引言与研究背景
人工智能发展的历史脉络与AGI愿景
人工智能的发展历程可以追溯到二十世纪五十年代,当时图灵提出了著名的"图灵测试",为机器智能的评估奠定了理论基础。从符号主义到连接主义,从专家系统到深度学习,人工智能领域经历了多次范式转换。然而,长期以来,人工智能系统始终面临着"窄人工智能"(Narrow AI)的局限性------即每个系统只能在特定领域执行特定任务,缺乏跨领域的泛化能力和适应性。
通用人工智能(Artificial General Intelligence,AGI)的概念应运而生,它代表了一种能够像人类一样在各种认知任务中表现出色的人工智能系统。AGI不仅能够执行特定任务,还能够学习新技能、适应新环境、进行抽象推理,并展现出创造性思维。这一愿景一直是人工智能研究的终极目标,但在很长一段时间内被认为遥不可及。
近年来,随着深度学习技术的突破性进展,特别是大语言模型(Large Language Models,LLMs)的兴起,AGI的实现路径变得更加清晰。2022年ChatGPT的发布标志着大语言模型进入公众视野,其展现出的对话能力、推理能力和知识整合能力引发了学术界和产业界对AGI可能性的广泛讨论。然而,正如Mumuni等人在其综述论文《Large language models for artificial general intelligence (AGI): A survey of foundational principles and approaches》中指出的,尽管大语言模型展现出令人印象深刻的能力,但其认知能力仍然"肤浅且脆弱",通用能力受到严重限制。
语言与智能的深层关联
语言作为人类智能的核心组成部分,在知识获取、表示和组织中发挥着不可替代的作用。认知科学研究表明,语言不仅是交流的工具,更是思维本身的载体。维特根斯坦曾言"语言的边界就是世界的边界",这一哲学洞见在人工智能研究中具有深刻的意义。
从认知神经科学的角度来看,语言能力与人类的高级认知功能密切相关。大脑的语言处理区域,如布罗卡区和韦尼克区,与其他认知功能区域存在广泛的连接。这种神经解剖学上的关联表明,语言处理不是孤立的认知模块,而是与记忆、推理、规划等高级认知功能相互交织的。这一发现为理解大语言模型的潜力提供了重要启示:如果语言确实是智能的核心组成部分,那么在语言建模方面取得突破的系统,可能也具备了通向更广泛智能的潜力。
语言在认知信息处理中的作用可以从以下几个维度来理解:首先,语言提供了符号化的知识表示方式,使得抽象概念能够被操作和组合;其次,语言支持递归和组合性,这使得有限的语言规则能够生成无限的表达;第三,语言是社会认知的基础,支持知识共享和协作推理。这些特性使得语言成为研究通用智能的理想切入点。
大语言模型的崛起与局限
大语言模型的发展建立在Transformer架构的基础之上。2017年,Vaswani等人发表的里程碑式论文《Attention Is All You Need》提出了Transformer架构,其核心创新在于自注意力机制(Self-Attention Mechanism)。这一机制使得模型能够直接建模序列中任意两个位置之间的依赖关系,突破了传统循环神经网络在处理长距离依赖时的局限性。
自注意力机制的数学表达可以表示为:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dk QKT)V
其中,QQQ(Query)、KKK(Key)和VVV(Value)分别是查询、键和值矩阵,dkd_kdk是键向量的维度。这一公式通过计算查询与键的相似度来确定对值的加权方式,从而实现信息的动态选择和整合。
输出层
线性变换 Linear
Softmax
解码器 Decoder
掩码自注意力 Masked Self-Attention
编码器-解码器注意力 Cross-Attention
前馈神经网络 Feed Forward
编码器 Encoder
多头自注意力 Multi-Head Self-Attention
前馈神经网络 Feed Forward
层归一化 Layer Norm
输入层
词嵌入 Embedding
位置编码 Positional Encoding
大语言模型通过在海量文本数据上进行预训练,学习到了丰富的语言知识和世界知识。GPT系列模型采用自回归语言建模的方式,通过预测下一个词来学习语言的统计规律;BERT系列模型则采用掩码语言建模,通过预测被遮蔽的词来学习双向上下文表示。这些预训练模型展现出了强大的迁移学习能力,能够通过微调或提示学习适应各种下游任务。
然而,正如Mumuni等人的综述所强调的,当前大语言模型存在若干根本性的局限。首先,这些模型缺乏与物理世界的直接交互,其知识完全来源于文本数据,这导致了"符号接地问题"(Symbol Grounding Problem)------模型中的符号与现实世界中的实体和概念之间缺乏直接的联系。其次,大语言模型主要学习的是相关性而非因果性,这使得它们在面对需要因果推理的任务时表现不佳。第三,Transformer架构的自注意力机制虽然强大,但其计算复杂度随序列长度呈二次方增长,这限制了模型的有效上下文长度,从而影响了长期记忆能力。
AGI的定义与研究意义
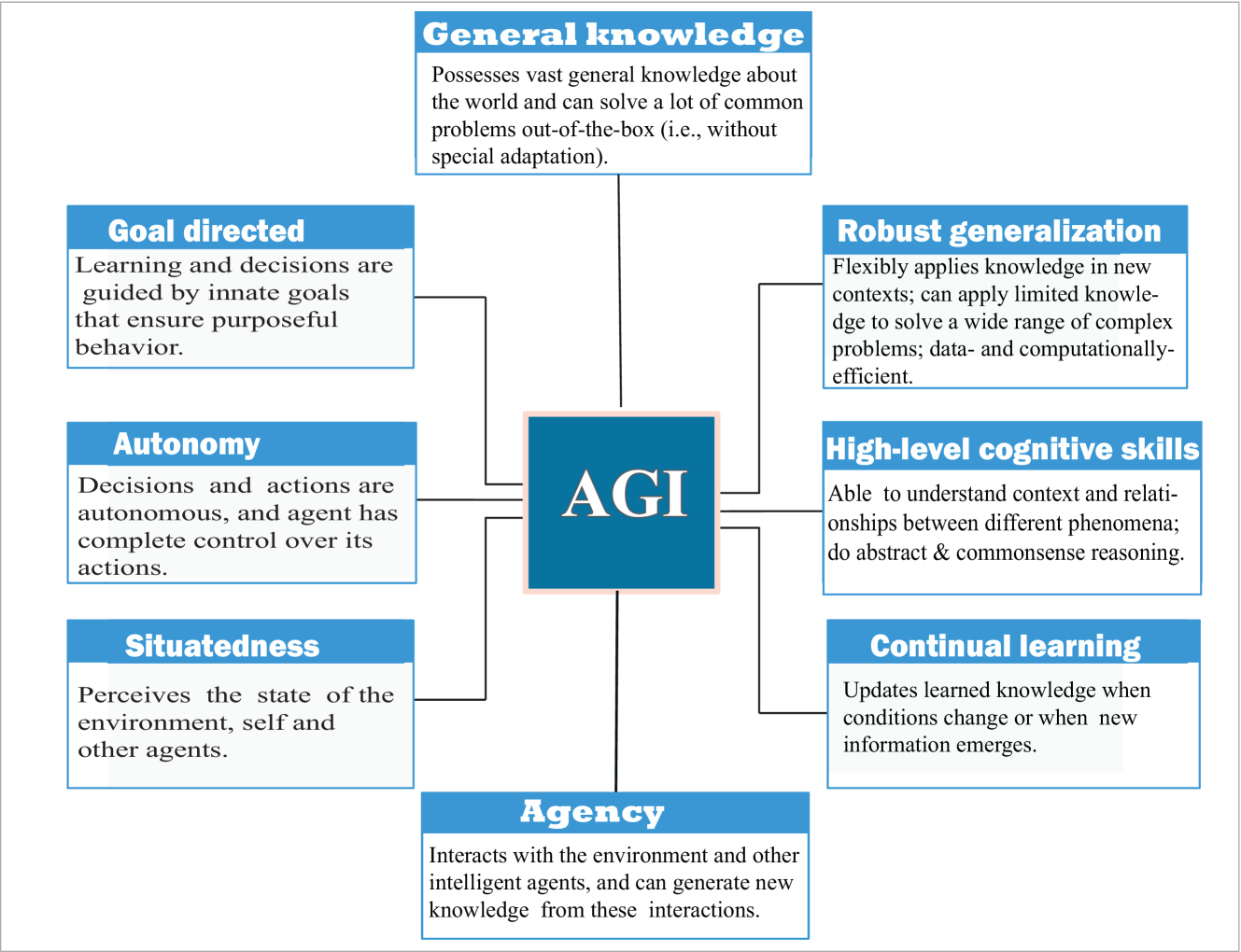
通用人工智能的定义在学术界尚未达成完全共识,但通常被认为具有以下核心特征:跨领域泛化能力、自主学习能力、抽象推理能力、以及适应新环境的能力。与窄人工智能不同,AGI应该能够像人类一样处理各种认知任务,而不仅限于特定领域。
表1:窄人工智能与通用人工智能的特征对比
| 特征维度 | 窄人工智能(Narrow AI) | 通用人工智能(AGI) |
|---|---|---|
| 任务范围 | 特定领域、特定任务 | 跨领域、多任务 |
| 学习能力 | 需要针对特定任务训练 | 自主学习新技能 |
| 泛化能力 | 有限,依赖训练数据分布 | 强,能适应新情境 |
| 推理能力 | 模式匹配为主 | 抽象推理、因果推理 |
| 知识表示 | 任务特定知识 | 统一的知识表示 |
| 适应性 | 需要重新训练适应新任务 | 动态适应新环境 |
| 典型例子 | 图像分类器、机器翻译系统 | 人类级智能系统 |
