
目录
INTRO
场景:大规模排序模型 Large Ranking Models (LRMs)
任务:推荐排序模型的scaling law
作者认为的challenge:
推荐系统中的scaling law受到 经典ID设置 的约束。具体来说,物品 ID 的分类特征的动态和不稳定性质阻碍了有效的知识共享:新引入的 ID 经常遇到冷启动问题,而旧的退役 ID 会丢弃所有以前学到的知识。因此,基于 ID 的特征分布的快速而剧烈的变化阻碍了密集参数的学习,特别是在大规模排名系统中。即
sparse ID类特征 分布变化剧烈 -> 影响dense 参数的收敛优化 -> 影响推荐模型scaling能力。
观察到的现象:
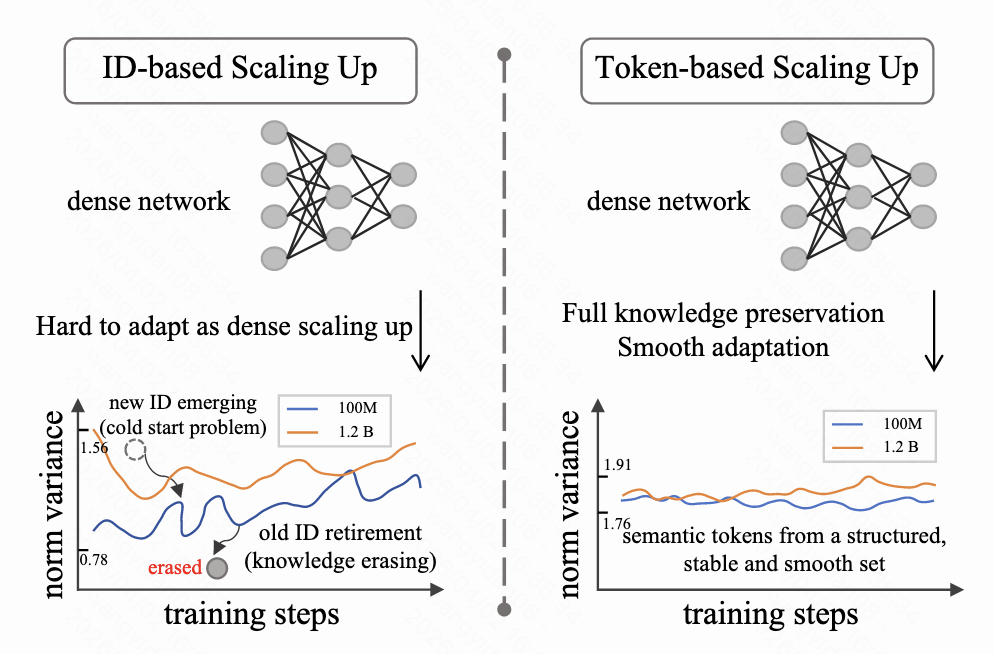
左图 ID:曲线乱跳 → 训练中id分布一直在变化 → 不稳定
右图 Token:曲线平稳 → 训练中token分布较平稳 → 稳定
因此:作者认为语义token在训练过程中随着参数尺度的数量变化具有更稳定的分布。
然而,直接用语义token代替原子ID会导致模型性能立即下降,作者认为有三个原因:
- 语义id大部分源于 物品本身文字/图像等内容模态的信息,缺少完全不同空间的协同模态(和用户交互)的信息。
- 实验表明,由于粗粒度聚类,现有的语义标记用记忆能力换取了更好的泛化性能。(?)
