前言
前面讲了 AdvancedRAG 在检索前的各种优化,那么在检索时能做哪些优化呢?我们知道传统 RAG 采用向量相似度来检索。现在有这样一个🌰:
- query:404 Net Not Found 错误怎么解决
- LLM(RAG):返回大量关于"系统故障排查"、"常见错误处理"的通用指南,因为它们语义相关。
- 痛点 :但是可能有一篇《404 Net Not Found解决方案》,因为内容的语义问题而被遗漏。
这个时候就需要传统的"关键词检索",精准命中包含"404 Net Not Found"的文档。当然,使用纯关键词搜索也是不够的。
所以是不是有思路了? 我们在前面的第一个 RAG 实战:医疗知识混合检索系统 中就使用了"向量检索 + 关键词检索"的混合检索方式。
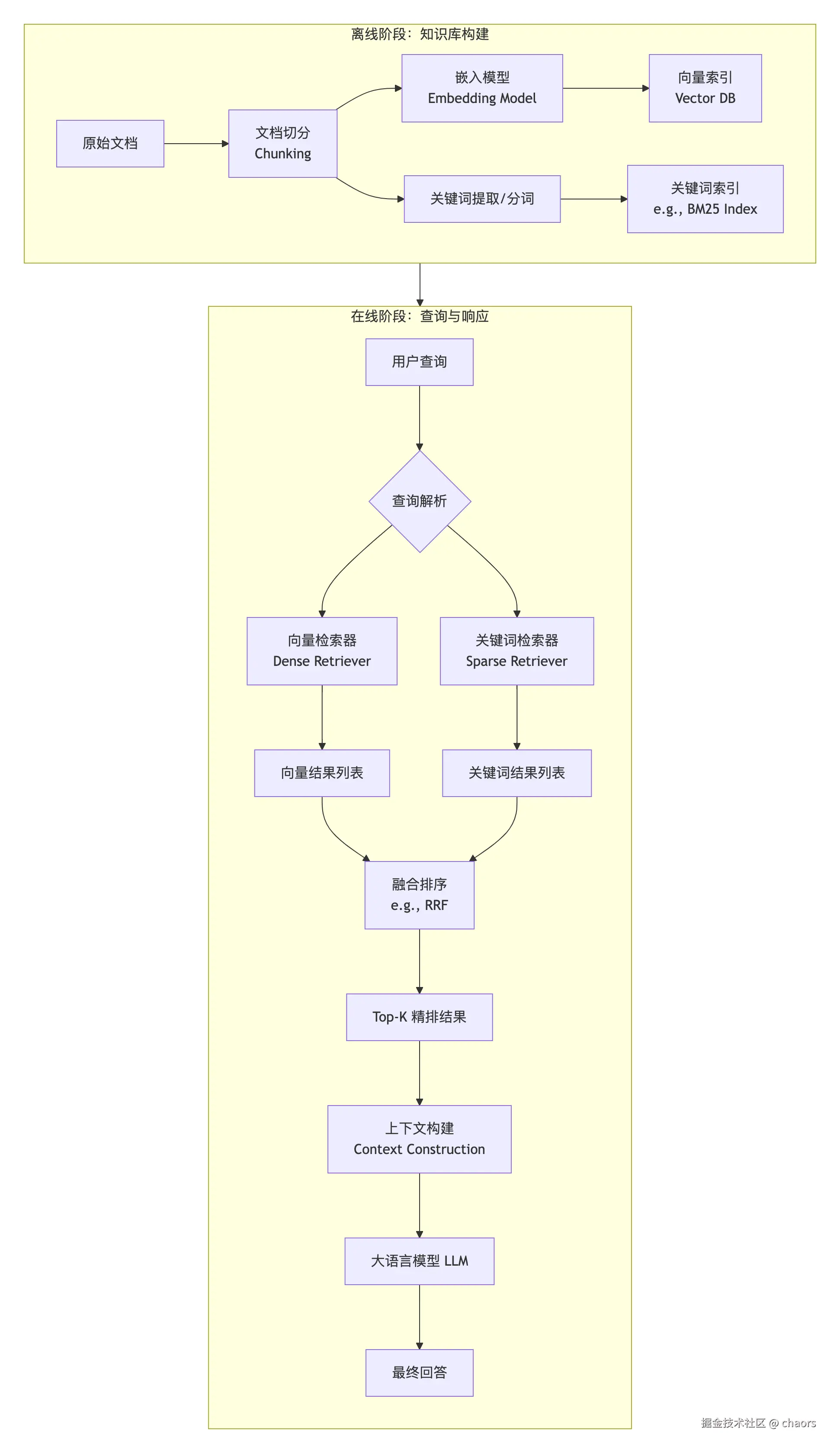
Hybird Search(混合检索)
通过组合两种根本不同的检索方式,来克服单一方法的固有缺陷,从而在"精确匹配 "与"语义理解"这两个常常矛盾的目标上取得最佳平衡。
-
检索方式:
-
稀疏检索 :代表算法是BM25 。它将文档和查询表示为庞大的、稀疏的向量(维度对应所有词表里的词,大部分值为0),通过统计关键词出现的频率、位置等信息计算相关性。它不关心词的语义,只关心"词是否匹配"。
-
稠密检索 :基于嵌入模型 (如BGE、text-embedding-v3)。它将文本映射到数百或数千维的稠密向量空间,语义相似的文本其向量距离也近。它深度理解语义,能处理同义词、转述和上下文推理。
-
-
核心流程:
-
并行检索:对于同一个用户查询,系统同时向稀疏检索索引(如倒排索引)和稠密检索索引(如向量数据库)发起搜索。
-
结果融合 :两路检索各自返回一个排序列表。由于它们的评分体系完全不同(一个是统计分数,一个是余弦相似度),无法直接比较。因此,需要做归一化处理。
-
EnsembleRetriever
EnsembleRetriever 是LangChain框架提供的一个高级检索器。通过组合多个基础检索器的输出,得到一个更优、更稳定的最终检索结果列表。我们这里的混合检索便要用到这个检索器。
- 核心:集成学习
归一化
定义
归一化 是将不同尺度和范围的特征或数据,转换到一个统一标准尺度的预处理技术。
- 目标:消除由于量纲、量级或分布不同带来的不可比性
- 本质:线性或非线性的数学变换
为什么❓
为什么要做归一化?这里很简单的一个🌰:
- BM25得分:85
- 向量相似度得分:0.77
至少我们可以看出一个很明显的原因:异源数据由于评分体系不同,如果直接比较将导致向量相似度得分全部淘汰。这显然不是我们想看到的,也不是正确的。
❓那么问题来了,如果本身 bm25 得出的分数也是小于 1 的浮点数 ,还需要进行归一化处理吗?其实还是需要的! 或者简单滴说:
- 数学的60分 和 音乐的60分等同吗?(假设都是总分100)
- 总排名的总成绩还能像 60 + 60这样去计算吗?
是不是感觉好理解了,数学和音乐试题的题量、难易程度都不一致,各自的分数关联的也是不同的语义。这和这里的 BM25 与向量相似度有着异曲同工之妙:
- BM25得分:0.66
- 向量相似度得分:0.66
同样是0.66,BM25 可能表示"出现了大部分关键词 ",向量相似度上可能表示"语义高度相关但未必包含原词 "。这两个0.66分的"含金量"不同,直接相加会混淆不同模型所衡量的"相关性"概念。
Max-Min 模式
- 将原始数据线性地映射到0, 1区间,是较为简单的一种归一化算法
新值 = (原值 - 最小值) / (最大值 - 最小值)
RRF 算法
定义
RRF(Reciprocal Rank Fusion),即倒数排序融合算法。是一种比较常见且强大的归一化算法。
-
核心:它不关心每个系统内部的具体评分(如余弦相似度得分),只关心排名位置。排名越靠前(数值越小),倒数越大,贡献的分数就越高。这种设计能自动放大那些在多个系统中都表现良好的文档的权重。
-
N:参与融合的检索列表数量(例如BM25和向量检索,则 N=2;multi−query生成了3个问题,则 N=3 -
rank_i(d):文档d在第i个检索系统的排名(从1开始计数) -
k:平滑常数,通常设置为60
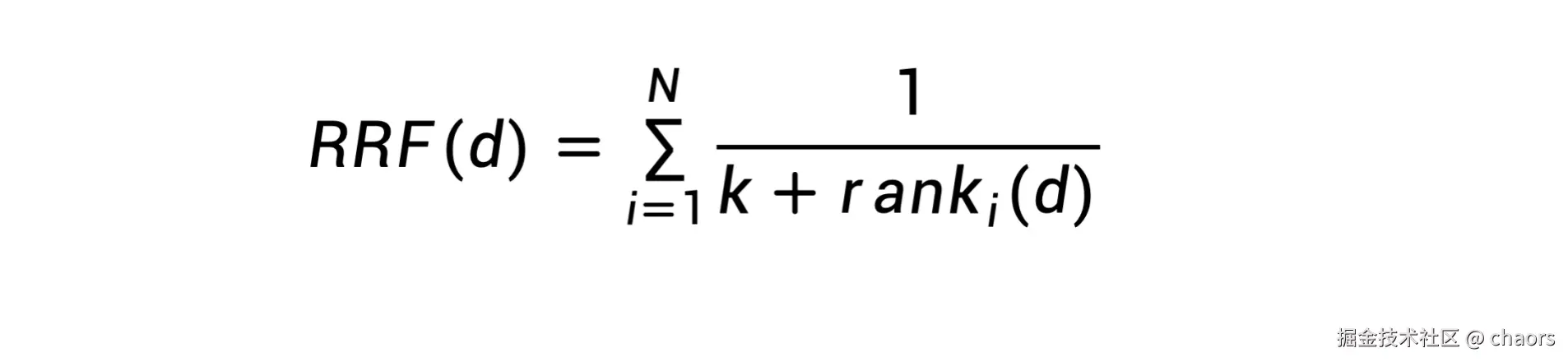
🌰:
现有如下排名,系统A、B分别为两种不同的检索系统。
| 系统A (关键词检索) 排名 | 文档 |
|---|---|
| 第1名 | 文档D |
| 第2名 | 文档A |
| 第3名 | 文档C |
| 第4名 | 文档B |
| 系统B (向量检索) 排名 | 文档 |
|---|---|
| 第1名 | 文档A |
| 第2名 | 文档B |
| 第3名 | 文档C |
| 第4名 | 文档D |
文档A:
- 在系统A中排名第2,1/(60+2)=1/62≈0.01613