研究AGI具有重要的理论和实践意义。从理论角度看,AGI研究有助于我们理解智能的本质,探索认知的基本原理,并推动认知科学、神经科学和人工智能的交叉融合。从实践角度看,AGI的实现将带来革命性的技术变革,在科学研究、医疗诊断、教育、创意产业等领域产生深远影响。
本文的研究范围与结构
本文基于Mumuni和Mumuni的综述论文,深入探讨大语言模型通向AGI的四个基础性原则:具身性(Embodiment)、符号接地(Symbol Grounding)、因果性(Causality)和记忆(Memory)。这四个原则被认为是实现人类级通用智能必须解决的核心问题。
具身性强调智能系统需要与物理世界进行交互,通过感知和行动来获取知识和理解世界。符号接地问题关注如何将语言符号与现实世界中的实体和概念建立联系。因果性涉及理解事物之间的因果关系,而不仅仅是统计相关性。记忆则关乎如何有效地存储、组织和检索信息,支持长期学习和推理。
本文将系统性地分析这四个基础原则的理论背景、当前研究进展以及在大语言模型中的实现方法,最终探讨如何将这些原则有机整合,构建通向AGI的技术路径。
大语言模型技术基础与AGI关联
Transformer架构的深度解析
Transformer架构的提出标志着自然语言处理领域的范式转变。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer完全依赖注意力机制来建模序列中的依赖关系,摒弃了循环结构和卷积操作。这一设计选择带来了显著的优势:首先,它使得模型能够并行处理序列中的所有位置,大大提高了训练效率;其次,它解决了长距离依赖问题,使得模型能够直接建模序列中任意两个位置之间的关系。
Transformer的核心组件包括多头自注意力机制(Multi-Head Self-Attention)、位置前馈网络(Position-wise Feed-Forward Network)、层归一化(Layer Normalization)和残差连接(Residual Connection)。多头自注意力机制通过并行运行多个注意力头,使得模型能够同时关注不同表示子空间的信息。其计算过程可以形式化表示为:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^OMultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中每个注意力头的计算为:
headi=Attention(QWiQ,KWiK,VWiV)\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)
这里,WiQ∈Rdmodel×dkW_i^Q \in \mathbb{R}^{d_{model} \times d_k}WiQ∈Rdmodel×dk、WiK∈Rdmodel×dkW_i^K \in \mathbb{R}^{d_{model} \times d_k}WiK∈Rdmodel×dk、WiV∈Rdmodel×dvW_i^V \in \mathbb{R}^{d_{model} \times d_v}WiV∈Rdmodel×dv和WO∈Rhdv×dmodelW^O \in \mathbb{R}^{hd_v \times d_{model}}WO∈Rhdv×dmodel是可学习的参数矩阵。
位置前馈网络对每个位置独立地应用相同的全连接网络,通常包含两个线性变换和一个非线性激活函数:
FFN(x)=max(0,xW1+b1)W2+b2\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2FFN(x)=max(0,xW1+b1)W2+b2
这一设计使得模型能够在注意力机制提取的上下文表示基础上,进行更复杂的非线性变换。
前馈网络
输入
线性层1
ReLU激活
线性层2
输出
多头注意力机制
Query
注意力计算
Key
Value
Head 1
Head 2
Head h
拼接 Concat
线性变换
Add & Norm
Add & Norm
大语言模型的预训练范式
大语言模型的训练通常采用预训练-微调(Pre-training and Fine-tuning)范式。预训练阶段,模型在海量无标注文本数据上进行自监督学习,学习语言的通用表示。微调阶段,模型在特定任务的标注数据上进行有监督学习,适应下游应用。
自监督学习任务的设计是大语言模型成功的关键。GPT系列模型采用的自回归语言建模任务,通过最大化以下似然函数来训练模型:
LLM=∑t=1TlogP(xt∣x1,...,xt−1;θ)\mathcal{L}{LM} = \sum{t=1}^{T} \log P(x_t | x_1, ..., x_{t-1}; \theta)LLM=t=1∑TlogP(xt∣x1,...,xt−1;θ)
其中,xtx_txt是序列中第ttt个词元,θ\thetaθ是模型参数。这一训练目标使得模型学会根据上下文预测下一个词,从而捕获语言的统计规律和知识模式。
BERT系列模型采用的掩码语言建模(Masked Language Modeling,MLM)任务,随机遮蔽输入序列中的一部分词元,然后训练模型预测被遮蔽的词元:
LMLM=Ex∼D∑i∈M−logP(xi∣x∖M;θ)\mathcal{L}{MLM} = \mathbb{E}{x \sim \mathcal{D}} \left \\sum_{i \\in M} -\\log P(x_i \| x_{\\setminus M}; \\theta) \\rightLMLM=Ex∼Di∈M∑−logP(xi∣x∖M;θ)
其中,MMM是被遮蔽词元的索引集合,x∖Mx_{\setminus M}x∖M表示未被遮蔽的词元序列。
随着模型规模的扩大,大语言模型展现出了涌现能力(Emergent Abilities)------即在模型规模超过某个阈值后才出现的能力。这些能力包括上下文学习(In-context Learning)、思维链推理(Chain-of-Thought Reasoning)和指令遵循(Instruction Following)等。涌现能力的发现引发了关于大语言模型是否正在接近AGI的热烈讨论。
大语言模型支持AGI的核心特征
Mumuni等人的综述论文系统性地分析了大语言模型支持实现人类级智能的核心特征。这些特征包括知识表示能力、推理能力、对话能力和协作能力。
