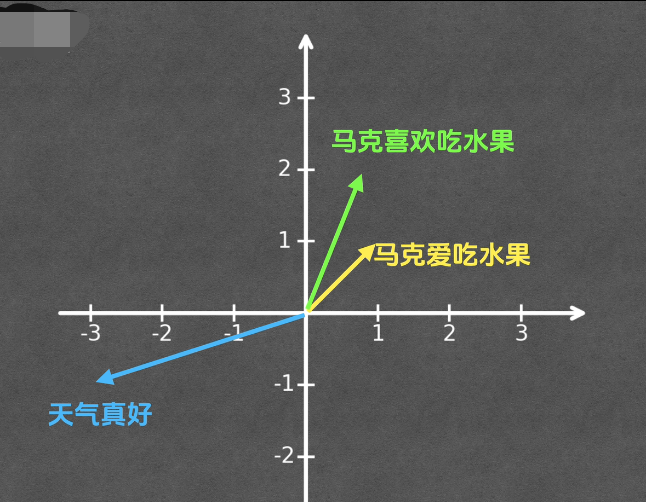
每个文本都对应有对应的向量
提取后:在线问答交互阶段
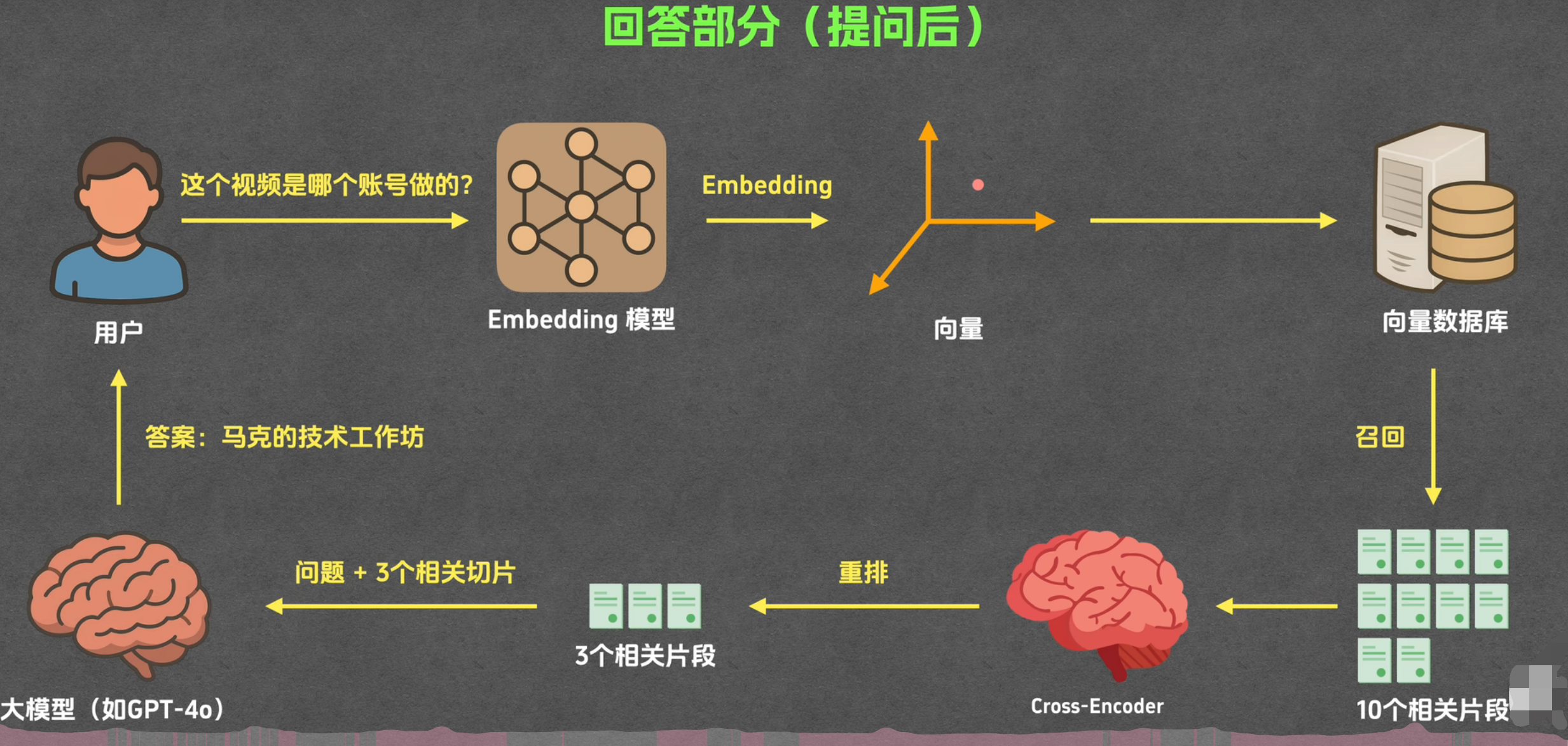
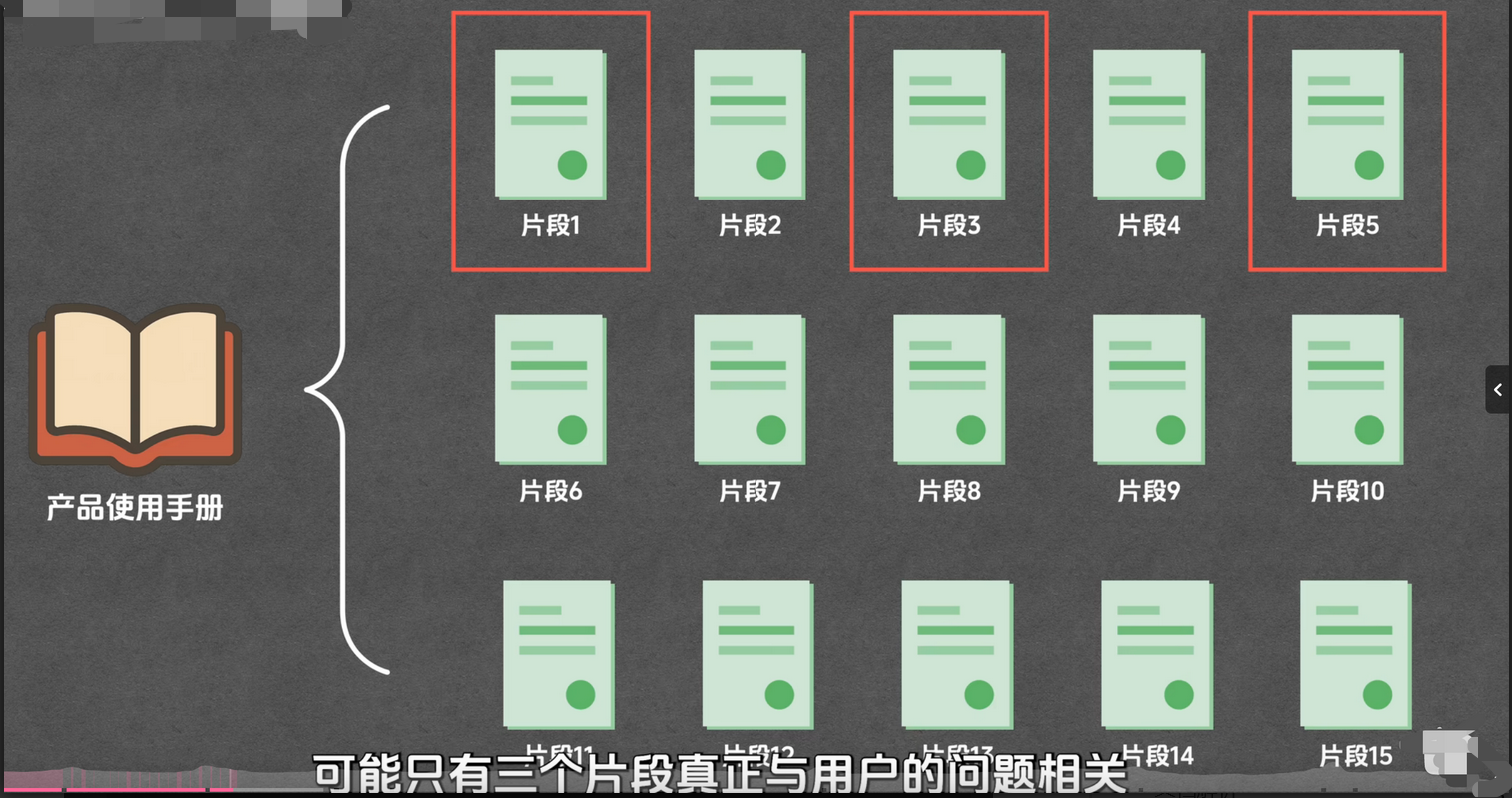
召回(Retrieval)
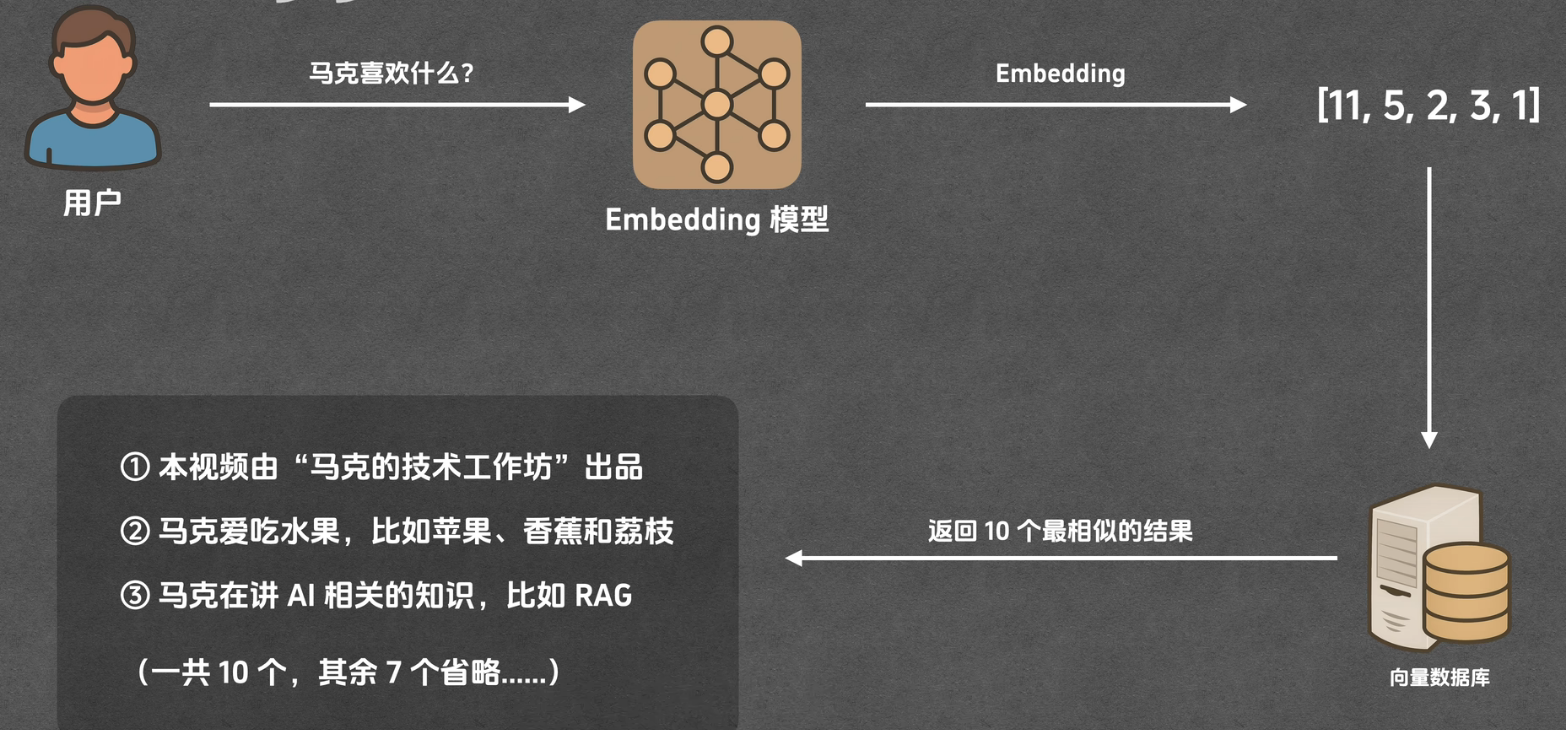
召回
-
核心作用 :从向量库中快速找出与用户问题语义最相关的 Top-K 个文本片段