- 当前的方法直接结合项目的语义标记作为输入特征,忽略了标记序列内的结构信息。
作者提出TRM(Token-based Recommendation Model),包括三部分,分别解决上述三个问题:
- 开发了一种基于协同过滤的方法,将用户交互行为信息集成到原始视觉语言嵌入模型中,从而使语义标记能够包含在多模态内容信息和个性化协同信息。
- 对于记忆能力的降低,作者建议独立学习每个item的组合知识,这可以更好地平衡语义标记的泛化和记忆。
- 设计了一个全新的训练框架,共同优化判别性目标和生成性目标。
TRM(Token-based Recommendation Model) 方法
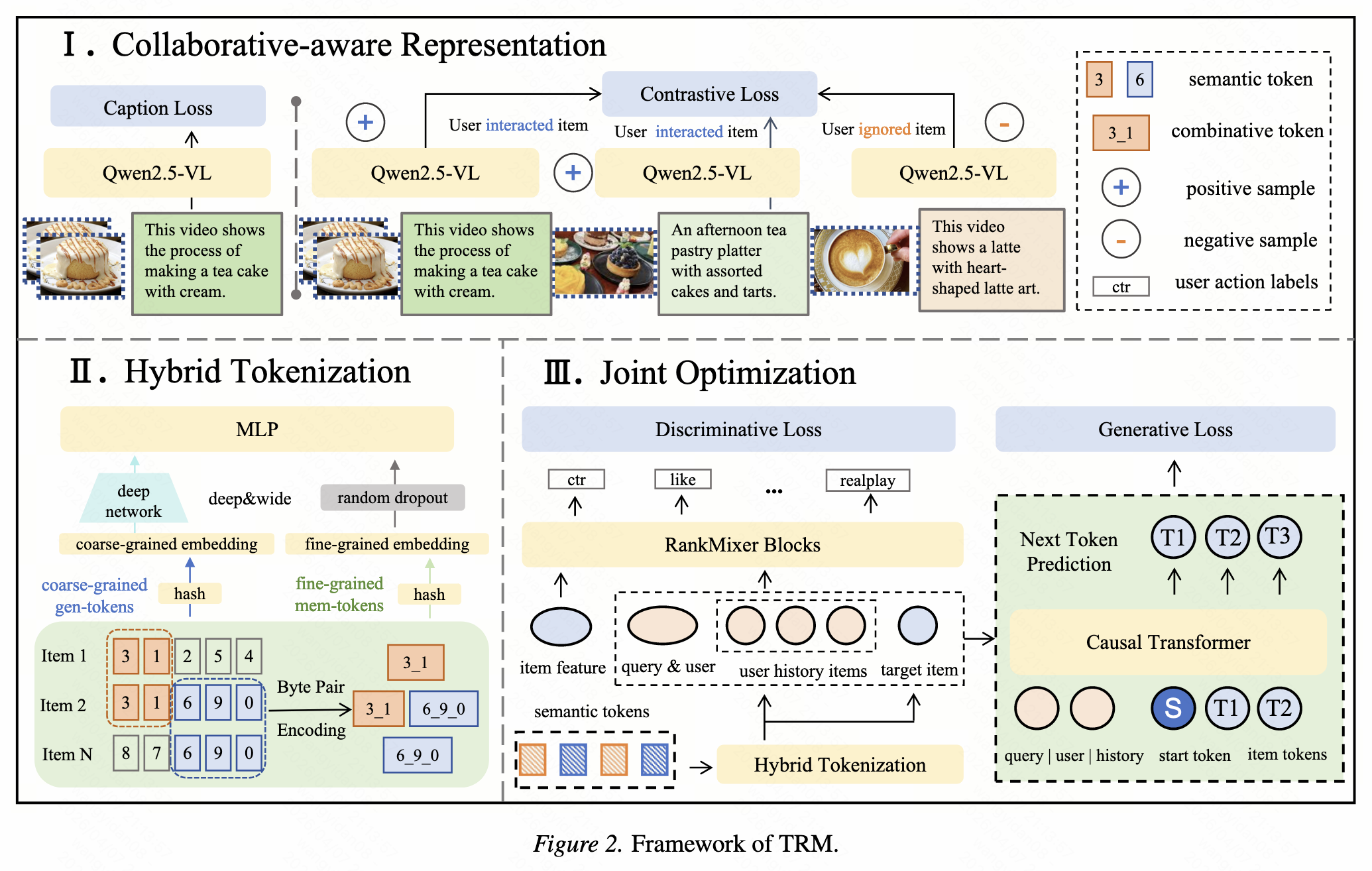
模型整体框架图如图所示,包括三部分。
- 通过联合利用多模态内容信号和大规模用户交互数据来学习密集的item表示。这会产生协同过滤感知的嵌入,捕获语义属性和行为相关性。
- 使用混合标记化策略从这些嵌入构建结构化语义标记。该策略将粗粒度的层次聚类与细粒度的子词组合相结合,平衡泛化和记忆。
