目录
[1. 语言模型分类:](#1. 语言模型分类:)
[2. 评价指标:](#2. 评价指标:)
[3. 典型结构:](#3. 典型结构:)
[RAG 技术概述](#RAG 技术概述)
[1. RAG 提出背景:](#1. RAG 提出背景:)
[2. RAG 基本原理:](#2. RAG 基本原理:)
[3. 检索范式](#3. 检索范式)
[RAG 早期经典工作](#RAG 早期经典工作)
[1. REALM:](#1. REALM:)
[2. Retrieval-in-context LM](#2. Retrieval-in-context LM)
[3. RETRO](#3. RETRO)
[4. kNN-LM](#4. kNN-LM)
[5. 对比](#5. 对比)
[RAG 技术发展](#RAG 技术发展)
[1. 发展阶段:](#1. 发展阶段:)
[2. 核心共识:](#2. 核心共识:)
[RAG 最新研究进展](#RAG 最新研究进展)
[1. 检索过程优化:](#1. 检索过程优化:)
[2. 知识有效利用:](#2. 知识有效利用:)
[UltraRAG 开源项目介绍](#UltraRAG 开源项目介绍)
本文由九格大模型团队讲述 RAG 技术相关基础知识、技术发展历程以及最新研究进展。
语言模型基础
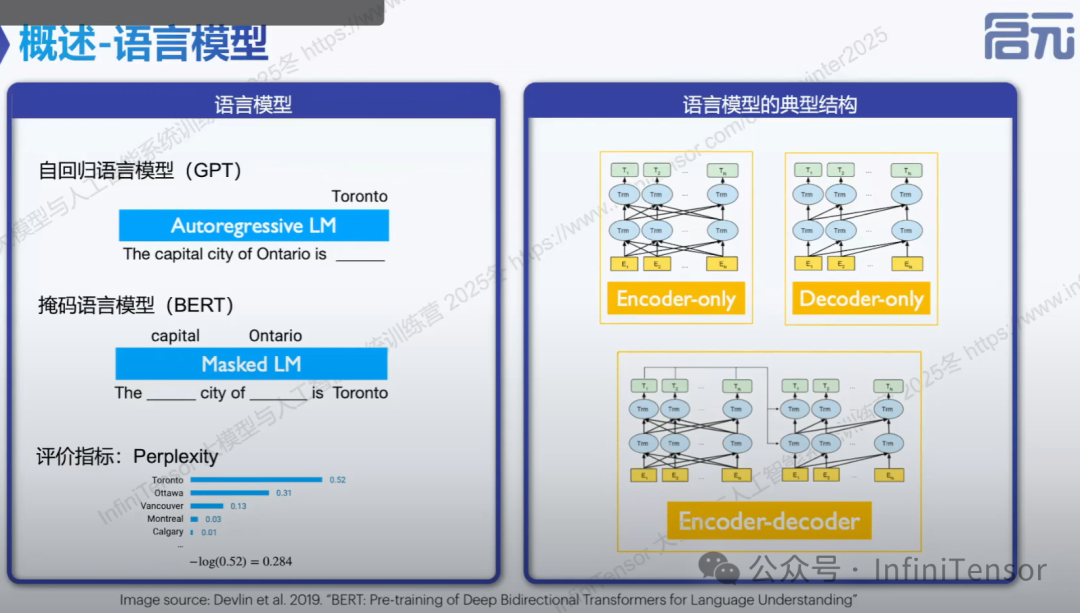
1. 语言模型分类:
-
• 自回归语言模型:GPT、千问等
-
• 掩码语言模型:BERT
2. 评价指标:
困惑度(Perplexity)
3. 典型结构:
-
• Encoder-Decoder 架构
-
• Encoder-only
-
• Decoder-only 的区别
RAG 技术概述
1. RAG 提出背景:
- • 预训练模型的局限性:知识密集型场景、时效性信息、幻觉问题
2. RAG 基本原理:
-
• 外部信息以平文本形式存在,通过检索增强模型生成能力
-
• 基础范式:用户 Query → 检索知识库 → 检索信息与 Query 结合 → 模型生成回答
3. 检索范式

RAG 早期经典工作
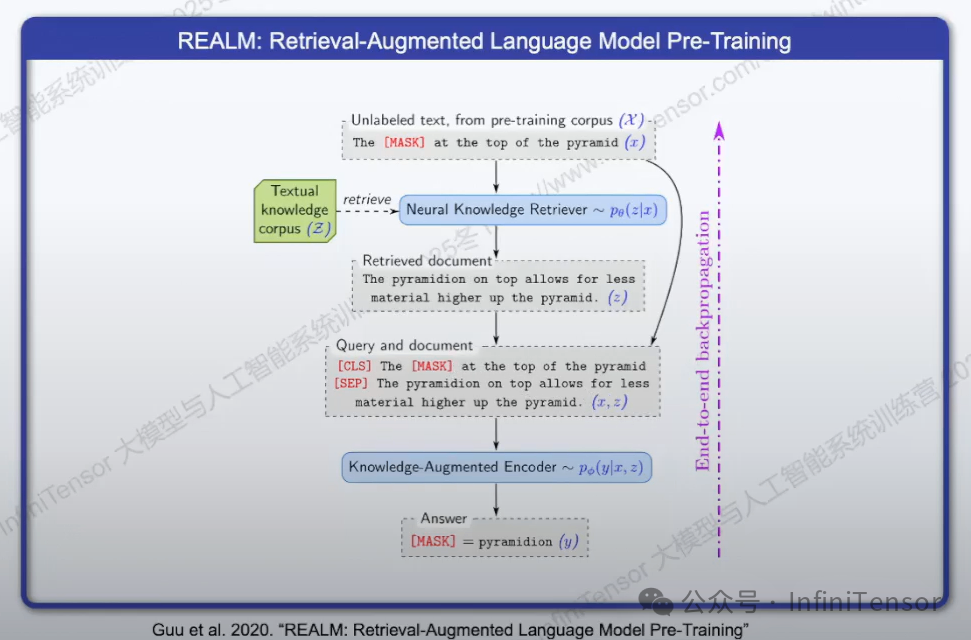
1. REALM:
