SurgPub-Video: A Comprehensive Surgical Video Framework for Enhanced Surgical Intelligence in Vision-Language Model (AAAI 2026) (A会)
核心内容:
这篇论文解决了手术领域视觉语言模型(VLM)仅依赖帧级数据、缺乏高质量视频级手术知识数据的关键问题,提出了一套包含大规模高质量手术视频数据集、专用视频级手术 VLM 模型、多任务评测基准的完整解决方案,大幅提升了手术场景的视频级视觉语言理解能力,是手术智能领域的重要突破。
核心挑战:
- 数据层面:仅基于帧级数据集训练,缺乏视频级标注,且现有数据存在多样性不足、标注粒度粗、数据源不可靠(如社交媒体视频无同行评审)的问题;
- 模型层面:主流手术 VLM 基于传统 LLaVA 架构,仅支持帧级输入,无显式的时间建模能力,无法捕捉手术流程的连续时序关系;
- 评测层面:缺乏覆盖多专科、多任务的视频级手术 VQA(视觉问答)基准,无法全面评估模型的手术视频理解能力。
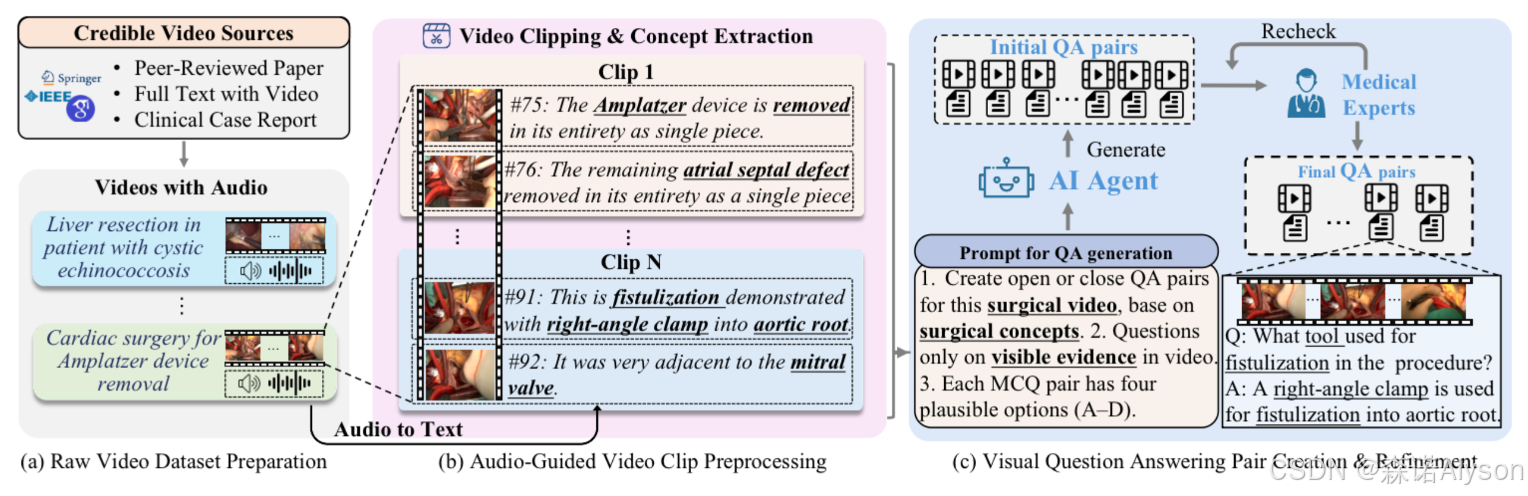
核心贡献1:构建 SurgPub-Video:首个大规模、高可信度的视频级手术 VQA 数据集
- 数据来源:从25 本同行评审的临床医学期刊爬取,共 3538 个原始手术视频,经处理得到 10926 个视频片段,保证临床可信度和权威性;
- 数据规模:覆盖11 个外科专科、75 种手术类型,包含 2500 万标注帧、48520 个 VQA 问答对,涉及 1823 个解剖结构、40 种手术器械、1290 个独特手术步骤;
- 标注特点:结合音频转录文本 + 手术相关文献记录生成问答对,包含开放式和选择题型,覆盖器械识别、解剖结构识别、手术流程识别、手术规划、通用手术知识5 类任务,且经医学专家审核,保证语义丰富性和医学准确性;
- 核心优势:是目前唯一专为视频级手术 VQA设计的数据集,相比此前帧级数据集,具备完整的时间连续性、临床真实性、语义丰富性。
核心贡献2:提出 SurgLLaVA-Video:专用的视频级手术视觉语言模型
基于 TinyLLaVA-Video 架构优化,适配手术视频的时序理解需求,仅 30 亿参数却性能超越大参数量模型:
- 视觉编码器:提取视频片段的帧级视觉特征,保留手术画面的空间信息;
- 视频重采样器:核心创新模块,将帧级特征动态投影为固定数量的可学习查询向量,在保留帧间时序关系的同时降低计算量,解决了视频级输入的时序建模问题;
- 大语言模型(LLM):将视觉特征与文本问题拼接,进行联合推理并生成答案。
- 训练策略:冻结视觉编码器,仅微调视频重采样器和 LLM,基于 SurgPub-Video 的 VQA 对完成训练,同时支持视频级和帧级双输入,兼顾手术流程整体理解和局部细节分析。
核心贡献3:建立 SurgPub-Video Benchmark:多专科、多任务的视频级手术 VQA 评测基准