在知识表示方面,大语言模型通过在海量文本数据上的预训练,学习到了丰富的世界知识。研究表明,大语言模型能够编码事实性知识、常识知识和程序性知识。知识被存储在模型的参数中,通过适当的提示可以被检索和应用。然而,这种知识表示方式存在固有的局限性:知识是隐式的、分布式的,难以进行精确的查询和更新;知识可能包含训练数据中的偏见和错误;模型难以区分已知和未知。
在推理能力方面,大语言模型展现出了令人印象深刻的性能。通过思维链提示(Chain-of-Thought Prompting),模型能够将复杂问题分解为多个步骤,逐步进行推理。研究表明,大语言模型能够进行数学推理、逻辑推理和常识推理。然而,这种推理能力仍然存在争议:一些研究认为模型只是在模仿训练数据中的推理模式,而非真正理解推理过程;模型在需要多步推理或反事实推理的任务上表现不佳。
表2:大语言模型的核心能力与局限性分析
| 能力维度 | 表现特征 | 支持技术 | 主要局限 |
|---|---|---|---|
| 知识表示 | 事实、常识、程序知识存储 | 预训练、参数编码 | 隐式表示、难以更新、偏见问题 |
| 语言理解 | 语义解析、上下文理解 | 自注意力、上下文编码 | 长文本处理、歧义消解 |
| 推理能力 | 数学、逻辑、常识推理 | 思维链提示、上下文学习 | 多步推理、反事实推理困难 |
| 对话交互 | 多轮对话、角色扮演 | 指令微调、RLHF | 一致性、长期记忆缺失 |
| 知识应用 | 任务迁移、零样本学习 | 提示工程、少样本学习 | 领域适应性、可靠性问题 |
| 创造生成 | 文本创作、代码生成 | 自回归生成、采样策略 | 幻觉问题、事实准确性 |
从LLM到AGI的鸿沟分析
尽管大语言模型展现出了强大的能力,但实现AGI仍然面临根本性的挑战。Mumuni等人的综述论文识别出了四个关键的基础性问题:具身性缺失、符号接地问题、因果推理局限和记忆机制不足。
具身性缺失意味着大语言模型与物理世界完全隔离。模型的知识来源于文本数据,而非通过感知和行动与世界的直接交互。这种"离身"的特性导致模型难以理解物理常识,难以在真实环境中执行任务,难以形成对世界的真实表征。认知科学研究表明,人类的智能深深植根于身体与环境的交互之中,感知和行动是认知的基础。
符号接地问题由认知科学家Harnad于1990年提出,指的是符号系统中的符号如何获得其意义的问题。对于大语言模型而言,模型中的词元(token)只是数学向量,它们之间的关系通过统计规律建立,而非通过与现实世界中实体和概念的直接联系。这导致模型可能生成语法正确但语义空洞或错误的内容。
因果推理的局限性是大语言模型的另一个根本问题。模型学习的是变量之间的相关性,而非因果关系。这使得模型在面对需要因果理解的任务时表现不佳,如预测干预效果、回答反事实问题、进行因果解释等。因果推理被认为是人类智能的核心能力之一,对于科学发现、决策制定和日常推理都至关重要。
记忆机制的不足限制了模型处理长期信息的能力。Transformer架构的自注意力机制计算复杂度为O(n2)O(n^2)O(n2),其中nnn是序列长度,这限制了模型能够处理的上下文长度。虽然通过位置编码和相对位置编码等技术,模型能够处理较长的序列,但有效的信息整合仍然受到限制。此外,模型缺乏显式的长期记忆机制,无法在多次交互之间保持和更新信息。
LLM到AGI的鸿沟
具身性缺失
无物理感知能力
无行动执行能力
缺乏环境交互
物理常识理解困难
符号接地问题
符号与现实脱节
语义理解表面化
缺乏指称能力
意义获取困难
因果推理局限
学习相关性非因果性
干预预测困难
反事实推理受限
因果解释能力弱
记忆机制不足
上下文长度限制
缺乏长期记忆
信息整合受限
跨会话记忆缺失
具身性与智能体意识
具身性的理论基础
具身性(Embodiment)是认知科学和人工智能领域的核心概念,它强调智能不是抽象的信息处理,而是深深植根于身体与环境的交互之中。这一观点可以追溯到现象学哲学家梅洛-庞蒂的思想,他认为身体是我们感知和理解世界的基础。
在认知科学中,具身认知理论认为认知过程受到身体形态、感觉运动系统和环境交互的深刻影响。这一理论得到了大量实验证据的支持。例如,概念隐喻理论表明,抽象概念的理解往往依赖于具体的身体经验------我们用"抓取"来理解"理解",用"看见"来理解"认识"。这些语言现象反映了身体经验在认知中的基础性作用。
具身智能的研究在机器人学领域有着悠久的历史。从Brooks的行为主义机器人到现代的深度强化学习方法,研究者们一直在探索如何构建能够与物理世界交互的智能系统。具身智能的核心假设是:通过与环境的交互,智能系统能够学习到更加鲁棒和可泛化的知识,这些知识难以仅从被动观察中获得。
具身性作为通用智能的基础
Mumuni等人的综述论文强调,具身性是实现通用智能的基础性原则。这一观点基于以下理论考量:首先,具身性提供了知识获取的渠道。通过与环境的交互,智能体能够获得关于世界的第一手经验,这些经验是构建世界模型的基础。其次,具身性支持语义接地。通过与物理对象的交互,符号能够获得其意义,解决了符号接地问题。第三,具身性促进了技能学习。许多智能行为,如操作、导航和社交,都需要通过实践来习得。
发展心理学的研究为具身性的重要性提供了支持证据。皮亚杰的认知发展理论表明,儿童的认知发展始于感觉运动阶段,通过与环境物体的交互,逐渐发展出更高级的认知能力。这一发展路径暗示着,真正的智能可能需要经历类似的具身发展阶段。
在人工智能领域,具身智能的研究正在经历复兴。随着机器人硬件的进步和深度学习技术的发展,研究者们开始探索如何将大语言模型与机器人系统结合,创建能够理解自然语言指令并执行物理任务的具身智能体。这一研究方向被称为"具身AI"(Embodied AI)。
具身智能的关键要素
综述论文识别出了具身智能的几个关键要素:目标意识(Goal-awareness)、情境意识(Situational-awareness)、自我意识(Self-awareness)和审慎行动(Deliberate Action)。
目标意识是指智能体能够理解并追求目标的能力。这包括理解任务目标、分解复杂目标、监控目标进展和调整目标策略。在人类认知中,目标导向行为是智能的核心特征。实现目标意识需要智能体具备目标表示、规划和执行监控的能力。