- 重新设计了排序模型,使其完全基于语义标记而不是item ID 进行操作。该模型将判别性排名目标与辅助生成建模相结合。
协同信号感知的多模态item表示
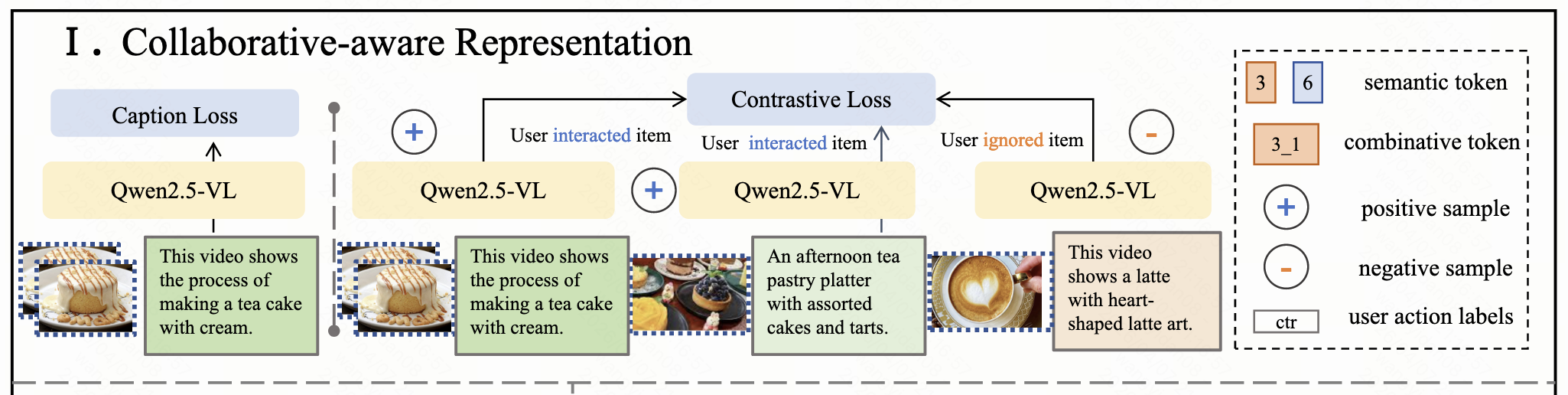
第一步本质上是使用用户-物品交互数据微调了多模态大模型,让该模型生成的物品嵌入表示 既包含物品本身多模态内容信息,也包含用户-物品行为反映的协同信息。具体分为两个阶段:
-
第一阶段,让模型学会短视频领域的内容语义。将每个短视频的视觉信息(视频帧)
文本信息(标题、ASR 语音识别、OCR 图像文字、描述)输入进一个多模态大模型中,让该模型生成对应视频的内容描述、语义概括。该阶段将特定领域的知识注入模型中,并提高其共同理解视觉和文本信息的能力。这个阶段通过自回归的生成任务进行监督:
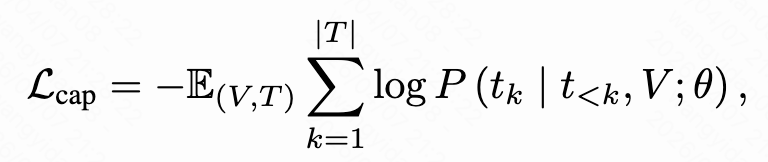
-