为全面评估手术 VLM 的视频理解能力,构建了标准化评测基准:
- 数据构成:从 SurgPub-Video 中随机采样 20% 的 VQA 对(共 3337 个样本),剔除相似样本以缓解数据不平衡,调整各专科占比(如心脏外科降至 38.6%,血管外科提升至 11.9%);
- 评测维度:包含整体准确率、专科专属准确率、任务专属准确率,覆盖 11 个外科专科和 5 类核心 VQA 任务。
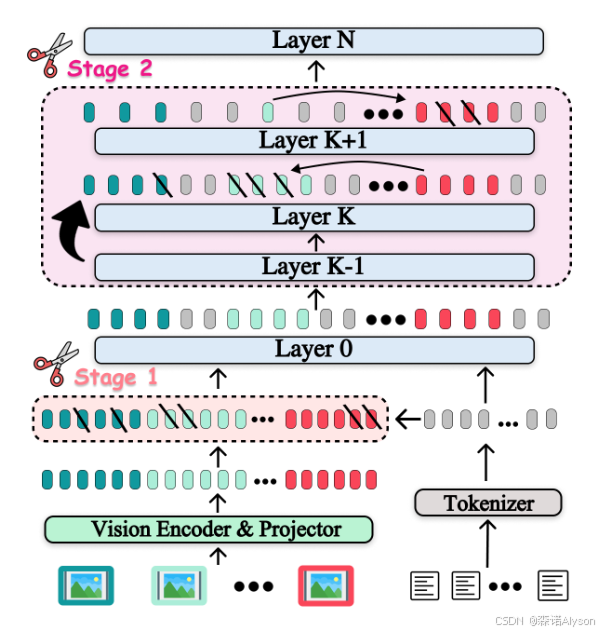
CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning (AAAI 2026) (A会)
核心内容:
提出了首个专为多模态上下文学习(Multimodal ICL)设计的免训练图像 Token 裁剪方法 CATP,解决现有裁剪方法在多图、图文交错 ICL 场景下精度暴跌、效率不足的问题,实现精度提升 + 推理加速双赢。
Stage 1:编码器→解码器之间(预裁剪)
从两个维度打分,贪心选最优子集:
- 文本语义对齐:保留和配对文本最相关的视觉 Token
- 特征多样性:避免保留高度相似的冗余 Token
- 作用:先过滤低信息 Token,减轻解码器压力。
Stage 2:解码器浅层(精裁剪)
用渐进自适应策略:
- 先把所有上下文示例(ICD)图像当作整体,结合层间注意力变化 + 查询语义关联裁剪
- 再用蒸馏后的上下文,指导裁剪查询图像 Token
- 作用:精准抓住 ICL 最关键的上下文 - 查询交互,不破坏推理逻辑。
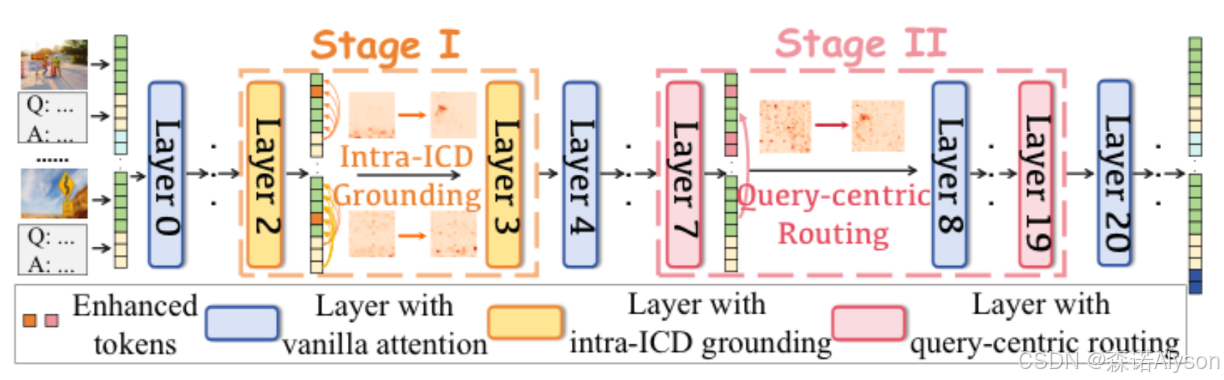
Make LVLMs Focus: Context-Aware Attention Modulation for Better Multimodal In-Context Learning (AAAI 2026) (A会)
核心内容:
提出无需训练、即插即用的 CAMA 方法,解决大视觉语言模型(LVLM)多模态上下文学习(ICL)不稳定、注意力失效问题。
核心挑战:
- 浅层:图文对齐弱
模型在每个图文对内部,无法把注意力放到和文本语义匹配的关键视觉区域。 - 中层:查询 - 示例分配乱
模型不会根据查询问题,给相关的上下文示例(ICD)分配更多注意力。 - 附加问题:位置偏差,前面的示例更容易被忽略。
CAMA 在推理阶段直接修改注意力 logit,不训练、不微调、不改模型结构。
Stage I:ICD 内视觉定位(浅层)
定位每个示例里和问答最相关的图像 token,用动态注意力增量计算关键视觉 token,放大这些 token 的注意力权重,解决图文不对齐
Stage II:以查询为中心的路由(中层)
识别对查询最敏感的注意力头,按查询与示例的相似度,重新分配注意力,让模型更关注有用的上下文示例
加入位置衰减因子,抵消序列位置偏差