情境意识是指智能体能够感知和理解其所处环境的能力。这包括环境感知、情境理解和情境预测。情境意识使得智能体能够根据环境状态调整行为,是适应性智能的基础。在具身AI中,情境意识通常通过多模态感知和环境建模来实现。
自我意识涉及智能体对自身状态、能力和局限的认识。这包括自我监控、能力评估和不确定性意识。虽然当前的AI系统远未达到人类水平的自我意识,但一些研究表明,大语言模型在特定任务中表现出了初步的自我评估能力。
审慎行动是指智能体能够有计划地执行行动,而非简单地反应。这需要智能体具备规划能力、行动选择能力和执行控制能力。审慎行动是智能体在复杂环境中有效运作的关键。
实现方法
能力要求
具身智能核心要素
目标意识
Goal-awareness
情境意识
Situational-awareness
自我意识
Self-awareness
审慎行动
Deliberate Action
目标表示与分解
环境感知与建模
自我监控与评估
规划与执行控制
任务规划器
多模态感知
元认知模块
行动执行器
整合架构
具身智能体
具身LLM的实现方法
将大语言模型与具身系统结合是当前研究的热点方向。综述论文讨论了几种主要的实现方法。
一种方法是使用大语言模型作为机器人的"大脑",负责高级认知功能如任务理解、规划和决策。这种方法通常采用分层架构:大语言模型处理自然语言指令,生成任务计划或代码,然后由底层控制系统执行。例如,Google的PaLM-E模型将语言模型与机器人控制结合,使得机器人能够理解自然语言指令并执行复杂任务。
另一种方法是训练端到端的具身多模态模型。这类模型直接从多模态输入(包括视觉、语言和本体感知)预测行动。例如,RT-2模型将视觉-语言模型与机器人行动结合,实现了从自然语言指令到机器人行动的直接映射。
Nature Machine Intelligence发表的研究提出了ELLMER(Embodied LLM-enabled Robot)框架,该框架整合了人工智能方法和感觉运动控制方法,创建了能够执行复杂任务的具身智能体。研究表明,通过将大语言模型的语义理解能力与机器人的感知运动能力结合,可以实现更加智能和灵活的行为。
表3:具身LLM的主要实现方法对比
| 方法类型 | 核心思想 | 优势 | 挑战 | 代表工作 |
|---|---|---|---|---|
| 分层架构 | LLM作为高层规划器 | 模块化、可解释 | 接口设计、延迟 | PaLM-E, SayCan |
| 端到端训练 | 多模态输入直接预测行动 | 端到端优化 | 数据需求、泛化 | RT-2, Octo |
| 世界模型 | 学习环境动态模型 | 规划能力、想象 | 模型准确性 | IRIS, Dreamer |
| 强化学习 | 通过交互学习策略 | 适应性强 | 样本效率、奖励设计 | ELLMER |
目标意识与情境意识的实现
目标意识的实现在具身AI中至关重要。综述论文讨论了几种实现目标意识的方法。一种方法是通过提示工程,将目标信息编码在提示中,引导模型生成目标导向的行为。另一种方法是训练专门的目标编码器,将自然语言描述的目标转换为模型可处理的表示。
情境意识的实现需要整合多模态感知信息。当前的研究主要采用视觉-语言模型作为感知前端,将视觉信息转换为语言描述或向量表示,然后由大语言模型进行情境理解。一些研究还探索了使用3D场景图或神经场景表示来支持更精确的空间推理。
自我意识在当前系统中仍然是一个开放问题。一些研究探索了让模型评估自身不确定性的方法,如通过多次采样估计输出的方差,或训练专门的不确定性估计模块。这些方法虽然远未达到人类水平的自我意识,但在提高系统可靠性方面显示出潜力。
符号接地问题与解决方案
符号接地问题的理论渊源
符号接地问题(Symbol Grounding Problem)由认知科学家Stevan Harnad于1990年提出,是人工智能和认知科学领域的经典问题。这一问题的核心在于:符号系统中的符号如何获得其意义?在传统的人工智能系统中,符号(如单词、概念)之间的关系通过形式规则定义,但这些符号本身并不指向任何外部实体------它们只是通过与其他符号的关系来定义,形成了"符号循环"。
Harnad用一个生动的比喻来说明这一问题:想象一个人在房间里,通过一本规则书将中文字符转换为其他中文字符。这个人不需要理解任何中文,只需要按照规则进行符号操作。这个比喻后来被Searle发展为著名的"中文房间"思想实验,用来质疑强人工智能的可能性。
对于大语言模型而言,符号接地问题具有特殊的意义。这些模型通过在海量文本数据上的训练,学习到了词元之间的统计关系。然而,模型中的词元向量并不直接指向现实世界中的实体和概念------它们的意义来自于与其他词元的关系,而非与外部世界的联系。这导致模型可能生成语法正确但语义空洞或错误的内容。
接地作为数字世界与现实的桥梁
综述论文将符号接地视为连接数字世界与现实世界的桥梁。在人类认知中,概念的意义来自于多渠道的经验:我们不仅通过语言描述了解"苹果",还通过视觉感知苹果的外观、通过触觉感知苹果的质地、通过味觉感知苹果的味道。这些多模态经验共同构成了"苹果"概念的丰富意义。
对于人工智能系统,接地意味着建立符号与感知经验之间的联系。这可以通过多种方式实现:将语言符号与视觉图像关联、与物理对象关联、或与交互经验关联。接地的过程使得符号不再是空洞的标记,而是承载了关于外部世界的丰富信息。
皇家学会哲学论文集发表的研究《Symbols and grounding in large language models》深入分析了这一问题。研究表明,虽然大语言模型缺乏传统意义上的符号接地,但它们可能通过另一种方式实现"功能性接地"------即通过学习语言使用中的规律,获得类似于接地的能力。这一观点引发了关于大语言模型是否真正需要传统符号接地的讨论。
符号接地的实现方法
综述论文系统性地回顾了在大语言模型中实现符号接地的多种方法。
知识图谱增强方法
知识图谱提供了结构化的世界知识,可以作为符号接地的外部锚点。通过将大语言模型与知识图谱结合,模型可以访问关于实体和关系的明确知识,增强其生成内容的准确性和一致性。具体实现方式包括:在预训练或微调阶段引入知识图谱信息、在推理时检索相关知识图谱三元组、或使用知识图谱约束生成过程。
本体驱动的提示方法