第二阶段,把多模态大模型(MLLM)改造用于表示学习,通过显式对齐,把物品嵌入向量和用户行为协同信号结合到一起。首先,对于每个输入,将mllm最后一层的hidden state序列mean pooling后作为该视频的表示;其次,从交互数据中构造两种正样本对:(1)query-item 对,(2)item-item 对(这种是经常一起被点击的)。通过infoNCE的对比学习方式,让相似的query和item表示相对齐,并分离不相关的样本。
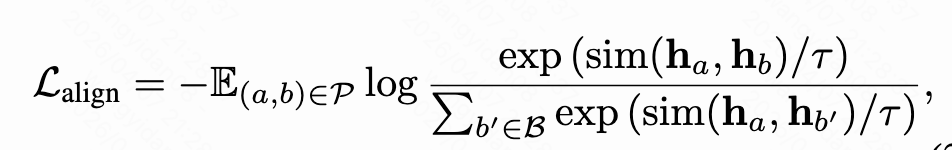
两个阶段共同组成最终的loss,对多模态大模型进行微调。
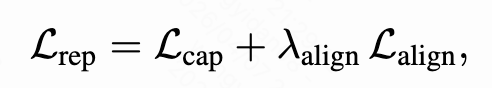
泛化和记忆相平衡的混合tokenization
通过第一部分训练的多模态大模型,每个视频item都得到包含自身内容信息和交互协同信号的嵌入表示。将该表示通过RQ-Kmeans量化成语义token序列,作为item基础的语义ID。