-
检索方式:
-
- 语义检索:基于向量相似度(余弦相似度、内积)
- 全文检索:基于关键词匹配(如 BM25 算法)
- 混合检索:结合语义 + 全文,提升召回准确率
-
关键参数:
-
- Top-K:通常召回 5~20 个片段,后续再筛选
- 相似度阈值:过滤掉相关性过低的片段
下面是语义检索:
- 基于向量相似度(余弦相似度、内积)





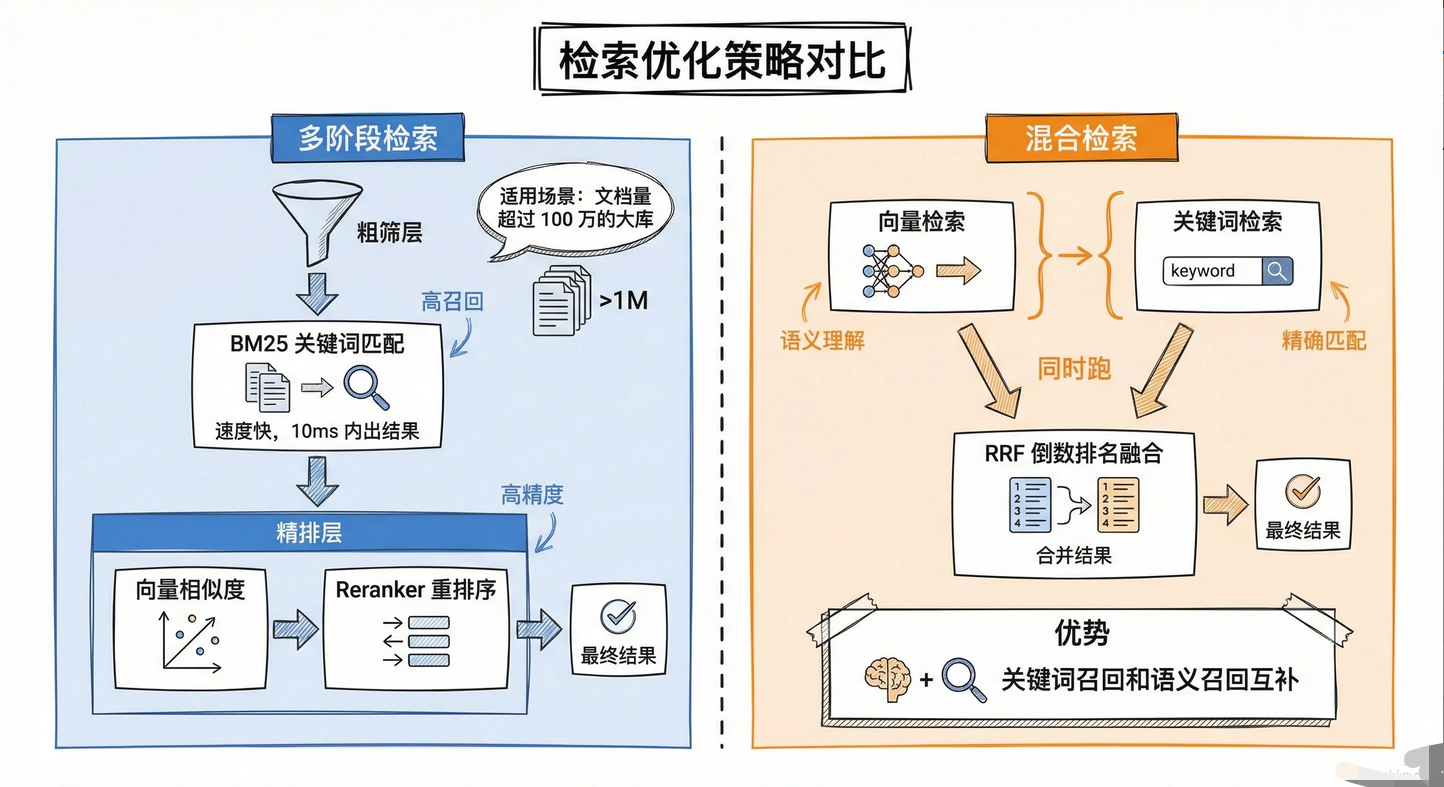
