论文信息
论文标题: Quantifying Document Impact in RAG-LLMs - 2026
论文作者: Armin Gerami, Kazem Faghih, Ramani Duraiswami - UMD
论文链接: https://arxiv.org/abs/2601.05260
论文关键词: RAG, Security, Explainability
研究背景
- RAG 的优势与隐患: 虽然 RAG 通过引入外部知识缓解了 LLM 的幻觉和知识过时问题 ,但也带来了事实不一致、来源冲突、偏见传播和安全漏洞(如检索毒化)等新挑战 。
- 解释性缺失: 目前缺乏有效的指标来衡量在检索到的一堆文档中,究竟是哪一个文档真正主导了 LLM 的最终输出 。
- 现有方法的局限: 传统的"提示词工程(Prompt Engineering)"要求模型自报出处,但这往往会导致模型为了符合引用格式而简化推理,且模型对提示词的遵循并不稳定 。
这里对 RAG 的基本流程做补充说明:
RAG(Retrieval-Augmented Generation)通过外部知识增强 LLM,基本流程:
bash
Query
↓
Retriever
↓
Top-k documents
↓
LLM (context + query)
↓
Generated answer本文探讨的核心问题为:
当 LLM 生成一个答案时,
每个 retrieved document 对最终结果的贡献是多少?
核心贡献:影响力评分 IS
论文基于 部分信息分解 (Partial Information Decomposition, PID) 理论 提出了一种名为 IS(Influence Score,影响力评分) 的量化指标。
PID 理论
PID 是一种理论框架,旨在分析一组输入变量(Sources)如何共同为一个输出变量(Target)提供信息 。
PID 定义了三种信息维度,用于完成该任务,下面对这三种信息维度进行介绍,并带入RAG语境(文档=输入,生成答案=输出)进行对照理解:
| 维度 | 定义 | RAG 语境下的直观理解 |
|---|---|---|
| Mutual Information 互信息 ( I ) (I) (I) | 单个来源与目标之间的关系 | 仅给 LLM 这一个文档时,它能答对多少。 |
| Union Information 并集信息 ( U ) (U) (U) | 至少一个来源提供的总信息量 | 整个文档库(作为整体)为生成答案提供了多少知识。 |
| Excluded Information 排除信息 ( E ) (E) (E) | 除了某一个特定来源外,其他来源所包含的信息总和 | 如果没有文档 A,剩下的文档能提供多少有用信息? |
定义来源变量为: X 1 , X 2 , . . . , X k X_1,X_2,...,X_k X1,X2,...,Xk,目标变量为: Y Y Y,PID 理论可以写为:
E ( X i → Y ∣ X 1 , X 2 , . . . , X k ) = U ( X 1 , X 2 , . . . , X k ; Y ) − ( X i ; Y ) , I ( X i ; Y ) = H ( Y ) − H ( Y ∣ X i ) , H ( . ) : = Shannon Entropy U ( X 1 , X 2 , . . . , X k ; Y ) = inf Q I ( Q ; Y ) such that ∀ i X i ∈ Q E\left(X_i\rightarrow Y|X_1,X_2,...,X_k\right) = U\left(X_1,X_2,...,X_k;Y\right) - \left(X_i;Y\right), \\ I\left(X_i;Y\right) = H\left(Y\right) - H\left(Y|X_i\right), H\left(.\right):=\text{Shannon Entropy} \\ U\left(X_1,X_2,...,X_k;Y\right) = \inf\limits_{Q} I(Q; Y) \text{such that} \forall i X_i \in Q E(Xi→Y∣X1,X2,...,Xk)=U(X1,X2,...,Xk;Y)−(Xi;Y),I(Xi;Y)=H(Y)−H(Y∣Xi),H(.):=Shannon EntropyU(X1,X2,...,Xk;Y)=QinfI(Q;Y)such that∀iXi∈Q
其中 E ( X i → Y ∣ X 1 , X 2 , . . . , X k ) E\left(X_i\rightarrow Y|X_1,X_2,...,X_k\right) E(Xi→Y∣X1,X2,...,Xk) 表示在整个文档库中,除去 X i X_i Xi 之后,还剩下哪些额外的信息?