直接使用这种语义id代替原子id,能够提高新出现视频item的排名性能,5天内相较于base都有auc增益,但是模型对于和query时间相差超过5天的物品则模型排序能力并不如base模型。 作者认为当前基础语义ID无法在大规模推荐场景中保留特定于item的知识,其表现好似模型遗忘了旧的item。
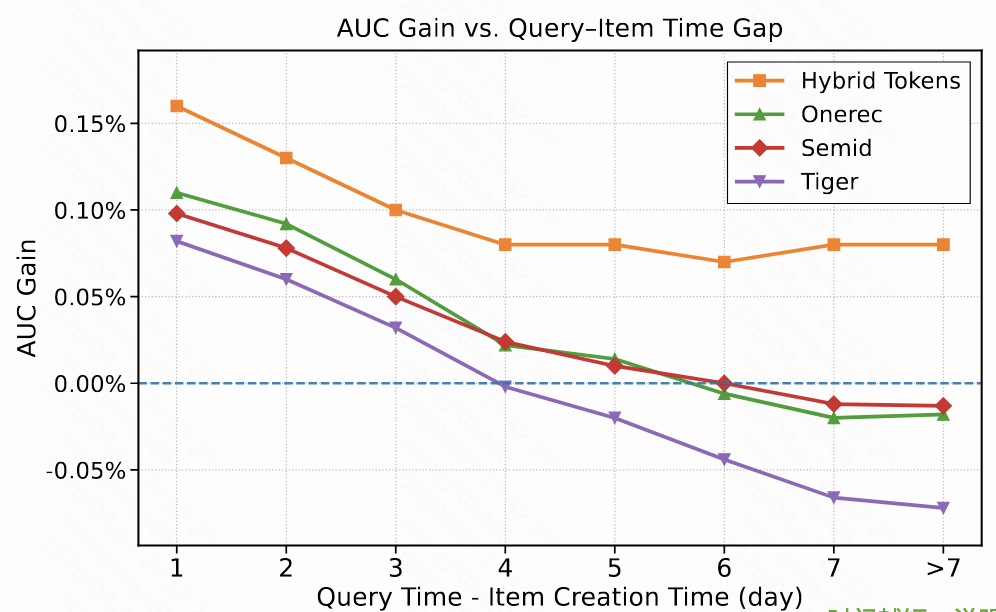
作者认为这种现象的根本原因在于传统残差量化(RQ)得到的语义 token,只能表示 "单个语义",token之间组合而反映出的组合语义无法捕捉,模型记不住细粒度特征,老物品效果变差。
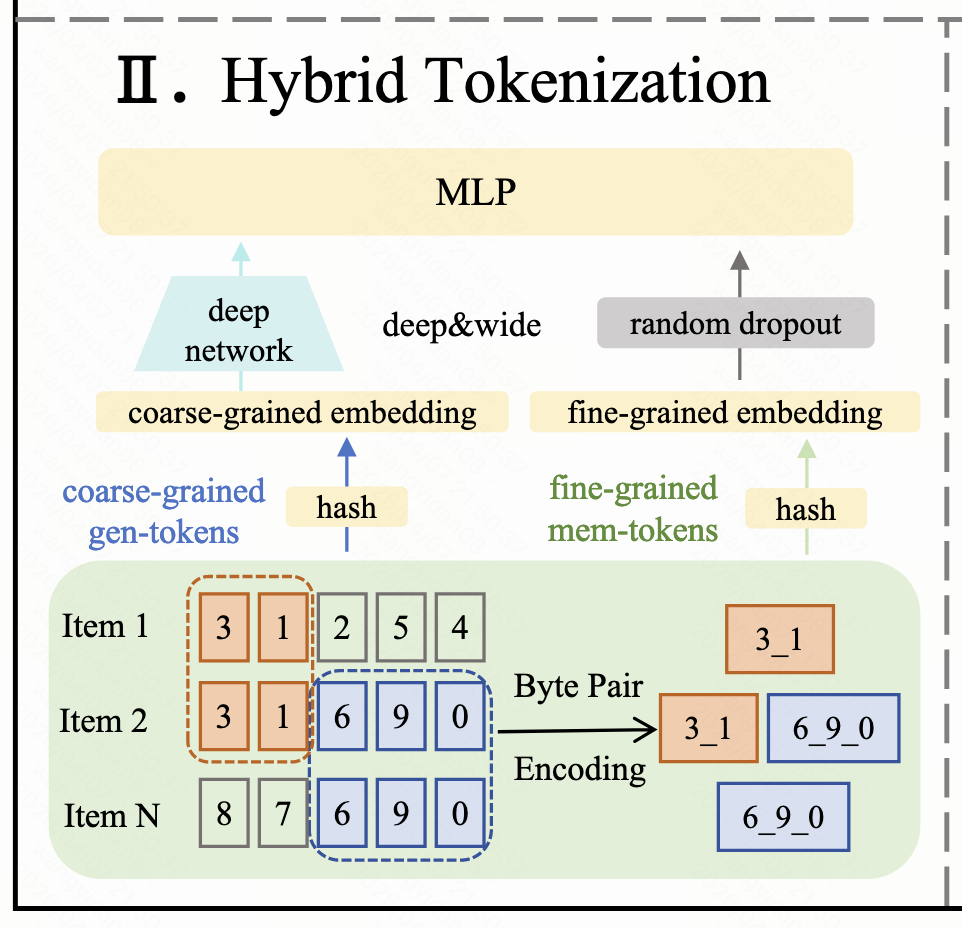
为了让模型能记住 "每个物品的细粒度特征",作者从高频出现的语义 token 组合里,用 BPE 算法挖出专属的新组合token,专门用来保存物品的细节与组合语义信息。也就是图中的"3_1","6_9_0"都是组合token。