本体(Ontology)定义了领域内的概念和关系,可以作为符号接地的框架。通过设计基于本体的提示,可以引导模型按照预定义的概念结构进行推理和生成。这种方法在专业领域(如医疗、法律)特别有用,可以确保模型输出符合领域知识规范。
端到端嵌入方法
端到端嵌入方法通过多模态训练,直接学习语言符号与感知输入之间的映射。视觉-语言模型如CLIP、BLIP等通过在大规模图像-文本对上的对比学习,建立了图像区域与语言描述之间的关联。这种方法使得语言符号能够"接地"到视觉经验,增强了模型对视觉概念的理解能力。
主动探索与交互方法
主动探索方法让智能体通过与环境的交互来建立符号与世界的联系。这类似于人类儿童通过探索世界来学习概念。在具身AI设置中,智能体可以主动执行行动,观察结果,从而学习行动-效果关系,建立符号与物理世界的接地。
外部锚点
接地过程
符号接地方法
知识图谱增强
本体驱动提示
端到端嵌入
主动探索交互
符号输入
外部锚点检索
多模态关联
意义建立
结构化知识
领域本体
感知输入
交互经验
大语言模型中的接地挑战与争议
关于大语言模型是否真正需要传统意义上的符号接地,学术界存在争议。一些研究者认为,大语言模型通过学习语言使用中的规律,已经获得了某种形式的"功能性接地"。EMNLP 2024发表的研究《Why The Symbol Grounding Problem Does Not Apply to LLMs》论证了这一观点,认为大语言模型的工作方式与传统符号系统有本质区别,符号接地问题可能不适用于这类模型。
然而,另一些研究者持不同观点。《The Vector Grounding Problem》一文提出了"向量接地问题"的概念,认为大语言模型的内部状态和输出是否能够指向语言之外的世界,仍然是一个需要解决的问题。这一观点强调,即使模型的表示方式与传统符号不同,接地问题仍然以新的形式存在。
综述论文采取了平衡的观点:虽然大语言模型可能不需要传统意义上的符号接地,但增强模型与外部世界的联系仍然是有价值的。这种增强可以提高模型的可靠性、减少幻觉、支持更丰富的语义理解。
因果推理与认知能力
因果性的理论基础
因果性(Causality)是理解世界运作的核心概念。与相关性不同,因果关系描述的是"导致"关系------一个事件如何引起另一个事件的发生。因果推理能力使人类能够预测干预效果、解释现象原因、设计有效策略,是智能的核心组成部分。
Judea Pearl提出的因果阶梯(Causal Ladder)框架将因果推理分为三个层次:关联(Association)、干预(Intervention)和反事实(Counterfactual)。关联层次涉及观察和预测,回答"如果我看到X,Y的概率是多少"的问题;干预层次涉及行动和改变,回答"如果我做X,Y会发生什么"的问题;反事实层次涉及想象和反思,回答"如果X没有发生,Y会怎样"的问题。
大语言模型主要在关联层次运作------它们学习的是变量之间的统计相关性。这使得模型在面对需要因果理解的任务时存在根本性局限。例如,模型可能知道"下雨"和"地面湿"经常同时出现,但可能无法正确理解是"下雨导致地面湿"而非"地面湿导致下雨"。
大语言模型的因果推理能力评估
近年来,研究者们开发了一系列基准来评估大语言模型的因果推理能力。CLadder基准测试了模型在不同因果场景下的推理能力,包括因果发现、因果推断和反事实推理。研究发现,虽然大语言模型在某些因果推理任务上表现不错,但其能力主要来自于训练数据中的因果知识记忆,而非真正的因果理解。
Microsoft Research发表的研究《Causal Reasoning and Large Language Models》深入分析了这一问题。研究表明,大语言模型能够生成准确的因果论证,在因果发现、反事实推理和事件因果性等任务上超越了现有方法。然而,研究也发现模型存在"因果鹦鹉"(Causal Parrots)现象------模型能够复述因果知识,但并不真正理解或应用它。
AAAI研讨会发表的论文《Can Large Language Models Truly Understand Causality?》进一步探讨了这一问题。研究指出,大语言模型在处理新颖的因果场景、需要多步因果推理的任务、以及与训练数据分布不同的情境时,表现显著下降。这表明模型的因果能力存在泛化局限。
因果建模方法
综述论文讨论了在大语言模型中实现因果推理的几种方法。
传统深度学习方法
传统深度学习方法尝试通过数据驱动的方式学习因果关系。因果发现算法如PC算法、FCI算法可以从观测数据中学习因果图结构。然而,这些方法通常需要大量数据和强假设,且难以处理高维数据和复杂因果关系。将因果发现与大语言模型结合是一个有前景的方向:大语言模型可以提供先验知识,指导因果发现过程。
神经符号方法
神经符号方法结合了神经网络的学习能力和符号系统的推理能力。在大语言模型中,这可以通过引入因果图或因果规则来实现。例如,可以将因果知识编码为结构化的提示,引导模型进行因果推理。或者,可以训练模型生成因果图,然后使用符号推理引擎进行因果推断。
物理信息世界模型
物理信息世界模型尝试学习环境的动态规律,包括因果关系。这类模型不仅预测"什么会发生",还理解"为什么发生"。通过在模型中编码物理定律和因果机制,可以增强模型的因果推理能力。综述论文指出,世界模型是通向AGI的重要方向,因为它提供了对世界运作规律的内部表示。
因果建模方法
大语言模型位置
因果阶梯
局限
增强
增强
增强
第一层:关联 Association
P(Y|X) 观察预测
第二层:干预 Intervention
P(Y|do(X)) 行动改变
第三层:反事实 Counterfactual
P(Y_X|X',Y') 想象反思
主要在关联层运作
学习统计相关性
传统深度学习
数据驱动因果发现
神经符号方法
因果图+神经网络
世界模型
学习环境动态
因果推理的挑战与前景
实现真正的因果推理能力仍然面临重大挑战。首先,因果识别问题:从观测数据中识别因果关系需要强假设,而这些假设在现实场景中往往难以满足。其次,因果泛化问题:模型学到的因果知识可能无法泛化到新场景,特别是当新场景的因果机制与训练数据不同时。第三,因果解释问题:即使模型能够做出正确的因果预测,也可能无法提供人类可理解的因果解释。
尽管存在这些挑战,因果推理仍然是通向AGI的关键能力。综述论文指出,未来的研究应该关注如何将因果知识与语言模型更紧密地结合,如何让模型通过交互学习因果关系,以及如何评估模型的因果理解能力而非仅仅是因果知识记忆。