接下来对论文中 PID 理论按顺序进行详细的解释。
- E ( X i → Y ∣ X 1 , X 2 , . . . , X k ) = U ( X 1 , X 2 , . . . , X k ; Y ) − ( X i ; Y ) E\left(X_i\rightarrow Y|X_1,X_2,...,X_k\right) = U\left(X_1,X_2,...,X_k;Y\right) - \left(X_i;Y\right) E(Xi→Y∣X1,X2,...,Xk)=U(X1,X2,...,Xk;Y)−(Xi;Y)
该公式用于计算 排除信息 E E E,他的直观含义是:"除了文档 X i X_i Xi 之外,剩下的那组文档还剩下多少关于答案 Y Y Y 的独特知识?" 或者更通俗点说,它衡量的是 "文档 X i X_i Xi 缺失了多少其他文档共有的知识"。
所以公式通过 并集信息 减去 互信息 得到 排除信息,即 用总的信息量 减去 文档 X i X_i Xi 的信息量 得到 排除 X i X_i Xi 的信息量。如果排除信息越小,说明该文档的占总共的信息量越大。
- I ( X i ; Y ) = H ( Y ) − H ( Y ∣ X i ) , H ( . ) : = Shannon Entropy I\left(X_i;Y\right) = H\left(Y\right) - H\left(Y|X_i\right), H\left(.\right):=\text{Shannon Entropy} I(Xi;Y)=H(Y)−H(Y∣Xi),H(.):=Shannon Entropy
H ( . ) H\left(.\right) H(.) 表示香农熵,在香农(Shannon)的定义中,熵是衡量一个随机变量"不确定性"或"信息量"的度量 。
- 高熵值 = 高度混乱/不确定: 如果 LLM 对某个问题生成了 10 个答案,且这 10 个答案的含义各不相同(甚至相互矛盾),那么熵值就会很高 。这表明模型处于"困惑"状态。
- 低熵值 = 高度集中/确定: 如果模型生成的多个答案虽然措辞略有差异,但表达的语义完全一致,那么熵值就会很低 。这表明模型对答案非常有信心。
那对于这里的两个熵值的理解如下:
- H ( Y ) : H\left(Y\right): H(Y): 完全不看文档时,模型自己瞎猜答案时的困惑度。
- H ( Y ∣ X i ) : H\left(Y|X_i\right): H(Y∣Xi): 在给定了文档 X i X_i Xi 的前提下,模型生成答案时的困惑度。
互信息 I I I 上面提到的解释是 单个来源与目标之间的关系,在这里也就可以理解为 因为看到了文档 X i X_i Xi, 我们对答案 Y Y Y 的困惑度减少了多少?