在这里,原来生成的基础语义ID称之为gen-tokens,负责泛化。新的组合token称之为mem-tokens,负责记忆。最后通过Wide&Deep 结构把它们的表示组合在一起,生成对item最终的表示。从图3可以看出,这样设计的混合token,无论是新物品还是老物品,相较base模型在auc上都有增益。
判别目标和生成目标的联合优化
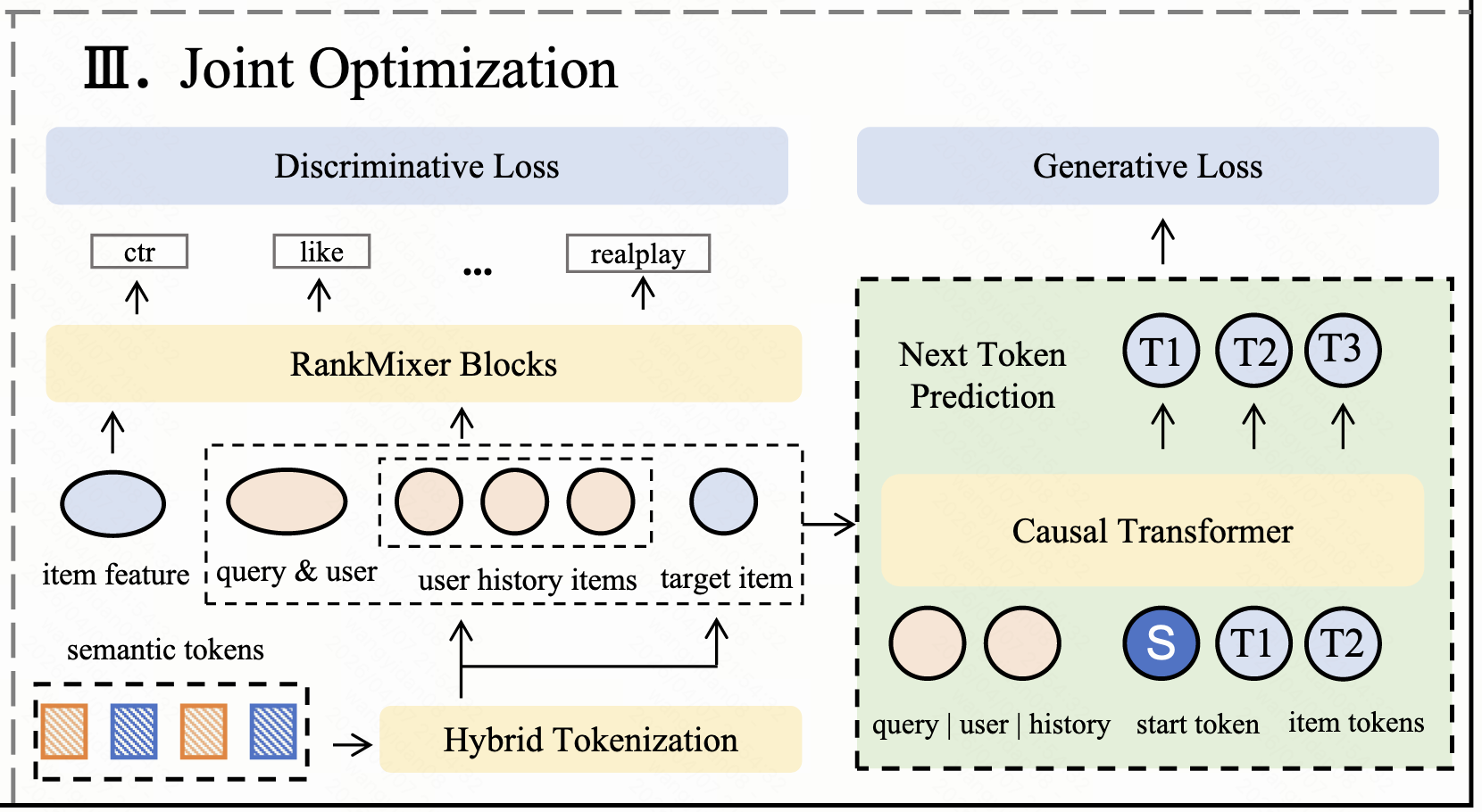
为了充分利用语义token的潜力,作者提出直接联合优化判别目标和生成目标。
- 对于判别目标,所有 Xq(query)、XI(item feature) 和 XU(用户行为历史) 都用于预测用户对target item的实际操作(ctr、like、real-play 等),使用 BCE 损失来优化判别目标:
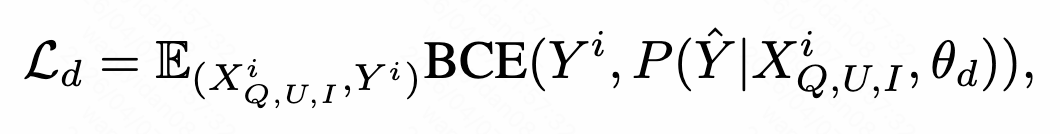
- 对于生成目标,使用 Xq 和 XU 作为输入来自回归生成target item的语义id,采用NTP损失来优化生成目标:
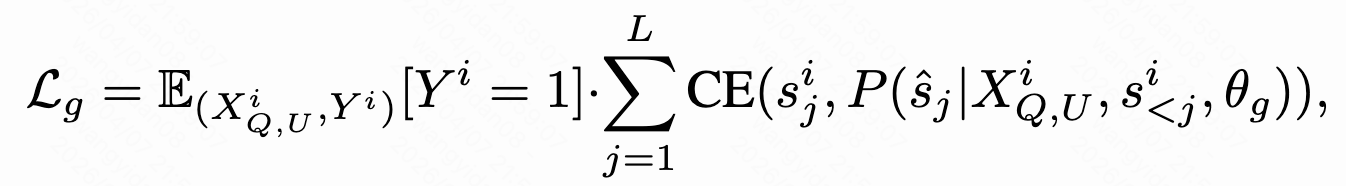