记忆机制与知识存储
记忆的理论框架
记忆是智能的核心组成部分,它使得智能体能够积累经验、学习知识、并基于过去进行推理。认知心理学将人类记忆分为多个系统:感觉记忆(Sensory Memory)、工作记忆(Working Memory)和长期记忆(Long-term Memory)。这一分类框架为理解和设计AI系统的记忆机制提供了理论基础。
感觉记忆是信息处理的最初阶段,短暂地保存感觉信息(视觉约0.5秒,听觉约2-4秒)。这一阶段的记忆容量大但持续时间短,为后续的信息处理提供输入。工作记忆是信息处理的活跃阶段,负责暂时存储和操作信息。工作记忆的容量有限(约7±2个信息单元),持续时间约20-30秒,是推理、理解和学习的关键。长期记忆是信息的持久存储,容量几乎无限,持续时间可以从几分钟到一生。长期记忆进一步分为陈述性记忆(事实和事件)和程序性记忆(技能和习惯)。
对于人工智能系统,记忆机制的设计需要考虑信息的编码、存储、检索和更新。不同的记忆类型需要不同的实现方式,以支持各种认知功能。
大语言模型中的记忆机制
大语言模型中的记忆可以通过多种方式实现,每种方式都有其特点和局限。
参数记忆
参数记忆是指将知识编码在模型参数中的方式。在预训练过程中,模型通过学习文本数据的统计规律,将知识隐式地存储在权重矩阵中。这种记忆方式的优点是知识可以直接用于推理,无需额外的检索步骤;缺点是知识难以更新、难以解释、且可能包含训练数据中的偏见和错误。
参数记忆的容量与模型规模相关。研究表明,更大的模型能够存储更多的知识,但存储效率(每参数存储的知识量)可能随规模增加而下降。此外,参数记忆存在"灾难性遗忘"问题------在学习新知识时可能遗忘旧知识。
注意力作为记忆
Transformer架构的自注意力机制可以被视为一种短期记忆机制。在处理序列时,注意力机制允许模型访问之前所有位置的信息,类似于工作记忆的功能。然而,这种"记忆"受到上下文长度限制,且计算复杂度随序列长度二次方增长。
扩展上下文长度是当前研究的热点。各种技术如稀疏注意力、线性注意力、状态空间模型等被提出来解决这一问题。Google的Titans架构探索了将长期记忆模块集成到Transformer中的方法,展示了增强记忆能力的潜力。
显式记忆模块
显式记忆模块提供了独立于模型参数的记忆存储。这类方法通常使用外部存储器(如向量数据库)来存储信息,并通过检索机制访问。显式记忆的优点是知识可以动态更新、容量可以独立扩展、且存储内容可解释。
检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合检索和生成的架构。在RAG框架中,模型在生成响应前先从外部知识库检索相关信息,然后将检索结果作为上下文输入模型。这种方法有效地扩展了模型的知识范围,减少了幻觉问题,并支持知识更新。
表4:大语言模型记忆机制对比
| 记忆类型 | 实现方式 | 容量 | 持续性 | 可更新性 | 典型应用 |
|---|---|---|---|---|---|
| 参数记忆 | 模型权重 | 有限(与规模相关) | 永久(需重新训练更新) | 困难 | 预训练知识 |
| 注意力记忆 | 上下文窗口 | 有限(受长度限制) | 临时(单次推理) | N/A | 短期上下文 |
| 显式记忆 | 外部存储器 | 可扩展 | 持久 | 容易 | 知识库 |
| RAG | 检索+生成 | 可扩展 | 持久 | 容易 | 问答系统 |
记忆系统的设计原则
综述论文提出了设计大语言模型记忆系统的几个原则。
多时间尺度
人类记忆系统在多个时间尺度上运作:感觉记忆以毫秒计,工作记忆以秒计,长期记忆以年计。类似地,AI记忆系统应该支持不同时间尺度的信息存储和检索。这可以通过设计层次化的记忆架构来实现,不同层次处理不同时间尺度的信息。
选择性注意
人类工作记忆的容量有限,需要选择性注意机制来决定哪些信息进入工作记忆。AI系统同样需要选择性机制来管理有限的计算资源。注意力机制提供了这种选择性的基础,但更高级的选择策略可能需要额外的控制模块。
记忆巩固
人类记忆通过巩固过程将短期记忆转化为长期记忆。这一过程涉及记忆的重放和重组。在AI系统中,类似的机制可以通过经验回放、知识蒸馏或持续学习技术来实现。
遗忘机制
遗忘是记忆系统的重要组成部分,它防止记忆过载并消除过时信息。设计合理的遗忘机制对于AI系统同样重要。这可以通过设置记忆衰减率、定期清理低价值记忆、或使用注意力机制动态选择相关记忆来实现。
记忆操作
LLM实现方式
记忆系统架构
输入
巩固
检索
感觉记忆
Sensory Memory
毫秒级
工作记忆
Working Memory
秒级
长期记忆
Long-term Memory
持久
输入编码器
多模态感知
上下文窗口
注意力机制
外部存储
向量数据库
编码 Encoding
存储 Storage
检索 Retrieval
遗忘 Forgetting
长期记忆的挑战与进展
实现有效的长期记忆是大语言模型面临的重要挑战。综述论文讨论了几个关键问题。
记忆容量与效率
传统的Transformer架构在处理长序列时面临计算效率问题。自注意力机制的O(n2)O(n^2)O(n2)复杂度限制了可处理的序列长度。各种改进方法被提出,包括稀疏注意力(只关注部分位置)、线性注意力(将注意力计算分解为线性操作)、状态空间模型(使用递归结构处理长序列)等。
记忆检索的准确性
从大规模记忆库中准确检索相关信息是一个挑战。传统的向量相似度检索可能无法捕获语义相关性,特别是当查询和记忆使用不同的表达方式时。改进检索准确性的方法包括:使用更强大的编码器、引入重排序机制、以及结合知识图谱的结构化检索。
记忆更新与一致性
在动态环境中,记忆需要不断更新以反映新的信息。然而,如何在不破坏现有知识的情况下整合新知识,是一个开放问题。持续学习领域的研究提供了部分解决方案,如弹性权重巩固、渐进式神经网络等,但这些方法在大语言模型中的应用仍在探索中。
Google的研究在记忆增强Transformer方面取得了重要进展。Titans架构探索了将长期记忆模块集成到Transformer中的多种方式,包括记忆作为门控(Memory as a Gate,MAG)、记忆作为深层记忆(Memory as a Deep Memory,MAD)等架构。这些研究表明,显式的记忆模块可以显著增强模型处理长程依赖的能力。