单纯靠向量检索其实不够用,生产环境通常会做多路召回,混合检索 特别适合那种用户可能用专业术语搜索的场景,纯向量检索容易漏掉精确匹配的结果。
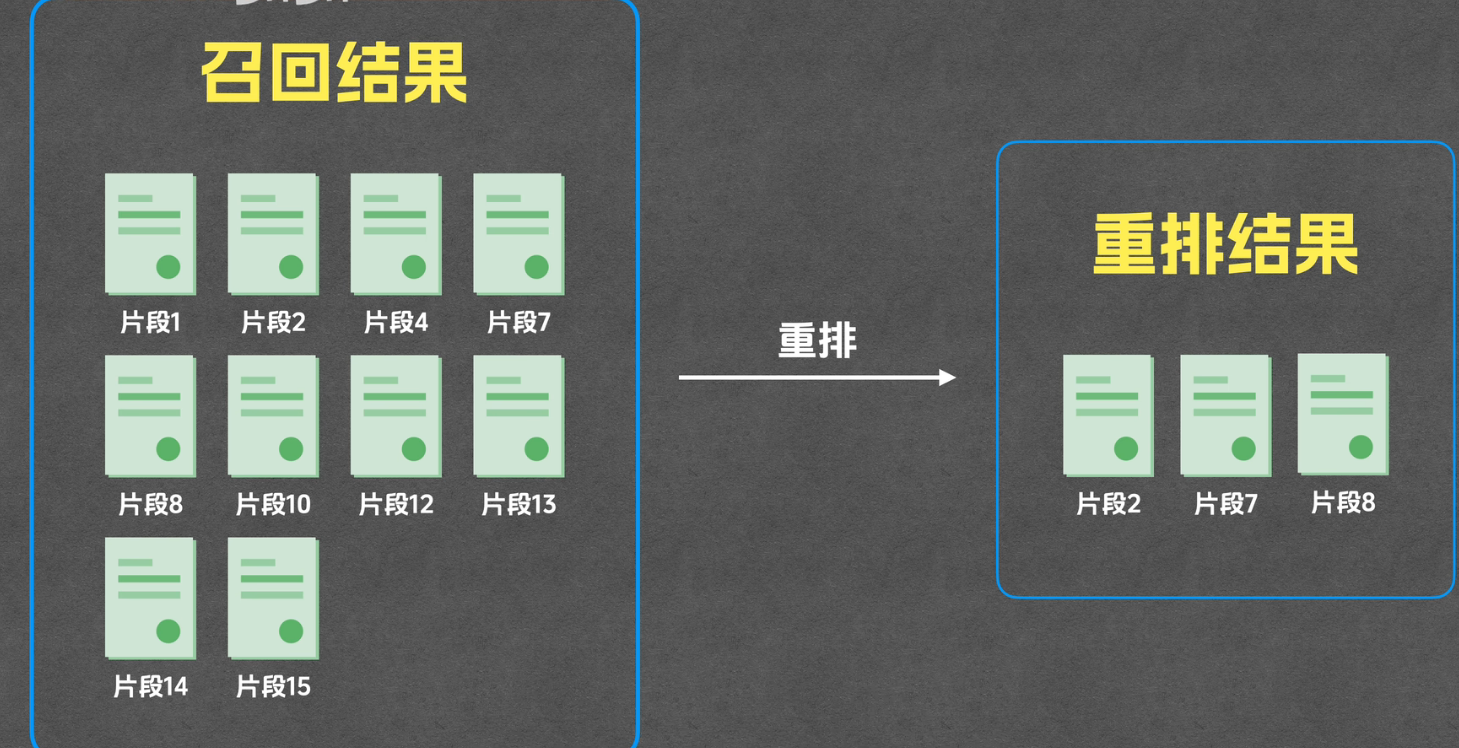
重排(Reranking)
重排即重新排序
- 核心作用 :对召回的片段进行二次排序,进一步提升相关性,筛选出最优质的片段送入大模型
- 技术实现:
- 轻量级重排模型:如 BGE Reranker、CrossEncoder(专门优化文本对相似度)
- 规则重排:结合片段长度、来源权重、时间戳等规则