TRM的最终学习目标如下,其中lambda是:
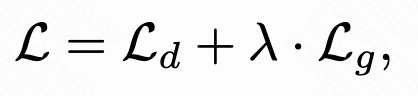
具体实验
基础设置
● 数据集:TIKTOK离线视频搜索数据集
● baseline:
○ ID-based方法:DCN、DHEN、WuKong、RankMixer
○ 语义token-based方法:TIGER、OneRec、SemID
● 实验模型基本框架采用RankMixer,本质上是语义token构造方式的不同。
● 采用AUC和QAUC(查询粒度的auc)作为评价指标,推理阶段还是使用模型的判别能力。
核心结果
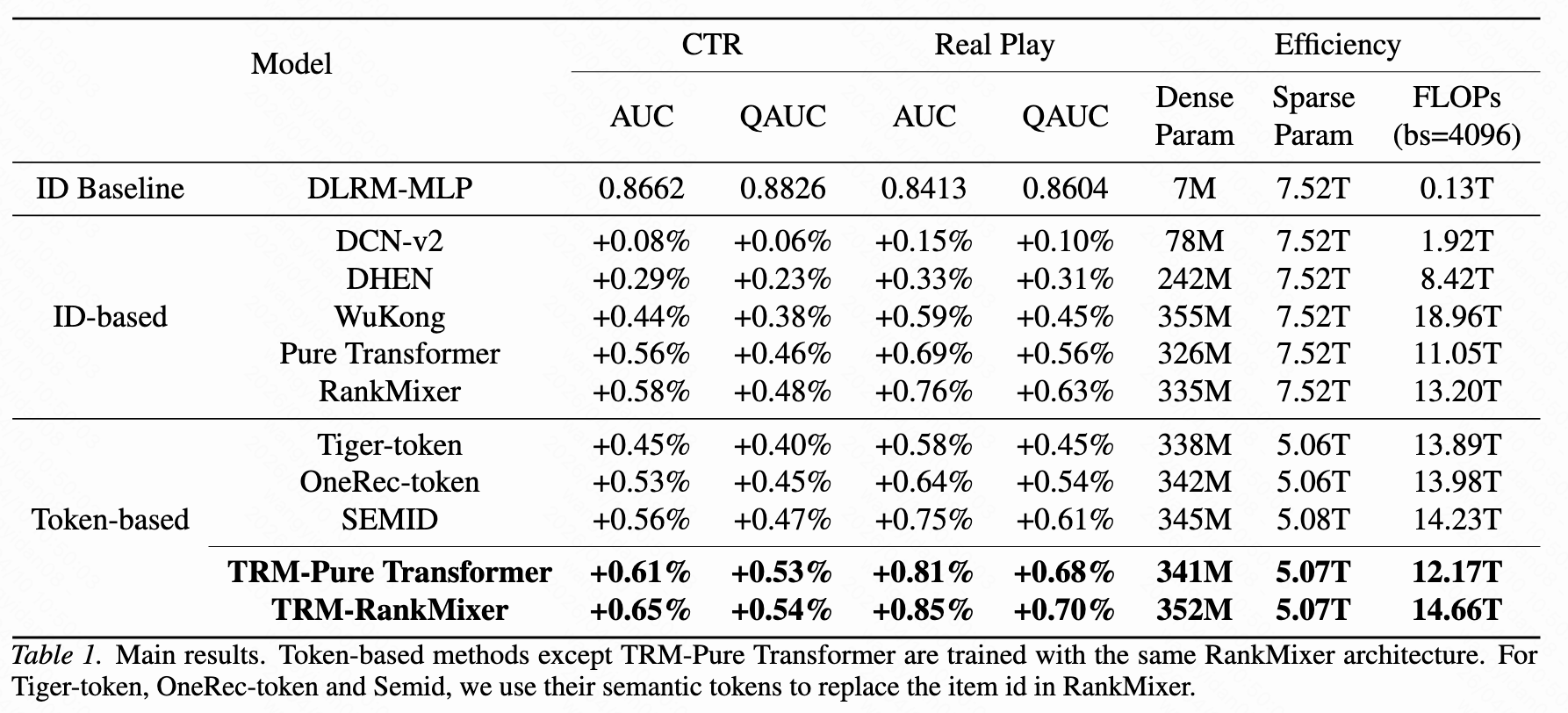
- 论文所提出的 TRM 框架展示了SOTA的性能和效率。TRM 将稀疏参数从基于 ID 的方法中的 7.52T 减少到 5.07T(减少了 32.6%)的同时,也提高了模型性能。