- • 掩码模型,检索相关片段拼接后预测
-
• 检索模型训练:
-
• 单塔与双塔模型原理
-
• 对比学习训练 Embedding 模型
-
-
• 检索后处理:多次推理与概率平均
-
• 后续工作:DPR、RAG、Atlas 等面向开放域问答任务
2. Retrieval-in-context LM
- • 顺序预测模型

-
• 检索对象选择:
-
• 查询语句长度与噪声问题
-
• 实验分析:查询语句长度对检索效果的影响
-
-
• 检索频率优化:
-
• 提高检索频率对模型性能的影响
-
• 计算量与检索成本的平衡
-
-
• 召回文本数量影响:
-
• 召回数量与模型性能的关系
-
• 噪声引入与性能下降问题
-

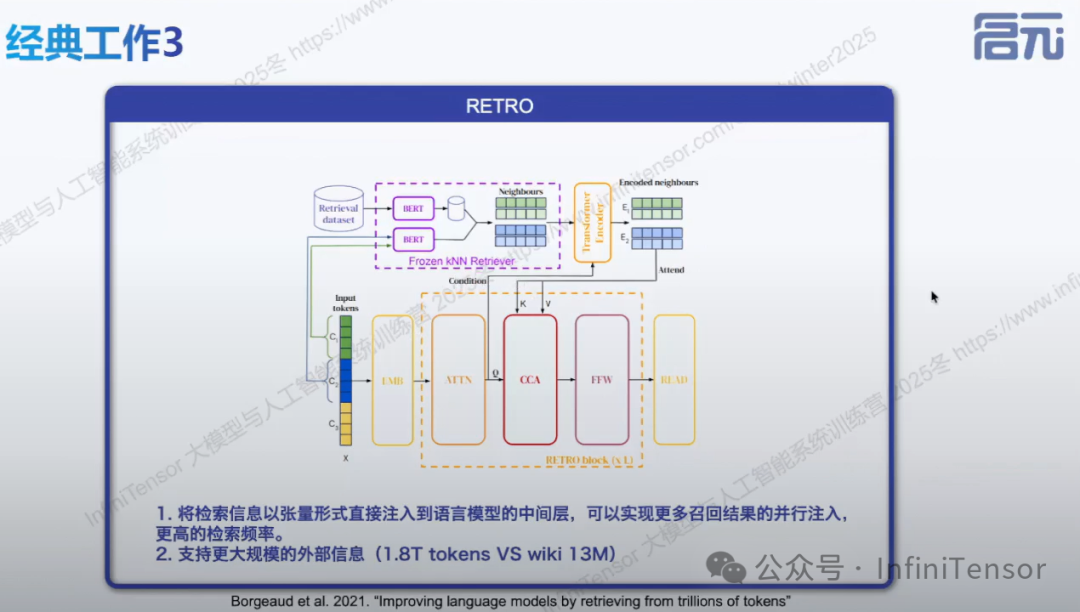
3. RETRO
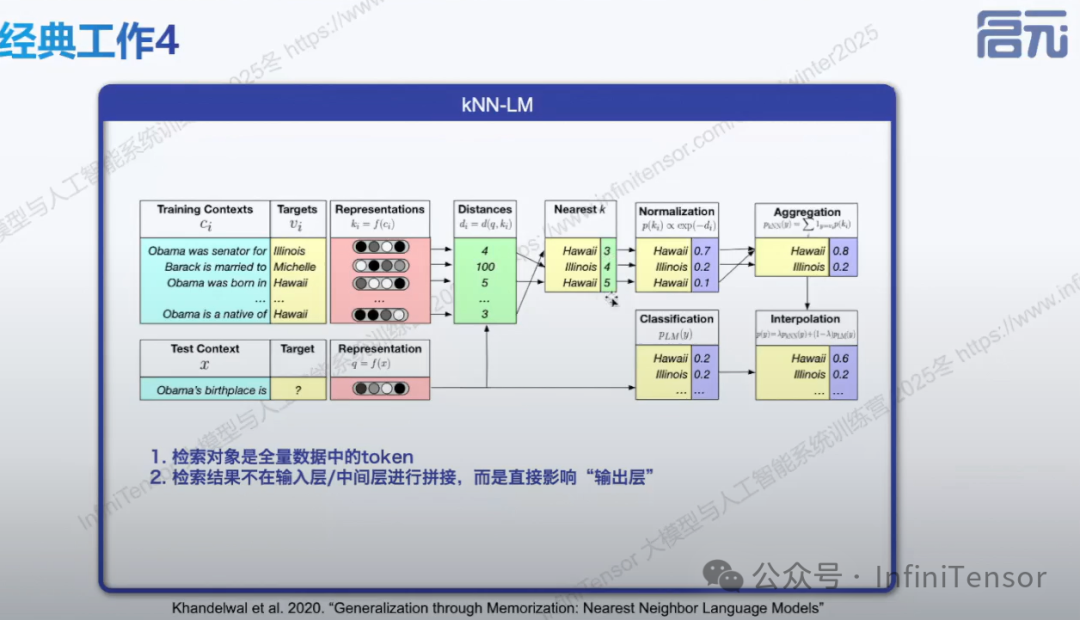
4. kNN-LM
5. 对比

RAG 技术发展
1. 发展阶段:
-
• 2022年:建立 RAG 基本范式
-
• 2023年:关注检索时机与方式优化