- 在系统B中排名第1,1/(60+1)=1/61≈0.01639
- 总分=0.01613+0.01639=0.03252
文档B:
- 在系统A中排名第4,1/(60+4)=1/64≈0.01563
- 在系统B中排名第2,1/(60+2)=1/62≈0.01613
- 总分=0.01563+0.01613=0.03176
文档C:
- 在系统A中排名第3,1/(60+3)=1/63≈0.01587
- 在系统B中排名第3,1/(60+3)=1/63≈0.01587
- 总分=0.01587+0.01587=0.03174
文档D:
- 在系统A中排名第1,1/(60+1)=1/61≈0.01639
- 在系统B中排名第4,1/(60+4)=1/64≈0.01563
- 总分=0.01639+0.01563=0.03202
综上,可得出归一化处理后的综合排名:
-
文档A在两个系统中都排名很高(第2/第1),因此其 RRF总分最高,成为第1名。
-
文档D在一个系统中是第1名,但在另一个系统中是第4名,综合后成为第2名。
-
文档B 和文档C在各系统中的排名相对靠后,因此其综合排名也靠后。
Coding
其实混合检索在上次实战:医疗知识混合检索系统 都有过实践,流程差不多。这里关键讲差异代码:BM25Retriever & EnsembleRetriever。
关键词检索
ini
# 关键词检索
BM25_retriever = BM25Retriever.from_documents(split_docs)
BM25Retriever.k = 3
doc_BM25Retriever = BM25_retriever.invoke(question)向量检索
ini
# 向量检索
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
doc_vector_retriever = vector_retriever.invoke(question)混合检索
ini
# 混合检索
#EnsembleRetriever是Langchain集合多个检索器的检索器。
ensembleRetriever = EnsembleRetriever(retrievers=[BM25_retriever, vector_retriever], weights=[0.5, 0.5])
retriever_doc = ensembleRetriever.invoke(question)