AGI框架整合与未来展望
四大原则的有机整合
Mumuni等人的综述论文提出了一个整合具身性、符号接地、因果性和记忆四大原则的AGI框架。这一框架的核心思想是:这四个原则不是独立的,而是相互关联、相互支持的。具身性提供了与世界交互的渠道,符号接地建立了符号与现实的联系,因果性支持理解和预测,记忆则使知识和经验得以积累。
在整合框架中,具身智能体通过感知和行动与环境交互,获得第一手的经验。这些经验通过符号接地过程被编码为可操作的知识表示。因果推理能力使智能体能够理解经验中的因果关系,形成对世界运作规律的认识。记忆系统则负责存储和检索这些知识和经验,支持长期学习和推理。
这种整合框架与认知科学中的具身认知理论相呼应。具身认知理论认为,认知不是抽象的信息处理,而是深深植根于身体与环境的交互之中。感知、行动和认知是相互交织的,共同构成了智能的基础。
世界模型与AGI
世界模型(World Model)是近年来AI领域的重要概念,被认为是通向AGI的关键技术。世界模型是指智能体对环境动态的内部表示,它使智能体能够预测行动的后果、规划未来的行为、并在想象中进行学习。
综述论文讨论了世界模型与四大原则的关系。具身性为世界模型的构建提供了数据来源------通过与环境的交互,智能体能够收集关于环境动态的数据。符号接地使世界模型中的表示能够对应于现实世界的实体和关系。因果性是世界模型的核心------一个好的世界模型应该能够捕获环境中的因果结构。记忆则是世界模型的基础设施,支持对历史经验的存储和利用。
世界模型的实现有多种方式。基于深度学习的方法使用神经网络学习环境动态,如循环世界模型、基于Transformer的世界模型等。基于物理的方法尝试将物理定律编码到模型中,以提高预测的准确性和泛化能力。混合方法则结合数据驱动和基于模型的方法,以获得两者的优势。
环境
智能体
世界模型
AGI整合框架
交互
语义连接
因果理解
经验存储
反馈
决策
具身性
Embodiment
符号接地
Grounding
因果性
Causality
记忆
Memory
环境动态表示
预测与规划
感知 Perception
行动 Action
推理 Reasoning
学习 Learning
物理世界
数字世界
当前研究进展与代表性工作
综述论文回顾了当前在AGI方向上的代表性研究工作。
在具身AI领域,Nature Machine Intelligence发表的ELLMER框架展示了将大语言模型与机器人控制结合的潜力。该框架整合了AI方法和感觉运动控制方法,创建了能够执行复杂任务的具身智能体。研究表明,具身LLM能够理解自然语言指令,并在真实环境中执行相应任务。
在符号接地领域,视觉-语言模型如CLIP、BLIP等通过多模态训练建立了语言与视觉的联系。这些模型展示了将语言符号"接地"到视觉经验的可能性。然而,全面的符号接地仍然需要与更丰富的感知模态和交互经验结合。
在因果推理领域,研究者们探索了多种将因果知识与语言模型结合的方法。一些研究使用因果图约束模型的推理过程,另一些研究训练模型生成因果解释。然而,实现真正的因果理解仍然是一个开放问题。
在记忆增强领域,Google的Titans架构、各种RAG系统、以及记忆增强神经网络展示了增强大语言模型记忆能力的多种途径。这些研究为构建具有长期记忆能力的智能系统提供了技术基础。
挑战与未来方向
尽管取得了显著进展,实现AGI仍然面临重大挑战。综述论文识别出了几个关键挑战。
数据效率
当前的大语言模型需要海量数据进行训练,而人类能够从少量经验中学习。提高数据效率是实现AGI的重要方向。这可能需要新的学习范式,如元学习、因果学习、或神经符号方法。
泛化能力
大语言模型在分布内任务上表现出色,但在分布外任务上泛化能力有限。实现真正的通用智能需要更强的泛化能力,能够适应新环境、新任务和新概念。
可解释性
大语言模型的决策过程难以解释,这限制了其在关键领域的应用。提高模型的可解释性,使其决策过程透明、可理解,是重要的研究方向。
安全与对齐
随着AI系统能力的增强,确保其行为符合人类价值观和利益变得至关重要。AI对齐研究探索如何使AI系统的目标与人类意图一致,这是实现安全AGI的关键。
计算效率
当前大语言模型的训练和推理需要大量计算资源,限制了其普及和应用。开发更高效的模型架构和训练方法,是实现AGI实际应用的重要方向。
结论与展望
核心贡献总结
Mumuni和Mumuni的综述论文《Large language models for artificial general intelligence (AGI): A survey of foundational principles and approaches》为理解大语言模型与AGI的关系提供了系统性框架。论文识别出了四个基础性原则------具身性、符号接地、因果性和记忆,并深入分析了每个原则的理论基础、当前进展和实现方法。
论文的核心贡献在于:首先,它提供了一个整合性的理论框架,将分散的研究线索组织成连贯的知识体系;其次,它明确指出了大语言模型通向AGI需要解决的核心问题,为未来研究指明了方向;第三,它系统性地回顾了各领域的最新进展,为研究者提供了丰富的参考资料。
技术路径展望
基于综述论文的分析,我们可以展望通向AGI的技术路径。短期来看,研究重点可能集中在:增强大语言模型的多模态能力,实现更丰富的符号接地;开发更有效的记忆增强技术,支持长期学习和推理;改进因果推理能力,使模型能够理解和应用因果关系。
中期来看,具身AI可能成为重要方向。将大语言模型与机器人系统结合,创建能够在物理世界中感知、行动和学习的智能体,是通向AGI的重要途径。同时,世界模型的研究将使智能体能够预测和规划,支持更复杂的认知任务。
长期来看,实现真正的AGI可能需要根本性的突破。这可能包括:新的学习范式,使系统能够从少量数据中学习;新的架构设计,支持更高效的计算和更强的泛化;新的理论框架,为智能的本质提供更深刻的理解。
结语
大语言模型的兴起重新点燃了对AGI的希望和讨论。然而,正如Mumuni等人的综述所强调的,当前的大语言模型虽然展现出了令人印象深刻的能力,但其认知能力仍然"肤浅且脆弱"。实现真正的通用智能,需要解决具身性、符号接地、因果性和记忆等基础性问题。