-
• 近期:结合思维链(CoT)、多模态知识注入
2. 核心共识:
-
• 基于 Embedding 模型的 Dense Retrieve 成为标配
-
• 输入范式:输入层直接拼接文本
RAG 最新研究进展
1. 检索过程优化:
-
• 多轮检索 (难以避免噪声问题)与自适应检索(信息割裂,缺少交互整合)
-
• 引入大模型笔记概念:记录检索信息、规划检索过程、减少噪声
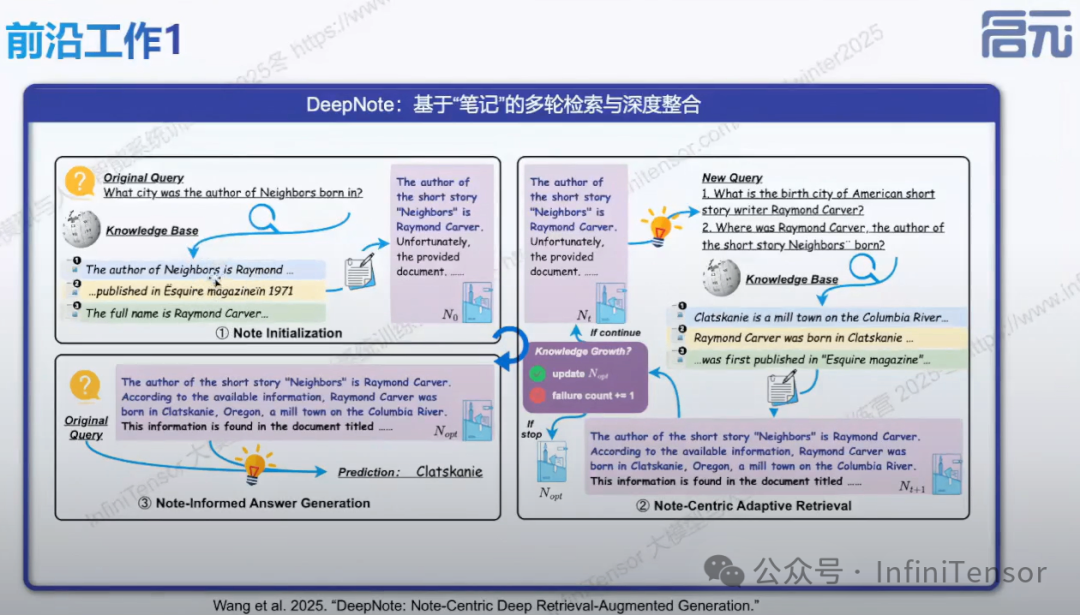
2. 知识有效利用:
-
• 指令跟随能力在知识密集场景下的局限性
-
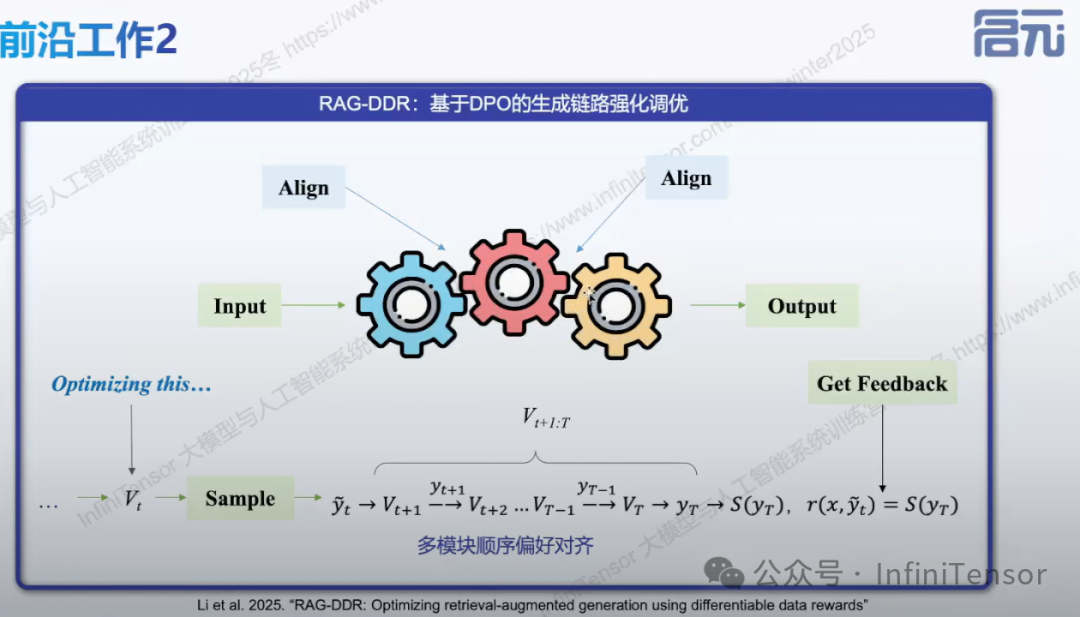
• 强化训练方法:DPO、GRPO 等
-
• RAG-DDR:基于 DPO 的生成链路强化调优
- • 后向对齐策略:模块化训练与采样调节
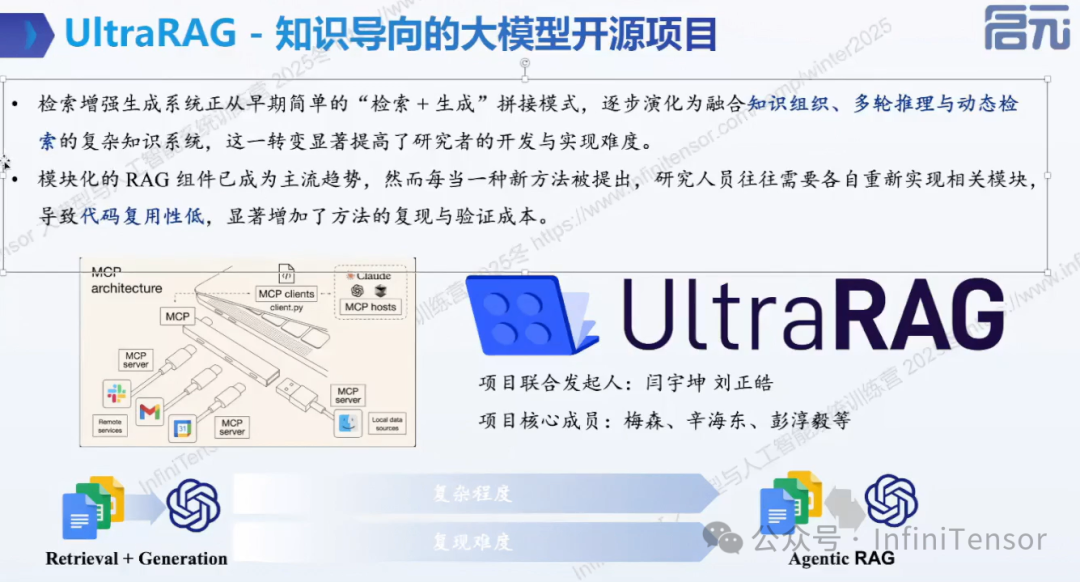
UltraRAG 开源项目介绍
总结
本文讲解了 RAG 技术原理、技术面临的挑战与解决方案,RAG 发展历程与最新研究进展。