所以两个值相减得到的差值越大,说明文档 X i X_i Xi 提供的有效信息越多。如果差值为 0,说明这个文档对模型回答问题毫无帮助。
- U ( X 1 , X 2 , . . . , X k ; Y ) = inf Q I ( Q ; Y ) such that ∀ i X i ∈ Q U\left(X_1,X_2,...,X_k;Y\right) = \inf\limits_{Q} I(Q; Y) \text{such that} \forall i X_i \in Q U(X1,X2,...,Xk;Y)=QinfI(Q;Y)such that∀iXi∈Q
并集信息衡量的是:这组文档 ( X 1 , ... , X k ) (X_1, \dots, X_k) (X1,...,Xk) 作为一个整体,一共为答案 Y Y Y 提供了多少总信息量 。
- 它不关心信息是分布在哪个特定文档里的,也不管文档之间是否有重复。
- 它关注的是:如果我们拥有了这全部 k k k 个文档,我们关于答案 Y Y Y 的不确定性消除了多少。
这个公式使用了信息论中经典的"最小化"定义方式:
- Q Q Q:可以看作是一个"知识集合",它必须包含所有的文档(即 ∀ i , X i ∈ Q \forall i, X_i \in Q ∀i,Xi∈Q)。
- inf Q I ( Q ; Y ) \inf_{Q} I(Q; Y) infQI(Q;Y):这代表在所有包含这些文档的可能分布中,找到它们与答案 Y Y Y 之间互信息( I I I)的下确界(最大共同点) 。
- 简单来说:它是在寻找这些文档库所能提供的"最起码、最保底"的总信息量。
语义熵 Semantic Entropy
在简单了解 PID 理论后,我们总结一下会发现,其实要使用该理论的话,我们便需要计算概率分布,但是在 RAG 中文档和文本并不是简单的随机变量,我们很难说直接计算其全部分布或是其他的分布,总结来说存在两大问题:
- 检索到的文档是检索函数的输出结果,而非随机事件。
- 传统的 PID 要求输入(文档)是具有概率分布的随机变量。但在 RAG 中,给模型看哪 5 个文档是由检索算法(如向量搜索)写死的,不是随机抽取的,这破坏了数学前提。
- 虽然大语言模型(LLM)的响应是概率性生成的,但所有可能文本输出的样本空间过于庞大,难以定义完整的概率分布,这使得真正的熵计算在现实中是无法实现的。
- 计算熵需要遍历所有可能的输出。对于文本生成来说,哪怕是几十个词的组合也是天文数字。你无法算出每一个可能的句子出现的精确概率,所以没法直接用公式算熵。
所以作者并没有使用 传统的 香农熵,而是选用了 语义熵 来作为 PID 中的 熵值。语义熵能巧妙地解决上面的两个问题,其优势总结如下:
- 解决"语义冗余"问题 (Semantic Redundancy)。传统的香农熵是基于 词汇(Token) 概率计算的。如果模型生成了两个句子:"北京是中国的首都"和"中国的首都是北京"。在传统熵看来,这是两个完全不同的序列,会分配不同的概率,从而计算出较高的熵(认为系统很不确定)。语义熵关注的是意思。它通过聚类发现这两个句子表达的是同一个事实(同一语义含义)。在这种情况下,语义熵会认为模型非常确定,从而给出一个较低的熵值。