- 在RankMixer架构下,其他的语义token效果都不如基于ID的模型,验证了直接用语义token代替原子ID会导致模型性能下降。而TRM能够超越基于ID的RankMixer,证明了该架构能更充分挖掘语义ID的潜力。
Scaling law
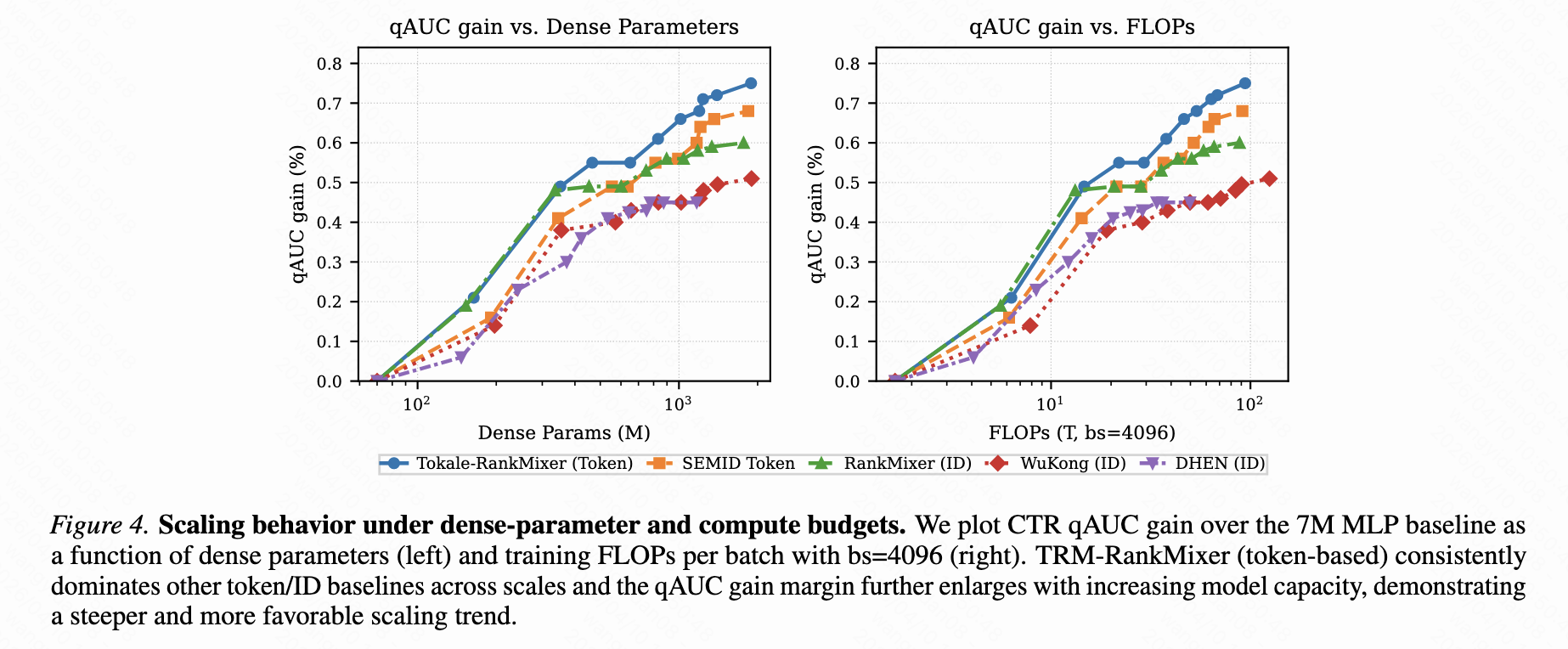
- 随着模型参数量的增长/ flops的增长,论文提出的TRM框架qauc表现都在提升,展现出了scaling 的趋势。
- 基于ID的方法,随着模型规模的增大,性能并没有明显的持续提升,反而趋近饱和,也反映出基于原子ID的方法在scaling 上是受限的。
消融实验
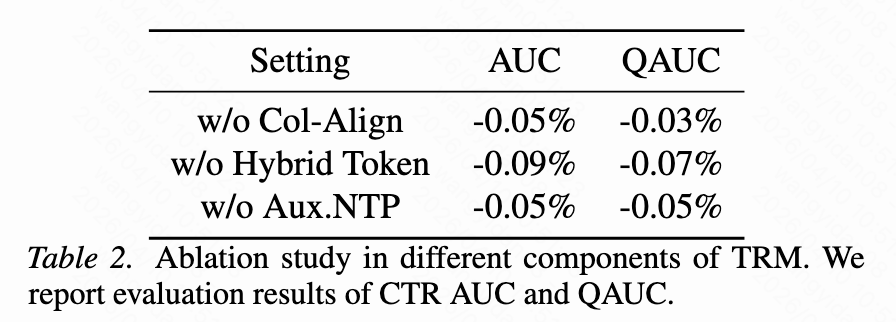
对3个阶段的消融,其中混合token贡献了最大的 AUC 增益,这证明了平衡语义token的泛化和记忆能力的必要性。
在线表现

在真实搜索引擎(TIKTOK视频搜索)上线了 TRM 模型进行在线实验,对比基线的 大小为7M的DLRM 模型,使用更大的 TRM-Rankmixer-352M 模型,CTR 对应的 QAUC 提升 0.54%。