这些问题的解决不仅需要技术进步,还需要跨学科的合作。认知科学、神经科学、哲学和人工智能的交叉融合,将为理解智能的本质提供更丰富的视角。AGI的实现可能是人类历史上最重要的技术突破,它将深刻改变我们与技术的关系,以及我们理解自身的方式。
参考文献
-
Mumuni A, Mumuni F. Large language models for artificial general intelligence (AGI): A survey of foundational principles and approachesJ. arXiv preprint arXiv:2501.03151, 2025.
-
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you needJ. Advances in neural information processing systems, 2017, 30.
-
Harnad S. The symbol grounding problemJ. Physica D: Nonlinear Phenomena, 1990, 42(1-3): 335-346.
-
Pearl J. Causality: Models, reasoning, and inferenceM. Cambridge university press, 2009.
-
Bubeck S, Chandrasekaran V, Eldan R, et al. Sparks of artificial general intelligence: Early experiments with GPT-4J. arXiv preprint arXiv:2303.12712, 2023.
-
Wei J, Wang X, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language modelsJ. Advances in Neural Information Processing Systems, 2022, 35: 24824-24837.
-
Brown T, Mann B, Ryder N, et al. Language models are few-shot learnersJ. Advances in neural information processing systems, 2020, 33: 1877-1901.
-
Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervisionC//International conference on machine learning. PMLR, 2021: 8748-8763.
-
Kıcıman E, Ness R, Sharma A, et al. Causal reasoning and large language models: Opening a new frontier for causalityJ. Transactions on Machine Learning Research, 2024.
-
Jin Z, Chen Y, Leeb F, et al. CLadder: Assessing causal reasoning in language modelsJ. Advances in Neural Information Processing Systems, 2024, 36.
-
Driess D, Xia F, Sajjadi M S M, et al. PaLM-E: An embodied multimodal language modelJ. arXiv preprint arXiv:2303.03378, 2023.
-
Brohan A, Brown N, Carbajal J, et al. RT-2: Vision-language-action models transfer web knowledge to robotic controlJ. arXiv preprint arXiv:2307.15818, 2023.
-
Behrouz A, Hashemi F. Titans: Learning to memorize at test timeJ. arXiv preprint arXiv:2501.00663, 2024.
-
Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasksJ. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
-
Cao P, Li H, Geng Y, et al. Embodied large language models enable robots to complete complex tasksJ. Nature Machine Intelligence, 2025.
-
Cappelen A, Gärdenfors P. Symbols and grounding in large language modelsJ. Philosophical Transactions of the Royal Society A, 2023, 381(2251): 20220041.
-
Zevcevic M, Willig M, Dhami D S, et al. Causality for large language modelsJ. arXiv preprint arXiv:2410.15319, 2024.
-
Wang L, Ma C, Feng F, et al. A survey on large language model based autonomous agentsJ. Frontiers of Computer Science, 2024, 18(6): 186345.
-
OpenAI. GPT-4 Technical ReportJ. arXiv preprint arXiv:2303.08774, 2023.
-
Anthropic. Claude 3 Technical ReportR. 2024.