- 应对"样本空间无限"的挑战 (Intractable Sample Space)。正如前面所说,文本生成的可能组合是天文数字。你无法计算所有可能句子的概率分布 p ( y ) p(y) p(y),因为你没法遍历宇宙中所有可能的句子。义熵通过采样(Sampling)有限数量的样本(比如 10 个),然后计算这些样本之间的语义相似度。它把无限的文本空间坍缩成了有限的"含义簇",使得计算在工程上变得可行。
在引入 语义熵 后 PID 理论在 RAG 场景下便变得可计算了。
I ( X i ; Y ) = H S ( Y ) − H S ( Y ∣ X i ) , U ( X 1 , X 2 , . . . , X k ; Y ) = H S ( Y ) − H S ( Y ∣ X 1 , X 2 , . . . , X k ) I\left(X_i;Y\right) = H_S\left(Y\right) - H_S\left(Y|X_i\right), \\ U\left(X_1,X_2,...,X_k;Y\right) = H_S\left(Y\right) - H_S\left(Y|X_1,X_2,...,X_k\right) I(Xi;Y)=HS(Y)−HS(Y∣Xi),U(X1,X2,...,Xk;Y)=HS(Y)−HS(Y∣X1,X2,...,Xk)
下面是语义熵的具体计算流程(共六步):
- 针对每个查询,生成多个( N N N 个)响应。
- 针对每个响应,获取其句子嵌入(Sentence Embeddings)。 论文使用由 基于 BERT 的模型。。
- 接下来,计算所有响应之间的相似度分数。 我们使用嵌入向量的余弦相似度。
- 将分数归一化至 0,1区间。
- 接下来,通过将每个分数除以所有分数之和来估算概率;即 p i = score i ∑ j score j p_i = \frac{\text{score}_i}{\sum_j\text{score}_j} pi=∑jscorejscorei
- 最后,推导出语义熵为: H S = ∑ i p i log 2 ( p i ) H_S=\sum_i p_i \log_2\left(p_i\right) HS=∑ipilog2(pi)
IS 影响力评分
在 PID(部分信息分解)框架下,IS (Influence Score, 影响力评分) 是该论文提出的核心指标。它的本质是量化:"在整个文档库中,某一个特定文档对最终答案的产出贡献了多少'确定性'。
作者对 文档 X i X_i Xi 的 影响力评分 I S i IS_i ISi 定义为:
I S i = − E ( X i → Y ∣ X 1 , X 2 , . . . , X k ) = I ( X i ; Y ) − U ( X 1 , X 2 , . . . , X k ) = H S ( Y ∣ X 1 , X 2 , . . . , X k ) − H S ( Y ∣ X i ) IS_i = - E\left(X_i \rightarrow Y\right | X_1,X_2,...,X_k) \\ = I\left(X_i;Y\right) - U\left(X_1,X_2,...,X_k\right) =H_S\left(Y|X_1,X_2,...,X_k\right) - H_S\left(Y|X_i\right) ISi=−E(Xi→Y∣X1,X2,...,Xk)=I(Xi;Y)−U(X1,X2,...,Xk)=HS(Y∣X1,X2,...,Xk)−HS(Y∣Xi)