- 优势:相比直接召回 Top-K,重排后能有效过滤低质量片段,提升最终回答的准确性
生成
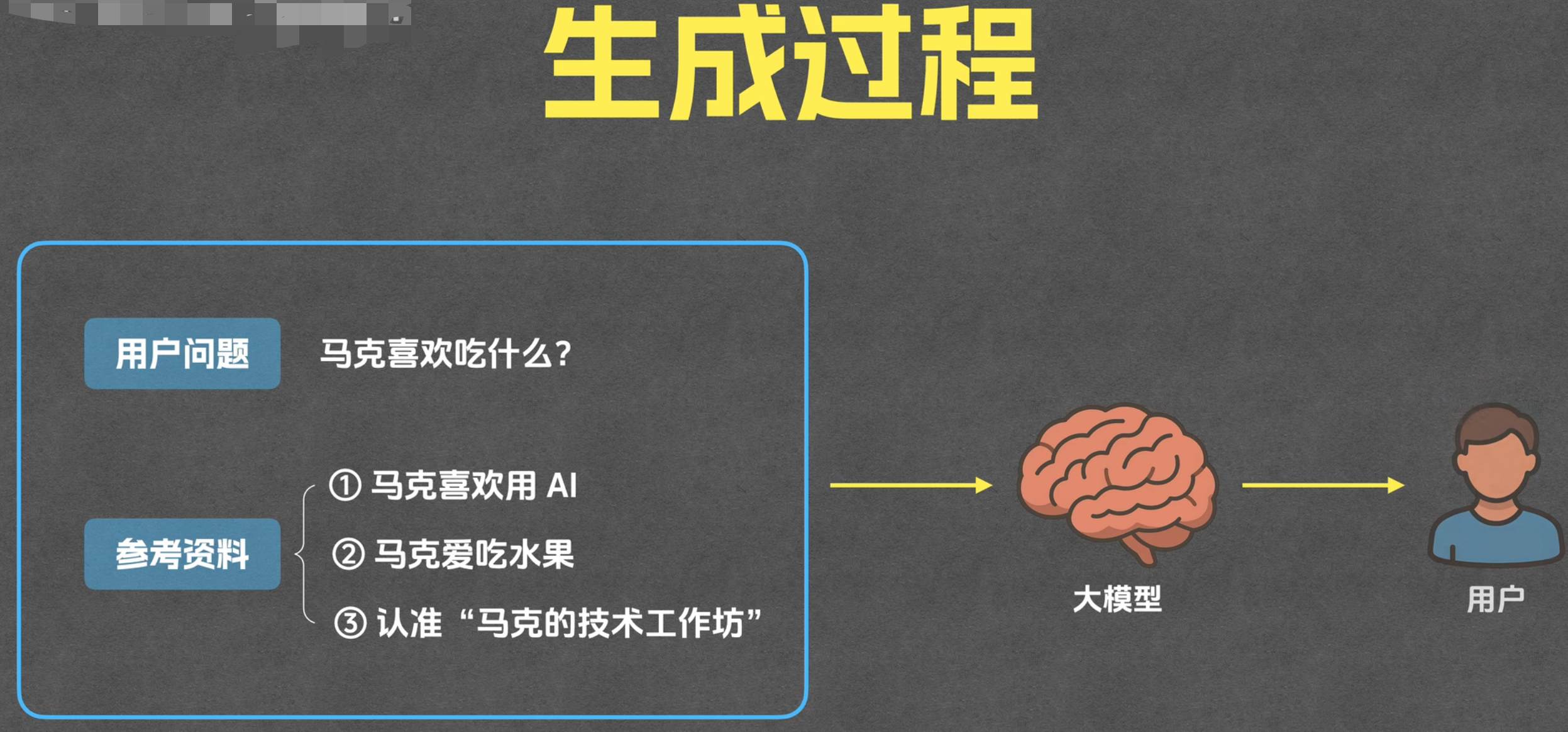
Prompt 拼接+生成
- 核心作用 :**将用户问题 + 召回的优质片段,**按固定模板拼接成 Prompt,交给大模型生成回答, 大模型基于拼接好的 Prompt,生成结构化、通顺的回答
- 示例:
注意事项:
- 控制 Prompt 总长度 ,避免超出模型上下文窗口
- 明确要求模型 "仅根据已知信息回答",减少幻觉