该分数反映了 LLM 相较于仅使用文档 i i i 的信息,在多大程度上更优先考虑来自其他文档的信息。
文档 i i i 的"排除信息"(Excluded Information)值越低,表明 LLM 在生成特定响应时对该文档的依赖程度越高。因此,较低的"排除信息"值应当对应较高的 I S IS IS。此外,较低的 I S IS IS 意味着相对于 H S ( Y ∣ X i ) H_S(Y \mid X_i) HS(Y∣Xi) 而言, H S ( Y ∣ X 1 , X 2 , ... , X k ) H_S(Y \mid X_1, X_2, \dots, X_k) HS(Y∣X1,X2,...,Xk) 的语义熵值更小,这表明:与仅提供孤立的文档 i i i 相比,当提供所有文档时,LLM 的信心提升幅度更大。这种差异越大,意味着其他文档中的内容比文档 i i i 中的内容更受重视(优先级更高)。
对应到 IS 即,
- I S IS IS 值越接近 0 (即越高) ,你是核心文档
- I S IS IS 值负得越多 (即越低),其他文档才是主力
为什么要添加 负号?因为 排除信息跟依赖程度呈现负相关关系,添加负号,使得 IS 跟依赖程度呈现正相关关系。
通过这样的定义和推导 IS 即可通过语义熵的计算得到。
实验验证与结果
研究者通过两项主要实验验证了 IS 的有效性:
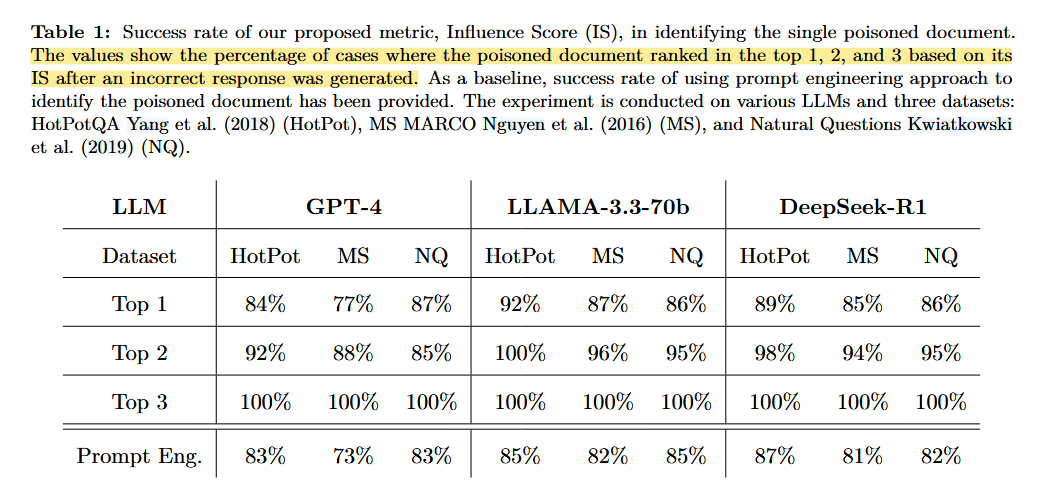
实验一:恶意文档识别 (Poison Attack)
- 设定: 在检索到的 5 个文档中植入一个恶意的"毒化"文档,使模型产生错误回答 。
- 结论:
- 在 86% 的案例中,IS 成功将毒化文档识别为影响力第一的文档 。
- 在前 3 名的影响力排名中,毒化文档的检出率达到了 100% 。
- 表现优于提示词工程:IS 在识别恶意来源方面比直接询问 LLM "哪个文档最相关"更准确 。
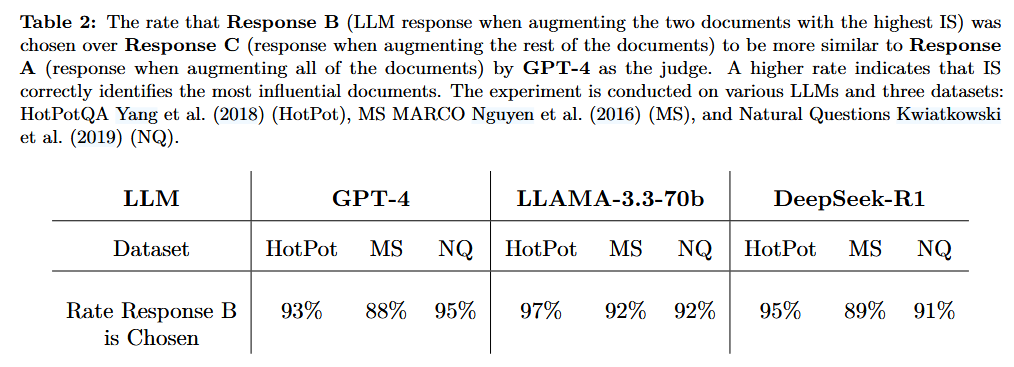
实验二:消融实验 (Ablation Study)
-
设定: 比较三组响应:
- Response A: 使用所有文档生成(基准)。
- Response B: 仅使用 IS 评分最高的两个文档生成。
- Response C: 使用剩余文档生成 。
-
结果: GPT-4 裁判和人类评委一致认为 Response B 与基准 A 更加相似 。这证明了 IS 选出的确实是"含金量"最高的文档。
IS 的实际应用价值
该指标为 RAG 系统提供了以下四个维度的提升 :
- 增强归因与事实核查:用户可以清楚看到每个文档对回答的贡献权重 。
- 偏见识别:通过分析模型更倾向于哪些文档,揭示知识库中潜在的偏见 。
- 精细化检索排序:根据文档对生成的实际贡献(而非简单的向量相似度)来优化检索算法 。
- 防御对抗性攻击:当系统产生有害输出时,能迅速定位并剔除对应的"毒化"数据源 。
局限性
- 计算开销: 这是该方法的主要缺点。为了计算 k k k 个文档的 IS 评分,需要对 RAG 系统进行 2 k + 1 2k + 1 2k+1 次查询
- 适用性: 如果 LLM 完全依靠内部知识回答(不看文档),IS 评分的区分度会下降 。
总结
这篇论文提供了一种非侵入式的方法来拆解 RAG 的生成过程。它不需要修改模型架构,只需通过多次推理观察"语义熵"的变化,就能像"X 光"一样透视出到底是哪个文档在影响 LLM 的决策。