技术实现:
- 调用大模型 API(如 OpenAI、讯飞星火、文心一言)
- 流式生成:结合 WebSocket 实现 "打字机效果",提升用户体验
关键参数:
- temperature:控制生成随机性(0~1,越小越严谨)
- top_p: nucleus sampling,控制生成多样性
- max_tokens:限制回答长度
结果后处理:
-
场景:对大模型生成的回答进行优化、校验
-
操作:
-
- 去除冗余内容、格式美化
- 引用溯源:标注回答内容来自哪篇文档片段(提升可信度)
- 敏感内容过滤:避免输出违规 / 敏感信息
一些疑惑
核心疑惑解答
- **Q:分片大小怎么选?**A:优先保证语义完整性,一般 256~512 Token;长文档可先按章节分割,再二次分片。
- **Q:向量库怎么选?**A:小规模数据用 FAISS/Chroma 快速验证;生产环境用 Milvus/Elasticsearch,支持分布式和高并发。
- **Q:召回准确率低怎么办?**A:尝试混合检索(全文 + 语义)、优化分片策略、更换更优 Embedding / 重排模型。
- Q:为什么有召回,还需要重排?

"召回和重排是粗与精的关系。
- 召回是利用向量数据库进行近似最近邻检索 ,目的是为了快,把相关的文档先捞出来,但此时数据量大、杂质多,是**'广撒网'**。
- 重排是利用重排模型(如 Cross-Encoder) ,对召回结果进行两两语义精算 ,目的是为了准 。它能过滤掉表面相关但实质不符 的内容,挑选出最贴合用户问题的 Top-K 片段。
- 两者结合,既保证了系统的高并发检索效率,又保证了最终问答的准确性。"